
情感增强的对话文本情绪识别模型
2023-03-24 13:24王雨袁玉波过弋张嘉杰
计算机应用 2023年3期
王雨,袁玉波,过弋,3,张嘉杰
(1.华东理工大学 信息科学与工程学院,上海 200237;2.上海大数据与互联网受众工程技术研究中心,上海 200072;3.大数据流通与交易技术国家工程实验室(上海数据交易所),上海 200436)
0 引言
近年来,随着人工智能和社交媒体大数据的快速发展,情绪(emotion)分析已经在社交舆情分析、用户画像以及推荐系统等多个领域广泛应用。情感(sentiment)是人类固有的一种基本的内在状态,在人类交流中帮助传达和理解实际信息,因此情感理解对于情绪分析十分重要。
在社交媒体大数据开发应用领域的网络对话文本中,说话人的情绪识别(Emotion Recognition in Conversation,ERC)作为自然语言处理(Natural Language Processing,NLP)的新课题越来越受重视,因为它具有从Twitter、微博、微信等平台上大量公开可用的交互式数据中挖掘舆情的能力。此外,对话情绪识别在医疗保健系统、智能教育、视觉问答等方面具有应用潜力。近几年,电商智能客服、闲聊机器人等对话系统的应用越来越广泛,但是它们往往缺乏带有情感的交流,不能很好地识别用户在对话中的情绪和情感,因此有必要研究对话中蕴含的情感信息。
对话情绪识别本质上是分类任务,旨在对一段对话中的话语进行情绪分类。与传统的文本分类任务不同,对话文本存在信息的交互以及说话人情感的影响,说话人的情绪变化不仅受自己情绪状态的影响,还受到对方说话人的情绪状态的影响,说话人之间的依赖和自我依赖之间总是存在重要的相互作用。因此需要综合考虑对话上下文、说话人、说话人的个性、意图、对彼此的态度等,分析这些因素可以得到丰富的会话信息。
情感和情绪都是人类主观的感受,因此它们的理解是相似的,并且经常互换使用。之前的相关研究大多将其视为两个独立的问题,情感分类多为情感正负极性的判断,而情绪识别多为更细粒度的情绪识别。文献[1-2]表明情感和情绪密切相关,大多数情绪状态都有明显的积极或消极的区别。如“愤怒”“恐惧”“悲伤”等,属于消极的情绪,而“高兴”和“惊讶”反映了积极的情绪。因此话语的情感知识(或情绪)可以帮助对其相邻话语分类,例如关于愤怒情绪的信息可以帮助预测负面情感,反之亦然。
本文的主要工作如下:1)将对话主题信息和行为信息融入对话文本,通过微调预训练语言模型RoBERTa[3]提取重构的句子特征。2)通过图神经网络(Graph Neural Network,GNN)建模对话上下文,并引入情感分类辅助情绪识别任务,将情感分类损失作为惩罚项设计了新的损失函数,动态调节权值。3)在DailyDialog 公开数据集[4]上进行大量实验,验证了本文方法的有效性。
1 相关工作
早期的情绪识别工作主要依赖于支持向量机(Support Vector Machine,SVM)[5]、规则匹配等。随着深度学习的发展,目前的情绪识别工作主要依赖于神经网络,如卷积神经网络(Convolutional Neural Network,CNN)[6]、循环神经网络(Recurrent Neural Network,RNN)[7]等。由于社交媒体平台上开源会话数据集的增加,ERC 引起了越来越多的研究兴趣。
