
多状态图神经网络文本分类算法
2023-05-05 03:00陈重元孙开伟
重庆邮电大学学报(自然科学版) 2023年2期
王 进,陈重元,邓 欣,孙开伟
(重庆邮电大学 数据工程与可视计算重点实验室,重庆 400065)
0 引 言
文本分类是自然语言处理(natural language processing,NLP)领域的一个基本问题和热点问题[1]。文本分类的应用有很多,比如情感分析、新闻分类和问题回答[2]等。文本分类的核心在于如何获得一个更优的文本表示[3]。因此,许多基于机器学习的算法都开始用于解决文本分类问题,比如支持向量机[4]、决策树[5]和逻辑回归[6]等,但这些算法在文本特征提取和文本表示的能力还不够完善。
随着深度学习的发展,涌现出大量基于神经网络的文本分类模型,取得了不错的效果。Kim[7]于2014年将卷积神经网络(convolutional neural network,CNN)用于文本分类任务,使用多个大小尺寸不同的卷积核来提取多种不同的文本局部特征,将这些特征结合后进行文本分类。Liu[8]于2016年提出基于循环神经网络(recurrent neural network,RNN)的文本分类模型,以获得文本之间的上下文信息以及较长文本中的依赖关系。Joulin[9]于2017年提出了快速文本分类器(fast text classifier,FAST),这是一个浅层网络模型且训练速度较快,可以快速地进行文本分类。Shen[10]于2018年提出的简单词嵌入模型(simple word-embedding-based models,SWEM),将词嵌入与池化技术相结合来进行文本分类。Devlin[11]于2019年提出的预训练语言模型(bidirectional encoder representation from transformers,BERT)借鉴解决完形填空问题的思想来训练双向的语言模型,然后使用模型微调的方式来完成文本分类任务,取得了较好的效果。预训练模型的优势在于大量的模型参数量以及丰富的训练语料,而其局限性在于计算量较大、对硬件要求较高,应用时需要对性能和成本进行权衡。
对于文本数据,其内部结构可看作是复杂的语法树结构的组合,而树结构又是图结构的一种特殊形式。由于图神经网络在处理复杂结构和保存全局信息方面表现出良好的性能,因此在文本分类任务中也取得了一些进展。Yao[12]于2019年提出的文本图卷积网络(text graph convolution network,TextGCN),使用所有的文本数据构建成一个大规模图结构数据,再使用图卷积网络(graph convolution network,GCN)来提取文本特征并进行文本分类。Huang[13]于2019年提出的文本层级图神经网络(text level graph neural network,TextLGNN),引入了一种非频谱的消息传递机制(message passing mechanism)从邻居节点来获取信息,进而完成文本分类。Zhang[14]于2020年提出的文本图归纳网络(text inductive graph neural network,TextING),将每条文本数据单独构建为一个图结构数据,再使用门控图神经网络(gated graph neural network,GGNN)来提取文本特征并进行文本分类。Zhu[15]于2021年提出的简单频谱卷积网络(simple spectral graph convolution,S2GC),设计了一种简单有效的过滤器来接受邻居节点信息,并解决文本分类问题。
