
噪声作用下的人脸面部情绪表情研究
2023-09-11 08:33闫靓周卉婷李争光
西北工业大学学报 2023年4期
闫靓, 周卉婷, 李争光
(1.西北工业大学 航海学院, 陕西 西安 710072; 2.浙江科技学院 建筑系, 浙江 杭州 310023)
烦恼是一种消极的复杂情绪[1]。噪声烦恼度(简称:“烦恼度”)包含人对噪声的体验、态度和行为,反映了人对噪声的情绪认知[2]。一直以来,学界多以基于调查或实验的主观方法测量烦恼度[3-4],其本质上属于心理学中的“内省法”[5]。虽然人类有能力借助语言自述情绪状态,但因“内省法”存在固有缺陷(如回想准确度低、潜在心理活动无法内省、意识到的心理活动未必能尽数精准报告以及存在不愿报告或虚假报告的情况),相关结果常受质疑(如客观性差、难再现、无法检验等等)[6]。此外,噪声自身属性(令人讨厌的、不需要的声音)[7]引发的负性情感定向作用(消极晕轮效应)会导致评价结果偏差[4]。加之人类反应的个体差异性、时变性以及情感成分和交感神经系统活动的调节机制等,都使烦恼度的评价与预测深奥莫测,举步维艰。
了解、认识和评价噪声引发的情绪效应,对实现精准高效的噪声控制至关重要。从噪声刺激下的生理唤醒开始,听音者对声环境的需求和愿望在其感受噪声的过程中经自我比较,形成自我体验,最终显现为可观察的行为(或表情,如面部表情、姿态表情和语调表情)。表情是情绪的外部表现,也是最有效的情绪显示器[8]。面部表情是最自然的情感表达方式之一[9],能够实现非侵入方式下的即时观测,具有可靠指示哺乳动物(包括人类)情绪体验的潜力。这种潜力不仅具有物种间的普遍性和特异性,还能适应个体差异。面部肌肉丰富细微的变化能够以“刺激-反应联结”(stimulus-response [S-R] connection)的形式表征情境中的刺激与个体情绪状态(类型/程度)之间的关系。不仅如此,人类观察者与生俱来的观察偏见使其总会将注意力集中于被观察对象的面部区域[10]。这种“精准定位”的能力对实现高效的情绪识别和正确的心理评估十分有利[11]。在噪声烦恼度研究中,如能将主观的情绪评估与客观的面部肌肉运动测量相结合,定会在最大程度上实现烦恼度的准确评价性[12]。
