
基于VMD-SSA及误差补偿的风电功率超短期预测
2023-03-04 07:52朱希林俊德施翔宇林金阳
福建工程学院学报 2023年6期
朱希,林俊德,施翔宇,林金阳
(1. 福建理工大学 微电子技术研究中心,福建 福州,350118;2. 智能电网仿真分析与综合控制福建省高校工程研究中心,福建 福州 350118)
“碳达峰、碳中和”双碳目标的提出明确了我国未来能源将朝着低碳、清洁的方向发展,风能资源的利用是实现该目标的主要途径之一[1]。然而,风能资源规律性差、随机性强,大规模接入电网后会对电力系统的经济安全运行造成影响。风电的超短期预测是指对未来0~4 h内的风电有功功率以15 min为分辨率进行滚动预测,其实时准确性使其在解决风电联网问题上得到了广泛的应用,对风电消纳、保持系统实时功率平衡具有重要意义[2]。
风电功率预测方法包括物理法和统计学习法两大类。物理法需根据风电场的周围环境搭建数学模型,模型复杂度高,不确定环节多,不适合用于风电的短期预测[3]。统计学习法因其以风电场的历史数据以及历史气象数据为基础,通过对数据进行特征挖掘和分析,建立风电特征与预测结果的非线性映射关系,与周围环境无关,预测速度快,被广泛使用在短期和超短期风电预测研究中[4]。文献[5]使用改进的支持向量机(support vector machines,SVM)模型进行风功率的短期预测,模型的预测精度更高,适应性更强,但SVM的参数选择依赖经验判断,存在一定的局限性。针对这些问题有学者提出了结合信号分解算法的预测模型。文献[6]提出了集合经验模态分解(ensemble empirical mode decomposition, EEMD)结合支持向量机SVM的风电功率预测模型,得到了良好的预测效果。文献[7]提出了变分模态分解(variational modal decomposition, VMD)结合极限学习机的组合预测模型用于短期风电功率的预测,验证了VMD在非平稳和非线性序列分解中的有效性,能更好地挖掘数据特征。文献[8]将完全自适应噪声集合经验模态分解与奇异谱分析(singular spectrum analysis ,SSA)相结合,建立了风速预测模型,其中SSA用于提取最高频率子层的趋势分量,可获得更高准确度的实验结果。为进一步降低预测误差,提供更精确的预测值,一些学者在模型中引入了误差补偿策略。文献[9]将风速误差分为横向误差和纵向误差,分别采用互相关法和卷积神经网络法进行补偿,所得结果在原来模型基础上均方根误差降低了17.8%。文献[10]采用广义回归神经网络对误差进行预测的方式对风速预测模型进行预测,在原模型的基础上均方根误差降低了5.89%。