Hazarika等[8]提出了 会话记 忆网络(Conversational Memory Network,CMN)为二元会话的参与者模拟人类交互,并利用说话人相关的记忆进行情绪识别。Hazarika等[9]扩展CMN,提出另一种用于模拟人类交互的记忆网络,称为交互式会话记忆网络(Interactive Conversational Memory Network,ICON),将所有历史话语包含在对话参与者的上下文窗口内,作为整体对话记忆。Majumder等[10]提出了一个基于RNN 的基准模型,使用三个门循环单元(Gated Recurrent Unit,GRU)跟踪单个说话人在对话中的状态、情绪状态和全局语境。另一方面,作为语境信息的一种考虑方式,Shen等[11]利用增强的记忆模块存储更长的历史上下文,并利用对话感知的自我注意以捕获有用的内部说话人依赖关系。此外,融入外部知识以及情感知识也是目前研究者探索的方向。Zhong等[12]通过多层自注意力机制理解上下文,同时,通过上下文感知的情感图注意机制将外部常识利用起来。Bhat等[13]通过在对话中添加情感词、主题词汇来为句子添加基于上下文的情感特征,通过微调预训练语言模型RoBERTa获得了不错的结果。
除了使用RNN 等序列结构处理对话中的话语序列,还有许多研究者通过图卷积网络(Graph Convolutional Network,GCN)结构建 模对话。Ghosal等[14]提出DialogueGCN(Dialogue Graph Convolutional Network)模型,利用GCN 模拟对话中的交互,并考虑未来的窗口话语。Ishiwatari等[15]针对DialogueGCN 没有考虑顺序信息的问题,在图网络中加入关系位置编码以捕获说话人的依赖性和话语的顺序。彭韬等[16]将文本的句法依存关系引入模型,通过GCN 提取句法结构信息,并与文本情感分析模型相结合。Shen等[17]提出用有向无环图(Directed Acyclic Graph,DAG)对话语进行建图,结合话语顺序结构设计了DAG-ERC(Directed Acyclic Graph-Emotion Recognition in Conversation)模型。
也有研究使用情感和其他任务的联合学习方法,利用多个任务之间的相关性提升分类性能。Qin等[18]提出深度协同交互关系网络(Deep Co-interactive Relation Network,DCR-Net),引入协同交互关系层建模对话行为识别(Dialog Act Recognition,DAR)和对话情感分类任务之间的交互。
基于上述相关研究,考虑到对话文本通常较短,存在表达能力有限等问题,而且对话主题和意图有助于建模说话人之间的影响,本文在话语特征提取阶段融入对话主题和意图信息从而提取更丰富的话语特征表示,然后基于GNN 建模对话结构和说话人信息,避免RNN 模型存在的长距离依赖问题。另一方面,本文针对对话情感和情绪存在一定关联的特点,通过基于双向长短时记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)模型的情感分类任务辅助情绪识别任务,从而提高模型情绪识别性能。
2 任务定义
2.1 问题定义
对话情绪识别的问题定义如下:
假设在一段对话中有M个说话人,用符号表示为P={p1,p2,…,pM},有N个句子的对话U={u1,u2,…,uN},其中:第i个说话人的话语ui={wi1,wi2,…,wini},ni为第i个句子中词的数量。对话情绪识别的问题表示如下:
即在给定的模型空间H中,求得一个最优的识别模型F*,在已知情绪标签的数据集合U上,使模型的识别结果和已知标签的差异极小。
2.2 情感对对话情绪识别的影响分析
下面分析说明情感和情绪之间的内在关系以及对话结构对它们的影响。
