
基于数据挖掘的视频评论识别分析
2023-05-30 10:48霍建光
电脑知识与技术 2023年2期
霍建光


关键词:BERT 模型;推荐;文本情感分析;分类
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)02-0050-03
1 引言
互联网技术的快速发展已经影响了人们工作、生活的方方面面。目前整个网络的数据量越来越多,呈现出信息多样化、信息化扩散快及类型多等特点[1]。整个数据的类型包括文本数据、视频数据、文件数据等内容,这些数据有些是结构化的、有些是非结构化的。为了能够获取相关数据信息,文章可以通过爬虫的方式来确定主题,以此获取针对性的业务数据信息。
随着技术的提升以及市场的完善,人们越来越多地使用网络平台进行购物、购票、出行等日常活动。另外,人们也增加了视频平台的使用时间。在这些活动之中,不论是日常活动还是娱乐活动,难以避免地会出现众多来自用户主观性的、带有情感色彩的评论[2]。这些评论并非活动中产生的赘余,而是一种宝贵的资源,它直观表现出对某一事物的偏好,网络平台运营者如果能根据用户的喜好进行推荐,则会大大促进用户的消费意愿,增加客户黏性。而若是能够提前对用户评论进行情感的分类,则能提升分析的效率。
对企业而言,各大社交平台网站充满了各种各样的用户评论,其中不乏过激的、恶意煽动的负面评论。败坏社区风气,而举报恶意评论的功能需要用户手動完成,不确定性高,而且效率低下。该系统可以帮助企业快速分辨出负面评论,再加以处理的效率随之提高;对个人而言,想要得知一个视频评论是正面评论还是负面评论居多并非一件容易的事,尤其是评论数量巨大的情况下,该系统可以分辨并展示出正面评论,中性评论和负面评论的数量,帮助用户更全面客观地了解人们对一个视频的评价[3]。
目前在学术界,文本情感分析的方式主要有三种,这三种方法技术路线不同,分别采用深度学习、情感词典与传统机器学习的方式与方法进行处理[4]。传统机器学习方法的优点在于方法容易实现且总体计算工作量小,但是缺点也很明显,需要专业人员完成技术特征的分析与提取,总体算法的泛化能力弱;采用情感词典的方式进行实现,主要优点在于方法实现简单,但是总体需要耗费大量物力人力来完成整个情感词典的构建。以此方式能够看出传统的机器学习方法与情感词典都需要花费大的人力与物力完成分析与计算过程。而基于深度学习的方法能够有效弥补这两种方法的不足,对整个特征进行自动提取并加以分析与处理,有效提升整个本文情感分析的准确性。
2 关键技术
2.1 Python 爬虫
目前常用的网络爬虫方式为聚焦爬虫[5],第一步需要设置爬虫的主题,在这个基础之上与主题无关的信息不被抓取,而保留整个链接之中有用的信息,接着根据一定的搜索策略寻找下一个链接。和通用爬虫相比,聚焦爬虫极大地节省了硬件和网络资源,并且增加链接评价模块和内容评价模块,评价的重要性不同,链接的访问顺序也不同。
2.2 BERT模型
1)BERT简介
在整个语言特征模型的处理之中[6],目前常用的模型为BERT,这个模型的全称为Bidirectional Encod?er Representation from Transformers,此模型主要特点在于采用新的MLM 方法进行语言表征的分析与处理。这样的处理方式与以往采用单一或者将两个语言模型进行简单的拼接有着本质的差异。
2)BERT优点
在整个训练词向量的处理之中,以往采用的方式主要是GloVe方法或者Word2Vec方法,这些方法是静态编码的处理方式,若是在不同的上下文环境处理之中,即使这个单词是单一的,此时这个模型对于语义的处理也是不同,准确率有待提升。
对训练词向量采用BERT模型的时候,整个预训练的处理采用MLM双向Transformers模型进行,主要工作目标是生成双向的语言表征。这个处理是深层的,采用预处理方式训练之后,需要增加一个输出层进行处理,能够有效提升整个词语的分类处理,整个过程之中并不需要对总体结构进行修改与处理。
3)BERT处理过程
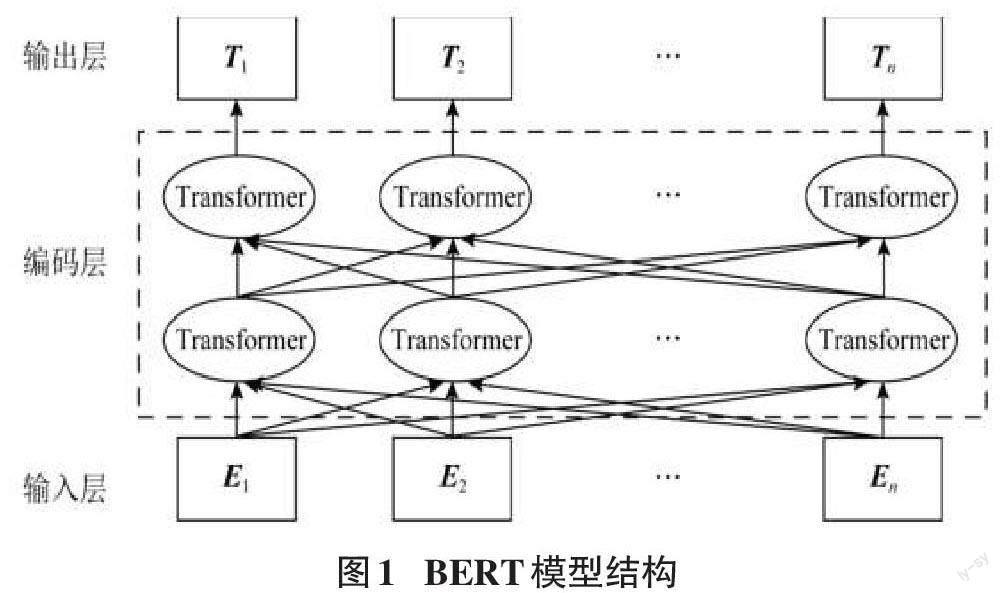
在整个BERT模型的分析与处理之中,其主要工作目标是完成语言模型的训练与处理操作,其在以往传统的方法之中进行了处理,其主要作用是确定句子语义之间的相互与处理,整个模型对应的处理结构如图1所示。
