
计算机辅助配棉技术研究进展
2023-09-25 11:21王梦蕾王静安高卫东
纺织学报 2023年8期
王梦蕾, 王静安, 高卫东
(生态纺织教育部重点实验室(江南大学), 江苏 无锡 214122)
在制造强国建设持续推进下,数字化、网络化、智能化制造已成为纺织行业转型升级的重要力量。全面加速行业数字化转型,优化生产工艺,提高生产效益,实现精益制造,是纺织行业“十四五”发展纲要对纺织智能制造提出的重要任务[1]。作为棉纺厂的一项基础工作,配棉决定的原料选配对稳定生产、保证质量[2]、控制成本至关重要,与原料采购及检验、产品试制与生产、企业管理与运维等工作息息相关。在传统的生产模式下,配棉工作主要依赖于人工经验完成。在产品品种发生变化,或当前配棉方案中部分棉种即将耗尽时,配棉必须考虑到原棉选择的连续性、稳定性,以及企业产品特点、库存情况、生产工艺、订单情况、机台状况等各方面因素,实现优棉优用、差棉巧用,减少性能过剩、保持质量稳定、降低原料成本。但棉纺过程具有工序多、周期长、信息反馈滞后、生产连续性强等特点,使得人工配棉存在着一定的片面性和偶然性。
早在20世纪70年代,有研究者提出采用计算机辅助技术替代或辅助人工配棉,但受限于当时纺织产业较低的信息化水平,并未形成系统性的研究成果与推广应用[3]。随着原棉供应体系的信息化程度不断提高,以及新一代信息技术的加速创新与推广应用[4],计算机辅助配棉迎来了新的发展契机。目前,国内外研究者采用机器学习、启发式进化算法等先进人工智能技术建立纱线质量预测模型和配棉最优化模型。这些研究成果一方面有效地根据配棉方案预测成纱质量,减少了纺纱生产中的试错成本;另一方面在充分考虑原料成本与产品质量需要的基础上,实现配棉方案的计算机辅助制定,缓解了配棉工作对人员经验的依赖。随着产业信息化程度的不断提高,当前研究成果在模型准确性、高效性与泛用性等方面仍须进一步提升[5-7]。
本文首先简要介绍计算机辅助配棉的系统框架及技术内涵;其次对计算机辅助配棉过程中的2个关键模块—纱线质量预测、配棉最优化模型中所采用的核心技术进行综述与问题分析;最后,从计算机辅助配棉的方法创新、产业数据规范与互联2个方面展望进一步研究方向,为纺织生产科学化指导、精益化生产、信息化管理提供具有启迪意义的参考。
1 计算机辅助配棉系统框架
计算机辅助配棉系统能够结合企业产品特点、库存情况、生产工艺、订单情况、机台状况、市场行情等信息,根据企业产品质量管理与原料成本控制的需要,制定合理的配棉方案,其中核心技术模块包括纱线质量预测及配棉方案制定。纱线质量预测是依据企业实际生产的历史数据,建立原棉指标到纱线质量指标的映射模型如图1所示。
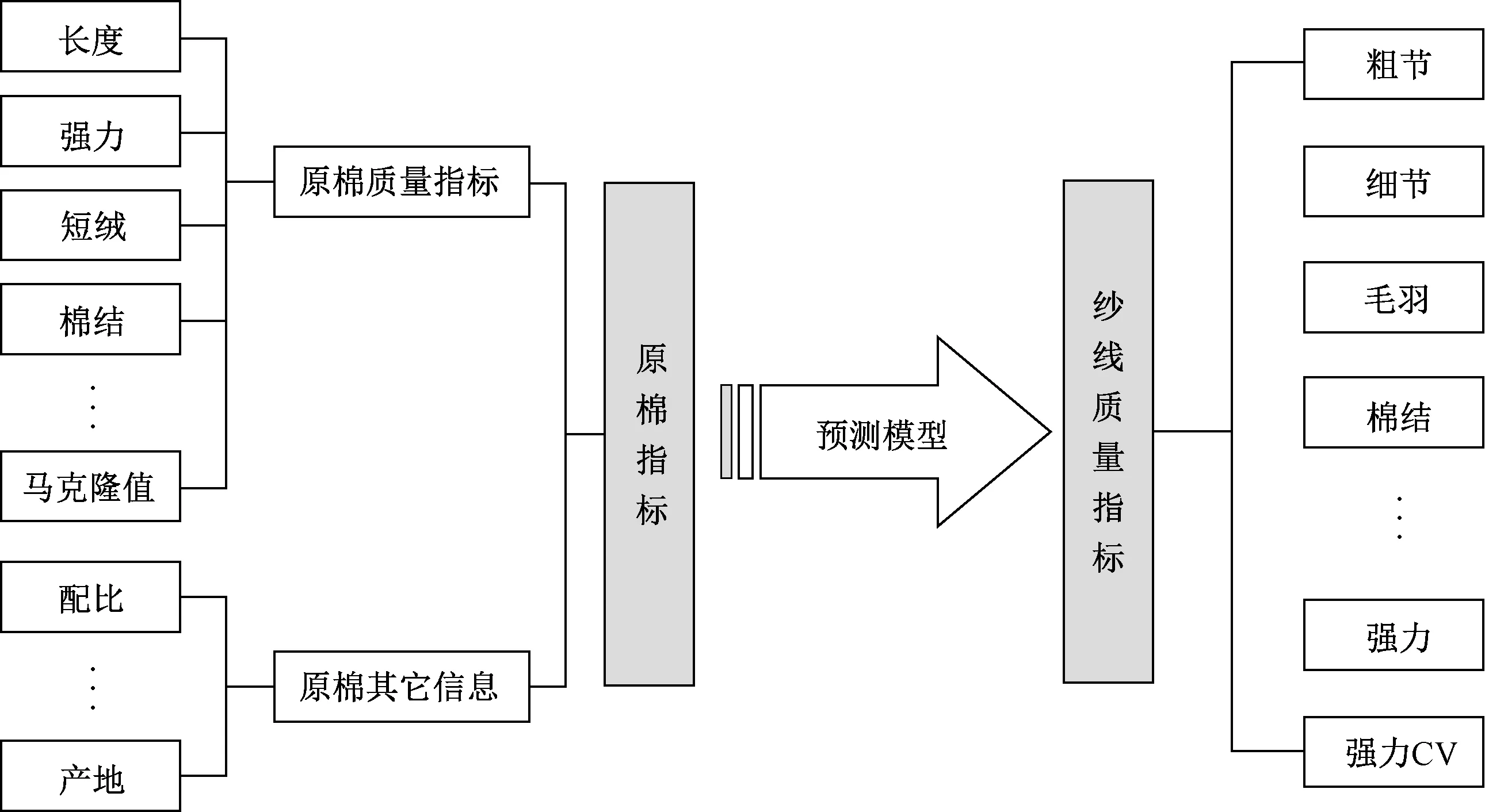
图1 原棉指标到纱线质量指标的映射关系Fig. 1 Mapping relationship between raw cotton index and yarn quality index
该模型能够从配棉方案预测纱线质量,用于从产品质量的角度评价各种配棉方案的优劣。目前,普遍采用的纱线质量预测技术包括人工神经网络、支持向量机、线性回归方法等。
在纱线质量预测模型的基础上,建立配棉最优化模型,用于描述在特定生产需求下最合理的配棉方案,该模型包含目标函数、约束条件、求解算法。其中目标函数和约束条件可根据企业实际生产侧重进行权重分配,在采用优化算法实现目标函数的最优化后,形成一系列推荐配棉方案,并显示各方案预测得的纱线质量参数,以供配棉人员参考。
