
基于深度哈希的图像检索技术研究
2023-05-17 03:17孙奇平
电子技术与软件工程 2023年5期
孙奇平
(漳州开放大学 福建省漳州市 363000)
移动互联时代,科学技术的发展日新月异,智能手机的普及、大数据的飞速发展、直播平台的火热、电商APP 的智能推荐……,各种多媒体数据让人眼花缭乱。基于内容的图像检索方法自推出以来有效提高了图像的检索效率,但是从原始图像中提取出来的高维特征存储量大、索引难等问题还有待解决,把哈希算法引入图像检索中,能提升检索速度。对图像底层特征的描述不足,影响了哈希算法检索的准确率,使用深度神经网络可以同时提取到图像的底层特征和高层语义信息[1],两种方法结合起来,能明显获得图像检索性能的提升,适用于大批量图像的检索。为此,本文在研究深度卷积神经网络的同时,把哈希算法结合起来,提出了一种基于深度哈希的图像检索方法。
1 图像检索技术
基于文本(以人工标注图像文本信息为主)和基于内容(以图像语义内容为主)是图像检索技术的两种类型[2]。在搜索引擎、内容审核、医疗诊断、人脸识别、电子商务等诸多领域都能看到图像检索技术的运用。
1.1 基于内容的图像检索
基于内容的图像检索技术有两个关键点[3]:一个是图像特征提取技术,另一个是特征数据库索引技术。其检索过程大致如下:一是获取预处理过的图像库中的图像特征向量,并建立向量特征库,二是处理查询图像,得到该图像特征,三是利用索引技术,计算查询图像与向量特征库的距离,四是根据图像相似性大小输出查询结果。颜色、纹理和形状这三大图像底层特征提取速度快,作为传统的图像特征提取方法其检索准确率有待提高。
1.2 基于哈希的图像检索
在图像检索中,把提取到的图像高维特征利用哈希算法映射成低维的二进制码,其高层语义特征在汉明空间还得以保持[4],内存占用减少了,同时检索速度也提高了。传统的哈希算法[5]可分为两类:数据无关和数据相关。在哈希图像检索方法中局部敏感哈希(LSH)率先被提了出来,作为与数据无关的一种哈希算法,虽然解决了高维度的问题,但其检索精度并不理想。为了提高图像检索精度,研究人员提出了与数据相关的检索方法,并根据样本是否存在标注,把哈希算法分为三种:无监督、半监督和有监督哈希算法[6]。

1.3 基于深度哈希的图像检索
1.3.1 深度学习
深度学习又称深度神经网络,不同于人工提取图像底层特征,深度学习通过模型自主学习图像特征,使得图像分类识别更加准确和高效。有赖于深度学习的研究发展,卷积神经网络在提取图像的高层语义特征[7]才能更全面。在深度学习模型中,一批优秀的模型例如AlexNet、VGGNet 等相继被推出。其中,深度卷积神经网络VGGNet[8]于2014 年在ILSVRC 比赛中取得佳绩,荣获定位项目冠军以及分类项目亚军。在六种VGGNet结构中,VGG16经常被使用,其包含16个具有权重的层,即卷积层13 层(conv1_1—conv5_3),全连接3 层(FC6—FC8)。
1.3.2 深度学习哈希
传统的哈希算法以检索精度换取检索速度,因其表达的图像内容和语义信息不完整,以致检索的准确率不高。在连续多年的PASCAL、VOC、ILSVRC 等国际计算机视觉大赛中,利用卷积神经网络提取图像特征都获得巨大成功。最先提出结合哈希技术和深度学习的Salakhutdinov R 等人[9]采用的学习方法是无监督的,样本图像的特征提取使用了多个受限玻尔兹曼机RBM。利用哈希技术和卷积神经网络的功能,深度哈希算法[10]表达图像特征时,通常先将图像转化为可编码的二进制,再通过有效的汉明距离来计算。
2 本文图像检索方法
本文在研究深度卷积神经网络VGG16 的同时,把有监督哈希算法结合起来,提出了一种基于深度哈希的图像检索方法。
2.1 模型描述
本文方法在VGG16 模型的基础上进行相应调整:模型中全连接层保留FC6 和FC7,去掉的FC8 用一个添加的哈希层替换,构建哈希函数获得哈希编码,并对损失函数进行优化,以便得到更好的训练效果,图像检索框架如图1 所示。
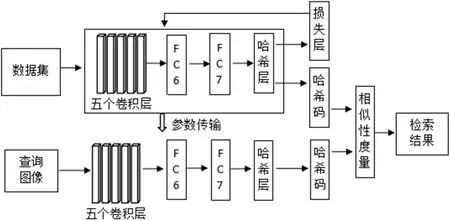
图1: 基于深度哈希的图像检索框架
检索过程主要包括模型训练和检索图像两个阶段:
(1)模型训练阶段:首先把输入的图像对特征向量使用VGG16 网络模型提取出来,并进行Dropout 操作,以避免过拟合。其次在添加的哈希层把提取到的图像对特征向量映射成二进制哈希编码。然后在损失层对损失函数做优化计算,保持哈希编码相似性学习。最后网络训练使用反向传播算法,更新权值,微调模型初始化参数。
(2)检索图像阶段:首先在训练好的模型中输入查询图像,获得对应哈希编码,然后进行哈希编码相似性度量,最后再输出检索结果。
2.2 问题定义

