
基于多源遥感数据的居延泽地区土壤盐分估算模型
2023-01-05 03:55杨丽萍李凯旋
农业机械学报 2022年11期
杨丽萍 任 杰 王 宇 张 静 王 彤 李凯旋
(长安大学地质工程与测绘学院,西安 710054)
0 引言
土壤盐渍化(Soil salinization)是破坏土地资源、严重威胁生态系统安全与稳定的全球性问题[1]。中国西部地区盐渍土面积占全国盐渍化土地总面积的69.03%[2],土壤盐渍化问题突出。黑河流域的盐渍化问题在中国西部干旱区具有典型性和代表性,其下游的额济纳盆地尤为严重,快速准确地获取大范围的土壤盐分信息对盐渍化监测与防治具有重要意义。
遥感技术具有数据获取速度快、覆盖范围广、成本低等特点,已被广泛用于土壤盐渍化监测研究。基于光谱波段或植被指数等[3]单一参数的盐渍化信息提取精度有限,随着遥感数据种类的日益丰富,多源、多参数联合的反演方法得到了广泛应用。
光学遥感通过地物反射辐射特征的变化,模拟各种遥感指数、地表温度等参数与土壤盐分之间的关系,实现土壤盐分监测。文献[4-6]基于光学影像,通过多参数联合的方式提升了盐分信息的提取精度,但未考虑各类参数的盐分反演效率和相互比较优势。
雷达遥感具有全天时、全天候成像的特点,且微波具有一定的穿透能力,可以与光学遥感优势互补,在土壤盐渍化监测方面发挥着重要作用[7-8]。近年来,全极化雷达遥感技术快速发展,全极化雷达影像由于包含了散射目标的几何特征、后向散射特征及丰富的极化特征信息,在土壤盐分反演中备受关注。贾殿纪[9]基于Radarsat-2全极化雷达影像,通过构建土壤盐分与极化特征参数间的偏最小二乘模型,实现了青海湖流域的土壤盐分反演,效果良好。然而现阶段利用全极化雷达影像开展土壤盐分定量反演的研究虽然取得了一定的进展,但工作较为有限。
光学遥感不仅可以通过光谱信息反映土壤盐渍化状况,同时也有助于微波遥感信息的解译和定量反演,而全极化雷达遥感能够提供丰富的地物特征信息,因此,集成光学与全极化雷达遥感技术的土壤盐分协同反演具有十分重要的科学意义与应用价值[10]。在利用多源遥感数据的盐分反演中,前人采用了众多的盐分指示环境变量,如波段反射率[6]、植被指数、盐分指数[4]、后向散射系数[7-8]、极化特征参数[9,11]、地表温度[5-6]以及地形因子[6,12]等,这些变量在盐分反演效率和相互比较优势方面,具有一定程度的不确定性和易混淆性。因此,有必要对众多盐分指示环境变量进行全面的综合评价,以确定盐分监测的优势敏感变量,进而建立盐分监测的有效模型。在利用多源遥感参数反演土壤盐分的方法上,RF和SVM等机器学习算法因具有能够处理复杂的非线性问题和不受制于输入环境变量的类型与个数的特点而被广泛应用,且取得了较好效果[4,6],为土壤盐分的定量反演研究提供了切实可行的思路。
本文以黑河下游额济纳旗东南的居延泽地区为研究区,基于Sentinel-2、Radarsat-2、Landsat-8和SRTM DEM数据提取波段反射率、植被指数、盐分指数、极化雷达参数、地表温度和地形因子共6类82个变量,采用变量优选策略筛选各类变量及其组合的最优变量,完成盐分敏感变量的优选,进而构建RF与SVM盐分预测模型,以期实现居延泽地区土壤盐分的定量反演。
