
面向用户需求的区域医疗数据质量综合评价研究
2023-05-23 19:01黄永生付晓璇江梦婷
医学信息 2023年10期
黄永生,孟 飞,付晓璇,江梦婷
(上海理工大学管理学院,上海 200093)
健康医疗大数据是指在疾病防治、健康管理等过程中产生的与健康医疗相关的数据,包括自然人从出生到死亡的完整生命过程中产生的与健康活动有关的全部数据,涉及患者诊疗信息、病历记录或者心理健康状况等个人健康生理信息[1,2]。在2018 年国家卫生健康委员会发布的《国家健康医疗大数据标准、安全和服务管理办法(试行)》中,重点强调了要充分发挥健康医疗大数据作为国家重要基础性战略资源的作用。区域健康医疗大数据在推进跨区域、跨机构、跨部门的健康医疗数据共享、政府医疗监管、临床大数据应用、科研大数据应用、公共卫生大数据应用、医疗产品与服务个性化应用等方面发挥重要作用[3-6]。而区域医疗数据质量的相关研究主要集中在数据质量评价维度和指标体系研究方面[7-10],少有从用户需求角度对医疗数据质量进行评价研究[11-14]。目前的研究工作虽然在评价体系和评价方法方面取得了一系列的研究成果,却存在难以满足个性化用户需求的问题。针对以上问题,本文提出了面向用户需求的区域医疗数据质量评价框架,并通过应用实例检测所提方法的有效性,旨在为区域医疗数据质量评价工作提供新的研究思路和设计方法。
1 区域医疗数据质量需求
当前,全国已建成多个省级和市级医疗数据中心,集成了居民健康档案、电子病历、疾病控制、疾病管理、医学数字影像等业务相关数据集[15]。经过处理的数据在医疗数据共享、政府医疗监管、临床大数据应用、科研大数据应用、公共卫生大数据应用、医疗产品与服务个性化等需求场景下发挥重要价值。但用户难以判断当前使用的数据质量是否满足要求,另外针对特定需求场景,不同的数据集具有不同的质量需求,有些数据集质量较低但并不影响当前业务,但有些数据集质量低下则不可接受[16,17]。例如,某些科研场景下只需要电子病历和居民健康档案业务相关数据集,而并不关心疾病控制和疾病管理业务数据集的数据质量,另外不同的科研任务对所使用的数据集也存在需求重要程度不同的情况。因此,需要明确不同应用场景所涉及的数据集范围以及对数据集分配需求重要度权重。本文基于对多个项目情况的调研,得出如表1 所示的数据集需求矩阵。

表1 数据集需求矩阵
2 面向用户需求的数据质量评价框架
2.1 数据质量评价流程 面向用户需求的数据质量评价流程共分为3 个阶段,首先基于需求场景计算指标权重,其次进行单数据集数据质量综合评价,最后面向用户需求进行多数据集数据质量综合评价。各阶段主要工作说明如下。
2.1.1 指标权重计算 不同的数据应用场景需求的数据集来源和结构存在差异,从而导致在数据质量评价指标的权重设计上也需要以应用场景为单位进行设计,以保证指标权重的设置更加符合当前应用场景的需求。
2.1.2 单数据集综合评价 单数据集综合评价是以特定场景下计算好的指标权重结合模糊综合评价模型进行数据质量综合评价,最终评价结果是单数据集对评语集的综合评价向量。如果评价向量中最大元素小于要求则需进行技术处理,以消除低质量数据直到满足要求。
2.1.3 多数据集综合评价 面向特定需求场景涉及的数据集,用户可根据自身需求设定每个数据集的权重,从而形成个性化的数据集需求权重向量。然后与单数据集综合评价形成的评价矩阵进行矩阵运算,得出最终评价结果,评价流程见图1。

