
基于图神经的DQN 的类集成测试序列生成方法研究
2023-05-17 03:16王晨源
电子技术与软件工程 2023年5期
王晨源
(中国矿业大学 江苏省徐州市 221116)
软件测试可以找出软件中潜在的错误和缺陷。软件测试阶段主要包括单元测试、集成测试、系统测试以及验收测试等[1]。其中,集成测试是在单元测试的基础上,将所有模块按照设计要求组装成为子系统或系统并进行测试用来保证过程中各部分工作是否达到或实现相应技术指标。在软件集成测试过程中,首先面临的问题是如何确定类的测试序列,又被称为类集成测试序列确定问题。不同的类测试序列需要不同的测试桩代价,一个好的测试序列能够节省相当的测试代价。因此,提出一个合理的类集成测试序列生成技术方法对软件集成测试来说具有重要的意义。
针对国内外相关技术的研究,发现目前解决类集成测试序列生成问题主要包括基于图论的方法,基于搜索的方法和基于强化学习的方法。其中,基于强化学习的方法在近几年才提出,强化学习适用于解决序列决策问题且已经应用类集成测试序列问题[2]中。然而,目前基于强化学习的类集成测试序列生成方法使用需要构造的测试桩总个数作为最终评价指标,忽略了测试桩复杂度这一重要的评价指标,即,评价指标将每个测试桩的复杂度看作相同。实际上不同的测试桩具有不同的复杂度,构建越少的测试桩数量不能表示确定一个类集成测试序列花费的测试代价越低。
鉴于上述问题,本文提出了一种基于图神经网络的DQN 的类集成测试序列生成方法。将测试桩复杂度最低作为评价指标,通过深度强化学习中的DQN-学习算法[3],用图神经网络提取类集成测试中类与类之间的复杂关系特征,并使用经验回放和目标网络机制,在智能体和环境不断的训练交互中逐步选择能够降低测试桩复杂的动作,进而最终获得测试桩复杂度最低的类集成测试序列。
1 基本概念
类集成测试序列生成过程中所涉及到的基本概念主要包括类集成测试序列相关、类间依赖关系、测试桩代价度量以及深度强化学习。
1.1 类集成测试序列相关
(1)集成测试[4]:集成测试是在单元测试后的基础上,软件的不同模块被集成并作为一个整体进行测试,验证组合后的模块系统能否达到预期要求的功能。集成测试目的是在集成这些不同的软件模块时揭示它们之间交互中的缺陷进而保证软件产品的质量。
(2)测试桩[4]:当添加的模块依赖于一个还没有集成到当前系统的模块时,要为当前模块创建测试桩,测试桩被用来模拟当前被依赖的未集成模块的组件。
1.2 类间依赖关系
