
融合隐向量对齐和Swin Transformer的OCTA血管分割
2023-09-26 04:22许聪郝华颖王阳马煜辉阎岐峰陈浜马韶东王效贵赵一天
中国图象图形学报 2023年9期
许聪,郝华颖,王阳,马煜辉,阎岐峰,陈浜,马韶东,王效贵,赵一天*
1.浙江工业大学机械工程学院,杭州 310000;2.中国科学院宁波材料技术与工程研究所慈溪生物医学工程研究所,宁波 315201;3.中国科学院空天信息创新研究院,北京 100094
0 引言
血管系统是视网膜中最重要的生物组织结构之一。视网膜血管的形态变化与系统性、代谢性和血液系统疾病密切相关(Mou等,2019),能够帮助眼科医生了解疾病的发展情况以及评估治疗效果(Zhao等,2018)。因此,对视网膜血管形态进行量化分析,可以辅助医生对相关疾病进行早期诊断,从而使患者在疾病的早期阶段或发展出不可逆转的病理之前得到有效治疗。
临床实践中,眼底彩照技术是最常见的一种视网膜成像技术,但由于成像设备的限制,眼底彩照只能显示较粗的视网膜血管,难以拍摄到黄斑周围的微血管信息,如图1(a)所示。而眼底荧光血管技术可以显示包括毛细血管在内的视网膜血管系统,但这些方法需要经静脉注射造影剂,相对耗时且可能存在严重的副作用(Witmer等,2013)。

图1 同一只眼睛眼底彩照中的黄斑中央凹示意(绿框区域)及其不同深度的OCTA 2维正面投影图像Fig.1 Illustration of the fovea(green rectangle region)in the color fundus image and OCTA enface images at different depth of the same eye((a)color fundus;(b)SVC;(c)DVC;(d)SVC+DVC)
相比之下,光学相干断层扫描血管造影技术(optical coherence tomography angiography,OCTA)存在显著优势。OCTA 作为一种高速、非侵入式的新兴成像技术,能够对生物组织进行高分辨率成像(Hormel 等,2021),已经成为视网膜血管成像及其评估的重要工具(Leitgeb,2019)。OCTA 技术可以对不同视网膜层的血管结构进行投影,从而实现相应视网膜血管丛的独立可视化。例如,美国Optovue公司生产的RTVue XR 二代SD-OCT 系统在配备AngioVue 软件(版本2015.1.0.90)下,能够生成不同深度视网膜血管丛的二维正面投影图像(enface):浅层血管复合体(superficial vascular complexes,SVC)、深层血管复合体(deep vascular complexes,DVC)以及内层视网膜血管丛,包括SVC 和DVC(SVC+DVC),如图1(b)—(d)所示。这种独特的观察视角提高了临床和研究领域对视网膜血管系统的病理学认识。临床医生可以凭借不同深度层的enface 图像,观察相应的血管结构,并通过分析血管结构的变化来判断是否存在相关疾病。特别是对于黄斑周围微血管(包括细血管和毛细血管),它的任何异常变化,通常都意味着存在某种眼科疾病,如早期青光眼神经病变(Alam 等,2018)、糖尿病视网膜病变(Zhao 等,2017)和年龄相关性黄斑变性(Zhang等,2020)等。此外,有研究表明(Yoon 等,2019),OCTA 图像显示的眼底微血管形态结构的改变和阿尔兹海默症等神经退行性疾病相关。因此,基于OCTA 图像的不同深度的enface 图像来实现视网膜血管结构的自动分割和定量分析对于相关疾病的早期诊断和疾病治疗具有重要意义。
