
结合注意力转移与特征融合算法的在线知识蒸馏
2023-02-02 09:25梁兴柱
湖北理工学院学报 2023年1期
梁兴柱,徐 慧,胡 干
(1.安徽理工大学 计算机科学与工程学院,安徽 淮南 232001;2.安徽理工大学环境友好材料与职业健康研究院(芜湖),安徽 芜湖 241003)
近年来,深度神经网络凭借强大的特征学习能力在计算机视觉处理中取得了令人欣喜的成绩[1-2]。但是,功能强大的模型往往会伴随大量的参数,占据较大的内存,不利于模型的部署与应用[2],因而提出了深度学习模型压缩技术,包括剪枝、二值化、轻量化模型设计[3-4]、知识蒸馏(Knowledge Distillation , KD)[5]等。其中,知识蒸馏又可以划分为离线知识蒸馏(Offline KD)和在线知识蒸馏(Online KD)。传统Offline KD[5]是一个两阶段蒸馏方法,必须先预训练一个功能强、参数多的教师模型,然后再将教师模型学到的知识迁移到性能较弱、参数较少的学生模型上,从而得到一个速度快、能力强的网络,达到减少参数、提高学生模型性能的目的,但存在训练时间长、计算成本高、占据内存大等缺点。Zhang等[6]利用深度相互学习(Deep Mutual Learning,DML)使学生模型直接从其他学生模型的预测中学习。Lan等[7]提出采用一个门控单元作为网络共享低层,在动态建立教师模型的同时训练多分支网络。Romberg等[8]进一步优化了FitNet 网络并率先在知识蒸馏领域提出利用教师与学生间的注意力图学习来代替特征图学习。Chen等[9]在OKDDip两级蒸馏方法的研究基础上使用分类器多样化损失函数和特征融合模块来提高学生模型的多样性和网络中注意机制的性能。
现有的大部分方法很难构建一个功能强大的教师角色,且忽略了单个子分支性能的自我提升。因此,本文提出一种结合注意力机制(Attention Mechanism,AM)与特征融合(Feature Fusion Module,FFM)的在线知识蒸馏方法(KD-ATFF),利用特征融合构建强大的教师角色指导模型训练,同时将深层神经元的注意力转移到浅层网络,进一步提升子分支的性能。
1 KD-ATFF
KD-ATFF拥有n个分支在线集成网络模型,每个分支网络由M个block组成。在没有教师模型指导的前提下,每个block在训练过程中将自己的特征图转化为注意力图,模块之间相互学习彼此的注意力地图,增加知识差异性。各个分支由浅层网络到深层网络相互学习得到的多样性知识被保留到最后1个block的特征,然后再将各分支的最后1个block的特征送入特征融合模块进行信息融合,最后根据模块内部为各分支分配的权重组成集成教师指导各子模型训练。KD-ATFF模型结构如图1所示。

图1 KD-ATFF模型结构
1.1 CL模块

(1)
(2)
采用L2范数作为2个模块进行互学习的损失函数,将2个模块的注意力图进行二次互学习得到的值进行相加后取1/2作为一次损失。模块间的互学习目标函数为:
(3)
1.2 特征融合模块
KD-ATFF共有n个相同的网络架构分支,多分支的特性比来自单分支的特性包含的信息要丰富得多。为便于表示,所有的学生模型从1到n进行索引。由于网络的深层会产生更丰富的语义信息,故将来自多个分支的最后1个block的特征作为特征融合模块的输入。这样可以利用高级的语义信息来丰富特征,所产生的权值能取得较好的效果。加权集成目标ze可表示为:
(4)
式(4)中,f(·)为特征融合模块中心块的函数,为每个分支输出相应的重要性分数;Fa为来自第a个分支的最后一个块的特征图;za为来自第a个分支的logits。
以3个分支作为输入为例,来自每个分支的最后1个block的特征映射Fa将被连接在一起,然后送入中心卷积块。中心卷积块是由多个卷积层、批处理归一化和ReLU激活函数组成,中心块的最后一层是全连接层,用于融合来自多个分支的语义信息。与其他方法相比,特征融合模块可以获得更多的语义信息,能够有效地提高模块的性能。最终目标由各辅助分支的logits输出zi加权和得到。特征融合模块结构如图2所示。

图2 特征融合模块结构
1.3 蒸馏模型的损失函数
1.3.1传统标签损失
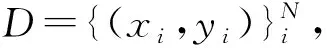
(5)
式(5)中,T为温度参数,取T=3。利用最小化交叉熵训练,得到标签学习的损失为:
Llabel=-∑ieilogqi
(6)
式(6)中,ei是标注的标签分布;qi是最小化预测的类概率。
1.3.2注意力转移损失函数

