
基于Stacking集成学习的区块链异常交易检测技术研究
2023-02-17 05:32王志强王姿旖倪安发
信息安全研究 2023年2期
王志强 王姿旖 倪安发
(北京电子科技学院 北京 102627)
区块链技术和数字货币的兴起颠覆了传统的交易模式,同时也导致许多交易安全问题,严重威胁经济社会的发展和用户资产安全.近年来,区块链交易安全事件层出不穷,如洗钱、勒索病毒、智能合约攻击和双花攻击等.
目前,针对区块链交易的安全研究是区块链研究的热门问题,国内外研究人员虽然提出了不同的异常检测方法,也取得不错的检测效果,但仍存在数据分布不均衡导致模型表现不好、特征选择方法过于粗糙等问题.因此针对极度不平衡数据集,本文基于Stacking算法设计了MLP_Stacking算法,结合SUNDO重采样技术平衡数据集,设计多模型联合特征排序法进行特征选择,并利用网格搜索算法优化模型,提高了异常交易检测的效率,为实现区块链异常交易检测研究提供了一定的参考价值.
1 相关工作与技术
1.1 相关工作
区块链交易是一种逐渐兴起的新型交易范式,基于区块链技术的共识机制以及分布式特点,能够在无可信第三方的环境下进行交易行为,用户的所有操作包括交易记录将会被安全地存储在区块中,具有去中心化、不可篡改、公开透明的特点,被广泛运用于金融交易、工业管理和医疗数据共享等场景中,为新的商业模式和新颖的分布式应用程序铺平道路.伴随着区块链应用在各行各业的井喷式涌现,如何在区块链金融应用中实现快速的异常交易检测成为当前研究的热点.
国内外研究人员针对区块链交易安全问题提出了不同的异常检测方法.2019年,Sayadi等人[1]提出了一种新的比特币电子交易异常检测模型,使用了2种机器学习算法,即单类支持向量机(OCSVM)算法来检测异常值,以便将具有相同异常类型的相似异常值进行分组,通过实验表明,该模型能获得高度精确的检测结果.2021年,Voronov等人[2]提出了几种有效的基于Sketch的异常检测和攻击缓解解决方案,通过识别单笔高价值交易、交易频率或交易总量来检测可疑账户的异常情况,与全数据方法相比,该算法在不影响检测精度的情况下显著减少了内存占用空间和运行时间.2022年, Fan等人[3]设计了一个轻量级和标识符模糊的模型LION用于加密货币网络的异常检测,利用流量分析使其对挖掘速率的影响最小,并且其计算效率大大优于以前的机器学习方法,他们在一个活跃的比特币节点搭建了LION原型,成本最低,为最先进的机器学习方法的12%,并且检测精确度大于97%.2022年, Jin等人[4]针对区块链交易中的庞氏骗局提出了通用异构特征增强模型HFAug,该模型在一个辅助的异构交互图中学习基于元路径的行为特征,并将异构特征聚合到同构图里对应的账户节点中,最后执行庞氏检测方法,综合实验结果表明,HFAug可以帮助现有的庞氏检测方法在以太坊数据集上实现显著的性能改进,体现了异构信息在区块链庞氏骗局检测中具有高效性.
1.2 相关技术
1.2.1 LightGBM
GBDT(gradient boosting decision tree)是机器学习中被广泛运用的一个模型,能够利用多个弱训练器迭代训练得到一个训练效果好、不易过拟合的最优模型,2018年杜炜等人[5]使用GBDT算法提升了安卓恶意软件检测效率.LightGBM(light gradient boosting machine)是对传统GBDT算法的一种改进,由微软亚洲研究院在NIPS系列论文[6-7]中提出,常应用于多分类、点击率预测、搜索排序等机器学习任务中,支持高效率并行训练,比其他框架内存消耗更小、训练速度更快、准确率更高.
LightBGM对GBDT算法的优化有:基于直方图改进决策树算法[6];采用带深度限制的Leaf-wise算法[6,8];使用单边梯度采样技术在减少数据量的同时平衡精确度[6,8-9];对互斥特征进行捆绑减少特征维度[6,10-11];直接支持类别特征[7,10,12];支持高效并行[7]与缓存优化[7,13].