目前,基于OCTA 图像的工作受到了广泛关注,包括图像去伪影、图像去噪、动静脉分类和疾病分类等。但基于OCTA 图像的血管自动分割任务的研究较少,难点主要包括:1)在 OCTA 成像过程中,不可避免地受到OCT 系统成像过程中固有的散斑噪声的干扰(Szkulmowski 等,2012),从而生成低信噪比的图像,对视网膜血管的自动分割精度带来严重影响;2)不同深度层的血管外观变化、运动和阴影伪影,以及潜在的病理结构都显著增加了视网膜血管精准分割的难度。目前,基于深度学习的方法主要是通过基于区域的学习(Zhang 等,2019),这种技术对于那些紧密连接的毛细血管很容易产生不连续、不精确的分割结果,这意味着当需要检测粗细、成像深度都不相同的血管结构时,这些方法难以满足现阶段的临床需求。因此,基于深度学习的OCTA 图像血管自动分割仍然是一项极具挑战性的任务。
针对OCTA 图像视网膜血管结构精准分割面临的挑战,本文提出一种端到端的视网膜血管分割网络,包括用于融合3 种enface图像的卷积块、基于Swin Tranformer 的特征编码器以及隐向量对齐模块。首先,所提方法对SVC、DVC 和SVC+DVC 3 种enface 图像进行融合并输入分割网络中,旨在丰富输入网络的图像特征信息,而且通过图像融合能够一定程度上缓解OCTA 图像中的散斑噪声和伪影对分割的干扰。然后,采用Swin Transformer 编码器从输入图像中提取丰富的特征,并从隐空间层次设计了一个特征对齐损失函数,以获得更精准的整体分割结果。最后,从定性和定量两个角度对OCTA 血管分割工作进行全面评估。实验结果表明,本文方法在两个不同设备采集的OCTA 图像中均能够得到优于对比方法的分割结果。
1 相关研究进展
过去20 年,基于眼底彩照的视网膜血管分割取得了令人瞩目的成绩。例如,基于各种滤波器的方法,包括匹配滤波器(Zhang 等,2016)、对称滤波器(Zhao 等,2018)、多方向滤波器(Zhang 等,2017)等,通过抑制非血管结构和图像噪声,增强图像中的血管结构,达到降低血管分割任务难度的目的。基于分类器的方法(Wang等,2015)能够提取像素附近区域的相关特征,将每个像素分为血管类和非血管类两类,实现血管的分割。基于深度学习的方法(Yan等,2018;Jin 等,2019)提取整个输入图像的浅层与深层特征,将它们进行编码和解码,通过学习血管结构信息来对血管和非血管区域进行识别。
目前,在OCTA 图像中进行视网膜血管自动分割的研究相对较少,现有的大多数方法都是基于阈值的方法。Yousefi 等人(2015)将基于Hessian 滤波器的形状分割方法与基于强度的分割方法相结合来对血管进行分割。Camino 等人(2018)通过对血管造影和反射信号进行回归分析,设置出基于反射率调整的最佳阈值,实现了对眼底血管结构的自动分割。然而,这些基于阈值的方法存在一定局限性,当血管结构与背景的强度差异不明显时,很难有良好的表现,而且对分布在OCTA 图像上的散斑噪声十分敏感。Eladawi 等人(2017)利用高斯—马尔可夫随机场模型来降低噪声,提高OCTA 图像的对比度,从而提升分割准确率。尽管该方法能够有效去除噪声,但在去噪过程中难以精确区分大血管与毛细血管丛,有时甚至无法准确识别大血管结构的边界,从而影响分割精度(Li 等人,2020)。随着深度学习在医学图像领域的不断发展,研究人员开始研究基于深度学习的OCTA 图像视网膜血管分割。Ma 等人(2021)提出了一个基于编码器—解码器的粗细血管分割网络,能够分别检测粗血管和细血管,并首次在视网膜图像分析领域构建了一个OCTA 分割数据集ROSE(retinal OCT-Angiography vessel segmentation);Li等人(2020)构建了一种能够同时进行特征选择和降维的投影学习模块,使得网络能够实现输入3D OCTA数据,输出2D的enface分割结果。