表1 是一段由A、B 两个人参与的对话示例。A 表现出“惊讶”的情绪,情感倾向是积极的。而随着对话轮次进行,A 的情绪逐渐变为“中性”“生气”,相应的情感倾向也变为消极,而B 随着A 的情绪变化也发生了变化,并且情感倾向的变化相似。这说明对话中说话人的情感和情绪之间存在一定的关联性,一个话语的情感(或情绪)经常与其他语境话语相互依赖,即情感(或情绪)可以对相邻话语进行分类。

表1 对话示例Tab.1 Example dialogues
在对话中特别是两人对话中,说话人之间表达的情感是动态变化的并且会相互影响,通常体现在说话人的自我影响和说话人之间的影响。自我影响或情感惯性是指说话人在谈话中对自己的情感影响。参与者对话由于自身的情绪惯性,很可能会坚持自己的情绪状态。而说话人之间的影响指对方在说话人身上产生的情感影响。这种影响与这样一个事实密切相关,即在对话过程中,说话人倾向于模仿他们面对的人来建立融洽的关系。
情感的表达方式、话语的意义也会随对话的主题变化而变化。通常,围绕特定主题的对话存在不同的语言表达方式,不仅影响话语的意义,还影响特定的情感因素的表达。对话行为或者对话意图指在一段对话中说话人说的某句话的动机。对话意图的不同使说话人在对话中表达的情感也会不同,并且两者也存在一定关联。通过识别说话人的意图能帮助检测话语中隐含的情感。此外,对话通常包含许多较短的文本,表达的信息可能有限。所以本文融合对话主题和意图信息以丰富句子的语义特征。
对话情绪识别的难点在于不同说话人之间的情感相互影响,并且依赖上下文信息。本文通过分析发现对话中说话人的情绪变化和情感倾向变化趋势相似,存在一定关联;对于同一个说话人,其情感倾向起伏不会很大。基于此,本文基于GNN 并考虑说话人信息来建模对话结构,探索通过粗粒度的情感分类任务来辅助细粒度的情绪识别性能,并融入主题和意图信息增强文本特征。
3 情感增强的对话情绪识别模型
本文提出的SBGN(Sentiment Boosting Graph Neural network)模型如式(2)所示:
即在模型中,融入了主题(s)和意图(a)数据,通过对话情感分类结果优化提升情绪识别的结果。SBGN 模型定义为情感增强的对话情绪识别模型,技术架构如图1 所示。
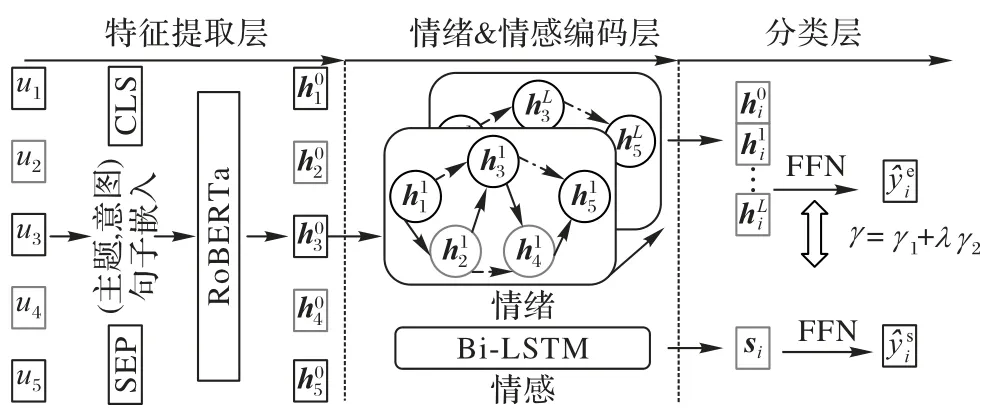
图1 模型框架Fig.1 Model framework
SBGN 模型主要包括三个部分:
1)主题特征增强的话语编码。说话人级别的上下文编码器将对话主题和行为信息与原始话语拼接,通过微调预训练模型RoBERTa 作为自编码器得到情感增强的话语特征。
2)情绪与情感对称学习。在情绪识别模型中,通过堆叠L层的图网络编码对话上下文和说话人信息得到输出向量,拼接L层的隐层向量以及原始特征,然后通过前馈神经网络(Feed-Forward Neural network,FFN),最后经过Softmax 层得到话语属于每一类情绪标签的概率。在情感分类模型中,首先将增强特征输给Bi-LSTM 模型,之后应用线性变换,并通过Softmax 层得到情感标签结果。两个任务共享底层特征,分别经过不同的模型结构进一步编码得到不同任务下的话语表征,最后进行联合优化,在形式上形成“对称”的两部分。
3)情感与情绪的融合优化。SBGN 模型通过调节损失调节因子平衡情感和情绪识别任务。
3.1 话语特征重构
