
基于提示学习的文本隐式情感分类
2023-06-05 09:14王昱婷刘一伊张儒清范意兴郭嘉丰
山西大学学报(自然科学版) 2023年3期
王昱婷,刘一伊,张儒清*,范意兴,郭嘉丰
(1.中国科学院网络数据科学与技术重点实验室 中国科学院计算技术研究所,北京 100190;2.中国科学院大学,北京 100049)
0 引言
文本情感分析是自然语言处理的重要任务之一,自动挖掘社交媒体、用户评论等文本的情感倾向性具有重要的实用价值。随着监管不断加强,人们在各类社交媒体上的表达方式逐渐由直白向隐晦演进,互联网中隐晦情感的表达不断增多,为当前情感分析领域带来了巨大挑战。Russo 等[1]提出,隐式情感(implicit sentiment)表达是指在文中没有情感标记,但是仍然传递了人能捕捉到的明确的情感极性。在广泛研究的方面情感分类任务中就有大量的隐式情感存在。例如,在句子“这电池的寿命估计也就一个小时”中,没有任何情感词或观点词,但是从句子含义我们可以推断出,作者表达的是对电池寿命的负面情感。再如,“在我们吃饭的过程中,服务员来了三次让我们买单”,该评论陈述了一件客观事实,没有任何的情感词,但是从其内容可以推断作者想表达的是对服务态度的负面情感。
随着预训练语言模型(Pre-trained Language Models)的不断发展,其在诸多自然语言处理任务包括情感分析任务上[2-3]均取得了巨大的成功。然而,当前使用预训练语言模型进行情感分类的方法主要集中表现为利用预训练语言模型得到句子表示,微调下游模型[4]。此类方法往往在具有显式情感标记(如情感词,表征情感的表情符号等)的文本上表现良好,但不能很好地处理隐晦情感的问题,难以逾越隐式情感与显式情感之间的鸿沟。此外,使用预训练语言模型在分类任务上,微调还存在着下游任务的训练目标和语言模型的预训练目标不一致的问题,这会极大地限制下游任务对预训练语言模型中知识的利用。Li 等[5]提出了一种基于监督对比损失的重新预训练的方法,利用大量的情感评论语料库重新训练语言模型,此方法相比之前的模型在显式和隐式情感分类上均有较大提升。相比仅仅微调的方法,利用外部语料库重新预训练学习情感的方法可以更好地利用预训练语言模型中的知识,然而,重新预训练和后续微调这一整个流程的成本较高,且大规模语料库中可能存在噪声数据,对分类结果造成一定影响。
近几年,一种弥合预训练阶段和微调阶段训练目标的新的训练范式:提示学习(prompt learning)被提出。其主要思想是将下游任务的训练目标统一形式化成为掩码语言模型的预测问题,设计提示模板,与原输入句子相组合,并采用预训练语言模型来预测提示模板中被掩盖([MASK])的词,最后通过预测词与类别的对应关系确定分类任务最终预测的类别。提示学习作为一种简单有效的训练方法,已经在许多自然语言处理任务上取得了良好的效果[6-7],尤其在低资源情况下效果更加显著。
本文提出采用提示学习的方法解决隐式情感分类的问题。通过对提示学习中提示模板和标签词映射器的设计,更好地利用预训练语言模型中包含的大量知识。由于在提示模板中要预测的[MASK]的候选词均为显式情感词,提示学习的方法可以在直白情感和隐晦情感中架起桥梁,将隐式的情感显式化,从而得到更准确的隐式情感分类效果;此外,已有情感分类模型大多采用交叉熵损失,交叉熵损失对于“正面、中性、负面”三个类别是同等对待的,但是在三分类的情感任务中,不同情感标签之间的距离是有远近差异的,不能一视同仁。隐式情感不包含明显的情感词,多为客观事实表述,所以在隐式情感分类中,这种差异需要被强化。在隐式情感表达中,正负和中性的在句子表述上的差异不那么明显,导致正负面和中性在分类的时候很容易混淆,不易区分,因此,本论文还对损失函数进行扩展,设计了一种以不同情感标签间距离为依托的类别差异化损失函数,进一步提升情感分类的准确率。
