
基于决策树算法的钢板探伤预测模型优化
2022-12-14 07:33王复越任毅赵坦崔福祥
鞍钢技术 2022年6期
王复越 ,任毅 ,赵坦 ,崔福祥
(1.海洋装备用金属材料及其应用国家重点实验室,辽宁 鞍山 114009;2.鞍钢集团钢铁研究院,辽宁 鞍山 114009;3.鞍钢股份有限公司鲅鱼圈钢铁分公司,辽宁 营口 115007)
数字化研发手段赋能传统工业领域可实现传统产业转型升级、提质增效以及先进产品研发创新能力的提升[1]。传统钢铁制造行业各生产环节自动化程度高、数据量大、检测数据完整性好,应用大数据技术可提升决策力、洞察力以及流程优化能力。钢铁行业在大数据技术方面的战略意义在于对有价值信息数据进行专业化处理,也就是数据挖掘[2]。人工智能是进行大数据分析及数据挖掘工作的必然选择,机器学习是实现人工智能的一种重要方式。目前机器学习领域已经发展出诸多适用于不同场景的机器学习算法,如决策树、支持向量机、随机森林、人工神经网络以及最近发展迅速的深度学习等[3-5]。其中,决策树算法因可进行可视化分析,生产规则易于理解和解释[6],在解决复杂、非线性、多变量、强耦合的工程问题上有明显优势,需要注意的是决策树模型容易出现过拟合的问题[7]。经过这些年的发展,各类机器学习算法建模已与钢铁行业各环节的实际生产有着广泛的结合,可应用于各类产品性能预测、失效预警与故障诊断当中[8-9]。
以管线钢为例,其服役场景往往是复杂地形和恶劣环境,管线钢钢板在满足各种服役力学性能的同时需兼顾良好的焊接性能、耐腐蚀性能。这对管线钢铸坯在高纯净度冶金与组织精细化控制方面提出了更高的要求[10]。然而在铸坯的生产及轧制环节中物理与化学过程复杂,工况变化频繁,生产过程中不可避免地引入非金属夹杂物以及形成组织缺陷。钢厂在后续的钢板自动探伤检测工序可将一部分存在问题的钢板筛选出来,但由于钢厂与制管企业以及管道安装施工方在探伤设备与检测方式等方面存在差异,时常出现钢厂未检出问题钢板,但后续工序检出的情况。此问题造成大批量钢板退货,给企业带来大量经济损失。
本研究基于上述问题与需求,采用CART决策树算法建立预测模型,充分挖掘利用管线钢铸坯生产关键环节数据,通过模型结构调整与参数优化,达到模型预测水平的提升与泛化能力增强的目的。最终实现对管线钢铸坯的质量预判,降低问题管线钢钢板探伤检测漏检率。此外,本研究对于提升设备运行水平、提高产品质量以及降低不合格品退换货带来的经济损失等方面都具有重要意义。
1 模型搭建
1.1 建模流程
本研究所涉及的决策树模型是使用Python编程语言在Pycharm集成开发环境下建立并运行的,通过开源机器学习工具包Sklearn中的NumPy、Pandas等数值计算的库来实现机器学习的算法应用。决策树模型搭建步骤与流程见图1。

图1 决策树模型搭建步骤与流程Fig.1 Building Steps and Flow Process for Decision Tree Model
结合冶金学原理,分析、筛选众多生产工艺特征选项,将预测建模中的特征选项(features)设定为:RH处理周期、钢中总铝含量、RH净循环时间、钢液浇铸过热度、拉速、辊缝合格率。预测结果即标签(Label)为钢板探伤是否合格,合格为0,不合格为1。将生产数据中由于数据漏采集、传输设备信号故障、中断等原因造成的数据缺失、乱码等数据进行剔除处理,并以8∶2的比例将数据集随机划分为互斥的训练集和测试集。特征数据集如表1所示。

