
一种管道蛇形机器人的裂缝视频检测系统
2023-04-08 13:59赵达王亚慧陈林林
科学技术与工程 2023年6期
赵达, 王亚慧, 陈林林
(北京建筑大学电气与信息工程学院, 北京 100044)
近年来,随着中国城镇化进程快速发展,全国各类市政管道大量的被投入使用。随着使用年限的增加,管道会产生各种损伤,管道的定期检查和维护是城市平稳运行的重要部分。为了检查和维护管道,颜凯凯等[1]、邢利辉等[2]、邓蕊等[3]研究设计了一款管道探测蛇形机器人,该机器人由多个舵机正交连接构成,通过STM32F103单片机控制,可实现在管道内部行波和蜿蜒运动等。张成林等[4]为管道探测蛇形机器人设计了一种基于捷联惯性导航的定位系统,可以实现蛇形机器人在管道中的定位。同时在管道中准确识别管道裂纹也是一个十分重要的环节。
Durai等[5]设计了一种搭载环形激光器的管道探测机器人,激光二极管用作光源,用于捕获高质量的检测图像。通过对采集图像的高亮度像素数量得到缺陷信息。李夷进等[6]针对当前管道图像存在白雾和光斑等干扰的问题,提出了一种管道图像去除光斑和白雾的方法,首先根据雾气特征,使用暗通道算法进行先验去雾,其次使用多尺度Retinex色偏恢复算法修复去雾算法产生的色偏,最后使用改进的二维伽马函数,实现对光斑的消除。赵谦等[7]针对工业管道内壁分辨率低、适用性差等特征,提出了一种工业管道内壁的重建方法,首先搭建了基于内窥镜的视频采集平台进行数据实时采集,接着使用张正友标定法进行平面标定计算镜头点在图像上的位置值,采用改进的尺度不变特征转换算法进行特征提取和匹配,最后使用融合随机抽样一致和加权融合算法消除误差,达到管道内壁重建目的。杨书娟等[8]为了实现对焊缝的快速准确识别,研究了一种激光视觉引导的焊缝跟踪系统。该系统使用电荷耦合器件(charge coupled device,CCD)工业相机采集焊缝图像,之后对采集的图像进行预处理,再经过特征点提取算法获得特征点坐标,最后进行三维重建得到三维坐标。综上所述,目前来说,关于管道探测缺少对视频进行自动识别缺陷的方法,上述方法都是依靠人工识别裂缝再对裂缝进行具体操作。
随着计算机技术的深入发展,深度学习目前被大量应用在缺陷检测中。现在被广泛应用的算法有两类,分别是以R-CNN系列算法[9]为代表的两阶段算法和以YOLO算法[10-11]、SSD算法[12]等为代表的一阶段算法。两者区别在于两阶段算法在结构上比一阶段算法多一个生成候选区域的步骤,然后再对其进行识别和定位,而一阶段算法直接对预测框进行回归和分类预测。所以两种算法比较起来,一阶段算法虽然在检测准确率上稍逊于两阶段算法,但其检测速度优于两阶段算法。