1.2.2 XGBoost
XGBoost(extreme gradient boosting)是由华盛顿大学Chen等人[14]提出的一种端对端的可以大规模并行计算的梯度提升树模型,XGBoost分别在算法层面和系统设计层面对GBDT进行了改进.
在算法层面,XGBoost在目标函数中对优化目标使用二阶求导,使得优化目标的定义范围缩小,加快了模型迭代速度,还利用正则项控制模型的复杂度以防过拟合现象出现.此外,XGBoost对缺失值处理进行了优化,使用稀疏感知算法自动处理缺失值,在生成树时对划分节点的选取利用加权分位数草图算法减少了时间消耗.在系统设计层面,XGBoost采用块结构存储不同的特征并进行排序,使XGBoost能够在不同的线程中进行并行训练,大大加快训练速度[15].
1.2.3 CatBoost
CatBoost(gradient boosting + categorical features)[16]是一款以对称决策树(oblivious trees)为基学习器的GBDT拓展框架,它能够支持类别性变量,减少了对非数值型特征进行预处理的繁琐步骤.还能够组合类别特征,使得特征之间的关系成为一个新的特征属性,解决属性较少的训练集特征维度不够的问题.CatBoost还使用排序提升方法对数据集中的噪声点进行过滤,有效缓解了最终模型预测偏移的问题.
1.2.4 LCE
LCE(local cascade ensemble)[17]是一种基于集成方法中处理偏置-方差权衡的新型机器学习方法,结合了随机森林与XGBoost的优势,能够获得更优的泛化预测期,实现对目标的精准预测.LCE的基分类器一般是基于boosting的分类器,用以减少决策树分治过程的误差.boosting分类器沿着树的路径将基分类器正确率作为新属性添加到数据集中,在下一树级中利用该正确率对下一树级的特征进行加权计算,对之前错误分类的特征加以标记用于下一轮训练.此外,LCE利用bagging缓和了boosting决策树的过拟合现象.
1.2.5 MLP
MLP(multi-layer perception)[18]也称为人工神经网络,是对生物神经元的模拟和简化,分别由输入层、输出层和隐藏层组成,其中隐藏层可能有多层,被广泛用于数据和图像分类的监督型机器学习模型中.隐藏层和输出层的神经元与其前一层的神经元相连,这种拓扑结构中的网络连接可以是完全连接的或部分连接的.在MLP神经网络中,每个单元对输入执行一个偏加权和,并通过传递函数来产生输出.
2 基于Stacking集成学习的区块链异常交易检测模型
本文设计的集成模型如图1所示,包含3个模块,分别是数据预处理模块、特征选择模块和异常检测模块.
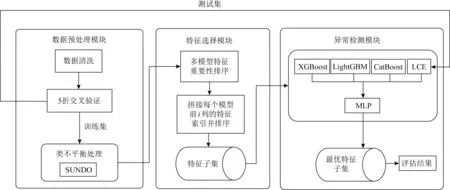
图1 MLP_Stacking集成模型
2.1 数据预处理模块
本文实验使用Kaggle平台提供的Credit Card Fraud数据集,该数据集包含了8 950个账户在过去6个月中的交易行为,共21个标识,其中20个为特征,1个为标签.数据集中正常账户被标记为0,异常账户被标记为1. 表1为该数据集变量说明:

表1 Credit Card Fraud数据集变量说明
本文采用k折交叉验证[19]的思想,将数据划分为k份,其中k-1份用来训练,1份用来测试.直到每份数据都进行了测试.本文采用重复的分层抽样的k折交叉验证,分层抽样是对每个类均按照一定比例抽取数据,本文中的k取5,重复次数为3.
