
谱方法求解水声传播问题的优化与并行*
2022-12-22 12:06王勇献朱小谦屠厚旺颜恺壮
计算机工程与科学 2022年3期
马 现,王勇献,朱小谦,屠厚旺,李 朋,颜恺壮
(国防科技大学气象海洋学院,湖南 长沙 410073)
1 引言
近年来,水声技术被广泛应用于水下通讯[1]、海洋环境测量[2]和海底测绘[3]等各个方面。海洋中声波的传播满足基本的波动方程,但由于海洋环境的时空复杂性,声场分布易受环境的影响,导致声波在海水中的传播异常复杂[4]。波动方程是所有的声传播数学模型的理论基础,至今已发展出了多种传播模型[5],目前利用数值模型进行水声传播计算已经成为最常用的研究手段之一。
经典的水声传播计算模型包括简正波近似法、抛物方程近似法等。每一种模型均是对原始波动方程在特定条件下的近似,需求解一组微分方程。在传统水声传播数值模拟中,有限差分方法是最常用的离散方法之一。例如,Porter等人[6]在简正波近似法中使用有限差分离散的方法,开发了Kraken程序;Collins等人[7]在抛物方程近似法中使用有限差分离散的方法,扩展了针对二维宽水平传播角情况的RAM(Range dependent Acoustic Model)程序;Lee等人[8]利用有限差分法开发了三维抛物模型的FOR3D程序;石铃林等人[9]进一步对抛物方程模型和FOR3D程序的声传播规律进行了研究。尽管有限差分离散在传统水声传播计算中发挥了重要作用,但它仍然存在很多不足,如处理复杂的边值问题时不够灵活,构造高精度的差分格式困难等。
在计算流体力学、地震波传播等其它方面,谱方法由于具有精度高、收敛速度快等优点[10-12],利用其进行数值离散也得到了学者们的青睐。20世纪80年代,韦达[13-18]对谱方法的理论进行了系统研究,发现谱方法无穷阶的收敛特性;谱方法在物理方面也得到了广泛的应用,如大气环流[19]、数值涡流[20]等;近年来,一些学者尝试将谱方法引入到水声传播的数值计算中,取得了较好的效果,Tu等人[21]最近提出了一种可以解决不连续分层问题的简正波-谱方法数值模拟新手段,用于求解经典的简正波模型,可以处理声速、密度和衰减剖面不连续的问题,并开发了相应的NM-CT(Normal Mode model program based on the Chebyshev-Tau spectral method)程序,计算结果具有较高的精度。
大海域、高频声源等复杂场景中的高精度声场模拟仍然面临着计算量较大、模拟速度慢和实时性不足等问题,难以满足水下实际应用场景中声场快速分析的需求。随着高性能计算技术的迅速发展,利用高性能平台研究水声传播优化与并行算法,为解决这个问题提供了新的途径。