综上,提高风电功率的预测精度需解决风电功率数据自身的随机性、波动性问题。本研究利用SSA算法的优势对VMD分解后的数据进行重构,平缓序列波动性,突出序列趋势特征,通过长短期记忆网络(long and short-term memory network,LSTM)对重构序列进行预测,结合高斯过程回归(gaussian process regression,GPR)补偿预测误差,建立VMD-SSA-LSTM-GPR的预测模型。
1 方法介绍
1.1 变分模态分解
变分模态分解是一种非递归信号处理算法,它可以将信号分解为一系列具有不同中心频率和有限带宽的序列[11]。风电功率序列经VMD分解后获得具有不同频率和明显特征的序列,提高了序列的平稳性。
假设将原始风电功率序列分解为K个特征模态分量,则约束变分模型如下:
(1)
式中,uk(t)表示分解得到的K个特征模态分量;ωk表示K个分量的中心频率。
为求解式(1)的约束变分问题,引入罚因子C和拉格朗日乘子θ,将约束变分问题转化为无约束变分问题,即

(2)
对于(2)中的无约束变分问题,采用乘法算子交替方向法求解,对uk和ωk在两个方向上加以更新,即
(3)
(4)
式中,n是迭代次数;上标^表示傅里叶变换。迭代终止条件为:
(5)
式中,γ为收敛误差。
1.2 奇异谱分析
奇异谱分析是一种处理非线性时间序列数据的方法,通过对目标序列的轨迹矩阵进行分解、重构等操作,将序列中的趋势、振荡、噪声等分量提取出来,进行数据分析和去噪[12]。针对经VMD分解后所得的序列,利用SSA在提取趋势分量中的出色效果,对序列中参杂成分较高的高频分量进行特征重构。
计算过程为以VMD分解所得的特征模态分量U1为例,将长度为m的时间序列U1={u1,…,um},根据给定的嵌入维数K,将其转化为轨迹矩阵X,即
(6)
式中,L为窗口长度,M为时间序列长度,L与K应满足K=M-L+1,通常L≤M/2。
对轨迹矩阵X进行奇异值分解,即
X=Z1+Z2+…+Zd
(7)
式中,Zi为经奇异值分解所得的分量(i=1,2,…,d)。
通过计算矩阵X的r(0≤r≤d)个奇异值之和对矩阵的贡献率η,对获得的子序列进行分析评价,以奇异值发生较大跳跃的情况将矩阵按频率进行分组,贡献率的计算如式(8):
