
基于ARIMA-CNN-LSTM模型的黄河开封段水位预测研究
2023-01-18 11:22陈帅宇赵骧
水利水电快报 2023年1期
陈帅宇,赵骧,蒋 磊
(河南大学 软件学院,河南 开封 475000)
0 引 言
近年来,随着人工智能和数据挖掘的不断发展完善,越来越多学者尝试利用神经网络模型和机器学习算法对河流水位进行时间序列预测。目前使用最为广泛的预测方法仅考虑了水位因素,即只将水位数据输入模型中,然后进行单变量的模型训练和时间序列预测,如王淑华[1]提出一种基于ARIMA的水位预测方法,通过将冯家山水库的水位数据输入ARIMA模型中进行训练,之后进行时间序列预测,最终得到了较为准确的预测值。但由于ARIMA模型单变量输入的局限性,且预测的时间序列多要求为线性,所以在支流众多的河道中往往预测效果较差。实际的河道情况更加复杂,水位受降雨、上游来水等要素的影响不可忽略。部分学者尝试利用多变量输入的时间序列预测模型对水位进行预测,取得了较高的精度。顾乾晖等[2]尝试利用向量回归机(SVR)处理非线性数据的优势以及粒子群优化算法(PSO)自适应全局搜索的优势,配合长短期记忆网络(LSTM)对水位进行精确预测,取得了良好的效果,但该类算法通常对数据的精度要求较高,往往需要时间序列较为平稳。刘青松等[3]提出了一种水位预测模型,通过利用AR对数据中的线性成分的敏感性以及RNN对数据中的非线性成分的敏感性进行优势互补,在四川省清溪河流域的水位预测中取得了良好的效果,但应用在水文情况更加复杂的黄河时,其多变量输入模块仍有待完善。商其亚等[4]利用混沌粒子群优化 SVM 参数来对水位进行预测,取得了显著的效果,但也仍存在部分预测精度不足的情况。刘晓伟等[5]提出了一种基于GRA-NARX神将网络的水位预测模型,通过使用灰色关联分析(GRA)和NARX神将网络联合对密云水库调蓄工程屯佃泵站站前水位进行了2 h预测,取得了较好的效果,但在长期时间序列预测中表现欠佳。总的来说,以上模型应用在黄河中下游的水位预测中存在局限性。多变量CNN-LSTM模型在捕获水文数据中的非线性关系上表现良好,但在捕获数据中的线性关系上的表现往往不尽如人意。ARIMA模型虽然在线性关系学习上表现良好,但往往需要时间序列严格平稳,同时其本质上只能捕捉线性关系,并不能很好的捕捉非线性关系。因此,本文采用多变量CNN-LSTM模型和ARIMA模型相结合的方法,在传统单变量水位预测模型的基础上,将夹河滩水位检测站的降水、流量,上游来水流量,上游水位等多个变量输入模型,从而对未来一段时间的黄河开封段水位进行有效预测,既实现了对序列中复杂的非线性关系的有效捕捉,又学习到一些有效的线性关系。
1 研究区域概况
本文研究对象为黄河开封段,黄河流经河南开封的一段是中国最高的地上悬河。其位于开封境内黄河南岸的柳园口,由于黄河流出邙山后落差变小,泥沙大量淤积,致使河床高出开封市区7~8 m,且因惠济河、马家河、黄汴河等众多支流的存在,增加了该地区水文环境的复杂性。同时,该地区降水多集中在7~9月,降水量占全年降水70%以上,汛期水位增高,黄河长期处于高水位且排洪能力较弱,易发生洪涝灾害。因此,黄河水位的精确预测对防洪抗旱、生态环境保护以及水资源合理利用有着至关重要的意义。尤其是近年来黄河中下游异常气候频发,降水明显增多,使黄河水位的精准预测更加复杂和困难。
2 研究方法
2.1 数据归一化
数据归一化是数据挖掘的一项基本工作,不同的评价指标往往所用量纲或度量方式不同,若不加以处理,会对后续实验精度产生较大影响。本文将各指标同量纲化,消除或减轻各指标之间由于量纲不同所带来的影响(即无量纲化处理),对各指标中每个样本值进行处理:
(1)
式中:xij为第i个样本的第j个指标的数值;x′ij代表第i个样本的第j个指标的归一化数值;max(xj)和min(xj)分别为第j个指标的最大值和最小值。
2.2 模型基本原理
2.2.1 ARIMA模型
ARIMA模型由Box和Jenkins于20世纪70年代提出,是一种著名的时间序列预测方法,该模型的基本思想是将数据看成一个时间序列对象,再使用数学模型对该时间序列进行描述,训练完成的模型可以通过时间序列的过去值、现在值来预测未来的数据及趋势,在一些工业设备强度预测等问题中得到了广泛的应用。由于实际的水文序列具有非线性非平稳的特点,而ARIMA模型引入了差分,对于非线性非平稳的时间序列也具有良好的处理效果,并对水文序列中的线性关系具有良好的学习效果,故本文采用ARIMA模型对未来水位变化情况进行预测。
ARIMA模型由自回归(AR)模型、移动平均模型(MA)和差分法(I)组成,其表达式如下。
自回归(AR)模型用来描述现值与过去值之间的关系,使用指标自身的数据对自身进行预测。
(2)
式中:yt为现值,即当前值;μ为常数项;p为指标的阶数;Υi为自相关系数;t为误差。
移动平均(MA)模型表示的是自回归模型中误差项的累加,能有效地消除预测中的随机波动。
(3)
式中:q为MA/Moving Average项,即预测模型中采用的预测误差的滞后数;θi为移动平均系数。
将自回归模型、移动平均模型和差分法结合,得到ARIMA(p,d,q)模型。
(4)
式中:d为需要对数据进行差分的阶数。
2.2.2 CNN-LSTM模型
考虑到黄河的水文环境复杂,且影响水位的因素众多,故本文使用了一种基于CNN-LSTM的多变量预测模型,将数据的多个变量输入进神经网络模型中,通过CNN对数据进行特征提取,其中原理如下。
定义一段水位数据序列为
Xr×m=
(5)
式中:X是一个r×m的矩阵,利用CNN在特征提取上有着良好表现的特点,使用CNN对X矩阵的特征进行提取,第一步特征提取通过filter函数进行、第二部激活利用Relu函数、最后使用max-pooling进行池化,同时加入dropout,得到的输出将输入后续模型继续进行后续处理。
CNN特征提取的流程见图1。

图1 CNN特征提取流程Fig.1 CNN feature extraction process
通过CNN特征提取后得到具有时间依赖性的数据,将数据输入到LSTM神经网络中进行训练。长短时记忆网络(LSTM)是在循环神经网络(RNN)的基础上加以改进而来,LSTM中含有门控单元(输入门It、输出门Ot、遗忘门Ft),其中遗忘门通过对上一时刻记忆单元Ct-1的信息进行保留、丢弃来对当前细胞的状态进行迭代等操作,使神经网络在较长一段时间的记忆功能上表现出良好的性能,因此被广泛地用于长时间、非线性的时间序列预测,如股票收盘价的预测、电负载预测等问题中。LSTM模型的基本单元结构见图2。
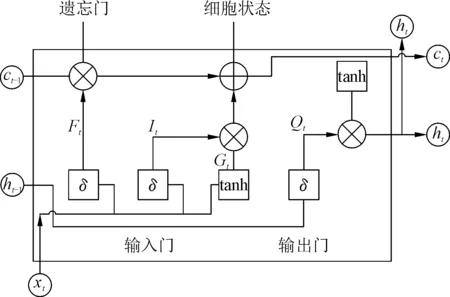
图2 LSTM模型基本单元结构Fig.2 Unit structure of LSTM model
输入门It、遗忘门Ft、输出门Ot的表达式如下:
It=σ(wi·g[ht-1,xt]+bf)
(6)
wi=[wht-1,wxt]
(7)
Ft=σ(wf·g[ht-1,xt]+bf)
(8)
wf=[wht-1,wxt]
(9)
Ot=σ(wo·g[ht-1,xt]+bo)
(10)
wo=[wht-1,wxt]
(11)
ht=Ot·tanh (Ct)
(12)