1 数据与方法
1.1 研究区概况
居延泽位于内蒙古自治区阿拉善盟额济纳旗的东南部,北邻阿尔泰山脉,南与巴丹吉林沙漠相接,由东、西居延泽2个子盆地构成(图1),西北角存有残留湖沼——天鹅湖。该区域地势东北高,西南低,平均海拔900 m,由于深居欧亚大陆腹地,气候干燥,降雨稀少,为典型的大陆型气候。
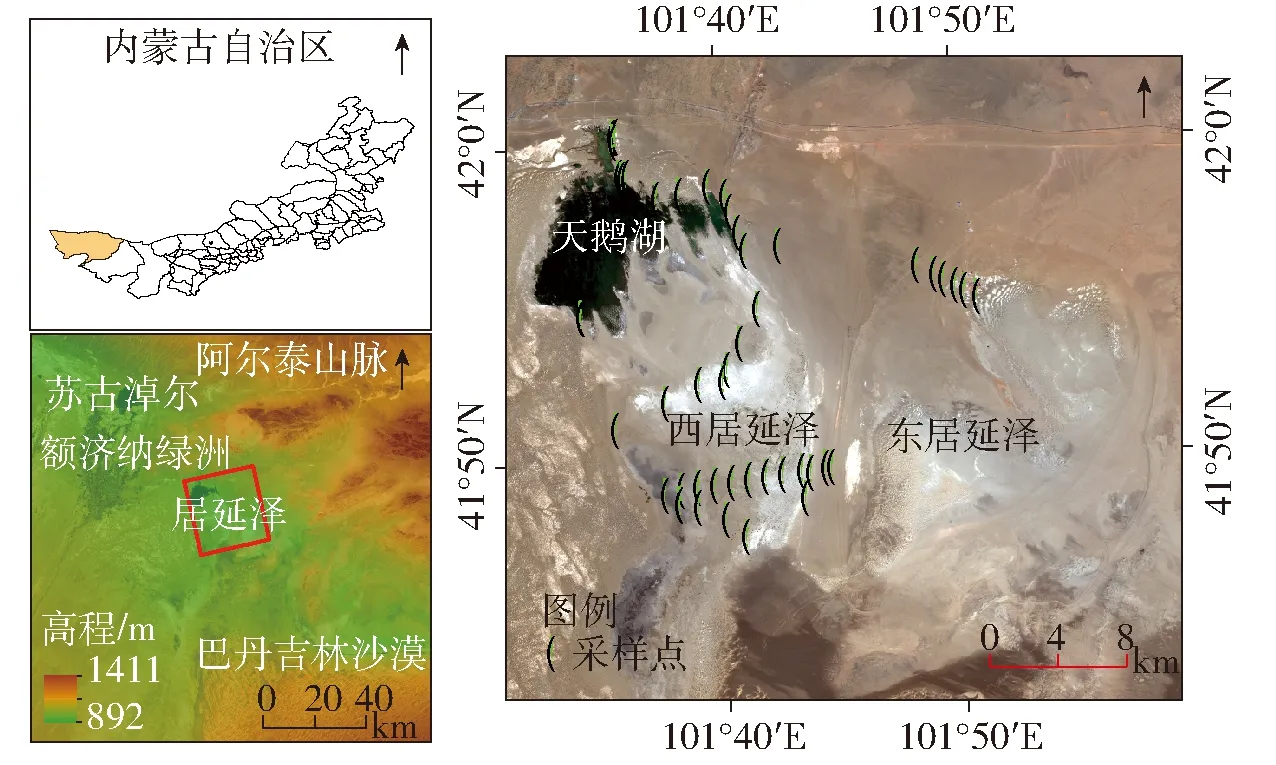
图1 研究区示意图
1.2 土壤样品采集及预处理
根据研究区的土壤类型和土地覆盖类型,考虑交通可达性,于2017年8月14—17日共采集42个盐分样点(图1)。在各采样点人工开挖长×宽×深约50 cm×50 cm×50 cm的探坑,采集0~10 cm的土壤样品。土壤样品经风干、研磨,称取20 g样品(已过1 mm筛),加100 mL超纯水5倍稀释,封口后上摇床3~5 min,过滤,并使用仪器测定过滤后原液的浓度,依据原液质量浓度是否大于500 mg/L考虑配置稀释液,最后用sensION5型电导率仪测定滤液或稀释液的电导率,并转换为土壤含盐量(SSC)[13]。
1.3 遥感数据及预处理
本文采用光学与雷达影像。光学影像采用Sentinel-2和Landsat-8影像,Sentinel-2影像成像时间为2017年8月24日,数据来源于哥白尼数据中心(https:∥scihub.copernicus.eu/),数据等级为L1C级,空间分辨率为10、20、60 m。利用配套处理插件Sen2Cor将经过辐射校正与几何校正的L1C级数据转为L2A级数据,完成大气校正等预处理。Landsat-8影像成像时间为2017年9月18日,数据来源于地理空间数据云(http:∥www.gscloud.cn),空间分辨率为30 m。订购了野外期间一景精细全极化模式Radarsat-2雷达影像,成像时间为2017年8月17日,幅宽25 km×25 km,空间分辨率8 m。使用ENVI软件的SARScape模块和PolSARpro软件完成原始SLC影像的多视、滤波、地理编码、辐射定标和正射校正等预处理。DEM数据采用SRTM DEM,空间分辨率为30 m,数据来源于美国地质调查局(http:∥www.usgs.gov/)。为便于后续分析,以上影像均重采样至10 m。
1.4 环境变量获取及计算
前人研究表明,植被指数、盐分指数以及地形因子可以为土壤盐渍化监测提供有效信息[6,14]。地表温度影响水分中可溶性盐的析出积聚,是干旱半干旱区土壤盐渍化监测的重要参数[15]。极化目标分解是从极化SAR数据中提取目标散射特征的方法,根据不同的分解机制,前人提出了An&Yang分解[16]、Cloude-Pottier分解[17]、Freeman-Durden分解[18]、H-A-α分解[19]、Krogager分解[20]和Yamaguchi分解[21]等方法。分解后的特征物理含义明确,在一定程度上可体现不同目标之间散射机理的差异,能够提供丰富的地物特征信息。此外,土壤盐分的积累会导致土壤介电常数虚部发生变化,进而引起雷达后向散射系数的变化[22]。因此,极化雷达的后向散射系数及极化分解后的极化特征参数也是土壤盐渍化监测的重要参数。鉴于此,本文选取波段反射率、植被指数、盐分指数、极化雷达参数、地表温度和地形因子共6类82个变量参与土壤盐分预测建模。其中,波段反射率、植被指数、盐分指数由Sentinel-2数据获取,极化雷达参数由Radarsat-2数据获取,地表温度由Landsat-8数据获取,地形因子利用DEM数据获取。具体变量及计算方法见表1。