然而,上述基于图神经网络的文本分类算法还是存在一些不足。首先,对于TextGCN模型,其主要局限性在于所有的数据都参与构建图结构数据和模型训练,因此,模型具有内在传导性,即无法对新加入的样本快速生成其文本表示并预测其所属类别。对于TextLGNN模型,它使用固定的全局词对关系来构建图结构数据,无法有效地利用当前词的上下文语境。对于TextING模型,其在提取特征时主要参考门控循环单元(gated recurrent unit,GRU)[16]的运行机制,这会导致模型训练时出现局部的过度平滑问题[15],使得模型性能下降;其次,则是基于GRU的图网络层更侧重于考虑文本的上下文依赖关系,而文本的局部相关性也需要兼顾;最后,在获取高层次文本表示时,可以对图读出器函数进行加强,以获得更优的文本表示。对于S2GC模型,虽然低通与高通滤波器的结合可以从一定程度上缓解过度平滑问题,但对文本中关键信息的捕捉能力有待提高。
因此,本文提出了一种基于多状态图神经网络的文本分类算法(multi-state graph neural network,MSGNN)。首先,将每一篇文档构建为各自的图结构数据,在训练模型时只会使用到训练集文本,从而可以快速地构建测试集文本的图结构数据并对其进行分类。其次,对图卷积神经网络和门控图神经网络进行改动,在提取文本特征时引入网络层多个历史时刻的状态信息,以增强中心节点自身的信息,并将提取到的2种文本特征相结合作为文本的基本表示。最后,使用多头注意力机制从多个角度提升文本中关键词的重要度。通过以上步骤聚合得到文本的高层次表示并进行文本分类,从而提高分类准确率。在几个公开的文本分类数据集上的对比实验表明,相较于其他神经网络文本分类算法,该方法取得了较好的效果。
1 多状态图神经网络MSGNN
本文提出的多状态图神经网络MSGNN,其算法流程主要分为3个部分:①将文本数据构建为图结构数据;②基于多状态图神经网络层的特征提取;③基于自注意力机制的图读出器函数。图1是MSGNN算法整体流程图,下面将详细介绍本算法模型的各个组成部分。
1.1 将文本数据构建为图结构数据
首先对文本做文本分词、大小写写法统一及去除停用词等[15]预处理操作;然后将每条文本中的所有单词进行去重处理,将去重后的每一个单词作为图的节点,将单词之间的共现关系作为图的边。单词之间的共现关系在这里具体是指:在一个固定大小的滑动窗口中所同时存在的单词之间的关系,滑动窗口默认长度为3。使用图中每个节点对应词的词嵌入向量来初始化图中所有的节点的向量表示;最后构建出一个无向的同质图。记文本构成的图为G=(V,E),其中,V和E表示此图的节点集和边集。
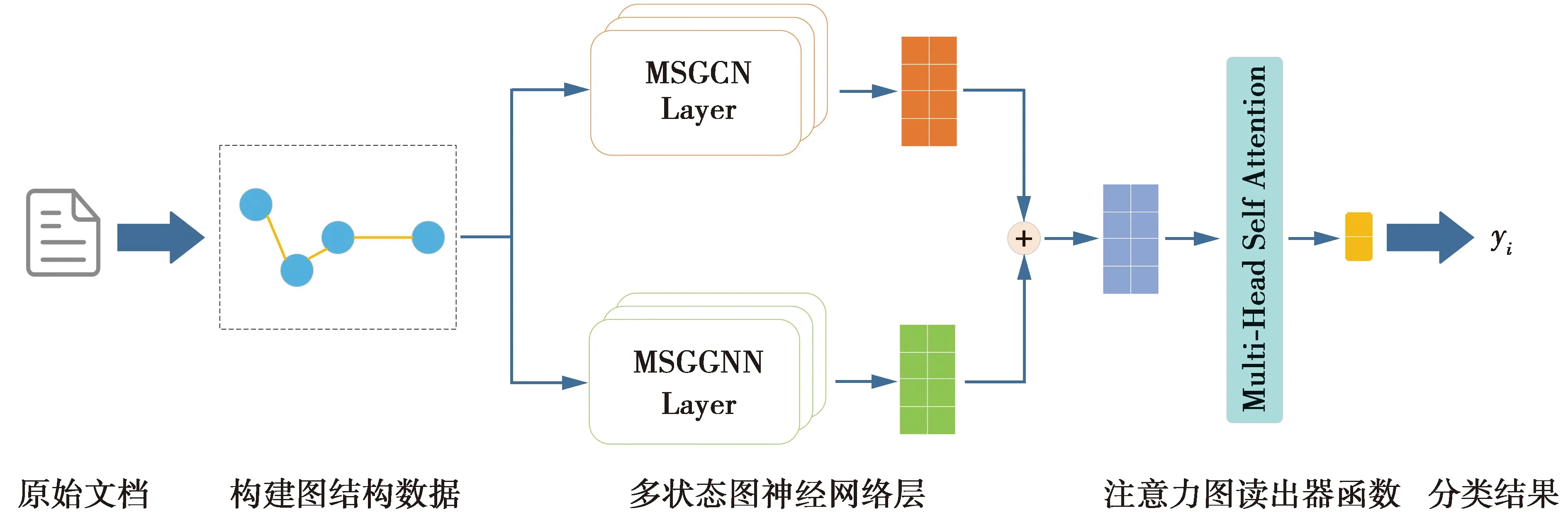
图1 算法整体流程图Fig.1 Overall flow chart of the algorithm
1.2 基于多状态图神经网络层的特征提取
图卷积神经网络GCN由Kipf[17]于2017年提出,它是一种基于频谱方式的卷积图神经网络,使用卷积操作对一个图节点及其邻居节点来提取特征。设某条文本数据的特征矩阵为X∈n×m,其中,n为该图中节点的数量,即文本中单词的数量,m为词嵌入向量的维度。对已经构建完成的图结构数据应用GCN,利用此图的邻接矩阵A∈n×n和度矩阵D∈n×n来完成节点更新与信息传递,并且可通过堆叠多个卷积层来获取高阶邻居节点的信息,其交互过程为
(1)
但随着GCN网络层层数的增加,中心节点的信息损失越多,导致包含中心节点的连通分量存在局部的过度平滑问题。为了在接收高阶邻居节点信息的同时,突显中心节点本身的信息,需要对网络做一些改进来缓解过度平滑问题。首先,将GCN的多层权重矩阵替换为参数共享的单层权重矩阵,在降低参数量的同时,减少网络出现过拟合问题的风险。其次,给当前网络层显式地添加前面若干网络层的历史隐藏状态,即使用多步历史状态来增强当前网络层状态,称为多状态图卷积网络层(multi-state graph convolution network layer,MSGCN Layer),其交互过程为