共存在5 种类间静态依赖关系[4]:
组合关系(Composition)、继承/泛化关系(Inheritance/Generalization)、聚合关系(Aggregation)、依赖关系(Dependency)和关联关系(Association)。
(1)组合关系:比聚合关系依赖强度更深的一种关联关系,也代表了整体和部分的关系,但是部分离不开整体独立存在。实例生活中可以表示为动物和动物内脏的关系。
图1::神经网络结构图
(2)继承/泛化关系:继承表示的是父类和子类之间的一种依赖关系,子类可以共享父类属性和操作,还可增加自己的新功能。父类负责定义所属子类的公共属性和操作。泛化指通过归纳概括子类抽象出父类。二者同属于子类父类关系的过程。
(3)聚合关系:聚合属于关联关系中的一种,代表了整体与部分的关系,属于一种较强的关联关系,生活中可以类比于汽车和轮胎的关系。
(4)依赖关系:类间关系最弱,有三种依赖关系的场景:类A 使用类B 的静态方法;类A 中某个方法涉及了类B 的实例作为局部变量;类B 实例作为类A中某个方法的参数或返回值。
(5)关联关系:包括两种类型,分为单向关联和双向关联共两种,当类A 中含有类B 实例的引用,或者类A 用到类B 中的属性和方法,而类B 不了解类A,则称为单向关联关系。若类A 和类B 都了解彼此的属性和方法,则称其为双向关联关系。
动态依赖关系可通过类间静态关系推导出动态依赖关系。
1.3 测试桩代价度量
通用测试桩[4]:当类1 依赖类2,但类1 被集成而类2 未被集成时,此时需让类2 成为通用测试桩为类1服务。
特效测试桩[4]:当类1 需要类2 的某些属性或方法时,类1 被集成而类2 未被集成,此时需让类2 成为特效测试桩为类1 服务。
本文使用最后整体类的复杂度作为评价指标,即测试桩的整体复杂度。通过Briand[5]等人提出的类间耦合度进而计算类的复杂度。测试桩整体复杂度计算方法采用丁艳茹[6]等人的计算方法。类间耦合度包括了属性耦合和方法耦合[5],分别对应着属性复杂度A(x,y)和方法复杂度M(x,y),x和y表示了两个类,其方向为类x到类y。在A和M的基础上进行归一化,公式如公式(1)和公式(2)所示。

1.4 深度强化学习
1.4.1 图神经网络
目前深度学习为机器学习领域的研究热点,深度学习在图像分析、自然语言处理等领域取得了成功[3],深度学习中包括了图神经网络。神经网络如图1 所示。