对于简正波模型,吉虹宇[22]基于并行应用框架OpenFOAM实现了水声传播并行数值模拟;对于抛物方程模型,范培勤等人[23]实现了弱三维情况下FOR3D模型的并行计算,徐闽等人[24]在高性能平台天河二号上实现了FOR3D模型的并行计算,王鲁军等人[25]使用共享存储并行编程(OpenMP)方法在多核计算机上实现了RAM程序的并行,均取得了较好的加速效果;对于射线模型,Xiao等人[26]在高性能计算平台上,利用OpenMP对三维楔形海底的水声传播模型进行并行加速与优化;Zhu等人[27]综合利用串行优化和并行加速的方法,在天河二号高性能计算平台上对三维水声传播模型进行了优化和并行加速,同样也取得了较好的效果。
本文拟针对谱方法求解大规模水声传播问题过程中,计算速度慢、实时性差等问题,面向主流众核平台开展程序的优化与并行,加速数值模拟。
各个章节主要内容如下:第1节主要介绍谱方法求解水声传播问题的现状与存在的问题;第2节主要介绍谱方法求解水声传播问题的原理及其计算流程;第3节介绍谱方法求解水声传播问题的优化与并行方法;第4节给出了在天河二号高性能计算平台上的数值测试结果,并对优化效果进行详细分析和评估;第5节对全文的工作进行总结,展望后续研究。
2 谱方法求解水声传播问题的原理及计算流程
考虑一个关于深度z和水平距离r的二维水声传播问题,设声源角频率为ω、深度为zs,声压为p(r,z),密度为ρ,声速为c,声音传播介质(海水及海底沉积底)是水平分层的,则在声源点以外的空间,声压满足Helmholtz方程,如式(1)所示:
(1)
采用分离变量法求解该方程,则有p(r,z)=ψ(z)R(r),其中R(r)为汉克尔函数,ψ(z)满足如式(2)所示的常微分方程:
(2)
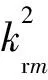
(3)
其中i为虚数单位。利用谱方法求解式(2)的基本思路是把解函数在一簇光滑的基函数上作近似展开(即谱展开),将原始物理空间中的问题转化为谱空间中求解展开系数的问题。下面以Tu等人[21]提出的Chebyshev-Tau谱方法计算简正波模型和其开发的NM-CT程序(用Fortran语言开发的开源代码,可从https://oalib-acoustics.org/Modes/index.html下载)为例,简要介绍谱方法求解水声传播模型的流程。

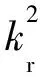
(4)
其中k表示波数。利用算子£代替式(4)左侧作用于ψ(x)的算子,则式(4)简化为式(5):

(5)
其中,对定义在[-1,1]上的任意光滑函数ψ(x)使用Chebyshev变换,即利用Chebyshev多项式Tmp(x)展开(mp表示谱方法的截断阶数)并对无穷项作有限的N阶截断近似处理,如式(6)所示:
(6)

(7)
利用Chebyshev变换将式(5)由原始的物理空间变换到谱空间,最终形成一个线性代数特征值系统,写为矩阵形式如式(8)所示:
(8)

输入:初始声速、密度、声源位置和频率等物理量。
步骤1利用Chebyshev多项式展开ψ(x),离散式(2);
