
基于AE-LSTM混合神经网络模型的NOx排放预测①
2023-05-08 04:46苏盈盈张气皓罗妤周昊何亚平阎垒
西南师范大学学报(自然科学版) 2023年4期
苏盈盈, 张气皓, 罗妤, 周昊, 何亚平, 阎垒
重庆科技学院 电气工程学院,重庆 401331
从环境保护的角度考虑,垃圾焚烧厂需要建立一个能够反映锅炉燃烧变量和排放尾气NOx浓度之间关系的模型,以便能够快速响应对NOx尾气的控制.NOx是垃圾焚烧发电厂的主要排放物之一,对环境和人类健康有害[1].人们已经考虑采用不同的技术来减少NOx的排放,例如低NOx燃烧技术[2]、选择性催化还原(Selective Catalytic Reduction,SCR)和非催化还原(Selective Non-Catalytic Reduction,SNCR)技术[3-4].
随着机器学习的不断发展,许多研究者开始利用神经网络(Artificial Neural Network,ANN)[5]对NOx浓度进行建模和预测.其中,文献[6]引入了一个具有外部输入神经网络的非线性自回归模型,以建立一个动态模型来预测NOx的排放.文献[7]使用人工神经网络开发了一个预测210MW煤粉锅炉满负荷条件下NOx排放的模型,并发现所提出的方法可用于生成可行的运行条件.除了人工神经网络,支持向量机(Support Vector Machine,SVM)[8-9]和极限学习机(Extreme Learning Machine,ELM)[10-11]也被引入用以模拟燃煤电厂NOx的排放.这些预测模型和方法都是在原有模型上进行的改进,虽然预测精度有所提高,但是同时也带来了更大的时间开销.
由于浅层网络模型的泛化能力不强,不能很好地适用于多种对象,因此,通过加深网络深度可优化浅层网络模型.文献[12-13]建立了最小二乘支持向量机LS-SVM预测模型,实现排放量等多种参数的软测量,随后将建立的模型与BP(Back Propagation,BP)神经网络模型进行对比,结果表明基于最小二乘支持向量机的网络模型的预测结果和运行速度均优于BP神经网络模型.文献[14]采用风驱动算法和基于混沌分组教与学算法优化极端学习机的NOx模型,通过参数调整及模型优化方法对NOx的预测提供了指导.文献[15]采用混沌分组教与学优化算法对NOx的预测建模,该模型具有较好的辨识与泛化能力,可以为解决工程实际问题提供思路.文献[16]在超临界机组的基础上,提出了一种改进的差分量子粒子群(Differential Evolution Quantum Particle Swarm Optimization,DEQPSO)算法,将其与极限学习机ELM相结合从而达到对NOx的排放预测.文献[17]提出了一种改进的最优觅食算法,并用该算法对锅炉NOx的排放特性进行建模.然而,上述运用传统的方式搭建的神经网络注重于数据的内部时序特征,却忽略了数据内部的空间特征联系,导致其模型对NOx的浓度预测精度低.
为了提高模型预测精度,本研究提出了一种基于自动编码器(AE)和长短期记忆神经网络(LSTM)的预测模型.首先,对原始数据进行标准化处理,剔除掉数据的异常值和缺失值; 然后,使用AE自动编码器来提取数据深层次的多维信息特征; 最后,将标准化后得到的数据输入LSTM网络中进行建模,并优化网络参数,建立基于AE-LSTM的NOx浓度预测模型.最终,以重庆市某垃圾焚烧厂某锅炉的燃烧数据作为研究对象来验证该预测模型的准确性.
1 LSTM网络模型
长短期记忆(Long Short Term Memory,LSTM)网络是一种具有记忆机制的神经网络,可以处理不同时间步的序列长度,以及能够学习到时间序列的关系等特点,因此可以非常有效地进行时间序列的建模.