考虑到RoBERTa 强大的特征提取能力,本文通过微调RoBERTa 提取话语级的句子特征,在后续模型训练中冻结其参数。本文将对话主题和意图作为数据增强映射到话语级别进行特征重构。结合DailyDialog 数据集标注信息,本文选择的对话主题包括{日常生活,学校生活,文化和教育,态度和情感,关系,旅游,健康,工作,政策/政治,经济}10 个类别,对话意图 包括{通知(Inform),疑问(Questions),建议(Directives),接受/拒绝(Commissive)}四个方面。
具体的,对话语ui,拼接其对应的主题数据ti和意图数据ai得到=ti⊕ai⊕ui={ti,ai,wi1,wi2,…,wini}。重构以后数据的输 入形式 为[CLS]ti,ai,wi1,wi2,…,wini[SEP],其中:[CLS]是用于分类的特殊符号,[SEP]是令牌分隔符。
在下游微调分类任务,将模型最后一层[CLS]的嵌入表示gi作为话语的特征表示,如式(3)所示:
3.2 情感增强的对话情绪识别模型
在ERC 任务中,除了建模对话结构,如何有效地模拟说话人的互动也是一个难点,除了需要捕捉当前说话人的自我影响之外,还需要考虑其他参与者状态对他的影响。本文通过图网络建模会话信息流,并在建图过程中模拟说话人之间的交互进行情绪识别。下面介绍图网络的构建与学习过程。
3.2.1 对话图构建
本文将对话图定义为G={V,ε,R,Ω},其中:V表示节点的集合;ε表示连接这些节点和边的集合;Ω和R分别表示边的权重和关系类型。下面介绍对话图的构建方法。
节点:对话中的每一个话语作为节点vi∈V,第一层节点向量由前述提取话语特征gi初始化,堆叠L层图网络后节点表示更新为。
边:考虑说话人的自我影响和对话参与者的影响,本文构建了两种关系类型的边。
1)自我影响。当前说话人的话语节点vi与他自身前一个直接话语节点之间连边,即:∃(j,i,rji)∈R。
2)说话人之间的影响。当前说话人的话语节点vi与其他说话人的直接话语节点相连,即:∃(k,i,rki)∈R。
因此关系集合R={0,1},1 表示两个连接的语句来自同一个说话人,0 表示来自其他说话人。
图2 是构建的对话图的一个示例。对话中有5 句话{u1,u2,…,u5},u1、u3、u5由说话人A 说出,u2和u4来自说话人B。对于节点v3,与它来自同一个说话人的最近话语为v1,来自不同说话人的最近话语为v2。由构建边的约束可知,节点v1和v2之间的边e12∈ε表示不同说话人之间的影响,节点v2和v3之间的边e23∈ε表示自我影响。图2 中说话人之间的影响和自我影响分别用实线和虚线表示。
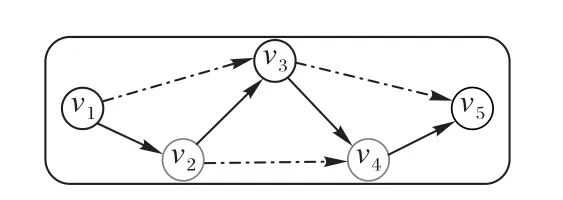
图2 对话图示例Fig.2 Sample dialogue diagram
边权重:通过注意机制计算当前节点与邻居节点之间的权重。具体的,对于第l层的节点vi,通过它在l-1 层的隐状态与l层的邻居节点的隐状态计算得到注意权重,如式(4)所示:
其中:Vi表示vi的邻居节点集合;是可训练的权重参数矩阵;‖表示拼接操作。
3.2.2 图表示学习
本文采用与文献[16]中类似的方式聚合和更新节点信息,按照序列顺序聚合每个节点的信息,并在同一层更新节点的状态,在传播步骤中利用了GRU 的门控机制。由于构建的对话图是多关系图,所以本文结合不同的关系类型并基于注意机制,对节点vi聚合邻居节点信息,即隐含地考虑了不同的说话人信息。第l层的节点聚合方式如式(5)所示:
其中:Vi为vi的邻居节点集合表示不同关系的可训练参数。得到聚合信息后,通过GRU 集成来自其他节点和前一层的信息,得到当前层每个节点更新的隐藏状态向量在GRU 中,重置门r决定是否忽略先前的隐藏状态,更新门z决定是否更新隐藏状态与新的隐藏状态。计算过程如下:
其中:Wr、Wz、Wh、Ur、Uz、Uh是可训练的参数矩阵是经过GRU 更新后的向量;σ是Sigmoid 激活函数;⊙是哈达玛积。
为了更好地学习上下文信息,本文使用另一个GRU 利用前一层的节点隐藏状态控制当前聚合信息的传播。将与在GRU 的位置互换,计算得到上下文信息
将两者相加作为节点在第l层最终表示
3.3 情感分类模型
情感分类任务旨在通过判断句子的情感极性辅助情绪识别。因此本文忽略情感分类模型中对说话人的建模,简单地将其视为对话中话语的情感倾向分类,并通过不同情感分类网络对比效果。首先,为了使特征更加适用于任务,本文将提取的句子特征进行线性变换,然后利用Bi-LSTM 模型编码,得到一系列隐藏句子向量。即在每个时间步输入对话中的一个话语,将正向和反向最后一个隐藏向量拼接作为话语的最终表征si,然后进行后续分类。
此外,在具体实验中,本文还对比了不同情感分类模型的效果,用多层感知机(Multi-Layer Perceptron,MLP)代替Bi-LSTM,然后通过Softmax 层进行分类。
3.4 分类与联合优化
对于情绪分类任务,本文将所有图网络层句子ui的隐藏状态拼接作为话语的最终表示Hi,然后经过一个全连接网络和Softmax 层预测情绪标签。
对于情感分类任务,将得到的话语向量经过Dropout 层和Softmax 层进行情感分类:
其中:Se和Ss分别表示情绪和情感标签集合。
由于模型分为细粒度的情绪分类和粗粒度的情感倾向分类两个子任务,所以需要同时优化两个任务的损失函数,又由于两个子任务都是多分类任务,所以本文选用交叉熵作为损失函数。在实验中,将情绪识别视作主任务,而情感分类作为辅助任务,对整个模型进行多目标联合训练。即将情感分类的损失作为惩罚构建新的损失函数,通过学习动态寻找最优的权重系数。损失函数定义如下:
其中:N表示对话总数;Ni表示每个对话中的话语数目;λ为调节因子;γ1和γ2分别是情绪识别和情感分类的损失函数。最终的损失函数为两者加权和。
4 实验与结果分析
4.1 实验数据集
本文使用的是公开的DailyDialog 英文数据集,这是一个多轮的日常对话数据集,包含了人类的日常交流数据,并标注了对话主题和对话行为。情绪标签有7 类:中性、快乐、惊讶、悲伤、愤怒、厌恶和恐惧。对于情感标签,将“快乐”和“惊讶”标注为“积极”,“中性”标注为“无情感”,其他标注为“消极”。本文对原始数据集采用标准分割方式,使用11 118 个对话进行训练,1 000 个对话进行验证,1 000 个对话进行测试。训练集、验证集和测试集分别有87 170、8 069、7 740 个句子,每个对话大概有8 轮。
由于数据情绪类别不均衡,本文选择不包括多数类(中性)的微平均F1(Micro-F1)作为情绪识别评价指标,宏平均F1(Macro-F1)作为情感分类的评价指标,根据真正性TP(True positives)、真负性TN(True Negatives)、假正性FP(False Positives)、假负性FN(False Negatives)计算:
其中:IF1是精确率P(Precision)与召回率R(Recall)的调和平均值;K为类别数。
4.2 实验参数设置
通过验证集调整模型超参数,包括学习率、批量大小、图网络层数、损失调节因子等。在RoBERTa 特征提取中,特征维度为1 024;对于情绪分类模型,GNN 隐藏层维度为300,层数为3,学习率为2× 10-5,丢弃率为0.3;对于情感分类模型,Bi-LSTM 模型为两层,隐藏层维度为512,丢弃率为0.5,学习率为2× 10-5;MLP 隐藏层维度为256,丢弃率为0.2,学习率相同。对于损失调节因子,设置其取值范围为[0.1,1],每次实验增加0.1,模型批量大小为64。本文实验使用Pytorch 框架,每个训练和测试过程都运行在单个RTX 2080 Ti 上。