步骤2求解式(8)特征值和特征函数;
步骤3利用Chebyshev变换求得矩阵L的特征解;
步骤4计算汉克尔函数R(r);
步骤5计算声压p;
步骤6计算TL。
算法包含如下3个主要的计算函数,第1个计算函数即算法第1~2行,命名为EIGsolve。EIGsolve函数主要计算式(8)矩阵L的特征值。第2个计算函数即算法第3行,命名为Genemodes。Genemodes函数主要对矩阵L的特征值和特征函数进行Chebyshev变换,得到每个简正波模态函数ψm,m=1,2,…。第3个计算函数即算法第4~6行,也是算法计算量最大的部分,命名为Syn。Syn函数主要计算声压p和传播损失TL。
谱方法与有限差分方法相比,是一种高精度的计算方法,两者的水声计算精度的对比在文献[21]中有详细分析。以文献[21]分析的存在解析解的算例1为例,与有限差分方法相比,谱方法在垂直方向离散点更少的情况下取得更高的精度,适合于对声场计算精度需求较高时的场景。下面以NM-CT程序为例,分析谱方法求解水声传播问题的优化方法和并行方案,详细描述每种优化方法的原理并对测试结果进行分析。
3 程序的优化方法与并行方案
为了使程序性能优化与并行工作更有针对性,本文利用Vtune工具测试和分析原始NM-CT串行程序,各个函数的耗时比例为:EIGsolve约2.91%,Genemodes约0.23%,Syn约54.95%,显然,程序的主要时间开销集中在Syn函数。因此,后续着重针对Syn函数进行优化与并行。首先对原始串行程序进行不同层次的优化,主要包括:编译器调整和优化、调用高性能数学库MKL、优化访存和精简计算等;其次针对高性能众核计算平台,对调优后的代码进行多线程并行加速,以充分利用多核心的计算资源。
3.1 串行优化
串行代码性能优化与并行优化同等重要,且极有可能获得大幅度的加速效果,因此首先对代码进行串行优化是非常必要的。
3.1.1 编译器优化
由于编译器首先会对代码整体进行优化,首先测试GNU 的gfortran和Intel的ifort 2种编译器对代码性能的影响。在保证正确性的基础上选用优化级别更高的编译器-O3、添加选项-ipo过程间优化和-funroll-all-loops循环展开选项对代码进行优化。
3.1.2 利用高性能数学库MKL
较大规模的矩阵乘法计算耗时比较突出,利用Intel公司开发的计算速度更快的MKL库函数GEMM来替换原始的矩阵乘计算,以提升运算速度。
3.1.3 访存优化
在代码的优化过程中,访存也是影响代码运行速度的一个重要因素,保证访存的连续性提升Cache命中率并尽可能减少内存的使用,对代码的性能有较为明显的提升。
在提升Cache命中率方面,在读取数据的过程中,按照存放顺序读取,可以保证较高的缓存命中率。以NM-CT代码计算矩阵L为例,EIGsolve函数的部分代码如下所示:
简化前的函数:
1dok=1,size(v)