(2)
(3)
门控图神经网络GGNN是由Li[18]于2015年提出的一种基于门控循环单元的循环图神经网络,通过修改GGNN的输入适配到图结构数据中,借助图节点前一时刻的隐藏状态和邻居节点的隐藏状态来完成节点在本次迭代中隐藏状态的更新。记第k次迭代时的隐藏状态矩阵为Tk∈n×h,而第0次迭代时有T0=X。在第k次迭代时,节点之间隐藏状态的更新过程为
(4)
zk=σ(Wzak+Uztk-1+bz)
(5)
rk=σ(Wrak+Urtk-1+br)
(6)
(7)
(8)

由于GGNN网络层在训练时需要循环迭代进行,因此,在提取隐藏特征时也存在连通分量的局部过度平滑问题。为了增强中心节点的信息,同样引入了多步历史状态来增强当前网络层状态并缓解过度平滑问题。不同的是,根据GGNN网络层特性,将网络层的历史隐藏状态引入在使用更新门单元和重置门单元对隐藏特征提取完成之后,以保证在增强本网络层隐藏特征的同时,避免对节点间的正常信息传递与更新造成影响,称为多状态门控图神经网络层(multi-state gated graph neural network layer,MSGGNN Layer),其交互过程为
(9)
(10)
在以上2种图神经网络层中,节点信息的更新与传递方式不同,会提取到不同层次的文本特征。设ci∈m为通过MSGCN层提取到的特征矩阵Cl的第i个特征向量,ti∈m为通过MSGGNN层提取到的特征矩阵Tk的第i个特征向量,将这2种特征进行组合,表达式为
hi=ci‖ti
(11)
(11)式中,‖表示向量的拼接。
随后可得到经过特征拼接后的新特征矩阵H={h1,h2,…,hn},hi∈m,以丰富文本表示。
1.3 基于自注意力机制的图读出器函数
至此,已经获得了由2种不同层次的隐藏特征构成的组合特征H。为了得到用于分类的高层次文本表示向量D∈n×d,在图读出器函数中引入多头自注意力机制(multi-head self-attention)[19]来获取更优的文本表示。自注意力机制(self attention)[19]可以较好地捕获语句中的长距离依赖关系,而多头自注意力机制可以从多个角度并行地选取输入信息进行计算,且每个注意力头的侧重点有所不同,其计算过程为
VA,e=WA,eH+bA,e
(12)
(13)
M=Concat(Q1,…,Qe)
(14)
(12)—(14)式中:VA,e是通过第e个全连接层变换后的隐藏特征,用于注意力机制的计算,WA,e与bA,e是可学习参数;Qe表示第e个注意力头的计算结果,δ表示Softmax函数,|V|表示节点集V中单词的数量;Concat表示多个注意力头的向量拼接操作;M表示使用多头自注意力机制的计算结果。
为了最终完成文本分类,将图中所有节点的向量表示累加,再根据图中节点的数量进行归一化后得到最终的图层次表示,也即最终的文本表示。最后,将得到的文本表示通过Softmax函数得到预测概率,再与文本真实的标签值计算交叉熵损失,计算过程为
p=φ(M)WM
(15)
(16)
f=δ(Wfg+bf)
(17)
(18)
(15)—(18)式中:p为通过全连接层的隐藏特征;φ为激活函数;WM是可学习参数。g为图节点使用均值聚合后的图层次表示,v表示该图中的某一具体节点。f为通过全连接层的预测概率,δ为Softmax函数。是当前批次文本数据的总损失值,yi是一条文本数据的标签值。
2 实验与分析
为了检验本文所提出的MSGNN的性能,在实验部分主要关注了MSGNN的分类准确率;多状态图神经网络层和多头自注意力机制的有效性,以及图神经网络层数量对分类准确率的影响。
2.1 实验数据集、基准算法与实验设置
对比实验采用了6个公开的基准数据集:基于电影评论的情感分析数据集MR,路透社新闻数据集R8和R52,医学文摘数据集Ohsumed,问答数据集TREC-6,新闻主题分类数据集20NG等文本分类领域的真实数据集[7,14-15],表1给出了上述数据集的一些基本统计信息。

