
基于评分离散度的托攻击检测算法*
2022-12-23 09:52贾俊杰段超强
计算机工程与科学 2022年3期
贾俊杰,段超强
(西北师范大学计算机科学与工程学院,甘肃 兰州 730070)
1 引言
目前,推荐系统大量应用于电商、社交媒体、电影推荐和外卖等互联网服务中。推荐系统通过收集、分析用户信息,向用户推荐可能感兴趣的信息,以满足用户个性化的服务需求。现代推荐系统通常采用基于协同过滤CF(Collaborative Filtering)[1]的推荐算法,协同过滤基于与用户相似的用户的偏好,通过用户的历史行为寻找与目标用户相似的用户组成最近邻,最近邻对目标项目的偏好即为用户的偏好[2,3]。这种算法在实际应用中具有良好的推荐效果,但容易受到托攻击(Shilling Attack)[4]。托攻击是指利用获取的用户历史评分构造攻击概貌,与目标用户形成最近邻来影响推荐效果。检测托攻击是当前推荐系统安全的研究热点之一。
检测托攻击本质上是对真实用户和攻击概貌进行分类[5]。对真实用户和攻击概貌分类需要寻找分类特征作为依据,即真实用户和攻击概貌评分在某个指标上具有明显的差别,可以通过这个差别将二者区分开来。目前已有一系列关于用户评分的特征指标,但单个特征指标无法有效地对各种攻击方式的托攻击进行检测,同时特征指标的选取角度不同会加大数据的处理难度。
基于上述问题,本文提出基于用户评分离散度的托攻击检测Dispersion-C算法。从用户评分离散度出发,提取用户评分极端评分比PER(Proportion of Extreme Ratings)、去极端评分方差RESV(Remove Extreme Score Variance)和用户评分标准差SD(Standard Deviation)3个特征,作为真实用户和攻击概貌的分类特征;然后将3个特征作为监督学习分类算法—ID3(Iterative Dichotomiser 3)决策树算法的分类特征,训练各自的分类器,对托攻击用户进行检测。实验结果表明,本文算法对托攻击用户具有良好的检测效果,鲁棒性较强。
2 相关技术
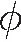
2.1 托攻击模型
目前流行的攻击模型主要有随机攻击(Random Attack)、均值攻击(Average Attack)、流行攻击(Bandwagon Attack)和段攻击(Segment Attack)等[5],4种攻击模型的攻击概貌组成如表1所示。

Table 1 Four common attack models
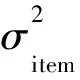
2.2 检测技术
现有的托攻击检测技术主要分为基于监督学习的检测技术、基于半监督学习的检测技术和无监督学习的检测技术。
