
基于闭环数据供应链的数据产品定价策略研究
2023-02-05 08:27喻海飞黄晋婷
管理工程学报 2023年1期
喻海飞 ,黄晋婷
(1.东北大学 工商管理学院,辽宁 沈阳 110169;2.北京科技大学 经济管理学院,北京 100083)
0 引言
新兴信息技术与应用模式的涌现,使得全球数据量呈现出前所未有的爆发式增长态势[1]。随着大数据的广泛普及和应用,数据资源的价值逐步得到重视和认可,数据交易需求也在不断增加。2017 年《经济学人》强调“世界上最有价值的资源不再是石油,而是数据”[2],诸如Facebook 和Google 这些公司已经将收集和分析用户数据作为他们商业模型的基础,这些公司拥有大量高质量的数据,这“给了他们巨大的能量”[3]。除此之外,还有阿里巴巴、腾讯等公司,作为数据供应商(data provider),他们通常收集原始数据自用或者用来改善自身业务,或者将这些数据销售给第三方数据服务商(data service provider),以获取相应的数据价值;数据服务商将购买的数据加工成数据产品或提供数据服务,最终销售给终端用户(end user)。当前,这种新兴的数据供应链(data supply chain)商业模式,正成为数据经济的重要基础。数据供应链通常包括:1)数据供应商,负责收集、整合、存储和传递数据;2)数据服务商,通过自身或借助外部技术资源,向消费者提供增值后的数据产品;3)终端用户,可以是个人、企业和政府,其购买数据产品指导决策[3]。对于数据产品的定价研究,本研究认为终端用户(包括个人、企业、政府等)作为数据产品的使用者,在使用过程中产生各种数据,就是数据供应商要收集的重要数据源,从而构成一个完整的闭环数据供应链。
目前,对于数据定价的研究尚处于初步阶段,已有的研究主要集中在数据供应商与数据中介或终端用户直接数据交易问题;有关数据供应链的研究,还鲜见报道。数据供应链的定价研究主要包括终端用户与数据供应商,数据供应商与数据服务商,以及数据服务商与终端用户之间等不同数据定价问题。闭环供应链的研究已有大量报道,其定价机制主要包括集中定价、分散定价、收益共享、一致定价和差异性定价等方法,这些方法为研究闭环数据供应链提供了重要的理论基础。例如Wu、Baron 和 Berman[4]提出收益共享模型通常应用在供应链于渠道定价中;Nash[5]、Binmore、Rubinstein和 Wolinsky[6]、Ghosh 和 Shah[7]提出的纳什议价方法。但是由于数据结构、数据质量、数据隐私特性等特征,使得数据在数据供应链中的交易模式区别于传统的供应链,已有的定价机制不能直接应用于数据供应链的定价研究。为此,研究闭环数据供应链中数据定价机制,是本文第一个研究动机。
在当前的数据交易市场中,已有的交易模式主要是按月或按次收取服务费用或进行协议定价的模式,比如,在Aggdata、CustomLists 等数据平台上,交易主要是通过数据供者和消费者线下协商达成的,而Infochimps、Azure DataMarket等则是按月收取订阅费用。Batini 等[8]提出了一个提供关联数据的定价机制,该机制会根据数据消费者的查询,提供不同的数据视图及相应的价格。例如在数据交易平台上,当一个数据被发布,决定该数据集合价值的多个属性均会被展示,在AggData 上,待售的数据集合会显示出记录数、覆盖区域和最近更新时间等属性。Koutris 等[9]发现当前定价数据的机制非常简单,即消费者以特定的价格选择购买一个特定的数据集,并提出满足无套利、无折扣的基于查询的定价机制,以解决自动定价的问题。已有的对于数据及数据产品定价研究,鲜有基于数据本身的价值以及其特征属性来进行定价决策,这也是本文研究的第二个动机。
Heckman 等[10]认为应该关注于数据本身的固有价值,而非数据隐藏的信息的价值,并将定性与定量方法相结合来确定数据的价值,这为本研究提供了一个研究思路。用于数据产品开发的原始数据规模和数据质量是评估数据产品价值的关键因素。在 Xignite 上,数据正是基于数据类型和数据量进行定价。在大数据时代,企业可以轻易地获得 1GB甚至 1TB 的数据,大规模的数据往往意味着更多的信息,如更多的记录数或更多的属性。自二十世纪九十年代中期,数据质量问题就已经引起了学者的兴趣。Wang 和Strong[11]进行了一项两阶段的调查和分类研究,从179 项评价标准中识别了15 个质量维度,并建立了一个层次框架来确定数据的质量特性。在2016 年,Batiniet 和Scannapieco[12]对数据质量维度进行了更加详细的描述,包括:准确性、完整性、冗余,可读性,可访问性,一致性,有用性以及可信度。对于一个公平的数据市场系统来说,最重要的是完整性、准确性、一致性和及时性(或流通性)[13-14]。考虑到大数据价值的稀疏性,大规模的数据并不一定意味着更大的价值,因此还需要同时考虑到数据的质量。数据的价值密度比较低,所以数据规模较大并不等于拥有高价值。目前已有部分学者对数据的质量和规模问题进行讨论,但是将数据的质量与规模问题与数据定价相互关联进行研究的目前鲜有报道。所以在已有学者对于数据的质量与规模特征讨论的基础上,提出第二个重要研究问题,即同时考虑数据质量和规模对闭环供应链中数据产品定价策略的影响。
综上所述,本研究针对闭环数据供应链的数据产品定价策略问题,分析不同利益相关者数据交易过程,提出基于闭环数据供应链的集中定价、分散定价和收益共享三种不同数据定价模型;讨论不同数据定价策略对终端用户提供个人数据质量、规模与激励的影响;探索不同定价策略下的最优定价、数据供应商与数据服务商收益以及消费者剩余。本研究将为数据定价及利益相关者提供有效的决策依据。
1 相关文献探索
虽然在数据市场中,设计一个合适的数据定价模型对于企业和学者来说已经变成一个问题,但是关于数据定价的相关学术研究鲜少出现,尤其是同时考虑在闭环数据供应链中的研究问题、数据质量和规模和激励机制问题等。为此,本文首先回顾本研究领域的一些代表性文章和相关进展。
1.1 闭环数据供应链
对于传统闭环数据供应链的研究,大部分是供应商通过对于消费者用剩产品的回收达到节约环保的作用。而对于数据供应链来说,首先数据供应链是指包含数据相关的供应商、产品开发商和消费者的整个大数据产业链条。Niyato[27]提出大数据市场包含数据供应商、数据服务商和终端消费者,数据服务商从数据供应商购买原始数据,通过数据分析、处理向消费者提供智能数据服务。Jiao 等[16]认为大数据服务是一种面向数据的数据产品,服务质量依赖于原始数据的收集和分析,提出了一种基于拍卖的大数据市场模型。Curry[17]认为大数据市场参与主体主要有:数据供应商,可以是个人或企业,负责生产、收集、整合、存储、传递数据;技术服务商负责利用其掌握的先进数据技术处理数据,提供数据产品;数据平台,作为技术提供商和顾客的桥梁,提供数据产品交易平台服务;终端用户,购买数据产品或数据服务指导决策。Bergenmann 和Bonatti[18]提出了有效的数据供应和数据定价的模型,认为广告商可以通过第三方数据供应商购买消费者个人信息等数据来获取超额收益。本研究认为数据供应链与传统供应链的有其相似和不同之处,如表1 所示。