最终,图2示出一套配棉技术管理决策支持系统[6,8-9],集成原棉库存数据库维护、纱线质量预测与管理、配棉方案的制定、配棉与纱线质量档案4个功能模块,以及供使用者查询、维护与反馈的人机交互界面,满足棉纺企业对于纱线质量管理、质量监督的需求,实现原料成本的控制、配棉方案的优化以及生产效益的提升。

图2 计算机辅助配棉系统框架示意图Fig. 2 Framework of computer aided cotton blending system
2 纱线质量预测模型
纱线质量预测的目的是从原棉指标预测成纱后的各类纱线质量指标,方法是建模原棉指标与纱线质量指标间的复杂的非线性映射关系。长期以来,国内外学者关于纱线质量预测开展了大量工作,主要采用的建模方法包括线性回归、支持向量机、人工神经网络等。
2.1 线性回归
纱线质量预测是一种多元线性回归建模问题。多元线性回归预测纱线质量的步骤主要包括:原棉指标提取、线性回归方程建立、回归模型的参数估计、模型参数的估计值检验;最优回归方程的确定以及模型的实际预测检验。其中,回归模型的参数估计常采用最小二乘法;回归模型的检验可包括拟合度检验、估计标准误差、回归方程的显著性检验、回归系数的显著性检验。
由于线性回归方程中的权系数直观地表达了各原棉指标在预测任务中的重要性,使得线性模型具有很好的可解释性;且模型形式简单、易于建模。早期关于纱线质量预测的方法主要集中在线性模型上。储才元等[10]采用相关性分析和多元线性回归方法建立了原棉指标与纱线质量指标之间的映射关系模型。Krupincova等[11]基于棉纤维HVI(high volume instrumen)数据,同时考虑纱线特数和纱线捻度的影响,建立了从纤维、纱线结构参数预测纱线毛羽的线性回归模型。继而,Ureye等[12]则引入包括特数、捻度的纱线结构参数,以及粗纱性能指标,通过线性回归预测纱线质量,并以方差分析技术检验了模型的显著水平。上述研究表明,除了原棉质量指标,纱线规格参数以及由纺纱工艺参数决定的粗纱性能指标对纱线质量指标也存在影响。但由于原棉指标与纱线质量指标之间是非线性映射关系,线性回归方法难以准确表达,存在较大的预测误差。
2.2 支持向量机
针对纱线质量预测问题的非线性特点,有研究者采用支持向量机SVM(support vector machine)方法。SVM能够使用核函数技巧将特征映射到高维空间,以实现对非线性问题的建模。SVM模型的参数求解能够获取全局最优,对样本量的依赖度较低,泛化能力较强,在小样本预测中表现突出。关于SVM方法的纱线质量预测研究主要集中在样本数据处理、模型超参数优化、核函数改良上。
在样本数据处理上,Doran等[13]采用主成分分析和方差分析对样本数据进行降维,使用平均绝对百分比误差、平均绝对误差和相关系数来评估SVM模型的预测能力,研究结果显示该模型在棉/氨纶包芯纱的质量变异系数和毛羽的预测上都表现出较高的准确率。王东平等[14]采用灰色关联分析得到原棉成熟度、断裂强度、均匀度等7个灰色关联度最大的指标作为SVM模型的输入,预测纱线的强力和条干CV,获得了良好的预测结果。进一步地,项前等[15]的研究表明基于灰色关联分析的SVM在小样本和“噪声”数据环境下仍能保持一定的预测精度,验证了该方法的鲁棒性。
典型的SVM包含若干超参数,如正则化项、核宽度。为选择最佳的超参数组合,有研究者采用网格搜索法、交叉验证法等传统方法对模型参数寻优,如前文王东平等的研究[14]。此外,亦有采用智能算法进行超参数寻优的研究,如宋楚平[16]、吕志军等[17]使用遗传算法,有效提高了SVM模型的预测精度。