本文在方面级情感分类标准数据集上进行大量实验,结果表明,使用提示学习可以有效提高隐式情感分类的效果;此外,在低资源设置下的实验也表明我们的模型在缺少大量标注数据的场景下依然能保证良好的情感分类效果。同时,引入类别差异化损失函数的设计,可以进一步提升隐式情感分类效果。
1 相关工作
本章主要从三个方面对相关工作进行介绍:方面情感分类,隐式情感以及模板学习。
1.1 方面情感分类
方面情感分类的方法主要分为传统基于规则和统计机器学习方法和基于深度神经网络的方法。本节主要介绍基于神经网络的方面情感分类方法。该类方法主要分为三个发展阶段:基于循环神经网络和注意力机制的方法,基于图神经网络的方法和基于知识增强的方法。
早期方面情感分类的方法主要基于长短时记忆网络[8](Long Short Term Memory)和注意力机制[9](Attention Mechanism)。一个句子中可能出现多个方面词,基于注意力机制的方法关键在于找寻句子中哪些词对方面词更重要[10-13]。
随着图神经网络的不断发展,许多方法提出结合语法树中的语法信息来更好地捕捉方面词与句子中其他部分的关系[4,14]。基于语法树和图神经网络的方法关键在于如何建图以及如何将语法树上点和边的信息与方面情感分类任务更好地结合。
方面情感分类的对象一般是评论数据,长度较短,可能包含的信息不够,因此有研究者提出利用大规模语料库或预训练语言模型作为外部知识增强方面情感分类的效果[2,15]。基于知识增强的方法关键在于如何选择有效的外部知识,如何将外部知识信息编码到模型结构中。上述模型在具有显式情感的文本上分类效果很好,但是均没有关注到隐式情感的问题。
1.2 隐式情感
目前关于隐式情感没有一个官方认可的定义,Liu 等[16]认为一个包含隐式情感的观点句通常是对客观事实的陈述,这样的客观句通常表达了一种理想的或不理想的事实。而Russo等[1]提出,隐式情感是指句子中不包含明显的情感标记,但是却清晰地传达了的情感倾向。总结来看,关于包含隐式情感的文本大家普遍共识的是,不含有显式情感词,但却表达了主观情感的事实陈述。
Chen 等[17]研究了观点对象和情感双重隐含的观点挖掘问题,并且构建了一个隐含观点的中文旅馆评论语料库,语料库标注了观点对象的类别和极性。Cai 等[18]提出了一个四元组抽取的新任务,专门处理隐式方面和隐式情感的问题。Li 等[5]提出了一种基于对比学习的预训练模型,通过引入大规模评论语料重新训练针对方面情感分类任务的语言模型。同时该论文还基于前人标注[19]的观点词对方面情感分类的两个标准数据集做了隐式情感的标注,如果句子中包含观点词那就标记为显式情感(explicit),反之则标记为隐式情感(implicit),该模型可以较好地处理隐式情感的分类问题,但是重新训练语言模型成本较高。
1.3 提示学习
