
跨模态检索技术研究综述
2022-12-06 10:26徐文婉周小平
计算机工程与应用 2022年23期
徐文婉,周小平,王 佳
北京建筑大学 电气与信息工程学院,北京 100044
进入大数据时代,数据化的信息涉及到电子商务、健康医疗、社交网络、工业机械等多个领域。这些信息以不同的数据类型存储,模态指的就是数据类型。现有研究的模态可以分为图像[1-2]、文本[3-4]、语音[5]、3D图像[6]、3D模型[7]、视频[8]、时间[9]、空间位置[10]这几种。以电子商务领域为例,多采用以输入关键词检索商品标题的单模态检索方式,该方法所得到的信息有限,而同一商品有文本和视频等不同模态的信息,如图1所示,这些信息并没有充分利用。跨模态这一概念来源于人类的多器官感知[11]:多个器官感知通道提供对感知实物的不同特征印象并传递给大脑,以加深对实物的特征感知。跨模态检索是指输入的查询数据和输出的被查询数据属于不同模态的检索方式。它比普通检索得到的信息更为全面准确且真实,在海量数据中应用能提高信息利用率和检索效率,具有十分重要的研究意义。

图1 商品的文本视频模态信息(来源:https://zhongpai.jd.com)Fig.1 Text-video modal information for commodity
由于不同特征空间的数据存在语义理解的差距,各个模态的数据具有多样性[12],如何减小语义差距并保留数据的有效对比特征是跨模态检索的关键问题。目前,跨模态检索实现[13]的主要思路是:利用表示同一语义的异构数据构建不同模态间的对应关系,构建数学模型并进行优化求解,然后对各个模态的数据进行相似性对比,从而检索到同一语义的不同模态信息。研究者主要采用不同的建模方法和相似性对比方法解决问题。本文系统整理了现有的跨模态检索技术,对不同的跨模态相关技术研究概括分析。首先对跨模态检索研究进行简要概述;然后按照数据编码类型分为实值表示和二进制表示,再根据技术不同分为:基于子空间学习、基于主题统计模型、基于深度学习、基于传统哈希和基于深度哈希五种方法,并进行分析对比各类技术的特点;也为相关研究人员评估各类方法整理了最新的多模态相关数据集;最后总结了跨模态领域研究遇到的挑战并指出未来的研究方向。
跨模态研究开展以来,其他研究者们也曾提供了各种分析思路:Chen等人[14]主要对图像和文本两种模态和基于深度学习的方法进行综述。陈宁等人[15]围绕公共子空间建模技术进行了分类及详细介绍,具体分为基于传统统计分析、基于深度学习和基于哈希学习三类技术。上述综述研究针对跨模态检索工作做了较好的总结和探讨,围绕不同的主要研究方法展开调研,而本研究的创新点可以概括为以下三个方面:(1)全面整理已有的研究工作,将以图像文本为主流的模态扩展到其他更多模态的文献研究;(2)在前人基础上分析实值和二进制两种表示下的跨模态检索技术,包含以建模技术和相似性对比为主线的最新相关文献研究;(3)总结最新的多模态数据集和面临的挑战,为相关的研究提供参考资料并为工程人员指出研究方向。
1 跨模态检索研究概述
本章首先对跨模态检索问题进行定义,然后采用文献分析工具对跨模态检索领域的相关文献进行分析并总结概括研究现状。
跨模态检索问题主要围绕不同模态间的语义如何减小相似度差距,增大非相似度差距进行研究。用数学公式表示跨模态检索问题的定义可使其更加清晰,问题符号定义如表1所示。假设以X与Y表示文本和图像两种模态,其数据集定义为公式(1),包含该模态下n个数量的特征向量。由于不同模态之间数据无法直接比较,需要定义两个模态X与Y的转换函数如公式(2);数据转换成相互对应的特征值后,将不同特征值的数据放在同一个空间Z;最后利用相似度函数计算特征数据之间相似度,例如X模态的数据映射到公共空间Z,相似度函数计算如公式(3)。

表1 问题符号定义Table 1 Question symbol definition

研究者们当前解决跨模态检索问题有着各种各样的技术方案。早期研究中主要是通过建立模型表示数据的对应关系。2003年Jeon等人[16]提出了跨媒体关联模型(cross-media relevance models,CMRM)。它实际上利用图像自动注释来检索图像的方法,也属于检索内容直接关联的跨模态检索。2008年张鸿等人[17]提出跨模态关联图的概念,将不同模态的关系用关联图的概念表示,这种方法后来也被称为图正则化的方法。近年来,国内外跨模态检索发表文献数量逐年递增,这表明越来越多的研究人员开始关注这一领域。
