
面向中文医学文本的知识图谱通用评测系统设计
2023-03-11 11:44林晓兰梁铭标张志辉江之晗谷祥拓陈秀娟梁会营
医疗卫生装备 2023年1期
林晓兰,梁铭标,王 浩,张志辉,江之晗,麻 硕,钱 鹏,谷祥拓,陈秀娟,黄 帅,梁会营*
(1.广东省人民医院,广东省医学科学院,广州 510080;2.中国食品药品检定研究院医疗器械检定所光机电室,北京 102629;3.深睿研究院,北京 100089;4.广州市妇女儿童医疗中心,广州 510623)
0 引言
近年来,知识图谱相关技术迅速发展,知识图谱在新形势的推动下逐步拓展出医学知识图谱[1]、金融知识图谱[2]、农业知识图谱[3]、安全知识图谱[4]等领域知识图谱,其中更不乏有风控[5]、营销[6]等场景化知识图谱。知识图谱在技术方面的突破,引发了相关研究者的进一步探索和评估,知识图谱评测随即应运而生。知识图谱评测作为评估知识图谱技术性能水平的一种手段,能够为知识图谱发展提供参考,但同时也面临着诸多挑战,如缺乏特定领域内真实场景下的文本数据等知识资源、相关研究匮乏、评测缺乏规范性、评测效力式微、评测数据集偏差、评测指标失真、评测生命期短、评测任务缺乏系统性、评测技术单一、可解释性较差等[7]。因此,许多评测数据集和评测任务不断被提出,如通用语言理解评估(general language understanding evaluation,GLUE)[8]、中文语言理解测评(Chinese language understanding evaluation,CLUE)[9]、中文生物医学语言理解测评(Chinese biomedical language understanding evaluation,CBLUE)[10]、全国知识图谱与语义计算大会知识图谱评测(China Conference on Knowledge Graph and Semantic Computing knowledge graph evaluation,CCKS)[11]等,研究者们正在逐步寻求评估知识图谱技术水平的标准策略。随着我国医疗领域信息技术的发展和信息化水平的提升,研究面向中文医学文本的知识图谱评测被提上日程。
众所周知,医学文本中蕴含着大量详尽而有价值的知识,尤其相较于英文文本,中文医学文本的处理存在着许多挑战,例如文本内容口语化、上下语境不丰富、实体关联困难等[11]。许多医学研究人员、医疗机构及企业因人力、技术水平等条件受限未能更好地使用数据,而在无法保证数据集质量和评估技术水平的情况下进行科学研究和智能应用建设,知识图谱作为承载底层海量知识并支持上层智能应用的重要载体的作用将大打折扣。
为此,本文采用浏览器/服务器(Browser/Server,B/S)架构,基于深度学习算法模型,结合医学专家人工标注的标准评测数据集,建立命名实体识别、实体链指、问答的医学知识图谱三位一体的标准测评任务体系以及相应评测数据集生成机制,搭建一个支持用户根据评测需求自定义评测项目、灵活配置必选和可选的评测内容、提供任务评测后单方面或者综合能力的量化成绩的知识图谱通用评测系统,以为医学领域的知识图谱评测提供参考。
1 需求分析
海量生物医学数据的积累为生命科学问题的解决带来了新的途径。医学文本作为医学知识最丰富的数据类型,常被用于构建医疗领域知识图谱系统,应用于语义搜索、知识问答、临床决策支持等方面[12]。随着医学信息技术的发展,医学知识图谱也被应用于辅助药物研发[13]、公共卫生事件的预警场景[14]中。医学文本中医学术语表达多样化作为一个国际性问题,在英文医学文本大数据方面的标准化数据库/语料库构建,以及在此基础上的命名实体识别、关系抽取、文本分类与聚类、临床术语集自动更新等标准化处理算法研究已有良好的基础[15],反而基于真实世界大规模中文医学文本数据的相关研究明显滞后。研究如何高质量地从中文医学文本数据中提取临床经验知识构建医学知识图谱是近年来的重大科学前沿。在自然语言处理领域,知识图谱评测作为评估、量化机器分析和处理人类语言能力的一种手段,往往也将评测成绩作为衡量科学技术研究水平、应用技术水平的一个重要依据。尽管现如今知识图谱评测任务的数量越来越多,但是评测的质量和效力仍旧参差不齐,这也是目前医学研究人员、医疗机构及企业构建医学知识图谱应用和实现落地化业务普遍存在的痛点。