LSTM与循环神经网络(Recurrent Neural Network,RNN)最主要的不同就是LSTM有多个门控机制,如图1所示的LSTM细胞图结构,其中,红色圆圈代表Sigmoid函数,蓝色圆圈代表Tanh 函数,输入门可以控制数据信息通过该门进入到LSTM细胞中; 遗忘门可以决定LSTM细胞对数据的遗忘程度,即保留或者丢弃数据信息; 输出门则控制LSTM细胞的输出.
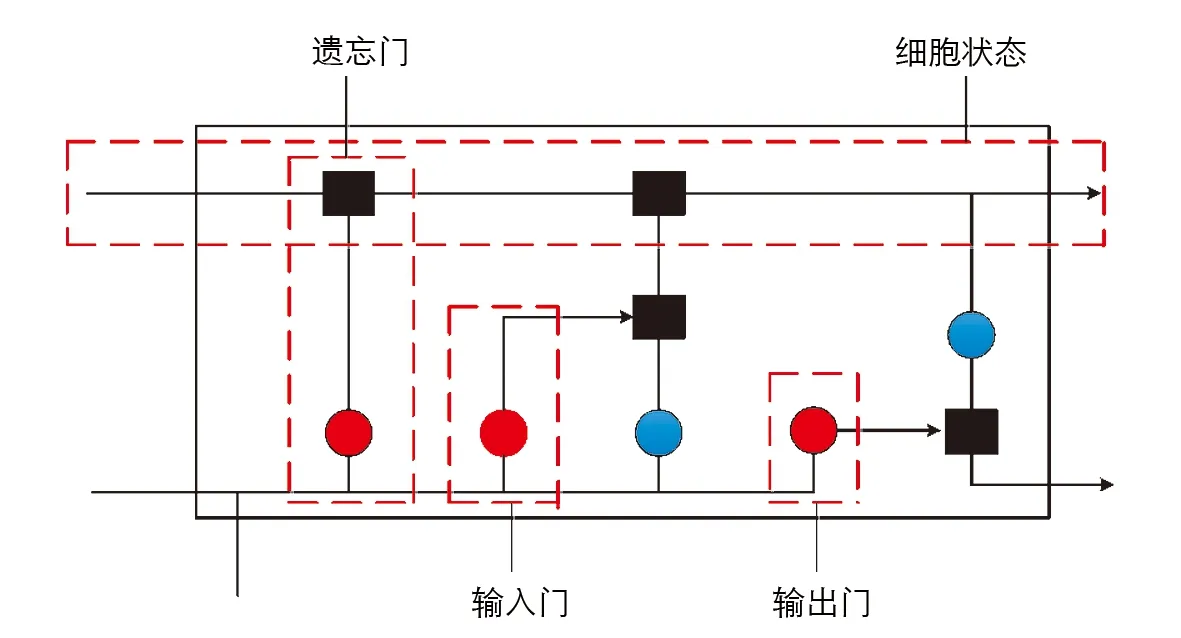
图1 LSTM细胞结构

为了获得这2个值,第一,需要计算3个门的状态和单元输入的状态:
1) 输入门Input gate
(1)
(2)

2) 遗忘门Forget gate
遗忘门决定应丢弃或保留“哪些信息”.
(3)
其中,ft为0~1之间的数,ht-1为上一单元的输出,xt为当前时刻的输入.
3) 输出门Output gate
(4)
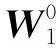
第二,计算单元的输出状态:
(5)

第三,计算隐藏层的输出:
ht=ot·tanh(Ct)
(6)
单元的输出定义为
(7)
其中,W2是2个元素之间的权重,b为输入层和输出层的偏置.
LSTM网络模型如图2所示,包含输入层、2个隐含LSTM层、2个Dropout层和一个Dense全连接层,共6个部分组成.该模型是用于NOx数据处理的,数据首先经过输入层后进入第一层隐含LSTM层,LSTM单元计算处理后得到输出状态和隐藏状态.为了避免过拟合,经过一个Dropout层进行正则化处理后,数据再次输入到第二层隐含LSTM层,得到新的输出状态和隐藏状态.在这之后,数据再经过一个Dropout层进行正则化处理,以进一步减少过拟合.最后,正则化后的数据输入到Dense全连接层,计算预测值,并输出NOx浓度的预测结果.

