
神经网络中梯度消失的解决办法
2023-06-03 18:04李文
电脑知识与技术 2023年10期
关键词:神经网络
李文
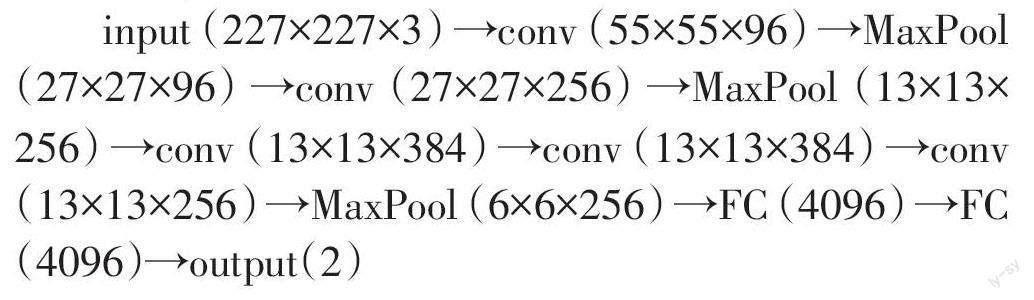
关键词:神经网络;梯度消失;激活函数;BN 层
中图分类号:TP183 文献标识码:A
文章编号:1009-3044(2023)10-0019-03
1 神经元与神经网络
1.1引言
神经元是人体神经系统的基本组成单位,由细胞体和突触组成,突触又分为树突和轴突两种,这两种突触的形状和功能大不相同。树突主要是用来接收外界的信号,所以比较短而且分支多,而轴突则与轴突截然不同,形状较长而且分支少,主要用途是传递信号。人体中大约有上百亿个神经元,这些功能和形状各不相同的神经元共同组成了人体的神经系统。一个神经元可以同时接收其他多个神经元传来的信息,还能通过突触将信息传递给相邻的神经元,图1为人体中神经元的示意图。
1.2人工神經网络模型
1.2.1神经元模型
1943年,麦卡洛克和皮茨提出“似脑机器”(mind?like machine)的思想,建立了MP模型,提出了神经元的形式化数学描述和网络构造方法,开创了人工神经网络研究的时代。
人工神经网络是由一个个的神经元连接组成的。图2为一个神经元模型。该神经元有多个输入(x1、x2、x3、x4...)和一个输出(t),同时,每个输入都有一个权重wi,每个权重各不相同。神经元的作用就是将输入加权求和,然后再加上偏执量b,最后再经过激活函数,就能够得到神经元的输出[1]。数学表达式为:
1.2.2人工神经网络模型
人工神经网络与人类神经系统相似,也是由大量神经元组成。其中每个神经元都存在状态变量ai,神经元i 到神经元j 之间的连接系数为wi。图3为一个简单的神经网络模型。
图3中的神经网络共有3层,其中第一层是输入层,用来为网络提供数据,第二层被称作隐藏层,隐藏层的深度是可以改变的,根据隐藏层的深度也可以将神经网络分为浅层网络和深度网络。最后一层是输出层。在网络中数据是单向流动的,并且同一层的神经元之间是没有连接的。如图3所示,将第i 层的激活值记为a(i),第i 到i+1 层的连接权重记为w(i),激活函数记为f(),第i 层神经元的偏置记为θ(i),则对于图3中的隐藏层来说,激活值分别为:
3 出现问题及解决方案
神经网络训练过程中梯度消失的问题被称作“梯度弥散”。梯度弥散会导致神经网络中靠近输出层的神经元参数更新较快,而靠近输入层的神经元由于梯度的消失,无法得到更新,参数几乎和初始值一样。产生梯度弥散最主要的原因就是模型中用的激活函数是“饱和”函数,如sigmoid函数。为了避免这一问题,可以采用非饱和的函数作为激活函数。比如relu。但是relu在输入小于0的时候,输出也为0,造成某些神经元无法被激活,参数无法更新。考虑这些问题之后,决定用改进后的leaky-relu函数来代替relu作为激活函数,这样既可以解决梯度消失的问题,也可以避免出现在输入小于0时,某些神经元无法被激活的问题,使所有神经元都能够参与训练[5]。
另外,还有一种办法可以避免梯度弥散,那就是加入BN层。BN层与卷积层和池化层一样,可以视为单独的一层,通常放在激活函数前,将进行线性变换前的激活输入值进行归一化处理。每一层的输入随着深度的增加,其分布也会逐渐偏移,落入激活函数的饱和区内,造成梯度消失,而Bn层能将每一层的激活输入值变换为均值为0,方差为1的标准分布,避免进入饱和区,同时由于输入落在激活函数的敏感区域[6],梯度大,所以收敛加快,网络训练也能更快完成。
