
流形正则化的交叉一致性语义分割算法
2022-12-21 03:23刘腊梅宗佳旭肖振久兰海曲海成
中国图象图形学报 2022年12期
刘腊梅,宗佳旭,肖振久*,兰海,曲海成
1. 辽宁工程技术大学软件学院,葫芦岛 125105; 2. 泉州装备制造研究所,泉州 362000
0 引 言
深度学习在计算机视觉领域取得了令人瞩目的成果。但是,训练深度学习模型需要大量的标记数据,获取这些数据是耗时耗力的,在语义分割中这种现象更为严重。像素级标签的获取需要耗费大量的人力和物力,成本是区域级和图像级标签的15倍和60倍(Lin等,2014)。因此,深度学习需要提高数据的利用率,特别是在图像语义分割方法中。
目前,越来越多的研究工作集中在深度半监督学习上,以利用大量未标记数据并限制对标记数据的需求。在深度学习中,主流的半监督方法包括一致性训练(Tarvainen和Valpola,2017)、伪标签法(陈辰 等,2020)和熵最小化(Miyato等,2019)等方法。而半监督学习的最新进展大多集中在分类任务中,在语义分割中仍然受到限制。语义分割中的大多数工作(Zhang等,2020)专注于利用弱监督学习训练模型,即利用图像级标签生成伪像素标签,然后与有限的像素级标签共同用于训练。然而这些方法依然会受到限制,弱监督的方法需要带有非像素级标签的示例配合像素级标签的数据共同训练,因此弱监督方法不会利用未标记数据来提取其他训练信号。在半监督学习方法中,基于生成对抗网络(generative adversarial networks,GANs)的训练方法会利用未标记的数据,通过GANs的框架结构扩展到像素级别的预测,利用鉴别器对抗损失和有监督损失来联合训练(Souly等,2017),但需要解决模型坍塌等棘手问题。同时,在语义分割的任务中需要依赖大量上下文之间的信息。目前的方法对上下文信息的采集及约束不能满足现阶段任务的需求,而且现有的增加上下文信息的方法都不同程度地增加了网络的推理速度。
为解决上述问题,在交叉一致性训练的基础上提出了一种流形正则化的半监督语义分割方法。一致性训练的目的是通过在输入图像上施加微小扰动以强制约束模型的预测结果不变。由此,模型将对微小变化具有强鲁棒性。一致性训练的有效性在很大程度上取决于数据分布的形态,即数据的流形分布。交叉一致性的半监督训练方式则是通过编码器输出的不同形式的扰动,将扰动施加于不同的解码器上并且强制使其解码器预测结果不变,以保持模型的预测不变性。Niyogi(2013)提出,尽管表面形式的自然数据分布在高维空间(语音、图像和文本等)中,但它们的构成元素并不多,因此具有较低的固有维数。这也证实了将流形正则化应用于交叉一致性半监督语义分割在理论上的可行性。
本文旨在利用未标记数据来找到可以支持语义分割阶段的流形结构。假设两个数据点x1和x2在输入中具有相似的特征结构,那么相应的输出y1和y1也应该是相近的。并认为两个数据域在低维流形空间上有相同结构,通过维持两个高维空间域低维流形的映射关系,促使图像中原有的几何结构不被破坏,在图像分割过程中增加了相应的上下文信息。这意味着不受监管的数据在深度网络中充当正则化器,从而提高了泛化能力。本文算法简单高效,具有很高的灵活性,可以很容易扩展到其他的半监督和弱监督算法中,是一种即插即用的模块。本文主要贡献如下:1)通过几何优化的方式建立语义分割中的流形正则化算法,通过引入上下文信息及维持原有局部几何特征的方式,提高了语义分割模型的精度;2)将流形正则化的图像分割方法引入主流的半监督和弱监督方法中,提升了模型的分割精度。
1 相关理论研究
1.1 半监督语义分割