图神经网络通过矩阵的形式表达图上的信息。本文通过使用图神经网络作为智能体Agent 与环境交互的动作选择函数,Agent 每一次的行动都可以作为该模型的训练数据,深度神经网络通过这些数据可以逐渐达到收敛状态。
1.4.2 强化学习
强化学习(Reinforcement Learning, RL),用于描述以及解决智能体(agent)与环境的交互过程中通过学习策略来达成回报最大化或者实现特定目标问题。结构图如图2 所示。
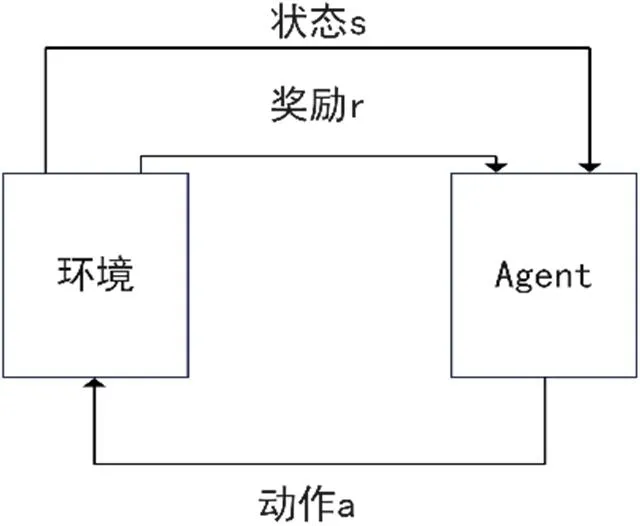
图2: 强化学习结构图
智能体在环境中不断摸索尝试从而学习到如何指导选择动作的策略。策略的好坏可以用长期执行该策略得到的累计奖励评估,强化学习的目标就是要找到能够使累计收益最大的策略。
对上述强化学习结构图中主要包括以下点[7]:
智能体(agent):可以通过执行动作与环境交互,从环境中获得奖励后调整学习策略,继续决策出下一步动作。
环境(environment):系统中除智能体外的部分,智能体通过在环境中执行动作。
状态(state,s):状态空间S 中包含智能体所处的全部状态。
动作(action,a):智能体所采取的动作,设A 包含智能体所有动作。
奖励(reward,r):智能体在状态s 采取不同的动作,环境会综合反馈给智能体一个奖励r。
1.4.3 深度强化学习深度强化学习通过结合深度学习和强化学习,借助神经网络强大的表征拟合能力来解决连续-动作空间问题。
2 基于图神经网络的DQN的类集成测试序列生成方法研究
2.1 强化学习任务设计
整个系统包括智能体和环境,智能体经过不断地尝试摸索出可测试路径并不断地学习直至收敛,最终获得最小的测试桩复杂度和测试序列。


2.2 奖励函数设计
奖励函数设计为:
针对上述公式的四种情况进行说明:
(1)-∞:智能体历史所选动作集包含了动作x
(2)c·(∑x=x,y∈NS(y,x)-S(x,y):此时环境状态为非终态,其中,c为奖励系数,S(x,y)表示类x到类y的整体复杂度
(3)0:达到终态但整体测试桩复杂度非最低
(4)MAX:达到终态且整体测试复杂度为最低,MAX 为自己设定的最大奖励值
2.3 图神经网络的DQN算法设计
(1)图神经网络:智能体中图神经网络负责接收环境反馈的状态S,其中S 包含了已选动作集和程序中类间关系信息。通过传入S,经过两层图卷积以及两层全连接层后输出每个类被选择的概率值,选出最大概率值所对应的类即为下次所选类。