本研究重点对近五年的研究成果进行分析,采用Citespace软件工具对跨模态领域的研究热点进行可视化的系统分析。对该领域近5年发表数量较多的中英文文献高频关键词进行聚类分析如图2所示,总结分析了以下几点:(1)哈希二进制编码出现频率排名第一,表明哈希编码用于检索的方法是目前研究热点;(2)利用深度学习嵌入空间进行检索的方法取得了显著进展;(3)联系上下文内容加深对模态场景的理解,说明基于主题场景分析的方法也占据了一席之地;(4)跨模态检索研究的模态由图像文本扩展到音频等更多模态。

图2 近年高频关键词聚类图Fig.2 High frequency keyword clustering map in recent years
通过文献调研与科学分析,系统梳理现有的重点文献,紧紧结合研究热点进行归纳分类。本研究按照数据表示编码方式将跨模态检索技术分为实值表示与二进制表示两类,跨模态检索技术分类如图3所示。

图3 跨模态检索技术分类Fig.3 Classification of cross-modal retrieval techniques
2 跨模态检索技术分析
本章对跨模态检索技术进行分类及详细介绍,其中实值表示学习中各种模态特征的共同表示都是没有经过哈希转换的值,具有相对方便的优点。二进制表示学习中各种模态特征表示为二进制,与实值表示相比具有存储空间小、易于计算的优点,但二进制码可能会产生信息丢失的问题,检索精度相对较低。
2.1 实值表示
在实值表示学习中,为了解决不同模态数据无法直接比较的问题,本文主要将其分为三种方法:基于子空间学习的方法、基于主题统计模型的方法和基于深度学习方法。
2.1.1 基于子空间学习的方法
子空间学习法是跨模态检索中一种直观的方法,图4以狗的检索特征为例,说明了子空间特征学习框架图。该方法从不同模态提取特征中后,利用一个公共的子空间将不同模态数据映射到同一空间,从而进行相似性度量。本小节介绍特征映射到公共子空间时所采用的不同算法,分为典型相关分析(canonical correlation analysis,CCA)及其相关方法、语义标签方法和其他方法三类。

图4 子空间特征学习框架Fig.4 Subspace feature learning framework
最经典的是Rasiwasia等人[18]提出的CCA算法,它根据空间向量关系模型计算子空间距离以解决线性问题。但它是一对一的两层模型,没有利用类信息,也找不到原变量之间的直接映射关系,不适用于学习非线性特征。为了适用于学习非线性特征,Hwang等人[19]提出核典型相关分析方法(kernel canonical correlation analysis,KCCA),它可以表示更复杂的相关性,提高算法性能,但它训练速度慢,测试时要求成对数据且需要提前存储训练集。为解除所有数据必须成对的要求,Rasiwasia等人提出基于聚类[20](Cluster-CCA)的方法,但是它应用于大型数据集时计算量比较大,处理效率低,后续可结合深度学习方法不断改进。为了得到更高级的语义信息,Shao等人[21]提出融合线性投影和非线性隐藏层的双向训练的ICCA(Improved-CCA),改善了控制传统双视图的CCA,使得在有类似原始数据输入时也有精细输出。为了同时保证检索效率和精度,Shu等人对ml-CCA[22]方法做出改进,提出可扩展多标签典型相关分析[23](scalable multi-label-CCA)方法,不仅可以学习共同语义之间的相关性,还可以同时学习特征相关性以提高跨模态检索精度。
除CCA外还有其他的方法,Tenenbaum等人[24]提出双线性模型(bilinear model,BLM)方法,它具有广泛的适用性但不能准确描述内在几何关系或物理现象。Chen等人[25]提出偏最小二乘法(partial least squares,PLS),这种数学计算的回归分析模型需要很大的计算量。后来这两种方法研究得较少,另外一种重要的方法叫语义标签法。Pereira等人[26]针对跨模态图像文本检索问题提出三种匹配方法:其中CM是一种基于无监督的跨模态关联建模方法,SM是一种依赖于语义表示的监督方法,而语义相关匹配(semantic correlation matching,SCM)则综合了它们的优点,同时考虑了相关特征向量与语义空间以改善检索效果。2020年Xu等人[27]提出基于半监督图正则化的语义一致性跨模态检索方法(semantic consistency cross-modal retrieval,SCCMR),它将标签的预测和投影矩阵的优化整合到统一的框架中,可以确保得到全局最优解。Zhang等人[28]提出广义半监督结构化子空间学习方法(generalized semi-supervised structured subspace learning,GSS-SL),主要利用标签空间作为链接对无标签信息进行预测补充,从而保证检索的准确度。Xu等人[29]提出共享子空间分离方法(private-shared subspaces separation,P3S),可排除不相关的背景图像或文本中的错句以提高标签的质量,使得子空间学习可获得更有效的公共表示。