随着GPT-3[20]的出现,提示学习作为一种新的预训练语言模型范式,受到了越来越多的关注。基于提示学习的方法在许多自然语言处理任务上都取得了良好的效果[6-7]。Schick等[7]提出了人工构建模板以及利用大规模无标注的外部语料库进行知识蒸馏的方法用于文档级情感分类任务。Hu 等[21]提出利用外部知识库来扩展分类任务的标签词映射器。Shin等[22]提出一种基于梯度指导的方法为下游任务自动构建提示模板。Li 等[23]提出将情感知识引入模板设计中,从而实现端到端的方面词、观点词和情感极性统一抽取。但是这些模型都没有关注到在隐式情感上的效果。
2 模型设计
本文提出的用于隐式情感分类的基于提示学习和标签差异化损失的模型(ImplicitPrompt)主要分为以下几部分:提示模板设计,标签词映射器和损失函数的设计。模型主要结构如图1 所示,对于方面情感分类任务来说,输入是句子和方面词,通过添加设计模板得到一个新的输入句子,输入中带有要预测的掩码标识符[MASK],将新的句子输入到预训练语言模型中,得到[MASK]位置关于整个词表上的概率分布,再通过标签词映射器定义的词表中的词和情感分类类别对应的关系,将标签词的概率转换成最终的类别概率,即可得到最终预测的类别。
2.1 提示模板设计
我们通过调研和实验选取了在情感分类任务中常用的提示模板,这些模板天然适配方面情感分类任务。原始输入x=(ssentence,saspect),其中输入句子为ssentence,输入方面为saspect,与模板进行组合后新的输入变为S(x)。提示模板设计如下所示:
2.2 标签词映射器
原始的输入x=(ssentence,saspect) 经过添加模板后得到新的输入S(x),再通过预训练语言模型M,可以得到[MASK]位置在整个词表V上的词概率分布PM([MASK]=v|S(x)),v∈V。需要借助标签词映射器处理该分布。标签词映射器首先要定义词表中哪些词是合适[MASK]位置的标签词,其次要定义标签词概率如何转化为最终的类别概率。
关于筛选哪些词是标签词,直接手工定义可能会造成选词有偏差的问题。为实现映射关系设计的全面性,本文借助广泛使用的情感词典[24],并结合情感标签,筛选出情感倾向明显的且主观性强的情感词。由于情感词典条数的限制,中性的情感词条数较少,最终选取了正面和负面各1000 条标签词,中性213 条。
Vy代表每个类别对应的标签词集合,其中y代表相应类别,在情感分类任务上y∈{positive,negative,neutral}。通过这些主观情感极其强烈的标签词,可以使得在隐式文本中的情感直白化。表1 展示了部分选取的标签词。

表1 部分标签词示例Table 1 Examples of label words
有了标签词集合后,我们需要定义标签词和类别的映射关系。为此对每个类所有标签词的概率取平均的方法得到最终对应的类别y的预测概率:
2.3 损失函数
本文模型的损失函数主要分为两部分:交叉熵损失和类别差异化损失函数。
2.3.1 交叉熵损失
交叉熵损失是为了保证大量显式情感文本基本的情感分类能力。在标签词映射器模块的最后得到了各个情感类别的预测概率P(),由此可以计算预测值与真实标签y之间的交叉熵损失:
2.3.2 类别差异化损失函数