在整个BERT的分析与处理之中,整个模型架构分为输出层、编码层与输入层三层的方式进行处理,在这个模型之中,若是句子的意思相近,则其在空间之中的距离是相近的,整个对文字理解与句子之间的向量操作是类似的。
BERT模型的处理之中,整个输入分为三个部分,第一部分是位置向量;第二部分是分段向量;第三部分是词向量,这三种向量主要针对词语的三个方面进行处理,位置向量主要的作用是确定词语的位置,这个词语的开头与结尾使用CLS、SEP进行标记;对当前词语的编码主要通过词向量进行标注,词语在整个句子之中的位置通过分段向量来表示。在整个BERT模型的处理之中,关键核心的部分为双向Transformer编码层,这一部分主要的作用是对语言之中的特征进行提取与分析,这一个操作主要采用的是Encoder特征抽取器,特征抽取器主要的结构示意图如图2所示。
从图2整个Encoder的结构示意图中可以看出,其主要包括多个处理部分,如前馈神经网络、求和与归一化、自注意力处理机制等内容。整个特征抽取器处理的重要部分就是这个自注意力的管理机制,其能够去除整个距离限制的影响因素,而主要考虑词语之间的关系,整个处理机制效率高,针对上百个词语也能够快速完成词语上下文、左右文等方面关系的分析挖掘与双向标志。
3 业务需求分析
在整个模型的实验与分析之中,第一步主要的任务是将模型的程序进行实现,主要通过程序框图的方式进行展现,对整个系统实现流程进行阐述,以此来给出用户登录系统之后进行情感分析算法的运行与处理,并将最后的处理结果进行展现。详细系统的处理流程如图3所示。
程序框图是进行程序设计的最基本依据。系统开始先对用户是否已有账号进行判断,没有账号则进行注册,再进行登陆,检测到现有账号则直接登录,接着用户输入BV号,系统进行预测,向用户返回结果。在整个程序的处理之中,从BERT模型的分析之中能够看出,其关键处理部分是自身的注意力机制,具体此机制的示意图如图4所示。
在整个注意力机制的处理之中,其主要输入的数据信息来源于BLSTM层,后者的输出相当于注意力层的输入,后续需要对这些不同的词向量进行赋权操作,整个权值的大小与情感极性的分类息息相关,以此完成最终分类的确定,后续需要完成的处理为soft?max归一化的操作。
4 模型实验与分析
4.1 深度学习过程
1)实验环境
对整个模型的程序流程处理过程阐述过后,后续需要对整个过程进行实现,第一步需要完成模型实验环境的配置,具体配置信息如表1。
在整个环境的配置处理之中,主要采用的开发环境为IDEA,主要采用的开发语言为Java,以此完成整个模型的处理操作。
2)数据集
数据集为chnsenticorp中文情感分析评论语料。chnsenticorp分为四类:
ChnSentiCorp_htl_ba_2000:2000 条视频评论re?view,label均衡。
ChnSentiCorp_htl_ba_4000:4000 條视频评论re?view,label均衡。
ChnSentiCorp_htl_ba_6000:6000 条视频评论re?view,label均衡。
ChnSentiCorp_htl_unba_10000:7000条,只有pos。
3)评价指标
本文实验效果的评价指标为准确率Acc,在整个模型的处理过程之中,需要完成这些视频评论的分析与处理,需要确定整个评论过程之中的积极评论、消极评论与中性评论的内容,并将这些评论数量在整个评论过程之中对应的比例进行阐述。
4)数据预处理
每一段评论都单独在一个txt文件中,首先将其整合在一个txt文件中,每条评论占一行,再人工对每条评论进行标注,标签-1表示负面文本,标签0表示中性文本,标签1表示正面文本,总共标注约2000条,将其中约200条提出作为验证集,训练集:验证集=9:1,然后将训练集和验证集文件转化成tsv格式。
5)BERT模型处理过程