近几年,Transformer 成为医学图像分析领域(Zhang 等,2021a;Huang 等,2021)关注的重点。得益于注意力机制建立的图像输入和输出之间的全局依赖关系,基于Transformer 的模型已经在图像分割(Deng 等,2021)、图像分类(Dai 等,2021)、图像重建(Wang 等,2021;刘花成 等,2022)、疾病诊断(赵琛琦 等,2022)、图像增强(McCollough 等,2017)和图像检测(Shen 等,2021)等诸多领域取得了非常好的结果。在医学图像分割领域,Chen 等人(2021)首先提出TransUNet,它同时具备Transformer 和U-Net 的优点,拥有强大的编码和细节恢复能力;Valanarasu等人(2021)针对医学图像样本数量相对较少的问题,提出一种门控位置轴向注意力机制,获得了优异的分割性能;Zhang 等人(2021b)提出一种基于Transformer 和body-edge 分支的多分支混合网络,分割性能超过了当时最先进的方法;Hatamizadeh 等人(2022)利用Transformer作为编码器来学习输入图像的特征,能够有效捕获全局多尺度信息;Cao 等人(2021)提出一种类似U-Net 的Transformer 网络,在多器官分割任务中表现优异。与上述方法不同,本文方法将Swin Transformer 与残差连接相结合,有效强化了编码器的表征能力,提升了整体的分割性能。
2 研究方法
本文网络结构如图2 所示,包括Swin Transformer 模块与残差结构相结合的特征提取编码器和基于标签自编码的隐向量对齐损失函数。

图2 OCTA血管分割网络框架Fig.2 OCTA vessel segmentation network framework
2.1 编码器—解码器架构
U 形编码器—解码器架构是本文所提出网络的主体结构。首先通过卷积块将输入的3 种enface 图像,即SVC、DVC和SVC+DVC,进行图像融合,从而能够为编码器输入丰富的图像信息,并一定程度上缓解了OCTA图像中的散斑噪声和伪影对分割的干扰。
编码器能够提取融合图像的浅层和深层特征,并通过跳跃连接与解码器相结合,将编码器提取的各个层次的特征与解码器上采样得到的特征相融合,得到最终的血管分割结果。具体来说,对于编码器模块,经典的U-Net 的编码器结构为VGG(Visual Geometry Group)结构,即每一层都由两个3 × 3 的卷积核、线性整流函数ReLU 和步长为2的最大池化层组成。随着残差模块ResNet、密集连接模块DenseNet 和Transformer 模块的相继提出,神经网络对输入图像的特征提取能力得到了显著的增强。考虑到网络的输入是3 种不同层的OCTA enface 图像,因此,为了提取更丰富的图像特征信息,本文将ResU-Net 网络作为基础网络(编码和解码器层由残差块和池化层组成),将Swin Transformer 引入ResUNet 中组成新的编码器结构。特征编码器的编码步骤包括4 个不同阶段,每个阶段都由两层组成,即数个堆叠在一起的Swin Transformer 块组成的Transformer层和残差结构。
如图3 所示,Swin Transformer 块由一个基于窗口的多头自注意力模块(window-based muti-head self attention,W-MSA)和一个基于移位窗口的多头自注意力模块(shifted window-based muti-head self attention,SW-MSA)以及两个多层感知器(multilayer perceptron,MLP)组成,在每个MSA 模块和MLP模块之前应用层归一化(LayerNorm,LN)层,并在相应模块之后应用残差连接,从而能够有效提升编码模块的表征能力。具体到详细的编码步骤,在编码器的每个阶段过程中,输入的融合图像首先分割为大小为4 × 4的非重叠局部区域,这些局部区域将作为标记并输入到Transformer层中。而Transformer层中的线性嵌入层能够有效改变标记的特征维度,以适应每个阶段的编码需求,同时,具有线性计算复杂度的窗口注意力块和用于处理非重叠局部区域的跨窗口连接也能够有效提升对图像特征编码的能力。在每个阶段过程中,为了实现层次化表示,本文将特征图从缩小到,然后进行下一阶段局部区域合并。在之后的阶段中,迭代进行局部区域合并,以获得分辨率为的分层特征图,其中,i∈{1,2,3,4}。需要注意的是,在每个阶段的局部区域合并后,将特征图与输入该Transformer 层之前的特征图通过残差结构相加,所得到的结果通过跳跃连接与解码器上采样的特征图相结合。