在以往大部分情感分类的工作中,对于正负面和中性三者是同等对待的,但是从人对三个类别的理解上讲,正面和负面之间的距离要大于正面和中性或负面和中性的距离,也就是说,如果模型将正面的文本误分类成负面情感,要比误分类成中性情感的惩罚更多。这一现象在隐式情感中需要被提出并显式地解决。对于隐式情感来说,由于句子中多为陈述客观发生的事实,没有明显的直白的情感词,情感特征不明显,导致正负面和中性三类文本之间的差异更加不明显,更难以区分中性和正负面,为此,提出了类别差异化损失函数,类别差异化损失函数依托于多分类的合页损失,在样本数为1 的时候,类别差异化损失函数计算公式如下:
其中,C为类别总数,对于情感三分类来说C=3,在我们的训练数据中正面的类别标签是0,中性是1,负面是2。P()为预测的类别分数,y是真实类别标签,其中0 ≤y,i≤C-1,那么P()[y]代表y这一类的预测分数,P()[i]代表除了y以外的类别的预测分数。ms与mb分别代表针对不同标签差异化的两个边缘值。
我们的目标是使得正面和中立类的距离,比正面和负面的距离更近。因此,采用一小一大两个边缘值ms与mb,小边缘值ms负责控制类别差|y-i|≤1 的情况(即与中性相关的情况),也就是说,如果类别标签相差小,相应的惩罚也小;相反地,大边缘值mb负责控制类别差|y-i|>1 的情况(也就是将正面误分类为负面或反之的情况),这种情况惩罚要大一些。最终的模型损失是:
3 实验与分析
3.1 数据集
在带有隐式情感标签的SemEval 2014 任务4[25]的Restaurant 和Laptop 两个数据集上进行实验,这两个数据集的情感标签有三类:正面、中性和负面。两个数据集的统计信息如表2 所示。可以看出,这两个数据集中含隐式情感的数据均占有超过27%的比例,这充分说明了研究隐式情感分类是很有必要的。

表2 数据集统计信息Table 2 Statistics of datasets
3.2 基线模型
我们选取了四类模型作为ImplicitPrompt的基线模型,分别是:(1) 基于注意力机制的模型(ATAELSTM[11],IAN[26],RAM[13],MGAN[27]); (2) 基于图神经网络的模型(ASGCN[14],BiGCN[28],CDT[29],RGAT[4]); (3) 基于知识增强的模型(TransCap[30],SPDAug[31],BERT-SPC[32],CapsNet+BERT[33],BERT-PT[2],BERT-ADA[15],LCF-BERT[34],RGAT+BERT[4]); (4) 基于大规模语料库重新预训练的模型(TransEncAsp+SCAPT[5],BERTAsp+SCAPT[5])。
3.3 实现细节
在标准的有监督的设置下,利用整个数据集进行模板学习。对Restaurant 数据集,损失函数中的超参数设置分别是α=0.2,β=1,ms=1,mb=1,对Laptop 数据集,超参数设置分别是α=1,β=0.5,ms=1,mb=2。针对ms和mb的设置,由于原始多分类合页损失函数的边缘值默认为1,因此,首先在1 附近取值。通过设置不同偏大或偏小的ms和mb,验证得到在以上情况下实验结果是最佳的。在低资源设置下,为了兼顾类别平衡和评价需要,随机选取了6 条(正面2 条,分别是显式的正面情感1 条和隐式的正面情感一条,中性和负面以此类推),30 条(正面10 条,分别是显式的正面情感5 条,隐式的正面情感5 条,另外两类以此类推)和60 条。
本文提出的ImplicitPrompt 模型分别以BERT-base[32]和RoBERTa-base[35]作为骨干,实验结果选取隐式情感子集上准确率最高的那一组模板的结果。