表1 实验数据集的基本统计信息
在实验中用于对比的基准算法有9个,分别是TextCNN[7],TextRNN[8],FAST[9],SWEM[10],BERT[11](base),TextGCN[12],TextLGNN[13],TextING[14]以及S2GC[15]。
主要的实验设置:由于所有数据集已经划分为训练集和测试集,因此随机选取训练集中10%的数据作为验证集,用于确定模型中较为适合的网络超参数。为了实验的合理性,所有模型使用的优化器均为Adam[20](初始学习率为0.005),使用的词向量均为Glove[21](词向量维度为300),而对于不在词表中的单词使用均匀分布([-0.01,0.01])来随机生成。
2.2 实验结果与分析
在实验部分,对所有模型进行10次实验,并取10次实验结果的平均值作为模型的最终结果,使用的评价指标为分类准确率。表2给出了本文所提出算法与基准算法在6个公开数据集上的实验结果,加粗的数字表示最优的结果,部分实验结果来源于其他文章[14]。
本算法MSGNN相比于其他算法具有一定的性能优势,具体体现在分类准确率上。MSGNN在4个数据集上超过了全部对比基准算法,证明了改进后的多状态图神经网络MSGCN 层和MSGGNN层,结合多头自注意力机制的整体有效性。值得注意的是,MSGNN在R52与Ohsumed数据集上的表现相比于BERT略有不足。这是因为MSGNN中的多状态图卷积网络层采用了参数共享的设计方式,虽然可以有效地提升模型的运行效率并缓解过拟合风险,但与BERT这种参数量规模较大的模型对比,参数量不足所带来的问题便通过分类准确率体现出来。另一个原因则是BERT模型得益于在预训练阶段所使用的丰富语料,为其在下游任务中带来较为准确的参数值。而BERT模型的劣势则体现在模型的训练与推断速度较慢,以及对硬件设备有着较高的要求。
下面将通过消融实验来进一步分析MSGNN中不同的改进部分对分类准确率的影响。
2.3 多状态图神经网络层对结果的影响
为了检验多状态图神经网络MSGNN在文本分类任务中的有效性,将MSGNN中改进的多状态图卷积网络层MSGCN与多状态门控图神经网络层MSGGNN分别替换为图卷积网络层GCN与门控图神经网络层GGNN来进行对比。图2展现了MSGNN模型(M1)及其3种变体模型(M2,M3和M4)在6个数据集上的分类准确率的对比情况。在图2中,M1模型表示MSGNN;M2模型表示将MSGCN层替换成GCN层;M3模型表示将MSGGNN层替换成GGNN层;M4模型表示同时将MSGCN层与MSGGNN层替换成GCN层与GGNN层。
从图2可以发现,相比于另外3种将MSGNN中网络层进行替换的情况,同时使用MSGCN层与MSGGNN层使得模型在6个数据集上的分类准确率均达到了最高,这得益于所引入的多步历史状态对网络层特征提取能力的增强。具体而言,MSGCN层可以有效捕捉局部单词间的相关性,而MSGGNN层擅长提取文本中的长距离依赖关系,结合这2种网络层能准确地提取文本中不同位置、不同细粒度的信息。图神经网络中所引入的多步历史状态,在缓解过度平滑问题的同时,也可以视作一种特征增强的方法。多头自注意力机制从多个特征子空间来筛选与聚合文本信息。经过文本特征提取、文本特征增强、文本信息聚合等几个对文本表示的精细优化阶段,最终能得到一种高质量的文本表示以及较高的文本分类准确率。
2.4 多头自注意力机制对结果的影响
为了探索多状态图神经网络MSGNN中多头自注意力机制的有效性以及注意力头的数量对MSGNN性能的影响,在本部分实验中去掉MSGNN中的多头自注意力机制或改变注意力头的数量,并在6个数据集上进行对比实验,所得到的模型分类准确率结果如图3所示。