在核函数改良方面,Abakar等[18]建立基于Pearson VII核函数的SVM纱线质量指标预测模型,从棉纤维的强度、长度、含杂量等11个指标预测纱线强力,研究结果表明,与径向基函数的SVM模型相比,该模型具有更高的预测精度。
2.3 人工神经网络
另一类常用于纱线质量预测的机器学习方法为人工神经网络ANN(artificial neural network)。人工神经网络是由具有适应性的简单单元(神经元)组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所做出的交互反应。Hornik等[19]研究证明只需一个包含足够多神经元的隐层,多层前馈网络就能以任意精度逼近任意复杂度的连续函数。由于人工神经网络强大的表示能力,在各类非线性预测任务中得到广泛应用。目前在纱线质量预测领域,研究者主要从网络结构设计和优化方法2个方面开展研究,以保障模型的预测精度和泛用性。最常见的神经网络结构是多层感知机MLP(multi-layer perceptron)单隐层结构[20],隐藏层的神经元个数决定了模型的拟合能力。Mwasiagi等[21]构建了预测环锭纱断裂伸长率的ANN模型,并研究了不同的网络结构、权重/偏差学习函数、激活函数、反向传播训练函数和隐藏层神经元数量对模型精度的影响,获得了一组最优的模型结构参数。查刘根等[22]提出了具有双隐藏层的四层前馈神经网络来预测棉纱成纱质量,进一步提高了前馈神经网络在纱线质量预测时的精度和训练速度。Hao等[23]研究了采用随机向量函数链接神经网络RVFLNN(random vector functional link neural network)预测纱线的不匀率,研究结果表明,RVFLNN有效地消除了多层神经网络训练过程过长的缺点,同时也保证了函数逼近的泛化能力。Turhan等[24]引入径向基函数RBF(radial basis function)神经元计算结构进行模型改进,有效提高了网络的预测精度。胡臻龙[25]提出通过增加网络深度提升模型的拟合能力,为此将模型输入参数构建成矩阵形式,引入卷积神经元结构,以在增加网络深度的同时避免过多的模型参数;同时引入广义回归神经结构,建立了隐藏层数超过5层的卷积神经网络CNN(convolutional neural network)模型,在避免模型“过拟合”的同时取得了性能的提升;为了缓解CNN模型对训练数据样本量的依赖,引入了对抗学习技术,实现数据样本量的扩增。
通常ANN模型参数优化采用误差反向传播技术BP(back-propagation),利用梯度法进行迭代寻优。梯度法在搜索过程中优化方向可控,但是容易陷入局部最优,且模型超参数选取较为困难。为此,很多研究者提出采用群体智能算法替代梯度法。针对纱线质量预测问题,Zhang Baowei[26]、熊经纬[27]、项前[28]、王军[29]、刘贵[30]、Amin[31]、Soltani P[32]、Hadavandi[33]等分别采用粒子群算法、遗传算法、蝴蝶优化算法、灰狼算法来训练ANN,研究表明这些群体智能算法均明显地提高了模型训练速度与预测性能[34]。群体智能算法虽然能够在一定程度上避免模型陷入局部最优,但其优化方向不可控,局部搜索能力与稳定性欠佳。因此,有研究者提出将群体智能算法与梯度法相结合,通过混合训练算法来优化ANN模型,实现两者的优势互补。Mwasiagi等[35]提出采用微分进化算法的全局寻优能力,首先在全局范围求取ANN参数,继而以此作为初值,利用Levenberg-Marquardt算法对参数进行局部寻优,获得了模型预测精度与训练稳定性的综合提升。
