
基于PCA-GA-LSSVMR的高速公路沥青路面行驶质量预测
2023-07-14 14:44曹雪娟李小宇吴博文郝增恒
重庆交通大学学报(自然科学版) 2023年5期
曹雪娟,李小宇,吴博文,郝增恒
(1.重庆交通大学 材料科学与工程学院,重庆 400074;2.重庆交通大学 土木工程学院,重庆 400074;3.重庆市智翔铺道技术工程有限公司,重庆 400067)
0 引 言
随着运营时间不断增长和运输量急剧变化,高速公路存在的路面性能变化规律难以掌握、养护时机难以确定、养护成本居高不下等问题逐渐显露,对沥青路面性能进行有效预测分析是实现道路科学养护的关键环节[1]。其中,路面行驶质量指数IRQ作为沥青路面性能的一项重要指标,可以直观地反映路面驾乘感受,并对行车安全产生一定影响。
20世纪60年代,美国国家公路与运输协会基于对路面性能预测的实际需求,提出了路面性能预测的思想;20世纪90年代,A.A.BUTT等[2]首次提出了MARKOV预测模型;K.D. JOHNSON等[3]使用3个指标并利用经验模型对路面性能进行预测。随着对路面性能预测研究的逐渐深入,多种研究方法被广泛应用,预测精度逐步提高。K.A.ABAZA等[4]提出了两个基于马尔可夫的经验模型来预测与修复路面相关的过渡概率,模型的可靠性较高,能够准确测算过度慨率; M.I.HOSSAIN等[5]基于神经网络对柔性路面的平整度指数进行预测,建立了平整度指数IIR预测模型。A.BIANCHINI等[6]考虑了影响因素的不确定性,采用模糊数学处理之后的影响变量(如气候、表面曲率指数、弯沉、车辙深度、交通量)作为神经网络的输入变量,PSI作为输出变量,得到预测精度优于线性回归模型的模糊神经网络预测模型。
我国学者则主要结合国内沥青路面的实际情况,对路面性能进行了一定的研究。较为成熟的有灰色预测模型[7-8]、机器学习模型[9-12]、统计学模型[13]和机理模型[14]。其中,灰色预测模型过于依赖初始值的设定,具有一定的缺陷;机器学习模型虽然可以根据路面性能指标监测数据预测路面性能变化趋势,但也存在模型参数设置需要经验累积、模型运行速度慢、预测精度低等问题;统计学模型的主要问题在于,沥青路面每年的养护情况与交通量变化情况差异巨大,无法给出高精度的预测结果;由于沥青路面性能受多种因素共同影响,且路面性能的变化过程是一个多维度复杂过程,而机理模型无法对每种变化过程有针对性地进行模拟,导致模型的普适性不足[15]。