4.3 情感分类模块选择
SBGN_Bi-LSTM 为本文提出的没有经过特征重构的模型,通过图网络建模对话上下文,情感分类模块选择Bi-LSTM 模型,调整损失调节因子联合优化,取其中的最优结果作为模型结果;SBGN_MLP 与SBGN_Bi-LSTM 模型的方法相同,情感分类模块为MLP,调整损失调节因子联合优化并选择最优结果。
通过实验对比,SBGN_Bi-LSTM 的微平均F1 和宏平均F1为59.45%、67.50%;SBGN_MLP 的微平均F1 和宏平均F1 为59.22%、67.53%。因此选择Bi-LSTM 作为SBGN 模型的情感分类模块。
4.4 与基准模型比较
本文选用以下方法进行对比分析。
1)MLP:利用MLP 作为分类器,情感分类和情绪识别分别训练一个模型。
2)DialogueGCN:以句子作为节点构建对话图,考虑说话人之间的依赖和自我依赖,在对话图中基于固定上下文窗口连接不同关系节点,考虑过去信息的同时还考虑了未来信息,模型通过GCN 更新节点表示。
3)RGAT(Relation Graph Attention Network)[14]:以句子作为节点,对不同说话人基于关系位置编码建模对话结构,基于图注意网络(Graph Attention Network,GAT)更新节点,同时考虑过去和未来信息。
4)DAG-ERC:以句子作为节点,通过有向无环图建模对话上下文,结合注意力机制和不同说话人收集信息更新句子节点,只考虑历史节点。
5)Bi-LSTM:预训练语言模型提取特征之后通过Bi-LSTM 层,然后通过线性层分类,情感分类和情绪识别分别训练一个模型。
6)Joint MLP(Joint Multi-Layer Perceptron):单层MLP 作为分类器,情绪和情感模型采用本文的权重调节方式联合训练。
7)Joint LSTM(Joint Long Short-Term Memory Network):情绪和情感联合训练模型,堆叠两层单向LSTM,情感和情绪模型采用本文的权重调节方式联合训练。
8)Joint Bi-LSTM(Joint Bidirectional Long Short-Term Memory network):情绪和情感联合训练模型,堆叠两层Bi-LSTM,情感和情绪模型采用本文权重调节方式联合训练。
9)SBGN:本文提出的经过特征重构的模型,其中情绪识别任务选择Bi-LSTM,调整损失调节因子联合优化,取最优结果作为最终结果。
对比实验结果如表2 所示。微平均F1 和宏平均F1 分别为5 次实验取平均后情绪识别和情感分类的结果,调节因子选择取平均后微平均F1 最好的值。
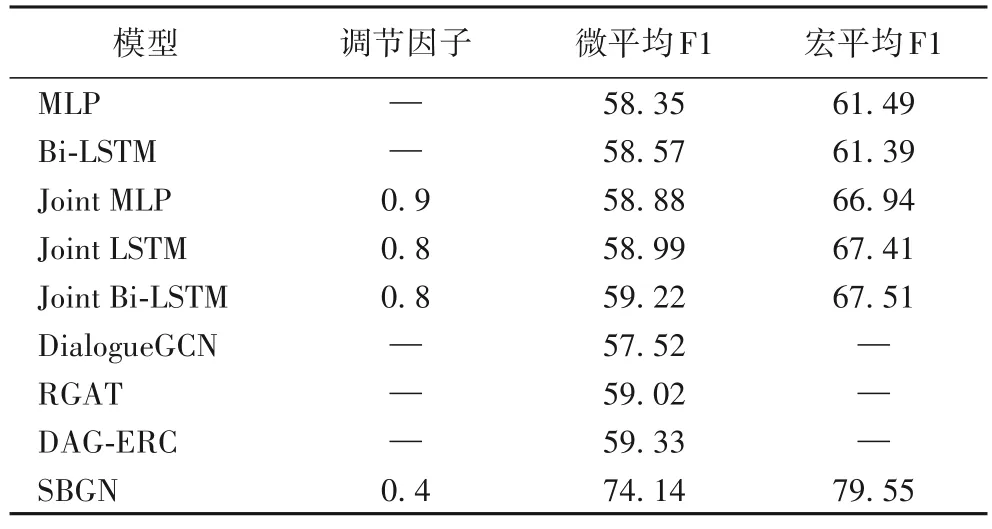
表2 与基准模型的比较 单位:%Tab.2 Comparison with baseline models unit:%
由表2 可以看出:
1)相较于MLP、Bi-LSTM 模型,本文提出的SBGN 模型在情感分类结果上均有提升,说明基于图网络的方法能够更好地建模对话中的说话人信息和上下文信息,有效传递对话历史信息,对话中的情绪识别需要综合考虑上下文信息和说话人之间的依赖性。
