
基于几何适应与全局感知的遥感图像目标检测算法
2023-03-24 13:25顾勇翔蓝鑫伏博毅秦小林
计算机应用 2023年3期
顾勇翔,蓝鑫,伏博毅,秦小林*
(1.中国科学院 成都计算机应用研究所,成都 610041;2.中国科学院大学,北京 100049)
0 引言
近年来,随着航天遥感技术的不断发展,遥感图像数据不断丰富,而且遥感数据中含有飞机、车辆、桥梁等敏感目标,因此对遥感图像进行目标检测在国防安全、灾害预测、智慧城市建设等领域具有重要意义。
自2012年AlexNet[1]被提出,卷积神 经网络(Convolutional Neural Network,CNN)已经从根本上改变了计算机视觉任务的处理方式。借助CNN 强大的特征表达能力,图像分类[2]、目标检测[3]及语义分割[4]等任务的性能取得了巨大提升。在COCO(Common Objects in COntext)[5]目标检测任务中,测试集的平均精度均值(mean Average Precision,mAP)已经提升到63.1%[6],表现出不俗的性能。基于神经网络的目标检测算法主要分为以R-CNN(Region-based Convolution Neural Network)[7]为代表的两阶段检测器和以YOLO(You Only Look Once)[8]系列为代表的单阶段检测器。它们最主要的区别在于:单阶段检测器直接在特征图上生成候选框,而两阶段检测器通过额外的区域建议网络生成候选框。Faster R-CNN(Faster R-CNN)[9]是经典的两阶段检测器,它将特征提取、区域建议、边界回归和分类集成到一个框架中,显著提高了检测性能;然而,额外的区域建议网络需要大量的计算资源,限制了处理速度。而经典的单阶段检测器YOLO 结合前沿技术迭代更新,具有良好的实时性。
遥感图像目标检测算法大多由通用目标检测算法改进而来。虽然这些算法能够在自然场景的数据集上表现出良好的检测性能,但是遥感图像存在背景复杂、目标方向任意和目标尺寸小等问题,传统的CNN 难以有效提取遥感图像目标的几何特征和全局信息,检测效果不佳。
为提高遥感图像目标检测的精度,本文基于YOLOv5[10]提出一种基于几何适应与全局感知的遥感图像目标检测算法。本文的主要工作有:1)针对遥感图像目标尺寸小、目标方向任意的问题,将可变形卷积和自适应空间注意力模块通过密集连接串联堆叠,然后构建密集上下文感知模块(Dense Context-Aware Module,DenseCAM),进一步学习对遥感目标几何形变具有稳健性的深度特征,以解决普通卷积对局部几何特征提取不足的问题;2)针对遥感图像背景复杂的问题,在骨干网络末端引入Transformer,以较小的开销增强全局特征的提取能力,通过挖掘遥感图像全局背景信息进一步增强模型的分类能力;3)联合使用局部上下文和全局信息,形成特征互补,进一步提高遥感图像目标检测精度。
1 相关工作
1.1 YOLO算法基本原理
YOLOv1[8]将目标检测视为单一的回归问题,通过CNN直接在一张完整的图像上预测目标类别概率并进行边界框回归。首先将输入图像划分为一定大小的网格,每个网格负责检测中心上的目标;然后根据CNN 提取的特征一次性预测目标的边界框位置、大小、定位置信度以及所有类别概率向量;最后通过非极大值抑制算法进行后处理。
