
基于中医药领域图谱自动构建与可视化研究
2022-11-28 11:42顾泽元刘星陈慧琴
齐齐哈尔大学学报(自然科学版) 2022年6期
顾泽元,刘星,陈慧琴
(黑龙江科技大学 计算机与信息工程学院,哈尔滨 150022)
自2012 年5 月谷歌(Google)提出知识图谱的概念[1],知识图谱得到广泛关注和应用。中医药是中华文化的瑰宝,经历上千年的传承与发展,形成了以经验为根据的理论体系[2]。随着现代社会的快速发展,知识的快速流通和数据的更新与补充使得中医药领域积累了大量的文本数据。如何自动高效地从海量的医学信息中抽取出有价值的实体关系信息成为了当前的一个研究热点[3]。同时中医药领域知识体系还具有规模大、内涵丰富、关系复杂等特点。知识图谱作为资源管理和知识应用的重要技术,应用于中医药领域能够更加有效地描述、挖掘实体之间的关系,使得大规模的知识存储能够更为规范、应用更加高效,实现中医药资源的有效整合,为知识服务相关研究奠定基础,为中医药传承和发展提供新的思路。
本文在传统的知识图谱构建体系基础上,结合中医药领域提出了一套构建知识图谱的方法框架,以中医药药品说明书为例构建领域知识图谱,探索中医药领域的大规模存储和可视化分析展示。
1 相关研究
1.1 知识图谱研究现状
知识图谱是一种以图形式描述知识及其相互关系的技术方法[4],实质上是一种大规模的语义网络,是实现网络知识可视化的有效载体[5]。知识图谱主要由节点和边组成,其中节点表示实体,边表示实体间的语义关系。知识图谱与本体联系紧密,本体侧重于表达认知的概念框架,知识图谱旨在以图谱的形式直观、准确地描述实体或概念本身及其之间的关系[6],故在知识图谱构建时,模式层构建实质上就是在完成本体定义的任务[7-8]。
知识图谱根据其知识覆盖范围可以划分为通用知识图谱和领域知识图谱。通用知识图谱体量大、覆盖面广,其代表性的知识图谱有DBPEDIA[9],YAGO[10]等;领域知识图谱在精度和深度则有着更高要求,其应用形式更为广泛。如孙明俊等[11]基于知识图谱构建了类风湿性关节炎中医辅助诊疗系统,为医生展示相关的诊疗指导并推荐药方。
针对知识图谱技术,除最初应用在搜索引擎方面,国内外相关科学家们在其他的领域也进行了大量的研究。2015 年,徐浩等[12]利用知识图谱技术分析了2004 年至2012 年中医学科交叉领域的研究热点和知识源流以及在该领域具有高影响力的作者群体;2019 年,常亮等[13]提出了基于图谱的推荐系统框架,并分析了构建推荐系统的关键技术和重点及难点问题;2022 年,肖乐等[14]构建了面向粮情的领域知识图谱,通过图谱进行分析推理,进而达到辅助决策的效果。
除了国内的相关学者,国外的相关学者也对知识图谱进行了大量的相关研究。如ROTMENSCH MAYA等[15]基于三种概率模型研究知识图谱的自动化构建,实验成功从电子病例中学习到了高质量的知识库。ZHANG 等[16]根据ISI 的引文数据库中的文献资料,使用了知识图谱的分析方法,分析了全球灾害教育的研究热点和发展趋势。ZHANG DEHAI 等[17]将知识图谱嵌套进注意力聚合网络,用以提高推荐系统的性能。
1.2 中医药知识图谱研究现状
从领域上划分,中医药知识图谱属于垂直领域知识图谱。相较于成熟的通用知识图谱来说,垂直领域的知识图谱在图谱构建方面仍需人工标注数据,并且缺乏统一的构建方法。对于中医药知识图谱而言,图谱构建流程依然包括知识抽取、知识存储等技术。中医药知识图谱的构建应当以中医药学科的建设目标、研究内容为指导依据[18]。表1 根据中医药知识图谱的范围和应用目标对其进行了一些整理归纳。从中医药领域基础理论、中医临床等5 个方面,例举了一些知识图谱技术在中医药领域的一些研究成果。
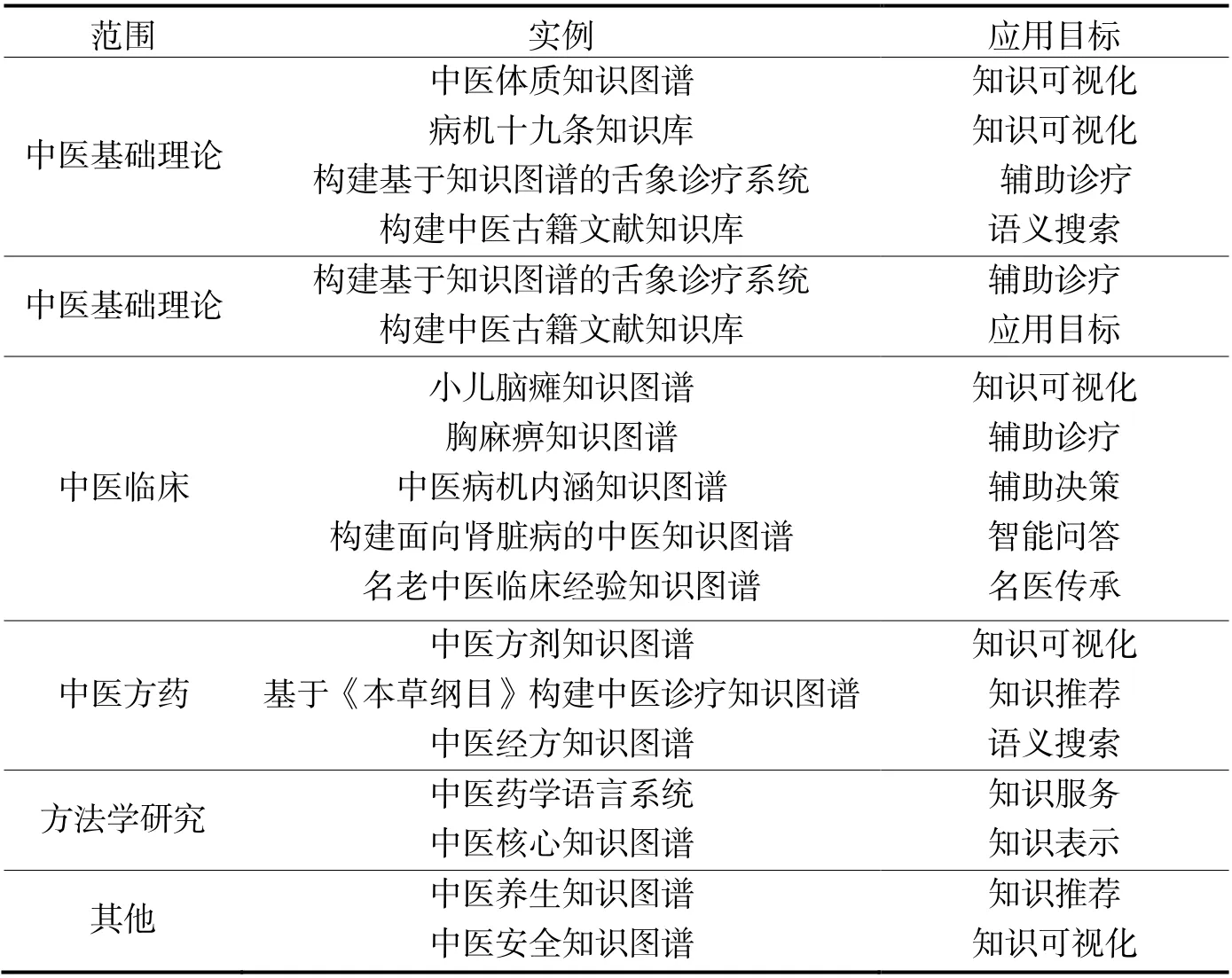
表1 中医药领域知识图谱应用示例
根据表1 罗列的研究成果,可以将中医药领域关于知识图谱技术的研究归纳成三个方面:
(1)以科学计量学为理论基础,数据来源大多是各大期刊的文献资料,使用知识图谱技术,归纳分析相关学科领域的研究前沿、发展趋势。(2)偏向于中医药知识图谱的技术方面,从技术、算法等方面,探索研究中医药知识图谱的标准化构建流程。(3)偏向于中医药知识图谱的应用方面,以中医药知识图谱为基础,专注于诸如知识推荐、语义搜索等下游任务的研究和探索。
虽然中医药学科使用知识图谱技术取得了一些成果,但是中医药知识图谱的研究依然面临者一些困难:
(1)没有统一标准的中医术语。中医术语是中医药领域利用特定文字来表述或限定专业概念的符号,集中体现中医学领域的核心知识[19]。中医药领域知识表达多样化,专家的诊疗相对独立、各具特点,经常以非结构化的文本形式存在,给信息抽取带来了一定的困难,故而需要标准的中医术语作为支撑。目前已有权威的药物、疾病词典,但是中医对于病症本身的描述相对复杂,在术语规范书没有形成统一的标准。(2)难以构建高质量的模式层。模式层的有效性将直接影响到知识图谱的质量,中医药领域隐形知识丰富且关系复杂,构建图谱耗时耗力,本体的构建并没有严格的规范和要求,如何定义本体之间的关系还没有统一的标准。(3)没有规范的知识融合技术。随着医疗数据不断增多以及中医师在实践过程中临床资料不断积累,这些不同来源的中医知识会存在大量重叠、知识质量参差不齐、知识关联关系不明确等问题[20]。由于中医本体的复杂性,中医本体对齐问题尚且没有得到很好地解决[21]。(4)没有适合中医药领域的推理方法和技术。中医药领域辅助诊疗系统的构建大部分都借助于人工智能领域比较成熟的技术和方法,但是这些技术和方法具有一定的适用范围,应用于中医药领域时,导致部分推导结果与中医真实的诊疗结果存在者一定的差距。
2 研究方法
本文构建中医药知识图谱的体系框架如图1 所示。