为了对托攻击概貌和真实用户概貌进行分类,学者们提出了很多方法。Rashid等人[8]提出了多种可能有效分析各种托攻击模式攻击概貌的特征,包括预测偏差数量、用户评分的标准偏差、与其他用户的评分偏移度和最近邻平均偏移度。Chirita等人[9]利用平均评分偏移度结合Degsim特征,提出了一种新的检测算法。该算法可以成功检测随机攻击、均值攻击和流行攻击概貌,但无法有效检测段攻击概貌。Bruke等人[10,11]在此基础上提出了加权平均评分偏离度和加权评分偏离度,并提出了一些真实评分特征,但该算法受攻击概貌填充率影响,对于较低填充率的段攻击概貌识别效率不高。
(1)基于监督学习的检测技术。
将上述用户评分特征与KNN(K-Nearest Neighbor)、SVM(Support Vector Machine)等监督学习算法相结合称之为基于监督学习的检测算法。Bryan等人[12]利用方差校正均方残差Hv-score发现攻击概貌,攻击概貌具有更大的Hv-score值,但极易受到攻击概貌填充率影响,在填充率低时,检测效果不佳。李文涛等人[13]从用户选择评分项入手,根据用户已评分项目流行度的不同,提出了一种基于用户评分流行度的区分真实用户和攻击概貌的方法,但由于流行攻击和段攻击存在选择项,该方法对段攻击的检测效率不高。基于监督学习的检测技术的关键在于拟合出合适的训练集和测试集来构造分类器。
(2)基于无监督学习的检测技术。
由于基于监督学习的检测技术过多依赖于特征和测试集,因此研究者转向利用无监督学习构建分类器。Metha等人[14,15]利用PCA(Principal Component Analysis)算法在检测算法中的思想,无需任何先验知识,提出根据托攻击概貌之间的相似性高于真实用户这一特点对攻击概貌进行检测的PCA VarSelect技术,是一种无监督的托攻击检测算法,但这种算法必须提前知道攻击强度,否则检测准确率会严重降低,而现实中攻击强度一般是无法获取的。李聪等人[16]提出了LFAMR模型,该模型以用户非随机缺失数据为依托,对导致评分缺失的潜在因素进行解析,利用聚类发现攻击概貌,但这种模型无法有效探测低攻击强度攻击。
(3)基于半监督学习的检测算法。
在大多数的推荐系统中,未标记的用户数量远远大于标记用户数量,因此同时对标记用户和未标记用户概貌进行建模有助于提高托攻击检测效率。Cao等人[17,18]提出Semi-SAD算法,该算法充分利用了标记和未标记的用户概貌,结合朴素贝叶斯和EM-λ算法,首先在标记用户概貌上训练一个朴素贝叶斯分类器,然后利用期望最大化算法和未标记的用户概貌对初始贝叶斯算法进行改进,提高攻击概貌的检测效率。但是,该算法对低强度的攻击检测效率不好,且EM迭代过程时间较长,需要极大的时间代价。