因此,针对目前关于管道视频自动检测研究不足的现状,现设计一种基于管道蛇形机器人的管道裂缝视频检测系统。系统搭载了500万像素的摄像机以及用于辅助标定的两个激光发生器。使用摄像机采集管道视频,并采用YOLOv3算法对管道视频进行检测,以实现对管道裂缝的实时准确识别和定位,之后将检测出裂缝的视频帧输出并结合激光标定和边缘检测算法得到该帧图像中裂缝的实际物理信息。
同时为了提高算法精度,现对YOLOv3 算法进行改进,首先在使用距离交并作为K-means++算法损失函数的基础上,利用K-means++算法对数据集进行聚类分析,得到合适的先验框;同时也将距离交并比用作YOLOv3网络的损失函数,优化和提高目标的检测精度。
1 YOLOv3算法
YOLOv3网络由Darknet-53网络和预测网络2个部分组成,在此网络中第1~75层为Darknet-53结构,Darknet-53结构由一系列的1×1和3×3的卷积以及残差层构成,在交替使用后再经过步长为2的下采样,将特征图缩小为原来的1/2,一共经过5个下采样最终将特征图变为原图的1/32。76~106层为预测网络层,预测网络从Darknet-53网络中选取三个尺度的特征图进行预测,分别是为13×13、26×26、52×52,每个尺度之间又通过卷积的方式实现交互,将感受野大的信息传递个感受野小的尺度。YOLOv3特征提取网络如图1所示。
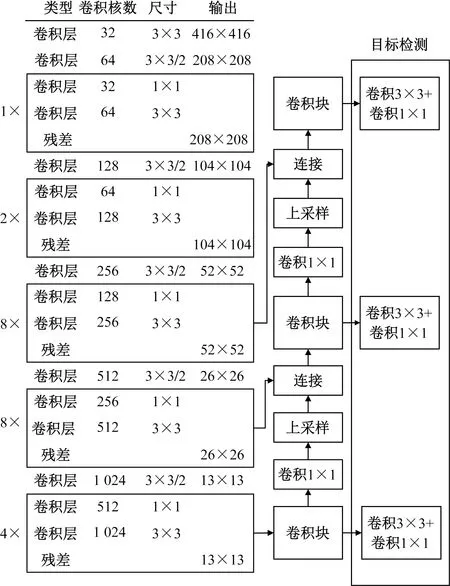
图1 YOLOv3网络结构Fig.1 YOLOv3 network structure
2 裂缝检测算法
2.1 损失函数的改进
在目标检测过程中,使用损失函数来度量预测和真实数据的差异,损失函数的优劣与网络学习速度和模型预测效果有着重大的关系。在原始YOLOv3中,使用交并比(intersection over union, IoU)作为边界框的损失函数,反映预测检测框与真实检测框的检测效果。交并比原理如图2所示。
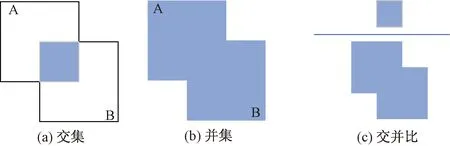
图2 交并比原理Fig.2 The principle of IoU
交并比的计算公式为