2.1.1 数据清洗和相关性分析
本文通过数据清洗去除空数据样本,进行数据类型转换,得到干净样本,此时剩余8 497条数据.经数据分析发现,数据中存在activated_data和last_payment_data这2个字符串类型的字段,表示信用卡激活和上次使用信用卡支付的时间,将这2个字符串转换成时间变量,并求得用户使用信用卡时长diff_days,作为新的特征,加入到原特征集中.由图2可知,正常账户的用户使用信用卡时间分布较为分散,而异常账户的用户使用信用卡时间较为集中,由此猜测异常交易是集中在某一时间段成规模发生的.同时,经过对正常账户的用户使用信用卡时长和异常账户的用户使用信用卡时长统计分析,发现存在负的时间,不符合现实中的逻辑,将负的时间样本作为异常样本去除.
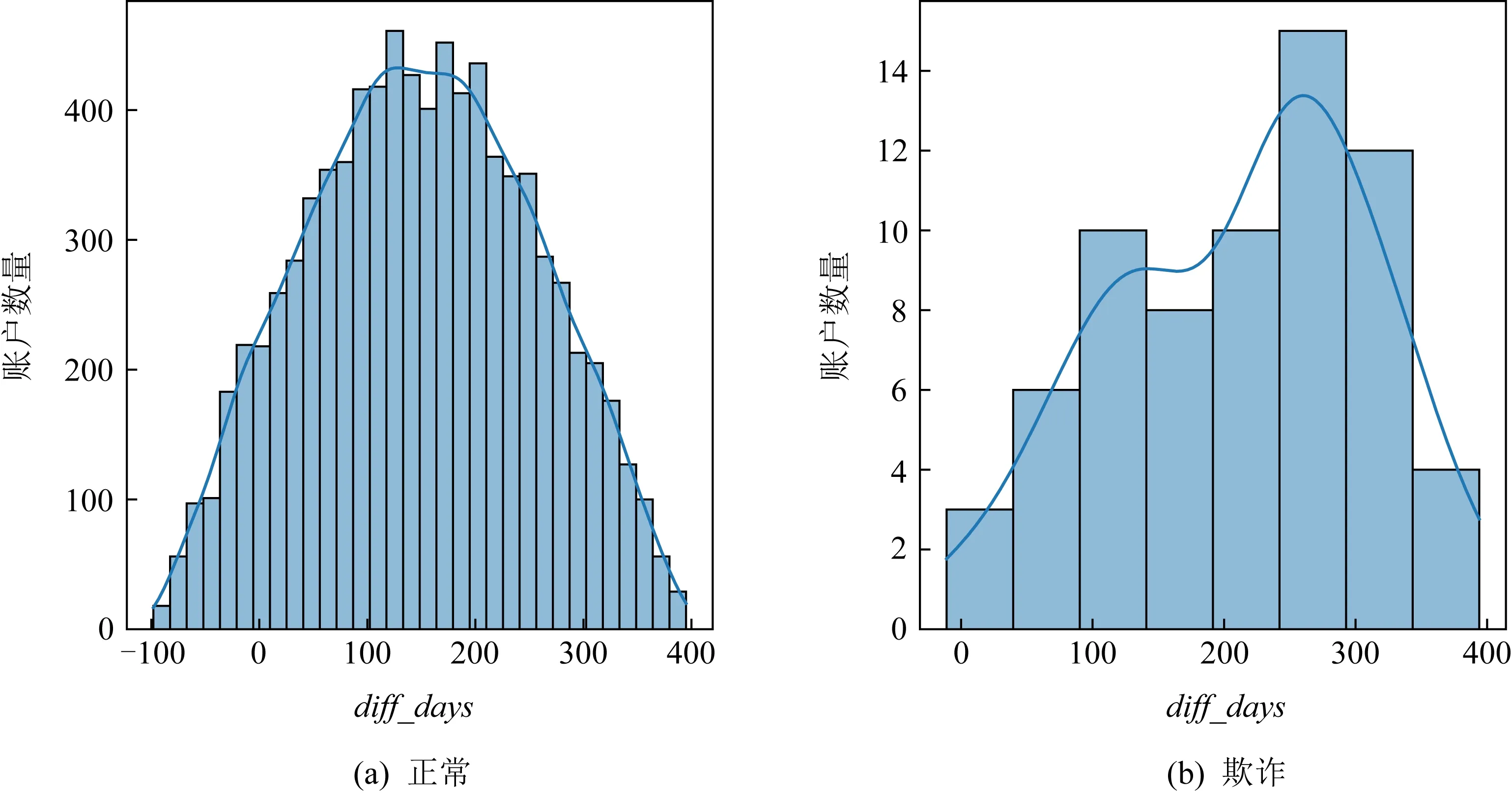
图2 用户使用信用卡时长分析
对特征进行归一化后进行相关性分析,图3所示的热力图表示各变量之间的相关性,由于本文检测目标是区块链交易异常,所以更加关注每个变量与异常变量的相关性,与异常变量正相关性较高的是用户完成的付款金额(相关性权值为0.53)和一次性完成的最大购买金额(相关性权值为0.48),由此推断用户完成的付款金额对预测异常账户最相关.先初步假设所有变量对于测试中发现异常都是重要的.