3.4 实验结果
本部分我们主要回答以下几个问题:
1) ImplictPrompt 在标准的有监督的设置下效果如何?
2) ImplicitPrompt 在低资源设置下效果如何?
3) 类别差异化损失对模型效果有何影响?
3.4.1 标准监督设置下的实验结果
为了回答问题1,对比了ImplicitPrompt 与许多表现强劲的基线模型,实验结果如表3 所示。可以观察到:1)利用预训练语言模型中的知识做微调的方法普遍比基于图神经网络和注意力机制的方法效果好,不论是在整体的准确率和宏平均还是在隐式的准确率上均有较大提升。这说明了微调预训练语言模型对模型效果的提升很有效。2) ImplicitPrompt 比基于知识增强的微调预训练语言模型的方法效果好。尤其是在隐式准确率上有大幅度地提升。这说明通过模板尤其是在标签词映射器中引入了强主观性的显式情感词典可以有效弥合隐式情感和显式情感之间的鸿沟。3) ImplicitPrompt 在整体数据集上准确率比不过基于大规模语料库重新预训练的模型BERTAsp+SCAPT,但是在隐式数据集上的准确率要超过BERTAsp+SCAPT。可能有以下原因:首先,SCAPT 是依赖大规模外部评论语料库重新预训练的语言模型,是完全针对方面情感分析这个任务训练的,因此重新预训练之后的模型在方面情感分类这个任务上效果有很大地提升,同时在整体数据集,显式和隐式数据集上均有大幅提升,但是本文模型依赖的是通用的预训练语言模型,没有进行重新训练,而且模型设计主要是为了提升在隐式数据集上的分类效果,而非提升方面情感分类这个任务的效果,所以整体上效果不如BERTAsp+SCAPT 模型。其次,可以看出,模型在隐式数据集上表现得更好,这也充分说明了本文模型设计更契合隐式情感分类。最后,我们认为,ImplicitPrompt 模型比SCAPT 模型要简单易行,不需要重新预训练,只需要简单的模板设计即可取得不错的分类效果。

表3 标准有监督设置下的准确率(Acc.),宏平均(Macro F1),显式子集上的准确率(Explicit Acc.)和隐式子集上的准确率(Implicit Acc.)。其中模型右上角加 “*” 的数据来源于Li等[5],其余数据来自我们复现的模型,最好的结果加粗表示,第二好的结果下划线表示Table 3 Accuracy, Macro F1, explicit accuracy, and implicit accuracy under standard supervised settings.The results with "*" in the upper right corner of the model name come from Li et al[5].And the rest results come from our reimplementation of each model.The best results are bold, and the second-best results are underlined
通过分析本文模型的两个变形:Implicit-Prompt-BERT 和ImplicitPrompt-RoBERTa 的实验结果,可以得出以下结论:1) 本文模型是可以扩展到多个通用的预训练语言模型上的。2) RoBERTa 比BERT 做骨干的效果更好,原因可能是,BERT 的预训练任务有两个,分别是掩码词预测和下句预测,而RoBERTa 模型的预训练任务只有掩码词预测,这与提示学习的任务更契合,因此RoBERTa 的效果更好。