于是,提出2点设想:①是否存在一种典型的面部表情与噪声引发的烦恼情绪相互对应;②当听音者出现“烦恼”情绪时,其面部肌肉的运动模式是否与噪声特性密切相关。若上述2种假设均成立,即可实现以客观的面部肌肉运动度量不同类型噪声作用下的听音者烦恼度,突破现阶段研究方法的圈囿,创新噪声烦恼度评价体系与评估方法。
为此,本文主要开展了以下工作:设计并完成噪声作用下的听音者面部表情与生理信号采集实验,获得10种类型噪声作用下、30位不同国籍听音者的面部视频影像(时长总计9 360 s)、生理数据(心率值)与自报告烦恼度。随后,参考面部动作编码系统(facial action coding system,FACS)确定了噪声作用下听音者烦恼情绪的AUs组合表达。同时,创设了集视觉情感符号(emoji表情符号)、明度变化的单色相(灰色)尺度与传统言语尺度和数字尺度于一体的烦恼度(五级)量表,依托自主开发的移动端应用程序[13](凡响®,Awesound®)借助大规模网络调查对相关技术方法的有效性进行了验证。
1 融合听音者面部表情采集的噪声烦恼度评价实验
1.1 实验准备
1.1.1 声音的选取
目前,对噪声的分类方法主要有:按物理特性分类、按机能意义分类、按感觉特征分类、按情感色彩分类[14]。通过对现有国家标准中噪声分类方法与各类噪声定义的全面搜集、整理与总结归纳,本文将噪声的物理特性与机能意义结合,综合声音的时、频域特征与来源,优化现有分类体系并借助网络资源,分类搜集了368段音频文件。从中选取了10段极具代表性且囊括噪声分类体系中所有类别标签的声音(经裁剪后时长均为30 s)作为诱发听音者情绪的声刺激物(即声样本),见表1。实验过程中,听音者聆听噪声的总时长为300 s,最大等效连续A声级不大于97 dB(A),符合GBZ/T 189.8-2007《工作场所物理因素测量 第8部分:噪声》的要求。