笔者提出的基于PCA-GA-LSSVMR组合算法的高速公路沥青路面行驶质量预测模型,首先采用主成分分析(principal component analysis, PCA)法提取数据有效信息,然后引入遗传算法(genetic algorithm, GA)对模型参数寻优,最后通过训练最小二乘支持向量机回归(least squares support vector machine regression, LSSVMR)模型,有效解决了单一模型存在的精度低、运行速度慢等问题。为验证模型的有效性与精确性,将其与SVMR模型、PCA-LSSVMR模型进行预测精度对比。实验结果表明,该模型预测结果与实际沥青路面行驶质量情况基本吻合,为沥青路面行驶质量预测提供了一种有效的方法。
1 算法基本原理
1.1 PCA算法基本原理
PCA算法能够将具有一定相关性的指标进行线性变换,形成一组线性无关的主成分综合指标,根据主成分累计贡献率选取贡献率大的主成分代替原指标,实现对数据的降维处理,提高运算速率[16]。
PCA基本模型如式(1)[17-18]:
X=LPT+Pe
(1)
式中:X为输入矩阵,即原始数据矩阵;L为得分矩阵,即主成分矩阵;P为加载矩阵,表征每个变量的贡献度;Pe为残差矩阵,表征PCA算法模型未能收容的变量。
PCA算法的基本计算过程如下:
1)取样本数据集均值向量:
(2)
式中:u为均值向量;m为样本总数;Xi为第i个样本数据。
2)样本数据中心化:
(3)
3)构建协方差矩阵V:
(4)
4)对矩阵V进行特征分解,求特征值和特征向量Ui。
5)根据贡献率大小对特征值进行排序,取前k个特征值Λ=diag(λ1,λ2,…,λk)及其对应的特征向量集U=[U1,U2,…,Ui,…,Uk],则要提取的主成分Lk如式(5):
(5)
1.2 GA算法基本原理
GA算法是一种通过模拟自然进化过程寻找最优解的方法。该算法具有鲁棒性强、适用范围广等优点,并具有一定的并行性与较强的全局寻优能力,广泛应用于组合优化问题中。
GA算法的设计步骤如下:
Step1生成初始候选种群(初始种群)。
Step2利用复制操作使亲代与后代相互复制,为后面交叉、变异做准备。
Step3将所有个体依据交叉概率进行随机交叉操作,得到新的种群。
Step4比较候选种群中的个体适应度,如果达到算法设计要求,则退出遗传算法,否则跳转至Step2继续执行。
1.3 LSSVMR算法基本原理
LSSVMR采用最小二乘线性系统作为损失函数,代替了SVMR的二次规划方法,使得运算速度显著提升。对于样本数据集M={(xi,yi)|i=1,2,…,n},采用LSSVMR进行函数估计,由KKT(Karush Kuhm Tuchker)条件[19],得到LSSVMR函数:
(6)
式中:αi为拉格朗日算子;K(xi,xi+1)为核函数;K(xi,xi+1)=φ(xi)φ(xi+1),其中,φ(xi)为输入空间到特征空间的映射。
2 基于PCA-GA-LSSVMR的沥青路面行驶质量预测模型
PCA-GA-LSSVMR模型的建模思想是利用PCA算法与GA算法,优化模型参数,然后利用LSSVMR算法,将反映行驶质量的数据集(各面层厚度、养护时间、路龄等)映射到高维特征空间中,对行驶质量进行线性回归,从而做出预测。笔者提出的基于PCA-GA-LSSVMR的沥青路面行驶质量预测模型建模流程如图1,具体预测步骤如下:① 数据预处理;② 行驶质量因素主成分分析;③ 利用GA算法优化选择模型参数;④ 建立LSSVMR训练模型。

图1 PCA-GA-LSSVMR算法流程Fig.1 PCA-GA-LSSVMR algorithm flow chart
2.1 数据预处理
在数据收集阶段,笔者共采集了四川省2014—2019年23条高速公路的施工建造数据、环境气候数据、交通荷载数据、养护历史数据、路面性能检测数据这五大类数据,共计25种。
2.1.1 数据指标选择
为简化指标数量,加快后期模型计算速度,首先利用Boosting分支的XGBoost回归算法对路面行驶质量影响因素进行分析,如图2。

图2 路面行驶质量影响因素重要性分析Fig.2 Importance analysis of influencing factors of pavement driving quality
从25类路面性能特征数据中挖掘出15类对路面行驶质量有较大影响的因素(表1)。其中,上面层材料类型、年均交通量、路龄、上面层厚度、养护时间等因素重要性得分较高,表明此类因数对路面行驶质量有较大影响,且年均交通量的重要性得分远高于其他因素,表明年均交通量对路面行驶质量的影响程度最大;同时基层材料类型、基层厚度、路基宽度、底基层材料类型的重要性得分非常低,表明此类因数对路面行驶质量的影响非常小。

表1 行驶质量数据指标
由于数据类别众多,且每一类别都包含23条高速公路6 a的相关数据,文中仅展示路龄及历史IRQ的部分数据(表2),以说明IRQ随路龄的变化趋势。

表2 23 条高速公路2014—2019年路龄及IRQ部分检测数据
在输出变量的选择上,选取IRQ作为模型输出变量,以表征路面行驶质量。
2.1.2 数据异常值处理