图1 中医药知识图谱框架图
本文构建中医药领域的知识图谱的过程分为数据获取、数据预处理、信息抽取、知识存储以及图谱可视化5 个部分。
(1)数据获取:数据集来源于阿里云平台的中医药药品说明书,该数据集有将近2 000 条药品说明书。
(2)数据预处理:构建用于训练的原始语料。
(3)信息抽取:使用信息抽取技术抽取语料中的中医药实体及其相互间的关系。
(4)知识存储:将抽取到的实体关系知识批量导入Neo4j 图数据库。
(5)图谱可视化:将图谱以可视化的形式呈现。
本文的主要研究内容与工作是根据当前的知识图谱研究现状,使用信息抽取技术,从非结构化的中医药药品说明书数据集中抽取出有价值的实体及其关系构建中医药领域的垂直领域知识图谱,并将图谱进行可视化的展示。研究内容与工作主要分为三个部分:
(1)命名体识别部分:该部分主要是利用命名体识别技术,从中医药药品说明书中挖掘出有价值的实体知识,如中医药剂型、中医药名称等。本文命名体识别采用的模型是BERT-BiLSTM-CRF。
(2)实体关系抽取部分:该部分主要是在实体抽取的基础上,加入关系抽取,采用目前主流的联合抽取方法,通过共享BiLSTM 的参数,将命名体识别任务与实体关系抽取任务结合,抽取出中医药药品说明书中有价值的实体对,并判断它们之间的关系。
(3)Neo4j 图数据库部分:该部分主要是将从中医药药品说明书中抽取出的实体以及关系,通过CSV文件导入的方式,将数据批量导入进Neo4j 图数据库中,进行可视化的展示和分析。
2.1 命名体识别
2.1.1 数据来源
本实验数据来源于阿里云天池大数据平台的中医药说明书实体识别数据集(https://tianchi.aliyun.com/dataset/dataDetail?dataId=86819),数据集共有1 000 份药品说明书(8.37 M),均为JSON 文本格式。该数据集已标注13 类实体,经过统计其中3 种类别的实体数量稀少,且与本文研究方向无关,最终选择10 类实体构建标注数据集。
2.1.2 构建实体标注数据集
针对中药实体数据,应用JSON 文本解析器抽取其中的文本并结构化存储。由于数据集都是段落形式,具有一定的噪声,为了提高模型的准确率和调试速度,需要对数据集进行预处理进行段落分句。由于每个句子的长短不一,为了不破坏句子的完整性,设定一个大小为N 的滑动窗口,从上一个分句的后N 个词开始新的分句。标注后的数据格式如表2 所示。

