
基于YOLOv3算法与3D视觉的农业采摘机器人目标识别与定位研究*
2022-12-02 06:03高帅刘永华高菊玲吴丹姬丽雯
中国农机化学报 2022年12期
高帅,刘永华,高菊玲,吴丹,姬丽雯
(1. 江苏农林职业技术学院,江苏镇江,212400; 2. 江苏省现代农业装备工程中心,江苏镇江,212400)
0 引言
随着工业化和城镇化的不断发展,从事直接农业劳动人口开始不断减少,此外人口老龄化也已成为不可避免的事实,这一切都导致农业劳动力成本持续上升,因此后工业化时期农业机械化逐渐向智能化发展[1]。而农业采摘是最费劳动力、最难实现智能化作业的环节,农业采摘机器运行环境复杂,不确定环境因素较多,对农业采摘目标的准确识别和精准定位是实现机器人采摘的重要前提[2-4]。随着3D视觉技术的发展,赋予了农业机器类似人眼一样的视觉功能,研究人员在采摘苹果[5]、番茄[6]、草莓[7]、樱桃番茄[8]等果蔬领域展开了一系列的研究,且开发了相应的农业采摘机器人,但目前尚未有成熟应用的商业案例,还需进一步优化算法结构,提高果实目标的识别与定位精度。
基于视觉的目标识别方法经历了传统数字图像处理技术、机器学习的图像分割技术和分类器以及深度学习的卷积神经网络算法[9]。传统数字图像处理技术依靠采集图像的颜色、纹理和形状或者多个特征的融合。机器学习的图像分割技术和分类器通过拟定训练方法,对输入输出进行评估预测,如王瑾等[10]提出一将AdaBoost分类器和颜色特征分类器相结合用于番茄采摘机器人的目标识别方法;李寒等[11]提出一种基于RGB-D图像和K-means优化的算法来进行果实的识别与定位,有着较强的准确性和鲁棒性。
由于农业采摘机器人容易受到采摘目标形状不同、大小不同、外界影响环境复杂的影响,传统目标识别方法准确率和定位精度效果并不理想,而深度学习具有很强的学习能力,受环境干扰程度比较小,特别是深度学习的卷积神经网络算法已经被广泛应用于果实的检测识别与定位领域。近年来已经出现AlexNet网络模型[12]、Fast RCNN深度卷积神经网络[13]、Mask RCNN网络模型[14]、SDD网络模型[15-16]、YOLO模型[17-18]等算法用于农业机器人的采摘,但各种算法不具备通用性,对每种采摘对象的识别和定位能力也不相同,这也进一步制约了农业机器人的发展。本文以番茄为研究对象,提出一种改进的YOLOv3卷积神经网络算法与3D视觉技术相结合的方法,实现农业采摘机器人目标的准确识别和精准定位,并与之前的YOLOv3算法、Fast RCNN算法和Faster RCNN算法进行综合比较,对于农业采摘机器人的识别定位发展具有重大意义。
1 目标识别算法
基于卷积神经网络的YOLOv3算法,不同于以往的YOLO算法,YOLOv3算法是YOLO算法的改进版本,它采用了残差模型,去除了池化层,使用Darknet-53(包含53个卷积层)进行特征图像的提取;同时YOLOv3算法采用了FPN架构,使得网络架构更深,可以实现目标的多尺度检测,检测精度进一步得到提升[19]。
YOLOv3算法主要由卷积层、Darknet-53结构、Res层和YOLO层组成[20-21],网络结构流程如图1所示,其中Conv代表卷积、Res代表残差块、CBL代表Conv与批量正则Leaky ReLU激活函数的合成。YOLOv3算法的基本流程是通过Darknet-53结构将输入图片(416像素×416像素)输出成最小尺度(13像素×13像素)、中尺度(26像素×26像素)、最大尺度(52像素×52像素)的特征图,运用Logistic Regression算法将3组9个先验框进行线性回归求解,并将置信度最高分作为图像的最终预测结果输出。
置信度反映了目标落在特定框区域的真实性程度,判断公式如式(1)所示。
(1)
式中:score——置信度的置信值;
Pr(Object)——预测框训练样本的概率;
IOU——候选框与原标记框的交叠率。

