
基于GPU的4K图像JPEG2000编码混合并行计算研究与实现
2023-05-29 06:02林晓森雷振宇李艳华
现代电影技术 2023年5期
林晓森 雷振宇 李艳华
1.国家超级计算无锡中心,江苏无锡214072
2.中国电影股份有限公司,北京100044
3.南京行影信息技术有限公司,江苏南京211106
【关键字】JPEG2000;编码;解码;CUDA;GPU
1 NVIDIA GPU的最新发展
2006 年英伟达(NVIDIA)推出了搭载G80 GPU的统一计算设备架构(Compute Unified Device Architecture,CUDA)并行计算平台,这是一种用于通用图形处理器(GPU)计算的革命性架构,它使科学家和研究人员能够利用GPU 的并行处理能力来应对最复杂的计算挑战。截止2021 年11 月,CUDA 工具和库的下载量已超过3000 万次,服务了近300 万名开发者。NVIDIA 一直在不断改进、优化和扩展CUDA 平台,为之配备支持CUDA 的更强大GPU、各式新型GPU 加速库、工作站、服务器和应用,用以扩大NVIDIA 加速计算的覆盖范围。NVIDIA GPU 加速计算技术可以应对远超普通计算机能力的计算挑战,为不同的行业、科学领域和应用提供全栈解决方案,包括游戏与设计、生命与地球科学、机器人、自动驾驶汽车、量子计算、供应链物流、网络安全、5G、气候科学、数字生物学等。
过去十几年时间里,受视频游戏、虚拟货币、深度学习等领域应用的激励,也得益于半导体工艺的技术进步,NVIDIA GPU 的芯片架构和计算性能得到了巨大的发展,NVIDIA 先后推出了Fermi、Kepler、Maxwell、Pascal、Volta、Turning、Ampere、Hopper 等8 代芯片。

图1 NVIDIA GPU的发展历史
最新一代的面向专业应用的GPU 是2022 年3 月发布的面向专业领域的Hopper 架构,该架构芯片拥有超过800亿个晶体管,采用五项突破性创新技术为NVIDIA Tensor Core GPU 提供动力支持。NVIDIA Hopper 架构的Tensor Core 能够混合应用FP8 和FP16精度,TF32、FP64、FP16 和INT8 精度的每秒浮点运算(FLOPS)次数提高了3 倍[1]。第二代多实例GPU(MIG)技术提供的计算容量大约增加了3倍,每个GPU实例的显存带宽提升了近2 倍。Hopper 架构支持机密计算能力。Hopper 支持动态编程DPX 指令,该指令将复杂的递归问题分解为更简单的子问题来解决。与CPU 相比,Hopper GPU 能将动态编程算法速度提高40 倍;与NVIDIA 前一代Ampere 架构GPU 相比,则提高了7倍。这项技术大幅加快了疾病诊断、实时路由优化甚至图形分析的速度。
2022 年9 月NVIDIA 发布了面先消费者应用的Ada Lovelace 架构芯片,该GPU 芯片被应用于40系列的GeForce 消费级显卡。Ada Lovelace 架构致力于提供优异的游戏与创意、专业图形图像、AI 计算等领域的性能,它能够为光线追踪和基于AI 的神经图形提供革命性的性能。该架构的完整版Ada AD102 GPU芯片包含12 个Graphics Processing Clusters(GPCs)、72个Texture Processing Clusters (TPCs)、144 个Streaming Multiprocessors(SMs)、576 个Tensor Core、576 个Texture Units、18432 个CUDA Cores,并且带有一个具有1232比特的内存控制器的384比特内存接口[5]。作为同一时期推出GPU,Ada Lovelace 架构和Hopper 架构有很多的相同之处,此处不再赘述。