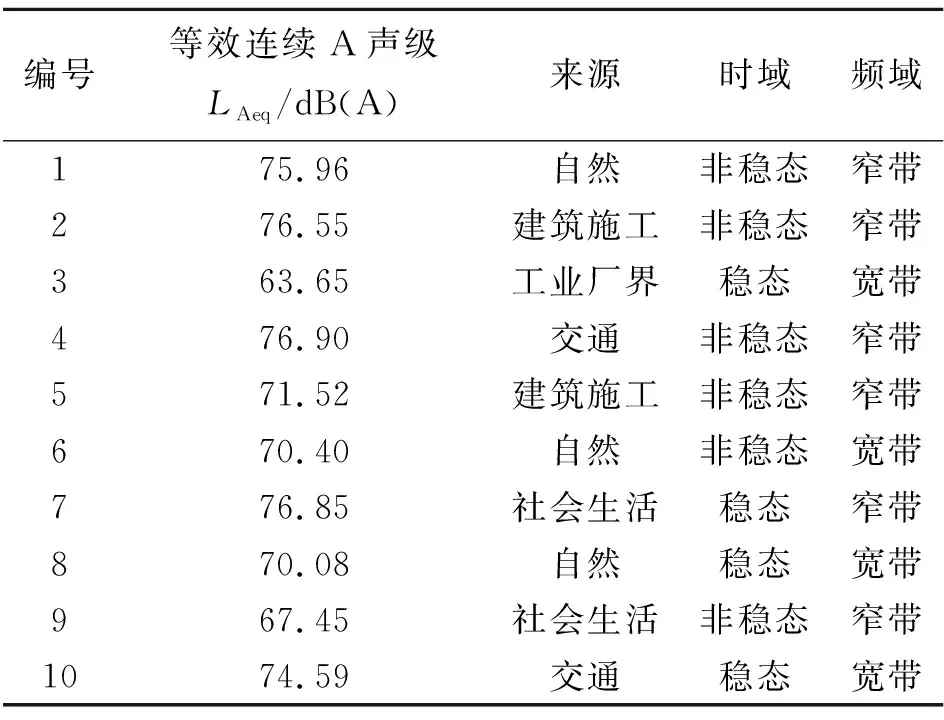
表1 各声样本参数及分类
1.1.2 问卷设计
相比文字和数字,色彩和图形会带给人更加直观的认知体验与情绪共鸣[15]。本研究尝试将色彩融入传统的烦恼度评价(描述词+数字)量表,创新问卷形式。具体做法如下:①调查适于表征“烦恼”情绪的色彩量表:a)探寻刻画烦恼情绪的单色色相;b)在a)的基础上,构建“以明度变化表示感受程度”的评价量表。②实施在线调查,验证新量表的有效性。调查发现:77.69%的被调查者倾向于以“明度变化的单色相尺度”衡量烦恼情绪的(程度)变化;40.9%的被调查者认为“灰色”能够更好地映射“烦恼”情绪。据此,决定以深浅不同的灰色构建噪声烦恼度评价量表。
1.2 实验实施
1.2.1 实验流程
本研究及相关实验程序由上海精神卫生中心伦理委员会批准(批件号:2021-53),符合NMPA/GCP和《赫尔辛基宣言》。实验招募13~52岁之间、听力正常的听音者共30人(男17人,女13人;平均年龄27.5岁)。其中,中国籍25人,外籍5人。实验前,所有听音者均签署了实验告知书,明确告知其有权在身体不适时随时暂停或退出实验且本人同意研究者使用其个人肖像。实验中,听音者先佩戴耳机聆听纯音乐(1 min),熟悉环境,平复心情,实验员开启摄像机并记录心率。随后,随机依次播放10段声样本(两样本间设置1 min静默时间,以便填写问卷),待10段声样本全部播放完毕,结束视频录制和心率采集,回收问卷,结束实验(见图1)。
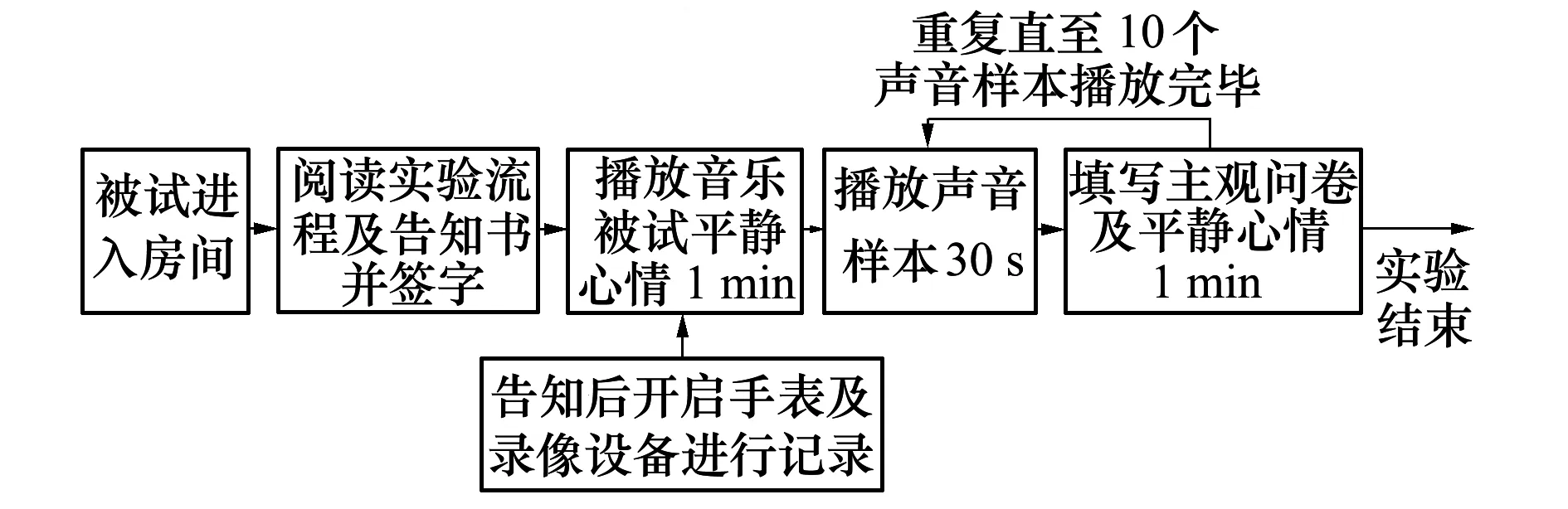
图1 实验流程图
1.2.2 面部表情采集
将烦恼度研究中惯用的听音实验与心理学研究中的行为观察相结合,在听音者完成听音评价任务的同时录制其听音过程中的面部表情变化。