3.4.2 低资源设置下的实验结果
在现实场景中,人工标注大量的数据用于微调预训练模型不仅耗费时间还耗费劳力。为了回答问题2,选取了基于知识增强的微调预训练语言模型中表现较好的RGAT-BERT 与ImplicitPrompt-BERT 作比较,分别在低资源设置下进行了实验,在两个数据集上的实验结果如图2 所示,图中横坐标代表训练集的数据量,纵坐标代表隐式情感分类的准确率。
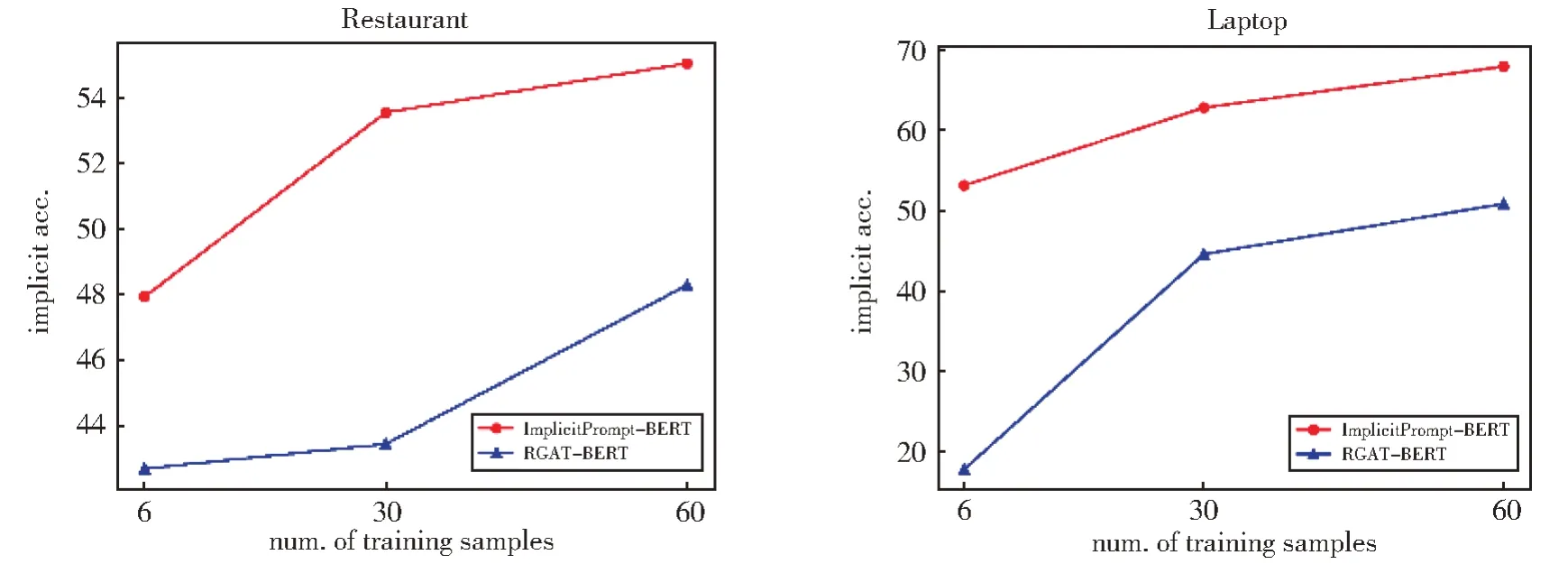
图2 低资源设置下的隐式分类准确率Fig.2 Implicit Acc.under low-resource settings
通过观察两个折线图我们可以得出以下结论:1) 不管是微调预训练模型(RGAT-BERT)还是我们的提示学习模型(ImplicitPrompt-BERT),随着数据量的增加,在隐式情感分类上的准确率都在不断地提升。2) Implicit-Prompt-BERT 模型一直稳定地比微调模型效果好。3) 但是随着数据量的增加,这二者之间的差异在不断地缩小,说明在小样本的情况下ImplicitPrompt 的效果更显著。
3.4.3 消融实验
为了回答问题3 和验证本文类别差异化损失函数的有效性,在两个数据集上进行了消融实验,结果如表4 所示。可以看出,我们的模型在不加类别差异化损失函数的情况下在两个数据集上的隐式准确率均有所下降,尤其是在Laptop 数据集上。这也说明了考虑类别之间的差异可以更好地刻画正面负面和中性三种情感,尤其是在隐式数据集上,隐式数据集中的情感往往隐晦,不易识别,正负面和中性的情感也不那么显著,通过类别差异化损失函数,可以将隐式情感中的正负和中性情感的差异刻画得更明显,从而提升隐式情感分类的效果。
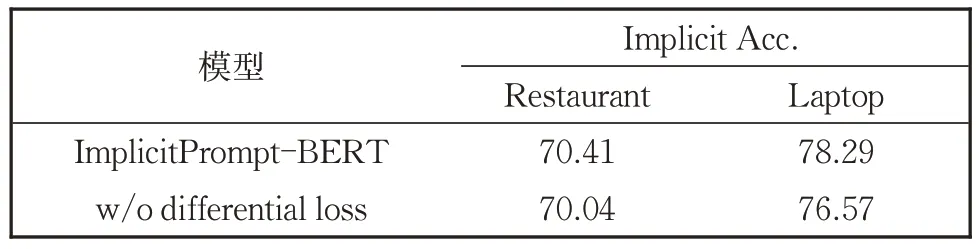
表4 消融实验结果Table 4 Implicit accuracy of ablation study
4 结论
本文提出了一种基于模板学习和类别差异化损失的隐式情感分类方法。通过模板和标签词映射器的设计,利用显式的情感词将隐式的情感直白化;同时在正负、中性三分类的情感分类中,将不同情感类别之间的差异进行区别对待,提出类别差异化损失,进一步地使得隐式情感中的情感差异更明显。通过在标准的监督学习的设置下和低资源小样本的设置下的实验结果均表明,我们提出的ImplicitPrompt 方法可以显著提升隐式情感分类的效果,更重要的是,我们的方法不需要重新训练预训练语言模型,只需要简单的模板和预测就可以完成分类,简单易操作。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
公民与法治(2016年10期)2016-05-17
新校长(2016年8期)2016-01-10
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
计算机工程(2015年8期)2015-07-03
读者·校园版(2015年19期)2015-05-14
商事法论集(2014年1期)2014-06-27