2doi=1,size(v)
3doj=1,size(v)
4if((i-1+j-1)==(k-1))
5Co(k,i)=Co(k,i)+v(j)*0.5;
6if(abs(i-j)==(k-1))
7Co(k,i)=Co(k,i)+v(j)*0.5;
8enddo
9enddo
10enddo
简化后的函数:
1n=size(v);
2doi=1,n
3dok=1,n
4j=k-i+1;
5if(1 ≤j.and.j≤n)then
6Co(k,i)=Co(k,i)+v(j);
7endif
8j=i-k+1
9if(j≤n.and.j≥1)then
10Co(k,i)=Co(k,i)+v(j);
11endif
12Co(k,i)=Co(k,i)* 0.5;
13enddo
14enddo
简化前的函数为原始循环方式,代码第1、2行改进后,按照简化后的函数中第2、3行所示的方式,大大提高了Cache命中率,对程序性能的提升有较为明显的作用。
在减少内存使用方面,访存优化更直接有效的方式是减少内存的使用。通过分析可以删减部分不必要的数组,减少内存空间的使用。以NM-CT代码计算psi数组为例,计算psi数组的具体过程如下所示:
改进前的计算:
1doi=1,nmodes
2psizs(i,i)=psi(…,i)*(…)+psi(…,i)*(…);
3enddo
4psi=matmul(psi,psizs);
改进后的计算:
1doi=1,nmodes
2psi(:,i)=psi(:,i)*[psi(…,i)*(…)+
3psi(…,i)*(…)]
4enddo
改进前的计算中,对psi数组的更新仅仅是将其每一列元素乘一个相同的数,即psizs对应的元素值,因此直接将数组psi的每一列元素乘原数组,如改进后的计算。通过分析发现,改进后的计算可以少开辟一个维度nmodes×nmodes的数组,减少了内存的使用,加快了其运行速度。
3.1.4 精简计算
程序中包含有大量的计算过程,若能够有效去除冗余计算,整个程序会有较大幅度的性能提升。对NM-CT的简化计算主要是减少分支判断语句。以EIGsolve函数的计算为例,利用谱方法计算矩阵L时,部分代码如简化前的EIGsolve函数所示。三重嵌套循环最内层第4、5行赋值语句所需j索引值可以用i和k表示,从而极大地减少生成指令中的循环分支语句数目,有利于串行代码的指令级调度与优化。
3.2 并行优化
当程序中含有大量的循环和数据计算时,采用并行计算是最有效的提速方法。以NM-CT中的Syn函数计算为例,其包含有大量的循环和数据计算,因此这个函数中的代码是可以并行计算的热点代码段。
(1)OpenMP多线程并行方案设计。
在循环计算中,若各个计算之间相互独立,则采用任务并行的策略,直接利用OpenMP多线程并行,还可以直接利用collapse对两重循环进行展开,从而增大了并行度,并且可以保证线程间的负载均衡;在调度的过程中,尝试静态和动态等多种不同的调度方式,寻找最优的调度方式。以Syn函数中的计算为例,嵌套循环的并行过程如下所示:
1 !$omp parallel default(none)&
2 !$omp shared(…)private(…)
3 !$omp do collapse(2)schedule(static,…)
4doi=1,nr
5dok=1,nmodes
6bessel0=r(i)*kr(k);
7 callZBESH(…);
8bessel(k,i)=cmplx(CYR,CYI)
9enddo
10enddo
11 !$omp end do
12 !$omp end parallel
上述第3行代码,循环内的计算没有依赖关系,直接利用OpenMP多线程并行,用collapse对两重循环进行展开,并且尝试多种不同的调度方式,寻找效率最高的计算方式。
(2)利用多线程高性能计算库MKL。
与OpenMP多线程相适应,通过调用多线程版本的高性能计算库MKL,可实现矩阵相乘GEMM函数的多线程加速,进一步提升计算速度。
4 实验与结果分析
4.1 高性能平台简介
为了检验本文所用的优化方法的效果,在高性能平台天河二号上进行了测试。天河二号高性能计算平台的CPU 为Intel(R)Xeon(R)CPU E5-2692,每个结点包含2个CPU,每个CPU包含12个核。在测试过程中,采用gcc/6.3.0版本和Intel-compilers/mkl-15 2种编译器进行测试。在实际测试过程中,对于每一次优化都进行5次测试,将时间最短的测试时间作为最优时间。
4.2 算例
谱方法求解水声传播模型能够对多种复杂的算例和模型进行数值模拟。选取具有代表性的Munk波导算例进行测试(本文所有图表的彩色版本可从https://gitee.com/maxian-nudt/nm-ct_-parallel/issues下载)。
Munk剖面是一个理想化的声速剖面,它可以刻画深海声场传播的规律与特征,声源位于1 000 m处,频率为50 Hz,水层密度为1.0 g/cm3,沉积层密度为1.5 g/cm3,水层衰减系数为0,沉积层衰减系数为0.01,水层深度为2 500 m,沉积层深度为5 000 m。Munk波导的声速值为c(z)=1500.0[1.0+其中,图1a展示了利用谱方法画出的传播损失场。图1b展示了海深1 000 m处利用不同方法计算的TL值,此算例不存在解析解,因此用传统有限差分方法的程序代码Kraken的计算结果作为参考解。从图1中可以看出,截断阶数N值越大,计算结果越精确。考虑实际复杂海洋环境对计算精度的要求以及算法整体计算量的大小,选择N=1 000进行计算和后续的测试分析。
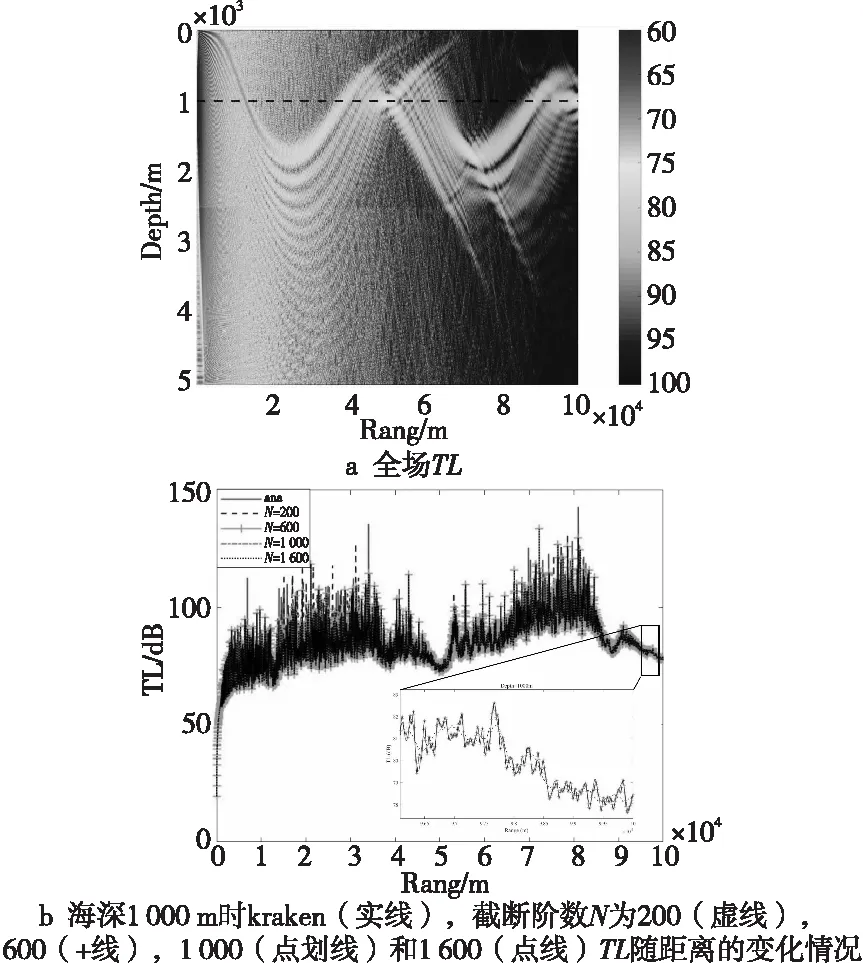
Figure 1 TL schematic diagram of Munk