上式中:σ为sigmod激活函数,It,Ft,Ot均由其控制,且输出值均在[0,1];bf,bo为偏置项;ht-1和xt为输入数据,同时使用wt-1来表示h-1的权重;wxt表示xt的权重;Ct为t时刻细胞的状态。
细胞状态Ct由输入门和遗忘门的变化决定,其表达式如下:
gt=tanh (wg·[ht-1,xt-1]+bg)
(13)
wf=[wht-1,wxt]
(14)
ct=ftct-1+itgt
(15)
上式中:wg为g的权重;bg为偏置项;it为输入门;ft为遗忘门;gt为表示当前记忆,即当前细胞状态。
综上,提出一种ARIMA-CNN-LSTM的水位预测模型,表达式为
Yt=DYL+BYA
(16)
式中:Yt模型最后输出的预测结果;YL为CNN-LSTM模型的输出结果;YA为ARIMA模型的输出结果;D和B为参量(修正参数),通常情况下,D和B之和为1。
2.3 模型的输入与输出
本文提出的ARIMA-CNN-LSTM模型包括两个部分,即主部分和修正部分,模型的主部分为非线性模块,修正部分输出结果对模型的预测结果进行修正。其中非线性模块的输入为水位、流量、降水、上游流量、上游水位5个变量,输出为预测得到的水位数值;修正部分输入为本站水位值,输出为预测的水位值,最终将两个模型的输出代入Yt得出结果。
记{y1,y2,…,yT}为时间序列,预测窗口长度为L,输入变量的时间窗口为K。
CNN-LSTM模型的输入数据表达式:
(17)
模型输出为
(18)
由于均方根误差具有对一组数据中的特大、特小误差反应极其敏感的特点,故采用均方根误差作为损失函数,后使用均方根误差(RMSE)、均方误差(MSE)、平均绝对百分比误差(MAPE)和平均绝对误差(MAE)来评价时间序列预测模型的精度,同时采用纳什效率系数、总量误差来对水文过程线的拟合精度进行评定。均方根误差、均方误差、平均绝对百分比误差、平均绝对误差的定义如下。
均方根误差:
(19)
均方误差:
(20)
平均绝对百分比误差:
(21)
平均绝对误差:
(22)
纳什效率系数常用于验证水文模型模拟结果的好坏,其定义如下:
(23)

同时,为了更加直观地评定拟合精度,本文引入了总量误差这一概念,将每一个测试点的误差进行加总,其表达式如下:
(24)
式中:所表示含义与式(23)相同,I的范围通常为(0,+∞);I值越接近0即总量误差越小,模型质量越好,可信度越高。
2.4 水位预测流程
本文提出的水位预测流程如图3所示。首先从水利部黄河管理委员会官方网站中“每日水情”板块获取公开数据,所获取的数据如下:黄河夹河滩水文监测站每日水位测量值、夹河滩水文监测站每日流量监测值,花园口水文监测站(夹河滩上游)每日水位测量值,花园口水文监测站每日流量监测值,以及夹河滩每日降水值。

图3 水位预测流程Fig.3 Overall framework and process of water level forecast
再对离散化分布的缺失数据进行多重插补以及剔除连续的缺失值,将数据进行归一化处理。
将得到的归一化数据中的水位指标放入ARIMA模型中进行训练,将水位等5个变量放入CNN-LSTM模型中进行训练,将得到的结果代入参数寻优后的ARIMA-CNN-LSTM模型中求得结果。最终得到拟合之后的数值,并且绘制出预测水位与真实水位的拟合图。为了验证模型的精确程度和稳定性,将数据放入ARIMA模型、LSTM模型、CNN-LSTM模型以及BP模型中进行训练,得到其训练结果并绘制拟合图,求得均方根误差、均方误差、平均绝对百分比误差和平均绝对误差来进行对比,并最终得出结论。
3 数据分析及处理
3.1 原始数据处理
3.1.1 数据来源