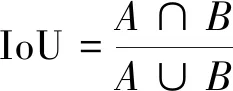
(1)
式(1)中:A、B分别为真实框和预测框,其中0≤IoU≤1。
在YOLOv3中,交并比损失函数定义为
LIoU=1-IoU
(2)
然而,一旦真实框和预测框不相交的情况下,IoU=0,此时损失函数无法表现预测框和真实框的实际距离,优化无法继续进行,如图3(a)所示。此外,当两个预测框大小相同且IoU相同的情况下,损失函数同样无法区分两种情况,如图3(b)所示。
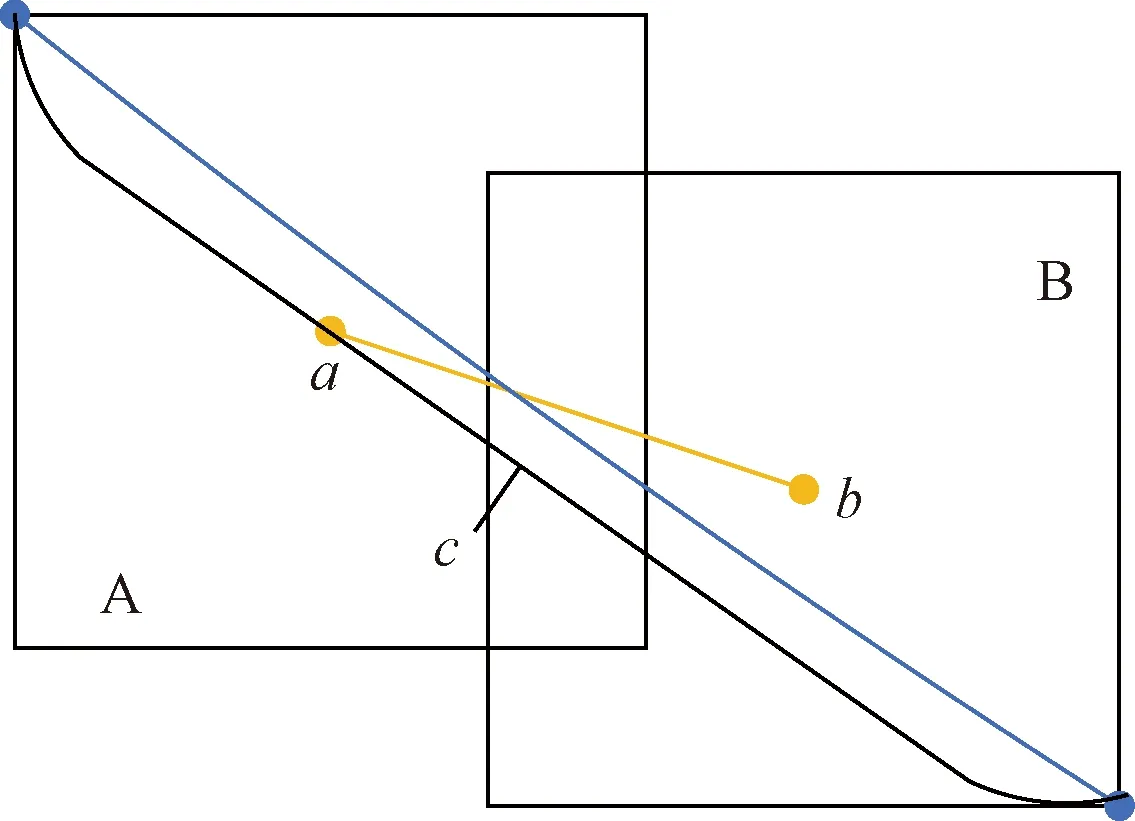
基于上述情况,提出使用距离交并比(distance intersection over union, DIoU)[13]作为边界框的损失函数。距离交并比原理如图4所示。
距离交并比计算公式为
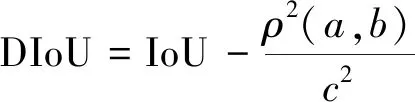
(3)
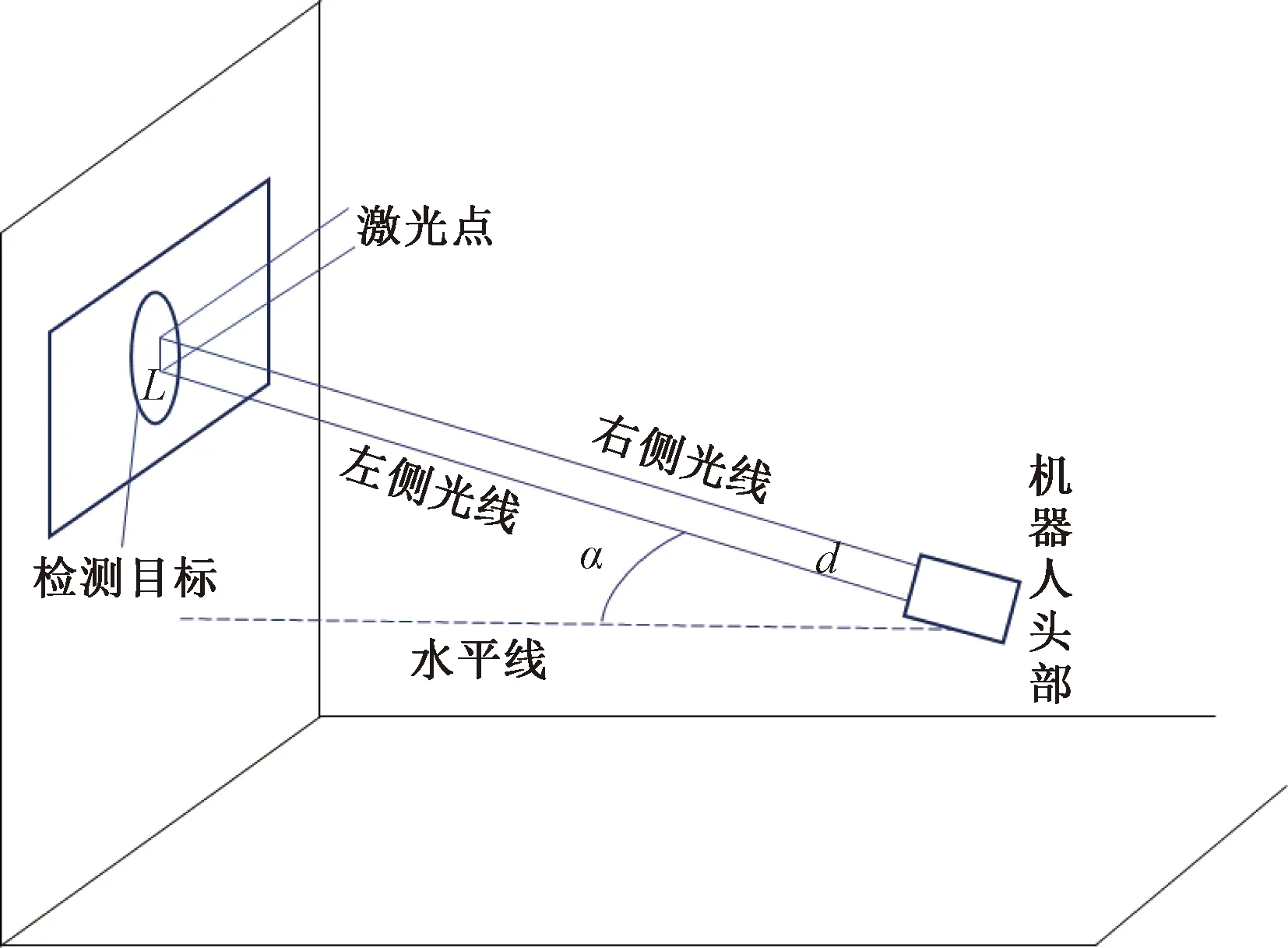
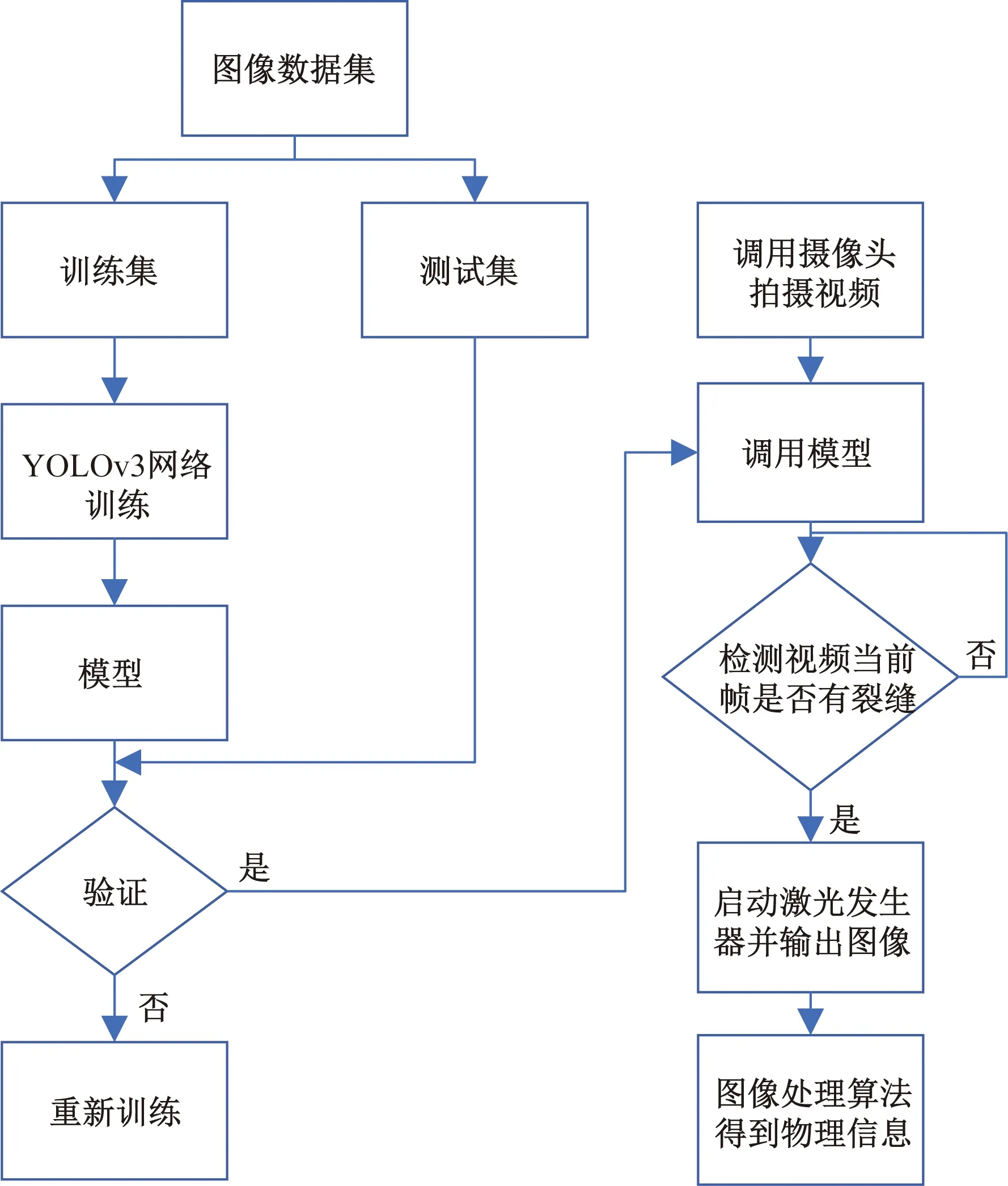
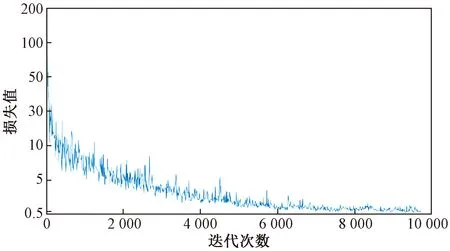
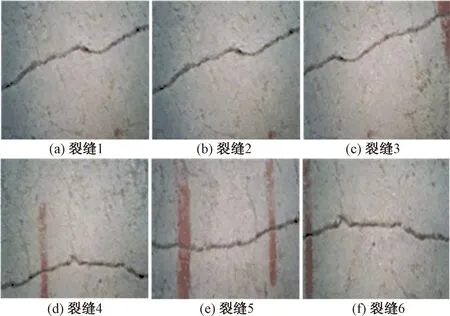
式(3)中:a、b分别为预测框和真实框的几何中心点;ρ为计算两个中心点的欧氏距离;c为能够同时覆盖预测框和真实框的最小矩形的对角线距离。由上述内容,可以得出-1 距离交并比损失函数定义为 LDIoU=1-DIoU (4) 图3 交并比的不足Fig.3 Deficiencies of IoU 图4 距离交并比原理Fig.4 The principle of DIoU 式(4)中:DIoU取值范围为(-1,1],当预测框和真实框重合时,DIoU=1;当两框不相交时,DIoU取值范围为(-1,0),且在两框远离的情况下,DIoU逐渐趋向-1。由此即使两框不相交时认可继续优化。同时,以DIoU作为损失函数相较于IoU作为损失函数,考虑到中心点的距离,其收敛速度更快。 YOLOv3将位置损失、置信度损失和类别损失融合在一个损失函数中,所改变的是位置损失函数。改进后YOLOv3损失函数分别为 (5) (6) (7) Loss=Lbox+Lobj+Lcls (8) Loss=Lbox+Lobj (9) YOLOv3在每个尺度的特征图中都与先设置了3个不同尺度的先验框,并通过对先验框的偏移实现对目标的预测,先验框的尺寸对检测精度有着重大的影响。