从已有的检测技术可以看出,检测托攻击概貌的关键在于特征选择,本文根据不同攻击模型和用户评分在离散度上的差异,从托攻击概貌和真实用户概貌的评分离散度选择特征,将这些特征作为决策树算法的分类特征。最后,通过实验说明了基于用户评分离散度的托攻击检测算法的可行性和优越性。
3 基于用户评分离散度的托攻击检测算法
3.1 基于用户评分离散度的特征选择
本文通过对美国Minnesota大学GroupLens项目组收集的MovieLens数据集[19]进行分析,发现用户评分存在一个显著的特点:用户对于电影项目的评分多是由用户对于电影的喜爱程度和电影的质量高低决定的,评分是随机的、个性化的。同时评分项目越多的用户,不同评分次数分布更接近,也就是说真实用户评分的离散度是在一定范围内随机分布的。托攻击用户概貌可采取一定的模型进行部署,攻击者根据其拥有的背景知识和想要达到的攻击效果采取不同的攻击模型,不同的攻击模型具有不同的评分生成方式,且评分生成满足一定的条件,因此托攻击概貌评分的频数分布是不均衡的,攻击概貌的评分离散度接近且和真实用户存在差异。本文从这个角度出发,以用户评分离散度区分真实用户和攻击概貌,提出了基于用户评分离散度的PER、RESV和SD3个分类特征,接下来通过不同攻击模型对分类特征进行说明。
3.1.1 随机攻击和均值攻击概貌
从攻击模型中可以看出,攻击概貌与真实用户在评分分布上存在一定的差异。其中随机攻击和均值攻击不具有选择项,且评分为随机生成,这2类模型可以一起讨论。随机攻击的填充项评分服从系统评分的正态分布。均值攻击的任一填充项评分的生成服从项目自身评分的正态分布。在生成这2种攻击方式的过程中发现,随机攻击和均值攻击的项目评分出现极端评分的概率极低,而真实用户中极端评分是常有的。
基于这种情况,Yang等人[20]提出了用户最高评分填充比来对此进行描述,但仅以最高评分区分真实用户和攻击概貌效果不佳,极易将真实用户划分为攻击概貌,影响推荐效果。因此,本文在此基础上提出极端评分比作为检测攻击概貌的特征之一。
定义1(极端评分比PER)PER描述用户评分中评分最大值和最小值的项目数占用户评分所有项目数的比值。用户u的极端评分比如式(1)所示:
(1)
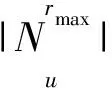
图1和图2所示为随机攻击和均值攻击概貌极端评分比与真实用户的对比情况。2种攻击模型由于不具有选择项且填充项的评分满足一定条件,出现极端评分的概率明显小于真实用户,且由于2种攻击方式接近,极端评分比的分布方式也相似。通过图1和图2可以发现,利用极端评分比可以有效区分真实用户和攻击概貌。
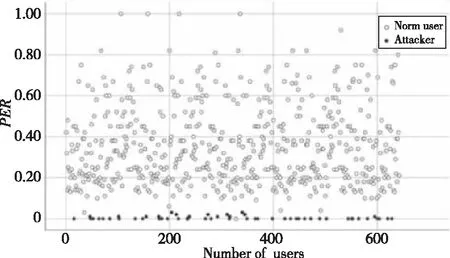