面向中文医学文本的知识图谱通用评测系统旨在把医学专家人工标注后的大规模真实临床文本数据作为评测任务的标准评测集使用,选用双向长短期记忆(bi-directional long short-term memory,BiLSTM)+条件随机场(conditional random fields,CRF)的传统序列标注模型、基于转换器的双向编码表征(bidirectional encoder representation from transformers,BERT)[16]语义匹配模型以及基于实体与关系识别的模型作为系统评测任务模型,为用户提供自定义评测项目功能模块,并提供量化成绩,为医学研究人员、医疗机构及企业评估知识图谱技术水平提供参考。
2 系统设计
2.1 系统开发环境
开发环境配置是进行系统开发的第一步,在设备硬件条件满足的情况下,搭建软件开发环境,继而开始进行系统设计开发。
硬件环境:(1)CPU:i5-10400 处理器,2.90 GHz以上主频;(2)图形处理器(graphics processing unit,GPU):GeForce RTX 3060 显卡芯片,12 GiB 显存容量;(3)内存:32 GiB 以上;(4)硬盘空间:50 GiB 以上。
软件环境:(1)操作系统:Linux;(2)软件开发编辑器:VSCode;(3)编写语言:Python 3.7。
2.2 架构设计
系统采用B/S 架构设计,前端展示利用HTML5、JavaScript、jQuery、Ajax 等技术实现,后端采用Python语言、Django 框架等技术实现与前端操作界面和数据库的交互,以Scikit-learn、TensorFlow 等技术实现对评测任务中算法模型的支撑。系统架构主要分为4 个层次,分别为运行环境层、数据资源层、数据服务层、系统应用层。系统总体架构如图1 所示。
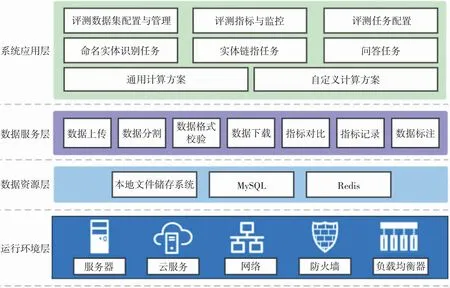
图1 面向中文医学文本的知识图谱通用评测系统架构图
运行环境层包括服务器、云服务、网络、防火墙和负载均衡器,为系统运行提供基础环境支撑。数据资源层为数据库层,通过本地文件储存系统、MySQL 关系型数据库、Redis 内存数据库实现对数据的共享和存储。数据服务层包含系统业务流程中涉及的一系列用户与数据的交互,分别为数据上传、数据分割、数据格式校验、数据下载、指标对比、指标记录和数据标注。系统应用层实现系统应用程序的协同工作,为用户提供功能服务,包括评测数据集配置与管理、评测指标与监控、评测任务配置、命名实体识别任务、实体链指任务、问答任务、通用计算方案和自定义计算方案。
2.3 流程设计
用户登录系统后,可选择系统提供的评测数据集配置与管理子模块对评测数据集进行数据处理,进入评测任务配置子模块选取数据集格式以及计算方案,再上传用户自身构建模型到系统中。接着再选择评测任务模型,启动任务评测,最后查看评测结果,并与系统自带评测任务模型进行对比。系统业务流程如图2 所示。

图2 面向中文医学文本的知识图谱通用评测系统业务流程图
2.4 功能设计
本系统主要包括评测任务以及数据集配置与管理模块、知识图谱任务评测模块、评测指标记录与对比模块。系统功能模块结构图如图3 所示。

图3 面向中文医学文本的知识图谱通用评测系统功能模块结构图
2.4.1 评测任务以及数据集配置与管理模块
2.4.1.1 评测数据集配置与管理子模块
评测数据集配置与管理子模块的功能为上传任务对应数据集、数据集格式的验证、数据集的切分和打乱重排,主要采用shuffle 函数实现。
2.4.1.2 评测任务配置子模块
评测任务配置子模块实现评测任务数据格式定义和评测任务评分方案选择2 个功能。该模块主要是向用户提供自定义数据格式的功能和自定义计算方案的选择,以便用户根据所需执行操作。
评测任务数据格式定义:用户可选用系统默认的通用数据集格式定义评测任务数据,也能自定义数据集样式,系统默认数据集格式为JS 对象简谱(Java-Script object notation,JSON)格式。