表1 特征数据集Table 1 Data Set of Features
1.2 模型设定及优化方案
决策树构建是通过选用不同的样本纯度度量指标(信息增益、增益率、基尼指数),找到包含关于目标特征的最大信息量(纯度)的描述性特征,并沿着这些特征的值分割数据集,使得生成的子数据集中的目标特征值纯度尽可能高,最终产生一个泛化能力强的判定流程模型[11]。为达到此目的,需要选定合适的样本纯度度量指标,设定决策树深度(层数)以及叶子节点最小样本数点。
本研究选择基尼系数作为数据样本的度量指标,在Sklearn机器学习工具包中Decision Tree Classifier模块的Criterion设定中选定gini。为优化决策树结构,分别设定决策树最大深度为三层与四层,考察叶子最小样本数从10到220条件下模型评估水平。随后,对预测水平与泛化能力最佳的模型调整预测判定阈值,使模型对于探伤不合格钢板的召回率达到70%以上的水平,且整体预测精准率不低于70%。此外,为平衡数据集中类别的失衡问题,根据数据集中探伤不合格钢板比例设定样本合格与不合格钢板权重为1:19。
1.3 模型评价
对于所涉及的探伤结果二分类问题,可将数据中探伤结果样例类别与分类器预测结果类别的组合划分为真正例 (实际探伤不合格且预测正确)、假正例(实际探伤合格但预测错误)、真反例(实际探伤合格且预测正确)、假反例(实际探伤不合格但预测错误)四种情况,令 TP、FP、TN、FN分别表示其对应数量。使用ROC(Receiver Operating Characteristic)曲线描述分类器的预测能力及泛化性能的优劣,ROC曲线的纵轴是 “真正例率”(TPR),横轴是“假正例率”(FPR),两者定义为:

通过积分计算ROC曲线下面积(AUC)来,比对AUC数值大小实现对模型预测效果的评价,AUC值来表现其预测能力,训练集与测试集AUC差值表现其泛化能力。AUC值越大,模型的预测能力越强,训练集与测试集AUC差值越小,模型的泛化能力越好。
此外,以实际探伤不合格钢板的召回率(Recall)为第一考察指标,并结合考察精准率(Accuracy)的方式对模型的实际预测水平进行评价。召回率与精准率的定义为:
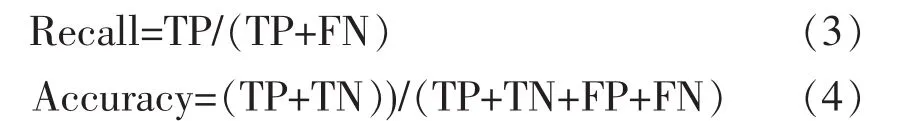
召回率可反映模型对于正例的预测水平,即对实际探伤不合格做出正确的判定,精准率则可以反映模型对正、反例的综合预测水平。
2 模型优化
2.1 决策树结构优化
本研究使用数据样本中同一训练集训练决策树分类器模型,分别设定决策树模型最大深度为三层与四层,考察叶子最小样本数从10到220条件下模型评估水平,叶子最小样本数对预测模型AUC值的影响如图2所示。
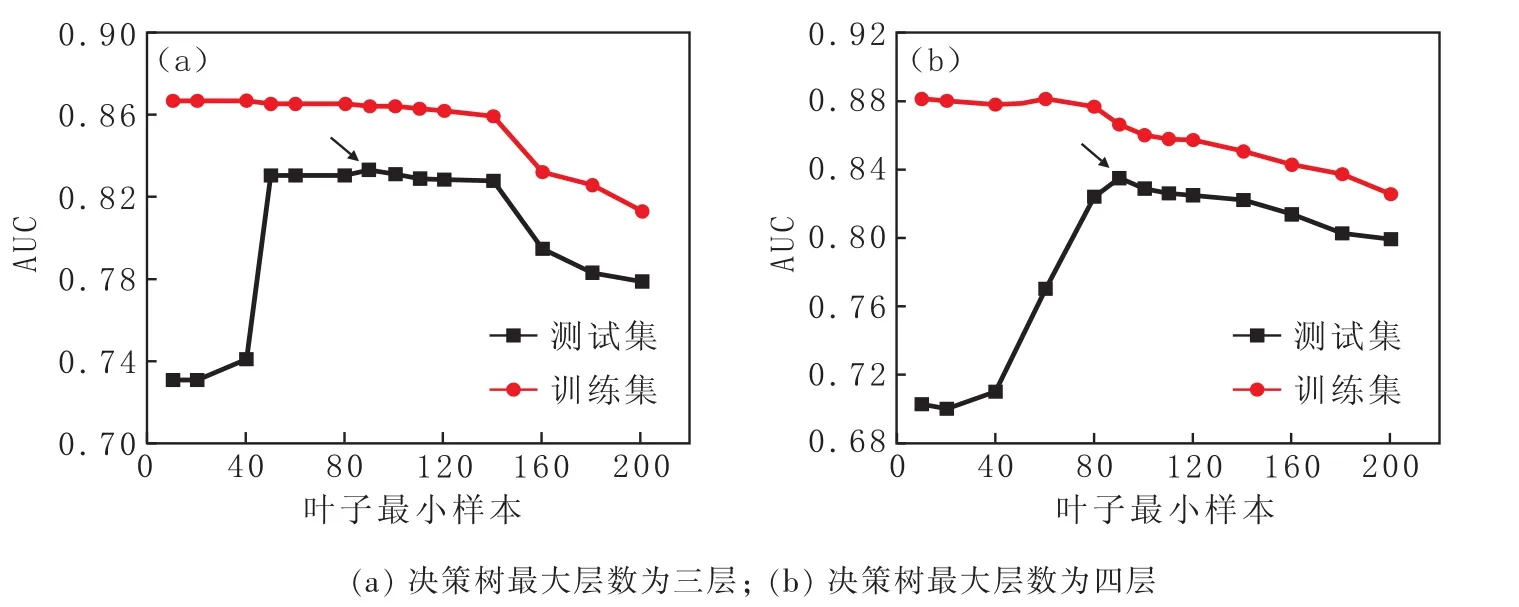
图2 叶子最小样本数对预测模型AUC值的影响Fig.2 Effect of Minimum Number of Samples of Tree Leaves on AUC Value of Prediction Model
从图2(a)可以看出整体上训练集AUC值高于测试集,训练集AUC随叶子最小样本数变化的增大而小幅降低,而测试集AUC则在叶子最小样本数为40时阶跃上升,而后AUC一直保持较高的水平。直到叶子最小样本数为超过140,测试集AUC下降明显。当叶子最小样本数为90时,测试集AUC值最大为0.833 9。在叶子最小样本数相对较小时,经训练集训练的模型出现过拟合的情况,测试集AUC值较低,模型预测水平较低;在叶子最小样本数设定相对较大时,所设定的模型结构规则无法很大的描述与反映数据特征,训练集与测试集AUC值都在较低的水平,这说明模型出现了欠拟合的情况。同样的,决策树模型最大深度设定为四层时,训练集与测试集AUC值随叶子最小样本数变化趋势基本一致。训练集AUC值在叶子最小样本数为90时达到最高,为0.848 4。而后随叶子最小样本数的增大训练集与测试集AUC值缓慢降低,如图2(b)所示。从上述测试集AUC最大值以及随叶子最小样本数变化的情况看,该决策树模型在最大深度为四层,叶子最小样本数为90时,模型预测水平达到最佳。
决策树模型训练集与测试集ROC曲线如图3所示。 从图3(a)与图 3(b)中可以看出,不同最大层数下代表训练集与测试集的曲线都基本重合,最大深度为三层、四层时训练集与测试集的AUC值差值分别为0.031 7、0.034 0。AUC差值都较小,这说明模型的泛化能力较好。

图3 决策树模型训练集与测试集ROC曲线Fig.3 ROC Curves of Training Sets and Test Sets for Decision Tree Model
2.2 判定阈值调优
根据上文评估结果可知,经过结构优化后的决策树模型具有较高的水平且模型泛化能力较强。然而在模型进行预测时需要设定一个预测判定阈值,模型生成预测分析值与其对比后才能进行合格与不合格的判定。通常判定阈值设定值较高时(接近1时),召回率较高,而精准率低;阈值设定值较低时(接近0时),召回率较低,而精准率较高。结合生产、检测与供货的诸多实际情况,建立“首先保证召回率”的模型判定的思想,同时兼顾考虑送检钢板数量与检测能力的矛盾关系,对预测判定进行比对与调优。图4为模型判定阈值对召回率及精准率的影响关系图。