Figure 1 Comparison of PER between random attackers and normal users
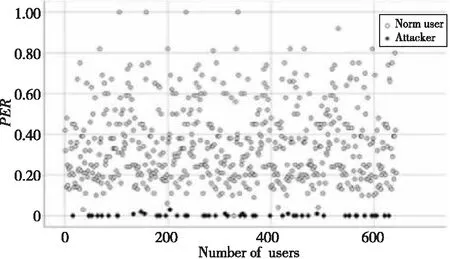
Figure 2 Comparison of PER between average attackers and normal users
3.1.2 流行攻击概貌
流行攻击选择当前系统中最流行的项目作为选择项,其评分为系统最高评分,选择项与随机攻击相同。由于流行攻击具有评分为系统最高分的选择项,故流行攻击中极端评分比根据其选择项的规模发生变化。图3所示为不同填充率下流行攻击中的极端评分比和真实用户的对比,流行攻击的极端评分比随攻击概貌的填充率发生变化且和真实用户的极端评分比相似。因此,使用极端评分比作为特征无法有效区分流行攻击概貌和真实用户,但流行攻击的概貌特征与真实用户在评分离散度检测下仍存在可区分的特征。下面对流行攻击概貌进行讨论。
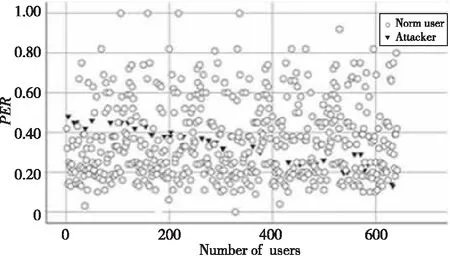
Figure 3 Comparison of PER between bandwagon attackers and normal users
流行攻击属于推攻击,可以看作是随机攻击的一种扩展。这种攻击方式具有的选择项为当前系统中流行度最高的几个项目,且评分均为系统最高评分,其填充项和随机攻击填充项的部署方式相同。因此,流行攻击概貌的评分分布存在一个有趣的现象,即去除极端评分后,剩余的评分分布与随机攻击相同。而对于真实用户在去除极端评分后,用户评分的离散度会降低。因此,本文定义去极端评分方差对流行攻击概貌和真实用户进行区分。
定义2(去极端评分方差RESV)RESV描述用户去除极端评分后其余评分的方差。用户u的去极端评分方差定义如式(2)所示:
(2)
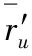
如图4所示,在去除极端评分后,流行攻击用户概貌的评分方差为用户整体评分的均值和方差。而真实用户去除极端评分值后,评分方差降低。因此,通过图4可以确定,利用去极端评分方差可以有效地区分真实用户和流行攻击概貌。
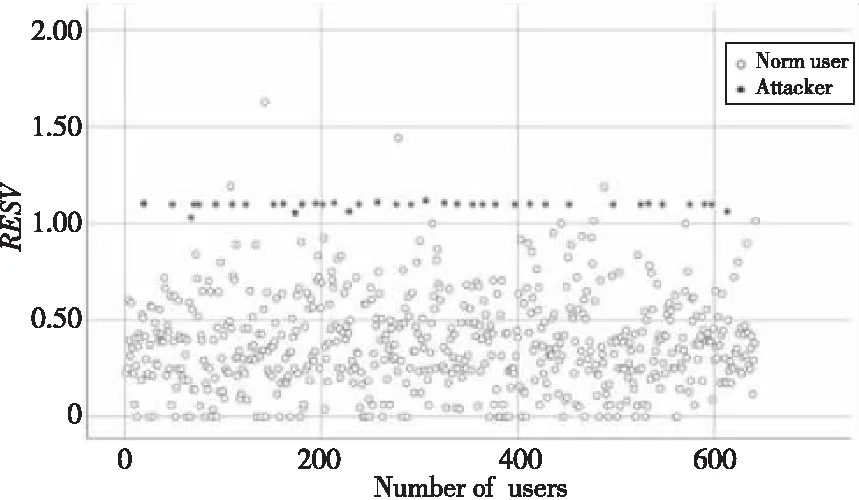
Figure 4 Comparison of RESV between bandwagon attackers and normal users
3.1.3 段攻击概貌
段攻击同样属于推攻击,具有选择项。但是,段攻击概貌和流行攻击概貌的区别在于,段攻击选择项为与目标用户类别相似的项目,评分均为系统最高评分。填充项与流行攻击的不同之处在于,段攻击的填充项为系统随机选择,但填充项目的评分均为系统最低分。这是由于段攻击是只针对目标项目具有潜在兴趣的一组用户群,而不影响推荐系统整体,因此利用去极端评分方差无法检测段攻击概貌。