图2 LSTM 网络模型结构
2 AE-LSTM混合神经网络模型
2.1 AE-LSTM网络结构
自动编码器(Autoencoder,AE)是一种网络模型,对于神经网络的发展起到了促进作用,尤其在对高维复杂数据的特征提取方面具有重要作用.自动编码器的网络结构图如图3所示.它是一种单隐含层的无监督学习模型,自动编码器通过对内在特征的不断持续学习,对输入层和输出层进行误差计算,使得两者之间的误差尽可能小,从而得到高维数据的特征输出.这个过程起到了数据降维的作用,其作用类似于主成分分析法、因子分析法等.与传统的数据降维方法相比,自动编码器能够更有效地提取新特征.

图3 自动编码器结构图
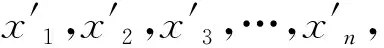
h=S(W·x+b)
(8)
其中,h为自动编码器的编码函数输出,也称之为隐含层的特征变量,S为自动编码器编码过程的激活函数,一般使用Sigmoid函数,W为输入层到隐含层的网络连接权重,b为网络偏置.通过解码过程得到输出层数据,再通过解码与编码的过程重构原始数据,保留原始数据中的重要特征.解码过程为
x′=S(WT·h+b′)
(9)
其中,x′为解码器的重构信息,S为自动编码器解码过程的激活函数,该激活函数使用Sigmoid函数,WT为隐含层到输出层的网络连接权重,b′为网络偏置.
趋势二:京津同城化将成为更加有效地推进京津冀协同发展,进而建立环渤海协同发展新机制的重大战略支点。以北京、天津为中心更加强调京津联动,加快实现京津同城化发展。同城化是区域经济一体化和城市群建设过程中的一个重要阶段,是区域城市间经济和社会发展到一定程度的必然趋势。推动京津同城化,关键是要实现京津基础设施一体化、产业发展一体化、市场一体化、公共服务一体化、资源配置一体化等,共同发挥高端引领和辐射带动作用,成为推动京津冀协同发展,建立环渤海协同发展新机制的重大战略支点。
经过自动编码器的编码和解码过程后,输入数据x映射为隐含层的特征h,再将特征h重构后输出为x′.为了确保最后的输出特征能够有效地代表原始数据,保留有原始数据的大部分信息,所以需要计算输入数据和输出数据的误差,对于自动编码器的误差损失函数通常为均方误差,公式如下:
(10)
自动编码器能够自动将高维数据特征提取至低维数据特征,同时还能保留原始数据的大量信息,保证数据的有效性不受破坏.这些低维数据特征可以被输入到LSTM神经网络中,LSTM网络通过不断学习权重参数来获得收敛,降低网络的预测复杂性,从而提高了预测的性能.AE-LSTM神经网络的结构如图4所示,该网络结构由两部分组成,第一部分是自动编码器,利用自动编码器将输入数据的高阶特征转换为低阶特征,并保留原始数据的信息.第二部分是LSTM神经网络,该部分将自动编码器输出的低阶有效数据输入到网络中,并对NOx进行预测,从而得到预测值.
