
外观和运动模式感知的有丝分裂细胞检测
2023-09-26 04:21林凡超谢洪涛刘传彬张勇东
中国图象图形学报 2023年9期
林凡超,谢洪涛,刘传彬,张勇东
中国科学技术大学信息科学技术学院,合肥 230026
0 引言
有丝分裂是细胞增殖活动中必不可少的过程,分析活体细胞的有丝分裂情况对于研究细胞群的行为方式等课题具有重要意义。通过对相衬显微图像序列中的有丝分裂细胞进行检测可以实现细胞跟踪和细胞谱系构建,进而为干细胞培养、组织工程、药物制造和癌症的筛查评估等医学研究任务提供丰富的信息判据(Liu等,2017a)。
然而,复杂的时空场景和背景干扰,使得相衬显微图像序列中的有丝分裂细胞检测任务充满挑战(Liu等,2017a;Su等,2021)。在空间上,有丝分裂细胞往往具有不规则的外观,在形态、纹理和方向等方面具有较大差异,而不处于分裂期的普通细胞的视觉模式也可能与有丝分裂细胞相似,这大大增加了分裂状态的检测难度。不同培养条件下细胞的空间分布和亮度特性也存在显著区别,使目标区域的筛选面临困难。在时间上,由于细胞发育过程的可变形特性,不同细胞间和同一细胞在分类周期的不同阶段都具有多样性的外观表现,这对关键时序的检测提出了挑战。此外,随着细胞培育过程进行,培养皿中的细胞密度也会急剧增加,使多个细胞相互靠近,待检测目标因此更容易受到背景细胞的干扰。
在早期发展过程中,研究者利用传统机器学习技术,通过细胞簇分离(Yang 等,2005)、均值偏移算法(Debeir 等,2005)、水平集算法和双边滤波器(Li等,2008)、卡尔曼滤波器和局部图匹配(Liu 等,2017b)等方法进行细胞跟踪和分裂检测。也有一些方法无需进行跟踪,而是根据任务设计了特定的预处理和事件检测技术。例如,Li 和Kanade(2009)和Liu 等人(2013)通过凸函数优化实现图像预处理;Liu 等 人(2010a)用支持向量机(support vector machine,SVM)分类器实现细胞分裂事件检测;Marcuzzo 等人(2009)利用收敛指数滤波器检测细胞核;Quelhas 等人(2010)结合图像配准和光流分析来搜索分裂细胞。为充分利用序列图像间的关联信息,不少研究者用图模型实现时空联合的细胞状态建模和预测。Gallardo 等人(2004)训练多个不同的隐马尔可夫模型对图像块进行分类。Liang 等人(2007)利用条件随机场模型来克服有丝分裂检测任务中的少样本和数据多样性问题。Huh等人(2011)进一步提出事件检测的条件随机场方法,利用分裂事件的时序信息强调细胞的动态变化。Liu等人(2010b)定义成像模型来筛选细胞分裂区域,并学习隐式条件随机场分类器对候选区域进行分类。然而,传统机器学习方法的特征提取和序列建模能力有限,在复杂图像场景下往往难以得到鲁棒的检测结果。
随着深度学习的兴起,基于深度神经网络的方法在许多医学影像分析任务中获得了应用(蒋希等,2022),也为有丝分裂细胞的自动检测提供了新的方向。在相衬显微图像序列中,由于细胞和背景之间、不同类型细胞之间容易产生干扰和混淆,需要结合图像的模态特性和细胞区域的时空特征来设计方法框架。Nie 等人(2016)首次提出使用三维的卷积神经网络(convolutional neural network,CNN)来提取细胞分裂过程中局部时空区域的特征,并采用支持向量机分类器对区域是否属于有丝分裂细胞进行分类。Nishimura 和 Bise(2020)基于前背景亮度差异提取可能包含有丝分裂细胞的候选区域,再用V-Net 网络(Milletari 等,2016)进行端到端的候选区域热力图估计,直接预测有丝分裂出现的时空位置。这些方法在模型中使用了三维卷积和池化操作,能够提取时序特征,但所需的模型参数量和计算量过大,处理速度较慢。Mao 和Yin(2016)使用多个二维卷积网络来分别提取细胞区域的外观和运动特征,并基于多层分级结构实现序列特征的融合来综合预测细胞类别。Su 等人(2017)将卷积网络与长短时记忆(long short term memory,LSTM)网络(Hochreiter和Schmidhuber,1997)结合,把卷积网络提取的图像块的特征输入LSTM 进行切片间的关系建模和预测。在此基础上,Lu 等人(2020)设计了显著性导向的深度网络,额外进行序列显著性和序列结构学习,同时实现有丝分裂细胞的识别和定位。Su 等人(2022)将分裂过程中关键帧的查询视为马尔可夫过程,并引入深度强化学习,通过细胞识别模块的激励来学习关键帧选择过程中的决策准则。
多数现有深度学习方法的基本思路是首先通过基于亮度的预处理进行区域筛选,再将空间特征编码网络与时序网络级联预测,融合时空特征进行端到端训练。然而,该框架仍然存在两个亟待解决的问题。一方面,基于亮度的图像特征判别处理能力有限,复杂场景下筛选结果冗余性大,影响后续预测的效率和精度;另一方面,训练过程缺乏对于区域编码的显式监督学习,从时序网络到编码网络的梯度衰减导致端到端优化难以为底层的特征编码过程提供有效监督,使编码网络不能充分学习不同类别细胞以及背景区域之间的多样化语义区别。