自全卷积神经网络(fully convolutional etworks,FCN)(Long 等, 2015)提出以来,语义分割技术得到高速发展。现阶段语义分割的方法大多是基于全监督学习的(青晨 等,2020),并且强烈依赖大型注释数据集,但是在很多情况下数据是不可获得或不能使用的。
为解决上述问题,研究人员探究了半监督和弱监督两种不同的语义分割方法,即使用有限数量的像素级标签和大量不精准的注释,例如区域级注释(Song 等,2019)或图像标签级注释(Lee等,2019),对基于图像级注释的方法使用类激活映射函数(class activation mapping,CAM)(Zhou等,2016)生成主要的定位图,在弱监督训练中与像素级标签共同用于训练分割网络,使深度网络学习更好地对视觉特征进行分类。Hong等人(2015)将语义分割作为分类和分割两个独立任务处理,假设数据集中所有图像级的标签和有限的像素级标签均可用,取得了良好效果。生成模型也可以用做半监督语义分割(Liu等,2019),以利用未标记的数据,在GAN的框架下,判别器的预测扩展到像素类别,然后通过标记示例的交叉熵损失和整个数据集的对抗性损失进行联合训练。
1.2 流形正则化
正则化在模型优化过程中对参数起到了约束作用,将参数限定在可控范围内。正则化约束需要丰富的数学理论基础,Evgeniou等人(2000)利用正则化的方式求解不适定逆问题,其理论目前广泛应用于现代机器学习。在现阶段的机器学习算法中,常见到正则化的影子,如支持向量机就可视为正则化的特例。流形正则化的算法承认样本之间的相关性,相关程度直接受样本间距离的影响,样本间距离越小,相关程度越大,并由此可以推断两个不同样本是否处于同一流形空间。由此,流形正则化可以广泛应用于半监督和弱监督学习(Belkin等,2006)。
目前,深度学习快速发展,在多种不同任务上取得了优异效果,但是在利用深度学习进行特征提取和传播的过程中,持续的卷积和池化操作会造成原始结构中关键信息的丢失,即本征结构损失。为解决上述问题,维持图像中原始的几何分布,科研工作者试图利用流形正则化的方式构建更加稳定的算法模型。
首先,利用流形正则化可以建立起相应的流形曲面,可对未出现对象的预测提供有力的依据,Belkin等人(2006)建立了面向半监督学习的流形正则化框架。为深入理解和应用流形正则化算法,以半监督算法为例,Niyogi(2013)建立minmax框架,通过对比不同的算法模型,更好地解释了流形正则化及相关几何算法。除建立算法框架外,流形正则化也应用于网络模型构建(胡聪 等,2020),将特征提取与构建流形结构同步进行,获得了较好的分类结果。其次,流形正则化除应用于上述分类任务中,也逐步应用于语义分割等其他不同任务。Quispe和Petitjean(2015)利用先验知识中的几何信息,通过为训练集中的形状信息编码,对语义分割起到了指导性帮助。徐胜军等人(2019)将马尔可夫条件随机场与流形约束进行结合,构建了用于分割的模型,优于以常规马尔可夫条件随机场构建的模型。基于上述方法,本文在图像分割训练过程中引入流形正则化的约束项,增强了图像分割中的上下文信息,提升了原有分割模型的分割精度。
2 流形正则化的半监督及弱监督语义分割算法
2.1 交叉一致性训练模型
以交叉一致性训练模型为基础的半监督语义分割的目的是在未标记集中提取相关信息。与传统一致性训练不同,交叉一致性训练模型(cross-consistency training,CCT)(Ouali等,2020)设计将扰动添加至编码器的输入之后,依赖主解码器和辅助解码器的输出之间的约束实现了模型的一致性预测。通过使用在未标记数据中提取的其他训练信号,可以增强共享编码器的表示。与编码器相比,添加的辅助解码器的参数数量可忽略不计。另外,在推理期间仅使用主解码器从而减少了训练和推理的计算开销。半监督的交叉一致性训练模型的网络结构如图1所示。