表2 标注后的数据格式
实验采用BIO 标注,每个字符标注以‘B’、‘I’或‘O’开头。其中‘B-x’表示实体类型为x 的第一个字符;‘I-x’表示实体类型为x 的中间位置或结尾位置字符;‘O’表示不属于任何实体类型的字符。实验识别的10 类实体类别及标注策略如表3 所示。

表3 实体类别及标注策略
2.1.3 基于BERT-BiLSTM-CRF 的命名体识别方法
本研究中,BERT-BiLSTM-CRF 模型由词嵌入层、特征提取层和CRF 层构成,如图2 所示。
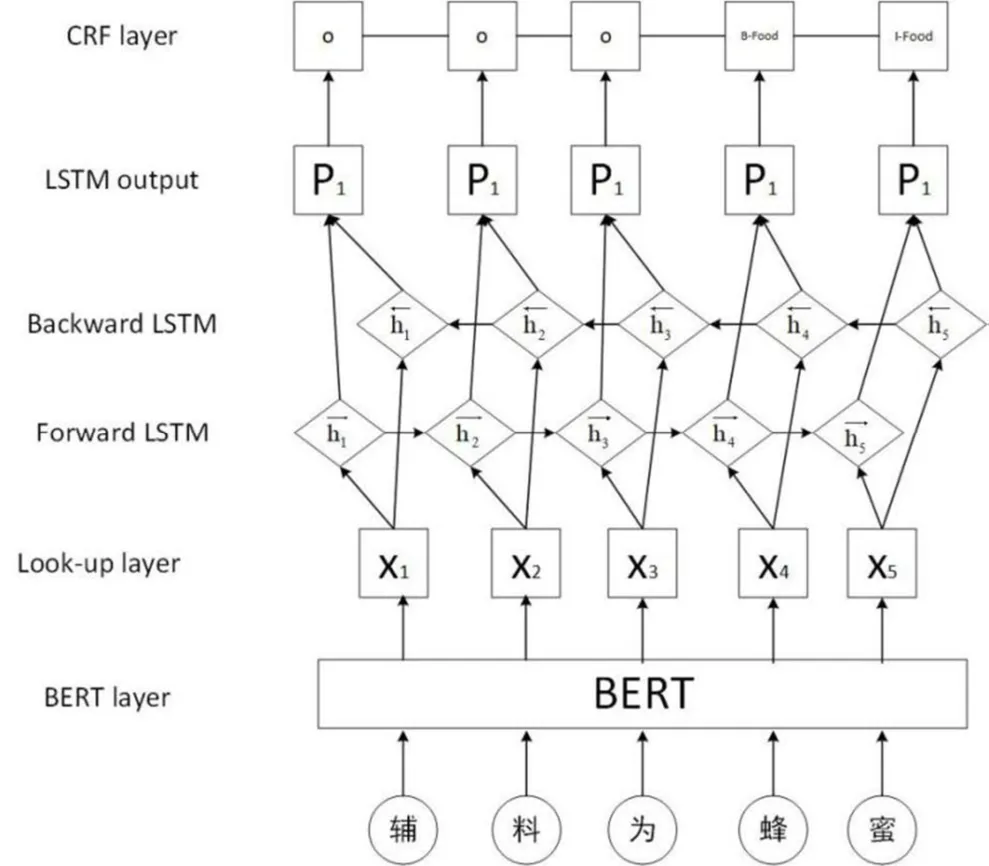
图2 BERT-BiLSTM-CRF 模型
(1)词嵌入层。现有的预训练语言模型主要包含浅层词嵌入和预训练上下文编码器两类,浅层词嵌入的典型代表有Skip-Gram、Glove 等;预训练上下文编码器的典型代表有ELMo、BERT 等。由于BERT已在不同的自然语言处理任务中表现出了强大的算法性能,所以实验选取BERT 作为模型的词嵌入层。BERT的Embedding表示如图3 所示,BERT的Embedding由Token Embeddings、Segment Embeddings和Position Embeddings 三部分构成。Token Embeddings 表示词向量;Segment Embeddings 对句子进行编码,用于刻画文本的全局语义信息;由于Self-attention 机制并不具备对输入序列的位置信息进行建模的能力,而位置信息体现了序列的逻辑结构,在计算中起着至关重要的作用,因此在输入层引入了Position Embeddings 对位置信息进行编码,记录单词顺序这一重要特征,实现对不同位置同一个字或词的不同区分。Token、Segment和Position 这三个向量相加为每个Token 的最终向量。