原始的YOLOv3使用K-means算法聚类得到先验框。算法流程如下:①确定要得到的先验框数量K;②从数据集中随机选择K个数据点作为初始聚类中心;③针对数据集中每个样本点,计算它们到各个聚类中心点的距离,到哪个聚类中心点的距离最小,就将其划分到对应聚类中心的类簇中(YOLOv3中使用IoU作为距离的判断标准,d=1-IoU);④针对每个类别,重新计算该类别的聚类中心;⑤重复流程③和流程④,直到聚类中心的位置不再变化。 传统K-means 算法初始点的选取随机性较大,影响聚类精度,本文使用K-means++算法[14]代替原来的K-means算法,对裂缝数据集的标记框进行聚类,得到更好的先验框大小。具体流程如下:①确定要得到的先验框数量K;②随机选取数据集中的1个数据作为初始聚类中心;③针对数据集中每个样本,计算它们到聚类中心的最短距离D(x)=1-DIoU,计算每个样本被选为下一聚类中心的概率,通过轮盘法选择出下一个聚类中心; ④重复步骤③,直到选择出K个聚类中心;⑤之后的步骤和K-means算法的步骤相同。 最终经过K-means++算法得到的先验框为[39,76],[216,34],[47,356],[391,68],[165,165],[74,396],[408,121],[127,411],[390,380]。 使用平均精确率(average precision, AP)对裂缝检测模型进行评价,AP与召回率(recall)和精确度(precision)有关。计算公式为 (10) (11) (12) 式中:TP为正确划分成正样本的数量;FP为错误划分成正样本的数量;FN为错误划分为负样本的数量;P(r)为根据召回率和准确率绘制的曲线;R为召回率。 为了给予工作人员具体的裂缝信息,需要将YOLOv3识别到的裂缝图像输出并加以处理得到裂缝的实际物理信息。本文所研究的系统搭载在本课题组所设计的一款蛇形机器人上,考虑到蛇形机器人的整体设计的情况,系统在硬件需求方面主要是一对激光发射器以及500万像素相机。将激光发射器安置在蛇形机器人的头部左右两侧,并使得发出的左右两条光线保持平行,两者间距为20 mm。这样,在安装在机器人头部的相机捕获图像时,激光就会在图片上形成两个亮点。在已知两个激光发射器之间的实际距离的情况下,通过图像处理技术计算出两个亮点之间的像素数,最终便可以计算出像素与物理尺寸的关系。