本文所用的数据来自水利部黄河水利委员会官方网站,网站中每日水情所公开的花园口水文监测站和夹河滩水文监测站的2007年1月15日至2017年12月31日的每日水位、流量等数据,降水数据来自国家气象中心的中国气象数据网所对应地点的每日降水。
3.1.2 数据格式
本文使用的数据格式:本站水位和上游水位单位是m,精度保留至小数点后两位;本站流量与上游流量单位是m3/s,保留一位小数;降水数据单位为mm,保留一位小数,其中32700是气象部门处理气象资料的一个特定编码,表示该数据是小于0.1 mm的微量降水,故使用0到0.1之间的随机值来对该编码进行替换。
模型输入数据的格式:非线性模型(CNN-LSTM)的输入数据夹河滩水文监测站的水位、流量、降雨,花园口水文监测站(上游)的水位、流量;线性模型(ARIMA)的输入数据为夹河滩水文监测站的每日水位。
3.2 数据预处理
3.2.1 数据缺失值剔除
本文所获取的数据中存在部分连续缺失值,无法使用随机森林、灰色预测等方法对其进行有效预测插补,故本文在保证原本时间序列连续性的前提下对其进行剔除处理,防止其对神经网络模型的训练造成影响。
3.2.2 数据多重插补
针对数据中存在的部分近似随机分布的缺失值,这些数据存在上下文,可通过一些插补方法来对数据进行插补和填充。本文采用一种基于重复模拟的处理缺失值的方法对缺失数据进行填充,有效地保留了部分数据,使数据能够反映真实情况。
3.2.3 数据预处理结果分析
图4~8可见,本站水位、本站流量、降水、上游水位、上游流量的时间序列均存在一定的周期性,且周期大致一致(均可近似看作1 a为一周期),总体较为平稳,可以通过其进行未来一段时间的本站水位的时间序列预测。

图4 本站水位Fig.4 Local water level
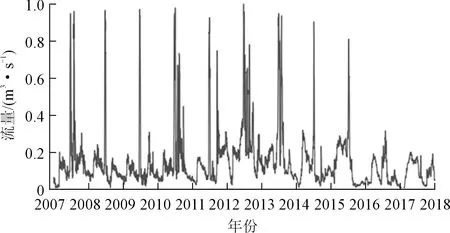
图5 本站流量Fig.5 Local flow

图6 本站降水Fig.6 Local precipitation

图7 上游水位Fig.7 Upstream water level
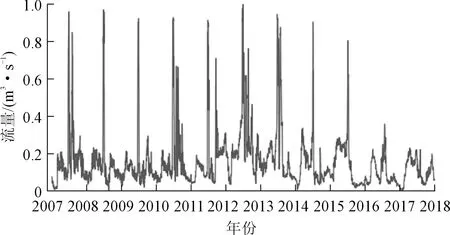
图8 上游流量Fig.8 Upstream flow
4 数值模拟分析
4.1 计算机配置
本次模拟使用的的计算机配置为处理器:Intel(R) Core(TM) i5-10400CPU @2.80 GHz,显卡:NVIDIA GeForce RTX 2060S,内存:32 GB,操作系统:Windows 10;程序设计语言:Python 3.8;集成开发环境:Anaconda,其版本为3.8 和Pycharm Community 2021.2.3;程序中TensorFlow版本为2.1.0。
4.2 数据选择与划分
选取2007年1月15日至2017年12月31日每日的本站水位、上游水位、本站流量、上游流量和降水作为数据集,将数据集中选取2007年1月15日至2016年1月1日的数据作为训练集,2016年1月2日至2017年12月31日的数据作为测试集,放入模型中进行训练。
5 模型对比及评价
将本文所提出的ARIMA-CNN-LSTM模型与传统的ARIMA、LSTM、CNN-LSTM、BP模型的拟合能力和泛化能力进行对比,各个模型在测试集的表现如表1所示。

表1 各模型在测试集上的表现Tab.1 Performance of each model on the test set