YOLO 算法经历数次更新迭代,在目标检测领域表现突出。YOLOv5 是最新版本,融合了许多高效的技术。在骨干网络中,使用跨阶段局部(Cross Stage Partial,CSP)[11]网络,降低计算开销并优化梯度更新过程,使用空间金字塔池化(Spatial Pyramid Pooling,SPP)[12]模块融合不同感受野特征;在特征融合网络中,使用PANe(tPath Aggregation Network)[13]增强信息流动并聚合特征;使用广义交并比(Generalized Intersection over Union,GIoU)[14]增强对实例尺度的感知;使用K-means 聚类算法生成适应数据集实例分布的锚点框;使用Mixup[15]和Mosic[16]进行数 据增强;使 用SiLU(Sigmoidweighted Linear Units)[17]增强网络的非线性映射能力。
1.2 面向遥感场景的目标检测优化算法
CNN 已被应用于遥感目标检测领域,但遥感图像是俯瞰拍摄,与自然场景图像存在较大差异,它的特点为目标尺寸小、目标方向任意和背景复杂,因此遥感目标检测是一个亟待解决的任务。为解决遥感图像密集区域中目标形变的问题,高鑫等[18]在CNN 中引入可变形卷积和可变形感兴趣区域(Region of Interest,RoI)池化模块[19]增强网络对几何变换的建模能力,提高了密集区域车辆目标的检测性能,但未关注遥感图像复杂背景的问题。为解决遥感目标易受背景相似物干扰的问题,胡滔[20]在分类检测头中引入双路径通道注意力模块,减弱噪声区域通道的特征响应并增强分类特征。针对遥感目标尺度多样的问题,田婷婷等[21]在特征金字塔网络(Feature Pyramid Network,FPN)[22]中,使用空洞卷积代替普通卷积并增加跳跃连接操作以实现遥感场景下的多尺度特征融合。此外,遥感图像往往包含更多的背景噪声,从而导致目标的边界信息模糊,难以有效提取目标的几何信息。Xu等[23]将浅层特征和采样后的深层特征以相同尺度融合来解决特征提取不充分的问题。汪亚妮等[24]在SSD(Single Shot multibox Detector)模型中引入注意力分支,与检测分支融合得到了更加丰富的语义信息。
从目标检测流程来看,骨干网络提取的特征是后续特征融合的基础,具有重要意义。但是目前许多遥感目标检测工作并没有关注骨干网络的结构设计。回顾遥感图像的成像过程与待检测目标特点,本文在骨干网络的设计上获得如下启发:1)遥感图像呈现的视角为俯视图,目标尺寸小且方向任意,通过增强局部几何特征建模,有利于增强定位能力。2)遥感图像俯瞰拍摄,包含更多的空间信息,背景复杂,通过综合全局信息挖掘同类共性特征,有利于增强分类能力。
2 改进的YOLOv5目标检测算法
2.1 网络结构
本文基于YOLOv5 提出一种基于几何适应与全局感知的遥感图像目标检测算法,由骨干网络、特征融合网络、检测头三部分组成,如图1 所示。其中:Ci是输入图像进行2i倍降采样后生成的特征图;骨干网络输出对应整张输入图像的特征图;特征融合网络使用PANet 融合C3~C6的多层次特征图以获取多尺度信息;检测头则基于候选框进行分类与位置回归;P3~P6为融合C3~C6后生成的新的特征图。改进算法保留了骨干网络浅层的跨阶段局部网络设计,将SPP 模块替换为DenseCAM,增强对局部几何特征的建模能力;在骨干网络末端引入 Transformer,使用 C3TR(Cross stage partial bottleneck with 3 convolutions and TRansformer)模块代替原始全卷积操作,增强模型的全局信息感知能力。