4.3 串行优化结果与分析
4.3.1 编译器和编译选项优化
表1为原始串行程序在天河二号高性能平台上不同编译器和编译选项的测试结果:选用Intel编译器并增加合适的编译选项可使性能进一步提升。以gfortran编译器下的-O2选项为基准,通过更换编译器及编译选项优化,最终获得了1.67倍的加速效果。
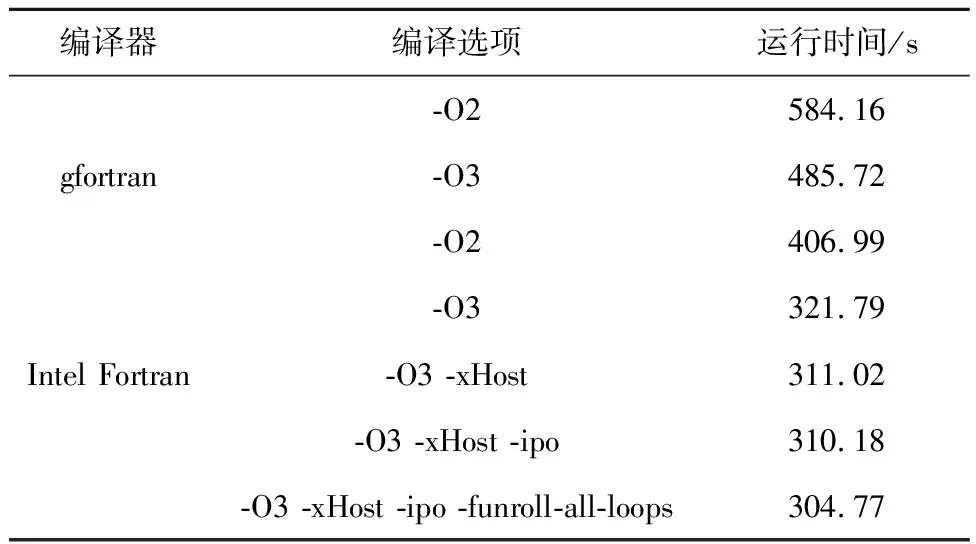
Table 1 Effects of different compilers and compilation options on running time of serial programs
4.3.2 利用高性能数学库MKL
测试计算声压大规模矩阵乘法代码段在使用MKL库前后的运行时间,时间由201.2 s减少至56.83 s,使用MKL库后运行时间缩短144.37 s,提速3.54倍。
4.3.3 访存优化
在提升Cache命中率方面,对程序进行访存优化,首先对计算矩阵L的两重嵌套循环交换循环嵌套的顺序,使访存满足空间的连续性,该代码段优化后运行时间由3.03 s减少至2.79 s。
在减少内存使用方面,通过分析具体计算过程,省略psizs数组,将运算简化,该代码段运行时间由0.58 s减少至0.003 s。
根据访存连续性的原理,对整个程序的嵌套循环和数组进行检查,最大限度地保证访存的连续性,优化后进行测试,运行时间由304.77 s减少至288.13 s,运行时间减少了16 s,加速了1.05倍。访存优化不仅提升了程序性能,且精简了代码,有利于后续对代码的维护。
4.3.4 精简计算
对计算矩阵L的部分代码减少分支判断语句后,计算量大大下降,测试优化前后每次调用此函数所需要的时间由3.03 s减少至0.02 s。由于调用矩阵L次数较多,测试简化运算后对整个程序性能的影响。测试结果表明,程序运行时间由304.77 s减少至242.19 s,对代码进行简化后,程序运行时间减少了62 s,加速了1.26倍。
图2主要展示了串行优化前后3个主要函数的运行时间变化。串行优化效果最为明显的是Syn函数,Syn函数利用了MKL替换原始矩阵乘计算、访存优化和精简计算3种方法。优化后Syn函数运行时间由320.91 s减少至80.43 s,加速比达到3.26,串行加速方法的有效性得到了证实。

Figure 2 Time changes of the three main functions and the total time before and after serial optimization
4.4 并行优化
并行加速效果遵循Amdahl加速比定律[27],据此可提前预判最优的并行效果。在众核平台上,若可以使用的最大线程数为nt,程序代码中可并行部分的执行时间所占百分比为q,则理想加速比S=1/(1-q+q/nt)。