段攻击概貌中选择项为系统最高分而填充项为系统最低分,但真实用户评分中用户根据对项目的喜爱程度进行评分。真实用户的评分是随机且波动较为平稳的,2类用户在整体评分离散度上存在较大差异,因此本文引入用户评分标准差作为检测段攻击的评分特征。
定义3(用户评分标准差SD)SD指的是用户对各个项目评分与评分均值的离差平方的算数平均数的平方根,如式(3)所示:
(3)
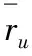
由图5可见,真实用户评分的离散度明显小于段攻击概貌的,因此SD可以区分真实用户的段攻击概貌。

Figure 5 Comparison of SD between segment attackers and normal users
3.2 基于用户评分离散度的托攻击检测算法
根据上面的讨论,托攻击概貌和真实用户概貌在评分离散度上存在差异,本文用极端评分比PER、去极端评分方差RESV和用户评分标准差SD3个特征对用户评分离散度进行描述。利用这些特征差异对攻击概貌和真实用户进行分类。
以上3个特征中,PER是一个适合对不具有选择项的随机攻击和均值攻击进行检测的分类特征,对真实用户和攻击概貌中的极端评分比进行统计可以看出,随机攻击和均值攻击的PER均低于正常用户的。RESV是针对流行攻击提出的分类特征,在去除极端评分比之后,流行攻击概貌的评分方差大于真实用户的评分方差。SD是专门针对段攻击的分类特征,由于段攻击由特殊的攻击概貌构成,其用户评分均方差大于真实用户的。为了从用户离散度上对攻击用户进行检测,将PER、RESV和SD3个特征作为相应攻击模型的分类特征,使用ID3决策树算法训练分类器。
决策树算法是一个以实例为基础的归纳学习算法[21],从一个无次序、无规则的实例集合中归纳出一组采用树形结构表示的分类规则。ID3决策树算法是对决策树算法的一种改进算法。本文将标记的数据集作为训练集,将ID3决策树算法作为分类算法。ID3决策树算法根据信息增益率选择测试属性,通过属性离散化的方式对连续属性进行处理。本文中系统标记的虚假用户和真实用户样本集D={x1,x2,…,xn},每个样本xi的属性向量P=(a1,a2,…,am),其中m=3,ai包括PER,RESV,SD3个特征值。类别属性C={C1,C2,…,Ck},其中k=2,根据属性特征值可以将样本划分为C1和C22个子集,代表真实用户和攻击概貌。步骤如下所示:
步骤1计算每个样本的RESV、PER和SD3个属性,得到用户评分属性特征向量。