NVIDIA基于GPU的强大运算能力和CUDA的通用计算能力,开发并推出了CUDA-X 数据科学与AI GPU 加速库。数据科学工作流程从开始到结束都需要强大的计算能力,CUDA-X AI 是GPU 软件加速库的集合,这些库使用NVIDIA CUDA(NVIDIA 的开创性并行编程模型)编写,提供已优化加速的深度学习、机器学习和高性能计算(HPC)功能模块。CUDA-X 包括cuDNN(用于加速深度学习基元)、cuML(用于加速数据科学工作流程和机器学习算法)、NVIDIA®TensorRTTM(用于优化受训模型的推理性能)、cuDF(用于访问Pandas 之类的数据科学API)、cuGraph(用于在图形上执行高性能分析),以及超过13个的其他加速库。这些库与NVIDIA Tensor Core GPU 能无缝地协同工作,为开发者提供快速AI应用程序开发和部署。CUDA-X AI 能让开发人员提高工作效率,同时从不断提升的应用程序性能中获益[3]。如图2 所示,显示了CUDA-X 在NVIDIA 体系中的地位。CUDA-X AI库支持多种设备的NVIDIA GPU,其中包括台式机、工作站、服务器、云计算和物联网(IoT) 设备的GPU设备。无论是开发新应用程序还是优化加速现有应用程序的运行速度,CUDA-X AI 都能提供极为高效和有效的路径。
图2 NVIDIA关于CUDA-X的地位【3】
2 CPU的最新进展
作为计算机体系的核心部件,中央处理器(CPU)的技术发展一直备受瞩目。CPU 的制造商Intel 和AMD 在整个市场里拥有毋庸置疑的领先地位,不仅拥有CPU,还有GPU、FPGA等技术。
CPU 与GPU 的异构融合是最新发展方向。AMD的研究人员[7]提出将CPU 与GPU 打包放置在一款芯片中的设计方案以实现EFLOPS 级别超级计算机的想法。2022 年Intel 宣布了下一步研发方向是XPU,并将开发项目代码命名为Falcon Shores。Intel 从第12 代开始引入了混合核的技术,CPU 的核分为性能核(Performance Cores,P-Cores)与效能核(Efficient Cores,E-Cores)两种。性能核是高性能CPU 核,主要用于处理高负债、高输入输出的单线程任务,例如游戏、视频、科学计算等。效能核是关注高效运行的CPU 核,主要用于系统的多线程任务中低等级任务,例如邮件处理等,在效率与低延迟之间取得一个最佳的平衡点。为此,Intel CPU 引入了一个称之为“Thread Director”的新技术,这项技术用于在合适的时间将不同的负载发往正确的CPU 核,它帮助评级和管理负载的分布,将任务发送至最优的线程[8]。混合多核架构为操作系统平衡速度与节能、优化节能策略带来了巨大的好处。
3 4K 图像JPEG2000 编码的混合并行计算分析与框架设计
4K 高帧率电影是电影高新技术的一个发展方向。相比2K 24FPS 的电影,4K 高帧率电影的数据量有了大幅度提升,在大屏幕上,能够给观众带来更好的观影体验。与此同时,4K 高帧率电影也对电影编码器的速率提出了更高的要求。
2K 遮幅电影的分辨率是1998×1080,2K 宽幅电影的分辨率是2048×858。4K电影的图像宽高的分辨率分别是2K电影的2倍,分辨率达到了3996×2160和4096×1716,像素总数是2K 电影的4 倍。可以预见4K 电影编码的计算量相比2K 电影有了大幅度的提升。