图1 面向用户需求的数据质量评价流程
2.2 数据质量评价指标体系 本文参考《信息技术数据质量评价指标(GB/T 36344-2018)》标准对数据质量评价的要求构建了区域医疗数据质量评价指标体系,包括4 个指标维度共10 个指标。数据质量评价指标体系见表2。

表2 区域医疗数据质量评价指标体系

表2(续)
2.3 数据质量综合评价模型 采用模糊综合评价法对特定需求场景下区域医疗数据质量进行评价[18]。模型实现步骤包括设计评语集及隶属函数、计算指标权重、确定数据集及数据集权重、构建单数据集评价矩阵和多数据集综合评价。
2.3.1 评语集及隶属函数 评语集指评价者对评价对象做出的所有评价结果的集合,用V 表示。本文选取3 个评价等级来建立评语集合,即V={正常,注意,异常},其中0.98 为正常、0.96 为注意、0.90为异常。
指标的值由系统自动根据质量校验规则进行计算,以本文采用梯形分布函数,建立指标隶属度函数,值越接近1 代表其质量满足度越高。指标对应评语集3 种状态的隶属度函数如下:
2.3.2 指标集及指标权重 CRITIC 分析法是一种适用于确定指标客观权重的方法,这个方法通过指标内变化的大小和指标之间的冲突来全面确定指标的客观权重[19]。本文选择的10 个二级指标均可收集到客观指标值,且指标之间具有一定的波动性和相关性,因此选择CRITIC 法对指标计算权重,并通过如下几个步骤计算特定场景下指标权重。
步骤1:基于指标之间的相关系数构建表征冲突的定量表达式来表示指标之间的冲突性。通过标准矩阵X' 可获得每个指标的标准差σi和指标之间的相关系数ρij。式中x¯ 'i 表示第i 个指标的均值,表示标准矩阵X'第i 行和第j 行的协方差。
综合步骤1、2、3 计算得出指标权重向量为W=(w1w2… w10)。
2.3.3 数据集及数据集权重 不同需求场景涉及的数据集不同,用户可根据自身需求设定每个数据集的权重从而形成个性化的数据集需求权重向量。假设某场景下共涉及k 个数据集,每个数据集的权重为αi,则数据集权重向量A=(α1α2… α10)。
2.3.4 单数据集综合评价 对单数据集进行模糊综合评价,分别计算它们对于评语集V 中不同等级的隶属度rij,由此可得出第个数据集的评价矩阵Ri=(ri1,ri2,ri3),可得当前场景下所有数据集的综合评价矩阵:
2.3.5 多数据集综合评价 在单数据集综合评价的基础上,结合数据集的权重向量,综合得出多数据集综合评价结果,即当前场景的所有数据集对评语集的隶属度向量M,其计算公式如下。
3 实例分析
根据上述构建的面向用户需求的数据质量评价框架,本文选取某区域医疗科研场景进行实例分析,首先选取60 d 的科研场景涉及的6 个数据集(住院病案首页、入院记录、入院病程记录、检查检验记录、住院医嘱、手术治疗记录)的数据质量校验指标计算结果数据进行指标权重计算,其次选取某日待评价数据且对这6 个数据集进行单数据集综合评价,然后对多数据集进行综合评价得出科研场景下所有数据集对评语集的隶属度矩阵,最后根据最大隶属原则判定此日数据质量评价结果。
3.1 科研场景指标权重计算 在选取60 d 的数据中所有指标的计算结果数据后,由于指标量纲不同,需要对指标进行标准化处理,得到结果见表3。基于特定场景下指标权重计算步骤得出科研场景下指标权重系数见表4。
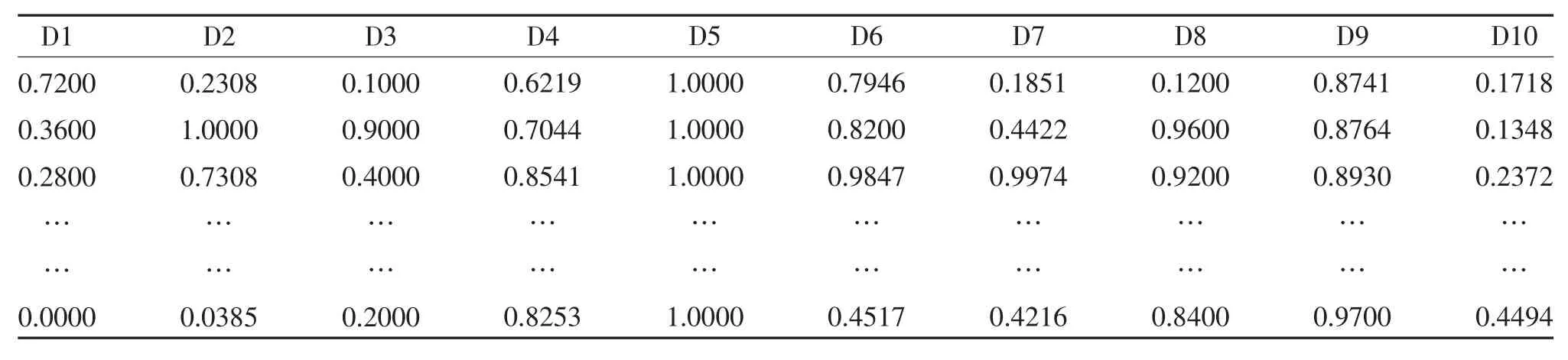
表3 标准化后科研场景指标计算结果