2.3 哈希函数

2.4 损失函数
本文利用成对标签信息作为监督,对哈希学习过程产生的误差进行约束,在损失层对损失函数做了优化计算。给定一对哈希编码hi和hj,可用公式

2.5 模型参数优化
在深度学习中,使用的训练样本需要足够多才能保证参数的可用性。利用迁移学习[12]的方法,本文选择的VGG16 模型已经在大规模的ImageNet 图像数据集上预训练过,其泛化能力已满足要求,在提取数据集图像特征时,对模型初始化参数进行微调能更好地适应本实验。综合考虑实验条件,本文学习率的调整使用指数衰减法,其中指数衰减率设为0.9,经过交叉验证,学习率调整为0.0001。因本实验用的两个数据集规模相对较小,为减少过拟合风险,迭代次数设为2000,批次大小设为128。经过交叉验证,动量设为0.9,偏置参数设为0.1,全连接层Dropout 率设为0.5 效果最好。
3 实验结果及分析
3.1 实验数据集及性能评价指标
综合考虑实验条件,CIFAR-10 数据集和NUSWIDE 数据集作为本文实验使用的图像数据集。其中,包含60000 幅图像的数据集CIFAR-10 是单标签的,分为10 个类别,每个类别各包含6000 幅图像。NUSWIDE 是一个多标签网络图像数据集,包含来自网站的269648 幅图像,本文使用21 个最常见标签的195834 幅图像,每个类别不少于5000 幅图像。在两个数据集中,测试集由每个类别中随机选取的100 幅图组成,剩下的图像组成检索集,训练集再由检索集中随机选取的500幅图组成。
本文采用在哈希算法性能评价中常用的三个指标:平均检索精度(mAP)、汉明半径为2 的精度曲线(P@H=2)以及精度—召回率曲线(P-R)作为实验评价标准。
3.2 实验比较及结果分析
与本文方法进行实验对比的是四种不同的哈希算法,其中传统的哈希算法有两种:局部敏感哈希(LSH)[13]和基于核的监督哈希(KSH)[14],另外深度哈希算法也有两种:卷积神经网络哈希(CNNH)[15]和深度神经网络哈希(DNNH)[16]。实验采用Tensorflow 框架[17],分别在12位、24 位、32 位和48 位哈希编码长度下进行。表1 给出了在四种不同哈希编码长度下,五种不同哈希算法在数据集CIFAR-10 和NUS-WIDE 上的总体mAP 实验结果。其中,在CIFAR-10 上根据整个检索集计算mAP,在NUS-WIDE 上根据返回的前5000 幅图像计算mAP。
作为多标签数据集,NUS-WIDE 中的每幅图像使用的类标签信息至少一个以上,因此从表1 中可见,该数据集mAP 检索结果总体上都高于使用单标签信息的数据集CIFAR-10。