表1 环境变量
1.5 变量优选
在土壤盐分反演中,并不是所有环境变量均可以提供有用信息而参与模型构建,模型应该避免不相关变量的影响[32]。研究表明,基于迭代删除潜在不相关的环境变量,有利于减少不确定性,提高预测精度[33]。本文参与模型构建的变量以各类变量及其组合进行分组,每组均会根据迭代删除产生最优变量集合。变量优选策略参照文献[32-33],具体为:
(1)将每组变量输入RF算法,基于平均精度减少量(Mean decrease accuracy,MDA),对环境变量进行重要性排序。
(2)删除重要性排序的最后一个环境变量,将剩余的变量输入RF算法重新训练并排序,随后再删除最后一位变量。重复删除最不重要的变量,直至剩余2个环境变量,循环结束。
(3)每次算法运行均会计算出决定系数(Determination coefficient,R2)和均方根误差(Root mean square error,RMSE),最终以RMSE为主、R2为辅综合判断最优变量集合。
(4)重复步骤(1)~(3),直到遍历所有分组,得到每组的最优变量集合。
1.6 预测模型及模型验证
RF是2001年BREIMAN[34]提出的一种机器学习算法,以CART决策树为弱学习器,通过自举法(Bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取n个样本生成新的训练样本集,重复采样生成多个新的训练样本集,用新的样本集训练决策树组成RF,并将所有弱学习器得到的结果进行算术平均作为最终的预测结果。其中,在每个弱学习器构建Bagging集成、生成决策树时,所选特征均为随机选出的少数特征,从而使RF不需要额外剪枝即可取得较好的泛化能力和抗过拟合能力。该算法仅需定义2个参数[33],即终端节点树和每个节点随机选择的变量个数。通过反复计算与比较,设置终端节点树ntree为1 500,选择的变量个数m为自变量数目的1/3。
SVM是以VC维(Vapnik-Chervonenkis dimension)和结构风险最小化为理论基础的机器学习算法,该算法基于核函数映射将低维空间非线性问题转换为高维空间的线性问题,利用一个超平面根据最大化间隔值,将输入数据划分到n维的特征空间,从而实现分类、回归任务。通过引入不敏感函数,SVM在曲线拟合中得以应用并发展为支持向量回归。作为模型的重要参数,核函数与惩罚系数c、参数g的选取对模型精度有很大影响[35]。本文选择径向基函数作为核函数,c、g通过交叉验证来计算,并通过调用基于libsvm网格划分(Grid search)的参数寻优函数来寻找最优解。