2.4 纱线质量预测存在的问题
当前研究中采用的各类建模方法均属于有监督机器学习模型,在实践中表现出一定的预测效果。但有监督机器学习模型的训练依赖于大量的数据样本,以及有效的输入数据特征表达。当前很多企业仍面临数据采集不充分与训练样本不足的问题。
此外,当前研究中的预测模型未充分考虑配棉方案。在实际生产中,配棉方案中包含了各原棉的产地、批次、种类、配比等信息。但是,当前研究仅采用各原棉指标的加权平均值作为混合棉指标,再输入模型进行预测,忽略了配棉方案中的大量信息,在一定程度上影响模型精度及实用性。造成该问题的主要原因是,当前研究所采用的机器学习模型只能输入定长特征,无法对长度变化的配棉方案进行通用性的预测;同时如何从维度较高且长度变化的配棉方案提取有效的特征表达仍缺乏探讨。
3 配棉方案制定
原棉的主要物理性质,如上半部分长度、整齐度、断裂比强度、马克隆值等与对纱线质量有很大影响[7]。棉纺企业关注的原棉指标也有很大差异,配棉时要根据产品需求、原棉库存、原棉特点制定出原棉用量及混合比。
传统棉纺企业使用的配棉方案制定方法是分类排队法[36]和组合方案法[37]。分类排队法是根据原棉的特性和各种纱线的不同要求把适合纺制某类纱的原棉划分为一类,排队即是将同一类的原棉,按照地区、性质、质量基本接近的排在一队中,以便交替使用。最后与配棉日程相结合编制成配棉排队表[38]。组合方案法是一种排列组合方法,即对多种可选原棉的多种可用混合比进行组合。早期的计算机辅助配棉工作,是将这种方法的操作流程数字化,由计算机查表辅助人工完成配棉,并未实现配棉方案的智能化制定。继而研究者提出构建配棉最优化模型,结合实际生产需要制定约束条件,采用最优化方法进行求解。这种配棉最优化模型包括目标函数、约束条件及求解方法。
3.1 配棉目标函数
从企业的实际生产需要考虑,配棉方案应实现质量与成本的统一,研究者常采用2种目标函数来描述配棉目标,一种为原棉成本最小目标,一种为原棉质量成本控制目标。
原棉成本最小目标是指配棉方案中涉及的各原棉成本之和最小,可依据配棉方案中各项原棉的成本及其用量求得[39]。为了保证纱线质量达到指定要求且避免过剩造成浪费,研究者提出原棉质量成本控制目标。该目标通过限定混合棉的指标范围来实现,即控制混合棉指标与标准棉指标间的差值最小,其中标准棉指标通过反向求解纱线质量预测模型的最优输入获取[40]。
此外,有研究者对原棉质量成本控制评价方法作了进一步改进。通过原棉指标与纱线质量指标的相关性分析,对混合棉指标进行赋权,即对混合棉指标影响纱线质量指标的程度进行评价,此方法能够更好地描述原棉质量的成本控制[41]。
在实际建立配棉最优化模型时,研究者通常有2种思路:一是将原棉成本最小目标作为单一目标函数,质量成本控制作为模型中的一种约束[40];二是将原棉成本最小目标与原棉质量成本控制目标作为一类多目标问题进行优化[41]。多目标的优化通常采用优先等级法或加权系数法将其转化为单目标进行求解。优先等级法是将各目标按照其重要程度赋予不同的优先等级,转化为多个单目标模型再逐步求解。加权系数法是为每一个目标赋一个权系数,把多目标模型转化为单目标模型,其难点在于权系数的合理化选定,通常是根据配棉人员的经验确定[42]。
3.2 配棉约束条件
配棉的过程还需考虑纱线质量控制、原棉库存控制、配棉总量控制等问题,因此配棉最优化模型中还需包含相应的各项约束,以满足不同企业的生产与管理需求。当前研究提出的关于配棉最优化模型的约束条件主要包括以下几种[40-42],可依据实际需求指定优先级。