为了解决上述问题,本文提出新的3 阶段检测模型。首先,针对复杂场景导致的区域冗余性问题,本文结合DeepLabV3+深度分割网络和先验优化算法进行序列预处理,逐步提高筛选精度,得到候选细胞区域;然后,针对多样化目标区域的特征学习问题,本文提出新的预训练策略,用CNN 编码网络提取候选区域的外观和运动特征,并通过设计图像分类和图像重构两种辅助任务为编码网络提供直接监督,强化网络对细胞不同状态模式的感知和区分能力;最终,基于预处理得到的候选区域和预训练得到的编码网络进行CNN—双向LSTM 时空模型的端到端训练和预测,实现复杂场景下的精准检测。
本文的主要贡献如下:1)提出了一种新的相衬显微图像序列中有丝分裂细胞检测框架,通过设计多层次的检测过程和多阶段的训练策略来由粗到精对图像序列进行预测,逐步优化检测结果。2)提出了两阶段预处理策略,结合可学习的深度网络和基于先验假设的优化算法,提升预处理过程的区域筛选精度。3)提出了基于辅助任务的编码网络预训练方案,通过分类任务训练外观编码网络的空间特征提取能力,通过重构任务训练运动编码网络的区域变化感知能力,解决了编码网络优化困难的问题,使候选区域的特征编码具备更强的判别性。4)剖析了在复杂图像场景中进行细胞检测的任务难点,进行针对性的方法设计,达到比现有方法更高精度和更加稳定的检测结果。
1 本文方法
1.1 任务概述
有丝分裂细胞检测任务中,输入一段连续的相衬显微图像序列,要求对序列中出现的有丝分裂细胞进行检测,输出其所在的时间和空间坐标。由于该任务需要在时空两个维度进行预测,当前的主流思路是首先用预处理过滤无关的背景区域,提取候选的细胞区域,再通过对时空特征的关联分析来优化候选区域,得到最终检测结果。其中,在预处理阶段,现有方法多采用基于亮度的阈值化方法进行区域选择(Mao 和Yin,2016;Nishimura 和Bise,2020)。这种方法虽然过程较为简明,但由于缺乏对细胞外观的高层语义理解,得到的结果中包含较多背景区域和不处于分裂期的普通细胞,冗余性较大。而在时空特征关联阶段,典型的做法是将每帧独立的空间特征编码(如CNN 网络)和连续多帧的时序状态建模(如LSTM 网络)结合进行端到端训练,预测细胞的分类结果并通过标签进行监督(Mao 等,2016;Lu 等,2020)。该过程通过检测结果误差的梯度反向传播进行联合优化,由于从时序到空间网络的传播过程存在梯度衰减,仅基于端到端的学习优化难以保证特征编码网络具备对不同细胞模式的感知能力。
针对现有方法在预处理和时空特征关联过程中存在的问题,本文提出一种基于外观和运动模式感知的多阶段细胞有丝分裂检测方案,整体框架如图1所示。本文方法主要分为3 个部分:1)候选区域预处理。在预处理过程中,针对亮度阈值化方法存在的区域冗余性问题,采用将深度网络和基于先验假设的优化算法相结合的方式进行区域筛选,充分精简候选区域;2)编码网络预训练。针对候选区域特征编码的学习优化问题,将编码网络分为外观编码和运动编码两部分,分别设计对应的辅助任务为编码过程提供直接监督,提升对于细胞间不同外观和运动模式的语义感知能力;3)空间—时间全模型训练和预测。将预训练得到的空间编码网络与时序网络相结合,建模候选区域的时空特征,得到最终检测结果。

图1 整体框架图Fig.1 The overall framework
1.2 候选区域预处理
原始电镜图像序列长、分辨率高,而细胞所占面积小,因而图像数据中绝大部分是与细胞分裂过程无关的背景区域。而由于有丝分裂过程发展较快,在可见的细胞中处于有丝分裂阶段的个体数量更为稀少。在细胞群发展的早期阶段,图像中大部分区域不包含任何细胞,而在发展后期,则会出现大量处于分裂间期的细胞。因此,通过预处理来剔除无关信息的干扰,筛选出可能包含有丝分裂行为的时空区域对于实现高效的细胞检测十分重要。
此前的预处理方法需要在图像上进行遍历式的滑窗搜索,基于细胞区域所特有的亮度差异来确定候选区域。这种方式下预处理结果受到窗口大小和亮度差异阈值等超参数设置的影响较大,且预处理后得到的候选区域往往仍具有较大的冗余性,精准率较低(Mao 和Yin,2016)。为了在预处理阶段得到更加精简的候选区域,提高后续预测的效率。本文采用两阶段的预处理过程:第1 部分使用可学习的预分割网络从电镜图像序列中分割出潜在的兴趣区域;第2部分对第1部分提取的兴趣区域进行整合与优化,依据细胞分裂过程在时空关系上的先验来滤除冗余的兴趣区域,得到精简的预分割结果作为有丝分裂细胞候选区域。
1.2.1 兴趣区域预分割
深度网络通过训练和学习具备强大的语义表征能力(曹家乐 等,2022),相比传统的亮度阈值类方法可以更好地理解图像区域的复杂视觉模式,对不同形态的分裂期细胞具有更强的识别能力。如图2所示,本文首先使用可学习的深度预分割网络,以热力图估计的形式预测潜在的候选区域。