笔者曾分析过2K 图像的JPEG2000 算法的并行计算可行性。JPEG2000 编码器的工作流程:首先对源图像数据进行离散小波变换(DWT),然后对变换后的小波系数进行量化,接着对量化后的数据熵编码,最后形成输出码流。解码器是编码器的逆过程。编码器的处理时间主要消耗在DWT 和EBCOT 编码。经过测试,DWT 预计要占据40%~60%的处理器时间。EBCOT 分t1 和t2 两个阶段编码,主要是t1 编码消耗绝大部分的时间,大约占据30%~50%的处理器时间[6]。
离散小波变换(DWT)是对一维数据做处理,对数据反复做加法和乘法运算。二维图像的DWT计算则是做两次处理,先对图像垂直方向列数据逐列做DWT 计算,再对图像水平方向的行数据逐行做DWT计算。由此可见对图像做DWT计算的计算量与像素总数有线性关系,4K 图像的DWT 计算量是2K 图像的4 倍。而EBCOT 的计算量受像素总数和图像内容复杂度两方面影响,与像素总数不是线性相关。相比文献[6]对2K 图像编码结果的分析,4K 图像编码中DWT 的计算量占比更高一些,预估在60%之上。DWT 在同一组数据上反复做加法和乘法的运算特点特别适合GPU,因此4K 图像编码的DWT 计算部分移植到GPU上进行将具有更高的性价比。
GPU 板卡是依附于CPU 主机运行的。而现代GPU 和CPU 都具有强大的算力,为了达到编码的最高速度,最好的方法应是充分利用这二者的算力,使两者的算力都能达到或者接近100%。在JPEG2000编码中,DWT 和EBCOT 都是需要消耗算力的过程,其中DWT 计算过程更适合GPU 计算的特点,因此我们设计将DWT 计算过程放置在GPU 中运行;EBCOT计算过程存在大量的条件判断语句,这种语句导致的执行指令流分支并不适合GPU 计算的特点,因此这部分计算由CPU 承担。CPU 和GPU 各自承担一部分计算任务,需要对计算的负载和计算的时序做优化从而达到系统的最优。
4K 电影的编码通常是对帧序列做编码。在多核CPU 和GPU 上做图像编码的并行化,通常有两个基本方案:第一种方案是对帧序列逐帧编码,每一帧编码时尽量将计算并行化以达到使用尽可能多的CPU核与GPU 核;第二种方案为启动多个线程同时对多个图像帧做编码,每个线程处理一帧图像。第一种方案的优点是每次只处理一帧图像占用内存较少,但是受并行化程度的影响对CPU 和GPU 性能的压榨不容易达到极致;第二种方案较容易实现充分利用CPU和GPU 性能,但是由于同时处理多帧图像占用内存较多,并且可能出现多个线程执行相同操作,例如同时读取文件,同时占用CPU 缓存和内存读写资源,同时向GPU 提交计算任务导致排队等候GPU 计算资源,同时写入文件,因此带来的计算效率下降的问题。
如果采用第一个方案,由于JPEG2000 编码过程中存在一些不可并行的计算过程,并且GPU 和CPU计算部分是依次进行,在进行GPU 计算时CPU 几乎是闲置的,反之在进行CPU 计算时GPU 几乎是闲置的。因此会造成CPU 和GPU 计算能力的浪费而远远不能达到性能充分利用的目标。