图1 改进YOLOv5s6的框架Fig.1 Framework of improved YOLOv5s6
2.2 密集上下文感知模块DenseCAM
在遥感目标检测任务中,局部上下文信息对提高定位能力至关重要,因为它可以提供额外的定位相关信息。所提DenseCAM 模块如图2 所示,由包含通道压缩函数fC、可变形卷积v2(Deformable Convolution Network v2,DCNv2)[25]和自适应空间注意力模块(Adaptive Spatial Attention Module,ASAM)的基本结构使用密集连接串联堆叠两次构成。

图2 DenseCAM模块结构Fig.2 Module structure of DenseCAM
为学习变换不变性特征并提取丰富的多尺度上下文信息,首先引入可变形卷积。在卷积运算的位置上引入偏移量,可变形卷积可以有效提取几何语义信息,但同时也会丢失部分位置信息。DCNv2 引入扩展变形建模范围的调制机制后该问题会更严重。
为缓解DCNv2 造成的定位信息丢失,引入ASAM 细化特征,整体结构如图3 所示。受CBAM(Convolutional Block Attention Module)[26]中空间注意力的启发,除了在每个位置的所有通道上进行最大池化与平均池化操作,还引入1× 1卷积作为可学习池化层,自适应地计算每个位置与任务相关的统计信息,然后将3 张统计信息图拼接后使用7× 7 卷积生成注意力系数图。ASAM 的计算过程如下:

图3 ASAM模块结构Fig.3 Module structure of ASAM
其中:F为输入特征图;C为特征图F的通道 数;f1×1(·)、f7×7(·)分别表示核大小为1× 1 与7× 7 的卷积运算;S为Sigmoid 激活函数;⊗为逐元素相乘运算;[C→1 ]代表通道 数变为1。
密集连接拼接所有层的输入,然后传递给之后的所有层,以加强特征传递并优化梯度更新。考虑到运算效率,在DenseCAM 中使用通道压缩函数fC在通道维度拼接输入的各尺度特征图,然后将通道数压缩为输入特征图F的1/4。
与SPP 模块提取固定感受野的多尺度特征不同,DenseCAM 模块通过DCNv2 根据上下文内容动态调节局部感受野范围;通过ASAM 进行特征选择,抑制与任务无关的信息;通过密集连接实现多尺度特征的深度融合。在构建DenseCAM 模块时,ASAM 模块不改变特征图通道数,两个DCNv2 模块的初始膨胀系数d分别设为1、2。
2.3 Transformer
遥感目标(飞机、汽车等)往往与全局背景存在密切关联,即飞机常出现在停机坪,而汽车常出现在停车场及公路。传统堆叠卷积层的操作虽然能在一定程度上增加感受野范围,但文献[19]指出普通卷积的有效感受野增长与网络堆叠深度呈平方根关系,表明该操作低效且开销大。另一方面,仅一层Transformer[27]即可实现全局依赖,对解决高分辨率遥感图像全局信息提取效率低的问题具有一定的优越性。
Transformer 是一个完全基于自注意力机制的模型,它利用自注意力机制从全局自适应地聚合相似特征,增强模型的特征表达能力。对于遥感目标检测,使用Transformer 进行全局特征建模能够挖掘同类别实例间的全局共性特征,有利于增强模型的分类能力。自注意力机制的计算过程如下所示:
其中:X为输入特征图;fQ(·)、fK(·)、fV(·)为线性映射函数;n为X的通道数;Q、K、V一般称为查询、键和值。