图2 兴趣区域预分割Fig.2 Pre-segmentation of regions of interest
本文采用图像分割领域经典的DeepLabV3+模型(Chen 等,2018)作为预分割网络。该模型具有编码—解码结构和多尺度的空间特征提取模块,可以较好地关注预分割任务所需的局部语义。如图2 所示,为降低训练所需的显存同时保留图像数据中的信息,首先将全分辨率(1 392 × 1 040 像素)的电镜图像在横向和纵向上分别4 等分,得到16 个切片图像后分别处理。考虑到细胞有丝分裂是一个动态过程,本文将切片图像依据时间顺序取对应位置的前后3 帧切片,连接成三通道的伪彩色图像作为预分割网络的输入。这样,网络通过连续3 帧的切片外观信息,足以对是否存在候选区域做出初步判断。预分割网络输出单通道的分割概率图,通过有丝分裂坐标点转换得到的概率图标签进行监督。设有丝分裂点坐标为(xl,yl),则对应的概率图标签为
式中,d(x,y)=表示从图中任意位置(x,y)到有丝分裂点的距离,这样就以有丝分裂点为中心、r为半径构造出了伪分割标签,越靠近分裂中心点标签值越高。通过对伪标签的拟合,预分割网络可以对存在有丝分裂的区域给出较高的预测值,从而达到筛选候选区域的目的。实际训练中,由于有丝分裂细胞较为稀疏,为保证前景和背景像素点具有合理的样本比例,本文仅利用切片中包含有丝分裂细胞的图像数据进行预分割网络训练。测试时,每帧图像输入预分割网络得到候选区域的预分割概率图,再通过候选区域优化算法对密集的概率预测进行精简和优化。
1.2.2 候选区域优化
预分割网络的检测结果具有很高的召回率,能够最大程度地保留潜在的有丝分裂细胞样本。但由于没有考虑更加长程的时序信息,容易导致同一细胞区域在不同时刻被重复检出,因此精准率仍然较低。本文基于细胞运动过程的先验假设,即细胞在相邻时序中的位移相对较小,设计了候选区域优化算法,对时空近邻的区域进行整合。伪代码如下:
如上述伪代码所示,步骤1)中设置概率阈值Rp,循环提取预分割概率图中高于Rp的最大值位置作为兴趣区域中心点,并将该位置半径Rr范围内概率置0,保证邻域内的区域提取结果不重复;步骤2)中设置时间阈值Rt和空间阈值Rxy,对时空重叠程度较高的区域位置进行合并,同一时空范围内只保留概率最大的候选结果,使预处理结果更加精简,进一步提高了检测的效率。两阶段预处理前后的性能对比表明,本文的预处理方法可以有效提取候选区域并保持较高的召回率。
1.3 编码网络预训练
利用多帧切片的时空信息可以更好地学习和预测细胞的有丝分裂过程,为此需要将局部的特征编码网络和长程的时序网络相结合。然而,现有方法的训练过程只通过时序网络的最终预测结果进行监督,而对时序网络之前的特征编码缺乏直接优化。为了提升特征编码网络对于不同细胞状态的语义建模能力,本文提出一种基于空间模式感知的编码网络预训练策略,通过构造辅助任务来直接训练特征编码网络,从而为后续空间—时间全模型的端到端训练提供充分的视觉模式感知能力。
细胞区域的视觉模式可以分为静态和动态两方面。静态视觉模式是指细胞区域在一帧图像内有特定的形态和空间分布,动态视觉模式细胞在相邻两帧之间具有特定的运动变化过程。如图3 所示,本文设计了外观和运动两种编码网络来对候选区域进行特征编码,其中外观编码网络学习细胞的静态视觉模式,并通过图像分类的辅助任务进行显式的监督训练;运动编码网络学习细胞的动态运动模式,基于图像重构的辅助任务进行训练优化。

图3 编码网络预训练Fig.3 The pre-training of encoding networks((a)pre-training of the appearance encoder;(b)pre-training of the motion encoder)
1.3.1 预训练数据构造
辅助任务的学习过程首先需要构造不同类型的样本和对应的标签。为使训练所用的正负样本更加接近实际预测过程,本文用1.2.1 节中训练完成的DeepLabV3+模型对训练集数据进行重新预测,从预测得到的候选区域中选择样本(取40 × 40切片),不同类别样本的选择如图4所示。

图4 特征相似度与样本选择Fig.4 Feature similarity and sample selection
在分裂时刻附近,细胞的外观会发生显著变化(如形态变圆、亮度提升等),通过选取分裂细胞周围的时空区域作为正样本,选取未分裂细胞和背景区域作为负样本,可以训练编码网络更好地理解分裂细胞所特有的模式信息。然而,细胞从常规状态发展到分裂状态存在较长的过渡过程,在此期间细胞外观缓慢变化,为了避免训练过程使用的标签产生歧义,需要对细胞的不同时期进行明确的类别划分。图4 分别统计了训练集中分裂前1 帧(t-1)和分裂后1帧(t)图像相对于其他时刻图像的特征余弦相似度。可见,分裂时刻前后3 帧内的图像区域具有较为明显的分裂期特性,特征相似度高,用于构造正样本,其中前3 帧标记为“分裂前”类别,后3 帧标记为“分裂后”类别;与分裂时刻时序间隔8 帧以上的图像区域与有丝分裂区域之间有明确的特征差异,用于构造负样本,标记为“未分裂”类别;其他时刻的图像区域不用于训练。这样,构造出的正负样本对具有较为明确的语义区分,不会产生混淆而误导编码训练过程。同时,相较于直接使用标签点来构造样本,通过上述策略构造的样本不仅更贴近测试时的实际网络输入,减小了训练和测试阶段的差异,也具有更好的空间分布多样性。