图3 Swin Transformer模块Fig.3 Swin Transformer module
2.2 损失函数
在医学图像分割网络中,大多数损失函数是对网络输出端的预测结果进行约束,例如交叉熵、均方误差和Dice 系数损失函数等。这些损失是训练分割网络常用的像素级损失函数,通过梯度下降对端到端的网络参数进行优化。目前大部分工作只针对像素级的损失进行网络优化,而忽略了隐空间特征对网络的约束。因此,为了充分利用隐空间特征的作用,本文网络主要包含两个损失函数,即基于图像的Dice 系数损失和基于隐向量的特征对齐损失函数。Dice系数损失函数是一种计算预测结果和分割标签之间重叠区域的度量函数,能够有效地评估分割性能,其定义为
基于隐向量的特征对齐损失函数是本文的主要贡献之一。与经典的像素级损失不同,特征对齐损失可以从特征维度对分割结果进行优化,通过约束标签与图像在隐空间的一致性,增强编码器对图像血管结构特征的提取。如图2 所示,本文首先训练自编码结构对分割标签图像进行编码,得到标签隐向量特征。本文引入的自编码结构包括编码器和解码器结构,每层编码器和解码器由一个ResNet 残差块和一个最大池化层组成。与常见的端到端的像素级重建网络不同,自编码结构没有引入跳跃连接,而是通过将输入的分割标签图像的特征编码到隐向量空间,然后直接经过解码器进行恢复。其中,自编码器的重建损失Lrecon为均方误差损失。此时训练好的自编码器所提取的隐向量空间包含了丰富的分割标签特征,并且可以通过解码器成功恢复标签图像。因此,为了从原始输入图像中获得丰富的与血管相关的隐空间信息,本文采用最小二乘生成对抗网 络(least squares generative adversarial network,LSGAN)对原始图像的隐空间和分割标签的隐空间进行特征对齐。如图4所示,判别器网络由3个步长为1的卷积层组成,每个卷积层后面是斜率为0.2的LeakyReLU 层和批归一化层,最后通过平均池化层输出最终的结果。LSGAN 的主要贡献是将交叉熵损失函数换为最小二乘损失函数,改善了传统生成对抗网络(generative adversarial network,GAN)生成的图像质量不高和训练过程十分不稳定的问题。

图4 隐向量对齐判别器Fig.4 Latent vector alignment discriminator
本文采用LSGAN 代替传统的生成网络来提高隐空间特征对齐的稳定性。LSGAN的目标函数为
式中,D和G分别代表判别器和分割网络的编码器,x代表标签编码的隐向量特征,z代表输入的原始图像。因此,本文的总损失函数为
式中,λ的取值为0.6。
3 实 验
3.1 数据集介绍
为了验证所提方法的有效性,使用3个OCTA视网膜血管分割数据集进行验证,包括OCTA-O、OCTA-Z 和公开数据集PREVENT(Giarratano 等人,2020)。其中,OCTA-O 来源于一个公开数据集ROSE(Ma 等,2021)。所有数据都是在相关部门批准和患者同意下收集的。
OCTA-O 数据集包括39 名受试者(26 名阿尔兹海默症患者和13 名健康对照者)的117 幅OCTA图像,受试者平均年龄为68 岁。所有的OCTA 图像均由配备了AngioVue 软件的RTVue XR Avanti SD-OCT 系统采集得到,扫描区域为3 × 3 mm,扫描中心位于黄斑中央凹处,包括SVC、DVC 和SVC+DVC 这3 种enface 图像。为了实现公平比较,本文在划分训练集和测试集时,遵循Ma 等人(2021)的设置。