(2)贪婪策略:设置参数ε值,以ε大的概率随机选择动作,1-ε大的概率选择当前Q 网络输出的最大值动作。
(3)DQN 算法:通过两个图神经网络,分别作为当前和目标值网络,前者网络使用最新参数,后者网络使用之前的参数,通过上述两种图神经网络用来提高算法稳定性。此外,还加入了经验回放机制,通过记忆库来存放智能体学习过的经验,在训练时可以从记忆库中随机抽取一些经验数据进行训练同时也打破了数据的相关性,提高了学习效率。

算法具体描述为:算法1.基于图神经网络的DQN 算法1:初始化记忆库D,设置可容纳数据量N。2:初始化Q 网络,设置初始权重为w,初始化目标Q 网络并设其初始权重w-=w。3:循环(episode =1, 2,…, M):4:初始化状态S。5:循环(step =1,2,…, T):6:采用贪婪策略生成动作at 7:执行动作at,接收奖励rt 和新的状态st+1 8:存储样本(st, at, rt, st+1)至D 中9:从D 中随机抽取一批样本(sj, aj, rj, sj+1)10:若达到终态,设yj=rj 11:否则:yj=rj+γ ·maxa' Q(sj+1, a′; w-)12:对(yj-Q(sj, aj; w)2 执行关于权重w 进行梯度下降并更新13:每隔若干步更新目标网络权重w-=w 14:直到 S 为终态15:直到 episode = M 执行结束
2.4 实例分析
此次采用来自Briand 等人的[5]文献中的ATM 程序作为实验分析,此程序共21 个类,代码行数占1390 行。ATM 的类的信息如表1 所示。
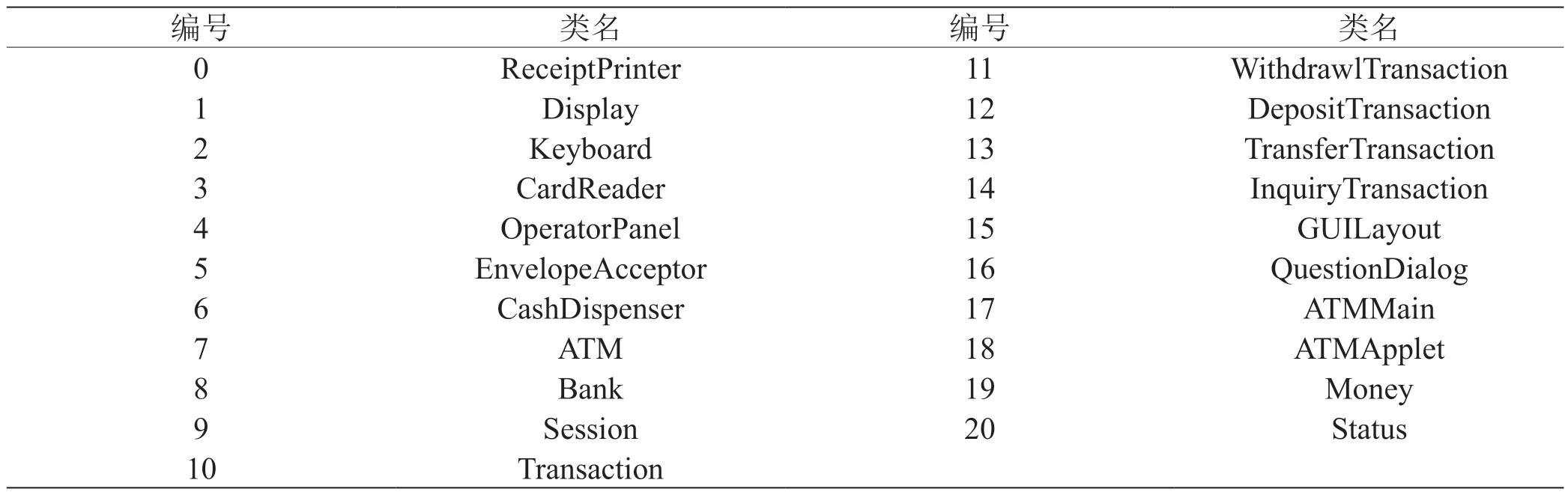
表1: ATM 系统信息
使用Soot 对ATM 程序静态分析以获得类间依赖关系中类间属性依赖和方法依赖值图,如图3 所示。

图3: 类间方法(左)和属性(右)依赖关系图
依照基于图神经网络DQN 算法流程,对于ATM系统程序,每一轮智能体选择前均需初始化状态S,在此轮中每次智能体依据贪婪策略选择动作并与环境交互,环境反馈奖励值和状态,智能体收到奖励值后进入下一状态并更新权重,继续依据环境反馈的状态给出动作。当智能体所给动作已存在过去选择动作序列中,环境直接反馈终态并给予非常小的奖励;智能体探索成功的标志是环境给予一个MAX 奖励并返回终态且选择动作序列中包含了所有的类,如表2 执行成功过程所示,集成序列为[0,4,5,1,11,2,15,17,16,14,9,3,8,18,6,10,20,7,12,19,13],此序列即为本次训练得到的最佳集成测试序列。