(8)

(9)
1.3 长短期记忆网络
长短期记忆网络是循环神经网络(recurrent neural network, RNN)的变体,为解决RNN在长序列中出现的梯度爆炸或梯度消失的问题,在RNN的结构上增加了3个控制传递的门控单元。LSTM的结构如图1所示,门控单元具体包括遗忘门、输入门和输出门。其中遗忘门在保留有用信息的同时避免了上一时刻的无用信息向后传递,输入门和输出门用于读取数据并将处理后的数据向下一个时刻传递,具体计算过程如式(10)。
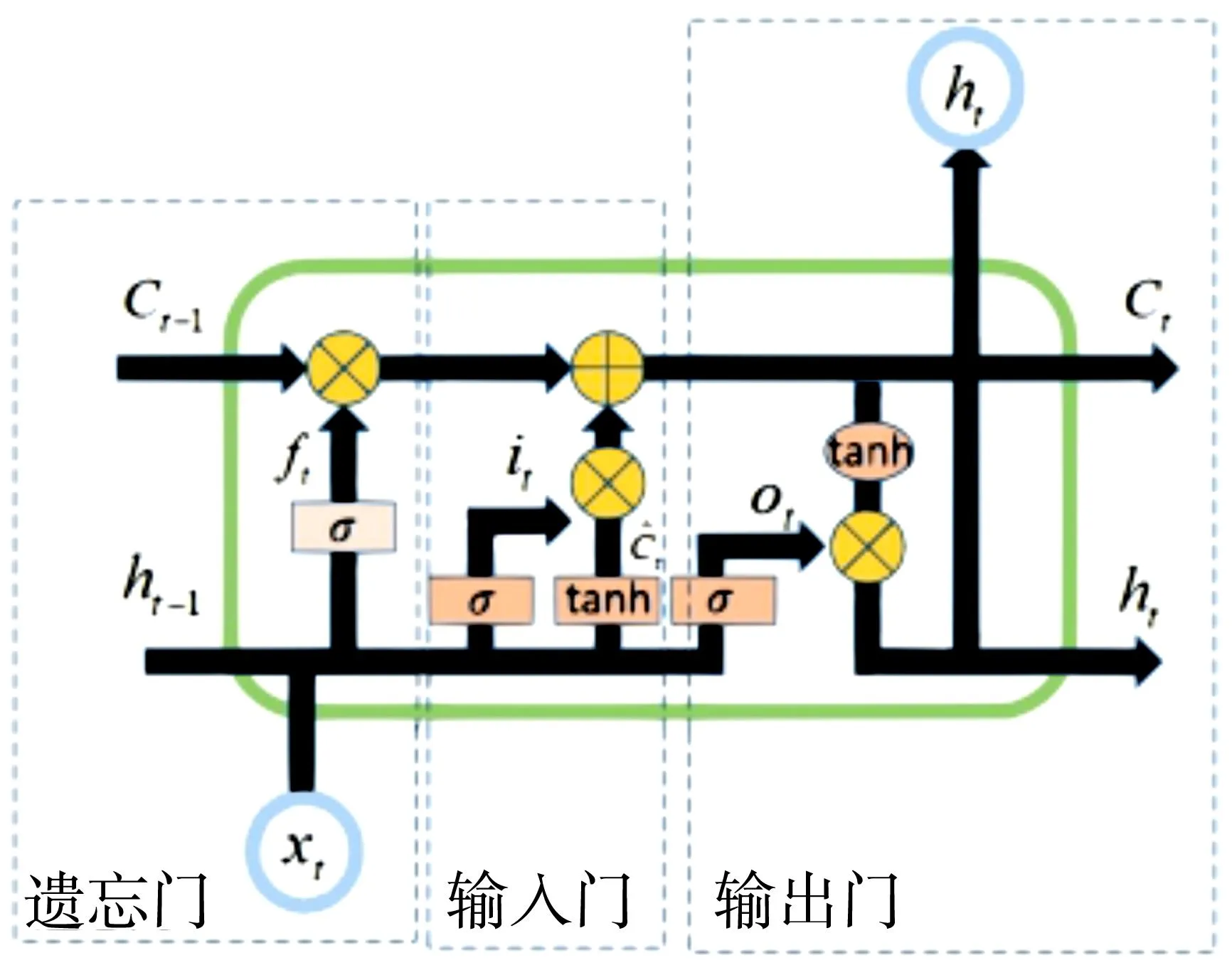
图1 LSTM单元结构Fig.1 Structure diagram of LSTM unit

(10)
式中,ft,it,Ct,ot指t时刻的遗忘门、输入门、细胞状态和输出门;σ为sigmoid函数;Wf、Wi、WC、Wo为遗忘门、输入门、细胞状态和输出门的权重矩阵;ht为t时刻的隐藏层输出;xt为t时刻的输入;bf、bi、bC、bO为遗忘门、输入门、细胞状态和输出门的偏置项;tanh为双曲正切函数。
1.4 高斯过程回归
高斯过程回归是一种基于贝叶斯理论和统计学习理论的机器学习回归方法,适用于解决高维、非线性等复杂的回归问题[13]。根据风电功率实际值与预测值做差的方式求取预测误差,并对预测误差进行概率密度分析,确定其是否符合高斯分布,然后使用高斯过程回归进行误差补偿。
对于所获得的误差序列,若其服从联合高斯分布,如式(11):
f(x)~GPR(m(x),k(x,x′))
(11)
式中,m(x)为均值函数,k(x,x′)为协方差函数。
考虑到噪声的存在,GPR预测模型可进一步表示为:
y=f(x)+ε
(12)
式中,y为目标输出,ε是独立于f(x)的高斯白噪声。
结合式(11)(12),则由目标输出y组成的高斯过程回归可表示为:
(13)
根据贝叶斯原理,训练样本的目标输出y和测试样本的目标输出y*的先验分布为:
(14)
式中,K(z,z*)是训练输入向量z和测试输入向量z*之间的协方差矩阵,K(z*,z*)是测试输入本身的协方差矩阵,K(z,z)是n×n的对称正定协方差矩阵。
对于测试输入向量z*,其预测输出y*的后验概率分布可以表示为:
(15)
式中,¯y*表示测试输入向量z*对应预测值的均值,cov(y*)为测试输入向量z*对应的预测值的方差。
2 组合预测模型
2.1 预测模型
针对超短期风电功率预测问题,本研究提出基于VMD-SSA-LSTM-GPR的风电功率预测模型。