OCTA-Z 数据集的OCTA 图像由配备AngioPlex软件的Zeiss Cirrus HD-OCT 5000 系统采集得到,包括42 名受试者(15 糖尿病视网膜病变患者、2 名阿尔兹海默症患者和25 名健康对照者)的126 幅图像。与OCTA-O 数据集相同,每位受试者都通过扫描得到了SVC、DVC 和SVC+DVC 这3 种enface图像。每幅图像的扫描区域均为以黄斑为中心的3 mm × 3 mm 区域,分辨率为512 × 512 像素。本文将所有受试者图像随机分配为测试集和训练集,其中,30 名受试者图像为训练集,其余图像为测试集。4 名训练有素的图像专家对所有图像都进行了精确的血管标注,两名资深眼科医生审查并完善了标注。本文将他们的共识作为最终的血管分割标签。
PREVENT 数据集包括11位年龄在44~59岁的健康受试者的OCTA 图像,通过配备了AngioVue 软件的RTVue XR Avanti SD-OCT 系统采集得到,扫描中心位于黄斑中心凹处。不同于OCTA-O 与OCTAZ,PREVENT 仅具有3 mm × 3 mm 视野的SVC 图像。每幅OCTA 图像在此基础上,在每个临床关注区域(region of interest,ROI),包括上、鼻、中心凹、下和颞,各提取一幅子图像,合计55个ROI,并将其分为训练(30个ROI)和测试(25个ROI)两部分。
3.2 实验细节
该方法由公开的PyTorch库实现。在训练阶段,使用Adam 优化器来优化深度模型。初始学习率设置为0.000 8,并在训练过程中不断衰减,动量为0.9,批量大小(batch size)为1。另外,将图像随机旋转-10°~10°扩充训练集。在总损失函数中,λ取值为0.6。如图5 所示,本文在OCTA-Z 数据集上对λ的取值进行了敏感性检验,实验证明,0.6 为λ的最佳取值。

图5 λ的敏感性研究Fig.5 Sensitivity study of λ
3.3 评价指标
为了客观全面地检验所提方法的性能,选择ROC 曲线下面积(area under the roc curve,AUC)、准确度(accuracy,ACC)、灵敏度(sensitivity,SEN)、Kappa 评分(Kappa)、Dice 系数(Dice)和错误发现率(false discovery rate,FDR)作为评价指标,具体为
式中,TP,FP,TN,FN分别为真阳性、假阳性、真阴性和假阴性的像素数量。Kappa 评分中的pe为标签和预测结果的一致性,表示为
3.4 实验结果分析
3.4.1 对比方法
为了验证所提方法的有效性,在OCTA-O、OCTA-Z 和PREVENT 数据集中,将提出方法与其他最先进的分割方法进行对比,包括3 种传统方法IPAC(infinite perime and optimally oriented flux)(Zhao 等,2015)、COOF(curvelet denoising)(Zhang等,2020)、COSFIRE(combination of shifted filter responses)(Azzopardi 等,2015)和5 种深度学习方法U-Net(Ronneberger 等,2015)、ResU-Net、CE-Net(context encoder network)(Gu 等,2019)、CS-Net(channel and spatial attention network)(Mou 等,2019)、OCTA-Net(Ma 等,2021),所有方法的相关参数都经过手动调整,以获得最佳性能。
3.4.2 定性比较
图6—图8 分别展示了在OCTA-O、OCTA-Z 和PREVENT 3 个数据集中,本文方法与其他4 种最先进的分割网络所产生的血管分割结果。整体而言,U-Net在血管背景复杂区域难以准确识别血管信息,因此性能相对较低;CE-Net 和CS-Net 的性能要优于U-Net,但是它们不能很好地分割出毛细血管;OCTA-Net能够准确分割出毛细血管,但存在一定的过度分割现象。相比之下,如图中的黄色箭头所示,本文方法的分割结果与标签更为接近,能够分割出更加准确、更加完整的毛细血管。不同于其他方法存在将噪声背景错误地判定血管结构的现象,本文方法表现出强大的血管识别和判断能力,获得了整体最佳的分割性能。