在子空间学习方法中,CCA及其改进方法是最基础的方法,现在常常被用作对比实验方法。它是将不同模态的特征映射到特征空间,建立投影矩阵从而直接度量特征相似度,但该方法需要找到对应的特征关系,会有特征分辨力不足的问题,需要结合深度学习等技术进行改善。另一种语义标签的方法主要是通过补充预测处理标签,完善不同模态之间的信息相关性,提高同类不同模态间的信息不相关性。标签信息越丰富它们的分辨力就会越强大,只是标签的大量补充是一个费时费力的工作,因此标签的补充预测会是未来研究的难点。
2.1.2 基于主题统计模型学习的方法
基于主题统计模型学习是另外一种通过建模来实现跨模态检索的方法。主题指的是具有同一特征的抽象空间维度,主题模型是统计模型学习中最重要的一种。该方法利用隐藏的语义空间来发现数据中出现的抽象空间维度。将这些特征映射到一个公共语义空间来统计相关性,用于在一种模态中查找结果的条件概率,同时在另一种模态中查询结果。主题模型的核心就是可以用公式(4)求解X和Y两模态的主题联合分布概率。

最初的主题模型方法是将隐狄利克雷分配(linear discriminant analysis,LDA)应用于多模态的联合分布模型[30]。Wang等人[31]提出有监督的多模态相互主题强化建模技术(multi-modal mutual topic reinforcement modeling,M3R),利用一个联合跨模态概率图形模型,对各模态数据相关性进行分析,从而找到相同语义主题。Wu等人[32]提出具有主题约束的区域强化网络模型(region reinforcement network with topic constraint,RRTC)来概括图像的中心主题,从而约束原始图像的偏差,然后考虑区域间关系和重新分配区域词的相似性来推断图像和文本细粒度的对应关系。该方法弥补了主题概率法检索不够准确的缺点。
除了主题统计模型外,统计模型还包括马尔可夫模型、马尔可夫随机场等。Jia等人[33]提出多模态文档随机场(Markov random field,MRF),通过定义马尔可夫随机变量之间的相似性对文本进行建模,找到内容相关概率,最终确定最接近的检索结果。为了避免出现主题冲突的情况,Wu等人[34]提出一种跨模态在线低秩相似函数学习法(cross-modal online low-rank similarity,CMOLRS)。通过训练数据三元组的相对相似性对跨模态关系进行建模,并将相对关系表述为凸铰链损失,利用多级语义相关性减小了跨模态数据之间的内容分歧,保证检索结果可靠性。
基于主题统计模型学习的方法能够保留它特有的主题特征,保证检索内容上最大的概率相关性,而且有可能发现有意义的潜在新情景。相较于子空间学习方法,基于概率的联合特征学习可以消除原始空间中的冗余和噪声问题,从而得到更完整、客观的描述。概率估计的方法虽然对于一些整体主题的判别有着不错的效果,但是它的准确度可能会不理想,而且该方法对存储空间要求较大,处理庞大的数据要付出昂贵的计算成本。
2.1.3 基于深度学习的方法
上述两种方法主要考虑的是模态之间的建模方法,从而得到特征的有效映射。然而深度学习网络主要考虑的是对有效特征的提取,并加入一些新的训练机制,提高模态间的不相关性和模态内的相关性,再进行相似性对比。对于提高高阶语义的相关性,深度学习的跨模态检索方法能够处理更为庞大的真实数据集,得到了广泛的应用。本小节介绍了具有代表性的深度网络模型与相关算法、对抗性学习合成特征方法、知识迁移学习方法和多模态通用的跨模态检索的方法。