通过相似度权值的计算,Transformer 过滤低匹配的噪声信号,增强高匹配的特征加权。Transformer 的计算复杂度和空间复杂度与输入特征图的空间尺寸平方呈正比,将它置于骨干网络末端能以较低的开销增强模型的全局感知能力。
3 实验与结果分析
3.1 数据集
为验证本文改进YOLOv5 算法的有效性,在UCASAOD[28]与RSOD[29]数据集上进行实验。其中:UCAS-AOD 数据集采集于Google Earth,图像大小为1 280×659~1 372×940,包含1 000 张飞机图像、510 张汽车图像和900 张负样本图像,共标注14 596 个目标。RSOD 数据集来源于Google Earth和天地图,图像大小为512×512~1 083×923,包含446 张飞机图像、165 张油箱图像、176 张立交桥图像和189 张操场图像,共标注6 950 个目标。将RSOD 数据集中存在的40 张未标注操场图像直接剔除,因此实验时RSOD 数据集中操场图像数量为149。实验时首先将数据集中的原标签转换为适合YOLO 训练的格式,然后按照文献[30]的数据划分方式,将每类图像按8∶1∶1 随机划分为训练集、验证集和测试集。
3.2 评估指标
采用mAP@0.5 和mAP@0.5∶0.95 进行性能评估,它的大小与网络性能的好坏呈正相关关系。其中:平均精确度(Average Precision,AP)为P-R曲线下 的面积;精确率P(Precision)表示预测为正例中真正例的比例;召回率R(Recall)表示所有正样本中被正确预测出来的比例。各指标计算公式如下:
其中:NTP为被正确分类的正例样本数;NFP为被错分为正例的负例样本数;NFN为被错分为负例的正例样本数;NC为类别数。mAP@0.5 表示交并比(Intersection over Union,IoU)为0.5 时AP 的均值,记为AP50;mAP@0.5∶0.95 表示IoU 从0.5取到0.95,间隔为0.05 时AP 的均值,记为mAP。P、R均在IoU=0.5 时统计。
3.3 实验环境及参数设置
实验基于YOLOv5 官方开源项目实现,使用YOLOv5s6作为基本配置,所有实验均在1 块NVIDIA RTX3090(24 GB显存)上进行,Pytorch 版本为1.9.0。实验前首先利用COCO数据集对各模型的骨干网络及特征融合网络进行预训练。
与YOLOv5 默认参数一致,实验时输入图像尺寸设为1 280×1 280,初始学习率设为0.01,动量设为0.937,衰减系数设为0.000 5,Batch size 设为16,使用随机梯度下降(Stochastic Gradient Descent,SGD)优化器。训练Epochs 设为200,训练过程中,前3 个Epoch 使用Warmup 算法进行预热;输出预测结果后,使用非极大值抑制算法进行后处理。
3.4 结果分析
为验证改进的YOLOv5 算法对遥感图像目标检测的有效性,在测试集上进行性能验证,除精度指标外,还统计了参数量与浮点数运算量,并与工业中广泛使用的YOLOv3-SPP(Spatial Pyramid Pooling)算法进行对比,结果如表1 所示。
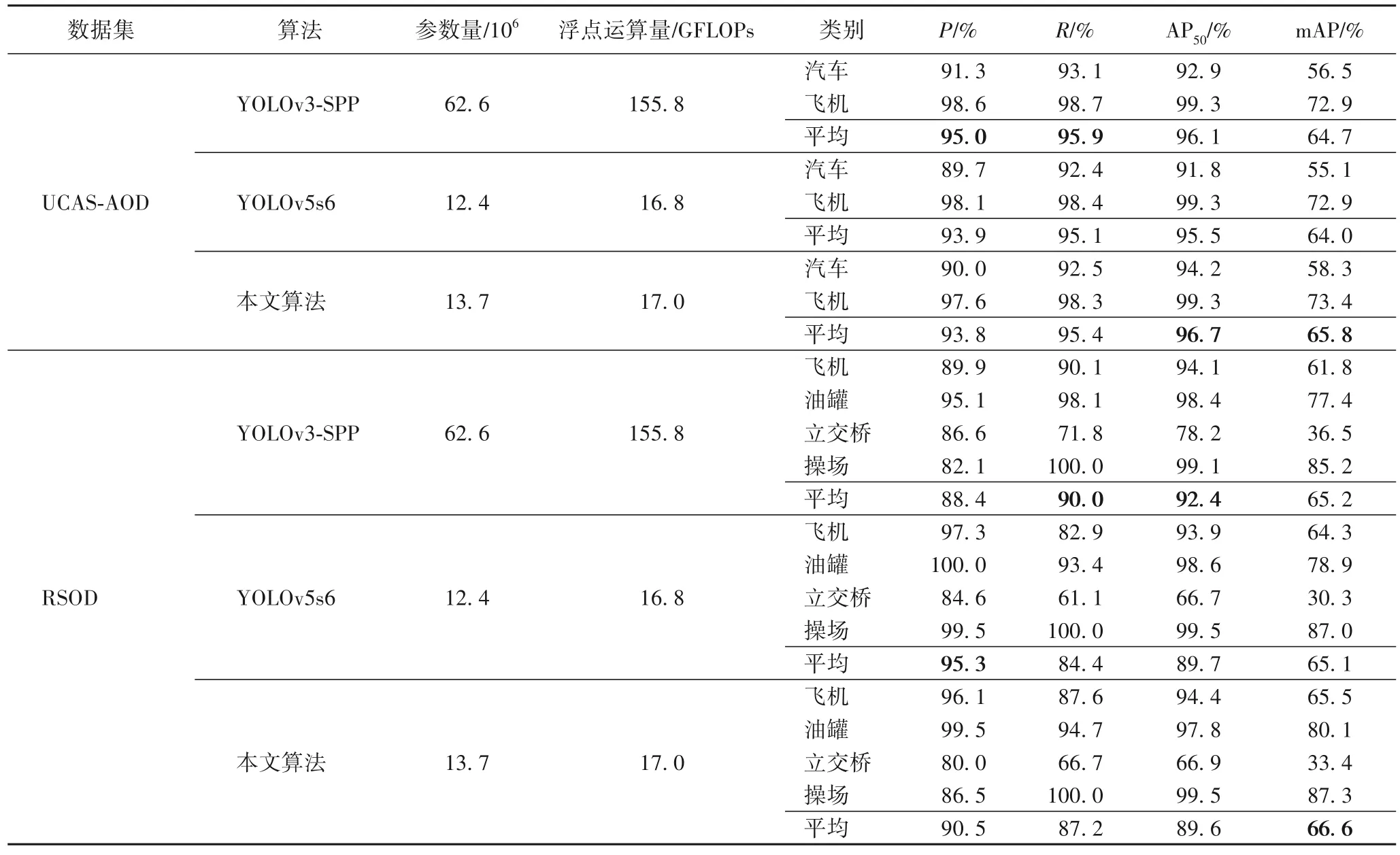
表1 不同算法在UCAS-AOD与RSOD数据集上的检测结果对比Tab.1 Comparison of detection results of different algorithms on the UCAS-AOD and RSOD datasets