1.3.2 外观编码预训练
预训练的目标是为编码网络提供直接监督,根据任务要求针对性地优化候选区域的特征提取过程。其中,外观编码网络旨在提取候选区域的视觉语义特征,特征信息应当具有足够的判别性,能够区分处于不同阶段的细胞和背景区域。基于上述考虑,本文设计了分类辅助任务对外观编码网络进行预训练。其基本思想在于:如果编码网络能够正确地分类候选区域,说明其学习到了类别间的判别性信息,具备识别类别特有的外观模式的能力。
如图3(a)所示,外观编码网络f由3个卷积核大小分别为7、6和4的卷积模块构成,每个卷积模块由一个不使用边界填充(padding)的卷积层和一个线性整流函数(rectified linear unit,ReLU)构成。前两个卷积模块后分别用一个最大池化层降低特征分辨率。设输入样本为区域块I,经过外观编码网络处理后得到外观特征f(I)。将外观特征展开成一维特征向量后输入两个全连接层组成的分类器,最终得到三分类的预测结果,分别对应分裂前、分裂后和未分裂区域。预测结果通过均方误差(mean square error,MSE)损失进行监督,具体为
式中,φ为分类器函数,Y为候选区域的类别标签,Lmse表示均方误差损失函数。
在外观编码预训练中,编码网络需要根据候选区域的局部外观特征进行静态的分类判断,这使得训练后的编码网络能够区分类别间的视觉语义差异,具备对于区域外观模式的感知能力。
1.3.3 运动编码预训练
由图4 可见,细胞在分裂时刻前后的两帧中变化最为明显,结合相邻两帧的运动特征有助于理解细胞状态的变化过程,改善检测结果(Mao 和Yin,2016)。本文提出基于图像重构的辅助任务来进行运动编码网络的预训练,先用运动编码网络提取相邻两帧图像间的运动特征,再将运动特征与其中一帧的外观特征结合来预测和重构另一帧图像。其基本原理在于设置信息瓶颈来迫使网络学习运动特征,只有当编码网络能有效提取相邻两帧间的运动和变化信息,才能利用其中一帧来重构另一帧。
如图3(b)所示,运动编码预训练过程的输入为时序相邻、空间位置相同的区域块It和It+1。首先对两个区域图像分别用外观编码网络提取外观特征f(It)和f(It+1),然后将两个区域块同时输入运动编码网络g提取帧间运动特征g(It,It+1)。运动编码网络的结构与外观编码网络相同,但将第1 个卷积层改为两通道输入,使网络能够同时感知两帧图像。为保证提取到的特征确实包含了运动状态信息,采用基于图像重构的自监督学习进行运动编码网络的训练。对于图像块It,将运动编码特征和外观编码特征按通道方向连接后,输入运动解码网络d。该解码网络由三阶段卷积构成,每个阶段卷积都使用两个带ReLU 激活函数的3 × 3卷积层。前两个卷积阶段分别用一个反卷积(即转置卷积)层进行特征上采样,最终输出与输入图像块具有相同尺度的预测图像块Mt+1=d(g(It,It+1),f(It)),该预测结果用输入图像块It+1进行监督。同样地,将图像块It+1的外观编码特征与运动编码特征输入运动解码网络,输出预测结果为Mt=d(g(It,It+1),f(It+1)),用输入图像块It进行监督。整体的损失函数为
由式(3)可见,运动编码网络的预训练是一个自监督学习过程,不需要额外的数据标注,只利用图像本身的重构就可以实现有效的训练监督。图像重构任务天然构成信息瓶颈,由于两帧图像并不相同,运动编码特征必须能够表征从一帧图像到另一帧图像的动态变化,才能提供恢复另一图像块所需的信息。因此,该训练过程可以使得运动编码网络有效理解细胞在不同阶段下所特有的运动模式。
1.4 空间—时间全模型训练与预测
预训练使空间编码网络能够充分提取候选区域的外观和运动特征,为时序的状态记忆和预测提供所需信息。预训练结束后,将空间编码网络和时序网络级联进行空间—时间全模型(CNN—双向LSTM网络)的端到端训练,通过优化序列图像的时空特征表示来预测有丝分裂细胞。
如图5所示,模型输入为1.2小节预处理生成的候选区域序列,由1.3.2 小节中预训练得到的外观编码网络(N1)提取区域外观特征,由1.3.3 小节中预训练得到的运动编码网络(N2)提取区域运动特征。将两种区域特征按通道方向连接后输入双向的LSTM(Hochreiter 和Schmidhuber,1997)时序网络进行特征的时序状态记忆与更新。时序网络由12 组时序单元组成,每组时序单元包含一个前向LSTM单元和一个反向LSTM 单元,通过时序信息的传播动态地更新区域状态。每个LSTM 单元由遗忘门、输入门和输出门组成。遗忘门从区域状态中丢弃无用信息;输入门接收当前时刻的新信息来更新区域状态;输出门输出当前区域状态并进行时序信息传播。在t时刻,LSTM单元的处理过程可表示为