图1 半监督交叉一致性训练模型的网络结构Fig.1 Network structure of semi-supervised cross-consistency training

(1)

对于未标记的示例xu,使用共享编码器z=h(xu)计算中间表示,并考虑使用T个扰动函数。t∈[1,T]表示一个扰动,其中一个扰动可以分配一个或多个辅助编码器。通过不同的扰动设置生成中间表示z的K个扰动版本,并且为保证一致性,算法将扰动函数视为辅助解码器的一部分。最后训练的目标是使用无监督的损失Lu最小化,具体为
(2)
式中,Lu用来衡量主解码器的输出与辅助解码器的输出之间的差异。在这项工作中,以均方误差(mean squared error,MSE)作为无监督部分的度量距离d。
与半监督任务相似,弱监督的交叉一致性训练模型在其基础上添加了由平均池化层和分类层组成的分支gk+1,并且使用CE损失对编码器进行训练以完成分类任务的预训练。通过预训练的编码器和添加的分支结构生成像素级别的预测图像yp。首先,利用分类分支和CAM(class activation mapping)生成特征图M(Zhou等,2016),其中M∈RC×H×W,通过设置前景阈值θfg和背景阈值θbg可以利用特征图M生成像素级别的伪标签图像yp。当特征值分数小于背景阈值θbg时,像素被视为背景,当特征值分数大于前景阈值θfg时,将该点像素视为具有最大关注的类别。生成像素级别的伪标签图像yp后,利用密集条件随机场(conditional random field,CRF)进行最后的细化。
通过Dw网络可以使用弱监督损失Lw训练辅助网络。在此情况下,Lw表示为
(3)
在交叉一致性训练模型中,无论是使用交叉熵损失还是均方误差,均只计算了单点像素之间的关系,忽略了区域间的影响。为解决这一问题,可以在半监督算法的损失函数中引入流形正则化实现相邻区域间的上下文信息捕捉。
2.2 流形正则化的交叉一致性训练模型
因为受限于现有的损失函数,半监督和弱监督的图像语义分割算法在参数表达过程中忽视了大量的上下文信息。流形正则化在原有交叉一致性训练模型的基础上,在不改变原有模型的前提下增加了相应的上下文信息。

(4)
式中,Ni表示xi近邻子图的个数,j为范围Ni内的任意一点。当j不处于xi的邻域内时,ωij为0。
在构建上述模型时,本文首先考虑到图像具有不同的尺度和范围,各分割任务对上下文信息的需求并不相同,可以通过控制邻近数据点的个数进而控制上下文信息的引入情况。其次,盲目利用全局信息进行约束将会消耗大量的空间资源和时间资源,不利于语义分割模型的训练。所以在关系矩阵的构建过程中根据实际情况选择近邻数据点与非近邻数据点对当前数据点的影响程度的大小。
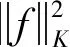
(5)
由式(5)可知,输入域数据两区间有高度相似性时,与之相对的输出域数据的两区间的计算差值应尽可能小,否则该惩罚项会增大损失函数。由此维持了输入域数据和输出域数据之间对应的几何结构,其几何结构如图2所示。

图2 数据域几何结构示意图Fig.2 Data field schematic diagram of geometric structure


(6)

与半监督的语义分割任务相同,在弱监督语义分割任务的损失计算中缺少了相应的上下文信息。对弱监督的语义分割问题,因包含伪标签图像yp,除了建立原始图像与预测图像之间在低维流形空间上的约束关系外,还建立了伪标签图像与预测图像之间在低维流形空间上的约束关系。流形正则项可表示为

(7)


(8)

2.3 流形正则化的弱监督交叉一致性训练模型
将流形正则约束项加入现有的深度学习网络模型,可以为现有的网络模型提供上下文的信息,增进模型参数的有效性,提高了端对端的图像语义分割模型的有效性,并由此建立了流形正则化有关各类语义分割任务的算法模型。
在深度学习分割模型上,首先需要判断当前语义分割任务的类型。若为弱监督语义分割任务,则首先为数据集生成伪标签;若为全监督或半监督任务,则无需此过程。此后计算生成数据集的权重矩阵。半监督和弱监督的流形正则化算法流程如图3所示,其模型伪代码如下:
输入:有标记的图像、无标记的图像。
输出:调优后的模型。
1) IF 语义分割为弱监督任务:
2) 为数据集中未标记的数据生成伪标签;
3) 子图像块划分;
4) 利用式(4)计算权重矩阵;
5) WHILE 模型不收敛:
6) IF 语义分割为弱监督任务:
7) 将图像输入弱监督语义分割模型中,计算出预测结果;
8) 利用式(6)计算总体损失;
9) ELSE:
10)将图像输入半监督语义分割模型中,计算出预测结果;
11)利用式(8)计算总体损失;
12)依照损失值计算更新对模型参数;
13)RETURN 调优后的模型。