图1 YOLOv3网络结构示意图
作为对误检测样本惩罚的依据,YOLOv3算法损失函数对检测精度的影响至关重要。YOLOv3算法损失函数主要包括目标坐标预测的损失、预测框置信度的损失和分类的损失。
Lcoord=λxyδ(x,y)+λwhδ(w,h)
(2)
Lconf=λconfδ(conf)
(3)
Lclass=λclassδ(class)
(4)
Loss=Lcoord+Lconf+Lclass
(5)
式中:Loss——YOLOv3总损失;
Lcoord——目标坐标预测的损失;
Lconf——预测框置信度的损失;
Lclass——分类的损失;
λxy——中心误差权重系数;
λwh——宽高误差权重系数;
λconf——置信度误差权重系数;
λclass——分类误差权重系数;
δ(x,y)——预测边界框中心坐标(x,y)的误差函数;
δ(w,h)——预测边界框宽w和高h的误差函数;
δ(conf)——预测置信度的误差函数;
δ(class)——目标物体类别的误差函数。
提出的改进YOLOv3算法是以YOLOv3算法为基本结构,在YOLOv3第一级检测之前加上一个SPP模块,通过改进模型可以实现小目标的精准识别,降低漏检率。SPP模块是由3个不同尺度的最大池化层组成的结构,如图2所示。其中Maxpool代表最大值池化,/1代表步长stride=1。

图2 SPP模块示意图
2 目标识别定位
2.1 目标识别定位系统
目标识别定位系统主要包含3D图像采集软件和远程动作执行软件,采用3D视觉相机里的深度相机获取采摘对象的立体信息,同时通过主相机获取空间颜色信息,通过计算机的图像识别与3D位置数据分析后,可以实现快速立体定位采摘对象。3D图像采集主要是显示作业实时采集图像,在相机计算机中运行,如图3(a)所示;远程执行软件主要是进行算法的选择、相机坐标标定、图像处理、机械臂手动测试、手动与自动目标识别与定位等功能,在客户端计算机中运行,如图3(b)所示。
农业采摘机器人3D视觉相机采用MYNTAI 3D双目视觉相机,位于整机上部,并可在空间范围内实现多角度的无级调整,利用视觉识别信息指导机器人进行行驶路线规划和寻找采摘目标的识别与定位功能。3D视觉相机的主要参数如表1所示。

(a) 3D图像采集软件

(b) 远程动作执行软件

表1 相机主要参数Tab. 1 Camera main parameters
2.2 目标坐标转换
由于3D视觉相机视野中捕获目标物体的坐标系与机器人坐标系不一致,它们各自的坐标没有联系,所以为了使两者坐标系形成关联,以便引导机器人进行采摘,故需要将相机的坐标系变换到机器人坐标系中,即进行标定。要完成农业采摘机器人与物体的坐标变换标定,需要一个4×4的矩阵,这个矩阵包含着一个旋转矩阵(3×3)和一个平移矩阵(1×3),主要步骤如图4所示。
步骤1:选择标定点:选择四个差异化的标定点,比如远近位置各不相同,同时又应该在相机的拍摄范围和机械臂的可采摘范围之内。
步骤2:目标图像采集:确保机器人在采摘初始位置,相机在初始采摘位置拍照。
步骤3:记录像素坐标:根据3D视觉相机拍摄照片,标定出目标位置的x,y,z的value值。
步骤4:记录世界坐标:利用示教器遥控机械臂到当前标定点所在的果实位置,记录下示教器的位置X,Y,Z的value值。
步骤5:相机标定数据:重复步骤3和步骤4,记录下四个标定点的相机像素坐标、机器人世界坐标,得到相机标定数据,将标定数据填入农业采摘机器人软件平台中,点击生成变换矩阵,至此完成两个坐标系的转换。


(a) 选择标定点 (b) 目标图像采集


(c) 记录像素坐标 (d) 记录世界坐标
3 试验与结果分析
为验证基于改进YOLOv3算法与3D视觉的目标识别与定位系统的可靠性和优越性,本文对其进行了模型训练和测试。所用计算机的CPU型号为Inter Core i7-10700,CPU频率为2.9 GHz,性能级独立显卡,显卡芯片为AMD Radeon RX 550X,内存容量为16 G,操作系统为Windows 10 64位简体中文版,开发语言为python。
3.1 模型训练分析
目标图像数据采集在江苏农博园番茄温室进行,为了保证样本的多样性,拍摄全天不同时间、不同角度、不同位置、不同品种类型的图像1 334张。按照训练集和测试集按照3∶1比例进行分配,其中训练集1 000 张、测试集334张,通过Labelimg软件对数据集中的番茄位置和类别信息进行手工标注。
然后利用候选框与原标记框的交叠率IOU、准确率P、召回率R来进行模型性能的评估,如式(6)、式(7)所示。
(6)