采用VMD和SSA结合的方式对原始风电功率序列进行预处理,原始数据经VMD分解后所得模态再由SSA进行数据分析,根据公式(8)计算贡献率η,选择贡献率大于0.01%特征表现明显的分量进行重构。通过经麻雀搜索算法整定超参数的LSTM网络对重构的序列进行预测,再与原始数据做差得误差数据,使用高斯过程回归对误差数据进行预测后补偿到预测结果中,具体流程如图2所示。
对于VMD分解模态数K难以确定的问题,本研究采用相关系数分析的方式选择合适的K值。首先,由于EMD存在过分解问题,所以可通过EMD确定K的最大值Kmax;再以K=1开始对原始序列进行VMD分解;然后将分解后的模态分量进行重构,计算重构后的序列与原始序列的相关系数,以反映两者的相关程度[14]。当相关系数达到阈值时,原始信号被完全分解,本研究实验验证表明阈值取0.998时分解效果最好,具体流程如图2所示。重构序列与原始序列之间的相关系数定义如式(16):
(16)
式中,上标^表示y(n)的重构序列,y(n)是原始序列,ρxy(k)是当分解模态数为K时的相关系数。
最后,采用基于高斯模型的GPR预测模型对预测结果进行误差补偿,以此来提高预测的精度。
2.2 评价指标
为合理评价预测模型的预测性能,本研究选取均方根误差(root mean square error, RMSE)、平均绝对误差(mean absolute error, MAE)和拟合优度R2作为评价模型预测精确度的指标,其中RMSE和MAE值越小说明预测值与实际值偏差越小,R2越接近1,则预测值对真实值的拟合效果越好。计算公式如下:
(17)
(18)
(19)
式中,Pi为预测值,Pyi为实际值,¯Pyi为实际值的均值。
3 算例分析
3.1 数据集和实验环境
本研究以西北某风电场数据进行算例分析,包含2017年全年的风力发电实测功率。该风电场装机容量为99 MW,时间分辨率为15 min,选取2017年中连续的共8 640个样本点。基于PyCharm平台搭建VMD-SSA-LSTM-GPR模型。
3.2 数据预处理
采用VMD算法分解原始风电功率序列,通过互相关函数法确定最佳的模态数K,结果如图3所示。当K值增加到5后,相关系数变化平缓,基本接近一条直线,所以选取K值为5。选取分解后的5个模态分量,采用SSA对各模态进行数据分析,根据公式(8)计算各分量贡献率,选取贡献率大于0.01%的特征分量重构,重构后的序列效果如图4(a)所示,图4(b)为局部放大图。由图4(b) 可知,经VMD分解和SSA重构后的序列相较于原序列更平滑,趋势特征更加明显。