由表1中各个模型的表现可以得出:ARIMA-CNN-LSTM模型的RMSE较ARIMA模型降低20%,较CNN-LSTM模型降低5%,较LSTM模型降低16%,较BP模型降低38%,说明预测模型描述数据具有更好的精确度;MAE较ARIMA模型降低12%,较CNN-LSTM模型降低11%,较LSTM模型降低26%,较BP模型降低43%,预测值误差优于ARIMA等其他算法,可以更加有效地预测黄河开封段水位未来一段时间的变化趋势。
各个模型在测试集上的拟合情况如图9所示。

图9 各模型在测试集上的拟合情况Fig.9 Fitting of each model on the test set
LSTM模型的隐藏单元层数为64,迭代次数为500。由表1中LSTM模型在测试集上的表现可以得到LSTM模型的MSE为0.000 5,MAE为0.017 9,RMSE为0.022 0,MAPE为5.78%;较ARIMA-CNN-LSTM模型,MSE高出40%,MAE高出26%,RMSE高出15.5%,MAPE高出35%。且在图9的对比中可以直观发现LSTM模型曲线的拟合情况不如ARIMA-CNN-LSTM模型。由此可见,ARIMA-CNN-LSTM模型性能整体上优于LSTM模型。
ARIMA模型在测试集上的拟合情况如图9中的浅绿色线条所示,调参后发现ARIMA(1,1,1)拟合效果最好,故模型的p,b,q分别设置为1,1,1;表1中ARIMA模型的MSE为0.000 5,MAE为0.015 0,RMSE为0.023 2,MAPE为9.14%;较ARIMA-CNN-LSTM模型,MSE高出40%,MAE高出12%,RMSE高出20%,MAPE低76%。并且在与ARIMA-CNN-LSTM的对比中可以发现:虽然ARIMA模型在数据集中编号为400~500数据段处的拟合情况优于ARIMA-CNN-LSTM模型,但是该模型在拐点处的拟合情况远不如ARIMA-CNN-LSTM模型敏感,且对非线性成分敏感性较弱,预测精度有所欠缺。由此可见,ARIMA-CNN-LSTM模型性能整体上优于ARIMA模型。
图9中黑色线条即CNN-LSTM模型在测试集上的拟合情况,本文采用的CNN-LSTM模型的隐藏层单元数为64,窗口长度为32,步长为200,最大迭代次数为500。表1中CNN-LSTM模型的MSE为0.000 4,MAE为0.014 9,RMSE为0.019 4,MAPE为6.5%;较ARIMA-CNN-LSTM模型,MSE高出25%,MAE高出32%,RMSE高出5%,MAPE低44%。并且在图9中可以发现,CNN-LSTM无论是在峰值的模拟精度,还是在常规周期性波动上的模拟精度均不如ARIMA-CNN-LSTM模型。由此可见,ARIMA-CNN-LSTM模型性能整体上优于CNN-LSTM模型。
图9中紫色线条描述了BP模型在测试集上的拟合情况,使用了3层BP神经网络,隐藏层神经单元为25,迭代次数为2 000;表1中BP模型的MSE为0.000 9,MAE为0.023,RMSE为0.029 8,MAPE为4.47%;较ARIMA-CNN-LSTM模型,MSE高出67%,MAE高出43%,RMSE高出20%,MAPE高38%。并且在图9中与ARIMA-CNN-LSTM的对比中可以发现,BP模型各方面均不如ARIMA-CNN-LSTM模型,并不能很好地在测试集上拟合。由此可见,ARIMA-CNN-LSTM模型性能整体上优于BP模型。