纱线质量约束:根据配棉方案纺制的纱线各项质量指标需满足产品需求。纱线各质量指标由纱线质量预测模型进行预测,模型输入为混合棉质量指标。
配棉库存约束:配棉方案中每种原棉的用量必须小于其库存量。
配棉总量约束:配棉方案中单种原棉的总量可以不加限定,但要求各原棉所使用的总量必须与设定的配棉总量保持一致,或配棉方案中各批棉所占的比重之和为1。
配棉种类约束:为了方便快捷地调度库存原棉,配棉方案中所使用的原棉种类不宜过多,最大种类数应小于设定的数量。
原棉品质指标约束:配棉方案中原棉质量指标平均值或者基于配比的加权平均值必须在规定的范围内。即将上述配棉目标函数中的原棉质量成本控制的目标函数转化为约束条件。
3.3 配棉模型求解
配棉最优化模型的求解是典型的多目标多约束非线性优化问题,无法采用线性规划法实现快速求解,为此研究者普遍采用启发式算法或机器学习技术进行求解。
1)启发式算法。启发式算法是一种基于直观或经验构造的算法,在可接受的计算时间和空间下给出待解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度一般不能被预计。张增强[42]、Das S[43]、杜兆芳[39]等分别采用粒子群算法(PSO)、模拟退火算法(SA)、微分进化算法求解配棉问题的目标函数,研究结果表明,在保证纱线质量的前提下,启发式算法有效地降低了原棉成本。围绕所构建的配棉最优化模型的特点,研究者对典型的启发式算法提出了一系列改进。例如,宋楚平等[41]通过改进遗传算法的初始种群生成策略、遗传算子和进化收敛条件,将配棉约束条件动态融合到种群进化过程中,在保证配棉约束条件的前提下,兼顾求解的效率和效果。陈怀忠等[44]采用惯性权重递减和学习因子自适应策略改进粒子群算法,使得改进的PSO在配棉问题寻优过程中更快更精,局部和全局寻优能力都得到了有效提高。易文峰等[45]采用一种萤火虫-粒子群混合算法对配棉问题进行求解,结果表明,混合算法的求解效率优于传统的粒子群算法。
2)机器学习技术。机器学习技术是通过学习算法从配棉经验数据建立优化模型,在面对新的纺纱需求时,制定新的配棉方案。Majumdar A等[46]通过使用人工神经网络建立纱线到纤维的“反向”模型,采用所需纱线质量作为ANN的输入,“反向”预测所需的混合棉指标,继而使用线性规划法对配棉方案进行最优化求解。
3.4 配棉最优化模型存在的问题
在目标函数与约束条件的构建上,当前研究围绕实际生产对原棉成本、原棉库存、纱线质量的需求提出了一系列方法,但具体目标与约束的选用及权重分配仍依赖于主观判断,尚未形成智能化模型构建方法。此外,当前研究采用的配棉方案表示方法均为混合棉质量指标,对变化原棉品种与配比的表示能力欠佳,导致模型对原棉种类及配比变化的优化求解能力受限。
在模型的求解方法上,启发式算法强大的全局搜索能力表现出显著优势,但随着原棉品种的增加与产品需求的丰富,此类方法的优化效率还需进一步提升。采用人工神经网络“反向”模型的优化方法虽然能够解决效率问题,但是灵活性和普适性不足。
4 计算机辅助配棉技术发展趋势
随着信息技术的不断发展,计算机辅助配棉技术在效率和精度上都有了明显地提升,未来可从以下方面进一步开展研究。
4.1 纱线质量预测
在建模方法上,当前研究围绕模型结构与优化方法开展了一系列探索。随着人工智能技术的不断发展,更多建模与优化方法的创新将进一步提高预测模型的精度与效率。此外,当前研究采用的训练与验证数据还较为局限,随着生产信息化程度的提高,采用更充分的实际生产数据对各类模型进行训练与实践验证亦是一个发展方向。
