
风电检修语音记录转译文本的纠错技术研究
2023-03-06 09:46运佳恩高永兵
智能城市 2023年12期
运佳恩 高永兵*
(内蒙古科技大学信息工程学院,内蒙古 包头 014010)
随着风电行业的快速发展,风电自动检修服务不断优化,风电自动检修技术也在不断进步和完善。在风电自动检修系统中,员工可以采用便携式设备取代录音、纸质记录等方式,可为工作人员提供便利,提高工作效率,降低某些安全隐患。风电自动检修系统需要语音转文字和文本纠错技术提高系统的识别和理解能力,从而提高系统的自动化程度和准确性的理解和分析能力,保证自动检修系统的高效运行。因此,为了确保风电自动检修系统的准确性和可靠性,必须解决方言和专业词汇混杂使用的问题。语音转文字和文本纠错的目的就是通过技术手段对口音和专业术语进行识别和纠错,提高系统的准确性和可靠性,减少错误,提高系统的智能化水平。风电自动检修系统能够更准确、高效地进行检修工作,提高风电设备的安全性和稳定性。因为要修改的字不经常使用,N-gram[1]模式并不适用该主题。BERT[2]中已有的Mask Language[3]模式可以用于文字校正,但该算法采用了对文字进行无规则遮挡的模式,导致无法精确地进行训练。
1 相关技术概述
1.1 语音识别原理
作为计算机语言学中一个交叉学科的分支,语音辨识是语言学、计算机科学、电子工程学等学科的结合,发展成了一种能够将语言的辨识和转换为文字的技术。语音识别实质上就是让机器把人说出来的话转化为可以被机器所理解的信息和数据,通过对语音数据进行加工、整理、聚类等处理,得到相应的模板。
语音识别原理如图1所示。
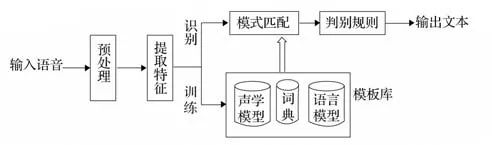
图1 语音识别原理
近年来,深度和点对点的学习在各种类型的工作中都显示出了较强的提取特性,使语音的识别精度大幅度提升。ASR[4]技术也逐渐被应用于各种场合,并逐渐受到重视。
1.2 文本纠错原理
文本纠错技术可以分为两大类别,即基于规则和基于统计的方法。基于规则的方法需要手动编写规则检测和纠正文本中的错误,如正则表达式或规则库,但需要大量的人力和时间编写规则,且很难覆盖所有的错误类型。基于统计的方法则利用大规模的语料库训练模型,以自动检测和纠正文本中的错误,通常包括训练语言模型和错误模型两个步骤。例如,基于统计的方法可以使用N-gram模型或神经网络模型[5]检测和纠正错误,具有自适应不同文本领域和风格的优点。
1.3 Transformer原理简述
Transformer[6]的双向编码器从2018年年底被推出后就备受瞩目,成为Word2Vec[7]的替代品,在多个方面的准确率都得到了极大提高,是近几年自残差网络突破较大的技术之一。文本纠错通常使用Transformer和双向模型,是因为这些模型在处理文本序列任务时表现出色。
双向模型也是文本纠错任务中常用的模型,使用双向循环神经网络(BiRNN)[8]学习序列中上下文的信息,其中循环神经网络可以分别从序列的前向和后向方向对序列进行处理。双向建模方法能够更好地利用序列上下文信息,从而在文本纠错任务中具有更好的表现。
1.4 BERT原理简述
BERT是一种预先培训的模式,其意义在于通过对海量未加标记的资料进行无监督训练,获取包括语言、句法、词义等在内的海量的先验性知识,并通过对所学到的知识进行调整。
构造token的embeddings时,需要每个embedding中都包括相关的文字和绝对的定位,以便使每一个embedding都含有文字的顺序。在BERT中,各个标记的绝对定位信息通常用position embeddings[9]表达,也就是将一个任意点作为初始值,通过模型训练获得一个含有定位的区域。通常使用segment embedding指示下一步Sentence预设工作的各个token的语句。选择BERT模式时,通常会把一个词用3种embedding结合在一起。
BERT的输入向量如图2所示。
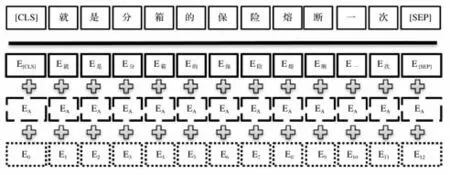
图2 BERT的输入向量