表1 传统供应链与数据供应链的对比Table 1 Comparison between traditional supply chain and data supply chain
Guijarro 等[26]分析了大数据市场的数据收集、数据分析和交易过程,提出了IoT 信息服务垄断市场中的两阶段定价模型。考虑到竞争关系,Niyato 等[27]利用博弈的观点给出了传感信息市场中的互补、替代服务的定价模型。Kannan 和Kopalle[28]提出由于互动定价机制的广泛应用,其中价格不仅由卖方决定,而是通过买卖双方的互动而发展起来的。讨价还价通常用于供应链或渠道环境[4,15,22]。本研究亦借鉴上述模型,研究数据供应链定价策略。
此外,收益共享契约是数据供应商制定低于其成本的一个批发价格,此时数据服务商为了弥补数据供应商的损失,将自己数据产品的销售收入按照一定比例返还给供应商,最终确保双方的收益水平均高于分散控制状态,使数据供应链的利润均达到最优。这种定价机制被广泛应用于信息产品和一些商业平台的模型中[29]。正如Iyer 和Villas-Boas[37]提到,渠道成员可通过协商来制定定价策略。本研究采用纳什均衡来求解问题,将这种定价机制称之为纳什均衡定价模型。
综上所述,本研究将在闭环数据供应链中应用集中定价、分散定价和收益共享三种不同定价模型,并比较这些定价模型的不同特点,得到最优定价方案。
1.2 数据规模
杨善林和周开乐[30]等认为,一定意义上,大数据资源与煤、石油、天然气等自然资源有一定的相似性,至于其管理特征,则有明显不同。在当前的数据交易市场中,已经存在的交易模式主要是按月或按次收取服务费用或进行协议定价的模式。Balazinska 等[31]提出了一个提供关联数据的定价机制,该机制会根据数据消费者的查询,提供不同的数据视图及相应的价格。大数据重要特性是数据规模巨大,而数据供应商和数据服务商所处理或购买的原始数据规模在很大程度上会影响到加工后得到的数据产品的质量。庞大的数据规模为生产生活创造了巨大的价值;同时面对如此巨大规模的数据资源,人们很难运用传统的数据处理技术和常规的数据管理工具进行数据的开发和处理,这为数据分析、融合和定价等带来了新的挑战。当前对于数据及数据产品的定价,鲜有基于数据本身的价值以及其特征属性来进行定价决策的。
因此,本研究认为数据规模是数据的重要特征之一,数据供应商和数据服务商对于原始数据的加工过程受到数据规模的影响,并且影响着处理后得到的数据产品的质量和定价。
1.3 数据质量
准确、有效地评价数据价值是数据公平交易的前提。Batini 和Scannapieco[12]提出了四种被学术界广泛应用的数据质量维度,即一致性(consistency)、准确性(accuracy)、完整性(completeness)和实时性(timeliness),提出了数据驱动和过程驱动的两种数据质量提升方法,并比较了各自优劣势。Serhani 等[32]提出了一种基于大数据价值链的质量评估方法,将数据驱动的质量评估方法和流程驱动的质量评估方法结合,既评价数据的质量,又评价数据处理流程、方法,并分别给出了完整的数据、流程的质量评价指标和相关评估方法。Naumann[33]将数据质量维度分成四个部分来讨论数据的质量评估问题,内容维度、技术维度、知识维度和数据展现形式维度。随后,Stahl 和Vossen[34]在这四类质量维度的基础上建立了定量评估模型。
由此可知,数据质量是一个非常重要的特性,它直接影响数据产品的质量。数据产品是一种特殊的信息产品,对于数据的依赖、数据的隐私性、频繁的数据更新以及多源数据的集成等等促成了数据产品的特殊性。
本文认为在闭环数据供应链中,数据质量会影响激励的水平。数据供应商为了提高获得的原始数据质量,会对终端用户提供一定的激励,本研究提出线性激励机制模型,认为当终端用户愿意提供更高质量的数据时,数据供应商选择提供更多的激励。
关于大数据经济领域的学术研究尚不成熟,尤其是信息、数据定价[15,35]等相关问题。Lawrence[36]给出了信息价值衡量的一般模型,为信息定价领域做出了重要贡献。作为一种高效的、有利于资源配置的定价方法,拍卖理论[22-24]被广泛地应用于数据定价中。Heckman 等[10]认为数据的价值与众多数据属性相关,用定性定量相结合的方法来确定数据的价值。本文认为,对于数据产品定价是应依赖于数据本身的质量,因此在对于定价模型的构建中,讨论数据质量对于整个模型的影响。
2 模型的建立
本文假设一个双寡头的数据市场,该数据市场中只包含一个数据供应商DP 和一个数据服务商SP,不同的消费者对同一产品有不同的购买意愿(willingness to pay)。章节2.1给出了模型中各符号的定义与说明,章节2.2 给出了闭环数据供应链中各参与者的交易过程。
2.1 符号的定义与说明
为了更加清晰地说明考虑规模的数据产品的定价模型研究,首先对本文的相关符号进行定义,如表2 所示。