图3 BERT 的Embedding 表示
实验首先将原始输入进行Token 嵌入、段嵌入和位置嵌入的表示后,输入至BERT 并生成词向量矩阵E∊Rn×d,其中n为输入长度,d为词向量维度(d=768)。令Xi∊Rd表示输入中第i个词的词向量,则长度为n的输入则可以表示为

(2)特征提取层。本实验模型通过BiLSTM层进行特征提取。为了保证词向量的维度不变,将BiLSTM 层的隐藏层维度设为d/2(d=768),词向量先进行正向传播提取出词向量的词特征表示,其词特征维度为d/2(d=768),再进行反向传播提取得到词特征表示x←,将两个词特征进行拼接,得到维度为d(d=768)的词特征表示。LSTM 单元结构如图4 所示。

图4 LSTM 单元结构
可以将LSTM 核心单元理解为一个细胞状态,用贯穿细胞的水平线进行表示。并且在LSTM 的网络中,可以通过一种被称为门的结构,对细胞状态的信息进行删除或者添加信息。门的结构通常由一个Sigmod 层和一个点乘操作的组合。通常在一个LSTM 单元中包含3 个门来控制细胞状态。LSTM 单元结构整体计算如式(2)~(7)所示。式中σ为sigmod 函数,Xt为输入向量,Ht是输出向量,W是参数矩阵,b是偏置参数。Ft代表遗忘门,它决定细胞状态需要丢弃哪些信息。模型通过遗忘门来选择控制上一个字信息保留或丢弃多少。它通过查看Ht-1和Xt中的信息来输出一个0-1 值之间的向量,该向量里面的0-1 值可以表示细胞状态中的哪些信息保留或丢弃多少。0 表示不保留,1 表示保留。

图4 中It代表输入门,它决定为当前的细胞状态添加哪些新的信息。这一步分为两个子步骤:第一步,利用Ht-1和Xt通过门操作来决定更新哪些信息。第二步,利用Ht-1和通过tanh 操作得到新的候选细胞信息tC~ ,这些信息可能会被更新到新的细胞中。更新旧的细胞Ct-1,变更为新的细胞信息Ct。更新规则是通过遗忘门Ft选择忘记旧细胞信息的一部分,通过输入门It选择添加候选细胞信息tC~ 的一部分得到新的细胞信息Ct。更新操作如式(3)~(5)所示。

图4 中Ot代表输出门,更新完细胞状态后根据输入的Ht-1和Xt判断输出细胞的哪些特征状态,输入向量经过门操作得到Ot向量,将该向量与经过tanh 层的Ct向量相乘即可得出神经网络单元的单元输出Ht,具体如式(6), (7)所示。

(3)CRF 层。最终在全连接层中,使用softmax 函数输出标签分类结果,得到一个发射矩阵H∊Rn×d',其n为输入句子长度,d'为标签的数目。CRF 是一个判别式模型,也是一种无向图模型。CRF 有两类特征函数,一类是针对观测序列与状态的对应关系;一类是针对状态间关系。对于本文来说,前一类特征函数的输出由LSTM 层的输出H 替代。后一类特征函数就变成了标签转移矩阵,用来对中医药领域标签进行标签前后的约束,CRF 层具体计算过程如式(8), (9)所示。
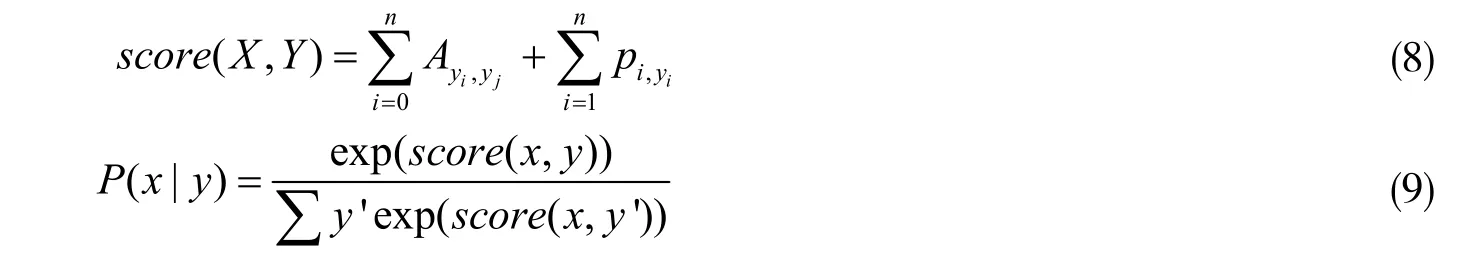
其中,A是转移矩阵,例如:Ayi,yj代表了标注序列上一个yi标签转移到下一个yj标签的概率,此概率为softmax 得到归一化后的概率。将BiLSTM 的输出H 送入CRF 层,通过式(9)计算得出标签序列y的概率,选取最大概率的标注序列,即为CRF 层的最终标注序列。
2.1.4 实验设计
(1)评价指标。在模型性能评价方面,按照8∶1∶1 将数据集划分为训练集、验证集和测试集。以人工标注结果为标准,采用基于实例的指标对模型的总体性能进行评价。总体性能评价采用精确率(P)、召回率(R)和F1 值作为评价指标。在测试时,使用Micro-Averaging 评测得出评测分数,计算公式如式(10)-式(12)所示。