评测任务评分方案选择:该方案分为通用计算方案及自定义计算方案,通用方案即利用系统设定的计算公式评测对应任务的预测效果,自定义计算方案则是用户自行定义评测任务计算的方式。
2.4.2 知识图谱任务评测模块
知识图谱任务评测模块包含评测任务查看、数据集下载、评测模型上传及评测结果获取4 个子功能模块。用户可在系统查看评测任务基本信息,选择下载所需评测任务的数据集对自身构建的模型进行离线测试,离线测试完毕后再将模型上传至系统,并将其与系统模型进行对比,最后查看系统的评测结果。
2.4.2.1 评测任务查看子模块
评测任务查看子模块的主要功能是查看评测任务基本信息,如任务名称、任务背景说明、任务的数据格式说明,以及任务对应的数据评测指标和基线(baseline)模型等相关信息。评测任务查看界面如图4 所示。

图4 评测任务查看界面
系统中有3 种评测任务,分别为命名实体识别评测、实体链指评测和问答评测,具体如下:
(1)命名实体识别评测任务:对于给定的一组纯医学文本文档,该任务的目标是识别并抽取与医学临床相关的实体,并将其归类到预先定义好的类别。在系统中该任务所用评测数据样本由电子病历的诊断、主诉、现病史等部分构成,其中涉及的医学实体包括治疗、检查、症状、疾病、药物、手术、解剖部位、检验等类型。对以上实体的标注,要求从原始文本中精准标记出符合要求的医学实体信息,由1 名标注人员和1 名工作经验15 a 以上的副主任医师或主任医师担任标注(由医学专家制定标注规范并进行人工标注)工作[17]。标注完成后,采取背靠背标注、二轮审核的标注检验方式最终确定标注结果[18]。针对该评测任务,系统提出一个基于BiLSTM+CRF 的命名实体识别模型作为baseline 方法,采用传统的精确率P、召回率R 以及F1值作为评测指标,当预测的起始、结束下标对应的实体与实体类型精准匹配时判定预测正确。其中,精确率指在所有被预测为正类的样本中实际为正类样本的概率;召回率指在实际为正类的样本中被预测为正样本的概率;F1值则是准确率和召回率的调和平均值,其最大值为1,最小值为0,在0~1 的值域内,F1值的大小与模型性能成正比。将真正类(true positive,TP)表示预测答案正确,假正类(false positive,FP)表示错将其他类预测为本类,假负类(false negative,FN)表示本类标签预测为其他类,则
(2)实体链指评测任务:指对于给定的中文医学短文本,实体链指策略输出的结果中包含给定中文医学短文本中出现的所有命名实体的链指结果。在系统中该任务所用短文本评测数据样本主要由门诊病历中主诉、现病史等组成。对数据样本的标注以尽量不丢失原始数据信息为原则,标出最精确匹配的标准词,要求尽可能细颗粒度地映射到同一个疾病上。同时,标注过程如遇不易划词或映射的文本,需要额外单独记录,并与医学专家讨论后完善标注规范[17]。针对该评测任务,系统提出将BERT 预训练模型作为baseline 方法,将F1值作为评测指标,通过将输出结果与医学专家标注结果集合进行比较来计算准确率P、召回率R 和F1值。假设给定属于医学专家标注集的医学短文本输入doc,doc 中有N 个实体提及(mention):Mn={m1,m2,…,mn},每个实体提及链接到知识库的实体ID 为En={e1,e2,…,en},输出标注结果为,则
(3)问答评测任务:指对于给定的一句中文医学问题,问答任务从给定知识库中选择若干实体或属性值作为该问题的答案。该任务评测样本数据的标注工作,要求标注人员对每个原始数据中患者提问找出对应的标准问题,且标注过程中需要遵循2 个原则:对于有多个对应关系的患者提问需要将所有对应的标准问题列出(例如,患者提问:“类风湿关节炎应该如何治疗?有什么不能吃的吗?”,对应类风湿关节炎的治疗和饮食上的注意事项都需要列出);对于不在标准问题库中的患者提问应单独记录,由医学专家统一完善标准问题库。其中,标准问题库指的是一个问题的集合,包含每一个问题答案和所属科室,其中问题的表述应该精炼,语义上不重复,并应尽可能在语义上覆盖所有领域内会被提问的问题。由于标注后的数据中每个患者提问仅与正确答案对应,还需要人工生成错误答案以供模型训练。在生成训练数据时,将每一问题对(患者提问与标准问题)的标签分为3类:如果患者提问和标准问题完全一致,则记标签为2;如果患者提问和标准问题不一致,但问题所属同一科室,则记标签为1;如果患者提问和标准问题不一致且不属于同一科室,则记标签为0。在构建评测数据集时,对于每一条患者提问,除了将其与对应的标准问题加入评测数据集外,额外从原始数据中抽取2条其他患者提问的标准问题作为负例。针对该任务,系统提出基于实体与关系识别的模型作为baseline。该任务的评测指标包括准确率P、召回率R 和F1值,设Q 为问题集合,Ai为第i 个问题给出的答案集合,Si为第i 个问题的标准答案集合,则