在数据特征表达上,纱线质量预测模型的输入包括生产工艺参数、产品规格参数以及配棉方案信息三类数据。前两类数据均可向量化表达,但配棉方案信息结构复杂,当前研究普遍采用原棉平均质量指标或加权平均质量指标作为其特征,配棉方案信息表达不完整。未来,可寻找有效的配棉方案信息表达方法,包括各原棉质量指标、配比、产地、批次等信息的表达方法,结合预测模型结构的改进,进一步实现纱线质量预测的精度和效率的提升。如何选择并引入生产工艺参数与产品规格参数也是重要的研究内容。
4.2 配棉方案制定
配棉方案的制定关键在于智能化的配棉最优化模型。在建模方法上,当前研究仍面临个性化与普适性之间的矛盾,研究个性化需求的规范性建模形式可有效支撑技术的推广,是未来的重要发展方向。另一方面,在原料品种不断增加,产品需求复杂度不断提高的背景下,当前普遍采用的启发式算法的效率面临巨大挑战,构建兼顾效率与精度的优化方法将是未来的研究热点。
目前配棉研究的对象普遍针对纺纱厂自身库存。若将原棉库存与市场数据联通,一方面能够增加原料选择面,提高配棉方案的综合效益,另一方面可基于配棉工作科学地“反向”指导原棉采购。但这也必将带来问题复杂度的增加,当前方法难以直接适用。未来研究可借助深度强化学习技术,建立高效智能化配棉策略模型,或可先解决原棉采购方案优化问题,再整合至配棉最优化模型中。
4.3 产业数据规范与互联
计算机辅助配棉技术的适用性很大程度上取决于原棉数据的规范性,以及对个性化数据的通用表达。如何从配棉与生产实际需要出发,构建更具通用性的原棉标准化指标,并针对不同企业的个性化需求建立原棉指标的筛选及表征方法,是进一步的研究方向。
随着产业数据的规范化与通用化,计算机辅助配棉系统将在产业互联平台中成为原棉供应与纱线用户间的媒介,发挥重要的供需调配作用,促进解决精准购棉和精确用棉的行业难题,实现原棉供应、纺纱生产、产品用户的宏观统筹,为构建智慧工厂体系打下基础。
5 结束语
计算机辅助配棉系统既为棉纺企业稳定生产、保证质量、控制成本提供可行方案,也为纺织行业降低人员依赖、提高生产效益,实现精益制造提供新思路。此外,计算机辅助配棉系统围绕对原棉大数据的深度运用,一方面持续推动原棉质检的标准化发展;另一方面有望加速推动纺织产业的智能化转型升级。目前,计算机辅助配棉系统研究仍然处于发展阶段,随着大数据与人工智能技术的不断进步,未来研究有望在以下方面取得实质性进展:
1)在纱线质量预测的方法上,构建更具通用性的原棉标准化指标,针对企业个性化生产模式建立原棉指标筛选及配棉方案特征表达方法,改进预测模型结构与模型优化算法,进一步提升模型的预测精度和泛用性。
2)在配棉方案的制定上,一方面研究具有普适性且兼顾个性化生产需求的配棉最优化模型,同时探索更具准确性与高效性的优化方法,另一方面将原棉库存与市场数据联通并引入最优化模型中,增加原料选择面的同时,“反向”指导原棉采购。
猜你喜欢
纺织科学研究(2021年6期)2021-07-15
中国农机化学报(2021年4期)2021-05-11
新疆农机化(2021年1期)2021-03-09
安徽农业科学(2020年12期)2020-07-14
纺织服装流行趋势展望(2020年3期)2020-02-01
现代纺织技术(2019年5期)2019-01-14
中国粮油学报(2018年12期)2018-03-19
现代检验医学杂志(2016年1期)2016-11-12
纺织服装流行趋势展望(2016年6期)2016-05-04
纺织服装流行趋势展望(2016年1期)2016-05-04