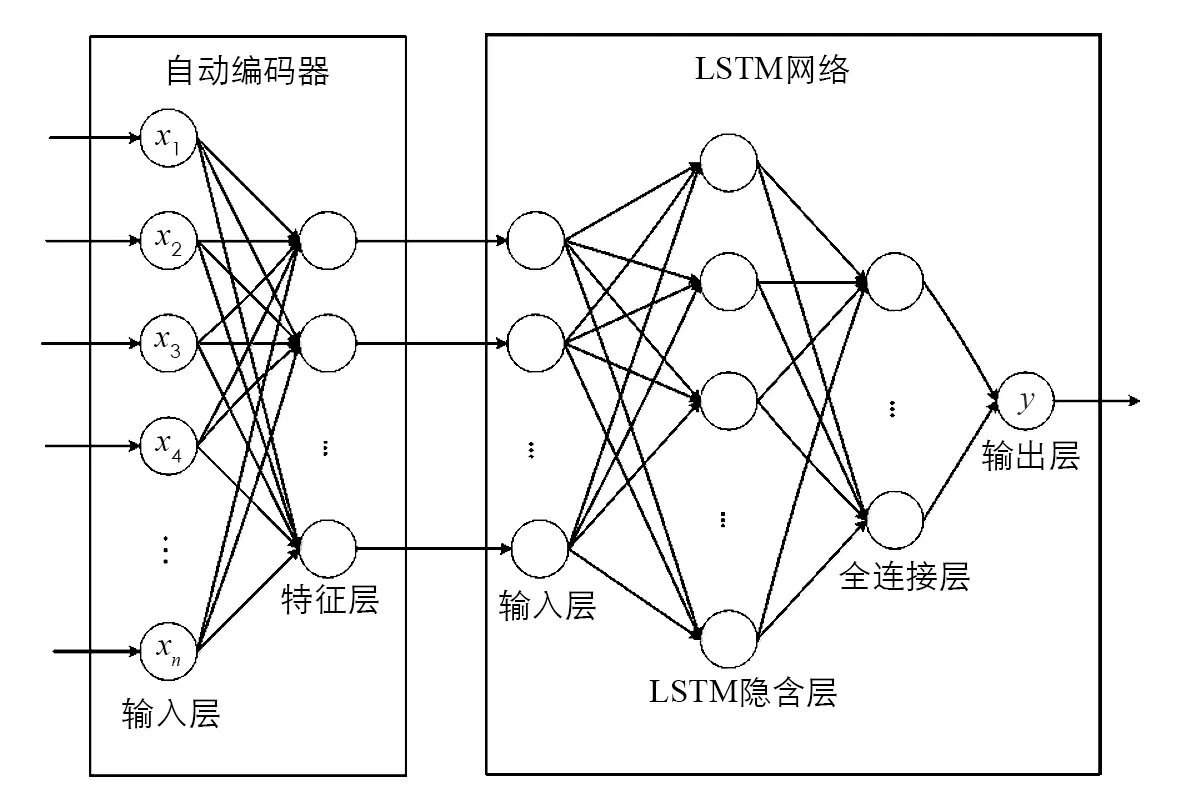
图4 AE-LSTM 模型结构图
2.2 AE-LSTM模型预测设计框架
AE-LSTM模型的预测过程如图5所示.首先,预处理好的数据集被划分为训练集和测试集.训练集用于训练模型的内部参数,得到收敛的预测模型,而测试集用于监测模型的预测性能.具体而言,原始数据首先输入自动编码器中,通过自动编码器的编码和解码过程得到低维度数据特征,然后将此数据输入LSTM网络中,经过LSTM网络的学习和调整,得到收敛的AE-LSTM网络.最后,将训练好的模型用于测试集上,得到预测值和真实值,并使用准确率和误差等指标来评估模型的性能.
1) 将处理好的数据矩阵划分成训练集与测试集;
2) 将数据输入AE中得到低维数据特征;
3) 确定AE-LSTM网络的结构;
4) 计算网络神经元的LOSS;
6) 达到迭代次数,网络训练结束,获得收敛的AE-LSTM网络;
7) 将测试集输入收敛的网络中,输出预测值,并计算准确率和误差,模型结束.
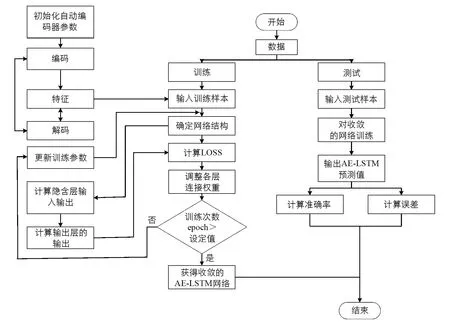
图5 AE-LSTM 模型预测流程
3 基于AE-LSTM的NOx排放预测
3.1 研究对象
工业预测的有效性很大程度上取决于数据的质量,因此数据预处理工作非常重要.本文使用的变量相关数据集来自于重庆市某垃圾焚烧厂的锅炉垃圾焚烧系统,如下表1所示.通过数据挖掘技术对原始数据中的异常值、缺失值进行处理,再消除数据共线性,最后对数据进行标准化处理,这些操作可以获得有效和可用的数据,有利于提高预测模型的性能.