2.4.2.2 数据集下载子模块
通过模块用户可下载系统对应评测任务的数据集,数据集中含有训练集、开发集和测试集,以便用户离线测试自身构建的模型。
2.4.2.3 评测模型上传子模块
通过该模块用户可将自身构建的模型上传至系统,系统将会把用户构建的模型与系统模型评测效果进行指标对比。评测模型上传界面如图5 所示。

图5 评测模型上传界面
2.4.2.4 评测结果获取子模块
评测任务结束后,用户可通过该模块可视化获取评测结果,可对评测任务的评测结果指标进行查看,并与baseline 模型指标进行对比,同时也生成指标对比记录。
2.4.3 评测指标记录与对比模块
用户进行评测任务后,能够在评测指标记录与对比模块查看相应的评测指标记录,自主选择评测配置方案后,系统展示评测指标对比结果。
评测指标记录:对用户提交的多次结果进行存储并提供查看、可视化功能。
评测指标对比:系统以可视化的人机交互界面,支持用户自定义裁剪测评方案。用户可通过配置评测方案的必选项和可选项、内容要求,定义通用部分的评测指标范围,如系统是否涵盖错误率要求等,以及选择特定知识领域定义内容部分的性能,如特定疾病模块的准确率P 和召回率R。系统针对用户的需求转化为结构化的评测标准细则,根据实际提交的结果,个性化地展示提交和评测记录。图6 为评测任务界面,图7 为评测任务结果指标对比界面。

图6 评测任务界面

图7 评测任务结果指标对比界面
3 应用效果
本系统已于2022 年5 月11 日在某三甲医院上线使用,截至目前,已有4 家企业、11 家科研单位使用本系统进行知识图谱任务评测,注册用户超50名。其中,用户自上传评测模型总量为87 个,分别为命名实体识别模型47 个、实体链指模型23 个、问答模型17 个;评测数据集共19 套。根据系统后台记录显示,针对同一评测任务,用户上传自训练模型次数越多,与系统自带模型预测结果对比差距越小,说明用户根据系统自带模型预测结果对线下训练的模型进行了一定的参数调整或算法改良后,达到了更好的预测效果。本系统具有以下特点:
(1)支持用户管理模型。用户可通过线下训练模型再上传至系统的方式,与系统模型进行算法性能对比,也可直接使用系统自带模型评测数据集。
(2)3 种评测任务均拥有医学专家人工标注的标准评测数据集,用户可下载至本地,线下训练自建模型。
4 结语
本研究通过建设面向中文医学文本的知识图谱通用评测系统,解决当下医学知识图谱领域面临的无法评估技术水平的痛点。结合医学专家人工标注真实临床文本数据构建的标准评测数据集,在一定程度上提升了标准评测任务评估技术水平。但本系统仍存在一些不足:由于获取的数据资源有限,知识库扩充难度高,难以保证知识库内容覆盖全面;知识库数据影响评测结果,因此入库数据要求严格,在数据标注规则迭代更新的同时,对满足标注资质的标注人员的培训还需不断加强。下一步将致力于解决数据长尾分布带来的研究痛点,融入迁移学习技术,合理有效地利用大、小样本数据,提升系统评测任务数据集的标注能力,扩充知识库内容,使数据能够覆盖更大范围的医学文本内容。
猜你喜欢
家庭影院技术(2021年2期)2021-03-29
家庭影院技术(2021年1期)2021-03-19
少先队活动(2020年12期)2021-01-14
动漫星空(兴趣百科)(2020年12期)2020-12-12
祝您健康(2020年4期)2020-05-20
中国自行车(2018年11期)2018-12-03
中成药(2017年3期)2017-05-17
中国自行车(2017年1期)2017-04-16
领导科学论坛(2016年9期)2016-06-05
新校长(2016年5期)2016-02-26