4 实验过程及结果
实验采用3 000张猫和狗的图片作为训练数据集对模型进行训练,1 000张图片作为测试数据集对模型进行识别正确率的计算。采用的cnn网络模型以AlexNet为基础,将激活函数依次更换为sigmoid、tanh、relu、leaky-relu函数,模型结构为:
输入的图片是大小为227×227的RGB彩色图像,输出层一共有两个单元,分别代表猫和狗两个类别。
实验首先将sigmoid、tanh、relu、leaky-relu依次作为激活函数构建模型,然后对模型进行50次训练,最后用测试数据进行分类,统计分类的正确率,绘制出折线图。
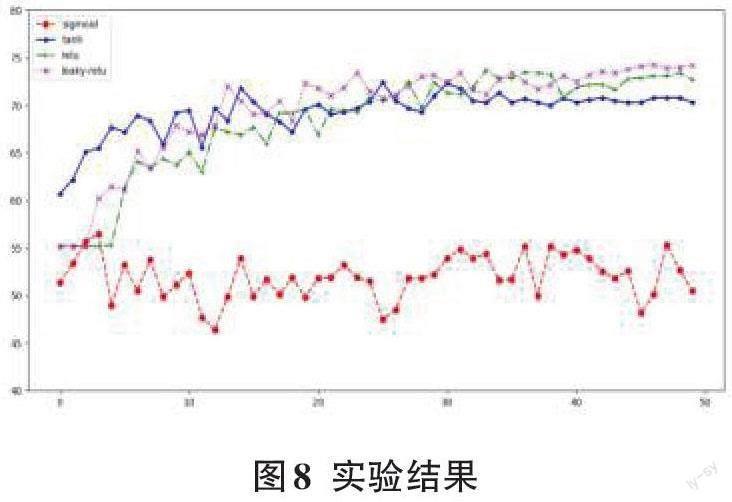
图8是由同一模型采用四种不同的激活函数(sig?moid、tanh、relu、leaky-relu)训练后,对测试数据集进行分类识别的正确率,横坐标代表的是模型的训练次数,纵坐标代表的是对测试数据进行分类的正确率。
从图8中可以看出,用sigmoid函数作为激活函数的模型正确率相较于其他函数来说相差很多,正确率仅有53%左右。不仅如此,模型的训练过程耗时也过长,并且不易收敛。而用tanh函数的模型的分类正确率则高了很多,最终能达到70%左右。采用relu函数的模型的分类正确率相较于tanh又有所提高,能够达到72%左右,并且relu函数较为简单,所以训练模型的时间也有所降低。而采用leaky-relu的模型的正确率达到了最高,leaky-relu函数作为对relu函数的改进,结合了relu的所有优点,理论上是在各方面都优于relu函数的,并且从图上也能看出来这一点。采用leaky-relu函数的模型分类正确率高,收敛速度快,在训练50次后正确率能够达到74%左右。
加入BN层的模型同样是以AlexNet为基础,在卷积层和激活函数之间添加BN层,将进行非线性变换的输入数据进行归一化处理,在模型进行50次训练之后对测试数据进行识别,计算识别的正确率。
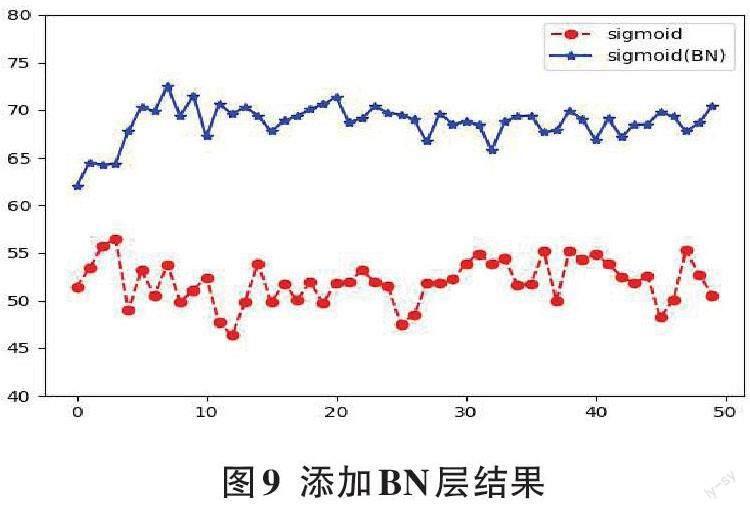
图9是在激活函数sigmoid之前添加BN层的模型对测试数据集图像进行识别后的正确率,横坐标代表的是模型的训练次数,纵坐标代表的是对测试数据进行分类的正确率。
从图9中可以看出,加入BN层后的模型相较于没有添加BN层的模型来说,正确率提高了很多,最后能够到达70%左右,sigmoid函数梯度消失的问题基本得到解决,并且收敛速度也有所提升。
总体来说,想要解决梯度消失问题,可以采用非饱和的激活函数,如leaky-relu,或者在激活函数之前添加BN层做归一化处理,这样就能够有效地解决梯度弥散的问题。
猜你喜欢
现代电力(2022年2期)2022-05-23
装备制造技术(2020年11期)2021-01-26
电子制作(2019年19期)2019-11-23
电子制作(2019年12期)2019-07-16
中国生物医学工程学报(2019年5期)2019-07-16
通信电源技术(2018年3期)2018-06-26
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
电测与仪表(2014年20期)2014-04-04