参考中国情绪图片系统[16]制作方法,以SNOY EX280摄像机录制听音者在整个听音过程中的面部表情。摄像机位于听音者正前方4.5 m处,镜头高度与其面部持平。听音者座位上方天花板安装4盏补光灯(其中2盏置于听音者正上方,另外2盏分置于听音者左右侧斜上方),以提供高强度的稳定照明(见图2)。录制视频分辨率1 920×1 080,帧率25 frame/s。

图2 实验现场
听音室(11.2 m×7 m×2.8 m)四周及顶部均铺设吸声材料,本底噪声符合NC20(《Criteria for Evaluation Room Noise》)[17]。室内温度21~30℃,湿度适宜,布局布置参考 GB/T 13868-1992《感官分析:建立感官分析实验室一般导则》。实验中,声样本经Artemis软件和双耳耳机均衡器(HEADlab-compatible binaural headphone equalizers labP2)调制后,由动圈式高保真立体声头戴式耳机(SENNHEISER HD600)回放给听音者。
为了验证Ekman等人提出的:人在不同情绪状态下会呈现出可观测的生理反应[18](如愤怒与恐惧时心率提升);实验中使用HUAWEI-B5手环同步采集听音者心率(采样频率1次/30 s),用以探索听音情绪的产生和变化与心率波动之间的关系。
2 实验结果与分析
2.1 听音者自报告烦恼度分析
定义3种参数,分析听音者依据图1量表判定并报告的个人烦恼等级(描述词):
1) 平均烦恼度Am:首先,依据以下规则对听音者个人判定并报告的烦恼等级进行赋值:“一点也不”(not at all)赋分值“0”,“轻微”(a little)赋分值“1”,“中度”(moderate)赋分值“2”,“非常”(very)赋分值“3”,“极度”(extremely)赋分值“4”;计算(全部听音者对)10个声样本的个人烦恼度平均值,获得每个声样本的Am。