图3 连续数值变量之间的相关性分析
2.1.2 类不平衡处理
如图4所示,数据集存在严重的类不均衡现象,异常账户仅占样本集的0.85%,而类样本分布不均衡会影响分类算法性能,降低模型性能.

图4 账户类型分布
常用的处理方法分为过采样和欠采样.欠采样是指减少大样本的数量,使之与小样本数量达到均衡状态.但很明显欠采样并不适合当前样本,因为欺诈交易数量本来就很少,若采用欠采样会大大减少样本总数,起不到训练模型的作用.本文采用一种结合过采样和欠采样技术的新型重采样技术(SUNDO)[20]对数据进行扩充.该方法结合了欠采样技术和过采样技术,通过欠采样移除的样本量等于通过过采样添加的样本量,因此既不会丢失大量信息同时也不会添加过多的合成数据.计算公式如式(1)所示:
N=round[(0.5·n0)-(0.5·n1)],
(1)

1) 基于正态分布的过采样.
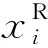
(2)
(3)
2) 基于相似性的欠采样.
首先使Xo条目对其自身的最大值进行静态归一化,得到变换矩阵π,其中第k行和第j列的条目计算如下:
(4)
通过计算π各列之间的欧氏距离,得到1个对称的平方距离矩阵DI,该DI在第p行和第q列处的计算如下:
(5)
DIp,q越小,Xp和Xq这2种模式就越“相似”,根据相似性指数对模式对进行排序,消除最相似模式对里的其中1个模式,此过程完成欠采样且没有显著丢失原始类分布的信息.
2.2 特征选择模块
XGBoost,LightGBM,CatBoost,LCE 都是基于决策树构建的模型,拥有天然的特征排序功能.特征J的全局重要度[21]是特征J在单棵树中的重要度的平均值,计算公式如式(6)所示:
(6)
其中M是树的数量.特征t在单棵树中的重要度[12]如式(7)所示:
(7)
其中L为树的叶子节点数量,L-1即为树的非叶子节点数量(构建的树都是具有左右孩子的二叉树),vt是和节点t相关联的特征.
本文基于基模型特征重要性排序结果,设计多模型联合特征排序算法,生成最优特征子集.算法基本思路为:每次特征排序时都会对每个特征进行打分,将得分高的特征排在前面,得分低的排在后面.每个基分类器都重复排序100次,防止只进行1次排序导致的随机性影响结果可靠性.第1次训练选择第1列中出现次数最多的特征进行分类,输出结果;第2次选择前2列中出现次数最多的2个特征进行分类,输出训练结果……以此类推直至训练完所有特征.多模型联合特征排序算法伪代码如算法1所示:
算法1.多模型联合特征排序.
输出:最优特征子集S.
① fori=1 tondo
③ 利用特征子集从原始数据集D中获得数据集D′;
④ 利用集成模型获得D′的分类指标metrici;
⑤ end for
⑥Metric∈{metric1,metric2,…,metricn};
⑦Ind∈{ind1,ind2,…,indn};
⑧ 输出max(Metric)所对应的特征子集S∈Ind.
算法1结束时,将获得400个特征排序表,可以联合构建18个特征子集.为了确定最优特征子集,使用AUC,F1,G-mean作为评价指标,采用5折交叉验证获得每个特征子集的评价指标值,将得分最高的子集作为最优特征子集.