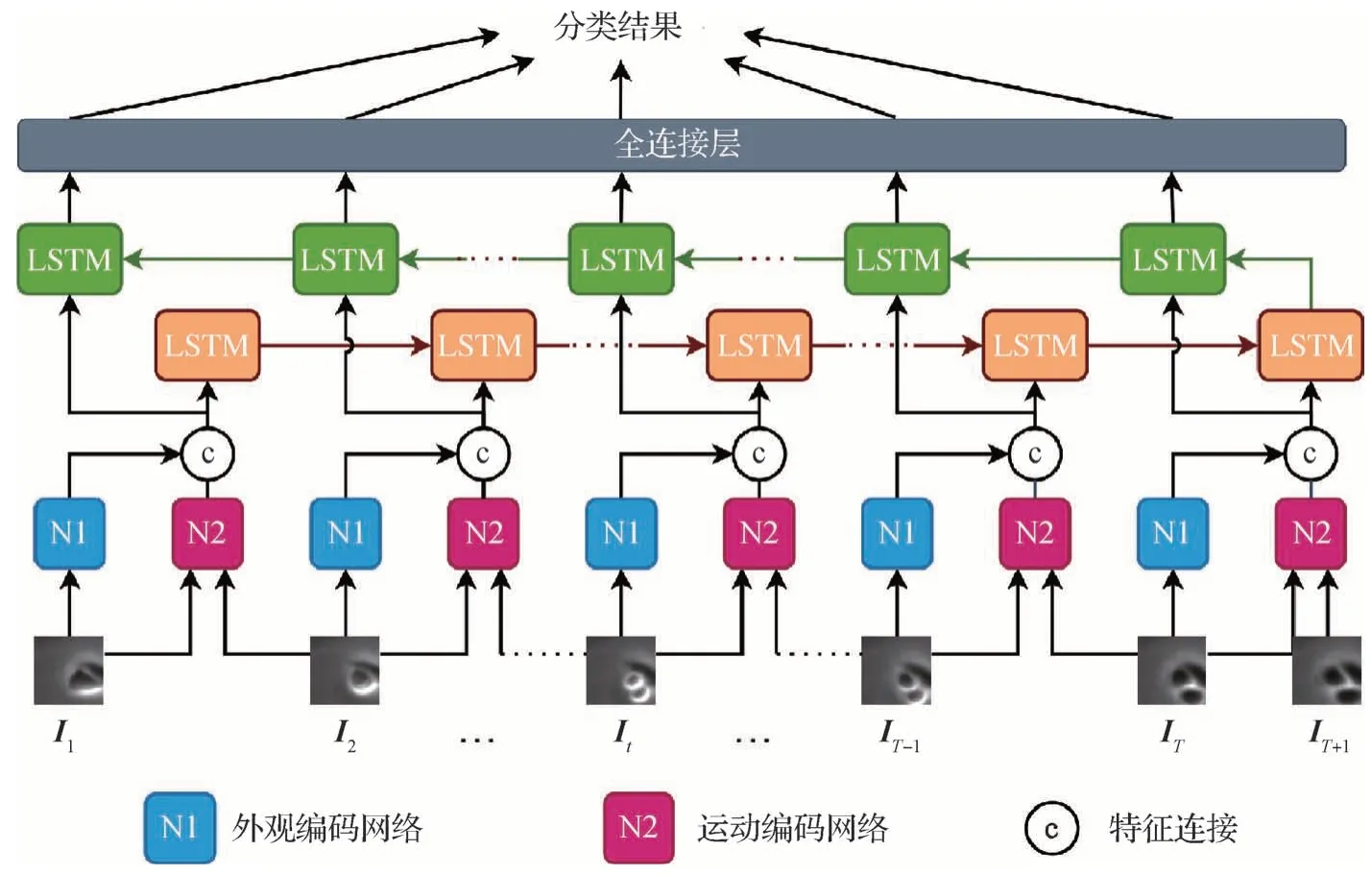
图5 CNN—双向LSTM检测网络Fig.5 CNN—bidirectional LSTM detection network
式中,it为输入门结果,ft为遗忘门结果,ot为输出门结果,ct为更新后的单元状态,ht为用于传播和输出的最终状态;W和b为可学习的权重和偏置参数,σ是sigmoid 激活函数;xt是将N1 和N2 网络的输出连接后得到的外观和运动联合特征;⊙表示对应位置相乘。由于预训练过程对N1和N2网络进行了直接的监督训练,在全模型训练初期就能为时序网络提供有效的语义信息,进而优化时序单元的训练过程。
最后,将每组时序单元的输出经过两层全连接层映射得到3 个预测值,分别对应分裂前、分裂后和未分裂状态,并由sigmoid 函数归一化得到对该时刻类别的概率预测训练时通过分类标签来进行端到端的监督学习,用均方误差损失进行监督,具体为
2 实验与分析
2.1 实验环境与设置
实验环境条件如下:在Ubuntu16.04 系统平台,使用单个具有11 GB 显存的GTX 1080Ti 显卡,基于PyTorch1.3.0深度学习框架进行训练和测试。
训练过程的参数设置如下:第1 阶段训练预分割网络时,批量大小设置为 5,以0.001 的学习率迭代训练500 个周期;第2 阶段编码网络预训练时,对于外观编码网络和运动编码网络,批量大小分别设置为4 000 和 200,两个网络都以0.000 5 的学习率迭代训练100 个周期;第3 阶段全模型训练时,批量大小设置为 400,以0.000 05的学习率迭代训练100个周期。训练过程使用Adam优化器。
2.2 数据集
实验数据集是由CVPR2019(IEEE Conference on Computer Vision and Pattern Recognition 2019)有丝分裂细胞检测竞赛提供的C2C12-16 数据集(Su等,2021)。该数据集包含16 个序列的成肌干细胞全载玻片相衬显微图像。每个序列中,细胞被随机放置于培养皿中并每隔5 min进行一次图像采样,共得到1 013 帧分辨率为1 392 × 1 040 像素的灰度图像。所有序列根据培养过程添加的不同药物分为4 组,其中第1 组不添加任何药物,第2 组单独添加成纤维生长因子2(fibroblast growth factor-2,FGF2),第3组单独添加骨形成蛋白2(bone morphogenetic protein-2,BMP2),第4组同时添加FGF2和BMP2。每组第1、2个序列作为训练集,第3个序列作为验证集,第4个序列作为测试集。图6对不同培养条件下的图像样本进行了比较,可见第2、4组图像包含更多与细胞分裂事件相关的高亮度区域,场景更加复杂。

图6 不同培养条件下的图像对比Fig.6 Comparison of images under different conditions
2.3 性能评价指标
采用平均精确率、平均召回率和平均F 得分作为对检测性能的评价指标。根据数据集官方设置,若检测出的有丝分裂细胞中心点位置与真实标签位置在时序上相差6 帧以内,在空间上相差15 个像素以内,则认为检测结果正确。此外,检测结果可根据对错分为真阳性(true positive,TP)、假阳性(false positive,FP)、真阴性(true negative,TN)和假阴性(false negative,FN)。
因此,F 得分是结合精确率和召回率的综合性指标。
2.4 实验结果
2.4.1 与现有方法的比较
本小节分别在C2C12-16 数据集的验证集和测试集上与EDCRF(event detection conditional random field)(Huh 等,2011)、V-Net(Nishimura 和Bise,2020)、MM-HCRF(max-margin hidden conditional random field)(Liu 等,2012)、3DCNN(Nie 等,2016)、CNN+LSTM(Su 等,2017)、SSG-DNN(sequential saliency guided deep neural network)(Lu 等,2020)、PSSD(progressive sequence saliency discovery network)(Su等,2022)和MViTv2(multiscale vision transformers:version 2)(Li 等,2022)方法进行比较。其中,EDCRF 和MM-HCRF 属于基于条件随机场的方法;V-Net和3DCNN 属于使用三维卷积网络的方法,CNN+LSTM 和SSG-DNN 属于结合二维卷积网络和时序网络的方法,PSSD 则进一步引入了强化学习。此外,MViTv2 是使用Transformer 架构的最新的通用目标检测方法。本文选取不同类型的方法进行对比,从而实现更加全面的分析。