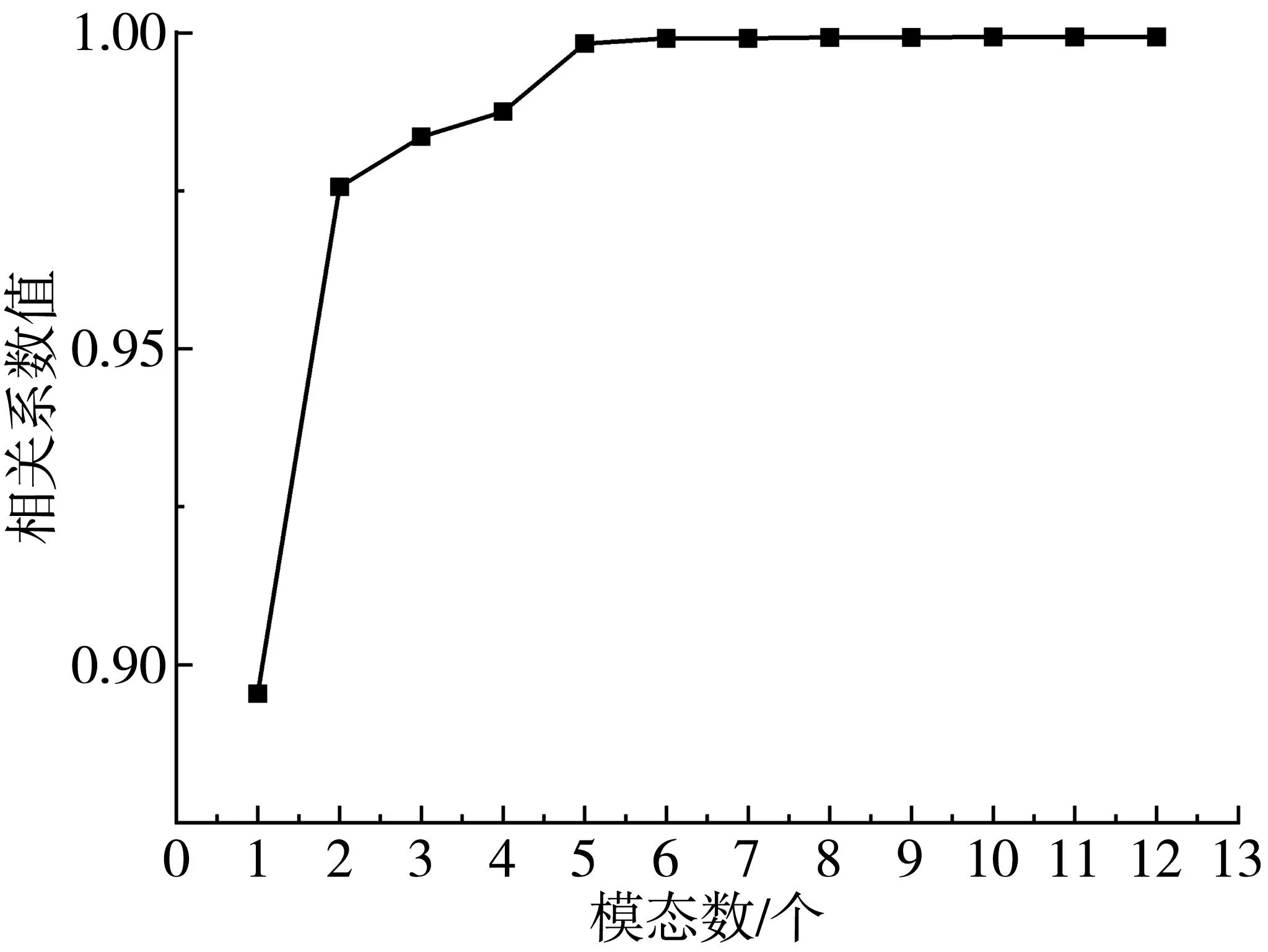
图3 相关系数趋势图Fig.3 Trend of correlation coefficient

图4 重构后序列对比图Fig.4 Comparison of reconstructed sequences
3.3 预测模型
实验采用的风电功率序列共包含8 640个样本点,将前89 d的数据即8 544个数据样本作为训练集,后96个数据样本作为测试集,通过LSTM模型进行风功率的预测。针对LSTM超参数选取问题,采用麻雀搜索算法对LSTM的超参数进行寻优,算法参数设置如表1所示。超参数寻优结果如表2所示。
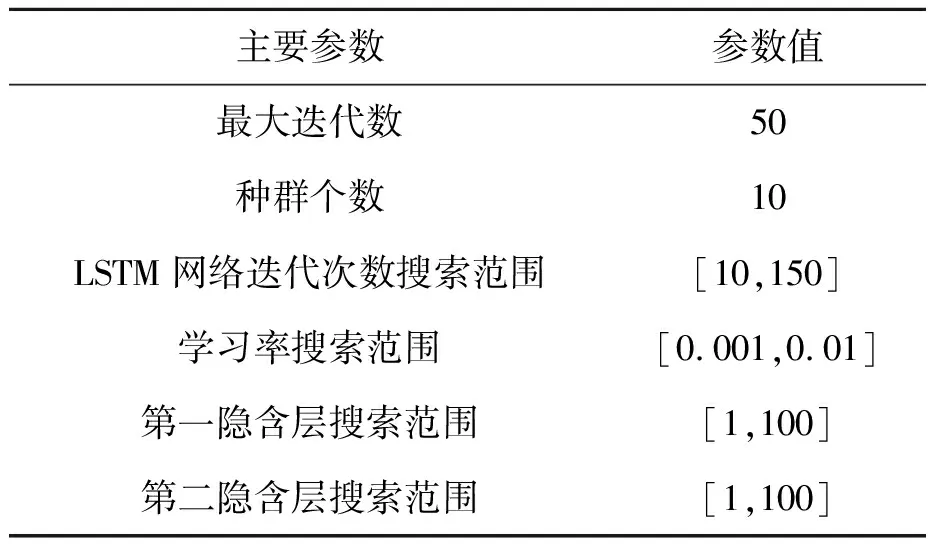
表1 麻雀搜索算法参数设置Tab.1 Sparrow search algorithm parameter settings

表2 LSTM超参数设置Tab.2 LSTM hyperparameter settings
3.4 结果分析
为验证预测模型的实用性,将一年数据划分为4个季节,分别对春季典型日和秋季典型日进行风电功率预测。图5展示了支持向量回归(support vector regression,SVR),LSTM,VMD-LSTM,EMD-LSTM,VMD-SSA-LSTM,VMD-SSA-LSTM-GPR等6种模型的预测结果。结合图5(a)和图5(b)可以看出,不论是功率波动较大时的春季模型,还是波动相对平缓的秋季模型,所提模型的风电功率序列的拟合效果都比同等条件下的其他模型更好。

图5 典型日预测结果Fig.5 Predicted results for a typical day
对比春秋季不同模型的评价指标可知,所提模型无论是在风电变化频率快的春季还是相对缓和的秋季,都具有较高的预测准确度。
由表3可知,以春季预测结果为例分析,单一模型SVR与LSTM在预测风电功率上具有一定的准确性,但准确度不高。结合图5分析可知其原因在于SVR和LSTM虽可预测风电数据的变化趋势,但难以把握数据的随机波动性致使误差较大。与LSTM相比,经EMD分解后的EMD-LSTM模型的RMSE、MAE分别下降了48.88%,40.83%,R2提高了11.84%,说明结合信号分解算法能显著提高预测模型的准确性。