表1 某垃圾焚烧厂燃烧过程的各工况变量
3.2 数据异常值和缺失值的处理
根据数据缺失的机理,可以将缺失值分为以下3类: 完全缺失、随机缺失和不完全缺失.通过对每个变量定义合理的取值范围,检查数据是否符合实际工况要求,并消除原始数据中的噪声,可以提高原始数据的质量.在数据预处理中,本文使用了样本均值来填充缺失镇,以提升数据的完整性.如表2为通过数学统计的方法来对数据进行的分析,分别计算每个变量的平均值、中位数、最大值、最小值、1stQu(25%值)和3stQu(75%值).另外,本文的数据集会用平均值对缺失值进行填充.
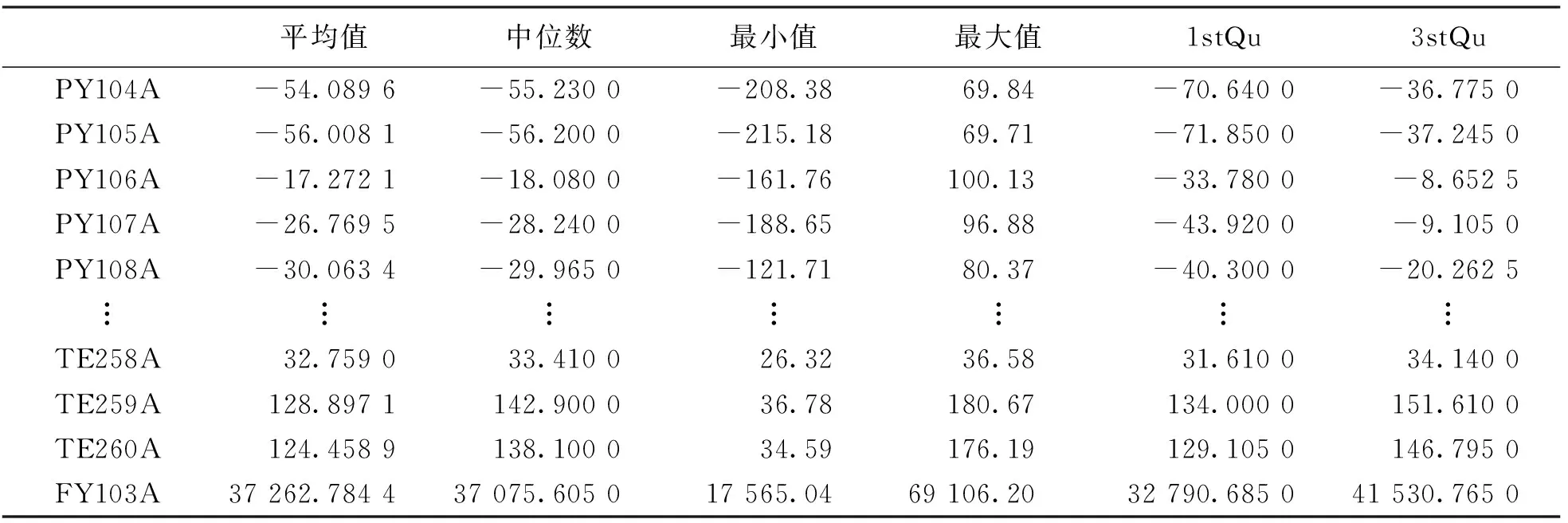
表2 数据的分析
3.3 数据共线性的消除与标准化
垃圾焚烧锅炉中相关的工艺变量共89维,变量间存在普遍的相关关系即共线性会影响模型的运行,降低预测精度.为了提高NOx预测的精度,计算各变量的相关系数,以消除共线性.通过反复测试,发现当删除相关性系数大于0.9的数据后,能够在线性范围内消除数据之间的共线性,使得模型精度最佳.因此最终得到了56维的工艺变量.