本文方法与EDCRF、V-Net 和MViTv2 方法在验证集上的比较结果如表1所示。EDCRF采用尺度不变特征变换(scale-invariant feature transform,SIFT)算子,其在第2 组检测中F 得分为39.4%,而本文方法在该组得分达到85.0%,显示了其对于不同培养模式下得到的图像具有更好的泛化性。V-Net 使用三维卷积直接提取时空特征,模型参数量和计算量大,其预测结果召回率较高,而精确率较低。本文方法在4 组序列上的平均F 得分达到87.2%,比V-Net高出4.7%,具有更好的整体性能。此外,V-Net需要对每组序列训练不同的最优模型进行检测,但其在不同组中的性能表现仍然差异较大,最低精确率(第2 组)为64.6%,最低召回率(第4 组)为74.6%。相比之下,本文方法仅使用单模型进行全部4 组序列的预测,最低精确率(第4 组)达到79.4%,最低召回率(第2 组)达到85.3%,对不同组数据始终能得到较为稳定的检测结果。为了与最新的通用检测方法进行比较,本文用MViTv2 提供的代码和模型在本文任务上进行了重新训练和测试。MViTv2使用高复杂度的Transformer 架构,通过级联的自注意力模块实现特征编码,而本文方法只使用简单的卷积编码网络,通过辅助任务的预训练就获得了更加有效的区域特征,平均F 得分比MViTv2(79.2%)高8.0%。
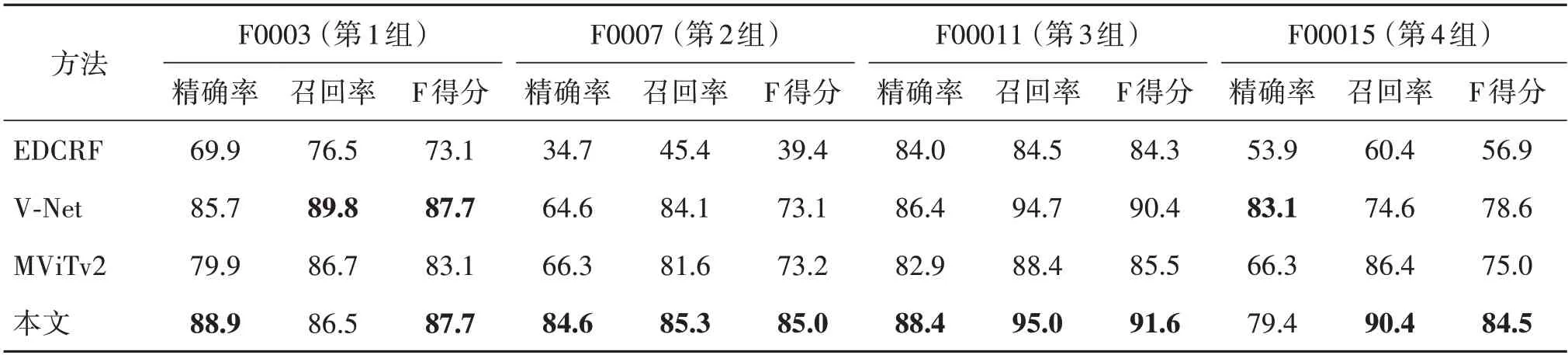
表1 C2C12-16验证集检测性能比较Table 1 Comparison of detection performance on C2C12-16 validation set/%
本文方法与MM-HCRF、3DCNN、CNN+LSTM,SSG-DNN,PSSD 和MViTv2 方法在测试集上的比较结果如表2 所示。基于神经网络的框架整体性能优于使用SIFT 特征算子的MM-HCRF。其中,本文方法在4 组序列的平均F 得分(86.2%)显著高于基于三维卷积网络的3DCNN 方法。相比于同样使用空间—时间模型架构的CNN+LSTM 和SSG-DNN,本文方法由于结合了静态的细胞外观信息和动态的运动变化信息,并针对两种编码网络构造了不同的辅助任务进行预训练,能更好地为时序网络的记忆和信息融合提供判别性的视觉语义,平均F得分比CNN+LSTM(70.1%)高16.1%,比SSG-DNN(79.6%)高6.6%。尤其在对较为困难的第2、4 组序列检测中,本文方法在保持较高召回率的同时,精确率分别达到了83.3%和83.2%,远高于其他方法,证明其对于复杂的图像场景和难以区分的样本仍然具有稳定的检测性能。

表2 C2C12-16测试集检测性能比较Table 2 Comparison of detection performance on C2C12-16 test set/%
近期研究中,PSSD 引入了深度强化学习来筛选序列中的关键帧,可以从长序列中关注到有丝分裂附近的时刻。从实验结果上看,PSSD 在C2C12-16测试集的第1、3组测试中取得较高精度,而在第2、4组测试中结果较差。这可能是由于第1、3 组的测试数据与训练数据更为接近,更有利于基于强化学习的帧选择策略发挥作用。此外,PSSD 方法的性能受到所使用的显著性帧数量这一超参数影响,不同超参数的选择会影响不同组的检测效果。从整体性能而言,PSSD 在4组序列中的F得分为85.7±6.2%,而本文方法的F 得分为86.2±4.2%,具有更高的平均预测精度,同时预测结果也更加稳定。此外,与最新的通用图像检测方法MViTv2相比,本文方法在训练集和测试集上都取得明显更优的性能表现,证明相比于在模型结构上进行调整,本文的预处理和预训练策略可以更好地提升复杂场景下的细胞检测能力。
2.4.2 消融实验
为检验不同模块在检测过程中的作用,本文在C2C12-16 测试集上进行了消融实验(取4 组平均结果)。整体框架分为3 个阶段:1)候选区域预处理阶段(S1)从图像序列中初步筛选出可能存在有丝分裂细胞的候选区域。2)编码网络预训练阶段(S2)构造辅助任务,训练外观和运动编码网络,学习从候选区域中提取判别性的语义特征。3)空间—时间全模型训练与预测阶段(S3)将预训练的空间编码网络与时序网络结合,通过端到端训练对预处理后的候选区域进行序列预测,得到最终的检测结果。