与EMD-LSTM相比VMD-LSTM模型的RMSE、MAE模分别减少了29.20%,17.33%,R2提高了2.08%,主要由于VMD相较于EMD具有更完备的数学理论,在处理非线性非平稳信号上更有优势。与VMD-LSTM相比VMD-SSA-LSTM模型的RMSE、MAE分别减少了4.18%,12.92%,R2提高了0.17%,这是由于SSA对VMD分解后的各模态进行了特征的重提取,凸显序列的主要成分,提高了强耦合数据所占的权重。与VMD-SSA-LSTM相比,VMD-SSA-LSTM-GPR模型的RMSE、MAE分别减少了10.2%,25.62%,R2提高了0.72%,主要由于VMD-SSA-LSTM-GPR模型引入了GPR误差补偿模块,对数据预处理时优化掉的部分数据以及预测模型产生的误差进行补偿,进一步提高模型的预测准确度。

表3 各模型评价指标对比Tab.5 Comparison of evaluation indicators of each model
4 结论
为实现风电功率的实时准确预测,提出了一种基于VMD-SSA-LSTM-GPR的风电功率超短期预测模型,经算例分析和不同预测模型结果对比,结果表明:
1)通过对风电功率序列进行VMD分解,再使用SSA对分解后的各模态进行数据分析重构的预处理方式,能够有效提升数据的平稳性,减少噪声信号的干扰,更利于神经网络进行数据的拟合。
2)采用GPR预测模型进行误差补偿,能够有效补偿神经网络模型产生的预测误差,在增加预测精度的同时,进一步提高模型的抗干扰能力。
本研究仅针对风电功率数据进行预测,并未涉及影响风力发电的环境因素,未来可结合风电场环境数据与风电功率数据进行特征融合的方式进行预测模型的搭建,在提高模型预测准确性的同时提高其适应能力。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
摄影世界(2022年1期)2022-01-21
基层中医药(2021年12期)2021-06-05
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·中考版(2018年12期)2019-01-31
知识经济·中国直销(2018年12期)2018-12-29
英美文学研究论丛(2018年1期)2018-08-16
商周刊(2017年6期)2017-08-22
纺织科学研究(2017年6期)2017-07-03