而第二个方案存在的问题是可以解决的。现代计算机系统通常带有大内存,主机内存可配置128GB甚至更高内存,GPU 板卡通常带有8~24GB 内存,并且笔者采用64位OS和64位软件编码技术,因此具备了同时处理多个视频帧编码所需大内存能力。笔者希望通过多个线程同时编码,尽量提升线程执行编码进度的无序程度,减少每个线程执行相同工作带来的资源冲突和等待的机会,以达到充分使用CPU 和GPU 资源的目的。理想情况是每个线程处于编码的不同节点位置,有的在读写文件,有的在主机和显卡之间拷贝数据,有的在做DWT,有的在做EBCOT 等。由于每一帧图像内容不同,EBCOT 计算时长不同,同时启动的多个编码线程在经过一段时间之后处理进度通常会处于不同的位置,可以接近我们所希望的状态。但达到这一状态的时间依赖于电影画面内容。为了进一步加强不同线程编码进度的无序程度,减少对画面内容的依赖度,我们在每个线程启动时随机等候0~2.0 秒的时间,再开始执行连续的编码任务。实验表明,采用这个方法可实现多个线程从一开始就处于不同编码进度的无序状态,显著减少任务刚启动时多个线程执行相同操作带来的资源冲突和等待的问题。
即使采用上述的办法,也还是可能存在多个线程同时向GPU 提交计算任务的情况。但是最新型号的旗 舰版GPU 的CUDA 核数高 达8000 个甚至10000 个以上,在下一章节将进一步详细阐述GPU 计算的实现细节,我们可以看到GPU 的计算资源或者是可以容纳多帧图像同时进行计算,或者是处于全卡计算状态没有浪费计算性能。
综合以上分析,笔者采用每个CPU 核处理1帧画面的计算框架。整个系统的混合并行计算的架构如图4所示。
4 JPEG2000 GPU编码的实现
JPEG2000 编码之前需对图像进行预处理,将像素转为YCrCb 分量,并减去其直流分量值。一幅4K图像拥有大约800 万像素。GPU 的CUDA 核的数量规模大约在几千至一万左右,例如GeForce 3090 显卡的CUDA 核为10000 多个,因此我们要让每个CUDA核处理大约几千个像素。如何在这些CUDA 核之间分配待处理的像素,有几种不同的方法。可以让一个CUDA 线程处理一行像素,大约启动2000 多个CUDA线程;也可以让一个CUDA 线程处理一列像素,启动大约4000 多个线程。但究竟哪种方法更好,或者是否还存在更好的方法,需要进一步分析GPU 计算的执行方式。
在硬件层面,每个NVIDIA GPU 包含了一组不同数量的Streaming Multiprocesser(SM)。在Ampere 架构芯片中,每个芯片包含128 个SM,每个SM 包含64个FP32 CUDA Cores,合计8192个FP32 CUDA Cores。在Hopper 架构中,每个芯片包含144 个SM,每个SM包 含 了128 个FP32 CUDA Cores,合 计18432 个CUDA Cores。
从软件的视角看,CUDA 编程的对象是数量可达成千上万的众多CUDA 线程。为了便于线程与数据的组织和管理,在CUDA 编程模型中,将一组线程集合称为Block(线程块)。由于线程块里的所有线程将同时驻存在同一个SM 里被执行,并且分享该SM 里的有限内存资源,因此一个线程块的线程数是受限的,在当前GPU里一个线程块最多能有1024个线程。CUDA 程序中,每个线程块里的线程数是相同的,因此启动GPU 执行一个CUDA 内核,内核的线程数为线程块个数乘以每个线程块的线程数。与线程集合组成线程块类似,线程块集合组成了Grid(网格),如图5 所示。网格中线程块的数量通常由正在处理的数据的数量决定,这个数值通常超过系统中的处理器数量。
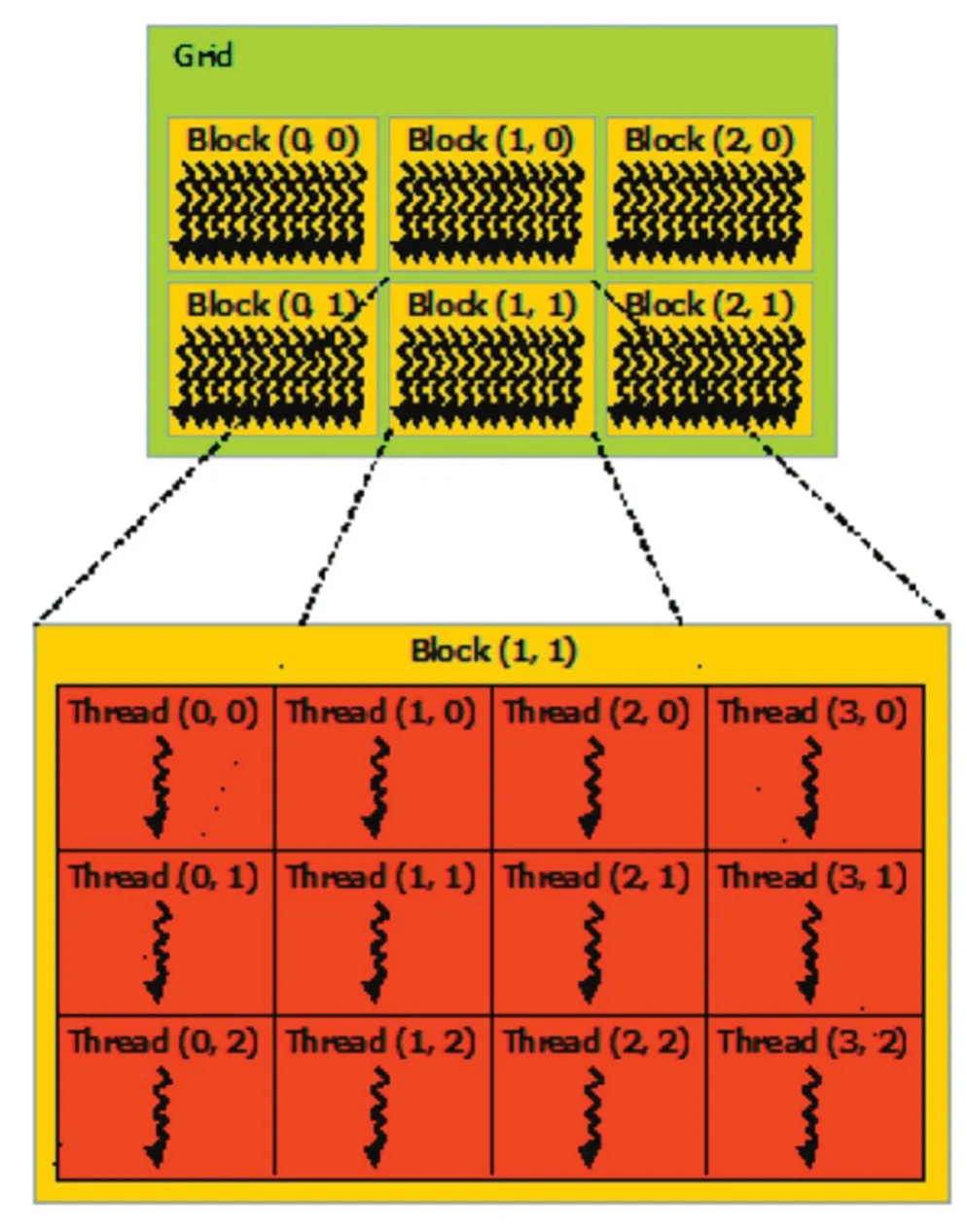
图5 线程块的网格