本文方法在不同阶段的检测性能如表3 所示。可见,预处理中使用深度网络进行兴趣区域预分割能有效地对潜在的候选区域进行筛选,同时保持很高的召回率(97.3%),充分保留处于分裂期的细胞区域。应用算法1 进行候选区域优化后,精确率从12.7%上升到了58.5%,说明该算法能够基于简单的时空先验对冗余的候选区域进行有效滤除,使得测试时的候选区域更为精简。全模型预测阶段基于时空特征进行预测,充分考虑了细胞的时序状态变化,将F 得分从70.8%提升到80.1%。而预训练阶段通过对外观编码网络和运动编码网络进行直接的监督学习,大大提升了编码网络对于不同细胞模式的语义感知能力,使S3 阶段的全模型训练更加充分,将F得分提高到了86.2%。

表3 不同阶段的检测性能比较Table 3 Comparison of detection performance at different stages /%
表4 展示了预处理阶段采用不同策略进行区域筛选的检测性能。现有方法主要根据亮度差异进行遍历搜索。其中,亮度均值法(Huh等,2011;Mao和Yin,2016)对图像进行均值滤波后设置阈值提取候选区域,达到1.2%的精确率(Mao和Yin,2016)。亮度标准差法(Su 等,2017)计算三维滑窗内的亮度标准差并设置阈值提取候选区域。本文对标准差法进行了复现,精准率仅为0.1%。相比于基于亮度的预处理方法,本文将预分割网络和先验优化算法结合的方式可以达到更高的精确率(58.5%),显著减少了候选区域中的冗余结果,提升检测效率。

表4 不同预处理方法的比较Table 4 Comparison of different pre-processing methods
为了进一步细化不同编码网络训练策略对于检测性能的影响,根据是否使用外观编码和运动编码预训练进行了消融实验,结果如表5所示。

表5 不同预训练策略的比较Table 5 Comparison of different pre-training strategies/%
不使用编码网络预训练时,全模型训练阶段的编码网络参数随机初始化,不具备有效的特征提取能力,难以为时序网络提供有效的细胞状态信息。而模型训练的反向传播过程需要经历全连接层、级联的LSTM 时序单元之后才能作用于CNN 编码网络,导致编码网络优化缓慢,进而使全模型收敛后的性能受限,最终检测结果的F 得分为80.7%。使用基于分类辅助任务的外观编码预训练后,外观编码网络能够为预测图像块类别提供必要的空间模式信息,在精确度和召回率指标上获得了全面提升。使用基于图像重构的运动编码预训练后,网络能够从区域外观变化中提取细胞的运动模式信息。单独对运动编码网络进行预训练,精确率提升6.4%,但召回率有所下降,这可能是由于网络过于依赖运动特征而忽视外观信息,导致对变化过程不明显的区域产生漏检。结合外观和运动编码可以有效解决对于细胞模式的单一类型感知导致的问题,在保持召回率的前提下大幅度提升精确率,最终将F 得分指标提升了5.5%。
图7 对使用预训练前后的检测结果进行了对比。其中青色边框表示真阳性(TP)检测结果,红色边框表示假阳性(FP)检测结果,黄色边框表示假阴性(FN)检测结果。由图7(a)可见,外观编码预训练使单帧图像的特征编码具有细胞类别的判别能力,相比于不进行预训练的模型能够更有效地排除假阳性,同时减少漏检的情况。由图7(b)可见,一些不处于分裂期的细胞也具有和分裂前细胞相似的外观特征,运动编码预训练使模型能结合候选区域的运动变化进行判断,识别出不符合有丝分裂变化过程的案例。
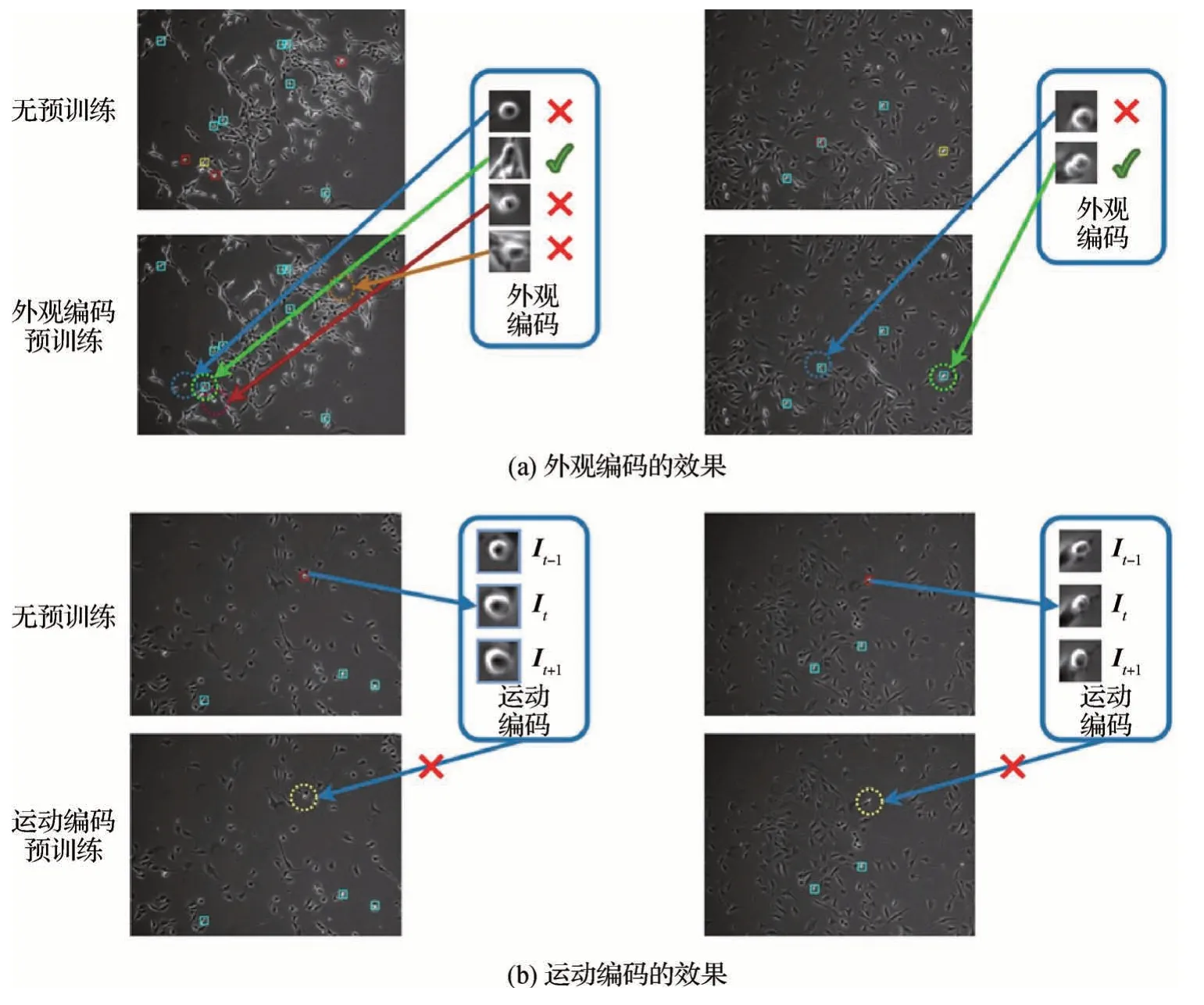
图7 预训练前后检测结果对比Fig.7 Comparison of detection results before and after pre-training((a)the effect of appearance encoding;(b)the effect of motion encoding)
在空间—时间全模型训练和预测阶段,本文使用LSTM 网络进行时序信息融合。LSTM 网络中特征逐帧传播的过程天然具有时序形式,适合于建模有丝分裂细胞的时序状态变化过程。除LSTM 外,Transformer模块同样可以实现序列化的信息处理和预测,但其时序信息需要通过在输入端加入时间位置编码来实现。同时,相比于LSTM 的逐帧传播,Transformer 模块需要密集的帧间交互,具有更大的模型容量和更高的计算复杂度。为了更直观地进行比较,将本文方法中的LSTM网络替换为Transformer编码网络(采用原论文设置)进行实验,表6 展示了对应方法的平均F 得分、单序列输入下所需的每秒浮点数计算量(floating-point operation per second,FLOPs)以及模型参数量。将LSTM 网络替换为Transformer 进行时序建模增加了模型参数量和计算量,同时检测精度反而降低。这可能有两方面原因:一是Transformer 网络的模型复杂度较高,需要较大数据量的训练或更加精细的初始化策略来达到较好的性能(Raghu 等,2021;Matsoukas 等,2021)。二是Transformer 通过额外的位置编码对时间维度进行建模,在有丝分裂细胞检测任务中其时序建模效果和LSTM 网络存在差距。本文最终选择LSTM 以更加适应于任务本身的数据规模和性能需求。