从深度学习所采用神经网络模型与相关算法的不同总结出以下几种代表类方法。Xia等人[35]提出基于深度学习的深度典型相关分析方法(deep-CCA)训练大规模数据,先求出两个具有最大相关性视图的投影向量,再通过多层堆叠的非线性变换来计算相似度,其效果明显优于CCA方法。Feng等人[36]提出对应自动编码器模型(correspondence autoencoder,Corr AE),关联两个相互对应的单峰自动编码器来表示隐藏信息。随后他又提出通信受限玻尔兹曼机[37],通过不同模态学习自编码表示并最小化模态间相关学习误差,不断训练使得模型不断优化。经实验验证,这种两两对应的方法能够发现新的属性,对于跨模态检索研究有着较大促进作用。Jiang等人[38]基于相似度理论对图文进行检索,使用局部二值模式(local binary pattern,LBP)作为图像描述符,深度信念网络(deep belief network,DBN)作为深度学习算法。该方法为跨模态检索提供了新思路,但由于理论分析的难度较大,该方法较难实际应用。还有一种图卷积神经网络,可同时学习各个节点的特征与结构信息,比卷积神经网络适应性更广。Dong等人[39]提出基于图卷积网络(graph convolutional network,GCN),利用样本与其邻域之间的邻接关系重构样本表示并基于局部图重构节点特征,将两种模态的特征映射到公共空间中,从而获取隐藏的高级语义信息并增强具有相同语义的样本相似信息。但图卷积网络计算量比较大,难以处理新加入节点信息,这些问题还有待解决。
对抗性学习方法有着强大的区分能力,能够很好地弥补异质差距以提高跨模态检索效率,是深度学习中重要的方法之一。Peng等人[40]提出跨模态生成对抗网络(cross-modal generative adversarial networks,CM-GAN),使用两对生成器和鉴别器共同工作对模态内和模态间进行判别,最终生成具有高分辨性的通用表示。然而CM-GAN方法倾向于全局特征的描述,为此Kou等人[41]提出结合对象注意和对抗性学习的方法。其中对象注意模型用来生成高质量的图像文本特征,反映更为丰富的语义,再加上生成对抗网络用来生成高质量的特征,使得检索效果有所改善。Shi等人[42]基于互补注意机制的特征提取来提高语义表示相关性,并在对抗式学习框架中训练公共特征映射和模态分类,获得了通用语义表示以减小模态间语义差距,其效果优于传统的深度学习算法。CM-GAN方法在各个模态生成特征时具有不稳定性,可能会有错误的数据影响检索效果。为此Xu等人[43]提出联合特征合成与嵌入方法(joint feature synthesis and embedding,JFSE),采用了两个改进的耦合GAN用于多模态特征合成,并将类嵌入作为特征级跨模态数据合成的辅助信息,有效地关联每个模态的特征合成。
迁移学习是深度学习中的一种重要方法,常常会与对抗学习结合来解决跨模态检索中的未知类问题。Huang等人[44]提出端到端两个网络结构的跨模态对抗混合传输网络(modal-adversarial hybrid transfer network,MHTN),一端利用迁移学习将相关表示从单模态源域迁移到多模态目标域;另一端在公共表示空间构建对抗训练机制进行语义学习,实现了多模态数据的有效检索。为了保留原始数据的潜在结构以获取更好的检索效果,Zhen等人[45]提出深度多模态迁移学习方法(deep multimodal transfer learning,DMTL),由两个多模态特定的神经网络和一个联合学习模块组成,并采用映射到公共子空间的思想实现跨模态检索。迁移学习方法从先前标记的类别源域中迁移知识,可以提高未标记的新类别目标域的检索性能,然而不能有效处理新增加的模态,需要重复地训练数据。
由于跨模态检索的模态不断增加,固定模态如图像文本模态的研究并不能完全应用于其他模态,总需要重复训练或重新设计网络模型,无用工作较多且设计复杂,因此学者提出通用的跨模态检索方法。Cao等人[46]提出混合表示学习(hybrid representation learning,HRL),由堆叠受限玻尔兹曼机(SRBM)提取每种模态表示,多模态深度信念网络(DBN)提取模态互表示,以及使用包含联合自动编码器和三层前馈神经网络的双层网络。该方法通过多模态推断图像的缺失信息以挖掘潜在图像表示,而且采用堆叠双峰自动编码器可以获得多种模态的最终共享表示。Hu等人[47]提出可扩展的深度多模态学习(scalable deep multi-modal learning,SDML)检索方法,在预定义公共子空间分别为n个模态训练获得n个网络,这是第一个提出将多模态数据分别投影到预定义的公共子空间的技术。