当一个CUDA 程序任务被发送至GPU 之后,CUDA 线程网格里的线程块被枚举分发至具有可用执行容量的SM。线程的线程块在一个SM 上并发执行,多个线程块可以在一个SM 上并发执行。当线程块终止时,新的线程块将在空闲的SM 上启动。当GPU 里的SM 执行一个线程块时,它将进一步将块里的线程划分为多个Warp,每个Warp 包含有32 个CUDA 线程。在SM 里,一个Warp 里的每个线程从相同的程序地址开始执行,并且每个线程拥有自己的指令地址计数器和寄存器状态,因此每个线程可独立的执行且避免了分支。SM 里Warp 调度器将线程块里的线程按照线程序号的升序进行Warp,每个Warp 里的线程序号是连续递增的,线程块里的第一个Warp的第一个线程序号为0。
每个Warp的线程在SM里执行时,它的所有执行上下文内容,诸如程序计数器、寄存器等,都被保存在芯片上,SM 从一个Warp 切换执行另一个Warp 是没有代价的。在现代处理器技术中,影响处理器不能全速满负载运行的因素主要是等待数据从内存中读取进寄存器。GPU 的SM 的Warp 选择算法将自动调度选择一个已经做好被执行准备的Warp 进行执行,因此能尽量地保持GPU 处于满负载运行状态,从而实现最高的处理速度。
在了解了GPU 的硬件并行工作原理和CUDA 软件编程模型之后,在官方开发文档[9]和一些代码样例中采用了每个CUDA 线程处理一个像素的做法。具体做法如下,将图像切割成宽高为N×M 的子块,N 和M的乘积小于1024,并且N和M尽量能分别整除图像的宽和高。每个子块里像素处理的CUDA 线程集合组成一个CUDA 线程块,整个图像的所有线程块集合组成一个网格。当这个算法的CUDA 执行内核被发送至GPU,SM 将自动调度每个已经准备数据处理的线程Warp,由于每个线程只处理一个像素即每个线程最多只等待一次,因此SM 的调度算法能以最优的状态保持GPU 尽量满负载运行而不浪费太多时间在等待上。而一个CUDA 线程处理多个像素的做法,可能存在多次等待数据的中断,经过仔细调优可能达到SM的最高工作负载也就相当于前一个算法。
在该处理中,我们设置每个CUDA 线程块大小为512(32×16),每个CUDA Thread 处理1 个像素。对于4K图像的处理,大约有800万个CUDA 线程。如果采用具有10000多个CUDA Core的3090显卡做计算,平均每个CUDA Core 需承担800 个CUDA 线程的任务,处理800 个像素值。这个计算量对于每个CUDA Core而言是很少的,并且这一步处理可占用所有GPU计算性能不造成性能浪费。
程序流程如图6所示。

图6 JPEG2000 编码预处理
完成预处理后的数据仍然保存在GPU 的显存里,不立即拷贝回主机内存。接着进行下一步离散小波变换(DWT)。基础的DWT 变换算法是一维的,对二维图像做DWT 变换需进行2 次,先做列变换,再做行变换。和预处理的过程不同,DWT 变换不是逐像素变换,而是逐行(或逐列)地处理,并且需对同一个元素进行反复操作。因此DWT变换不能再采用一个CUDA 线程处理一个像素的办法。考虑到DWT 算法计算过程中,虽然有少量条件判断语句用于计算位置,但指令分支并不多,并且也不存在层数较深的分支,因此笔者采用一个CUDA 线程处理一行(一列)元素的方法。如图8 所示,做水平DWT 变换时,设置CUDA 线程块大小值为512;做垂直DWT 变换时,设置CUDA 线程块大小值为256。在完成所有GPU 计算后,最后将图像数据拷贝回主机内存,进行后续的编码计算。
对4K 图像的其中一个分量做处理时,根据DCI的规范要求,需对图像逐级做7 次DWT 变换。以宽幅图像为例,第一次对4096×1716 全画面做DWT 处理,第二次对分辨率为2048×858的画面1/4部分做处理,第三次对画面的1/16 部分做处理,依此类推,最后一次对分辨率为64×27 的画面的1/(64×64)部分做处理。由于笔者所采用的是每个CUDA Thread 处理一行(或一列)数据,因此在上述过程中最多启动4096 个CUDA 线程,并且在逐级计算中每次启动的CUDA 线程数快速减小。相对于仅10000 个CUDA Core 来说,DWT 计算占用的GPU 计算资源是不饱和的,是允许多个图像同时进行GPU 的DWT 计算以提高GPU计算性能的利用率。