表6 不同时序网络检测性能和代价对比Table 6 Comparison of detection performance and cost using different temporal networks
2.4.3 可视化与误差分析
图8 展示了按时间顺序对不同组的检测结果进行的可视化。随着时间推移,相衬显微图像中的场景变得更加复杂,发生的有丝分裂情况也更多。由图8 可见,在不同分组的培养条件和不同的时序阶段下,本文方法都能从复杂场景中排除背景和未分裂细胞的干扰,检测出大部分有丝分裂细胞。
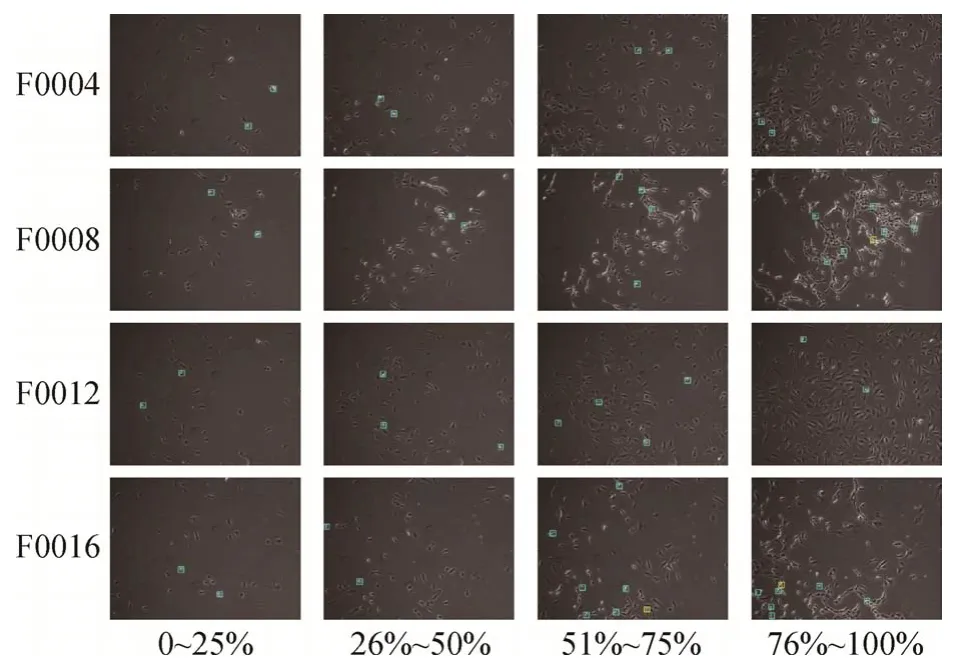
图8 时序检测结果可视化Fig.8 Visualization of temporal detection results
本文方法也存在一些预测失败的案例。如图9所示,当候选区域具有典型的外观和运动模式时,本文方法可以做出精准的识别和检测,但当细胞外观语义模糊以及运动特征不明显时,会出现一些误检(FP)和漏检(FN)的情况,这可能是由于训练过程缺乏对于此类样本的学习。

图9 误检测案例分析Fig.9 Analysis of failure cases
表7 对检测结果的时序偏差和空间偏差进行了量化统计。在4 组测试序列中,本文方法的最小时序偏差均值为0.203帧,最大时序偏差均值为0.242帧;最小空间偏差均值为3.137 像素,最大空间偏差均值为3.561 像素。可见,本文方法对不同组实验条件下的图像检测能力相差不大,检测结果具有一致性。此外,时序和空间上的最大标准差仅为0.618帧和2.603像素,体现了本文方法的预测性能具有较强的稳定性。

表7 检测结果的时空偏差Table 7 Spatiotemporal biases of detection results
图10 对比了本文方法和CNN+LSTM(Su 等,2017)以及 PSSD(Su 等,2022)在不同组序列的时序偏差。其中,柱状图为偏差平均值,折线为偏差的标准差。由图10 可见,CNN+LSTM 方法的检测结果时序偏差较大(平均1.05 帧),且不同组的检测偏差变化范围大,对于第2、4 组的困难场景的检测偏差显著高于第1、3 组中的偏差。与之相比,本文方法在4 组序列中的表现较为平均,时序偏差均始终保持在不到0.25 帧的低数值。这主要是由于本文方法采用了编码网络预训练策略,能够从复杂多样的图像场景中关注到候选区域的外观和运动变化等本质信息,使得时序预测结果更加稳定可靠。相比于PSSD 方法,尽管本文没有显式的显著性帧检测过程,但编码网络可以有效识别具有分裂期特征的关键时序,达到更低的检测偏差均值和标准差。

图10 不同方法的时序偏差对比Fig.10 Comparison of temporal biases of different methods
3 结论
本文针对复杂显微图像场景中的有丝分裂细胞检测任务,设计了基于外观和运动模式感知的模型学习框架。该框架由3 个阶段组成,在第1 阶段,结合深度预分割网络和候选区域优化算法对长序列高分辨率的电镜图像序列进行预处理,筛选可能存在有丝分裂细胞的候选区域;第2 阶段构造辅助任务来预训练外观和运动编码网络,对候选区域的编码过程实现直接的监督优化,提供具有判别性的区域内细胞模式信息;第3 阶段基于预训练权重进行空间—时序网络的全模型训练和预测,结合时空特征从候选区域序列中检测出有丝分裂细胞。与现有方法相比,本文的预处理策略结合了可学习的有参网络和基于先验假设的无参优化过程,可以更好地在保持目标召回率的同时过滤无关区域,大幅度精简后续预测过程。本文提出的预训练策略可以为编码网络提供检测任务所需的区域状态感知能力,进而使时序网络更加充分地融合时空信息,提升全模型的预测能力。在C2C12-16 数据集上的实验结果显示,本文方法达到了比其他方法更强的检测性能和更好的稳定性,且在不同实验条件下的图像检测效果具有一致性。
本文方法的重点在于设计预处理策略来提高检测效率和设计预训练策略来优化编码网络的训练过程,而没有在数据分布层面针对任务进行设计。后续研究可以尝试更加多样和均衡的数据增广策略来强化模型对少见样本的检测能力。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
阅读(快乐英语高年级)(2022年6期)2022-06-17
中国农业信息(2021年3期)2021-11-22
家庭影院技术(2021年10期)2021-11-20
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
电子制作(2017年13期)2017-12-15
紫禁城(2017年6期)2017-08-07