Token embedding表示字的量化,CLS标记被用来进行分类工作,在其他工作中可以被忽视。“SEP”标记被用来分隔两个语句。
Segment embedding表示前和后两种语句的区别,在进行下一步推理的练习时,用来识别前后的不同语句。
Position embedding由上文可知通过模型训练得到当前token的位置信息。
2 纠错模型设计
BERT-BiLSTM-CRF模型是一种基于深度学习的序列标注模型,主要用于文本纠错任务,结合了BERT预训练模型、双向LSTM(BiLSTM)[10]和条件随机场(CRF)[11]3种不同的模型,以提高文本纠错的准确性和效率。BERT模型提供了上下文信息的丰富表示,BiLSTM模型可以更好地捕捉序列信息的前后依赖关系,而CRF模型可以在全局上对标签进行约束,从而避免局部最优解。因此,BERTBiLSTM-CRF模型可以更准确地识别文本中的错误,并进行适当纠正。
2.1 针对性掩码策略
掩码语言模型的本质是一种具有双向的自注意力和遮蔽机制的Transformer编码器,该译码者可以在各个层次上对语境进行双向表达。
错误词主要出现在专业词的部分,指的是因为发音问题、词汇生疏而无法辨认的单词,也就是在语音辨识模组中出现的失误。在发音模组中,正确单词的标注主要根据语音辨识的语句与人工聆听的语句进行对比而得出。
BERT中的掩码语言模型(MLM)[12]机制原本可以修正文字,调整掩码方法后,把模糊的错误分为3种,即专业词错误、专用词杂糅、专业词切割。
专业词错误标注如表1所示。

表1 专业词错误标注
2.2 检错阶段
BERT-BiLSTM-CRF是一个将CRF与BERT模式相融合的综合模式。在获得一个待测的基因时,把该序列导入BERT预培训模式,获得与被测序列同样长的新序列,该序列由原来的文字形式转化成矢量形式,且每一矢量都含有大量的语义,把新的序列加入BiLSTM中,给新的顺序加上前后两种不同的顺序,在CRF层中加入一个新的标记,对所预测的标记加入一定限制,以确保标记的正确性。该模式对3种不同的针对性错误(专业词错误、专业词杂糅、专业词切割)进行了分类。
BERT-BiLSTM-CRF模型架构如图3所示。
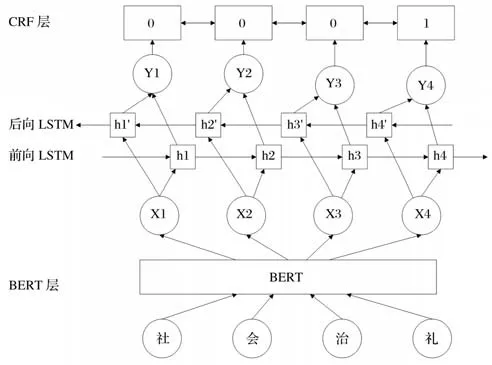
图3 BERT-BiLSTM-CRF模型架构
2.2.1 BERT层
待检测的中文文本序用W={w1,w2,…,wn}表达。把这些输入顺序与BERT模式相匹配,在BERT中产生3个单词(字符矢量、句子矢量和位置矢量),把3个单词嵌套在一起,形成BERT的输入顺序X={x1,x2,…,xn}。BERT的预习模型能够有效地利用词语的前后两边的信息,从而获得更好的词汇分配特征[8]。
2.2.2 BiLSTM层
中文的错误校正效果与语境的关系存在某种关系,所以需要将语境的相关知识引入序列。在BERT的输出顺序X={x1,x2,…,xn}后,将其添加到LSTM的两个模式。第一个LSTM是正向流动,token隐藏状态与上一个token隐藏状态和本token值有关,得到隐层序列H={h1,h2,…,hn}中,h'i的值由h'i+1的值和xi的值计算得到,隐层序列H包含了前向token的信息。第二个LSTM与第一个LSTM形式相同,只是从前向变成了后向输入,因此隐层序列H'={h'1,h'2,…,h'n}中,h'i的值由h'i+1的值和xi的值计算得到,隐层序列H'包含了后向token的信息。将前向隐层序列H和后向的隐层序列H'直接拼接在一起,就得到了同时包含前向信息和后向信息的序列Y={y1,y2,…,yn},其 中yi=[hi,h'i]。BiLSTM层最终的输出由包含过去的信息和包含将来的信息共同组成。
2.2.3 CRF层
CRF的输出为BERT和BiLSTM两层的训练后的序列Y,在此输入顺序上,根据机组培训模式,生成对应该输入顺序的标记顺序L,并从一个特定标记集合选择各个标记L。
将CRF的概念引入该模式。参照常用的顺序标记方法,将CRF层置于神经网络结构的末级,将BiLSTM的输出当作顺序的输入,并对各个字母进行标记。