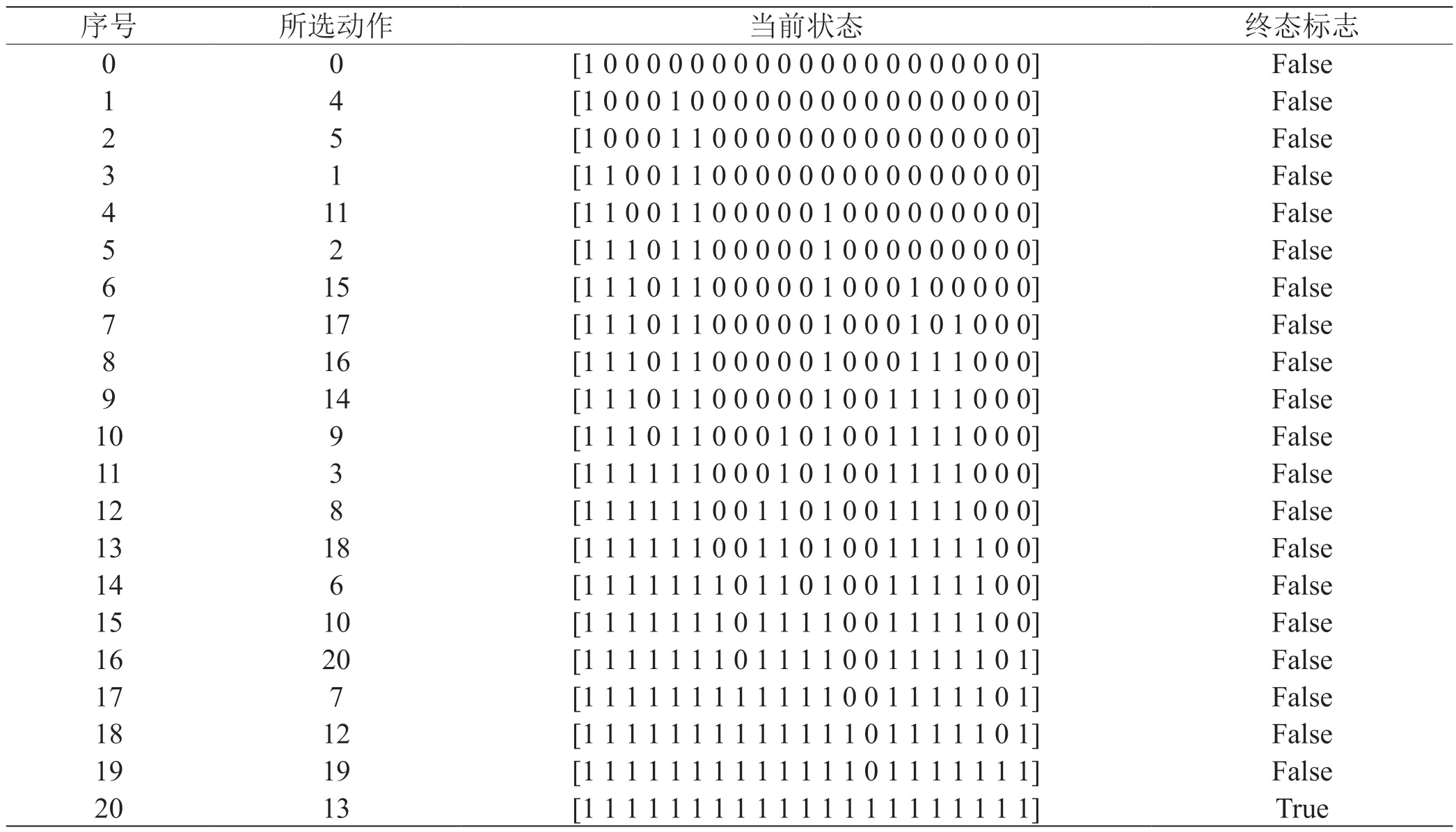
表2: 智能体执行整个过程
计算测试桩整体复杂度由环境负责计算给出,此次实验对ATM 训练3000 次,得到整体测试桩复杂度为2.2540242263114,对比丁艳茹[6]等人文献中的数据,属于最低的复杂度。实验结果对比如表3 所示。

表3: 实验结果对比
在实例测试之外还分析了来自SIR(software-artifact infrastructure repository,软件工件基础结构存储库)[8]中的了notepad_spl 和elevator 程序,共测试三个程序的整体测试桩复杂度,其中对于ATM 程序,使用图神经网络的DQN 算法要优于其他方法;对于notepad_spl 程序,使用图神经网络的DQN 算法要优于强化学习的方法和PSO 方法;对于elevator 程序,使用图神经网络的DQN 算法要优于基于搜索的方法。
3 总结
本文运用图神经网络和强化学习理论提出针对类集成测试序列问题使用基于图神经网络的DQN 算法来解决问题,以整体测试桩复杂度为评价指标,在有限的训练次数内得出最优测试序列的整体复杂度。所得出结果和现有方法相比,对比实验效果可以发现本文方法的有效性。
虽然所得结果有些优于其他方法,但是测试次数和参与测试的程序数量均较少且深度强化学习DQN 中还涉及到一系列参数问题,本文并未将所有参数的可测范围都进行测试,仅选择了一组常用参数进行测试,所以对本文方法中的算法优化还有待提高和发现。
总的来说,本文通过设计实验验证了本文方法的有效性,为软件测试中集成测试提供了一种新方法,拓宽了深度强化学习的应用范围。
猜你喜欢
电子制作(2019年19期)2019-11-23
中国惯性技术学报(2019年6期)2019-03-04
小学生作文(低年级适用)(2018年3期)2018-04-17
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
重型机械(2016年1期)2016-03-01
火控雷达技术(2016年3期)2016-02-06
大连工业大学学报(2015年4期)2015-12-11
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
海军航空大学学报(2015年4期)2015-02-27