图3 算法流程图Fig.3 Algorithm flow chart
3 实验及结果分析

3.1 评价标准和数据集
实验采用平均交并比(mean intersection over union,mIoU)作为语义分割的评价标准。具体为
(9)
式中,tp表示某一类别中正确的正样本分类结果,fp表示错误的正样本分类结果,fn表示错误的负样本分类结果。
实验在PASCAL VOC 2012(pattern analysis, statistical modeling and computational learning visual object classes 2012)数据集上进行。在数据集中,将图像中的物体分为目标和背景,目标按类别用不同颜色表示,背景用黑色表示。PASCAL数据集中的分割如图4所示。实验选取数据集中1 464幅带标记图像为有监督训练集、9 188幅图像为无监督训练集以及1 449幅带标记图像为评估数据。

图4 PASCAL VOC 2012分割示意图Fig.4 Division diagram of PASCAL VOC 2012
针对基于流形正则化的弱监督交叉一致性训练模型,按照伪标签的生成方法生成对应标签。数据集中未标记数据生成的伪标签分割如图5所示。

图5 伪标签分割示意图Fig.5 Division diagram of pseudo tags
在训练过程中,通过预处理操作,使训练样本图像均为256×256像素。在PASCAL VOC生成的半监督数据集上,对模型进行100次循环(epoch)的迭代训练,批处理(batch size)大小设置为1。
3.2 半监督语义分割对比实验
本文在交叉一致性语义分割的基础上,通过流形正则化的方式引入了更多的上下文信息,并且使分割图像和原始图像具有相同的几何信息。为了进一步探索提出框架的有效性,在PASCAL VOC数据集上,将本文算法与目前先进的半监督语义分割模型进行定量比较,实验结果如表1所示。可以看出,本文算法模型优于对比模型。此外,因为网络结构没有改变,故推理本文模型速率可以与原始模型保持一致。

表1 半监督实验对比结果Table 1 Comparison results of semi-supervised experiments
图6为半监督语义分割结果对比图。可以看出,本文模型的分割结果优于交叉一致性训练模型,在交叉一致性训练模型中考虑到了多种噪音的干扰,并且通过训练使图像在多重干扰下分割结果仍然可以趋于一致。但是图像分割中各像素点的分割并没有充分利用上下文之间的信息,将会造成图像中部分区域的漏分和误分。图6(c)为CCT的分割效果,图6(d)为本文方法的分割效果图。可以发现本文方法在图像分割的细节上更优秀,并且减少了漏分和误分现象,这是因为本文采用流形正则化的方法约束图像分割方法,为图像分割方法增加了更多的上下文信息,使像素点在类别划分上增加了图像中不同位置的信息,提高了图像的分割精度。

图6 半监督语义分割结果对比图Fig.6 Comparison diagram of semi-supervised semantic segmentation results((a)original image; (b) ground truth; (c) CCT; (d) ours)
为了验证流形正则化的语义分割算法在半监督语义分割任务中的有效性,将本文算法与CCT模型在PASCAL VOC数据集上每一类别的分割结果进行对比,如表2所示,二者的平均交并比分别为48.4%和44.7%。可以看出,与原始网络相比,本文算法提升了大部分分割目标的精度。主要有两个影响因素:1)本文算法建立了分割图像在源域和目标域之间的对应关系,对图像中关键的几何信息进行了相应的约束,使分割图像可以保持原有的本征结构不被破环,使得目标图像更加贴近原始图像中的几何形态。2)采用流形正则化的半监督图像语义分割算法增加了图像分割过程中的上下文信息,使图像在分割或评价的过程中作为一个整体存在,即分割模型在学习过程中不再局限于局部信息。由此,针对图像分割的神经网络得到了更好的训练,提高了网络的学习能力,使得在原有参数量不变的基础上神经网络得到了更好的表达。实验中部分图像类别分割精度下降,这些目标类别多为动态物体,几何结构复杂,且受环境影响较大。