BERT模式装载了经过培训的谷歌chineseL-12H-768A-12的checkpoint。在训练过程中,仅对BiLSTM-CRF进行了参数的修正。采用4种顺序标记模式对每个语句进行了独立的预测,根据方程式进行判定:
2.3 纠错阶段
在BERT的预先培训工作中,有一种掩码语言模型是为了在含有mask标记的顺序中对mask进行预言。MLM是一个典型的语言建模工作,可以被用来预报遗漏的差错。本研究采用BERT掩码的方法对缺失类型的差错进行校正。针对不同类型的标记,如专业词错误、专业词杂糅、专业词切割等,给出了相应的处理方法。
3 实验设计
在纠错过程中,利用BERT的掩码语言模式对误分类进行了修正,利用BERT的掩码语言模式和模糊集合的匹配对差错进行了预测。
3.1 实验环境及数据
3.1.1 实验环境
操作系统为Windows,开发语言为Python,开发框架为pycharm。
通过对风力发电机组的维修过程进行分析,筛选和剔除了无用的剩余33 701条错误文本,并对50 139条错误文本进行熔断,将两者的测试集、验证集和训练集的数量分别进行1∶1∶8的处理。
3.1.2 实验数据
本研究还建立了专用词词表,通过手工抽取专门词汇和对其进行了归类,一种是风力发电行业中使用的专门词汇,来自《电力术语汇总》的文献;名词的出处是《电力术语汇总》,共有972个条目,地名有4 356个,对每条数据进行标注。专业词错误类错误,在冗余的位置标注“5”;专业词杂糅类错误,在专业词杂糅的位置前后加标注“6”,非专业词错误加标注“1”;专业词切割类错误,在错误的位置分别标注“7”;非专业词错误类错误,在错误位置标注“1”。
经过对4 356条数据进行数据清洗、数据构造和数据标注,得到了一套由36 704条数据组成的数据包,其中80%用于培训,20%用于检测。将同样数目的恰当语句也加入测验集合,以供测试时参考。
3.1.3 评价标准
使用精确率、召回率和F1值对实验结果进行评估。
文本纠正的精确率为:

3.2 实验结果
检错阶段错误类型实验结果如表2所示。

表2 检错阶段错误类型实验结果
专业类错误准确率最高为92.30%,召回率为97.81%,F1值为0.940 4。在后续研究中提高模型的效率,应针对专业词杂糅类错误的识别进行提升。
纠错阶段错误类型实验结果如表3所示。
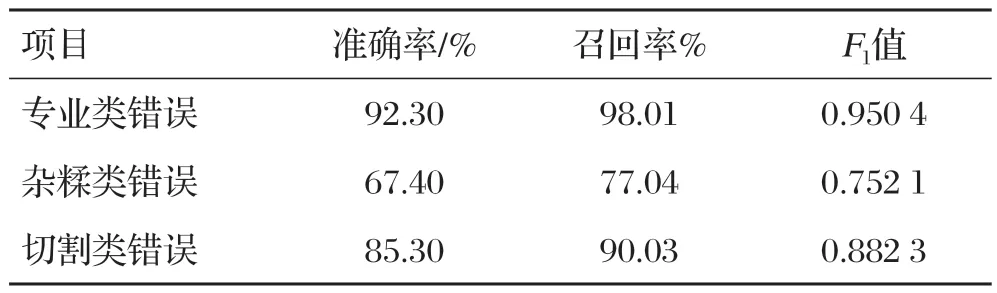
表3 纠错阶段错误类型实验结果
错误类错误在纠错模型中不需要进行任何附加运算,只需要将多余的数据段替换即可,所以在精度召唤和F1数值方面,与误差检测模式的误差并无差别。
4 结语
本研究在对标准文档进行学习和研究的基础上,提出了一种以BERT为基础的标准文档错误校正模式。该模式将故障检测和纠正两个环节结合,可显著提高风力维修话音录音翻译中的文字错误校正效率。在错误检测方面,采用BERT-BiLSTMCRF模型进行错误检测,其中BERT层补充语义,BiLSTM提取背景信息,CRF规范化文字标记。通过3个层次的构造,可以获得包含正确和不正确文字标记的相应顺序标记。利用名称本体辨识技术对序列中的实体进行识别,并根据其与本体之间的联系来决定标记的处理方式,包括保留或删除。误差校正采用mask代替不正确或遗漏的错误,在BERT的遮蔽和模糊集合比对相结合的基础上,估计出现的错位或遗漏的缺失标记,并获得多个候选语句。
猜你喜欢
小天使·一年级语数英综合(2022年2期)2022-03-30
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
通信学报(2019年5期)2019-06-11
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
通信技术(2018年3期)2018-03-21
浙江大学学报(工学版)(2015年4期)2015-03-01
人生十六七(2015年29期)2015-02-28
电子设计工程(2015年20期)2015-01-29