(7)
式(7)中,αm和αm+1分别为第m以及第m+1个block输出的注意力图。
1.3.3集成教师损失函数
KD-ATFF每个分支不仅从地面真实标签中学习,还从通过特征融合模块获得的加权集成目标中学习。知识转移是通过将学生模型生成的概率分布q与目标分布z对齐实现的。用KL散度表示其损失函数,第a个学生模型的预测分布为qa(a=1,2,…,n),每个辅助分支学习ze中提取的知识,故所有分支的蒸馏损失为:
(8)
则,整个KD-ATFF的损失函数为:
(9)
Llabel是第α个子模型的传统知识蒸馏损失;θ,β是调节软硬标签比例的超参数。
1.4 KD-ATFF的算法流程
与两阶段传统蒸馏训练不同,Online KD中学生网络和集成教师同时进行训练。在每个子网络进行相同的随机梯度下降,并训练整个网络直到收敛,作为标准的单模型增量批处理训练。批处理贯穿整个训练过程,在每个batch进行子模型参数的更新和执行训练。KD-ATFF的算法流程如下。
输入:训练数据集D;训练Epoch数;分支数n
输出:n个训练好的模型{θ1,θ2,θ3,…,θn}
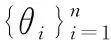
2.whilee≤do
3.使用公式(5)计算所有分支的预测{q1,q2,…,qn}
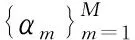
5.计算每个子模型的输出:(z1,z2,…,zn)
6.通过FFM获取每个分支的权重
7.使用公式(4)计算目标logits
8.利用公式(8)计算蒸馏损失LKL
10.e=e+1
11.end while
2 实验分析
2.1 实验设置与数据集
实验采用CIFAR-10和CIFAR-100多类别分类基准数据集。CIFAR-10是1个自然图像数据集,包含从10个对象类中提取的50 000/10 000个训练/测试样本(总共60 000个图像),每个类有6 000个大小为32×32像素的图像。CIFAR-100与CIFAR-10类似,也包含50 000/10 000个训练/测试图像,但覆盖100个细粒度类,每个类别有600张图片。实验在CIFAR-10/100数据集上的batchsize设置为256。
实验所使用的学生网络包括:ResNet-32(3.3 M)[2],ResNet-110(0.5 M)[2]和MobileNet(1.7 M)[10]。分支m设置为2;θ,β,T分别为1,1,3;选取随机梯度下降,SGD为优化器;模型的学习率初始化为0.1,并且每80周期减少为原来的1/10。采用top-1分类错误率,将所有模型的训练结果取平均值。模型训练和测试的计算成本,使用浮点运算(FLOPs)标准。
2.2 实验结果分析
将KD-ATFF方法与几种有代表性的蒸馏方法进行比较,采用不同的骨干网络分别在CIFAR-10/100数据集上进行实验。不同骨干网络在CIFAR-10/100上的top-1错误率见表1。

表1 不同骨干网络在CIFAR-10/100上的top-1错误率
由表1可知, KD-ATFF与其他几种方法相比,top-1错误率有明显降低,能适用于不同网络且能得到良好的分类效果。具体来说,KD-ATFF模型在CIFAR-10上以ResNet-32或MobileNet为骨干网络时,比原始Baseline的top-1错误率降低了约30%;在CIFAR-100上以ResNet-110为骨干网络时,top-1错误率比DML降低了1.57%,比ONE降低了1.31%;以MobileNet为骨干网络时,top-1错误率比DML降低了1.76%;在CIFAR-10上以ResNet-32为骨干网络以及在CIFAR-100上以ResNet-110为骨干网络时,与最新的OKDDip方法相比,top-1错误率都能够与其比肩甚至比其更优。实验结果表明,KD-ATFF提高了模型的泛化性,训练出的模型更加高效,对提升模型准确率有很大的贡献。
2.3 消融实验
为验证CL模块和特征融合模块的有效性,在CIFAR-100数据集上使用ResNet-110为骨干网络进行消融研究,将这2个模块与ONE中的Gate模块进行比较。消融实验结果见表2。由表2可知,当只使用CL模块时的性能已经略超过其他方法。这说明CL模块在不同维度的注意力转移能学习到更多的知识。与ONE中的Gate模块相比,CL的top-1错误率降低了0.76%。FFM与CL模块同时工作时整体模型的改善更为明显。与独立的CL模块相比,top-1错误率降低了1.31%。实验结果表明,CL模块在整体性能改善中发挥了重要的作用,特征融合模块可以明显增强分支间的多样性。
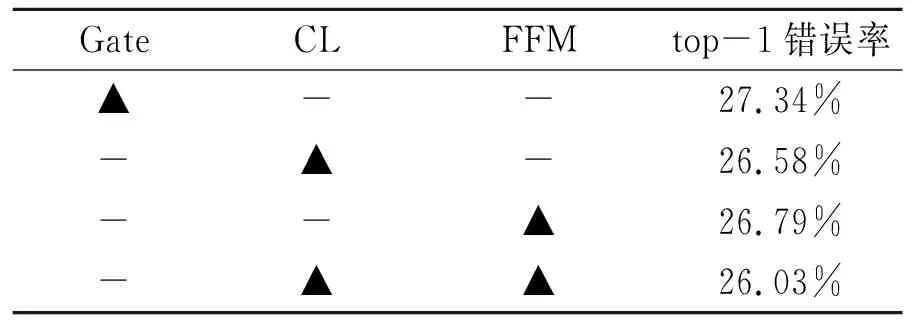
表2 消融实验结果
3 结论
结合注意力转移与特征融合的在线知识蒸馏方法(KD-ATFF)是一种可以在不需预先训练教师模型的前提下训练学生模型的改进在线蒸馏模型。基于模块间的差异性,KD-ATFF引入了注意力机制,让不同维度的模块互相学习,在各子模型的最后1个block的特征输出加入特征融合模块,分配不同权重组成集成教师指导各子模型训练,以提升整体模型的性能。与其他几种代表性的在线知识蒸馏方法相比,KD-ATFF的top-1错误率明显降低,验证了注意力转移和CL模块以及特征融合模块的有效性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
学生天地(2019年28期)2019-08-25
新课程·上旬(2019年1期)2019-03-18
数学物理学报(2018年1期)2018-03-26
传媒评论(2017年3期)2017-06-13
教师·中(2017年3期)2017-04-20
第二课堂(课外活动版)(2016年2期)2016-10-21
试题与研究·教学论坛(2016年27期)2016-08-11
教学研究与管理(2014年4期)2014-05-16
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