2.3 异常检测模块
2.3.1 MLP_Stacking算法设计
本文将基于XGBoost,LightGBM,CatBoost,LCE分别对处理后的数据集进行建模并预测类别,然后基于Stacking的思想,将4种模型的预测结果进行编码作为新的样本输入,将初始数据集的标签作为新的样本标签,在其上训练MLP模型,通过MLP模型对基模型的预测结果分配权重,目的是实现4种算法的融合以取得更好的分类效果.图5是MLP_Stacking算法流程图:

图5 MLP_Stacking算法流程图
2.3.2 基于网格搜索的参数调优
网格搜索法[22]通过穷举法遍历参数列表,对参数自动进行排列组合,从而筛选出最佳参数组合,参数设置范围如表2、表3所示.其原理是:首先选择当前对各个模型影响最大的参数进行调优,每组参数都采用5折交叉验证来评估,通过给定取值区间,按照顺序进行搜索,直到最优,再对下一个影响较大的参数进行调优,以此类推,直至所有的参数调优结束,选出最佳参数组合.函数输入为分类器需要优化的参数及参数列表,输出为5折交叉验证的模型评价指标的平均值.
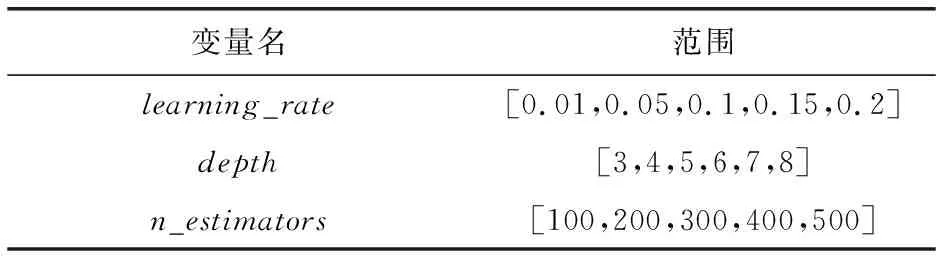
表2 XGBoost,LightGBM,CatBoost的被调参数设置和范围

表3 LCE的被调参数设置和范围
3 模型训练及实验结果
3.1 评价指标
本文使用了极度不平衡数据集, 由于AUC值、F1和G-mean不会受到数据分布不均的影响,能更有效地反映模型分类性能,因此本文选用AUC,F1,G-mean作为评价指标.
AUC为ROC曲线下的面积,ROC曲线的横坐标为假正例率(FPR),纵坐标为TPR(真正例率).FPR,TPR具体定义如式(8)和式(9)所示:
(8)
(9)
F1和G-mean具体定义如式(10)和式(11)所示:
(10)
(11)
3.2 实验环境
本文编程语言为python,操作系统为Windows10,64位,处理器为Intel®CoreTMi7-1065G7 CPU@1.30 GHz 1.50 GHz,16 GB内存.
3.3 实验结果展示
本文分别对单个模型和Stacking集成模型进行实验研究,以验证模型性能.
3.3.1 单模型分类实验
本文在进行Stacking集成模型分类实验前,先分别测试基分类器XGBoost,LightGBM,CatBoost,LCE在不采用数据生成方法下的AUC,F1,G-mean,如表4所示.由于存在严重的类不均衡现象,采用SUNDO技术对训练样本进行扩充,这里利用了smote_variants python工具包.经比较发现使用SUNDO对数据进行扩充之后4种模型性能均有提升,后续的集成学习和特征排序算法均采用SUNDO.采用SUNDO数据生成方法后各模型性能如表5所示.通过多次训练调参后,各模型较优的参数如表6所示.XGBoost,LightGBM,CatBoost的learning_rate分别为0.15,0.05,0.2;depth分别为4,5,7;n_estimators分别为200,300,200;LCE的depth和n_estimators分别为5和30.通过对比可见各模型性能又进一步提高.AUC分别提高0.3,0.6,1.3,0.6;F1分别提高1.6,1.0,1.3,0.9;G-mean分别提高2.1,0.8,1.2,0.7.