图9红色线条描述了ARIMA-CNN-LSTM模型在测试集上的拟合情况,该模型在参数上的选择:p,b,q分别为1,1,1,隐藏层单元数为64,窗口长度为32,步长为200,最大迭代次数为500,调优参数分别为0.487和0.513。表1中ARIMA-CNN-LSTM模型的MSE为0.000 3,MAE为0.013 2,RMSE为0.018 6,MAPE为3.76%。并且在图9中可以发现,ARIMA-CNN-LSTM模型无论是在峰值的预测,还是在常规周期性变化的预测上均表现良好,可以很好地在测试集上拟合。可以得出,无论从MSE等评价指标来看,还是从拟合图上直接观察,ARIMA-CNN-LSTM模型性能均优于LSTM、CNN-LSTM、ARIMA和传统的BP模型。
使用各模型在测试集上的纳什效率系数和总量误差,来对模型质量做出更加直观的评价(表2~3)。

表2 各模型在测试集上的纳什效率系数Tab.2 Nash efficiency coefficient of each model on the test set

表3 各模型在测试集上的总量误差Tab.3 Total error of each model on the test set
由表2~3可以看出,ARIMA-CNN-LSTM模型的纳什效率系数为0.96,较其他模型更接近于1,表现高于其他模型;虽然总量误差高于ARIMA模型,但低于CNN-LSTM等其他模型。评价数据更加直观地反映出了该模型质量较好、可以更加有效地对未来一段时间水位的变化情况进行预测。
6 结 论
本文针对现有的时间序列预测模型无法对降水频繁、水文环境复杂的黄河开封段进行有效的时间序列预测的现状,以及传统的时间序列预测模型无法很好地学习复杂多变量之间的线性关系等一系列现有的不足和问题,提出一种ARIMA-CNN-LSTM多变量黄河水位预测模型,在对其进行一系列验证之后,应用在黄河开封段的时间序列预测中,通过利用ARIMA模型对线性成分的敏感性以及CNN-LSTM模型对数据中非线性成分的捕捉能力,通过二者结果的加权调优,提出一种适应于黄河水系复杂的水文环境、可以精确预测未来一段时间水位变化且对拐点反应灵敏的水位预测模型,并且通过其预测结果拟合度与其他模型的拟合度等一系列参数进行对比,最终验证了ARIMA-CNN-LSTM模型在黄河开封段水位时间序列预测上表现出了较高的预测精度和较强的灵敏性,可以有效对黄河接下来一段时间的水位变化情况进行有效的时间序列预测。
(1) 相较于传统的、常规的单变量水位预测模型,如ARIMA、LSTM等只将水位作为模型输入,而忽略影响水位的其他因素,故只能表征出水位在未来变化的一个趋势,无法给出更精确的预测,从而影响了后续的水文工作。而ARIMA-CNN-LSTM模型通过综合考虑上游水位、上游流量、本站流量、本站降雨等影响水位的重要因素,在拟合度和峰值预测上更加优于传统的单变量水位预测模型,且模型的鲁棒性高于传统的单变量模型。
(2) 与单独的常规CNN-LSTM模型相比,ARIMA-CNN-LSTM模型通过加入ARIMA模型对结果的修正,使模型对序列线性特征捕捉更灵敏,且模型在水位峰值处的预测精度高于CNN-LSTM模型,可以有效地预测未来一段时间的黄河水位变化情况,为有关部门的决策提供了一定的参考。
猜你喜欢
河北地质(2021年3期)2021-11-05
金桥(2020年11期)2020-12-14
金桥(2020年11期)2020-12-14
数学年刊A辑(中文版)(2020年2期)2020-07-25
河南水利年鉴(2020年0期)2020-06-09
河南水利年鉴(2020年0期)2020-06-09
数学物理学报(2019年6期)2020-01-13
当代陕西(2019年21期)2019-12-09
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
河南水利年鉴(2017年0期)2017-05-19