综上所述,深度学习方法已经是大数据时代跨模态检索的重要方法,在信息数量越多时检索效果越好,且适用于图像文本等更多模态的检索。随着深度学习网络模型的不断改进并与其他建模方法结合,能不断地优化处理多模态数据和特征提取问题。对抗迁移学习方法可以检索未知类数据,尤其是使用对抗学习可以生成相关特征以提高分辨能力,而且没有对于模态的限制。另外,通用多模态表示技术如混合表示、多层表示的方法,能够综合不同技术的特点,只要设计好合理的网络结构,就能在多种模态应用中取得很好的效果。本文认为,在未来研究中可以将深度学习的思想与各种建模方法融合,也可以利用GAN及其改进方法生成多模态特征以减小语义差距,还可以设计混合的多模态学习框架以适应多种模态的跨模态检索。
2.1.4 实值表示技术总结分析
实值表示方式可以包含不同的数据类型,能够保留原始数据且满足多种模态的检索需求,但它需要大量的存储空间,不能满足高效的检索要求。其中子空间模型与主题统计模型都是为实现跨模态检索提供一个数据比较的模型,基于深度学习的方法是提供一种特征提取的有效手段。本研究选取了几种实值表示技术,比较它们在Wikipedia数据集上应用的MAP值。如表2所示,可以看出P3S在基于子空间学习的方法中效果最好,CMOLRS在基于主题概率模型的方法中效果最好,DMTL方法的MAP值远高于其他方法。
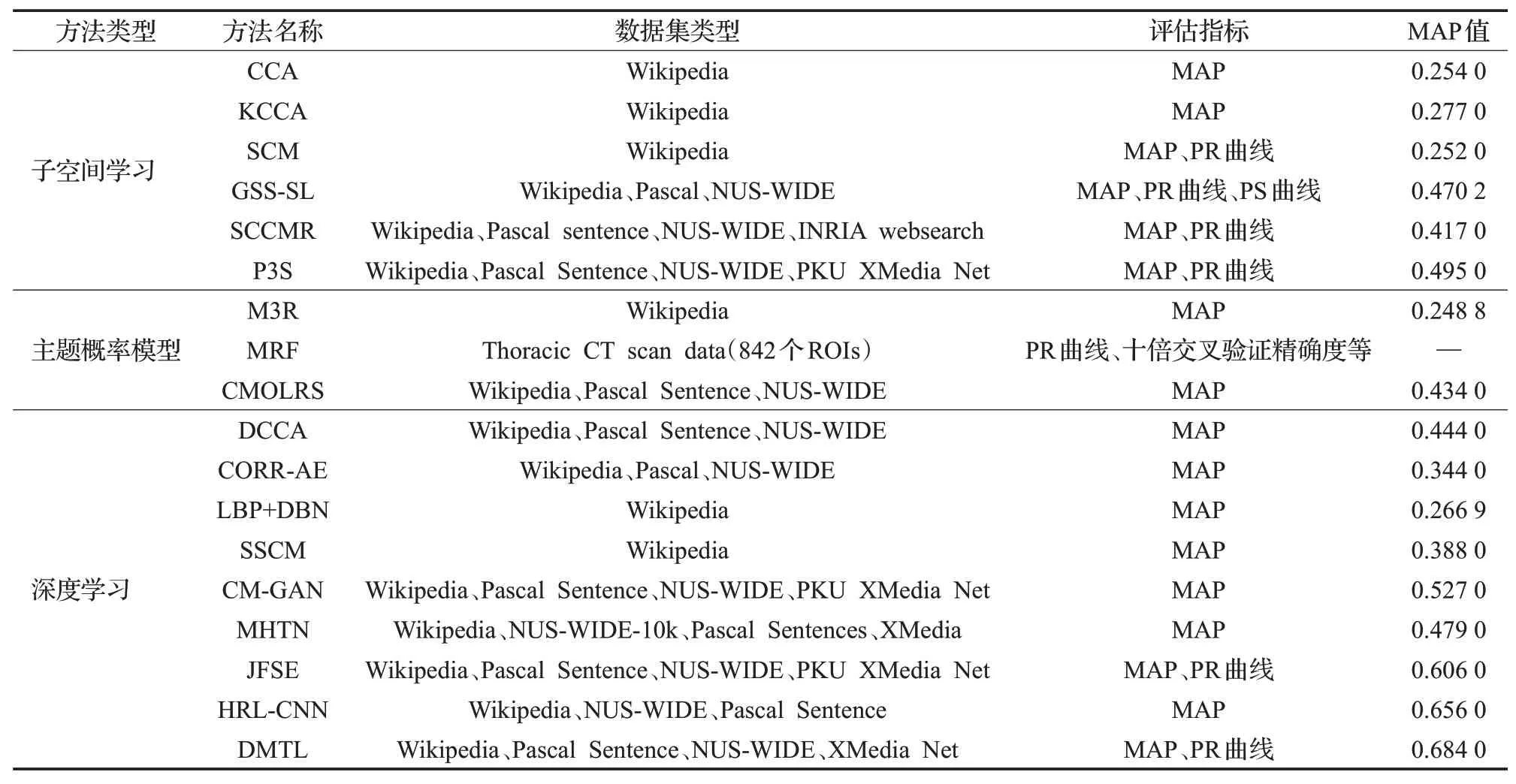
表2 实值表示方法数据集及评价指标对比Table 2 Comparison of real value representation method datasets and evaluation indexes
实值表示方法还可以在检索精度和效率、多模态的相互表示上进一步优化。对于检索精度的提升,上面提到了补充语义标签等方法;对于检索效率的提高,融合神经网络模型与联合学习的机制是可行的,该方法所呈现的检索效果往往优于单一模型的检索机制,不过融合模型太多会将简单问题复杂化,在实际应用中需要衡量实用价值选择适合的方法。
2.2 二进制表示
不同于实值表示的数据直接表示,二进制表示将数据转换成另一种更短的存储方式,能够降低存储成本。利用哈希算法学习转换数据可以提高检索效率,跨模态哈希有二进制码和哈希函数两大重点内容。跨模态哈希函数通常是在目标函数中使用额外的二进制约束,并利用迭代量化或离散优化算法来学习二进制代码。本节按照二进制实现算法分为基于传统哈希的方法和基于深度哈希的方法。传统的哈希算法是针对任意长度的二进制值,映射为较短的固定长度的二进制值以节省存储空间。深度的哈希算法不再限制二进制码的长度,只要满足在一定范围就可进行计算。
2.2.1 基于传统哈希的方法
传统的哈希算法本质上是近似最近邻搜索的优化问题,求解哈希函数最优解以更好地实现模态的相关表示。大部分哈希函数学习分为降维和量化两个阶段:降维是将信息从原始空间映射到低维空间表示,量化是将实际特征线性或非线性转换为二进制的特征空间。
Yu等人[48]通过结合图正则化学习哈希函数的无监督级联哈希技术(unsupervised concatenation hash,UCH)进行降维,将原始特征投影到哈希码中建模求解,该方法的MAP值远高于CCA等传统的方法。Yu等人[49]之后又提出利用多个视图之间的互补信息来更好地学习哈希码的学习框架(multi-view hash,MVH),为3D模型的跨模态检索提供一种新思路。Shen等人[50]提出采用语义标签关系来缩小模态差距的跨模态哈希监督子空间关系学习技术(subspace relation learning for cross-modal hash,SRLCH),将两种模态的语义标签映射到具有变换矩阵的子空间来减小相似度计算距离。Liu等人[51]提出矩阵三因子分解哈希框架(matrix trifactorization hash,MTFH),首次采用不同的哈希长度对异构数据进行编码的方法,能在不完全成对关系的多模态数据以及任意的哈希长度编码的场景下工作。它利用哈希函数学习特定于模态的哈希码,同时学习两个语义相关矩阵,以便对异构数据的不同哈希表示进行语义关联,提升了检索效果。
传统哈希方法往往会放松离散约束,导致相对较高的计算成本和量化损失,故研究者们提出了各种离散优化的方法。Zheng等人[52]提出快速离散协作多模态哈希方法(fast discrete collaborative multi-modal hash,FDCMH)同时具有高效计算和存储的性能。首先采用高效的协作多模态映射模块,保证多模态特征的互补性和语义相关性,此外还有一个非对称哈希学习模块,在公共潜在空间和哈希码之间建立连接,将更多的标签信息嵌入到二进制代码中以增强对语义哈希码的识别能力。Wang等人[53]提出有监督的跨模态哈希(scalable asymmetric discrete cross-modal hash,BATCH)方法也采用了非对称哈希模块。和FDCMH的区别在于:它利用矩阵分解来学习标签和不同模态的公共潜在空间以便于关联不同模态二进制码。在离散优化模块,它引入了量化最小化项和正交约束大大减少了量化误差和冗余。Liu等人[54]提出一种有监督的潜在语义增强离散哈希,也是利用矩阵分解获得不同模态的个体潜在语义表示,采用离散优化策略以减少量化损失。该方法是目前处理图像到文本检索任务时准确性最高的跨模态哈希方法。