(7)
式中:TP——IOU大于等于设定阈值的数量即预测框与标记框正确匹配的数量;
FP——IOU小于设定阈值的数量即预测错误的数量;
FN——IOU等于0的数量即漏检的数量。
训练参数设置每批量样本个数为64,动量因子设置为0.95,权值衰减设置为0.000 5,学习率设为0.001,非极大抑制设为0.5,最大迭代次数设置为30 000。且每次迭代完成后,均保存成对应的模型,最后选出具有最高精度的模型,在训练的过程中得到训练损失趋势曲线如图5所示。

图5 训练损失趋势曲线
由图5曲线图可以看出,在模型训练过程中,当迭代次数小于400次时,损失函数值迅速降低至4左右;当迭代次数大于400次时,损失速度变缓,说明模型训练效果较好,随着迭代次数的增加,损失函数值不断减小,在训练迭代次数达到16 000次时,损失函数值已经趋于平稳,并稳定在0.4附近,说明迭代次数在16 000 次时停止模型训练比较合适。
3.2 识别准确率、识别召回率和平均识别时间分析
为了验证改进YOLOv3算法的目标识别相比于之前的神经网络算法的可靠性和优越性,随机抽取600个训练样本照片,分别利用YOLOv3算法、改进YOLOv3算法、Fast RCNN算法和Faster RCNN算法进行目标的识别,目标识别效果如图6所示。并对目标的识别准确率、识别召回率和平均识别时间进行了比较,如表2所示。

图6 目标识别效果
从表2的对比结果可以看出,所用改进YOLOv3算法和3D视觉的识别准确率和召回率分别达到97.2%和95.8%,改进YOLOv3算法要比YOLOv3算法、Fast RCNN算法和Faster RCNN算法的准确率要高,在同等条件下分别提高5.5%、9%、1.4%;改进YOLOv3算法同时要比YOLOv3算法、Fast RCNN算法和Faster RCNN算法的召回率要高,在同等条件下分别提高1.4%、2%、3%;改进YOLOv3算法的平均识别时间要比YOLOv3算法、Fast RCNN算法和Faster RCNN算法的少,在同等条件下分别降低20.1%、25.6%、52.1%,这表明改进YOLOv3算法完全可以满足后期农业采摘机器人实际工况下的模型识别检测要求。