2)联合优化模型Joint MLP、Joint LSTM、Joint Bi-LSTM 相较于两个单任务模型MLP 和Bi-LSTM 效果均有所提升,说明情感分类在一定程度上能够辅助细粒度情绪识别任务,反之情绪识别也能提高情感分类的效果,两个任务正相关,同时也证明了本文通过加权调节惩罚因子方法的有效性。
3)相较于基于GCN、GAT 等的模型,SBGN 模型的性能有一定提升。特别是在特征增强之后微平均F1 值提升较大,说明主题信息和对话行为信息能够弥补短文本表达信息有限的问题,丰富文本表示。
4)相较于DialogueGCN 模型与目前较先进的DAG-ERC模型,SBGN 的微平均F1 提高16.62 与14.81 个百分点。
5)情感分类整体的指标高于情绪识别,这可能是由于情感分类的分类粒度比较粗、分类任务相对简单,模型更容易学习,通过一些基础的模型就可以达到较好的效果。
在以上的模型中,SBGN 模型获得了最优结果,说明本文通过情感倾向分类任务辅助情绪识别的设想是正确的。通常一句话会有一个确定的整体情感倾向,而不同的情感倾向对应不同的情绪类别,因此将两者结合起来是一个值得探索的方向。未来本文将试图通过注意机制等方式将两个任务联合建模。另一方面,融入对话主题信息和对话行为信息之后模型效果提升明显,说明对话主题和对话行为是对话情绪识别等任务中不可忽略的特征,也说明丰富的背景信息能够帮助分类。此外,实验结果也表明本文通过有向图结构建模对话图符合实际的对话流,这种图结构可以在单个层中重复收集每个话语的前置信息,从而使包含较少层次的模型就能获得远距离的历史信息,并能处理不同说话人之间的依赖。
本文考虑了几种不同模型的组合,通过对比情绪分类最优调节因子下的微平均F1 验证本文特征重构以及联合优化方法的有效性。实验结果如表3 所示,设计了8 组实验,对比各模型特征重构前的基础特征与重构后的增强特征的差异。LSTM 模型是单向长短时记忆网络,与Bi-LSTM 方法类似;DAG-ERC 的重构特征结果为按照作者提供代码复现所得。
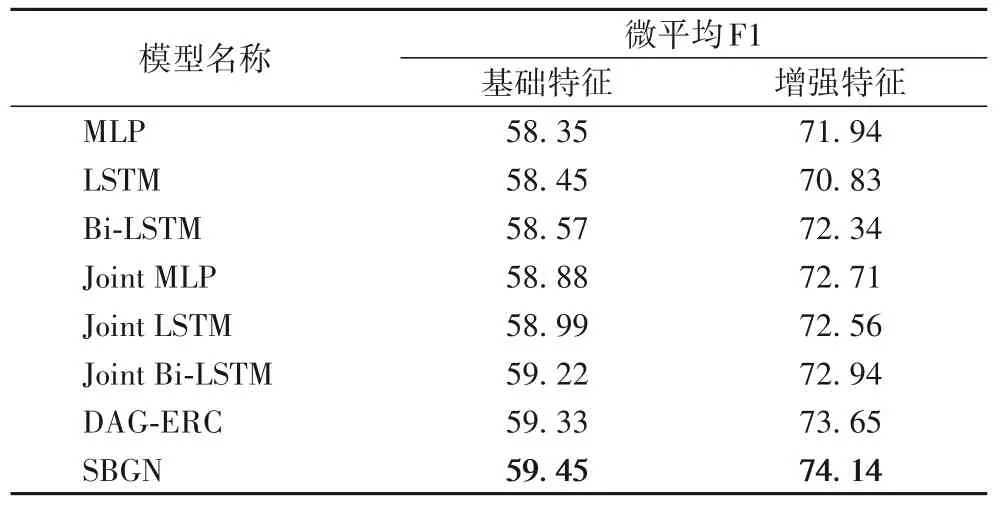
表3 不同特征下的结果对比 单位:%Tab.3 Comparison of results under different features unit:%
分析表3 可以看出:
1)与没有进行特征重构的模型的基础特征结果相比,所有重构后的模型的性能都获得明显提升。因为DailyDialog数据集中的文本大多较短,平均每句话长度为14.6 个词,所以通过嵌入外部信息一定程度上能够丰富句子的表达,提取更多文本特征。这也说明对话中的情绪与对话中的主题和对话意图存在一定的关联性。这一定程度上说明用与对话相关的信息扩充特性可以带来明显的性能改进,不一定需要建模更复杂的模型。
2)联合优化模型在进行特征重构后依然优于单任务模型,说明情感和情绪相互关联,通过情感分类能够帮助提升情绪识别性能。而对于对话中的情感分类,MLP 模型与LSTM 模型特别是Bi-LSTM 效果差别不大,总体上Bi-LSTM模型略优。
另外,通过RoBERTa 提取特征之后,通过全连接网络这样的简单网络编码进行句子分类的效果与Bi-LSTM 效果区别不大,也侧面说明了预训练语言模型强大的特征提取能力,只需要简单的线性变换和全连接网络即可得到很好的分类结果。
4.5 损失调节因子对比
此外,本文对比了两种模型在不同损失调节因子下的结果,如图3 所示。图3(a)为没有重构特征时的SBGN_MLP 和SBGN_Bi-LSTM 模型情绪分类的Micro-F1 值;图3(b)展示了嵌入主题和意图信息之后对应的Micro-F1 结果。