图6 不同方法在OCTA-O数据集中的分割结果Fig.6 Vessel segmentation results of different methods on OCTA-O dataset((a)original images;(b)U-Net;(c)CE-Net;(d)CS-Net;(e)OCTA-Net;(f)ours;(g)manual annotations)
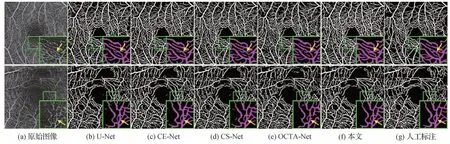
图7 不同方法在OCTA-Z数据集中的分割结果Fig.7 Vessel segmentation results of different methods on OCTA-Z dataset((a)original images;(b)U-Net;(c)CE-Net;(d)CS-Net;(e)OCTA-Net;(f)ours;(g)manual annotations)

图8 不同方法在PREVENT数据集中的分割结果Fig.8 Vessel segmentation results of different methods on PREVENT dataset((a)original images;(b)U-Net;(c)CE-Net;(d)CS-Net;(e)OCTA-Net;(f)ours;(g)manual annotations)
3.4.3 定量比较
为了更好地评估所提出方法的性能,在3 个数据集中对所有方法的分割性能进行定量评估,实验结果如表1—表3 所示。需要注意的是,Zhao 等人(2015)、Zhang 等 人(2020)以 及Azzopardiet 等 人(2015)提出的传统方法的评估性能明显低于其他所有基于深度学习的方法,这可能是因为传统方法尚未解决以下挑战,即不同个体的眼底血管存在高度解剖学差异以及同一幅OCTA 图像不同区域的血管尺寸和清晰度之间存在较大不同。此外,OCTA 图像中可能存在的散斑噪声、运动伪影和条纹噪声,以及OCTA 图像整体对比度较差、分辨率较低,这些不利因素也加剧了这些困难。相比之下,基于深度学习的方法能够从图像的整体和局部特征中提取深层的判别表示,从而得到更好的分割性能。具体到本次研究的实验结果,总体而言,本文方法几乎在所有的指标中都实现了最佳的性能。具体而言,在OCTA-O 数据集上,与经典医学图像分割网络U-Net相比,所提出方法的AUC 提升了约4.06%,Kappa 提升了约10.18%,FDR 提升了约23.16%,Dice 提升了约7.87%。在OCTA-Z 数据集上,与目前最先进的OCTA 图像血管分割网络OCTA-Net 相比,AUC 提升了约1.47%,ACC 提升了约0.89%,Kappa 提升了约2.23%,Dice 提升了约1.26%。而在PREVENT 数据集上,由于该数据集仅包括SVC图像,血管信息相对简单,所有基于深度学习的方法均取得了较好的性能,但本文方法依旧取得了最佳的整体分割性能。与经典医学图像分割网络U-Net 相比,本文方法的AUC提升了约1.47%,G-mean提升了约0.92%,Dice提升了约0.67%。
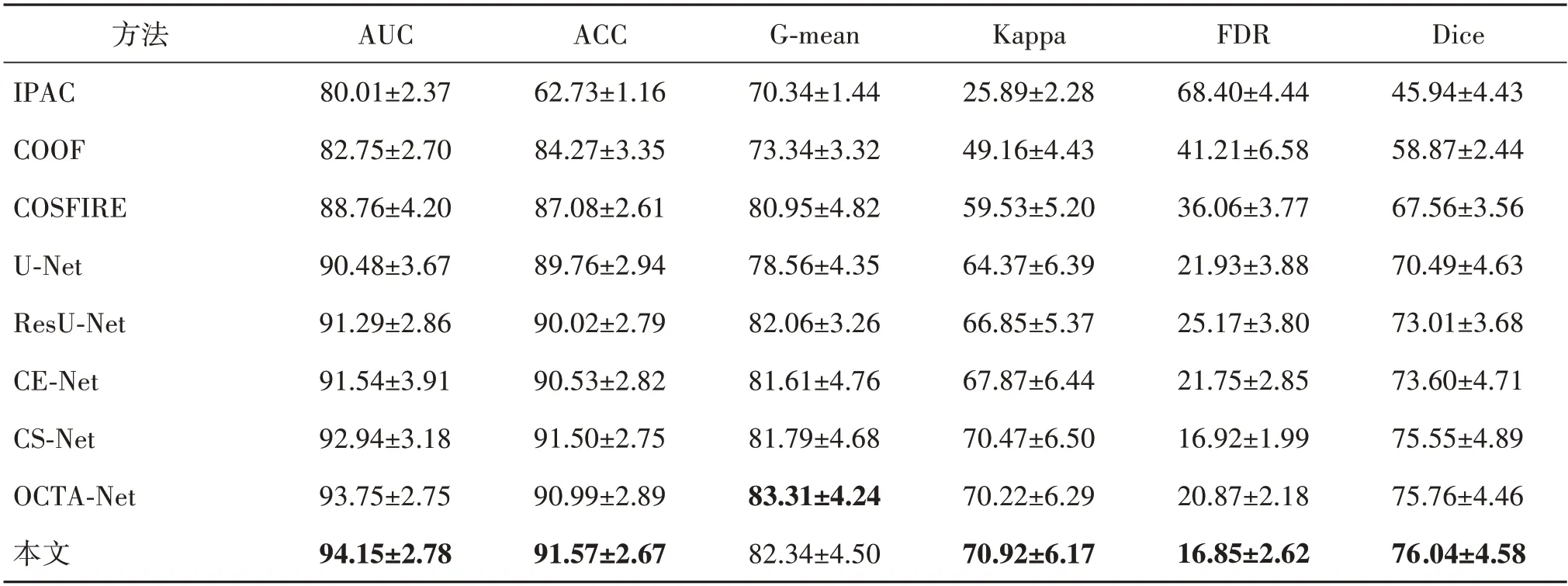
表1 不同方法在OCTA-O上的分割结果Table 1 Segmentation results obtained using different methods on OCTA-O/%

表2 不同方法在OCTA-Z上的分割结果Table 2 Segmentation results obtained using different methods on OCTA-Z/%