其中,n表示NER 文本总数,TPi表示第i条文本中正确识别为实体的数量,FPi表示第i条文本中误识别为实体的数量,FNi表示第i条文本中未识别出的实体数量。
(2)实验环境与模型参数设置。深度学习框架采用Pytorch1.5.1,GPU 为NVIDA GeForce RTX 2080,使用NVIDA CUDA 10.2 进行GPU 加速训练。实验采用Bert_base 版本,Bert_base 拥有12 层transformer,768个隐藏单元,12 个Attention-head,340M 参数。为了缩短训练时间,尽早选取最优模型,在模型训练时,人为设计了两个指标patience 和patience_num。其中patience_num 为模型训练的耐心次数,patience 为每次模型训练的耐心值,每当模型在验证集进行验证时,会记录当前的F1 值,与上一次模型训练的F1 值进行比较,当F1 值的增加没有超过设定的patience 值,patience_num 会加1,当patience_num 超过5 次模型就会停止训练,保存轮次训练中最优模型。实验模型参数设计如表4 所示。

表4 模型实验参数
2.1.5 实验结果及分析
模型实验结果如表5 所示。从表5 的实验结果可以看出,与其他模型相比较,BERT-BiLSTM-CRF 模型从总体上看,F1 值在几种模型中得分最高。

表5 中医药命名实体识别结果
(1)从CRF 方面,BiLSTM-CRF 模型相比BiLSTM 模型在召回率(Recall)方面仅减少了0.17%,但是在精准率(Pre)方面有很大的提升幅度,提高了5.32%,并且综合F1 值提升了2.96%,BERT-CRF 模型比BERT 模型类似,在精准率方面提升幅度较大,提升了5.3%,且综合F1 值提升了2.19%,实验表明CRF 模型输出时在标签之间添加了依赖关系,从而减少了非法标签的出现,在一定程度上提升了模型的性能。对比BERT-BiLSTM-CRF 和单个的BERT 以及BiLSTM模型,BERT-BiLSTM-CRF 模型相比BiLSTM 模型F1 值提高了5.68%,相比BERT 模型F1 值提高了2.4%,说明结合后的模型在中医药命名体识别方面相比单个模型具有更优秀的性能。(2)从预训练方面看,Word2vec-BiLSTM-CRF 模型与BiLSTM-CRF 模型相比,从精准率、召回率以及F1 值三个方面都有提升,且BERT-BiLSTM-CRF 的模型的三个评价指标都比Word2vec-BiLSTM-CRF 模型要高,精准率提升了0.99%,召回率提升了4.56%,F1 方面提升了2.53;实验表明训练好的词向量能够有效提升模型性能;此外使用BERT 进行预训练词向量的BERT-BiLSTM-CRF 模型的F1 值比BiLSTM-CRF 模型提升了2.72%,而Word2vec-BiLSTM-CRF 模型仅提升了0.19;结果表明预训练词向量相比传统词向量在词表示方面更具优越性,能够解决传统词向量存在的一词多义的情况。(3)BiLSTM 模型比单向的LSTM 模型在精准率方面高了4.05%,召回率方面提升了3.14,F1 值提升3.71,实验结果表明,双向的LSTM 相比单向的LSTM 能够更好的从两个方向提取句子的特征,提升模型的性能。
综上,针对中医药药品说明书中的命名体识别任务,本文采用的BERT-BiLSTM-CRF 模型与其他模型相比较整体上更具优越性。实验结果表明其精准率达到了76.12%,仅比BERT-CRF 低1.12%,但却高于其他模型;其召回率达到了87.83,仅比BERT 低0.07%,却远高于其他模型;其综合F1 值在所有模型中最高,达到了81.52%。
2.2 关系抽取
2.2.1 构建关系标注数据集
关系抽取实验使用的数据与命名体识别使用相同,选自阿里云大数据平台的中医药药品说明书数据集,其原始数据是JSON 格式,但只标注了实体并没有标注实体间的关系,其内容实例如:“【药品商品名称】 乌鸡白凤丸 【药品名称】 乌鸡白凤丸 【批准文号】 国药准字Z13022373 【成分】 乌鸡、鹿角胶、鳖甲、牡蛎、桑螵蛸、人参、黄芪、当归、白芍、香附、天冬、甘草、地黄、熟地黄、川芎、银柴胡、丹参、山药、芡实、鹿角霜;辅料为蜂蜜。”,由于原始数据只有实体标注,没有实体关系标注,首先使用标注工具进行数据标注,数据标注部分截图如图5 所示。