分析图3(a)可以看到,SBGN_MLP 模型性能随着损失调节因子改变有所上升,但是变化不大,说明MLP 网络比较简单,性能趋于稳定。而SBGN_Bi-LSTM 模型变化幅度较大,除了存在一定的随机性之外,与模型结构也存在一定关系,Bi-LSTM 能更好地建模对话中的序列关系,性能提升明显。另外,本文推测也与对话数据有关,模型容易受数据质量影响。当SBGN_Bi-LSTM 模型在损失调节因子λ=0.5 时获得了最优结果,SBGN_MLP 模型在λ=0.9 时获得最佳结果。这可能是由于MLP 模型需要更多的情感分类“知识”来辅助情绪识别。相比之下,Bi-LSTM 模型更加复杂,在少量外部信息的情况下即可获得较好的结果,权重过大反而会损失模型性能。
从图3(b)可以看出,当输入增强后的特征时,SBGN_MLP 模型的最优调节因子变小,SBGN_Bi-LSTM 模型也有所减小,两者的最优结果相差不大。说明通过特征重构嵌入主题信息和意图信息能丰富句子特征,在较少外部信息辅助时,情绪识别模型可获得更好的分类结果;也说明当提取的特征比较丰富时,通过较简单的模型也能获得比较好的结果。这也启发我们尽可能地提取文本的特征,借助外部知识库丰富文本信息也是一个值得探索的方向。
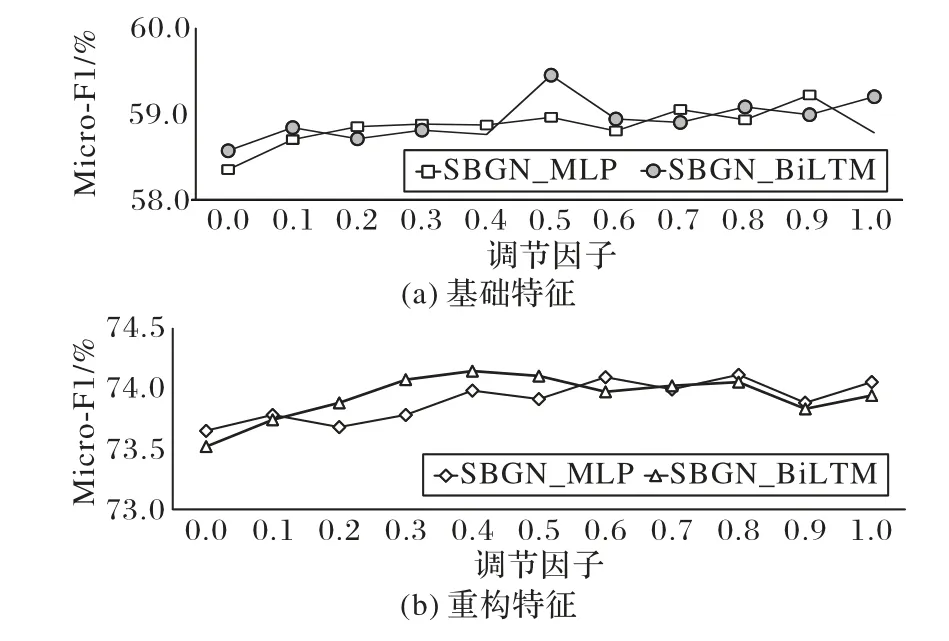
图3 损失调节因子对比Fig.3 Comparison of loss adjustment factor
4.6 时间消耗
本文对比了SBGN、SBGN_MLP、SBGN_Bi-LSTM 与DAG模型的计算时间消耗情况,如表4 所示所有模型选择最优调节因子下,5 次实验的平均1 个epoch 的结果。可以看出,联合优化模型的运行时间都高于单一的DAG-ERC 模型,并且主要与图网络有关。因为模型复杂度主要与图网络层数L和对话长度N有关,通常网络层数越深、对话规模越大,复杂度越高。而Bi-LSTM 比MLP 复杂,所以SBGN_Bi-LSTM 模型的运行时间高于SBGN_MLP 模型。由于特征已经固定,输入维度一致,所以重构特征前后模型运行时间基本一致。虽然本文提出的联合模型SBGN 时间消耗略高,但是F1 指标更优。后续将探索如何在保证算法有效的同时提高效率。

表4 不同模型的运行时间比较 单位:sTab.4 Comparison of running time among different models unit:s
5 结语
本文提出了一种情感增强的图网络对话情绪分析模型(SBGN),通过图结构建模对话上下文和说话人的依赖关系,并与情感倾向分类联合优化。针对文本较短问题以及对话数据特点,本文在特征提取阶段融入对话主题和对话意图信息丰富短文本表示。实验结果表明,SBGN 模型取得了较好的性能。此外,还可以得出几个结论:首先,基于对话上下文和说话人依赖的对话图结构能有效建模对话信息流,从较远的话语中获取更多的信息;其次,情感和情绪是密切相关的,通过情感分类所获得的信息能帮助情绪识别;最后,对话主题信息和意图信息能够辅助情绪识别,缓解短文本表达能力有限的问题。未来,我们将探索如何在模型中更好地建模对话情感与情绪之间的交互,如应用注意力机制等,并考虑引入外部知识库、情感词典等辅助分类。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
河北画报(2021年2期)2021-05-25
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
浙江人大(2014年6期)2014-03-20
浙江人大(2014年5期)2014-03-20