激光标定模型如图5所示。 图5 激光标定模型示意图Fig.5 Schematic of a laser calibration model 安装在机器人头部左右两侧的激光发射器相互平行且处于同一水平高度,以确保发出的激光线是平行的。两个激光发射器之间的距离d,发出的平行光线打在被测目标上形成的两个激光点之间的距离为L。假设像平面上像素为正方形,机器人头部的仰角与水平面之间的夹角像为α,便可以得到激光发射器水平距离d与两激光点距离L的关系,即 (13) 假设经过图像处理后两个亮点之间的像素数为N,便可以计算出图像坐标系与现实物理坐标系之间的比例系数K,即 (14) 在得到比例系数后使用Canny边缘检测算法[15]和形态学处理算法提取出裂缝特征,并提取计算图像裂缝像素,将裂缝像素与比例系数相乘得到实际信息。 本文的检测系统安装在管道探测蛇形机器人上,蛇形机器人可应用在多种管道情形下,现以水泥管道为背景进行研究。选取从搜索引擎找到的关于水泥裂缝图像的数据集,对其使用LabelImg软件重新进行标注,同时使用自己采集的1 000张水泥裂缝图片,同样使用LabelImg软件进行标注。将两个数据集一起进行训练。部分裂缝图像样例如图6所示。 图6 部分裂缝图像样例Fig.6 The example of a partial crack image 为了验证蛇形机器人裂缝检测系统,实验器材包括管道蛇形机器人、直流稳压电源、笔记本电脑、500万像素相机、激光发生器等。笔记本电脑配置如下:操作系统为Windows10,CPU为Intel(R) Core(TM) i7-10750H,内存为16 GB;GPU为NVIDIA GeForce GTX 1 650 Ti,显存为4 GB。 首先将数据集图像划分为训练集和测试集,两者比例设置为7∶3;由迁移学习的思想,加载darknet53.conv.74作为算法的预训练权重,使用训练集数据对改进的网络进行训练,在模型训练好后,使用该模型对测试集图片进行检测,同时将检测结果输出,从而确定模型的性能优劣。在确定模型性能后,调用摄像头使用训练好的模型进行实际实验,当在视频中检测到裂缝时,视频中出现标记框,同时激光发生器启动在当前位置打出两个光点,并输出当前图像,运行边缘检测和激光标定算法得到当前图像裂缝物理信息。裂缝检测整体算法流程如图7所示。 