交叉验证对机器学习有很强的指导与验证意义,K折交叉验证[36](K-fold cross validation)是广为使用的交叉验证方法之一,尤其在数据集较小的情况下,能够最大程度地提高数据利用率,使模型性能更为优越。本文采用10折交叉验证法,将样本划分为10个互斥子集,每次将9个子集作为训练集以拟合模型,剩余1个子集作为验证集用于评估所建模型的预测能力,验证过程重复10次,每次将不同的子集作为验证集,故每个模型会得到10次模型验证结果,取其平均值,作为该模型的最终验证结果。本文采用R2和RMSE为指标评价预测模型的效果与性能。当R2趋近1,RMSE趋近0,表示模型效果最佳。
2 结果与分析
2.1 实测土壤盐分统计分析
研究区实测土壤含盐量在0.201~119 g/kg之间,土壤含盐量变化较大,平均值为23.898 g/kg,变异系数为1.175,属于强变异性。根据土壤盐分分级标准[37],盐渍土可分为非盐渍化(含盐量小于1 g/kg)、轻度盐渍化(含盐量1~2 g/kg)、中度盐渍化(含盐量2~4 g/kg)、重度盐渍化(含盐量4~10 g/kg)和盐土(含盐量大于10 g/kg)5个等级。参考以上标准,研究区实测盐分等级分布如表2和图2所示。由表2可知,该地区非盐土样本与盐土样本约各占50%,而非盐土样本又以中度和重度盐渍化土居多。在图2中,小提琴宽度表示数据分布密度,越宽表示数据分布密度越大,高度表示土壤盐分分布范围。

表2 实测盐分等级分布
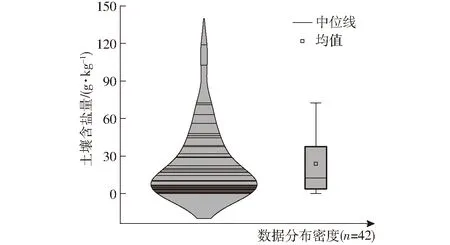
图2 实测盐分分布图
2.2 优选变量及重要性分析
利用Random forests软件包对变量进行了重要性分析。就所有变量(图3,图中以平均精度减少(MDA)衡量环境变量重要性)而言,地表温度的重要性最高,为12.416%,且远远高于其他变量;Kkh的重要性次之,为4.121%;地形深度指数TWI的重要性居第三,为3.984%;波段反射率、植被指数及盐分指数的重要性靠后且均小于2.3%。综合考虑,6类变量的重要性从大到小依次为地表温度、地形因子、极化雷达参数、盐分指数、植被指数、波段反射率。通过变量优选策略进一步选择各组最优变量,结果如表3所示。

图3 变量重要性
由表3可知,优选的波段反射率重要变量有B6、B8a、B11和B12等,揭示了红边和短波红外波段在土壤盐分监测中的重要性,与TAGHADOSI等[6]的研究结果相一致。在植被指数中,CRSI、ERVI、ENDVI和SAVI与土壤盐分存在密切关系,与周晓红等[38]的研究中增强型植被指数与盐分相关性最强的结果相一致,同时也与王飞等[39]在不同绿洲区得到的CRSI和增强型植被指数(ENDVI、EVI、EEVI)在干旱区具有普适性的结论相吻合。在盐分指数中,优选的重要变量有SI2re3、S5re1、S1re2和S2re3等,而这些变量均有红边波段参与计算,再次证明了红边波段在土壤盐分监测中的重要性,与马国林等[12]的研究中RESI63、RESI31、RESI12和RESI16红边光谱指数重要性居前的结果一致。优选的极化雷达参数重要变量有An4Odd、An4Vol、FOdd、YOdd、Kkh、H和Kks等,其中,FOdd与Kks同样在依力亚斯江·努尔麦麦提等[11]的研究中作为优选变量。各变量有明确的物理含义,可以在一定程度上体现不同目标之间散射机理的差异,尤其是重度与中-轻度盐渍地之间的差异[40-41],对土壤盐分预测有重要作用。地形因子优选的重要变量有CA、VD、CNBL和TWI等,以水文相关的地形因子为主,这与居延泽地区为古湖盆区有关,而CA和TWI也在马国林等[12]的研究中作为重要性居前的优选地形指数。