步骤2计算待分类数据样本在每个属性A=ai时的信息增益度h(D,A)=Gain(D,A)/Entropy(D),i=1,2,3,选择信息增益度最大的属性作为根节点,其中Entropy(D)是当前样本的信息熵,Gain(D,A)为属性在当前样本下的分类信息增益,其计算公式如式(4)所示:
Gain(D,A)=Entropy(D)-
∑v∈V(A)Entropy(Dv)
(4)
其中,D为当前待分的数据样本集,Dv是样本集D中属性A的值等于v的样本集合,V(A)是属性A的值域。
步骤3对于根节点属性的每个可能值vi和相应的数据点集合Dv,递归步骤2选择子树根节点建立子树,直至某个分支下只有一个类标签的样本子集为止。
本文算法流程如算法1所示:
算法1基于评分离散度的托攻击检测算法
输入:含有攻击用户的用户评分数据集S,用户集合U,项目集I,决策树算法分类数K=2。
输出:分类结果。
BEGIN
步骤1foru∈U
步骤2fori∈I
步骤3计算特征向量P=(a1,a2,a3)/*用户特征向量由SD,PER,RESV组成*/
步骤4endfor
步骤5endfor
步骤6foru∈U
步骤7计算用户特征向量集合;
步骤8fori≤3
步骤9A=ai;
步骤10计算属性A的分类信息增益度:
步骤11Gain(D,A)=Entropy(D)-∑v∈V(A)Entropy(Dv);
步骤12计算信息增益度:
步骤13MAE(ai)=root;
步骤14endfor
步骤15endfor
END
4 实验与结果分析
4.1 实验数据集与实验指标
本文使用MovieLens数据集[19]进行实验,包括943个用户对1 682个项目的评分数据,并且每个用户至少对20部电影进行评分,评分取值为[1,5]。实验假定系统中原有的用户为真实用户,利用托攻击的模型向系统中注入的用户为攻击概貌,实验的目的是在不删除虚假用户的情况下,对目标用户进行分类。
托攻击常用准确率fp和召回率fr的综合指标F值[13]作为监测指标,设N为分类器预测出的虚假用户数量,Na为分类器正确分类出的虚假用户数,Nt为系统中实际存在的虚假用户数。为了适应本文算法,重新定义N为ID3决策树算法中虚假用户集C1中用户的数量,Na为C1中虚假用户数,Nt为系统中实际存在的虚假用户数。则准确率fp、召回率fr及综合指标F值的计算公式分别如式(5)~式(7)所示:
fp=Na/N
(5)
fr=Na/Nt
(6)
F=2fpfr/(fp+fr)
(7)
4.2 实验与讨论
为了说明实验的效果,本文进行了2组实验。首先在注入不同的攻击概貌之后,验证Dispersion-C算法的准确率fp和召回率fr;其次利用fp和fr的综合指标值,在10%的攻击强度下,将本文算法与文献[13,16,22]的托攻击检测算法进行对比验证。
4.2.1 算法的检测效果分析