图7 裂缝检测整体算法流程Fig.7 Overall algorithmic flow of crack detection 对改进后的YOLOv3算法进行训练,随着迭代次数的增加,损失函数的变化趋势如图8所示。 由图8可以看出,刚开始训练时,模型的损失值在200左右,随着训练迭代次数的增加,损失值迅速逐渐减小到10左右,之后随着训练的继续,损失值减小的速度开始放缓,当迭代次数到9 000次左右时,损失值在0.6左右,此时的损失值已不再有明显的下降趋势,即已到了合适的效果。 图8 损失函数趋势Fig.8 Loss function trend 对同一训练集分别使用改进YOLOv3算法和原始YOLOv3算法训练得到模型,之后使用同一个验证集进行对比实验。裂缝检测性能指标如表1所示。算法结果对比图如图9所示。 表1 裂缝检测性能指标 图9 算法结果对比图Fig.9 Algorithm results comparison chart 由表1可以看出:相较于与原始YOLOv3算法,本文提出的改进YOLOv3算法在平均精度方面提高了5.88%,这表明改进方法在一定程度上能够提高网络模型的检测性能。 从图9能够发现,本文的方法相较于原始算法的检测结果更优,与裂缝的实际位置更加吻合。 在确定了模型的可行性后,使用模型进行实际测试。本文检测时,会在识别出裂缝后输出不含标记框的图片,使用不含标记框的图片进行图像处理得到裂缝物理信息。视频检测输出的部分图像如图10所示。 图10 部分输出裂缝图像Fig.10 Partial output crack image 之后使用检测出的裂缝图片验证图像处理算法的准确性,使用实际的一张带有激光点的照片,使用图像处理算法计算裂缝参数,同时实际测量该裂缝的物理信息,与计算出的参数进行对比。裂缝图片如图11所示。 图11 裂缝图像Fig.11 The crack image 本文设置的两个激光发生器之间间距为 20 mm,测量的裂缝是两条红线间的裂缝数据,经过图像处理最终得到的结果以及实际测量的结果如表2所示。 通过算法计算出的长度误差为2.6%,宽度误差为4.5%,两者误差皆在5%以内。同时由于探测时摄像头与被测量面间距离很短,故检测到的裂缝大小也有限。5%的误差可以满足实际的应用。 表2 测量结果 针对管道裂缝自动检测存在的问题,本文基于改进YOLOv3算法为管道蛇形机器人设计了基于一个快速检测识别管道视频裂缝的系统。