表3 优选变量
2.3 土壤盐分估算模型的构建与精度评价
以波段反射率、植被指数、盐分指数、极化雷达参数、地表温度和地形因子6类变量及其组合方案的优选变量作为RF和SVM模型输入的自变量,土壤含盐量作为目标变量,建立土壤盐分RF和SVM预测模型,不同变量模型的盐分预测精度如表4所示。
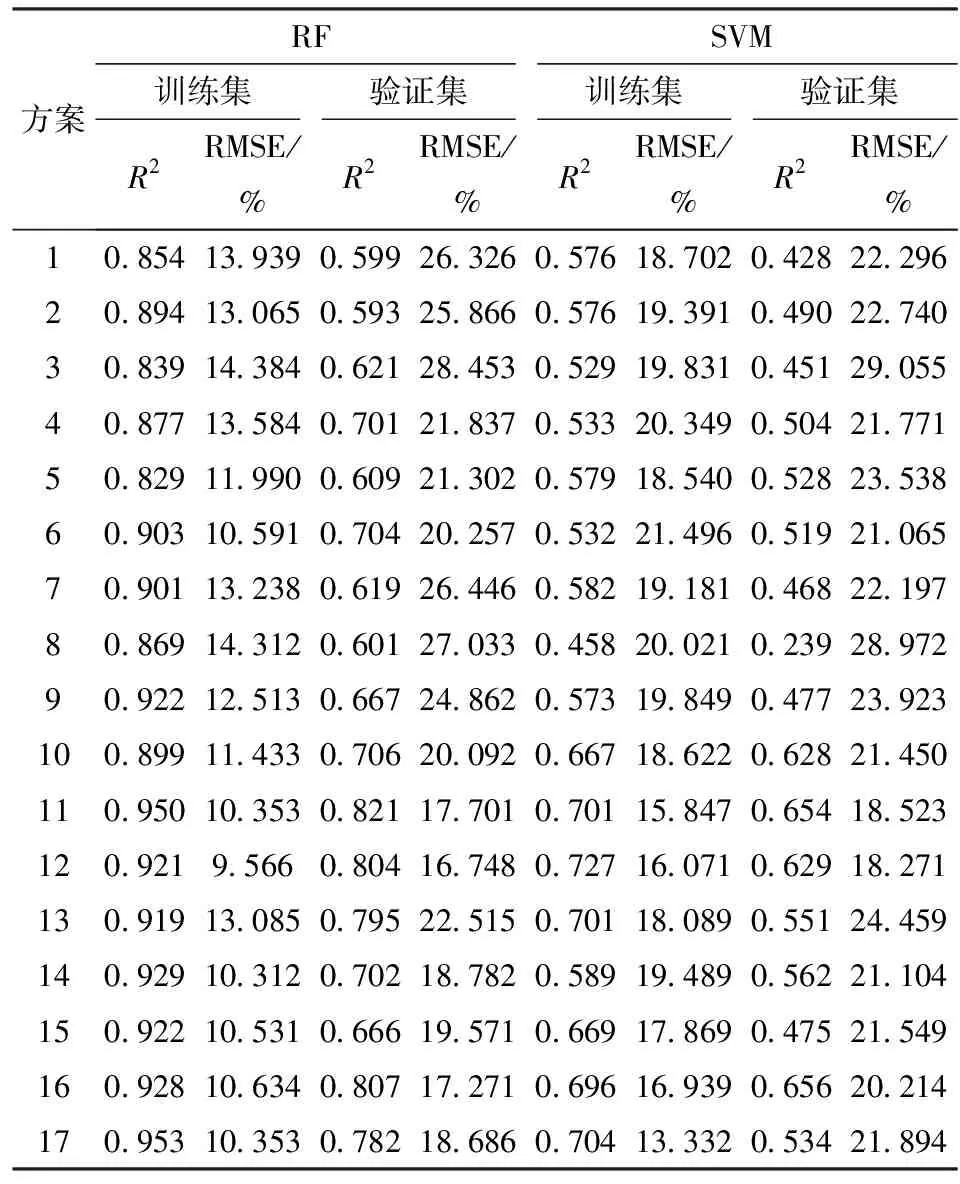
表4 土壤盐分反演精度
由表4可知,在单一变量反演方案中,极化雷达参数与地形因子对土壤盐分预测有较大贡献,极化雷达参数(方案4)建立的RF模型验证集R2为0.701,RMSE为21.837%,SVM模型验证集R2为0.504,RMSE为21.771%。地形因子(方案6)建立的RF模型验证集R2为0.704,RMSE为20.257%,SVM模型验证集R2为0.519,RMSE为21.065%。其次地表温度(方案5)对土壤盐分反演也较为重要,RF验证集R2稍低,为0.609,RMSE为21.302%,SVM验证集R2为0.528,RMSE为23.538%。盐分指数、植被指数与波段反射率(方案3、2、1)建立的RF模型精度略低且相差不大,R2分别为0.621、0.593、0.599,RMSE分别为28.453%、25.866%、26.326%,SVM模型趋势与RF模型相似,R2分别为0.451、0.490、0.428,RMSE分别为29.055%、22.740%、22.296%,与陈俊英等[4]研究优选盐分与植被指数组以及张智韬等[42]研究敏感波段组与光谱指数组对盐分反演精度影响的结果相吻合。极化雷达参数包含了丰富的极化信息,不同地物的散射机理不同,反映的极化信息也不尽相同,尤其是重度与中-轻度盐渍地[40],因而可以较好地预测土壤盐分。居延泽地区为古湖区,湖水在汇聚、流动和退缩过程中会受到地形影响,并最终在低洼地带汇集。湖水干涸后,地下水毛细上升使得地表盐分大量析出。因此,土壤盐分的分布与地形有密切关系。地表温度同样影响盐分分布,土壤中的可溶性盐随湖水流动,在温度与地形的影响下,盐分朝着某一方向汇聚,随着高温条件下水分的快速蒸发,盐分便会积聚在土壤表面。由于植物盐胁迫的影响,植被指数在较高植被覆盖下对土壤盐分变化敏感[30],而本研究区极度干旱,植被稀疏,导致植被指数对土壤盐分预测精度较低。盐分指数与植被指数恰恰相反,由对盐分敏感的波段组合计算得到,主要依据土壤的光谱响应来反映土壤盐分变化,地表植被越少,对光谱响应影响越小,盐分指数对土壤盐分的监测效果越好,因而盐分指数对土壤盐分的预测精度高于植被指数。