为降低异常数据对模型精确性的干扰,减少LSSVMR训练模型的迭代次数,加快计算效率,对数据集数据异常值进行处理。
施工建造数据、环境气候数据、交通荷载数据、养护历史数据中的15类影响因素数据与相关资料数据一致,可认定其数据为正常值,仅对IRQ数据进行异常值处理。
JTG 5210—2018《公路技术状况评定标准》指出,路面性能指标检测得分在0~100之间,数值越大表明路面性能越好,超过上限100或低于下限0的数据可以明确划分为异常值。
最终统计出异常数据共计75个,占数据总量的1.5%,由于异常值占比较小,故直接将其剔除。
2.1.3 数据归一化处理
为消除不同指标之间量纲的影响,使各指标处于同一数量级,采用min-max标准化方法对样本集进行归一化处理[20],具体可表示为:
(7)
式中:pg为归一化后的数据;po为路用数据样本集的原始数据。
2.2 路面行驶质量影响因素主成分分析
通过分析可知,影响路面行驶质量的因素主要有年均交通量、路龄、年均气温、养护时间等。为精简模型的输入变量,加快计算速度,采用PCA算法将15种路面行驶质量影响因素转化为少数几个主成分因素,新的主成分因素在包含原数据大部分信息的同时,降低了数据中的信息重复率,因此可以提高模型工作效率,保证预测精度。
PCA算法应用与分析过程如下:
1)在Rstudio软件中,提取程序包psych,利用函数princomp构建主成分分析算法,对15种路面行驶质量相关特征数据进行主成分分析, 分析结果如图3。
2)通过对图4分析可知,C8之后图线斜率变化趋于平稳,而C9与C10之间的线段斜率近乎为0,说明C1~C8包含了原始数据的大部分信息,因此可初步选定前8个主成分因素代替15种路面行驶质量影响因素。为进一步验证C1~C8的可靠性,需进一步计算每个主成分的个体贡献率,计算结果如表3。

表3 主成分特征贡献率
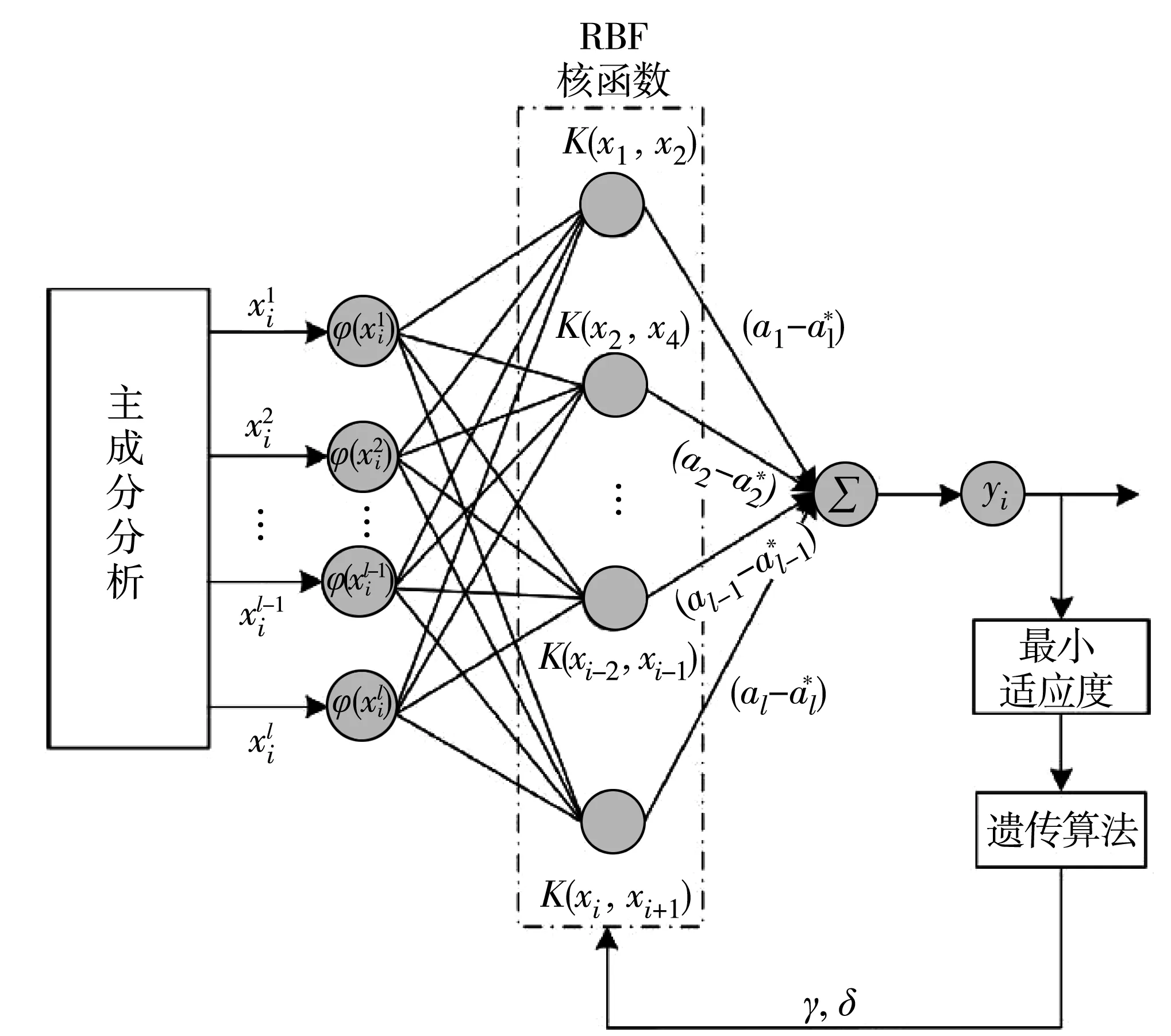
图4 PCA-GA-LSSVMR网络结构Fig.4 PCA-GA-LSSVMR network structure
3)分析表3可知,C1~C8已包含原始数据集中90%以上的信息。
4)综合图2与表3,可选定C1~C8这8个主成分对LSSVMR模型进行训练。
2.3 优化模型参数
LSSVMR算法的效率与性能由惩罚系数γ和核函数宽度δ等决定。惩罚系数γ是权衡损失与分类间隔的权重系数,可以保证模型计算结果的客观性与稳定性;核函数宽度δ反映了样本数据集在高维特征空间中的复杂程度。为进一步提高模型预测精度,笔者选用GA算法对γ与δ在全局范围内进行寻优计算。GA算法能够通过模拟自然选择过程寻找最优解,具有鲁棒性强、适用范围广等优点,具备一定的并行性与较强的全局寻优能力,广泛应用于组合优化问题中[21]。