为了说明实验效果,在不同的实验参数下对本文Dispersion-C算法的效果进行测试。实验的参数包括:装填规模和攻击规模。其中,攻击强度取5%,7%,10%和12%,填充率取3%,8%,10%,12%,15%和20%,攻击模型为随机攻击、均值攻击、流行攻击和段攻击。将2个参数进行相互组合,每一种组合对应一个实验设置,其中选择75%的数据样本组成训练集,25%的数据样本组成测试集,然后计算算法的准确率和召回率,并在重复进行100次实验后,统计得到最终的结果。
表2~表5是Dispersion-C算法在不同装填规模和攻击规模下的分类效果,从中可以发现,对于不同填充率和攻击强度的流行攻击和均值攻击,Dispersion-C算法均有较好的检测效果,并且随着填充率和攻击强度的增大检测效果逐渐提高,算法鲁棒性较好。对于具有选择项的流行攻击和段攻击,Dispersion-C算法的检测效果同样优势明显,特别是针对段攻击的检测。实验中算法存在召回率大于准确率的现象,说明本文算法检测严格,出现了将真实用户划分为攻击概貌的现象。
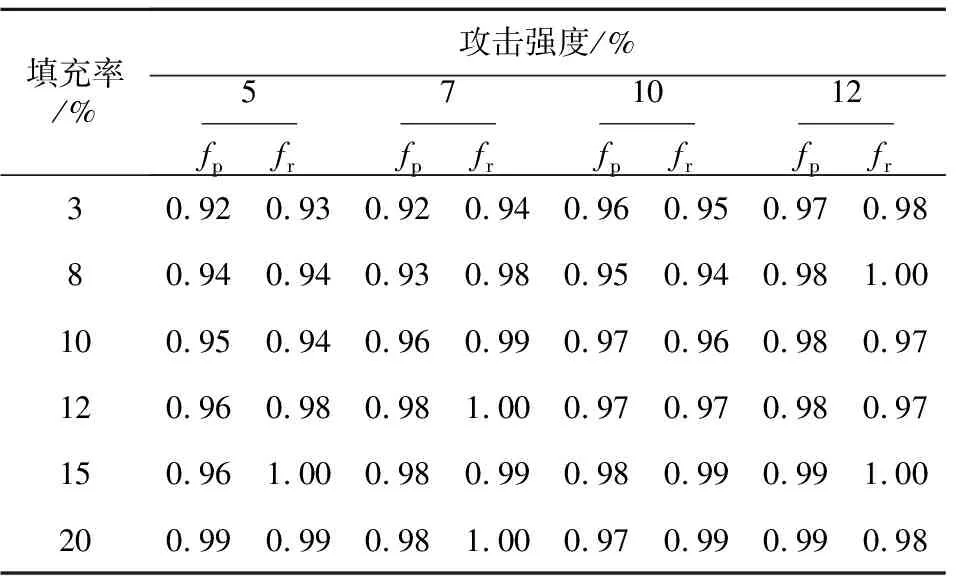
Table 2 Detection precision and recall of random attack detected by Dispersion-C algorithm
4.2.2 Dispersion-C算法与其他算法对比
为了对本文提出的 Dispersion-C算法的检测效果进行更加全面的分析,将本文算法与文献[13]提出的基于用户评分流行度分类特征的监督学习的DegreeSAD算法、文献[22]提出的利用特征指标进行托攻击检测的半监督学习的检测算法SEDSA-CI和文献[16]提出的无监督学习的检测算法LFAMR一起进行讨论。在相同配置的情况下,且攻击强度均为10%时,将4种算法的检测效果利用式(7)进行比较。实验结果如图6所示。
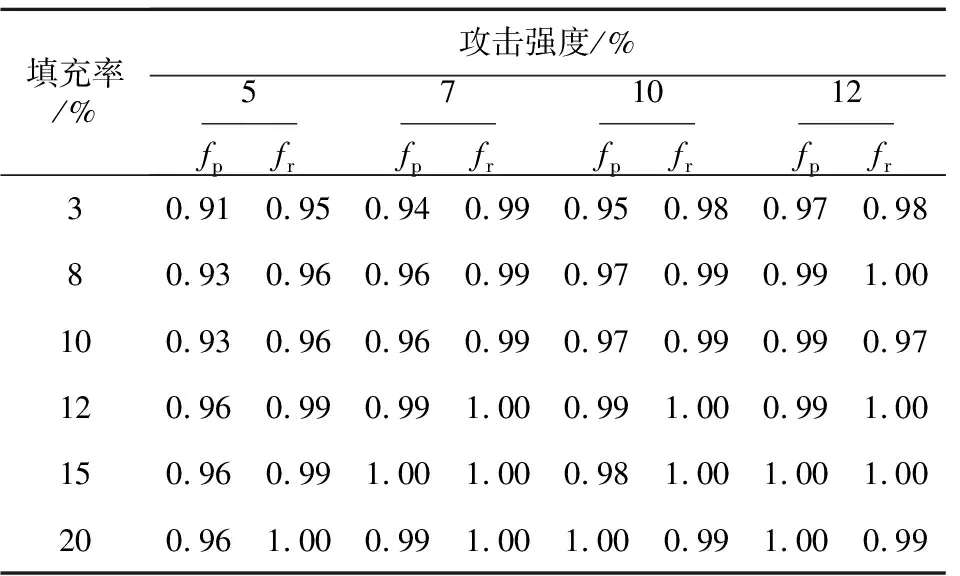
Table 3 Detection precision and recall of average attack detected by Dispersion-C algorithm
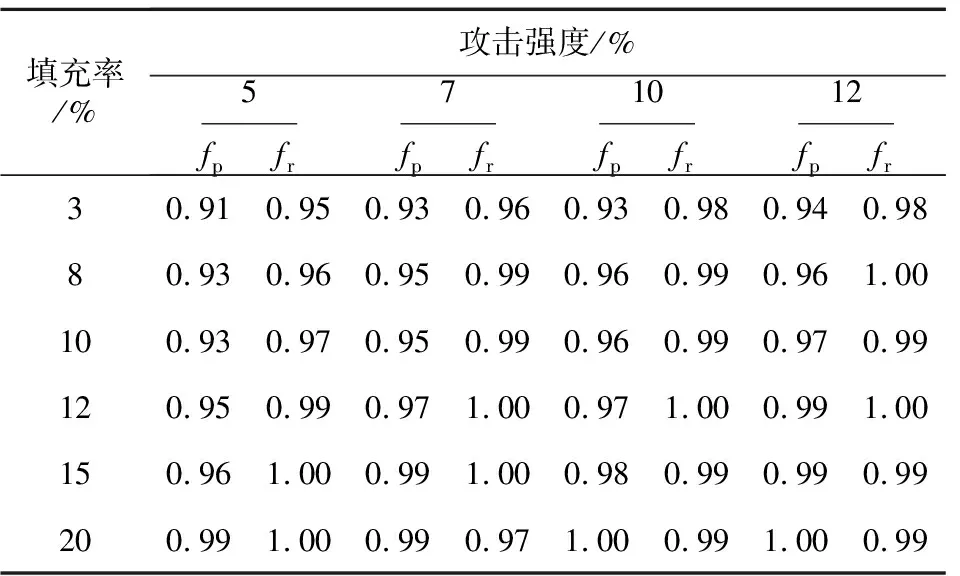
Table 4 Detection precision and recall of bandwagon attack detected by Dispersion-C algorithm

Table 5 Detection precision and recall of segment attack detected by Dispersion-C algorithm
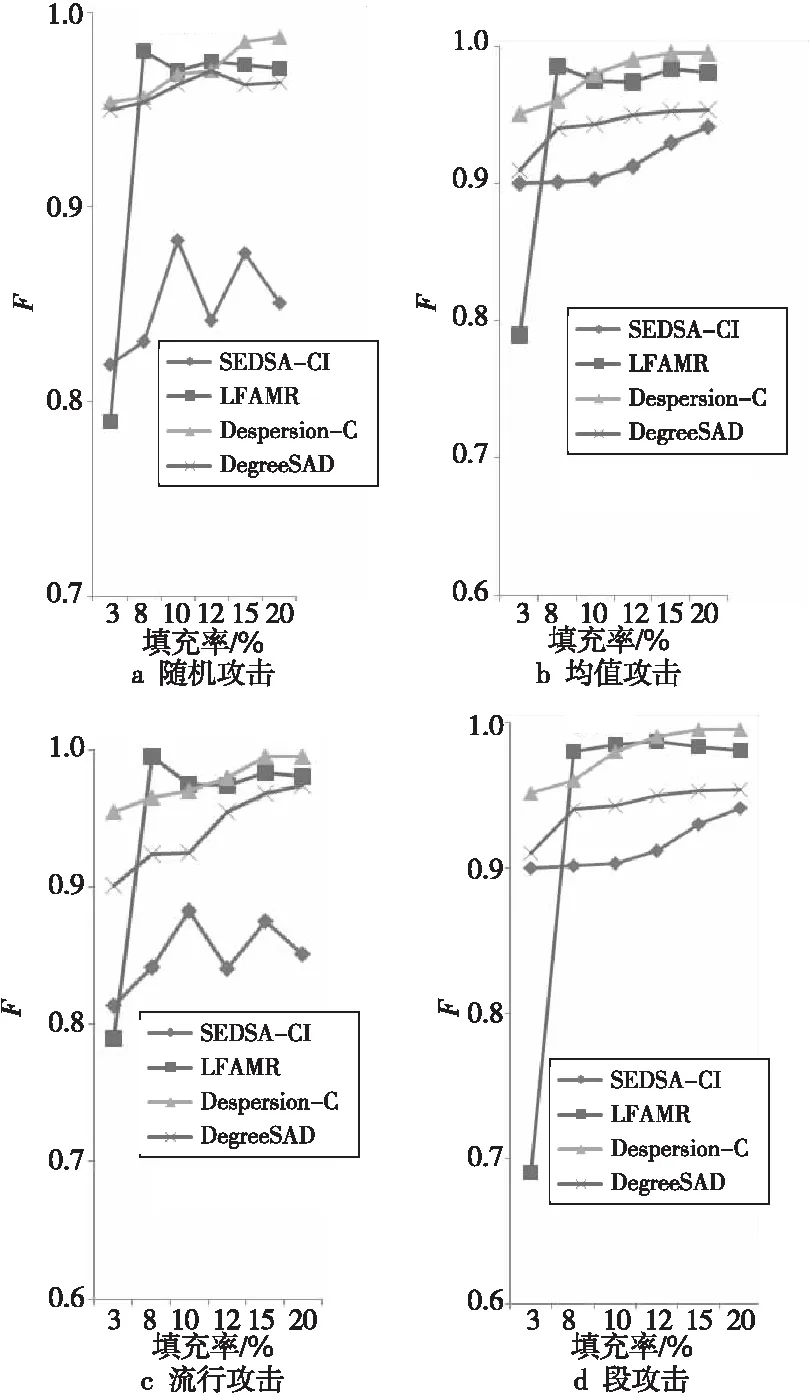