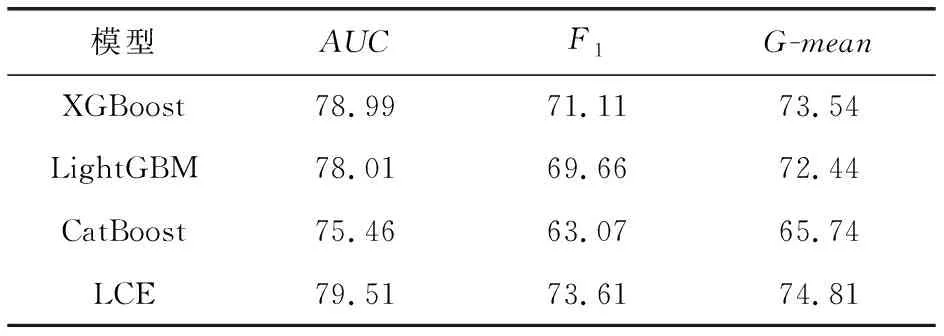
表4 不采用数据生成方法时各模型性能 %

表5 采用SUNDO数据生成方法时各模型性能 %

表6 各模型参数设置及性能
3.3.2 Stacking集成模型分类实验
在集成模型分类实验中,将不平衡数据处理后的样本数据进行多模型联合特征选取,5折交叉验证后得到的各模型的特征重要性排序结果(重要的特征排在前面)如图6~9所示.从图中可以发现,各模型特征重要性较为一致.用户完成的付款金额对预测异常账户最相关,与3.1.1节相关性分析预测一致.

图6 XGBoost特征重要性排序结果
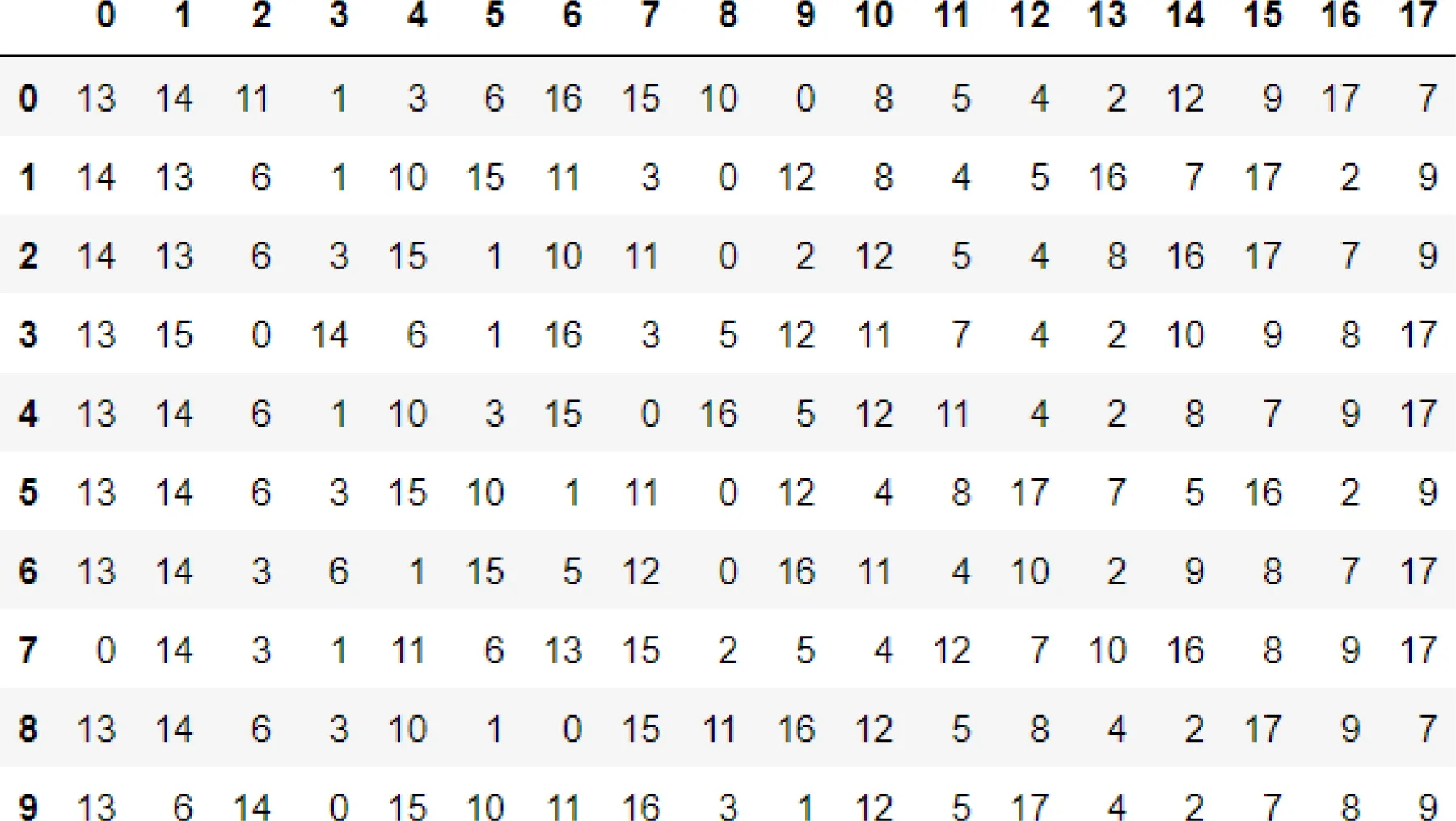
图7 LightGBM特征重要性排序结果
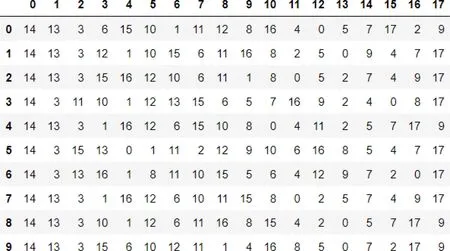
图8 CatBoost特征重要性排序结果
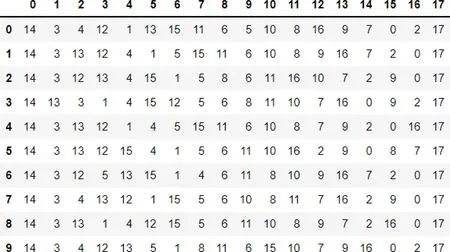
图9 LCE特征重要性排序结果
通过多模型联合特征排序的方法进行特征选择,将最优特征子集作为Stacking_MLP模型的输入进行分类预测,训练最优特征子集得到的AUC,F1,G-mean如图10所示,又经5折交叉验证网格搜索参数调优后得到的AUC,F1,G-mean如图11所示.模型训练全部特征和训练最优特征子集性能对比如表7所示,对比发现,网格调优前,AUC,F1,G-mean分别提高了1.7, 1.6,1.6;网格调优后,训练全部特征和训练最优特征子集得到的AUC,F1,G-mean又进一步提高,最终得到AUC为90.94%,F1为81.54%,G-mean为82.43%.

图10 网格调优前的模型性能

图11 网格调优后的模型性能

表7 集成模型的性能对比(全部特征和最优特征子集特征) %
4 结 语
为检测异常交易账户,本文提出了一种基于Stacking集成学习的区块链异常交易检测方法.利用多模型联合特征排序算法进行特征筛选,得到新的特征子集,通过多次训练得到最优特征子集,将得到的最优特征子集作为MLP_Stacking输入数据集进行分类训练,网格搜索5折交叉验证确定模型最优参数,实现模型优化.实验结果显示本文设计的集成模型训练效果明显优于单个模型.未来将探索选取新的特征选择方法来提高检测性能,设计新的异常检测模型或异常检测算法.
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
科学(2020年5期)2020-11-26
科普童话·学霸日记(2020年1期)2020-05-08
南京大学学报(数学半年刊)(2020年1期)2020-03-19
科学(2020年6期)2020-02-06
小天使·一年级语数英综合(2019年2期)2019-01-10
吉林大学学报(理学版)(2018年4期)2018-07-19
传媒评论(2018年4期)2018-06-27
现代企业文化(2018年13期)2018-06-09