表3 不同方法在PREVENT上的分割结果Table 3 Segmentation results obtained using different methods on PREVENT/%
3.5 消融实验
本文提出的血管分割方法包括一个主干网络ResU-Net、图像多融合输入、用于特征提取的Swin Transformer编码器模块以及基于标签自编码的隐向量对齐损失函数。为了验证这些组成部分的有效性,进行了消融实验,将ResU-Net 作为基准编码器—解码器方法,然后逐步测试各组成部分对分割结果的影响,结果如表4 所示。其中,M 代表多融合输入(multiple fusion input),L 代表隐向量对齐(latent vector alignment),SwinT 代表Swin Transformer。首先,检验了图像多融合输入对分割性能的帮助,在两个数据集上的实验表明,与单独输入SVC+DVC图像相比,融合了3 种enface 图像输入之后的ResU-Net的AUC 分别提升了1.60%和1.46%,Kappa 分别提升了4.10%和8.88%,Dice 分别提升了3.87%和5.52%。可见,图像多融合输入对提升分割性能有明显作用。其次,分析了基于标签自编码的隐向量对齐损失函数对血管分割性能的影响,表明该模块在视网膜血管分割任务中具备一定优势。值得注意的是,加入该损失函数后,AUC 分别提升了0.64%和0.32%,Kappa 分别提升了2.69%和1.83%,Dice分别提升了2.55%和1.17%,表明该损失函数能够有效提升血管分割性能。最后,比较了Swin Transformer 编码器对分割性能的影响。整体而言,加入Swin Transformer 编码器之后,网络的整体性能获得了一定提升,尤其是AUC 分别提升了1.00%和1.32%,充分证明Swin Transformer 编码器对分割性能的提高起到了积极作用。

表4 本文方法在OCTA-O和OCTA-Z数据集上的消融实验Table 4 Ablation study of our method on both OCTA-O and OCTA-Z datasets/%
4 结论
本文提出一种新的OCTA 图像视网膜血管结构分割方法。近年来,许多研究工作都表明基于OCTA 图像的视网膜血管系统量化对相关眼科疾病和神经退行性疾病的定量研究以及临床决策起着至关重要的作用。为此,提出一种端到端的血管分割学习方法,用于OCTA 图像中的视网膜血管分割任务。考虑到编码器—解码器结构在分割任务中的巨大优势,将ResU-Net 作为主干网络,通过图像多融合输入来缓解OCTA 图像中散斑噪声和伪影对分割的干扰,并将Swin Transformer 模块作为编码结构,从而获取更加丰富的特征信息,之后,将编码器获取的高级特征与标签自编码网络获取的隐向量对齐,缩小分割结果与标签之间的差距,同时,通过跳跃连接将编码器获取的各个层次的特征图与解码器上采样的相应特征图进行融合,得到最终的分割结果。实验证明,本文方法在3 个数据集上都取得了最佳的分割性能。未来,将在其他模态的图像中检验所提出方法的分割性能,例如彩色眼底图像和眼底荧光造影图像等;此外,还将就分割结果提取重要的生物标志物,计算包括血管密度、血管弯曲度在内的相关指标,为相关疾病的量化分析和临床治疗提供帮助。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
小学生必读(低年级版)(2021年10期)2022-01-18
中医眼耳鼻喉杂志(2021年1期)2021-07-22
中医眼耳鼻喉杂志(2021年2期)2021-07-21
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
成都信息工程大学学报(2018年3期)2018-08-29
电子设计工程(2017年20期)2017-02-10
湖南中医药大学学报(2016年1期)2016-12-01