本文对3.2节的并行方法进行了测试。首先对热点Syn函数内部的3个主要步骤(计算R(r)、计算声压、计算TL)进行多线程并行,测试不同线程数目下的运行时间,结果如表2所示。

Table 2 Program running time under different thread numbers
通过多线程并行加速后程序的总运行时间由串行最优版本的93.94 s减少为24.38 s,热点函数Syn的运行时间由原来的80.43 s减少至9.84 s。当线程数为24时,整个程序的理想加速比S=5.68,实际并行后的绝对加速比为3.85,未达到理想值。究其原因,可能是由于串行程序中部分可并行的代码之间夹杂部分不可并行的计算,需要多次进行开关线程的操作,导致程序运行时间增加,对程序的优化效果产生不良影响。
图3显示了Syn函数中3个子计算步骤的加速比情况。由于各网格点之间的计算没有依赖,因此多线程并行计算具有良好的加速效果。随着线程数的增加,加速比基本呈线性增长。当使用24个线程时,计算R(r)的代码段加速比可达17.59。图3中虚线表示对应线程数目下的最优加速比。
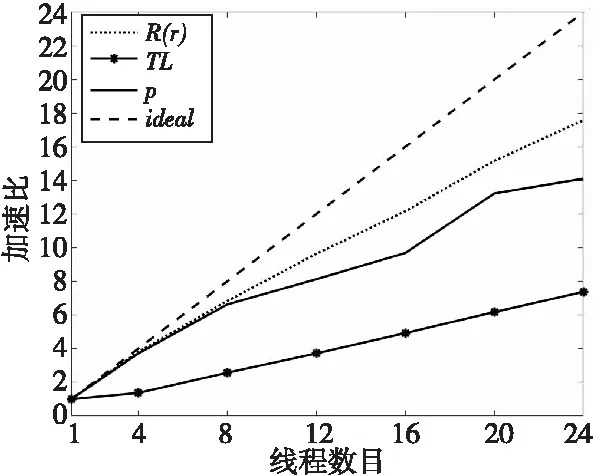
Figure 3 Speedup of R(r),TL, and p under different thread numbers, and the optimal speedup under the corresponding number of threads
此外,为了进一步测试多线程并行的任务调度对性能的影响,对Syn函数中的计算TL步骤进行了测试,图4展示了使用动态调度以及不同粒度参数下的静态调度时代码的执行时间。结果表明静态调度随着块中的迭代次数chunksize值的增加,耗时逐渐减少,当chunksize值达到1 024时,该代码段的耗时达到最低。
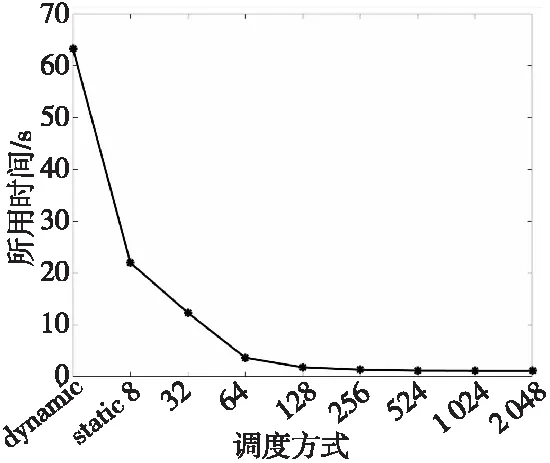
Figure 4 Different scheduling methods to calculate the time change of TL under 24 threads
4.5 优化前后结果对比
对程序进行串行和并行优化后,需要对程序改进前后的计算结果进行对比分析,比较计算结果精确度的变化,取声源深度1 000 m的计算结果进行比较,如图5所示。
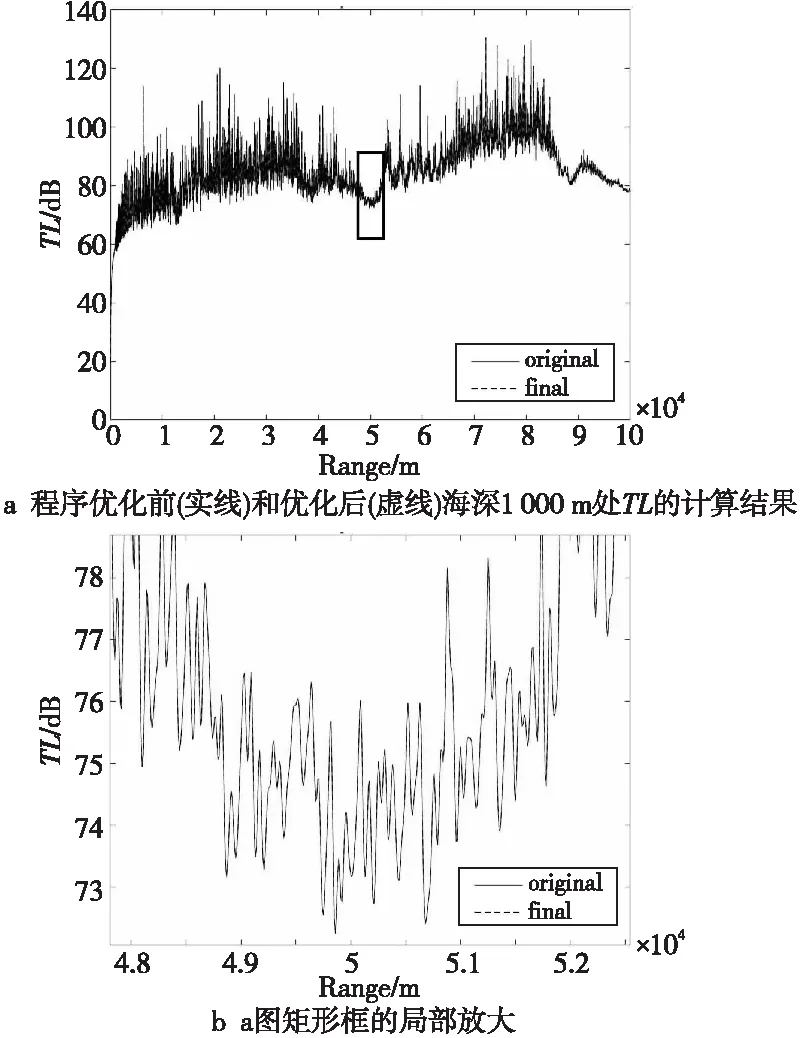
Figure 5 Comparison of calculation results before and after optimization
根据图5优化前后的计算结果,可以看出2条曲线基本重合,程序改进前后计算结果非常接近,表明此次优化没有改变程序计算结果的精度。
4.6 实验结果分析