基于传统哈希的跨模态检索方法依据样本的二进制编码,能够优化复杂计算和减小存储空间,已成为目前较为热门的方法。但由于哈希算法会产生量化损失影响信息准确度,离散优化问题会成为未来研究的关键。本文总结了提高效率的协作多模态映射模块、提高识别能力的非对称哈希模块来减小量化损失,为哈希算法的探索提供了新思路。
2.2.2 基于深度哈希的方法
基于深度哈希的方法融合了深度学习和哈希算法的优点,不仅具有强大的特征学习能力,其高效的检索性能远远超过传统哈希算法,近年来已成为跨模态检索研究的热门方法。本小节对近年来主要的深度哈希算法进行分析,最后对现有的方法进行总结。
为提高检索效率,Cao等人[55]提出深度视觉语义哈希模型(deep visual semantic hash,DVSH),文中第一次提出端到端网络框架,融合了多模态嵌入和跨模态哈希。多模态嵌入的一端是视觉语义融合网络,以图像卷积神经网络和学习文本的递归神经网络(long shortterm memory,LSTM)紧密关联组成;另一端是两个特定模态的哈希网络,用于学习特定哈希函数便于对未知的数据编码。另外,Deng等人[56]提出基于三元组的深度哈希网络(triplet-based deep hash,TDH),使用三元组标签能灵活捕捉更高级的语义信息并容易生成各种约束,再由图正则化和模态内外间双重视图生成三重损失函数,保持哈希编码之间原始语义的相似性,从而提升检索精度。
基于注意力机制方法能够准确定位到主要信息,减小无用信息的干扰,在深度哈希方法里广泛应用。Zhang等人[57]提出具有注意力机制的深度对抗性哈希(attention-aware deep adversarial hash,AADAH)用于增加内容特征相似性的测量,证明了注意力机制针对多媒体的信息片段有强大的识别能力。吴吉祥等人[58]提出加入多模态注意力机制的跨模态哈希网络(hash network based on multi-modal attention mechanism,HX-MAN),将注意力机制引入到端到端的深度跨模态哈希技术[59](deep cross-model hash,DCMH)方法中来提取不同模态的关键信息,能够准确地检索图像和文本模态的局部细粒度特征,明显改善了检索精度。Wang等人[60]提出自约束和基于注意力的哈希网络(selfconstraining and attention-based hash,SCAHN),将早期和后期的标签约束及其融合特征集成到哈希表示和哈希函数学习中,提升了跨模态检索的精度。
离散优化是解决深度哈希和传统哈希中量化损失问题的有效方法。Xu等人[61]首先提出离散跨模态哈希(discrete cross-modal hash,DCH),它学习特定模态的哈希函数以生成统一的二进制代码,然后采用离散约束求二进制解。之后他又提出离散潜在语义哈希[62](discrete latent semantic hash,DLSH),使用离散优化算法直接学习二进制码,再次减小量化损失。为了解决同时学习二进制代码和哈希函数优化的复杂性问题,Zhang等人[63]提出了一种两阶段监督离散哈希(two-stage supervised discrete hash,TSDH)方法。它将各模态生成潜在标签后直接学习哈希函数,以增强二进制码的可辨别性,分为两阶段处理可以更快进行优化从而提升检索效率。
零样本的跨模态检索具备可扩展性,它可以检索出不同模态的新类且不需要每次对新类重复训练。Liu等人[64]提出跨模态零样本哈希方法(cross-modal zeroshot hash,CZSH),零样本哈希学习使用类别属性来寻找语义嵌入空间,使用已知类中的样本训练的哈希模型对未知类的样本进行扩展,然而要在大量标记数据的情况下才会有好的检索效果。Xu等人[65]提出具有自我监督的三元对抗网络(ternary adversarial networks with self-supervision,TANSS)。它由两个特定模态形成端到端的网络结构,分别是两个语义学习子网络和自监督语义学习子网络,并在整个网络上应用对抗式学习。与之前语义标签方法不同,该方法提出新的自监督机制学习新类标签,有助于有效地迭代参数优化。