图4 模型判定阈值对召回率及精准率的影响Fig.4 Effect of Decided Threshold Values for Model on Recall Rate and Accuracy Rate
从图中可以看出,召回率随判定阈值的增大而降低,精准率随判定阈值的增大而提高,两者呈相反的变化趋势。当判定阈值小于0.4时,召回率约为80%,说明对大部分存在潜在问题的钢板可完成召回。
结合模型在召回率与精准率的表现,设定判定阈值为0.4。为了更直观的展示模型对训练集与测试集的预测表现,将其对应混淆矩阵列出,如图5所示。图5(a)为以训练集的混淆矩阵,召回率为85.3%,精准率为75.4%;图5(b)为以测试集的混淆矩阵,召回率为74.0%,精准率为73.5%。此设定下模型在相对较小的检测样本中最大限度的完成不合格钢板的预测与召回,同时模型对正、反例的预 测精准率均在70%以上,有效的利用了检测资源。

图5 训练集与测试集混淆矩阵Fig.5 Confusion Matrix of Training Sets and Test Sets
3 决策树可视化与分析
决策树模型包括钢中总铝含量、RH净循环时间、钢液浇铸过热度、拉速、辊缝合格率的五点关键性生产指标,经过结构优化后的模型通过Graphviz.Source模块实现对决策树模型的可视化,图6为管线钢连铸板坯探伤预测影响因素的决策树模型。从图6中可以看出,该决策树模型共四层,共有9个节点,终端11个叶子节点。拉速是影响管线钢连铸板坯探伤结果最重要的影响因素,出现在决策树的各层中。在实际生产中,通过调整连铸拉速的方式来实现对生产节奏变化以及中间包温度的配合与调节,其调节效果明显,这也使得连铸拉速波动较大。与此同时,连铸拉速的波动对于铸坯冶金质量的影响也是显著的,拉速的变化关乎钢液的动量传递、热量传递与质量传递,影响熔体流动、液穴形态、凝固相变、结晶器壁面冷却强度、“浮游晶”沉降、气体与夹杂物上浮以及对耐火材料的溶蚀等多重方面[12]。因此,应严格控制连铸拉速工艺波动,并设定连铸拉速波动上限值,通过此方式可有效提高铸坯与钢板的冶金质量。

图6 连铸板坯探伤预测影响因素的决策树模型Fig.6 Decision Tree Model for Influencing Factors of Flaw Detection Prediction of Continuous Casting Slabs
4 结语
基于工业生产数据,以炼钢与连铸环节多项关键工艺点为特征属性,采用CART分类决策树算法建立了中厚板连铸板坯探伤预测模型。通过调整决策树最大深度、叶子最小样本数以及判定阈值,对决策树结构与判定策略进行优化调整,经测试集验证:优化后的决策树模型对连铸板坯对应轧后钢板探伤结果预测具有较好的预测效果,AUC值为0.848,且模型泛化能力较强,训练集与测试集AUC差值低于0.04。当判定阈值为0.4时,模型对测试集数据预测的召回率与精准率都高于70%,可实现对连铸板坯探伤结果的高精度预测。此外,通过决策树可视化分析可为工艺参数的调整与控制提供可靠依据。此项工作的开展有效提升铸坯质量判定能力、大幅降低漏检率,减低企业由于钢板探伤不合退换货带来的经济损失。为企业工艺智能化调节以及产品质量智能化管理提供帮助,对提高产品质量稳定性与工艺控制水平起到积极作用。
猜你喜欢
甘蔗糖业(2022年2期)2022-05-22
湖南林业科技(2021年3期)2021-12-02
成都信息工程大学学报(2019年3期)2019-09-25
小学生导刊(2018年34期)2018-12-18
电子制作(2018年16期)2018-09-26
小学生优秀作文(趣味阅读)(2018年6期)2018-09-19
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
海峡姐妹(2016年1期)2016-02-27
小学生时代·大嘴英语(2015年10期)2015-11-26
郑州大学学报(医学版)(2015年1期)2015-02-27