由于均方差函数能够较好地反映LSSVMR的回归性能,所以选择均方差函数作为GA算法的适应度函数,函数表达式如式(8):
(8)

还有安南(越南)自古以来就使用中国钱币。最早开始铸钱是在丁朝大瞿越大平年间(970),仿照中国宋朝方孔圆钱的形制铸成的,钱文多有宋体之意。从黎仁宗延宁起,到昭宗光绍年间(1454—1521),则是安南铸钱的成熟时期,无论铸钱技术,还是工艺水平,都达到了较高水平。光绍以后,安南古钱的制作便逐步走向下坡。安南曾经大量仿制过中国古钱,与中国铜钱同名的有15种。
计算得到惩罚系数γ=0.901,核函数宽度δ=0.019 5。
2.4 建立LSSVMR模型
按照以下步骤建立沥青路面行驶质量LSSVMR训练模型:
1)选定合适的样本数据集,并将其分为训练集与测试集。将优选后的年均交通量、路龄、年均气温、养护时间等15种路面行驶质量影响因素指标进行主成分分析,将提取出的主成分作为预测模型的输入变量,路面行驶质量指数IRQ作为模型的输出变量。
2)利用核函数训练模型。由于径向基核函数(RBF)处理多元问题具有效率高、非线性映射能力强、依赖参数少等优点[22],笔者选用RBF对LSSVMR模型进行训练。RBF表达式如式(9):
(9)
3)利用GA算法对LSSVMR模型参数寻优。基于GA算法的全局寻优能力,优化惩罚系数γ和核函数宽度δ,以优化模型计算能力,提高预测结果的准确度。
4)确定回归函数f(xi)。通过训练LSSVMR模型,得到回归函数如式(10):
(10)
基于PCA算法、GA算法和LSSVMR算法构建的网络结构如图4。
2.5 模型评估
为验证模型在沥青路面行驶质量预测方面的可行性与有效性,分别选取SVMR模型、PCA-LSSVMR模型与所建PCA-GA-LSSVMR模型进行对比。2 种对比模型均选取15类路面行驶质量影响因素作为模型的输入变量,IRQ数据集作为输出变量,构建出包含5 000组数据的建模数据集。为避免模型在学习过程中出现过拟合现象,选择将15类数据构成的数据集按照7∶3 分为包含3 500组数据的训练集和包含1 500组数据的测试集,分别用来训练和检验模型。
在Rstudio软件中通过3 500组训练集数据分别对SVMR模型、PCA-LSSVMR模型与PCA-GA-LSSVMR模型进行训练,训练过程如图5。