标准化是一项重要技术,通常在许多机器学习模型之前作为预处理步骤执行.本文的研究对象为垃圾焚烧NOx预测,采用Z-score标准化的方式对数据的量纲进行统一的去量纲处理,该处理方法对于模型的学习速度和训练速度都有所提升.利用Python 软件对现场采集的数据进行 Z-score 标准化处理,标准化后数据集中共有56×3612维数据.
4 实验及结果分析
AE-LSTM的初始参数设置如表3所示,对于自动编码器,主要由编码层和解码层两部分组成,其中解码层会将输入的数据进行压缩并提取特征,再对特征重新构造.由于自动编码器具有成镜像的对称结构,所以通过实验可得到最优的自动编码器结构,前面对原始数据预处理中得到56维变量,进而可以确定输入层节点为56个.为了减少权重的相互依赖,使用 Sigmoid 函数作为激活函数,损失函数使用均方误差,优化函数为 Adam 函数.

表3 AE-LSTM模型最优参数
通过十折交叉检验,得到基于AE-LSTM的NOx平均预测准确率如表4、图6和图7所示,其中图7为截取的图6部分片断以便观察.表4展示了不同模型的平均预测准确率和RMSE指标,其中,AE-LSTM网络的预测准确率为85.1%,高于CNN-LSTM网络的预测准确率83.8%和LSTM网络的预测准确率79.7%.AE-LSTM网络的RMSE为0.705,低于CNN-LSTM 网络的RMSE 0.725和LSTM网络的RMSE 0.833.可见AE-LSTM在NOx预测方面表现最优.
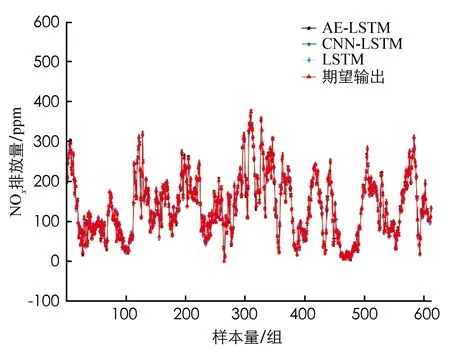
图6 基于AE-LSTM 模型的NOx预测结果

图7 截取的部分NOx预测效果

表4 AE-LSTM与LSTM、CNN-LSTM模型对比
5 结语
通过建立有效的NOx浓度预测模型,可以帮助垃圾焚烧厂提前做出规划,减少NOx排放.本文提出了一种基于自动编码器和长短期记忆神经网络的预测模型,针对垃圾焚烧NOx数据的空间特征,实现对长短期记忆神经网络的改进.长短期记忆神经网络主要关注数据的内部时序特征,而忽略了数据内部的空间特征联系,引入自动编码器可提升模型对数据内部的空间特征联系和数据多维度特征的提取能力.本文以重庆市某垃圾焚烧厂锅炉的燃烧数据为研究对象,首先利用LSTM网络进行建模,并进行了网络参数优化,再使用自动编码器对数据深层次多维信息特征进行提取,建立改进的AE-LSTM的NOx浓度预测模型.研究表明,相比LSTM模型,AE-LSTM模型在时序特征、空间特征强的数据集方面,表现出较好的预测精度和泛化能力.本文开展NOx浓度预测研究,有望为下一步如何调控工艺变量操作指标,优化工艺参数,达到NOx浓度减排目标奠定重要的理论依据.
猜你喜欢
China Report Asean(2022年8期)2022-09-02
云南化工(2021年8期)2021-12-21
环境保护与循环经济(2021年12期)2021-03-16
物联网技术(2020年12期)2021-01-27
成都信息工程大学学报(2018年3期)2018-08-29
汽车零部件(2017年4期)2017-07-12
环境保护与循环经济(2017年4期)2017-03-03
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
电测与仪表(2014年13期)2014-04-04