2) 易感烦恼率Psensitive:某声样本的烦恼等级为“中度及以上(包括“中度”、“非常”或“极其”)”的结果占全部评价数据量的百分比;当Psensitive>50%时,即可判定该声样本“易致人烦恼”。
3) 烦恼度A:根据“易感烦恼率”判定:当50%≤Psensitive<75%,对应声样本的烦恼度为“高”;当Psensitive≥75%,对应声样本的烦恼度为“极高”;此外,声样本的烦恼度为“低”。据此,获得全部声样本的相关评价数据,见表2。
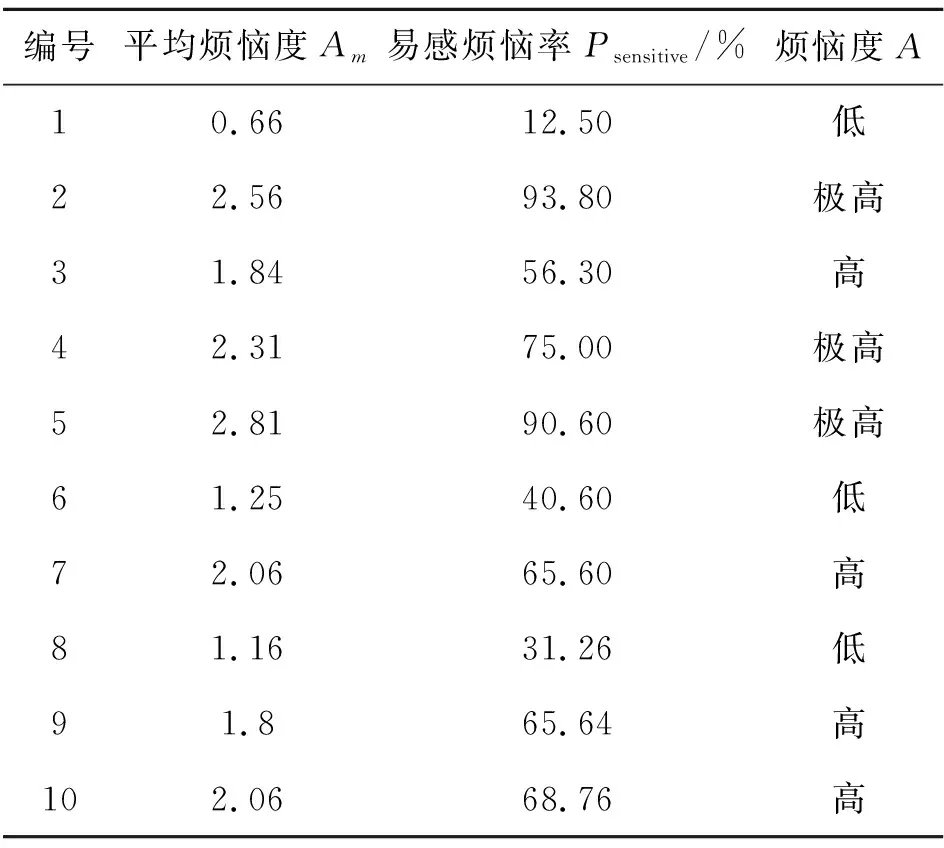
表2 声样本烦恼度分析结果
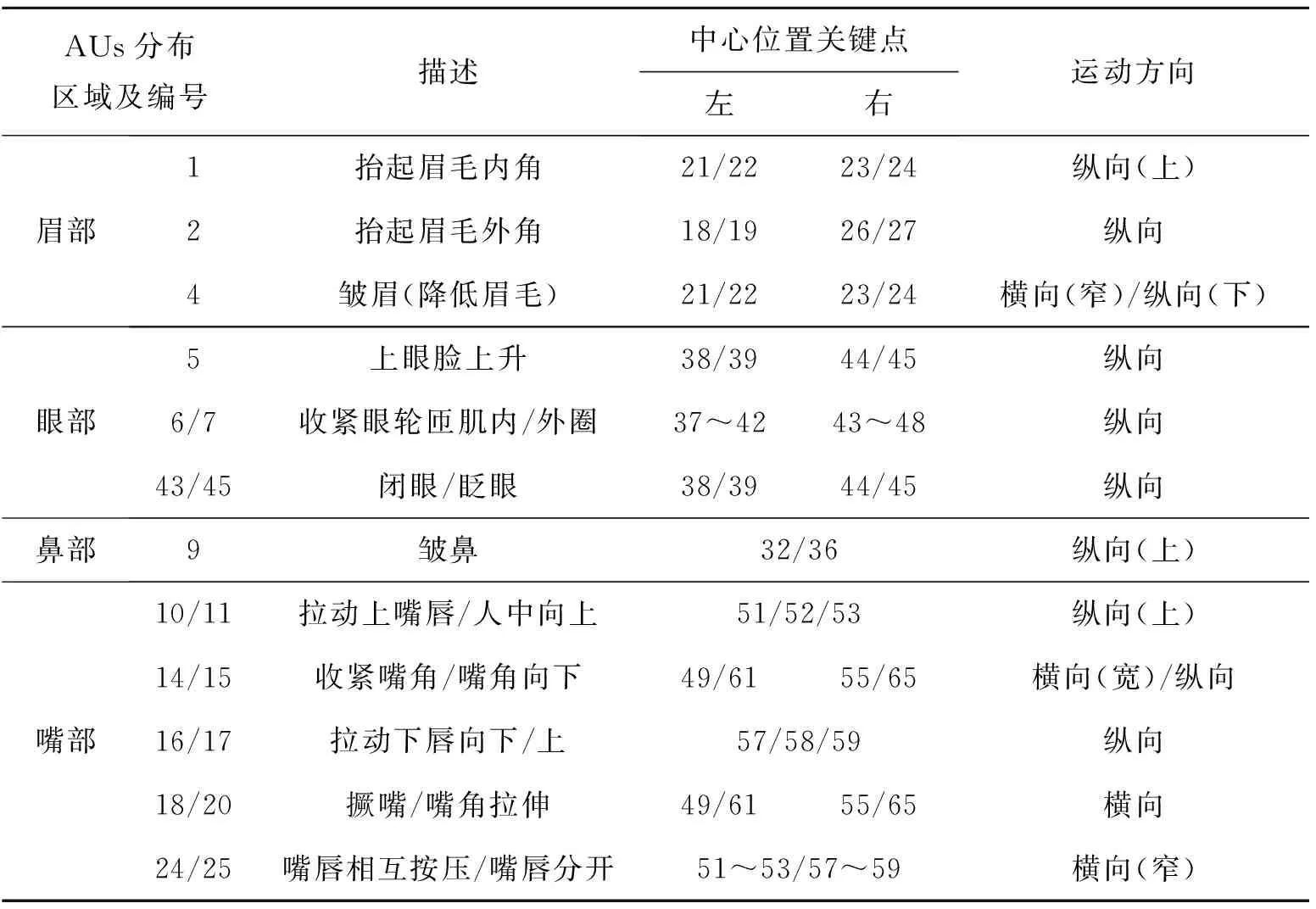
表3 与烦恼相关AUs及其中心点与关键点对应关系
2.2 听音者面部情绪表情分析
在探究与“烦恼”情绪相关的面部表情之前,首先,将人脸面部分为眉部、眼部、鼻部、嘴部及外轮廓。结合FACS中对AUs的描述,选择眉部:抬起眉毛内角(AU1)、抬起眉毛外角(AU2)、降低眉毛(AU4),眼部:上眼睑上升(AU5)、眼轮匝肌内/外圈收紧(AU6及AU7)、眨眼(AU43)、闭眼(AU45),鼻部:皱鼻(AU9),嘴部:拉动人中/嘴唇向上(AU10及AU11)、收紧嘴角(AU14)、拉动嘴角向下(AU15)、拉动下唇向下(AU16)、推动下唇向上(AU17)、撅嘴(AU18)、嘴角拉伸(AU20)、抿嘴(AU24)、嘴唇分开(AU25)的运动进行统计及分析。具体分析步骤如下:
1) 首先,对所采集到的300段视频进行图像配准,以消除头部偏转导致的无关抖动。采用dlib库中训练好的人脸关键点模型进行面部关键点提取,获得人脸轮廓0~17号关键点,眉部18~27号关键点,鼻部28~36号关键点,眼睛37~48号关键点,嘴部49~68号关键点(见图3)。
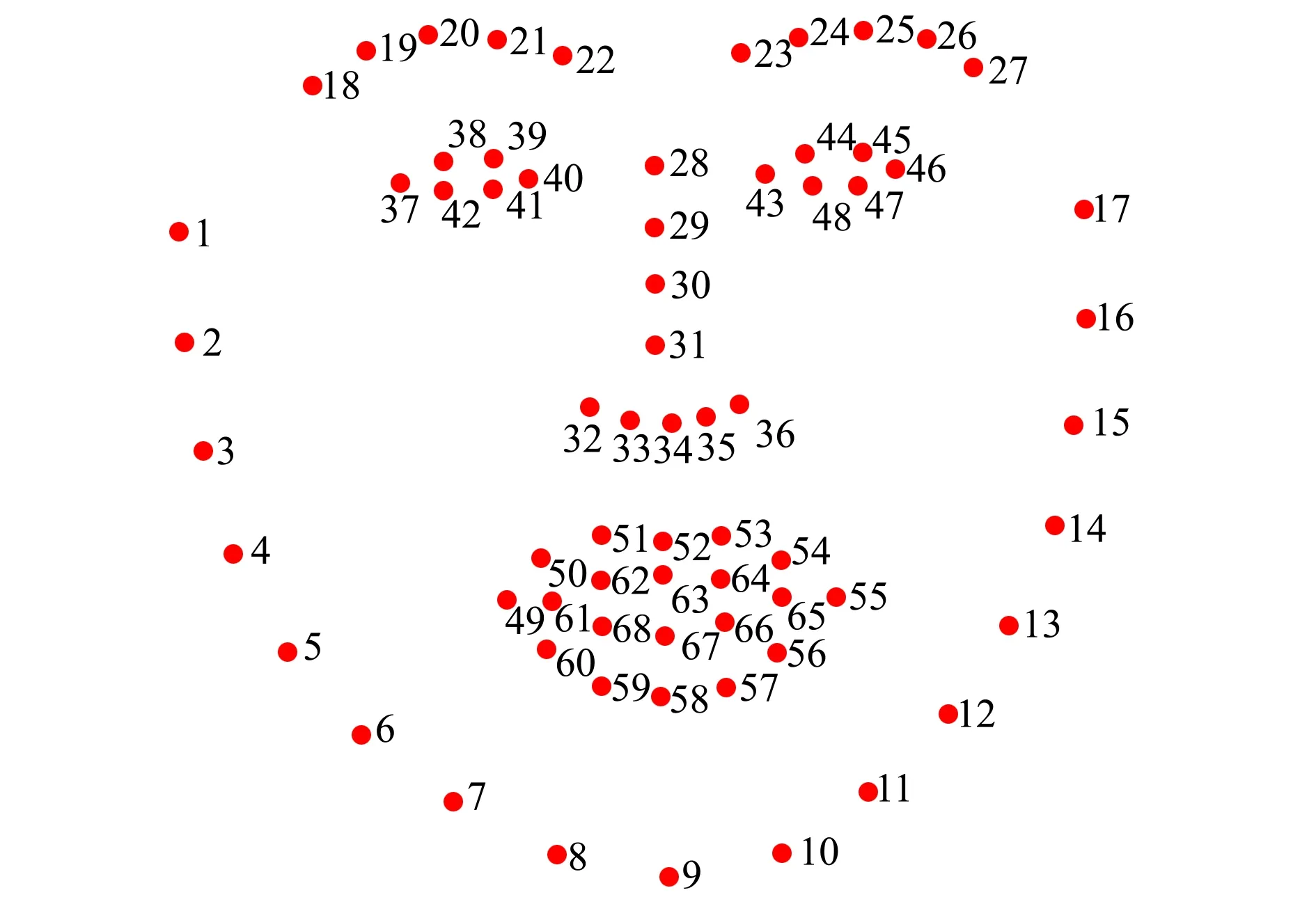
图3 人脸面部图像处理中的关键点
2) 根据既有研究[19-20]对AUs 的区域划分(见图4),确定其中心点与上述68个面部关键点间的对应关系,并对关键点的运动趋势进行了人工标注(见第3节)。