表1: 不同哈希算法在CIFAR-10 和NUS-WIDE 上不同哈希码长度下的mAP
为了进一步验证本文算法的检索性能,图2 给出了在NUS-WIDE 上不同哈希码长度下的精度曲线(P@H=2),图3 给出了在NUS-WIDE 上哈希码长度为48位时的精度—召回率(P-R)曲线。
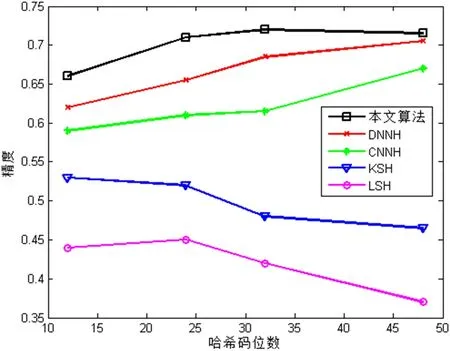
图2: 在NUS-WIDE 上不同哈希码长度下的精度曲线(P@H=2)
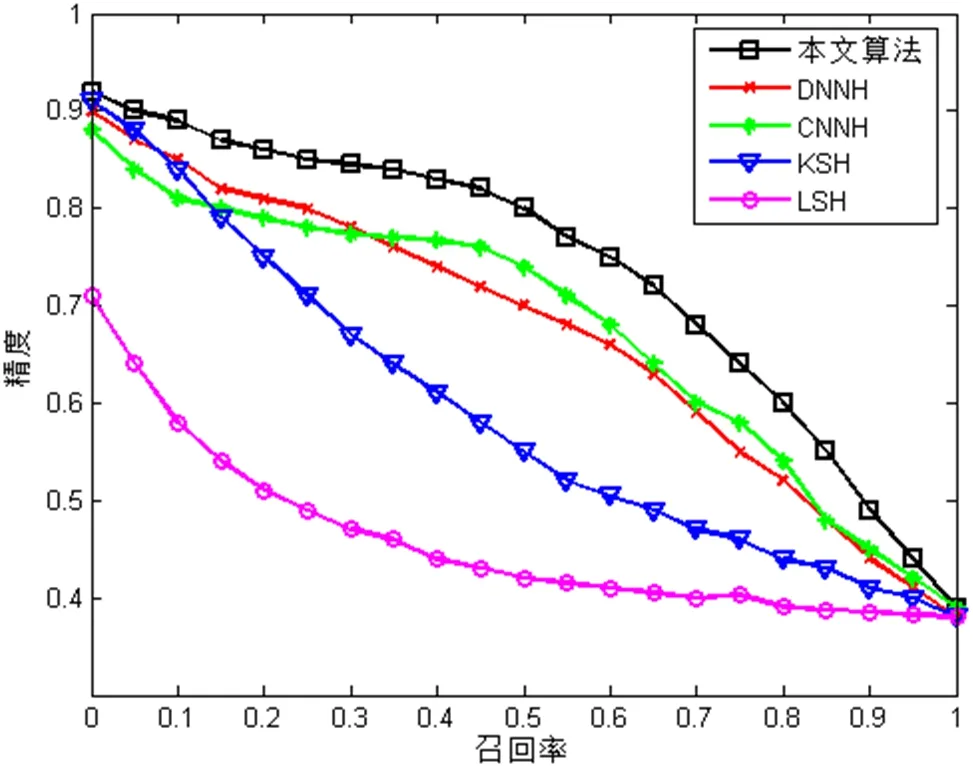
图3: 在NUS-WIDE 上哈希码长度为48 位时的P-R 曲线
对比实验结果表明,本文提出的检索方法,无论是跟传统的哈希算法:LSH、KSH 相比,还是跟深度哈希算法:CNNH、DNNH 相比,其检索性能明显优于其他四种,检索精度更高。
4 结束语
当前大数据技术的发展方兴未艾,在图像检索技术中,反映图像高层语义的深度特征被广泛运用,利用深度学习技术和哈希算法的研究方法,能进一步提高图像的检索效果。本文在VGG16 模型的基础上,先进行了改进和微调,再结合有监督的哈希算法,提出了一种基于深度哈希的图像检索方法。在跟文中其他四种典型哈希算法进行实验对比后,结果表明,本文所提方法检索精度更高、总体性能更佳,具备一定的实用性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
意林图解作文(小学版)(2019年6期)2019-07-16
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
专利代理(2016年1期)2016-05-17
计算机工程(2015年8期)2015-07-03
电视技术(2014年19期)2014-03-11
计算机工程(2014年6期)2014-02-28
电子设计工程(2014年12期)2014-02-27
质量与标准化(2010年5期)2010-05-03