在多变量反演方案中,波段反射率、植被指数、盐分指数这3类变量联合反演的精度几乎没有提升,波段反射率与植被指数联合反演(方案7)的RF验证集R2为0.619,RMSE为26.446%,SVM验证集R2为0.468,RMSE为22.197%,而加入盐分指数后(方案8),RF验证集R2降低0.018,RMSE升高0.587个百分点,SVM验证集R2降低0.229,RMSE升高6.775个百分点,或许是因为植被指数与盐分指数都是由对盐分敏感的波段计算的光谱指数,这3类变量本质上都是波段信息组合,相互之间存在信息冗余与重叠。而对植被指数与极化雷达参数联合反演的方案13而言,RF验证集R2比两者单独反演分别提升0.202、0.095,RMSE比前者单独反演降低3.352个百分点,比后者单独反演升高0.667个百分点,SVM验证集R2比两者单独反演分别提升0.061、0.047,RMSE比两者单独反演分别升高1.719、2.688个百分点,说明光谱指数和极化雷达参数之间不存在信息冗余,体现出光学遥感与微波遥感信息互补的优势。当光谱指数加入极化雷达参数、地表温度和地形因子联合反演时(方案9~11),RF验证集R2分别提升0.048、0.087、0.202,RMSE分别降低1.584、6.354、8.745个百分点,SVM验证集R2分别提升0.009、0.160、0.186,方案9的RMSE升高1.726个百分点,方案10、11分别降低0.747、3.674个百分点,表明极化雷达参数、地表温度及地形因子包含丰富的信息,是土壤盐分反演的重要参数,这与前文单一变量盐分反演精度较高的结果是一致的,同时与6类变量的重要性排序结果吻合。当地表温度与地形因子联合反演时(方案12),RF验证集R2为0.804,RMSE为16.748%,SVM验证集R2为0.629,RMSE为18.271%,但在加入植被指数或盐分指数后(方案14、15),RF验证集R2分别下降0.102、0.139,RMSE分别升高2.034、2.823个百分点,SVM验证集R2分别下降0.067、0.154,RMSE分别升高2.833、3.278个百分点,与极化雷达参数、地表温度和地形因子联合反演(方案16)加入植被指数(方案17)的变化趋势一致,这或许是因为在联合反演时,各变量间互相影响、互相牵制,植被指数和盐分指数的加入对地表温度及地形因子的联合反演有一定的影响。
从不同方案的优选变量来看,各变量之间相互影响、相互制约,联合反演并不是将重要性最高的变量组合在一起。从不同方案优选变量的个数结合预测精度也可以说明,反演时变量并不是越多越好,引入过多的自变量会产生信息冗余,造成过拟合,使模型预测精度下降[42]。由上文可知,RF模型的R2均高于SVM模型,RF模型的RMSE总体也均低于SVM模型,且两者在各方案模型上的变化趋势一致,表明RF模型比SVM模型对土壤盐分的预测效果更好。张智韬等[42]在内蒙古河套灌区耕地的土壤盐分反演中也用到了本文的2种机器学习模型,发现RF模型效果最好,SVM模型次之。马国林等[12]基于多光谱与DEM数据反演艾比湖湿地土壤盐分时,同样发现机器学习RF模型的反演效果更优,上述研究均与本文的模型研究结果一致。对表4进一步分析发现,在RF与SVM 2种模型中,基于方案11、12、16构建的模型均具有较高精度且模型精度相差较小,其中方案11引入了波段反射率、植被指数、盐分指数、极化雷达参数、地表温度和地形因子,方案12引入了地表温度和地形因子,方案16引入了极化雷达参数、地表温度和地形因子,但方案11包含6类变量,信息丰富,且较单一变量最佳模型R2提升0.117,RMSE降低2.556个百分点,综合考虑认为基于方案11构建的RF模型为研究区土壤盐分预测的最优模型。