另外,跨模态深度哈希学习中还有些其他的方法。Zhang等人[66]提出混合跨模态相似性学习模型(hybrid cross-modal similarity learning,HCMSL),首先从标记和未标记的跨模态对中捕获足够的语义信息,在具有相同分类标签的模态内配对;然后将两个连体CNN模型用于相同模态的样本中学习模态内相似性。该方法可以融合模态内外相似性,从而减小模态差距。Li等人[67]提出多层表示学习方法(multi-level similarity learning,MLSL),首先采用多标签卷积神经网络框架对语义层信息进行编码,再应用图形匹配建模结构层对应关系,最后结合上下文对应不同模态细节并采用三元组损失来减少跨模态差异,最终改善图像文本检索任务。Li等人[68]提出图像文本双向学习网络(bidirectional learning network,BLN),用一种多层监督网络来学习生成表示的跨模态相关性,其双向学习中的双向交叉损失函数能有效减少高级语义信息的丢失。这些混合模型、多层表示、双向学习方法的思想可以应用于多模态,能有效减小模态差异。
本小节总结分析了不同的网络模型以提高检索效率和精度,如端到端网络模型、三元组标签哈希模型、基于注意力机制的哈希网络,还有解决量化损失问题的离散优化方法,解决未知类问题的具有可扩展性的零样本跨模态检索方法和其他综合类方法。基于深度哈希方法的研究主要是通过改善模型和优化算法来寻找更佳的跨模态检索技术,目前仍然具有很大的发展空间。随着深度学习技术的不断优化和哈希算法的不断改进,在未来的研究中可以选择更适合的模型与算法融合以提高信息利用率和检索效率。
2.2.3 二进制表示技术总结分析
二进制表示技术的跨模态检索本质上是一种降维量化的方法。它的优势在于能够节省存储空间,提高检索效率,得到了广泛应用。注意力机制与对抗性学习的方法也大大提高了采用二进制方法的效率和精度。另外多模态的扩展问题也因零样本跨模态检索有了新突破。但降维会破坏数据原始结构,且哈希算法是不可逆的,可能会产生过拟合问题。它还存在离散约束问题,对此在传统哈希和深度哈希中都提到了从算法和哈希函数学习进行离散优化的方法。如表3所示,本文整理了各种二进制表示技术的数据集和评价指标,并分析了方法的特点,以便于后续研究者使用。

表3 二进制表示方法数据集及评价指标对比Table 3 Comparison of binary representation method datasets and evaluation indexes
表4总结了所有的跨模态检索技术并将其分为两类表示技术的不同类型方法,从具体思路、优势、局限性和适用场景展开对比分析。实值表示保留原始数据的结构,二进制表示对数据进行哈希转换,可以提高检索效率,但同时会破坏数据结构。其中子空间学习与主题概率学习模型在处理特定场景问题时具有一定优势。深度哈希方法或许是未来跨模态检索技术的研究热点,它可以融合新的深度网络模型和先进的哈希算法,能够处理复杂的问题。其他的方法也同样重要,深度哈希技术的发展也离不开对于深度学习方法与哈希算法的进一步深入研究。

表4 跨模态检索不同表示方法分析Table 4 Analysis of different representation methods for cross-modal retrieval
3 数据集及评价指标
3.1 数据集
本节对常用的多模态数据集进行总结并分析,如表5所示。

表5 数据集统计表Table 5 Dataset statistics table
(1)Wikipedia[18]:由一个文档语料库和相关的文本和图像对组成,分为10个语义类。维基百科将每篇文章分为29个概念,最终的语料库有2 866份文件。
(2)WIKI-CMR[69]:数据主要集中在地理、人文、自然、文化和历史领域,包含图像、段落、超链接类别标签共74 961个文档。文档分为11个不同的语义类。图像使用8种类型的特征表示,包括密集筛选、Gist、PHOG、LBP和其他特征,文本使用TF-IDF表示。
(3)NUS-WIDE[70]:数据类似于真实世界的网络图像。包括81个类别的约27万幅图像以及5 018个相关标签,共6种类型的低层图像特征。