BERT模型代码分为几个部分:classifier.py开始固定种子并进行微调训练,configs.py确定了参数的设置,其中包括训练集和验证集的读取路径、随机种子数,确定了batch_size=8,learning_rate=1e-05,epoch=5,dropout=0.3等超参数设置,model.py负责将BERT模型的输出,一个768维的张量转化为3维的输出,代表了评论属于正面评论、中性评论、负面评论的可能性,read_data.py负责读取数据,test_code.py负责将测试用的数据代入模型运行得出结果,检测模型的准确率。
4.2 模型训练结果
1)处理结果模型训练后会生成一个json 文件,记录训练结果。
{"micro/precision": 0.95, "micro/recall": 0.95, "mi?cro/f1": 0.9500000000000001, "macro/precision": 0.9340801538006507, "macro/recall": 0.8945502053004852,"macro/f1": 0.9121639784946236, "samples/precision":0.95, "samples/recall": 0.95, "samples/f1": 0.95, "accu?racy": 0.95, "labels/f1": {" -1": 0.96875, "0":0.7999999999999999, "1": 0.967741935483871}, "la?bels/precision": {" -1": 0.9489795918367347, "0":0.875, "1": 0.9782608695652174}, "labels/recall": {" -1": 0.9893617021276596, "0": 0.7368421052631579, "1": 0.9574468085106383}, "loss": 0.6011847257614136}
其中可以看到模型准确率为95%,判断负面文本的概率是98.93%,正面文本的概率是95.74%,中性文本的概率为73.68%。
2)模型算法分析
在整个算法的分析过程之中,为了验证整个处理模型的准确性,进行实验的分析与对比,整个实验分为两种:第一个实验需要完成不同云联模型的对比实验;第二个实验需要将本系统采用的BERT实现的方法与其他方法进行分析与对比。
在第一个实验的处理之中,由前文可以了解,目前语言的预训练采用的方法有BERT、GloVe、Word2Vec,这些不同的训练模型在针对同一个任务进行处理的时候,对这些实验进行分析与对比,同时记录每一个训练模型的实验结果,这些结果如表2所示。
从表2可以看出,将三者的处理结果进行对比,总体BERT模型在整个处理过程之中能够对词语的上下文进行提炼与管理,总体感情分类任务处理的效率与准确率会更高。为了确定整个BERT模型处理的准确性,需要对其文本情感分析有效性进行确认,核心的工作内容是完成准确率的计算,具体计算的结果如表3所示。
从中能够看出本文采用的BERT方法相比机器学习与RNN等方法来说,总体准确率较高,具备良好的处理效果。
5 结论
虽然评论数据仅限制在了bilibili视频平台,但仍然有众多的视频分类包括音乐、舞蹈、游戏、知识、运动、生活等,这需要庞大的数据集进行训练,而目前的数据集并没有达到要求,也因此提供了管理员更新深度学习模型的功能,希望之后能收集到足够多的数据进行训练。
每个视频平台的前端页面结构不同,爬取策略也会不同。为了方便起见,该系统目前仅限制在bilibili 视频平台进行爬取,希望之后可以针对不同的视频平台都可以进行视频评论的获取。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
成都医学院学报(2021年2期)2021-07-19
数学小灵通(1-2年级)(2021年4期)2021-06-09
大众健康(2021年6期)2021-06-08
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
数学物理学报(2020年2期)2020-06-02
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
光学精密工程(2016年6期)2016-11-07
核科学与工程(2015年4期)2015-09-26