图5 数据标注图
将原始数据标注好之后,将其转换成ann 格式的文件。表6 为ann 格式的标注文件。

表6 标注文件格式
表7 展示了标注后的数据格式。表中包含了一个Drug 实体“乌鸡白凤丸”,两个Ingredient 标签实体“乌鸡”和“鹿角胶”。这三个实体之间存在两个关系,都是“Ingredient_Drug”,即:(“乌鸡白凤丸”,“Ingerdient_Drug”,乌鸡)与(“乌鸡白凤丸”,“Ingredient_Drug”,“鹿角胶”)。

表7 标注数据
2.2.2 融合BERT-BiLSTM-CRF 和Multi-Attention 的关系抽取模型
如图6 所示,为本文采用的多头选择联合抽取模型。
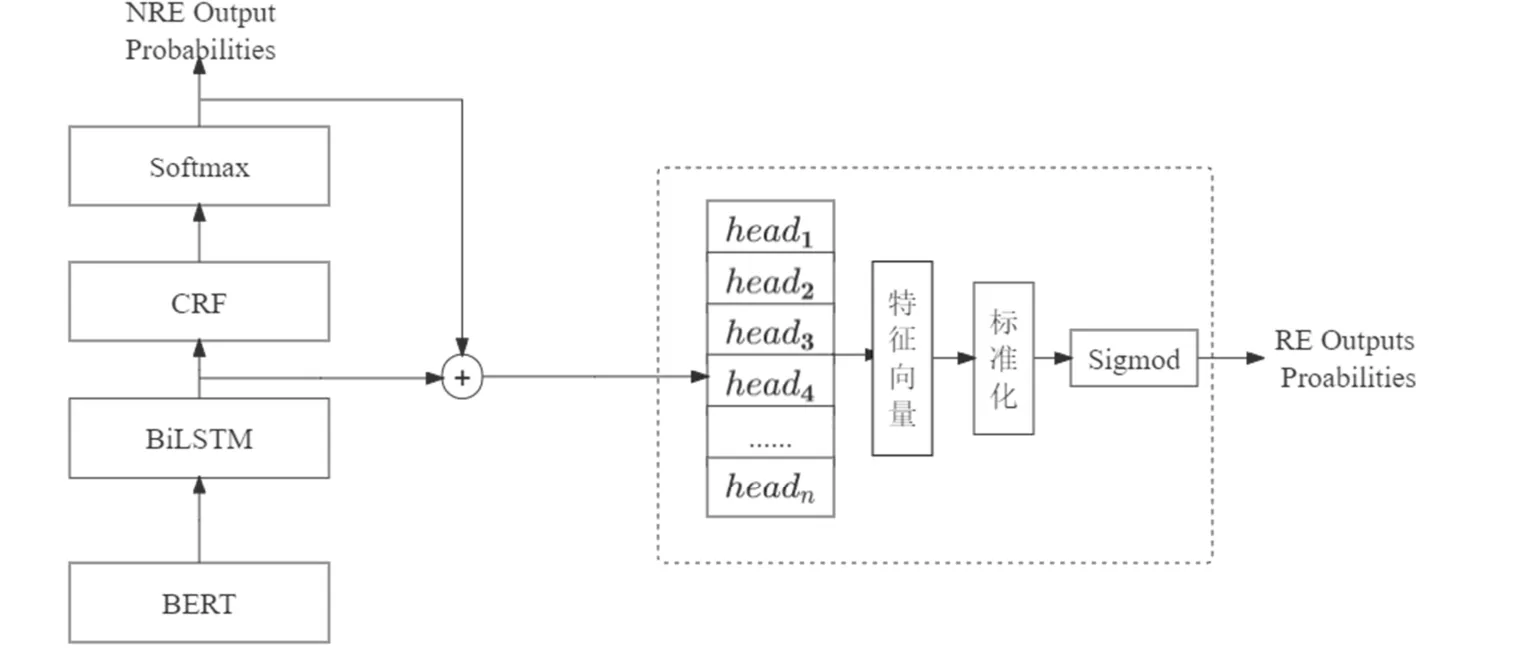
图6 多头联合模型结构图
该联合抽取模型共分为命名体识别和关系抽取两个模块,其中命名体识别模块与2.2 节中介绍的命名体识别基本相同,不再赘述,下面将详细介绍联合模型中的关系抽取模块的各个部分。
(1)输入向量的拼接。关系抽取模块的输入由两部分信息信息组成,即:BiLSTM 层输出的特征提取信息和实体识别输出的类别信息。将两部分信息编码成固定的维度向量和然后拼接起来,作为关系抽取模型的输入。其输入可表示为

其中,EBERT∊Rn×d;EBiLSTM∊Rn×d;Econcat∊Rn×2d;d=768;n为输入句子的长度。
(2)Multi-Head Attention 层。多头的注意力机制是Attention 机制的一个变种,将每次的attention 计算分为多个头同时进行计算,从不同的维度提取出不同特征。如图7 所示是一个head 进行特征提取的过程。

图7 Multi-Head Attention 结构图
(3)线性变换。本文使用了Self-Attention 机制,所以对于给定的初始矩阵Q,K和V,令Q=V=K=X,线性变换公式为

(4)缩放点积模型。缩放点积操作是使用点积进行相似度计算,主要是用于计算概率分布。计算步骤是先将Q与K进行点积操作,再利用Softmax 函数得到K关于Q的注意力分布,最后将其与V进行加权求和。计算公式为

其中,Q,K,V都是X进行不同线性变换后得到的矩阵;r为K的维度,除以是为了将数值压缩到合适的范围,不至于太大。将得到的多个head 进行拼接,得到最终的特征向量。Softmax 是归一化函数,其公式为