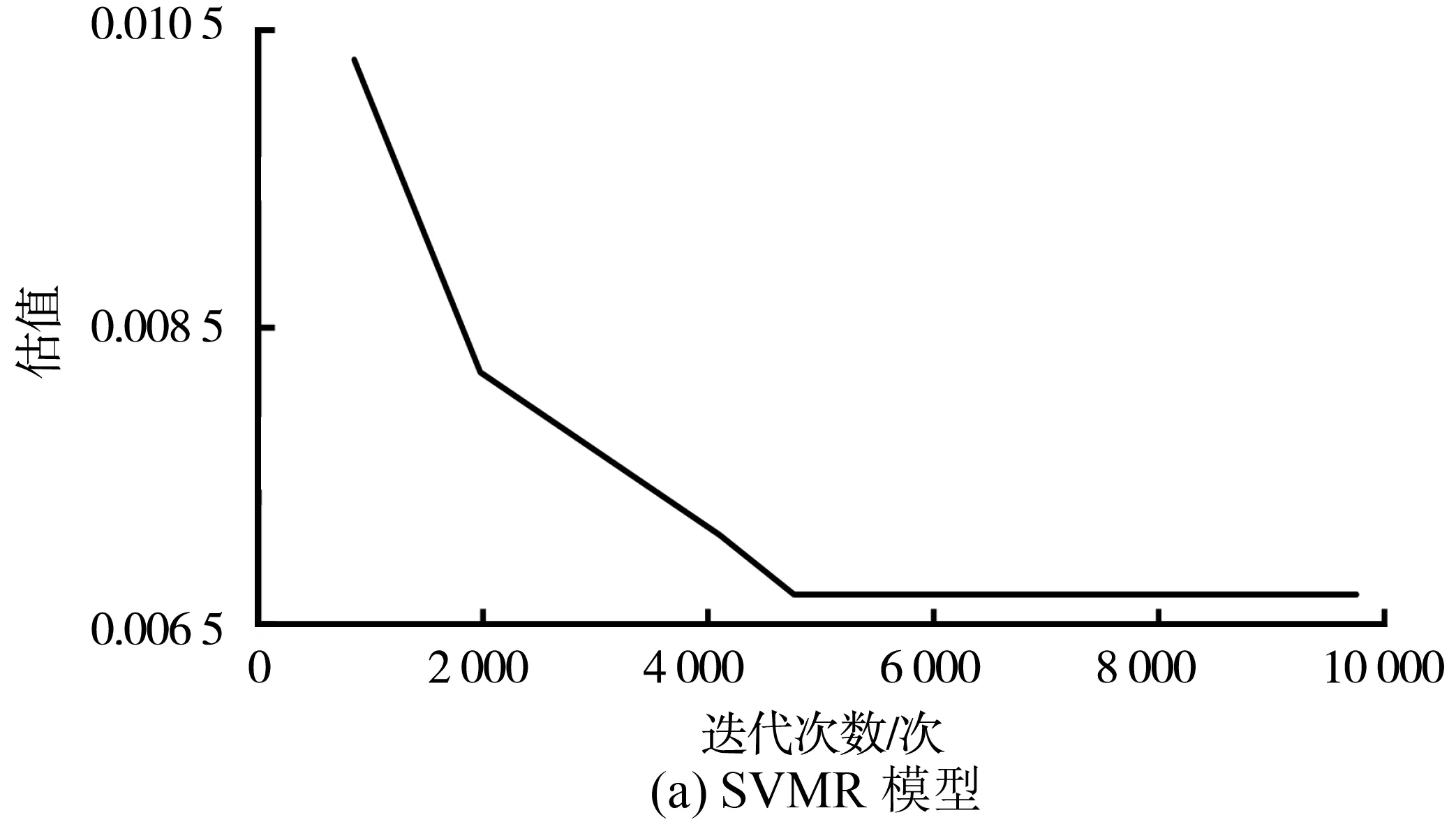
图5 模型训练过程Fig.5 Model training process
对图5分析可知,对比SVMR模型,PCA-LSSVMR模型和PCA-GA-LSSVMR模型训练过程曲线斜率较大,表明组合模型计算效率比SVMR模型的计算速率更快。在迭代次数方面,SVMR模型共进行了4 766次迭代运算,PCA-LSSVMR模型与PCA-GA-LSSVMR模型均进行了3 920次迭代运算。由此可见,经PCA算法与LSSVMR算法优化,有效减少了SVMR模型计算的迭代次数,简化了模型结构,加快了模型计算速率。
2.5.2 检验模型
在Rstudio软件中分别使用SVMR模型、PCA-LSSVMR模型与PCA-GA-LSSVMR模型对1 500组测试集数据进行计算。为便于模型计算,将IRQ数据进行归一化处理,使其取值范围在0~1之间,结果如图6。
分析图6可知,相比SVMR模型和PCA-LSSVMR模型,PCA-GA-LSSVMR模型各离散点密集地分布在等值线两侧,离散程度最小,说明该模型预测精度最高,真实值与预测值之间的偏差波动最小,表明PCA-GA-LSSVMR模型结果可信度最高。
3)模型结果评估。通过计算3种模型的线性回归确定系数R2和均方根误差ERMS,比较3种模型的预测精度。计算结果如表4。

表4 模型评估结果
分析表4可知,3种不同模型中,PCA-GA-LSSVMR预测模型的R2=0.835,最接近1,表明该模型稳定性最好,ERMS=2.394,在3种模型中最小,表明PCA-GA-LSSVMR预测模型的预测精度最高。
综合对比3种模型的训练过程、计算过程与误差分析过程,PCA-GA-LSSVMR预测模型迭代次数最少、计算速度最快、预测精度最高、模型稳定性最好。
3 实例预测及分析
在四川省2014—2019年23条高速公路中随机选取10条高速公路的路面施工建造数据、环境气候数据、交通荷载数据、路面性能检测数据和养护历史数据共计2 280条记录。按照7∶3的比例将数据集分为包含1 596组数据的训练集和包含684组数据的测试集,对10条高速公路的路面行驶质量进行预测分析。
3.1 评价方法
根据JTG 5210—2018《公路技术状况评定标准》,利用路面行驶质量指数IRQ实现对路面平整度的分级评价,计算公式如式(11):
(11)
式中:IIR为国际道路平整度指数;h0为标定系数,取0.026;h1为标定系数,取0.65。
路面平整度评价标准见表5。
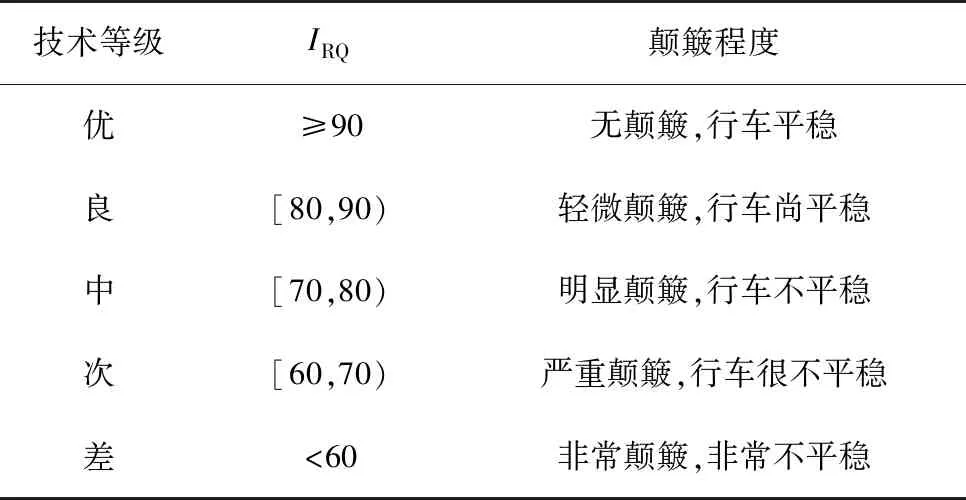