表2 四种算法的准确率和召回率对比Tab. 2 Four algorithms comparison of accuracy and recall rate
3.3 定位结果分析
为验证本文所提方法的定位精度,由于试验条件所限,采用一个番茄进行定位试验,其初始位置为(0 mm,0 mm,100 mm),每次向远离摄像头Z方向移动10 mm,农业采摘机器人共进行10次位置定位,分别采用Fast RCNN算法、Faster RCNN算法、YOLOv3算法和改进YOLOv3算法对采摘点进行空间定位试验,并综合比较四种算法的定位误差,计算方法如式(8)所示。
(8)
式中:xli,yli,zli——第i次位置理论坐标值;
xci,yci,zci——第i次测量位置坐标值;
Elc——定位误差。
以定位误差来衡量最终的定位精度,如表3所示。
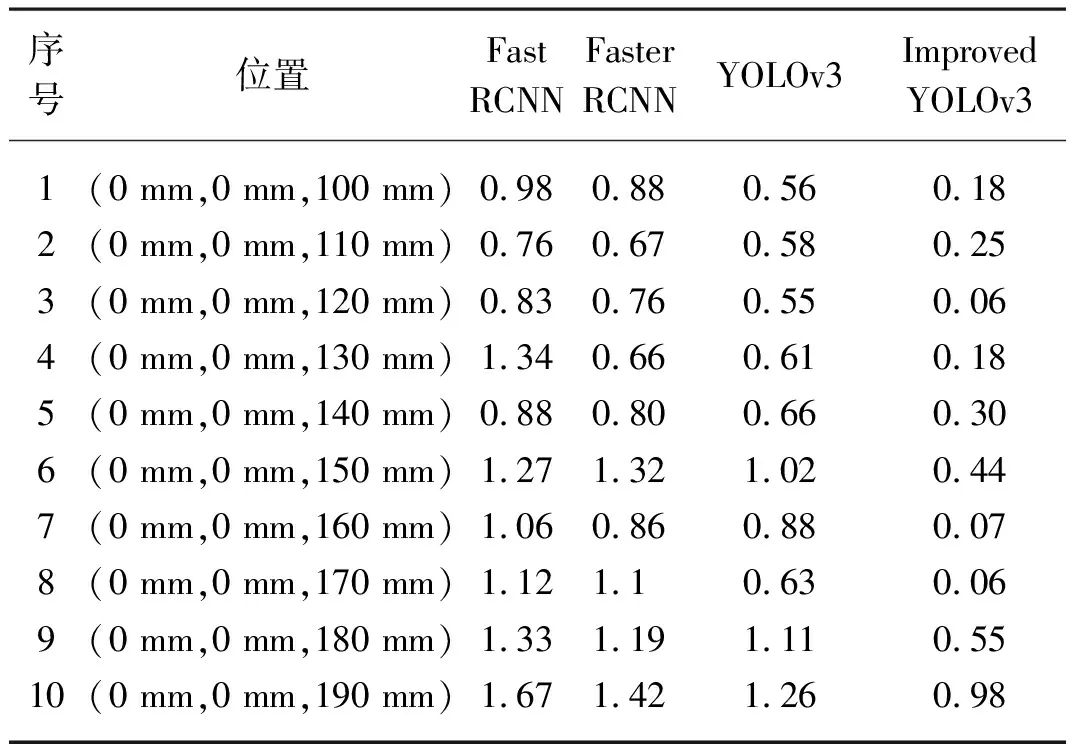
表3 四种算法的定位误差对比Tab. 3 Four algorithms comparison of localizing error mm
从表3中可以看出Fast RCNN算法、Faster RCNN算法、YOLOv3算法在10次的定位试验中最大定位误差分别是1.67、1.42、1.26 mm,而改进YOLOv3算法的在10次的定位试验中最大定位误差只有0.98 mm,分别比Fast RCNN算法、Faster RCNN算法、YOLOv3算法的最大定位误差降低0.69、0.44、0.28 mm,且改进YOLOv3算法的定位误差多次在0值附近进行波动,证明了改进YOLOv3算法系统具有一定的准确性和稳定性。
4 结论
1) 传统目标识别方法准确率和定位精度效果并不理想,本文采用改进YOLOv3算法进行了模型训练,模型训练效果较好,在训练迭代次数达到16 000次时,损失函数值趋于平稳,并稳定在0.4附近,说明迭代次数在16 000次时停止模型训练比较合适。
2) 通过试验对比分析,改进YOLOv3算法要比YOLOv3算法、Fast RCNN算法和Faster RCNN算法的准确率要高,在同等条件下分别提高5.5%、9%、1.4%;改进YOLOv3算法同时要比YOLOv3算法、Fast RCNN算法和Faster RCNN算法的召回率要高,在同等条件下分别提高1.4%、2%、3%;改进YOLOv3算法的平均识别时间要比YOLOv3算法、Fast RCNN算法和Faster RCNN算法降低20.1%、25.6%、52.1%,可以满足后期农业采摘机器人实际工况下的模型识别检测要求。
3) 通过试验对比分析,改进后的YOLOv3算法的最大定位误差分别比Fast RCNN算法、Faster RCNN算法、YOLOv3算法降低0.69、0.44、0.28 mm,且改进后的YOLOv3算法定位误差多次在0值附近进行波动,证明改进后的YOLOv3算法系统具有一定的准确性和稳定性,可以更好地完成采摘工作,同时也为农业采摘机器人目标识别与定位方法的改进提供了重要的参考价值。后续研究可以对匹配算法进行进一步的完善,逐步提高农业采摘机器人识别与定位的性能。
猜你喜欢
中学生数理化·七年级数学人教版(2022年6期)2022-06-05
小哥白尼(军事科学)(2022年2期)2022-05-25
导航定位与授时(2020年5期)2020-09-23
汽车维修与保养(2020年11期)2020-06-09
铁道通信信号(2020年9期)2020-02-06
红领巾·萌芽(2019年8期)2019-08-27
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
知识经济·中国直销(2018年3期)2018-04-12
中国与非洲(法文版)(2017年10期)2017-11-23