表4 科研场景下数据质量指标权重系数
3.2 科研场景模糊综合评价 通过收集到的某日指标计算结果结合隶属度函数分别对6 个数据集进行单数据集模糊综合评价,得出单数据集对评语集隶属度矩阵如下。
在单数据集综合评价的基础上,结合数据集的权重向量计算科研场景的所有数据集对评语集的隶属度向量M。本实例中数据集权重向量为用户指定为A=(0.35 0.2 0.15 0.15 0.1 0.05),用式(6)计算科研场景所有数据集对评语集的隶属矩阵过程如下。
经过计算得到M=(0.104 0.101 0.678),根据以上评价等级的隶属度范围,本实例科研场景下数据质量评价结果处于“异常”水平。
4 总结
本文将用户需求贯穿于区域医疗数据质量评价的全过程,明确了面向用户需求的数据质量评价框架。首先,基于用户的数据需求设计了数据质量评价流程,构建了数据质量评价指标体系。其次,建立了数据质量综合评价模型,利用CRITIC 分析法确定了指标权重,同时确立了单数据集和多数据集综合评价矩阵。最后,通过某区域科研场景对数据质量进行了综合评价,其评价结果总体上为“异常”水平。总体来看,本文构建的采用面向用户需求的区域医疗数据质量评价框架既能够根据用户需求灵活地进行数据质量评价,也能够及时根据用户需求及反馈信息中隐含的规律动态完善评价指标权重。根据这一研究结论,提出如下建议:①在区域医疗数据评价和管理过程中应多关注和了解用户的真实需求,结合用户需求来决定对哪些数据集进行评价以及动态调整评价指标的权重等;②在对数据质量进行评价时,可以考虑让用户参与进来,根据自身需求对数据集的重要程度进行辨识和赋权,使评价结果更贴近用户需求。未来研究可对数据质量评估框架的测度及实现方法进行细化,同时探索纳入用户对数据质量定性评价指标,如用户的质量感知性评价,另外需将本文所构建的面向用户需求的区域医疗数据质量评价框架下沉到实践应用中去,在实践中不断完善框架的适用性。
猜你喜欢
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
电信科学(2017年6期)2017-07-01
中国卫生(2016年1期)2016-11-12
中国卫生(2016年1期)2016-11-12
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
中国卫生(2016年1期)2016-01-24
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