综上所述,通过综合使用串行优化和多线程并行加速技术,分层海洋声传播Chebyshev-Tau谱方法程序NM-CT的性能得到了提升,计算效率大幅提升。以gfortran编译器作为基准版本,程序原始版本的运行时间为584 s,优化与并行的各阶段的加速效果如表3所示。

Table 3 Changes in program performance under different optimization techniques
通过结果对比发现,首先选择合适的编译器对程序性能的提升有较大的作用,对于NM-CT程序,在天河二号的平台上 Intel 的 ifort 编译器对提升此程序的性能作用更加显著。此外,加入合适的附加编译选项、使用高性能MKL 函数库、优化访存和合理简化计算等串行优化方法,在单结点单线程下,充分利用了资源,取得了较好的加速效率。利用并行加速方法,并在此基础上研究不同调度策略以及chunksize大小对程序的影响,发挥众核潜能,进一步提升了程序的运行速度。针对天河二号单结点,本文提出的关于 NM-CT 程序的一系列优化和并行加速方法非常有效,程序运行时间从原始的584 s减少到最佳优化版本的24 s,加速了23.98倍,优化效果明显,极大地提升了程序的性能,对解决计算大范围海域声传播实时性问题做出了重要的贡献。
5 结束语
为解决谱方法数值求解水声传播问题计算量大、实时性差等问题,本文充分利用高性能计算平台对谱方法求解水声程序进行性能优化与并行加速,首先从选择合适的编译器和优化选项、调用高性能数学库MKL函数、访存优化和精简计算4个方面对串行程序内部进行优化;接下来在天河二号众核平台上对程序进行更细粒度、更轻量级的多线程并行,在此基础上研究不同调度策略和chunksize大小对程序性能的影响。以NM-CT程序为例测试优化与并行手段的加速效果,结果表明,本文所使用的优化与并行方法,对于加速谱方法数值求解水声传播问题有非常明显的加速效果,计算深海波导程序运行时间由原始串行版本的584 s减少到24 s,加速了23.98倍,显著提高了程序的运行效率。进一步分析程序,若截断阶数更高,导致EIGsolve函数耗时较长,因此在下一步的工作中,需要进一步对程序在截断阶数更高的情况下进行优化。尽管对于实际的大范围海域声场计算仍没有达到实时处理的要求,但本文的工作为达成这一目标迈进了一大步。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
舰船科学技术(2022年20期)2022-11-28
计算机研究与发展(2021年3期)2021-04-01
计算机与网络(2019年9期)2019-10-21
电子制作(2017年19期)2017-02-02
电子制作(2017年19期)2017-02-02
山东工业技术(2016年15期)2016-12-01
扬子江(2016年1期)2016-05-19
汽车维护与修理(2015年1期)2015-02-28
汽车零部件(2014年8期)2014-12-28