新算法首先使用DIoU代替IoU作为损失函数用于先验框聚类计算损失值,以及用于YOLOv3算法训练时的损失值计算;其次,使用K-means++算法对裂缝数据集的标记框进行聚类;最后使用图像处理算法对检测出的裂缝图像进行测量。得出如下结论。 (1)通过使用DIoU作为损失函数优化YOLOv3算法,以及使用K-means++算法进行聚类得到合适的先验框。实验结果表明,本文算法比原始YOLOv3算法AP提高了5.88%。 (2)进行实际实验,训练好的模型在使用中可以识别视频中的裂缝并定位。同时输出识别出裂缝的视频帧。 (3)建立了激光标定模型,针对从视频中检测出的裂缝图像使用边缘检测算法和形态学处理提取裂缝特征,之后结合激光标定得出裂缝物理信息。实验表明,该算法得到的结果与实际结果误差范围在5%以内,满足实际需求。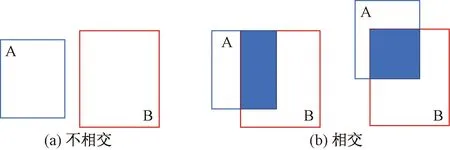
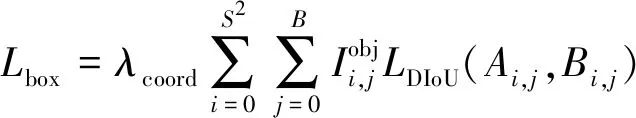
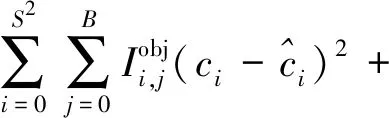
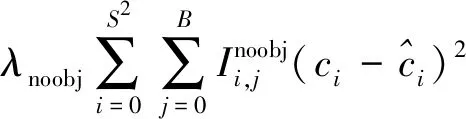
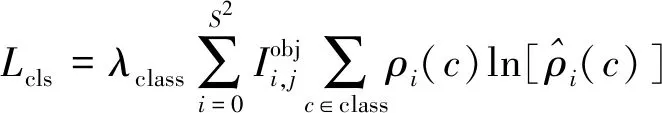
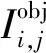
2.2 先验框聚类改进
2.3 评价标准
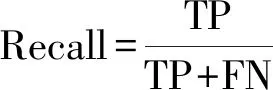
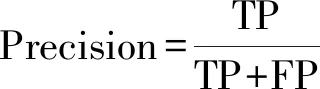
2.4 图像处理算法
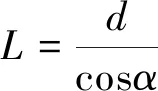
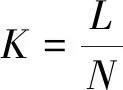
3 实验与分析
3.1 数据集

3.2 实验条件及步骤
3.3 实验结果及分析




4 结论
猜你喜欢
昆明医科大学学报(2021年6期)2021-07-31
锻压装备与制造技术(2021年2期)2021-07-19
数学小灵通·3-4年级(2021年5期)2021-07-16
科学(2020年5期)2020-11-26
小哥白尼(趣味科学)(2019年2期)2019-04-17
今日农业(2019年15期)2019-01-03
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