在UCAS-AOD 数据集上,本文算法对全部类别的AP50、mAP 分别为96.7%、65.8%,相较于YOLOv3-SPP 分别提高了0.6、1.1 个百分点,相较于YOLOv5s6 分别提高了1.2、1.8 个百分点。本文算法对汽车、飞机两类典型遥感小目标的AP50、mAP 具有明显优势,具备良好的小目标检测性能,能从弱语义的目标中提取更强的特征。
在RSOD 数据集上,本文算法的AP50相较于YOLOv3-SPP、YOLOv5s6 分别下降了2.8、0.1 个百分点,表明本文算法具有一定的局限性。从各类别目标检测精度来看,本文算法对油罐类别目标的检测效果不佳,这可能是因为油罐颜色及几何形状单一,且分布密集,传统卷积在正方形感受野下就能获得较好的特征表示,而DenseCAM 模块在计算位置偏移时易受相邻实例和阴影轮廓影响,对背景相似物给出了较低置信度的误判,该问题在实际工程上可以通过设置高置信度阈值缓解。对于飞机类目标,本文算法的AP50为94.4%,取得了该类别的最高值,表明针对小目标检测具备一定优势。而本文算法在更苛刻的mAP 指标上相较于YOLOv3-SPP、YOLOv5s6 分别提高了1.4、1.5 个百分点,表明本文算法能够更精确地定位目标示例,具备良好的边界特征提取能力。YOLOv3-SPP 虽然在AP50上取得了最佳性能表现,但mAP 表现不佳,表明它更适合低精度检测任务,对背景相似物表现出良好的鲁棒性,但同时对边界信息提取不足。
本文算法在两个数据集上的mAP 均优于YOLOv3-SPP和YOLOv5s6,说明通过嵌入DenseCAM 与Transformer 可以提高遥感目标检测精度。从模型效率上来看,本文算法显著优于YOLOv3-SPP 算法,在取得相同量级性能的情况下,参数量、运算量为YOLOv3-SPP 算法的21.9%、10.9%。相较于YOLOv5s6,本文算法虽然在参数量上增加了10.5%,但在运算量上仅增加了1.2%,检测效率较高。
在测试集上对YOLOv5s6 与本文算法进行可视化对比,检测结果如图4、5 所示。可以看出,无论是飞机、车辆等小目标,还是立交桥、操场等大目标,本文算法均能取得较为理想的检测结果。得益于DenseCAM 模块对局部几何特征的有效提取与Transformer 的全局感知能力,本文算法提高了遥感目标检测精度。
对于图4 的汽车目标,本文算法能够检出UCAS-AOD 数据集中漏标且被YOLOv5s6 漏检的汽车实例,表明本文算法具备良好的鲁棒性。
对于图5 的飞机目标,本文算法能够检出被YOLOv5s6漏检的飞机实例;对于立交桥目标,立交桥的YOLO 格式[8]真实坐 标标签 为(0.472 093,0.534 670,0.642 791,0.388 950),YOLOv5s6 预测为(0.392 093,0.558 505,0.447 442,0.399 783),与真值的IoU 为63.0%;本文算法预测为(0.466 977,0.537 378,0.699 535,0.411 701),与真值的IoU 为86.8%,相较于YOLOv5s6 提高了23.8 个百分点,表明本文算法能够更精确地定位立交桥位置,提取更强的边界特征。

图5 在RSOD数据集上的检测示例Fig.5 Detection examples on RSOD dataset
为探究YOLOv5s6 与本文算法在骨干网络上对特征的学习差异,在UCAS-AOD 测试集上通过热力图可视化骨干网络不同阶段特征图的前4 个通道,结果如图6 所示。可以看到,在具有相同网络结构(第3~5 阶段)的特征图上两者差异较小,而在修改部分(第6 阶段)的特征图上则差异较大,表明不同网络结构能够引导不同类型特征的学习。