表5 路面平整度评价标准
3.2 性能预测
在实验数据及评价标准的基础上,利用Rstudio编程软件构建PCA-GA-LSSVMR预测模型,预测结果如图7。

图7 PCA-GA-LSSVMR模型预测结果Fig.7 PCA-GA-LSSVMR model prediction results
由图7可知,在PCA-GA-LSSVMR预测模型中,各数据点密集地分布在等值线两侧,表明模型的离散程度小、误差波动性小、泛化能力强;模型R2=0.87,表明模型预测精度高,使用效果好。
3.3 预测结果检验
将PCA-GA-LSSVMR模型计算得到的路面行驶质量预测等级与真实等级进行对比,得到的路面评价结果如表6。

表6 PCA-GA-LSSVMR模型预测结果评价统计
分析表6可知,PCA-GA-LSSVMR模型的平均预测准确率为86%,模型具有较高的预测精度,可以作为沥青路面行驶质量评价及预测的有效手段。
通过对预测结果进行检验,说明笔者提出的PCA-GA-LSSVMR沥青路面行驶质量预测模型切实可行,实现了对沥青路面行驶质量指标变化情况的合理预测,为养护时机的选择提供了理论依据。
4 结 论
1)利用PCA算法、GA算法以及LS-SVMR算法对SVMR模型预测结果精度差、模型求解速度慢等问题进行了改进,建立了适用于沥青路面行驶质量预测的PCA-GA-LSSVMR模型。
2)PCA算法与GA算法对SVMR模型的优化作用明显,使得PCA-GA-LSSVMR模型稳定性最好,达到了预期效果。
3)通过对四川省2014—2019年23条高速公路的使用性能检测数据进行计算与实例验证,发现PCA-GA-LSSVMR模型线性回归确定系数为0.835,最接近1,均方根误差为2.394,预测误差最小,模型的平均预测准确率为86%,说明模型具有较高的预测精度,可以作为沥青路面行驶质量预测的有效手段。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
疯狂英语·新悦读(2019年11期)2019-12-18
工程与建设(2019年2期)2019-09-02
凿岩机械气动工具(2017年3期)2017-11-22
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
专用汽车(2015年4期)2015-03-01
浙江大学学报(工学版)(2015年1期)2015-03-01
筑路机械与施工机械化(2014年2期)2014-03-01