2.4 土壤盐分预测结果
利用选取的最优变量集和RF模型反演居延泽地区土壤盐分,结果如图4所示。由图4可见,土壤盐分由研究区东北向西南增高,西南方向的盐分又以东、西居延泽古湖盆区为最。研究区地势由东北向西南倾斜,东北地区地势高,为山区与戈壁,盐分含量较低。由于古湖的退缩,致使西南地区成为水盐汇聚中心,在高温干燥环境下,湖水迅速蒸发并干涸,地下水毛细上升使得地表盐分大量析出,形成低洼地带盐分高的分布特征。天鹅湖附近滩涂众多,旱生植被集中生长,涵养了一定水分,导致含盐量较低。在西居延泽中部出现斑块状的低盐分区,可能是因为古湖在干涸前涵养了周边大量的植被。图中出现的条带状低盐区,为东、西居延泽之间表面覆盖小砾石的古湖岸线,零星斑块状低盐区为雅丹地貌和灌丛沙堆分布区。东居延泽中存在的大块低盐区,是由于该区为地势较高的沙土区域,含盐量较低。从分布格局而言,模型预测结果符合野外调查结果,与实地情况较为接近。

图4 土壤盐分预测结果
3 结论
(1)众多盐分指示变量中,短波红外波段(B11)、冠层盐度响应植被指数(CRSI)、扩展比值植被指数(ERVI)、红边盐分指数(S2re3)、单次散射(FOdd)、地表温度(LST)与汇水面积(CA)等变量对土壤盐分监测具有较强的普适性。
(2)单一变量模型的盐分预测精度根据R2和RMSE综合判断,从高到低依次为地形因子、极化雷达参数、地表温度、盐分指数、植被指数和波段反射率,其中地形因子构建的RF模型预测精度最高,其验证集R2为0.704,RMSE为20.257%。
(3)多变量联合可以进一步提升模型的预测精度与稳定性,随着环境变量的逐步加入,当6类变量均参与模型构建时,RF模型预测精度最高,其验证集R2为0.821,RMSE为17.701%,与单一变量最佳模型相比,R2提升0.117,RMSE降低2.556个百分点。
(4)RF模型较SVM模型更适于干旱区土壤盐分反演,优选全变量组构建的RF模型具有最佳预测精度,其验证集R2为0.821,RMSE为17.701%。基于该模型的反演结果表明,区域东北及天鹅湖附近盐渍化程度较低,西南部古湖盆区盐渍化程度较高。
猜你喜欢
农业知识(2022年9期)2022-10-13
草业科学(2022年3期)2022-03-26
资源信息与工程(2021年5期)2022-01-15
中国土壤与肥料(2021年5期)2021-12-02
农业机械学报(2021年8期)2021-08-27
土壤与作物(2021年1期)2021-03-07
湖北农业科学(2020年23期)2020-12-30
矿产勘查(2020年11期)2020-12-25
农业机械学报(2019年6期)2019-06-27
祝您健康·文摘版(2019年3期)2019-06-11