表2 相关符号说明和定义Table 2 Key notations and descriptions
对于数据供应商和数据服务商来说,前期用于设施设备建设将投入大量资金并无法回收,也就是说这部分资金作为沉没成本,对数据产品定价策略无影响,因此本研究对此不再讨论。此外,消费者对数据产品质量的偏好程度具有异质性,数据服务商需要确定数据产品质量,而数据产品质量在很大程度上取决于原始数据质量。而一旦数据产品被成功开发,数据服务商“复制”另一份产品,并将它销售给其他数据厂商或用户的成本几乎为零,边际再生产成本可忽略。特殊的数据产品特征以及成本构成,决定了需要特殊的定价策略。
在数据供应商、数据服务商和终端用户的决策过程中,原始数据规模、数据产品的市场需求和数据供应商的供给水平等信息都是公开的。数据供应商(DP)通过激励等一系列措施从终端用户(EU)处获得质量为q1、规模为n的原始数据,经过脱敏处理,去除个人属性后,按一定的价格销售给数据服务商(SP),在这一过程中,产生一定的数据处理成本。欧盟2012 年出台的《European General Data Protection Regulation》、美国1999 年颁布的《听译计算机信息交易法》以及我国不断完善的《民法总则》等法律条例保护用户的个人信息不能被售卖,数据供应商的脱敏处理对于数据服务商SP 期望购买的数据质量无影响。因此我们假设终端用户EU 向数据供应商DP 提供的原始数据规模n和质量q1与数据服务商从数据供应商处购买数据的规模和质量无明显变化。SP 运用自身或者外部的技术资源,对得到的原始数据进行处理,向EU 销售增值后的数据产品,给出数据产品的销售价格。
2.2 闭环数据供应链中各参与者的交易过程
在本节中,将详细说明在如图1 的闭环数据供应链中,数据供应商DP、数据服务商SP 和终端用户EU 之间的相互交易过程,从而更好地建立合理的定价模型。
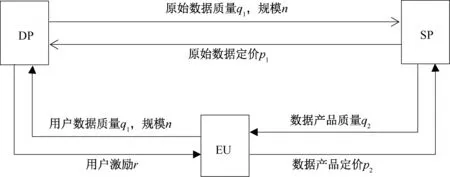
图1 闭环数据供应链示意图Figure 1 Closed-loop data supply chain
2.2.1 数据供应商(DP)的数据供应过程
本研究考虑数据质量和数据规模同时作用下数据产品的定价问题。显然两个具有相同规模的数据集,高质量的数据集比低质量的数据集价值会更高,两者并不能以同样的价格出售。
本研究假设数据产品质量随着原始数据规模的增大而不断增加,且增长率随着原始数据规模的增加而逐渐递减。数据产品质量与原始数据规模之间有Q=f(n),Q≥1 的关系,并且关于n的一阶导数大于等于零f′(n)≥0,二阶导数小于等于零f″(n)≤0。并选取数据产品质量与原始数据规模之间的函数关系为q(n)=。
数据服务商希望可以得到更高质量的原始数据,这样可以简化数据的处理过程,降低数据处理成本,满足终端用户的要求,原始数据质量的提高对于数据产品质量的提高有正向作用。学者Niyato D、Hoang D T[35]在研究物联网传感数据质量对数据服务的影响时,认为数据服务的质量与传感数据质量线性相关,边际服务质量不变,给出Q(s)=qlog(1+s/I),其中Q(s)是服务质量,q是传感数据的质量,I是物联网的传感器总数量,s是参与数据服务开发商合作的传感器数量。本文将沿用这一思想,假设数据产品质量与原始数据质量之间呈线性关系,其关系函数为:

同样的,由于DP 自身设备能力及资源的限制,不能无限地给SP 供应数据。假定DP 给SP 提供的原始数据规模为n,0≤n≤1。
在激励问题中,闭环数据供应链中激励的主体数据供应商DP 对客体终端用户EU 进行激励,激励水平越高,EU 愿意提供数据规模和数据质量都会越大。因此为了获得更大规模、更高水平的原始数据,在本文假设数据供应商DP 为终端用户EU 提供的激励r与原始数据规模n和质量q1之间存在关系,即:

数据供应商DP 通过向SP 销售原始数据和向 EU 提供激励获得利润,其利润函数为:
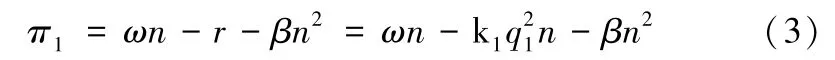
其中,ω为SP 从DP 购买单位数量数据的价格,是DP的决策变量;β是数据供应商DP 的原始数据处理成本系数,处理成本随着数据规模的增加而增大,且增长率不断增加。DP 首先向SP 告知能够提供的原始数据的价格和数据规模,可以计算SP 的利润函数,再以自身利润最大化的原则来确定SP 从DP 购买单位数量数据的最优价格ω。
2.2.2 数据服务商(SP)的数据产品供应过程
在上述的闭环数据供应链中,SP 从DP 购买的数据质量必然会影响数据产品的质量。通常,训练的原始数据越多,机器学习等的准确性就会越好[34-35],从而SP 可以提供的数据产品的质量越高,EU 的购买意愿就越强烈。在这一交易过程中,运用传统的集中定价、分散定价和收益共享三种不同的模型,观察DP 和SP 之间的交易过程,判断三种不同的模型对于DP 和SP 的利润函数以及EU 收益函数的影响,从而确定最优定价模型。
假设终端用户具有垂直差异性,都希望可以得到更高质量的数据产品,但每个终端用户的购买意愿不同。数据服务商仅开发一种数据产品,其质量为q2,销售价格为p,且0
假设数据产品市场中终端用户的总量为单位1,终端用户对于同一个数据产品的购买意愿用θ表示不同的消费者类型,θ服从[0,1]的均匀分布,即θ~U[0,1]。每一个终端用户的决策都是相互独立的。对θ类型的终端用户,其从数据服务商处购买数据产品的效用函数为:

当终端用户的效用函数非负时,会从数据服务商处购买数据产品。此时数据产品的市场需求函数为:
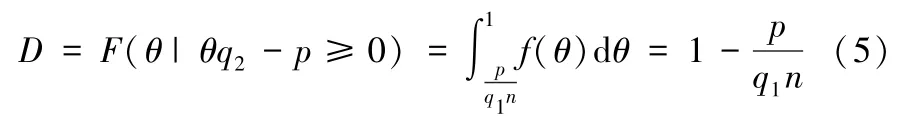
其中,F(θ|θq2-p≥0)表示终端用户的购买意愿大于购买数据产品价格的条件概率;0 是消费者类型θ的概率密度函数。
本文沿用上一节对于边际规模成本递增的假设,当原始数据的规模增加到过大时,数据服务商的数据产品开发成本过高而放弃开发。用γn2(γ >0)来表示数据服务商对于数据产品的开发成本,γ为常量。大规模数据的处理过程是非常复杂的,数据的规模越大,所需的数据处理技术水平也就越高,所以原始数据的规模越大,边际规模成本增速越小。
数据服务商SP 向终端用户出售数据产品获得利润,其利润函数为:

其中,p为向终端用户出售数据产品的价格,D为该数据产品的市场规模;p是SP 的决策变量;pD为SP 出售数据产品的收益;ωn为SP 从DP 处购买原始数据的总价格;γn2为SP 的数据产品开发成本。SP 根据对DP 对于原始数据的报价以及对市场需求的分析,确定对于数据产品的报价,使得利润最大化。
2.2.3 终端用户(EU)的原始数据提供过程
由章节2.2.1,本研究假设数据供应商DP 为终端用户EU 提供的激励r与原始数据规模n和质量q1之间存在关系,即:
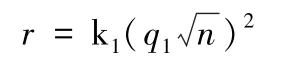
此外,终端用户EU 在向数据供应商提供原始数据时,由于个人数据携带部分个人信息等,使EU 产生包括个人隐私成本在内的一系列成本,且个人提供数据成本与数据质量成本是非线性关系,终端用户提供的数据越多,其所包含的数据信息更丰富,因而数据的质量更高,本文假设两者关系为平方形式;用户提供的数据越多,数据成本也越高,假设个人数据成本与数据规模之间的关系是线性的。因此本研究假设终端用户EU 为DP 提供个人数据成本c与原始数据规模n和质量q1之间存在如下关系:

对于终端用户而言,通过向数据供应商DP 出售个人数据获得消费者剩余,包括终端用户EU 从数据服务商SP 处购买数据产品的效用和EU 出售个人数据的总效用,其消费者剩余为:

其中,θq2-p表示终端用户EU 从数据服务商SP 处购买数据产品的效用函数;r表示数据供应商DP 为终端用户EU 提供的激励;c为终端用户EU 为DP 提供原始数据时的成本。
3 闭环数据供应链的定价机制研究
本文结合上一章节中提出的闭环供应链中各参与者的交易过程,利用集中定价、分散定价和收益共享三种定价机制,进行求解和初步分析,并讨论不同的定价机制对不同利益相关者的影响,从而得出相应的管理启示。
3.1 集中定价模型的分析
3.1.1 集中定价模型中的数据产品定价
本文以数据供应商、数据服务商和终端用户组成的三级闭环数据供应链为基础,在集中的数据供应链中,数据供应商直接向数据服务商收取原始数据的订购价格为ω,数据服务商向终端用户收取数据产品的订购费用为p。本研究将这两个参与者之间的相互作用建立为一个两阶段博弈,其中数据供应商对于原始数据的零售价格ω的决策为第一阶段,数据服务商对于数据产品订购价格的决策为第二阶段。该模型可表示为:

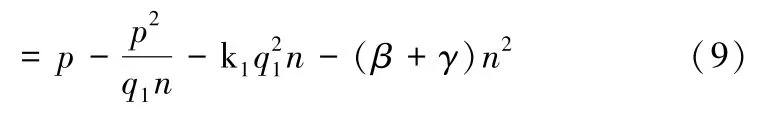
对决策变量数据产品的价格p 求一阶偏导数,得:

再对p 求二阶偏导数,得到:

所以,二阶偏导数严格小于零,所以存在极大值。根据一阶偏导数等于零,得:

式(10)表达了SP 的决策变量p和n,q1之间的关系。将上式代入(9)中得到供应链的总利润函数,可得:

总利润分别对n,q1求一阶偏导数,得:
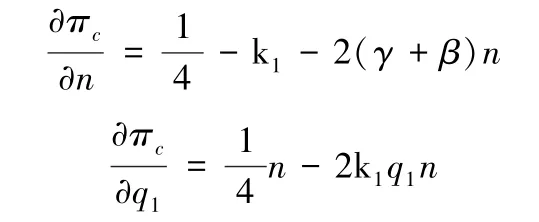
对两个决策变量求二阶偏导数,得:

可见两个决策变量的二阶偏导数都是严格小于零的目标函数maxπc具有凸性,存在唯一的全局最优解。根据一阶导数等于零,

原始数据规模n与数据质量q1分别为:
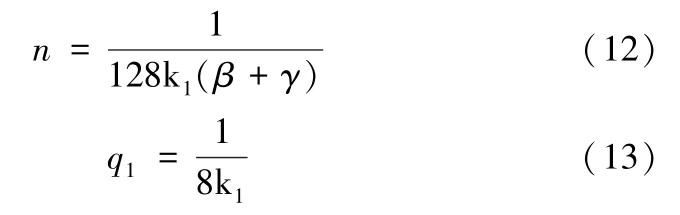
此时,SP 数据产品最优定价为:
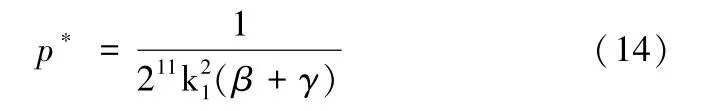
可得,终端用户消费者剩余为:
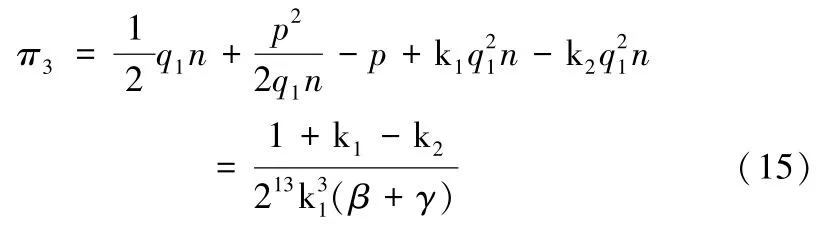
数据供应链的总利润函数:

对于数据服务商SP 来说,数据产品的订购费用p受到激励系数、数据处理成本等参数的影响,可得命题1。
命题1激励系数k1、数据处理成本系数β,γ与原始数据规模n 成反比,与数据服务商SP 开发的数据产品的订购费用p 成反比;激励系数与k1与原始数据质量q1成反比。
证明:由式(12)(13)和(14)可知,终端用户EU 提供的数据规模n=,原始数据质量q1=,数据服务商SP 开发的数据产品的订购费用p=。由上式可知,当数据处理成本系数β、数据服务商的数据处理成本系数γ和DP 的激励系数k1增加时,原始数据规模n和SP开发的数据产品的订购费用p均减少;数据供应商DP 的原始数据处理成本系数β、数据服务商的数据处理成本系数γ和DP 的激励系数k1对于原始数据规模n和SP 开发的数据产品的订购费用p均有负面影响;当DP 的激励系数k1增加时,原始数据质量q1减少。
3.1.2 集中定价模型中的供应链总利润
命题2数据供应链的总利润与激励系数k1、数据处理成本系数γ,β成反比。
证明:由数据供应链的总利润函数:

上式可知,当β,γ增加时,πc减小;当激励系数k1增加时,πc也会减小。无论SP 的数据处理成本系数γ还是DP的数据数据处理成本系数β,以及激励系数k1都会对供应链总利润函数造成负面影响。命题得证。
3.1.3 集中定价模型中的消费者剩余
命题3消费者剩余与DP 的激励系数k1、终端用户的成本系数k2、数据处理成本系数β,γ成反比。
证明:由章节3.1.1 可得,终端用户EU 的消费者剩余π3:
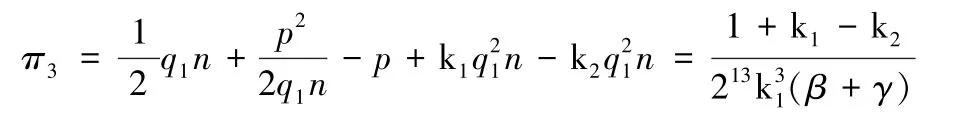
上式可知,当β,γ增加时,终端用户的消费者剩余π3减小。无论SP 的数据处理成本系数γ还是DP 的数据数据处理成本系数β,都会对消费者剩余造成负面影响;当DP 的激励系数k1增加时,消费者剩余π3减小;当终端用户的成本系数k2增加时,消费者剩余π3减小。
3.2 对分散定价模型的分析
3.2.1 分散定价模型中的数据产品定价
本节以数据供应商、数据服务商和终端消费者构成的三级闭环数据供应链为基础,考虑SP 和DP 之间的原始数据交易过程、SP 和EU 的数据产品交易过程,将最终的数据产品定价问题表述为一个领导者(DP)和一个跟随者(SP)的Stackelberg 博弈模型。在第一层,DP 向SP 出售原始数据,给出原始数据的销售价格;在第二层,SP 从DP 处购买原始数据,向EU 销售数据产品,给出数据产品销售价格。其中DP 从EU 处收集原始数据,决定数据质量q1和规模n。该模型可表示为:

首先,本研究假定SP 知道DP 给出的原始数据的定价、数据质量和规模水平。在向EU 出售数据产品的过程中,优化数据产品质量和对数据产品的定价,接受EU 的消费反馈,考虑其购买意愿,给定合理数据产品销售价格p。然后DP在决策时预见SP 的反应函数,根据利益最大化原则决定原始数据的销售价格和质量水平。该Stackelberg 博弈模型以数据供应商为领导者,数据服务商为跟随者,体现了在大数据及其指导的电子商务环境下,数据的拥有者扮演着越来越重要的角色。同时,该模型将原始数据的规模和质量都考虑到了产品开发的过程中,与各参与者的成本相关联,体现了数据规模和质量对数据产品设计的影响以及数据的基本特征。
根据(18)可得SP 的利润函数为:

分别对决策变量数据产品的订购价格p和原始数据规模n求一阶偏导数,得:
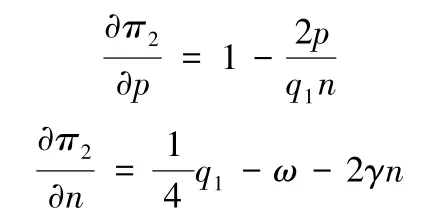
同时,再分别对两个决策变量求二阶偏导数,得:

由此可知,两个决策变量的二阶偏导数都是严格小于零的,目标函数具有凸性,即存在唯一全局最优解。根据一阶偏导数为零,

式(20)和(21)分别表达了SP 的两个决策变量p、n和DP 的决策变量q1、ω之间的数量关系。将上式带入(17)中可以得到DP 的利润函数为:

DP的利润函数π1分别对两个决策变量q1和n求一阶偏导数,得:
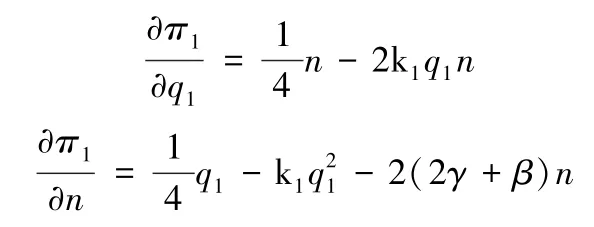
同时,再分别对两个决策变量求二阶偏导数,得:


可见两个决策变量的二阶偏导数都是严格小于零的。所以,当数据规模n为固定时,最优数据质量q1是全局最优解;当数据质量q1为固定值时,最优数据规模n是全局最优解。所以目标函数maxπ1 具有凸性,存在唯一的全局最优解。根据一阶导数等于零,
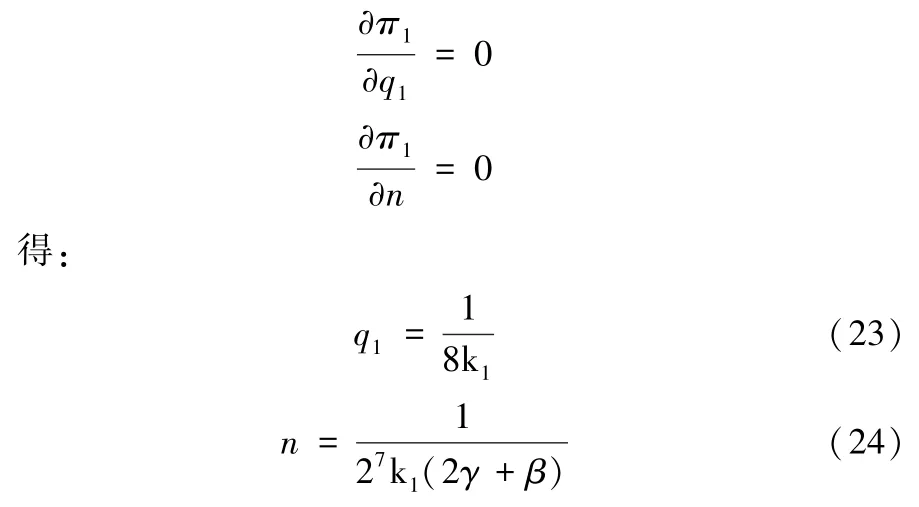
此时,有:
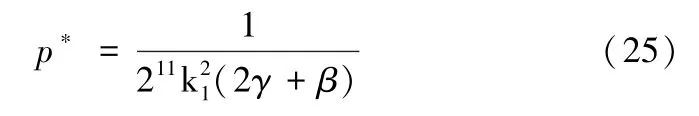
所以,数据供应商的定价ω 为:
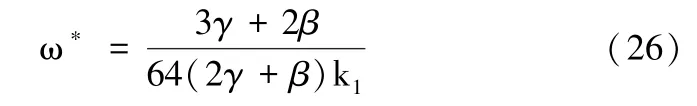
此时,DP 的利润函数为:

SP 的利润函数为:

终端用户的消费者剩余为:

对于SP 和EU 来说,数据产品定价p2将会影响他们的最终收益和购买成本,因此可以得到如下命题4。
命题4激励系数k1、数据处理成本γ,β与终端用户EU提供的数据规模n成反比;与数据服务商SP 开发的数据产品的订购费用p成反比。
证明:由式(4.23)(4.24)(4.25)可知,终端用户EU 提供的数据规模n=,数据质量q1=,数据服务商SP 开发的数据产品的订购费用p=。由上式可知,当原始数据处理成本系数β、数据服务商的数据处理成本系数γ和DP 的激励系数k1增加时,原始数据规模n和SP 开发的数据产品的订购费用p均减少;当DP 的激励系数k1增加时,原始数据质量q1减少。
3.2.2 分散定价模型中DP 的利润函数
命题5激励系数k1、数据处理成本系数β,γ对单位原始数据定价ω的影响如下:
(1)当激励系数k1增加时,单位原始数据的定价ω减小;
(2)数据供应商的数据处理成本系数β增加,ω增加;
(3)数据服务上的处理成本系数γ增加,ω减小。
证明:由式(23)(24)可得,单位原始数据定价ω=。分别对β,γ求一阶偏导数,可得:
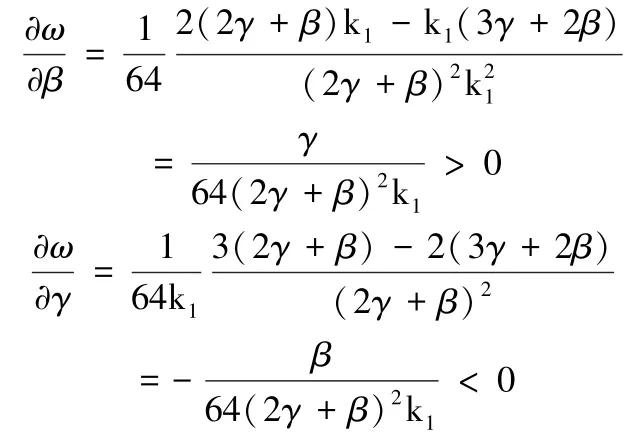
所以,对于ω有:当激励系数k1增加时,单位原始数据的定价ω减小;数据供应商的数据处理成本系数β增加,ω增加;数据服务上的处理成本系数γ增加,ω减小。
3.2.3 分散定价模型中的消费者剩余
命题6消费者剩余与DP 的激励系数k1,终端用户的成本系数k2,和数据处理成本系数β,γ成反比。
证明:由章节3.2.1 可以得到,终端用户EU 的消费者剩余π3:
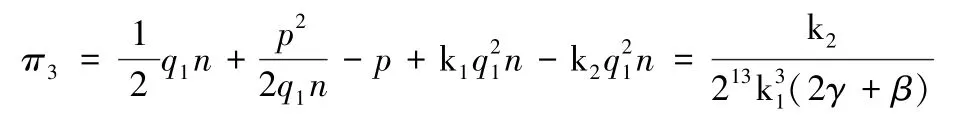
由上式可知,当β,γ增加时,终端用户的消费者剩余π3减小。无论SP 的数据处理成本系数γ还是DP 的数据数据处理成本系数β,都会对消费者剩余造成负面影响;当DP 的激励系数k1增加时,消费者剩余π3减小;当终端用户的成本系数k2增加时,消费者剩余π3增大。
3.3 对收益共享模型的分析
3.3.1 收益共享模型中的数据产品定价
利用收益共享模型,假设DP 与SP 之间的利润共享率为α,且α∈(0,1),即SP 将销售收入的α返还给DP。因此SP 的利润函数为:

数据供应商DP 的利润函数为:
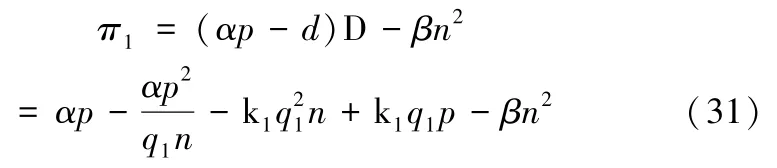
本节仍旧考虑SP 和DP 之间的原始数据交易过程、SP和EU 的数据产品交易过程,将最终的数据产品定价问题表述为一个领导者(DP)和一个跟随者(SP)的Stackelberg 博弈模型。在第一层,DP 向SP 出售原始数据,给出原始数据的销售价格;在第二层,SP 决定从DP 处购买原始数据的规模,并且向EU 销售数据产品,给出数据产品销售价格。该模型可表示为:
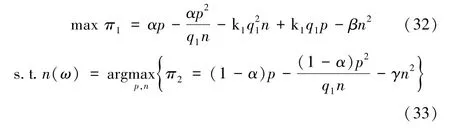
首先,DP 向SP 销售原始数据,给出原始数据的销售价格;SP 决定购买原始数据的规模,向EU 出售数据产品,给出数据产品销售价格。DP 在决策时能够预见SP 的反应函数,根据利益最大化原则决定原始数据的销售价格。
根据式(33)可得SP 的利润函数为:

对决策变量数据产品的订购价格p求一阶偏导数,得:
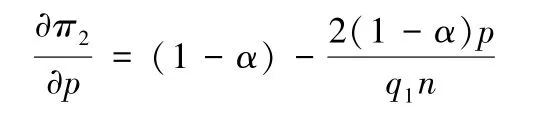
同时,再对决策变量求二阶偏导数,得:
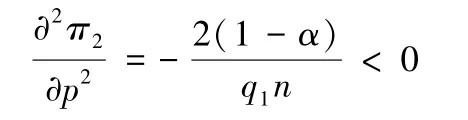
由此可知,决策变量的二阶偏导数是严格小于零的。所以目标函数具有凸性,即存在唯一全局最优解。根据一阶偏导数为零,

式(35)表达了SP 的两个决策变量p、n和原始数据质量q1之间的数量关系。将上式带入(14)中可以得到DP 的利润函数为:

对决策变量原始数据规模n和质量q1分别求一阶偏导数,得:
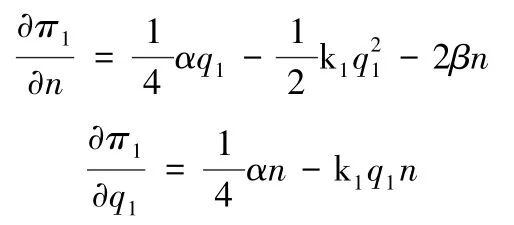
同时,再分别对决策变量求二阶偏导数,得:
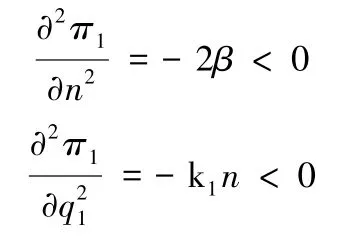
由此可知,两个决策变量的二阶偏导数都是严格小于零的,目标函数具有凸性,即存在唯一全局最优解。根据一阶偏导数为零,
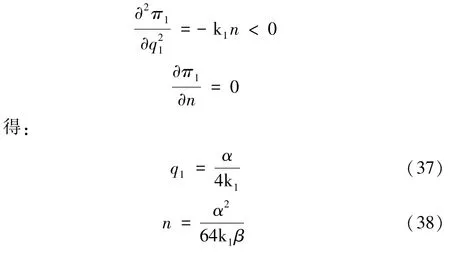
此时,有:

此时DP 的利润函数为:

SP 的利润函数为:

对决策变量收益共享率α求一阶偏导数,得:

同时,再对决策变量求二阶偏导数,当α <时,得:

此时,决策变量的二阶偏导数是严格小于零的。所以目标函数具有凸性,即存在唯一全局最优解。根据一阶偏导数为零,

将式(42)代入DP 的利润函数式(40)、SP 的利润函数式(41)和终端用户EU 的消费者剩余式(8)中,得,数据供应商的利润函数:

数据服务商的利润函数:
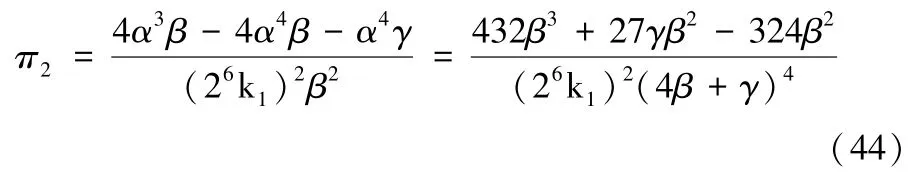
消费者剩余:
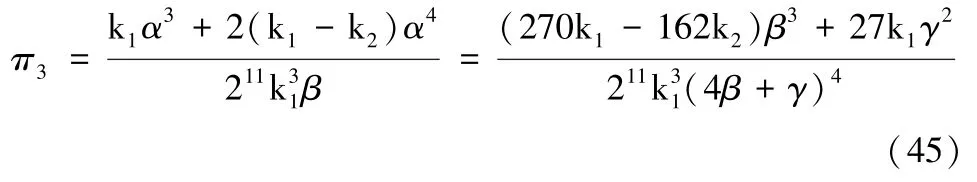
对于SP 来说,数据产品的订购费用p会受不同参数的影响,因此得到如下命题7。
命题7激励系数k1、数据处理成本系数β与终端用户EU 提供的数据规模n成反比,与数据服务商SP 开发的数据产品的订购费用p成反比;数据供应商DP 与数据服务商SP之间的利润共享率为α与终端用户EU 提供的数据规模n和数据质量q1成正比,与数据服务商SP 开发的数据产品的订购费用p成正比;激励系数k1和数据质量q1成反比。
证明:由式(37)(38)和(39)可知,终端用户EU 提供的数据规模n=,数据质量q1=,数据服务商SP 开发的数据产品的订购费用p=,可得,当收益共享比率增加时,原始数据规模n和数据服务商SP 开发的数据产品的订购费用p均增加;当激励系数k1或数据处理成本系数β增加时,终端用户EU 提供的数据规模n和数据服务商SP 开发的数据产品的订购费用p均减小。当收益共享率α增加时,原始数据质量q1增加;当激励系数k1增加时,原始数据质量q1减小。
3.3.2 收益共享模型中的消费者剩余
命题8消费者剩余与DP 的激励系数k1成正比;与终端用户的成本系数k2、数据处理成本系数β,γ成反比。
证明:由章节3.3.1 本研究可以得到,终端用户EU 的消费者剩余π3:
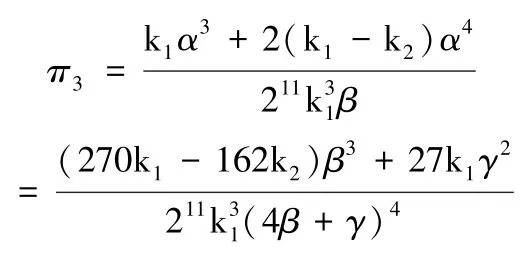
由上式可知,当k1增加时,终端用户的消费者剩余π3增加;当β,γ或k2增加时,消费者剩余π3减小。无论DP 的数据处理成本系数β、SP 的数据处理成本系数γ和终端用户的成本系数k2均会对消费者剩余造成负面影响。
3.4 不同定价模型的比较分析
3.4.1 不同定价模型中数据供应商利润比较
由3.2.1 可得,在分散定价模型中DP 的利润函数为:
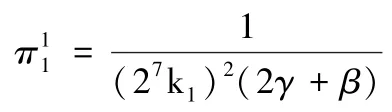
由3.3.1 可得,在收益共享定价模型中DP 的利润函数为:
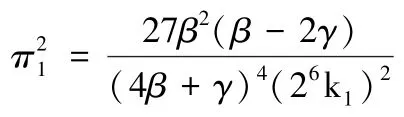
因为:
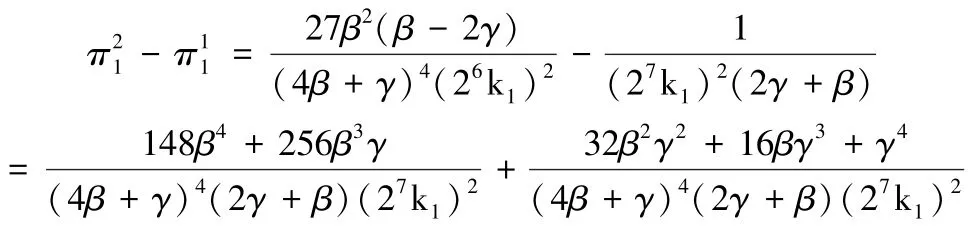
3.4.2 不同定价模型中数据服务商利润比较
由3.2.1 可得,分散定价模型中SP 的利润函数为:
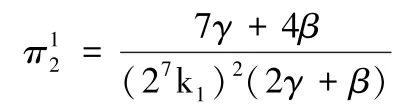
由3.3.1 可得,收益共享定价模型中SP 的利润函数为:
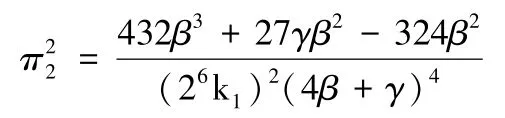
因为:

令:
f(γ)=1024β5+2816β4γ+1920β3γ2+288β2γ3+116βγ4-432β4+324β3-891β3γ+648β2γ-56β2γ2
对其进行最优解计算,得到f随γ的增大而增加,此时也有>0 恒成立。
3.4.3 不同定价模型中消费者剩余比较
由3.2.1 可得,分散定价模型中EU 的消费者剩余:
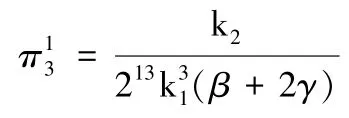
由3.3.1 可得,收益共享模型中EU 的消费者剩余:
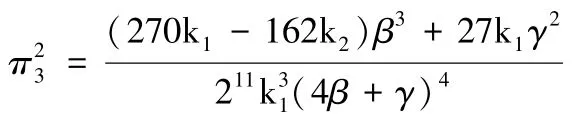
由3.1.3 可得,集中定价模型中EU 的消费者剩余:
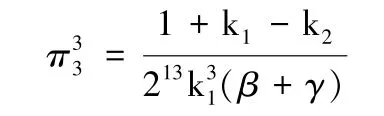
考虑激励水平系数k1和终端用户的隐私成本系数k2对消费者剩余的影响,将上述三种定价模型中的消费者剩余分别对k1,k2求一阶导数,得到<0,且研究激励水平系数k1对消费者剩余的影响时,有;研究终端用户的隐私成本系数k2对消费者剩余的影响时,有。由此可得,对于终端用户而言,当数据供应商与数据服务商之间采取分散定价模型时,消费者剩余最高。在三种定价模型中,消费者剩余均随激励系数k1的增加而减小;在分散定价模型中,消费者剩余随终端用户的成本系数k2的增加而增大,在分散定价和收益共享模型中,消费者剩余随终端用户的成本系数k2的增加而减小。
4 结束语
本文针对闭环数据供应链数据产品定价策略问题,分析不同利益相关者数据交易过程,提出了基于闭环数据供应链的集中定价、分散定价和收益共享三种不同数据定价模型;讨论不同数据定价策略对终端用户提供个人的数据质量、规模与激励的影响;并得到不同定价策略下的最优定价、数据供应商与数据服务商的收益以及消费者剩余。本研究主要得到以下结论:
首先,根据原始数据的规模和质量特性,从闭环数据供应链的角度研究了数据定价机制。本研究分析了原始数据质量和规模在不同定价机制下对于数据供应链中各参与者收益的影响。对数据供应商DP 来说,选择收益共享定价模型时利润更高。而对数据服务商SP 而言,选择分散定价模型时利润更高。在分散定价的定价机制中,提高原始数据质量与规模于数据供应商而言会增加成本,而对数据服务商而言会提高其利润,因此需要取使两者都相对获利的最优值。最后在收益共享机制中,本研究认为数据供应商要对数据服务商进行补贴,对利润进行合理的分配,这样才能使双方的利润都达到最优状态。其次,研究了激励机制中激励水平对于数据供应链中各参与者的影响。本研究发现,对于终端用户而言,激励水平越高,消费者剩余会降低;对于数据供应商和数据服务商来说,激励水平越高,利润增加,且利润增加得越快。最后,本研究将数据特性和激励机制的问题融入数据产品的定价机制中,丰富了相关的研究,同时也对数据市场中数据交易和数据定价等相关问题具有一定的指导作用。
本文研究局限性在于,简化了数据质量与数据规模等大数据特征,未考虑闭环数据供应链利益相关者不对称信息对数据交易的影响等,这方面的问题有待下一步深入研究。
猜你喜欢
China Report Asean(2022年8期)2022-09-02
军民两用技术与产品(2022年3期)2022-06-05
福建江夏学院学报(2021年6期)2021-08-10
物联网技术(2020年12期)2021-01-27
汽车零部件(2017年4期)2017-07-12
中国新通信(2016年21期)2017-01-06
中国新通信(2016年2期)2016-03-11
中国期刊年鉴(2015年0期)2015-01-19
软件和集成电路(2014年7期)2014-12-31
中国石油石化(2013年5期)2013-05-03