(4)Pascal VOC[71]:其名称概念为模式分析、统计建模、计算学习和视觉对象。它包含带注释的消费者图片,由9 963幅图像和24 640个注释对象组成,分为20个不同类别。注释中提到的实体包括类、边界框、视图、截断实体和困难实体。
(5)Flickr 30k[72]:Flickr 30k是Flickr 8k数据集的扩展,其包含31 783张日常图像与158 915个相关字幕。这两个数据集都来自Flickr网站,数据主要在某些动作的人或动物(以狗为主),可用于图像和长文本。
(6)MS COCO[73]:由总计328 000张图像和250 000个标记实例的日常场景图片组成,共91个不同的类别,每个图片有5句对应的注释,注释分为标记图像中存在的概念、定位和标记概念的所有实例、每个对象实例的分割共三种。
(7)PKU XMedia[74]:数据由5 000个文本、5 000个图像、500个视频、1 000个音频片段和500个3D模型组成,共20个类别,每个类别有600个媒体实例。数据集被随机分成包含9 600个对象的训练集和包含2 400个媒体对象的测试集。
(8)PKU XMedia Net[13]:数据有200个类别,分为5种模态类型,文件格式分别为txt、jpg、avi、wav和obj,其数据量依次为40 000、40 000、10 000、10 000、2 000。数据集分成81 600个媒体对象的训练集和2个测试集,以4∶1切分数据集与训练集。
(9)M5Product[75]:该数据集包含600万个多模态样本、分为5种模态类型。具有100万家商户针对电子商品的粗粒度和细粒度注释,600万个类别注释,包含6 000多个类别、5 000个属性和2 400万个值,比具有相似模态数量的最大公开可用数据集大500个。
3.2 评价指标
本研究的评价指标采用广泛使用的性能评估标准平均精度(mean average precision,MAP)。MAP度量综合考虑了排序信息和精确率。精确率往往反映检索的整体效果,即所有返回样本中正确相关的样本所占的比例。理想的情况是检索结果排序越靠前的样本与查询样本的相关性越好,平均准确率(AP)可以更好地反映检索的效果,定义如公式(5),其中N是检索集中相关实例的数量,P(r)表示前r个检索实例的精度。平均准确率平均值定义如公式(6):

另外,采用其他评价指标,如精度召回(precisionrecall,PR)曲线表示精度和召回之间的关系,精度是结果相关性的度量,而召回是实际返回多少相关性结果的度量;采用前N个精度曲线(TopN-precision)反映精度随检索实例数量变化的状态。它们的值越大表明性能越好。对于跨模态检索中的图像文本模态检索,Wikipedia数据集通常用MAP来评估算法性能,而MSCOCO、Flickr30k数据集还会用在前K个结果中检索到的正确图像或文本的百分比(Recall@K,R@K)来评估算法性能。
4 结论与挑战
本文对跨模态检索技术进行综述,针对如何减小语义差距并进行有效相似度对比的问题给出了解决方案。文中对实值和二进制表示中具有代表性的技术方法进行分类研究讨论,包括子空间学习、主题统计模型、深度学习、传统哈希和深度哈希的五类方法。这些跨模态检索技术可以从海量信息中快速准确地找到最有价值的数据类型,从而提高信息利用率和检索效率,具有重要的实际意义。
本文根据跨模态检索技术发展现状,列出以下几点跨模态检索面临的挑战,也是未来研究的重要方向。
(1)扩展模态范围。不同的应用场景需要选择不同的模态数据,而固定的模态数据并不能完全应用于其他模态。未来可以利用混合表示模型、多模态学习模型等方法扩展各模态范围,提高跨模态方法的通用性。
(2)精细化模态细粒度。当前基于子空间和主题概率模型的方法可以提取显性特征进行相似性比较,但仍存在隐藏语义特征提取不完整的问题。通过对语义标签的进一步补充预测或借鉴零样本检索探寻未知类可以找到更精确的语义特征,从而精细化模态细粒度的分类。
(3)提升检索效率。检索效率的提升包含了检索准确度和检索速度两部分。目前的跨模态哈希方法已经在检索速度上取得了一定进展,但对哈希检索算法的信息丢失问题,还要继续进行离散优化。对于检索精度的提升,为满足更高准确度的检索要求还可以继续改进损失函数与哈希函数。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
大数据(2021年6期)2021-11-22
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
电脑爱好者(2015年13期)2015-09-10