3) 接着,根据面部关键点的位置变化,辅以人工观察,判定并标注与烦恼情绪密切相关的面部AUs。
4) 最后,统计每段视频中各AUs运动的次数。
3 烦恼情绪面部表情关键特征提取与有效性验证
现有面部情绪分析理论与计算方法均未涉及复杂情绪面部特征的描述与表征。烦恼是一种典型的复杂情绪。为了寻找“易感烦恼”噪声作用下听音者面部情绪表情的显著特征,构建基于FACS的烦恼情绪面部AUs组合。分析30位听音者在聆听“高”与“极高”烦恼度声样本(共7个)时的面部影像(时长总计为6 300 s),具体做法如下:对面部变化区域进行划分并对其中涉及面部AUs的关键点进行运动状态变化的时间统计分析,完成关键表情特征的拣选、分类与重组。
研究发现:听音者面部表情可分为习惯性面部表情及情绪引发的面部表情两类。前者为听音者在平静状态及整个听音过程中均出现的面部表情,包含张嘴(AU25),快速眨眼(AU45)等。习惯性面部表情具有显著的个体性差异性。而情绪引发的面部肌肉运动在听音者自报告不同烦恼度时,面部表情呈现明显可分的等级变化(见图5)。可见,利用听音者面部情绪表情的变化模式(即面部肌肉的具体的运动方式和幅度)评价噪声烦恼度是可行的。统计30位听音者在不同ANOYI等级的声样本影响下各面部AUs的平均运动频次(见图6),发现眉部的AU1、AU2、AU4,眼部的AU6和AU7和嘴部的AU14及AU20随着声样本的ANOYI上升呈现出增长的趋势,由此推测,上述AUs对解释烦恼情绪具有普适性。结合FACS中用AUs对各类基本情绪的描述方法,将烦恼情绪下的面部运动定义为由眉毛内角(AU1)及外角(AU2)、降低眉毛(AU4)、眼眶收紧(AU6和AU7)、收紧嘴角(AU14)和嘴角拉伸(AU20)共同描述。

图5 烦恼度程度尺度条对应面部情绪表情尺度
4 结 论