其中,g(Q,K) 是将Q与K进行点积运算得到Q与K的相似度;Softmax 函数的作用是将所用的实数映射到0~1 的范围内。
(5)层标准化。Layer Normalization 是一种恒向规范化。其针对同一层的隐藏单元进行计算,同一层的输入拥有相同的方差与均值,不同的训练样本则是不同的方差和均值。层标准化可以改良数据的分布,加速训练损失的收敛。其计算公式如下所示。
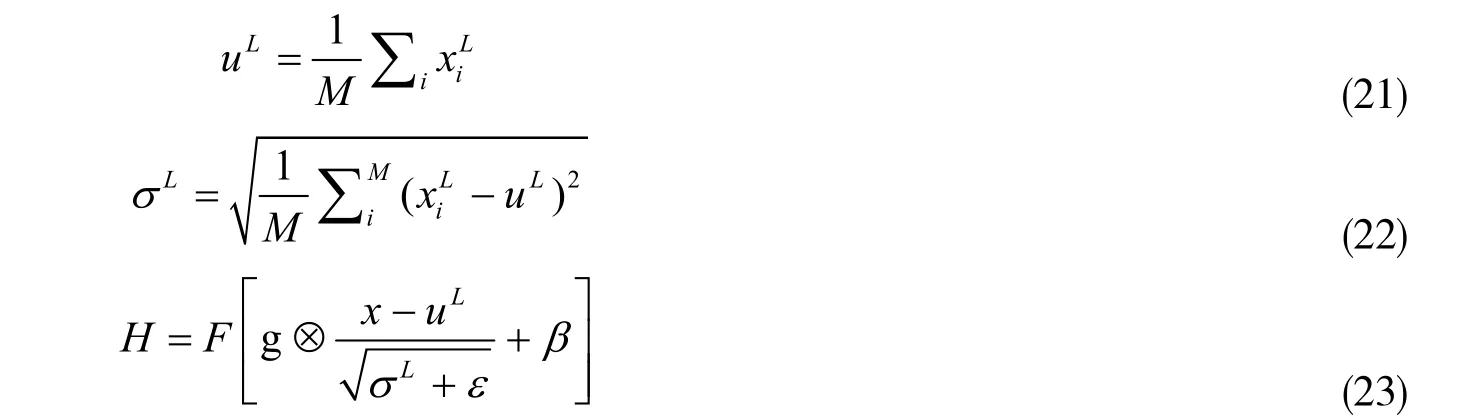
其中,g,β均为参数;⊗为点乘运算;L ix为模型中第L层隐藏层的第i个隐藏单元;M为第L层隐藏层单元的总数;uL表示第L层的均值;σL为第L层的方差。
2.2.3 标注策略与评价标准
(1)如表8 所示展现了5 种实体之间的关系类别。
表8 关系待预测种类
(2)评价标准。一般来说,关系抽取只有当实体和关系两者都被正确识别时才被认为是对的。与命名体识别类似关系抽取以准确率、召回率以及F1 值作为评价指标。

2.2.4 实验结果及分析
为验证本联合模型在中医药药品说明书数据集的效果,将数据集在以下几个模型中进行了训练,实验对比结果如表9 所示。从表9 中可以看到,联合模型的各项指标相都高于流水线模型。

表9 模型实验结果
(1)融合Multi-Head Attention 的联合模型综合F1 值比联合模型的综合F1 值提升了1.96%,实体识别部分F1 值提升了1.83%,关系抽取部分提升了2.1%。表明在模型中引入Multi-Head Attention 能够在不同的表征空间学习到不同的信息,加强了对于输入向量的特征提取能力,在一定程度上提升了模型的性能。
(2)BERT-融合Multi-Head Attention 的联合模型综合F1 值比融合Multi-Head Attention 的联合模型高了2.26%,比流水线PCNN 模型高了4.51,除综合F1 值外,本文提出模型在实体识别部分和关系抽取部分的F1 值都有了提升,表明BERT 模型预训练的词向量很好的提升了命名体识别模块的性能同时,也在一定程度上提高了信息抽取模块的性能,从而整体上带动了整个联合抽取模型性能的提升。
综上所述,针对中医药药品说明书的关系抽取任务,本文所提出的BERT-融合Multi-Head Attention 的联合抽取模型与其他模型相比整体上更具有优越性,实验结果表明其实体识别部分的F1 值达到82.31%,关系抽取部分的F1 值达到了76.94,其综合F1 值在所有模型中最高达,到了79.62%。
3 中医药知识图谱构建
如图8 所示,展示的是中医药知识图谱的构建流程。

图8 知识图谱构建流程
知识图谱的构建主要包括以下几个步骤:
(1)整理数据并保存为CSV 文件,将实验所得实体与关系进行保存,对实体和关系进行消歧处理,避免导入的信息数量冗余,产生无用的知识图。(2)数据导入,将CSV 文件利用批量导入方式导入Neo4j 数据库。(3)知识图谱查询,使用图数据的Cypher 语言,查询数据库。(4)图谱分析,简单分析知识图谱的概况。为进一步的知识推理、知识检索等下游任务做准备。
如图9 所示展示了数据库的部分截图。
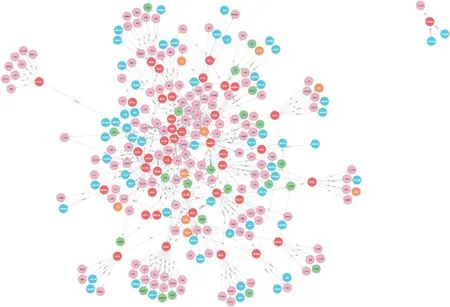
图9 Neo4j 可视化图
该知识图谱共有实体267 个其中Dosage 标签实体9 个,Drug 实体标签41 个,Funtion 标签实体56个,Taste 标签实体22 个,Ingredient 标签实体139 个。共有关系411 个,其中Dosage_Drug 类别关系27 个,Funtion_Drug 类别关系71 个,Taste_Drug 类别关系45 个,Ingredient_Drug 类别关系268 个。图谱规模如10所示。
4 图谱分析
在Neo4j 中通过Cypher 命令可以方便的进行各种操作,例如查询、推理等内容。通过一种类似于SQL语句的格式,可以得到各个实体及其之间的关系。在导入实体和关系数据之后,可以在Neo4j 中进行以下操作。
(1)查询所有实体及其之间的关系,命令如下:

运行完成后的知识图谱部分截图如图11 所示。

图11 实体“乌鸡白凤丸”及其相关内容的知识图谱
红色的圆代表中医药名称“Drug”的实体节点;粉色的圆代表中医药主要成分“Ingredient”的实体节点;绿色的圆代表中医药性味“Taste”的实体节点;橘黄色的圆代表中医药“Dosage”的实体节点;蓝色的圆代表中医药“Funtion”的实体节点。该截图主要是围绕实体“乌鸡白凤丸”,展示与其相关的实体内容。
(2)查询“Drug”中乌鸡白凤丸的主要成分,命令如下:
MATCH n=(Drug{name e:”乌鸡白凤丸”})->[r:成分]->()RETURN x
运行结果如图12 所示。

图10 Neo4j 数据库
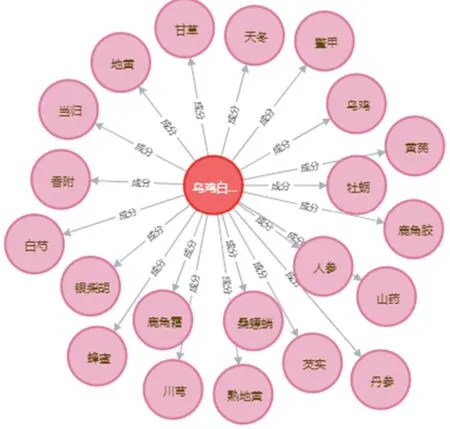
图12 实体“乌鸡白凤丸”及其主要成分的知识图谱
红色的圆代表“乌鸡白凤丸”的实体节点,粉丝的圆代表其所关联的主要成分节点,得到乌鸡白凤丸的主要成分有“甘草”、“天冬”等“Ingredient”。
5 总结与展望
5.1 结论
本文的研究成果如下:
(1)构建中医药原始语料。结合中医药领域的语义逻辑,依据现有的TCMLS 作为标准,采用其中的实体关系逻辑框架,设定中医药药品说明书实体、关系标签的分类。对数据集进行处理之后,构建了中医药领域命名体识别和关系抽取实验的原始语料。
(2)中文命名体识别实验的创新。提出BERT-BiLSTM-CRF 模型进行中医药领域的命名体识别任务。在Embeddin 层,使用BERT 模型,动态训练词向量,解决了传统词向量一个词语多个语义的问题。在BiLSTM的输出部分,加入了CRF 层,添加了对于标签之间的依赖,降低不合理标签的出现,令多标签分类问题在特定领域有了更优的方案。通过实验得出:实验所用模型在中医药领域的学习效果取得了更优的效果。
(3)关系抽取实验的创新。在基于共享参数的联合模型基础上,融合了Multi-Head Attention,不同的head 提取多个表征空间信息,将其作为输出特征进行分类。
(4)构建中医药知识图谱。将抽取出的实体及关系转存为CSV 文件之后批量导入到Neo4j 图数据库中,应用三元组格式形成中医药领域的知识图谱,实现了该领域的知识结构化、可视化,为今后的中医药领域的知识查询、知识挖掘等提供了基础。同时本研究也为中医药结构化、智能化、数字化、可视化构建提供了新的方案,为今后特定领域的NLP 提供了新的思路和解决方案。
5.2 存在问题及展望
本文对与中医药领域的命名体识别和关系抽取研究还存在着一些不足,主要表现在以下几个方面:
(1)中医药领域数据不全。对于中医药领域数据的收集不全面且覆盖面小。由于手工标注的工作量较大,且需要领域专家的指导,所以实验的原始语料规模较小。无论是命名体识别实验还是关系抽取实验,模型的训练样本有限,这也对后期模型的学习和后期知识图谱的构建存在影响。
(2)样本不均衡、数据规模小。信息抽取的两项子任务都存在着样本数量不均的情况,在后期如果进行数据的扩充,或者投入真正的使用智能化构建知识图谱,可能存在不稳定性。
针对当前存在的这些问题,希望接下来的工作可以在以下几个方面进行:
(1)收集更多地中医药领域的信息,比如增加经典的行医医案和中医药病例等,使模型可以学到更多更重要的行医规律和有价值的知识,提高模型的泛化能力,在中医药领域发挥更好地效果。
(2)本文构建的知识图谱属于小型特定领域的知识图谱,希望未来的研究能够将此实验的结论和结构化的知识引入大规模的领域知识图谱,扩大该知识图谱的领域范围,更好地帮助中医药领域学科的传承与发展。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导科学论坛(2016年9期)2016-06-05
高中生学习·高三版(2016年9期)2016-05-14