图6 在UCAS-AOD数据集上的骨干网络特征图可视化Fig.6 Visualization of feature maps of backbone network on UCAS-AOD dataset
3.5 消融实验
为验证各模块的有效性,在样本量更大的UCAS-AOD 数据集上开展消融实验:将Transformer、CAM 与DenseCAM 依次嵌入YOLOv5s6 模型,结果如表2 所示。其中:CAM 舍弃了DenseCAM 中的密集连接,在未使用通道压缩函数的情况下将DCNv2 和ASAM 串联堆叠两次。可以看出,在嵌入各单个模块后,均能获得比YOLOv5s6 更好的性能。嵌入CAM 模块后,AP50与mAP 分别提升了1.0 与1.0 个百分点。在进一步结合密集连接后,DenseCAM 模块在AP50与mAP 上分别带来了1.0 与1.1 个百分点的性能提升。由于DenseCAM 在密集连接时使用通道压缩函数降低中间特征图的通道维度,在取得与CAM 相近性能的情况下参数量与浮点数运算量分别减少了18.0%与2.8%,降低了模型复杂度。通过挖掘局部上下文信息并融合丰富的多尺度信息,DenseCAM 模块能够有效建模目标实例的轮廓特征,高效地提高定位精度。在嵌入Transformer 后,AP50与mAP 分别提升了0.3 与0.6 个百分点,由于网络结构设计时考虑了Transformer 复杂度,在骨干网络末端将其引入,因此改进算法在几乎不增加参数量的情况下,浮点数运算量甚至比原始YOLOv5 算法更少。在结合Transformer 与DenseCAM 模块后,AP50与mAP 均获得了最佳性能。Transformer 与DenseCAM 模块在mAP 上分别带来0.6与1.1 个百分点的性能提升,而结合两个模块后mAP 提高了1.8 个百分点,表明局部上下文信息和全局信息相辅相成,形成了特征互补,能够有效提高遥感图像目标检测精度。

表2 UCAS-AOD数据集上的消融实验结果Tab.2 Results of ablation study on UCAS-AOD dataset
4 结语
遥感图像目标检测具有重要研究意义,本文在YOLOv5基础上提出了一种基于几何适应与全局感知的遥感图像目标检测算法。针对遥感图像目标尺寸小、目标方向任意的问题,将SPP 模块替换为密集上下文感知模块DenseCAM,以增强模型对目标实例局部几何特征的提取能力。针对遥感图像背景复杂的问题,在骨干网络末端引入Transformer,以较低的开销增强模型全局感知能力。实验结果表明:与基线模型相比,借助局部上下文特征和全局特征提供的额外定位与分类信息,本文算法能够有效提高遥感图像目标检测精度。虽然本文算法能够带来一定的性能改善,可以更精确地定位目标实例,但在某些场景下仍易受背景相似物干扰。后续工作将继续根据遥感场景特性进行网络结构设计,着眼于实际场景需求,构建鲁棒性更强的高精度遥感目标检测算法。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
电子制作(2019年11期)2019-07-04
金桥(2018年4期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
数学物理学报(2017年5期)2017-11-23
中国卫生(2014年5期)2014-11-10