Figure 6 Comparison of detection effects between Dispersion-C and other algorithms
图6展示了4种算法对于不同攻击模型的检测效果。Dispersion-C算法根据用户评分离散度选取分类特征,不易受到项目填充率的影响,因此对于较低项目填充率的攻击概貌检测效果较好,但因攻击概貌始终存在接近真实用户评分分布的可能性,因此很难达到完美的检测效果。
与同为有监督学习的基于流行度分类特征的算法DegreeSAD相比,Dispersion-C算法针对4种攻击模型具有较优的检测效果。由于DegreeSAD算法从用户选择评分项目的方式入手,因此对于存在选择项的流行攻击和段攻击,在填充率低于10%时,检测效果不太理想,并且随着填充率的增加,对于随机攻击的检测存在F值下降的现象,说明DegreeSAD算法的检测不稳定。对于半监督学习SEDSA-CI算法,由于其使用K-means算法对标记用户进行分类,算法易受到聚类中心选择的影响,导致检测效果不稳定,且检测效果较差。无监督学习算法LFAMR从用户评分的缺失项目潜在因素构建分类特征,在填充率较低时目标项和选择项的数目相差不大,算法对各类攻击的检测能力均较差。
根据以上实验对比,基于用户评分离散度的托攻击检测算法与传统的有监督学习的托攻击检测算法相比具有较好的检测效果;同时与半监督学习和无监督学习算法相比,不受填充率的影响,且具有较好的鲁棒性。
5 结束语
托攻击的检测通常面临鲁棒性问题,针对这一问题,本文对真实用户和攻击概貌的评分分布情况进行分析,发现真实用户和攻击概貌在评分频数分布上是不同的。引入评分离散度作为衡量标准,将评分离散度的描述特征PER、RESV和SD作为检测攻击概貌的分类特征。选择信息增益最大的特征作为ID3决策树的分类属性,对真实用户和攻击概貌进行分类,实现托攻击的检测。实验结果表明,本文算法在不同的填充率和攻击强度下,对攻击概貌均有较好的检测效果,同时算法具有良好的鲁棒性。本文算法主要针对单一推荐系统的托攻击检测,而目前分布式协同过滤算法越来越流行,下一步工作将对分布式协同过滤算法中的托攻击检测算法进行研究。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
昆明医科大学学报(2022年3期)2022-04-19
昆明医科大学学报(2022年2期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
小学生优秀作文(低年级)(2020年5期)2020-07-25
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