本研究践行了跨领域融合创新,获取了一个分析噪声刺激作用下听音者自然流露的面部情绪表情的数据集。其中,包括了30名听音者在聆听10段具有不同时频特征声样本时的面部视频及其对每段声样本的自报告烦恼度;以此为基础,借助面部表情识别技术并配合人工标注,对发生运动的面部区域(以面部关键点的多少表征)及运动程度(以面部关键点运动频率)进行分析统计,寻找与听音(烦恼)情绪紧密相关的面部AUs。本实验是对噪声烦恼度研究的理论创新与方法变革的初步探索与大胆尝试,期望能够克服领域研究中大量主观因素对研究结论客观性的影响。诚然,面部情绪表情模型的正确构建和运动模式的精准识别,必须以全面、详尽、充分的数据收集和分析为基础。本文相关工作的完成,旨在促进建立集噪声特性、听音者生理数据、面部表情变化与自报告烦恼度于一体的研究型数据集和深入开展后续工作。为了实现合理严谨、科学可靠、灵活便捷、普适性强的噪声烦恼度评估,避免传统描述性评估技术流程繁琐、成本密集、耗时耗力的弊端,提高研究的信度和效度,尽量减少使用模棱两可的主观感受描述词与未经设计的心理反应量表,采用行为心理学的观点和方法,通过直接观摩、记录、分析听音者在声刺激作用下的面部表情反应,阐释其情绪状态,用“看到的”而非“想到的”,评价“感觉”,预测“反应”,解释“情绪”,从实际出发开展包括烦恼度在内的一切噪声作用下的情绪效应研究。
猜你喜欢
新作文·小学低年级版(2022年6期)2022-08-30
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
数学年刊A辑(中文版)(2020年3期)2020-10-27
汉字汉语研究(2019年2期)2019-08-27
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
小学教学设计(英语)(2016年4期)2016-04-16
噪声与振动控制(2015年4期)2015-01-01
中国卫生(2014年2期)2014-11-12
声学技术(2014年2期)2014-06-21