计算流程图如图7所示。

图7 DWT变换
在上述分析的处理过程中,从主机内存拷贝图像数据至显卡内存,预处理后再进行DWT变换,然后再把数据从显卡内存拷贝回主机内存。在这些GPU 处理之间还存在一些CPU 处理,而这些CPU 处理并不需要等待上一步GPU 处理完成,因此在上述GPU 相关的处理中,我们采用CUDA 的异步处理技术。CUDA 编程提供了Streams 流处理技术,无论是数据拷贝还是调用CUDA 内核函数,都可作为一系列GPU操作命令流式执行,在所有处理的最后环节再进行同步操作。采用CUDA Streams 可进一步提升GPU 和CPU混合计算的负载密度,减少等待带来的浪费。
JPEG2000 的解码过程与编码过程相反,按照上述流程反向操作即可。
5 运行测试结果
16 位的4K 图像每帧有接近50MB 的数据,每秒钟24 帧,则一秒钟有超过1GB 的数据。如此巨大的图像数据读出写入会占据大量的时间。因此为了测试最大编码速度,必须排除图像读写时间的影响,否则测出的编码速度不是准确的。为此我们预先将尽可能多帧的图像数据预先读入内存,编码后的JPEG2000码流直接抛弃而不写入硬盘。计算编码时间从图像数据被读入内存之后开始,直至JPEG2000码流完成为止,如此计算出的编码速度才是真实的。
用于测试的工作站配置如下:
CPU:Intel Core i9-12900;
主机内存:128GB;
GPU:NVIDIA GeForce RTX 3080 24GB;
硬盘:2TB固态硬盘。
我们将4K 视频片段作为编码对象,测试结果见表1。

表1 测试结果
在这个测试系统里,我们采用的NVIDIA Ge-Force RTX 3080 虽然是3 年前发布的,但是它目前仍是市场主流选择之一,这块GPU 的计算能力高达29.77TFLOPS。系统采用的Intel Core i9-12900 的算力是1.26TFLOPS。GPU 的计算能力远远大于CPU 的计算能力。因此在实际计算过程中,CPU 的负载是100%,而GPU 的负载保持在较低水平。测试结果表明基于混合架构的4K 图像JPEG2000 并行编码的算法以较低的成本达到了较高的性能。未来如采用更高性能的CPU,编码速度还能有更高的提升空间。
6 结论
笔者设计实现的GPU 与CPU 的混合并行计算架构,采用非专业级应用的游戏显卡和消费级CPU 即可达到较高的4K 图像编解码速度,具有很好的性价比。该技术可应用于数字电影4K 母版制作和4K 节目播放等应用场景。未来为了进一步提升速度,可研究JPEG2000 的t1 编码的GPU 算法实现以期获得更快的速度。❖
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
高技术通讯(2021年5期)2021-07-16
汽车工程(2021年12期)2021-03-08
当代陕西(2019年13期)2019-08-20
电信科学(2017年6期)2017-07-01
环球市场(2017年36期)2017-03-09
电测与仪表(2015年22期)2015-04-09
测绘科学与工程(2014年5期)2014-02-27
计算机工程与科学(2013年2期)2013-06-07
吉林建筑大学学报(2012年3期)2012-08-15