表2 模型语义类别实验精度对比结果Table 2 Comparison results of experimental accuracy of model semantic categories /%
3.3 弱监督语义分割对比实验
流形正则化增强了模型在训练过程中的上下文信息,并且维持原有图像的几何结构不被破坏,提高了原有模型的分割精度。实验已经证明流形正则化可以优化现有的半监督语义分割算法。为证明流形正则化是一种即插即用的算法模型,可以广泛应用于半监督和弱监督算法,本文特别设计在PASCAL VOC数据集上与未添加流形正则化的弱监督语义分割算法模型进行定量对比,表3显示了添加流形正则化与未添加流形正则化算法的对比结果。如结果所示,本文算法对弱监督算法起到了提升作用,由于在弱监督模型中采用相同的推理结构,因此推断本文模型速率可以与原始模型保持一致,证明了流形正则化在弱监督图像分割中的实用性。

表3 弱监督实验对比结果Table 3 Comparison results of weakly supervised experiment
为直观展示实验结果,对弱监督图像分割实验的效果进行对比,如图7所示。从该效果对比图可以发现,本文算法对原有弱监督分割算法具有较大提升。首先,添加流形正则化的算法可以纠正一些类别误分和漏分的情况,如图7第1、2、3行。同时,分割目标的整体性更好,目标内部的信息缺失明显减少。原因可以归结为通过流形正则化算法可以加强图像内目标的几何信息,保证其本征结构不被丢失。其次,采用添加流形正则化的算法可以更好地区分图像中的前景和背景,如图7的第3、4、5行。这体现了采用流形正则化的图像分割算法可以更好地利用图像中的上下文信息。综上所述,本文算法无论对图像固有几何结构及区域信息的描述,还是对全局内信息的理解和区分均有帮助,在采用本文算法获得的分割图像中,语义一致性得到明显改善。

图7 半监督语义分割结果对比图Fig.7 Comparison diagram of semi-supervised semantic segmentation results ((a) original images; (b) ground truth; (c) backbone network; (d) ours)
3.4 与其他先进算法的对比实验
将本文算法与其他先进的弱监督语义分割模型进行对比,对比方法包括LCEM-Fixed-2-Hyb(localization clues guided expectation-maximization using fixed vision2 and hybrid)(Li等,2018)、SN_B(the network is trained by taking the rough masks as the supervision based on the single-label images from the training set.)(Wei等,2016)、DCSM(distinct class saliency maps)(Shimoda和Yanai,2016)、Build in FG/BG(built-in foreground/background)(Saleh等,2016)、SPN(superpixel pooling network)(Kwak等,2017)和DHSN_S2_AM_CRF(deep hierarchical saliency network s2 using attention map and conditional random fields)(李阳 等,2020)等,实验结果如表4所示。可以看出,结合流形正则化的半监督及弱监督图像语义分割算法的分割结果较基础模型有显著提升,并且优于其他先进模型。

表4 弱监督语义分割算法对比结果Table 4 Comparison results of weakly supervised semantic segmentation algorithms
4 结 论
本文提出了一种基于流形正则化约束的交叉一致性图像语义分割算法,通过建立输入域与输出域之间在低维流形上的对应关系,并以此为约束,使现有的网络模型可以更好地捕获数据中的上下文关系。在无需生成巨大特征矩阵并在任何推理过程中不引入额外计算量的前提下,建立了图像分割网络中像素点间的依赖关系,提高了算法的分割精度,保持了原有的推理时间。本文在交叉一致性训练模型的基础上,证明了流形正则化算法可以同时适用不同的分割任务并取得了最优性能。
在后期工作中,考虑对流形正则化算法进行改进,使其不仅在相同的空间域(同一个数据集)内进行几何约束,更要扩展到不同的空间域(不同的数据集),通过几何结构将每个数据中相同的种类约束到同一个流形中,使图像语义分割模型具有更好的泛化性,解决模型重复训练和数据集缺少的问题。
猜你喜欢
公民与法治(2022年5期)2022-07-29
怀化学院学报(2021年5期)2021-12-01
教学考试(高考物理)(2021年5期)2021-11-08
中医眼耳鼻喉杂志(2021年1期)2021-07-22
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
数学物理学报(2020年2期)2020-06-02
数学年刊A辑(中文版)(2019年3期)2019-10-08
数学物理学报(2019年1期)2019-03-21
数学年刊A辑(中文版)(2019年1期)2019-01-31