在图3中,数字0表示MSGNN模型不使用注意力机制(注意力头的数量等于0)的情况,而其他数字表示MSGNN模型中含有的注意力头的数量。结果表明,使用注意力机制(注意力头的数量大于0)时模型的分类效果更好,而多头注意力机制(注意力头的数量大于1)会比单注意力机制(注意力头的数量等于1)更进一步提升模型的分类准确率。但注意力头的数量并不是越多越好,可以利用验证集来确定一个适合的数量。

图3 MSGNN中不同数量的注意力头在6个数据集下的分类准确率对比Fig.3 Comparison of classification accuracy of different number of attention heads in MSGNN under six data sets
2.5 图神经网络层数量对结果的影响
在多状态图神经网络MSGNN模型中,MSGCN层与MSGGNN层的数量是2个可调节的网络层超参数,不同的网络层数量所提取到的隐藏特征的质量也会不同。增加网络层的数量会接收到更远的高阶邻居节点的信息,网络层参数更新次数也越多。但堆叠的网络层越多,模型中缓解过度平滑问题的能力也会下降。在本部分实验中:改变MSGNN中含有的2种图网络层的数量,并在6个数据集上进行实验,所得到的模型分类准确率结果如图4所示。

图4 MSGNN中不同数量的图网络层在6个数据集下的分类准确率对比Fig.4 Comparison of classification accuracy of different number of GNN layers in MSGNN under six data sets
在图4中,坐标图中横轴上的数字(从1到6)是MSGNN中所含有的MSGCN层与MSGGNN层的数量,比如横轴为1表示MSGNN中MSGCN层与MSGGNN层的数量均为1层。通过观察可以发现,当增加图网络层的数量时,模型的分类准确率会呈现出先上升后下降的趋势。过少的网络层数量会使得模型的学习能力不足,而过多的网络层会使得模型训练时间大幅增加且可能损害模型的分类性能。
3 结 论
本文提出一种基于多状态图神经网络的文本分类算法MSGNN。通过引入网络层的多个时刻的历史状态信息,结合参数共享的方式,来缓解图神经网络中存在的过度平滑问题。在特征提取方面结合了2种不同类型的图神经网络,得到了层次丰富的隐藏特征。基于多头自注意力机制的图读出器函数从多个角度将隐藏特征转化为更为完善的文本表示,最终提升模型的分类准确率。通过在6个公开数据集上,与9个基准算法进行实验对比,MSGNN在其中4个数据集上取得了最佳的实验结果。在对比实验部分可以得知,不同数量的注意力头以及图网络层对MSGNN的分类性能有影响,而这些超参数较为适合的值可通过实验进行确定。
尽管MSGNN具有较强的特征提取、特征聚合以及表示优化等能力,但其中的多步历史隐藏状态与图网络层数量相关,而在某些领域的实验成本通常较高。因此在后续研究中可以考虑如何更合理地选择图网络层数量,比如,通过构建加权图结构结合图节点重要度来自适应地去掉图中的某些边,以缓解算法模型中的过度平滑问题,并降低其对图网络层数量的敏感度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
科学与生活(2021年23期)2021-12-06
软件工程(2018年6期)2018-09-26
现代商贸工业(2017年23期)2017-09-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
物联网技术(2015年8期)2015-09-14
电脑知识与技术(2015年12期)2015-07-18
中国神经再生研究(英文版)(2014年11期)2014-01-22
现代电子技术(2009年14期)2009-09-05
