
结合全局上下文与融合注意力的干涉相位去噪
2023-09-26 04:22曾庆旺董张玉杨学志种法亭
中国图象图形学报 2023年9期
曾庆旺,董张玉,3*,杨学志,种法亭
1.合肥工业大学计算机与信息学院,合肥 230031;2.工业安全与应急技术安徽省重点实验室,合肥 230031;3.智能互联系统安徽省实验室,合肥 230031;4.合肥工业大学软件学院,合肥 230031
0 引言
合成孔径需达干涉测量(interferometric synthetic aperture radar,InSAR)作为一种先进的微波遥感测量技术,在遥感与测绘领域取得了巨大成就和贡献(Massonnet 和Feigl,1998),其工作原理是测量从空间相同但时间不同的位置获取的两个独立的合成孔径雷达(synthetic aperture radar,SAR)图像之间的干涉相位(Ferretti 等,2007)。不可避免地,干涉相位噪声由以下3 类因素引入(Xu 等,2020):1)系统噪声,如热噪声和 SAR 散斑噪声;2)去相干问题,包含基线、时间和空间去相干;3)信号处理误差,主要涉及配准错误。噪声的存在增加了相位解缠的难度甚至导致其过程失败,严重干扰了最终的干涉测量结果。因此,干涉相位去噪是干涉测量处理中的必要步骤,已发展成为一项重要技术。
现有的相位去噪方法可以分为空间域、变换域和深度学习3 类方法。传统空域滤波算法使用滑动窗口获得图像局域统计特征进行滤波处理,从而达到去除噪声的目的。目前Lee 滤波算法(Lee 等,1998)作为一种经典的空域去噪方法,根据局部噪声统计和方向相关的窗口自适应地滤除沿条纹的噪声。在Lee 滤波算法的基础之上,其改进版本(Fu等,2013)具有一个自适应滤波器窗口,其方向和高宽也可以随图像自适应变化。传统空域滤波算法试图通过自适应窗口处理来增加保留相位细节的能力,但窗口处理操作可能会由于过度平滑而导致条纹细节丢失,并且花费大量的处理时间。作为一种新的空域方法,NL-InSAR(non-localinterferogram estimator)方法(Deledalle 等,2011)结合了最大似然估计和非局部思想,利用图像子块间的相似性和图像中的结构信息,从而能够在稳定去噪的同时在纹理细节保持上取得提升,此外非局部方法突破了搜索相似点的区域限制,可以在全局内寻找可用于滤波的像素,提高了滤波的质量,是近年来优秀的空域滤波算法,但是它在执行过程中多次迭代,效率略低。
变换域去噪方法通常分为频域和小波域方法。频域滤波基本思想是假设干涉相位与噪声分布于不同的频带。Goldstein 滤波算法(Goldstein 和Werner,1998)是第一种干涉相位频域滤波方法,由于滤波参数强烈依赖经验而定,具有很强的主观性,其改进版本通过对滤波参数(Li 等,2008)、自适应窗口大小(Suo 等,2016)等提供更适度的估计,实现了一些滤波性能提升。但这一类频域方法受滑动窗口大小和滤波参数的影响较大,且有过度平滑的趋势,图像的细节信息保持度不稳定。小波变换是一种具有良好的时频分析和多分辨率特性的方法,Lopez-Martinez和Fabregas(2002)提出了一种复域小波域滤波器,能有效分离信号中的细节信息和噪声。与上述频域滤波方法比较,小波滤波可以较好地保留干涉条纹,保持图像的边缘稳定性。InSAR-BM3D(blockmatching 3-D)方法(Sica 等,2018)结合了非局部和小波变换等方法,有效地利用局部和非局部冗余,且 3D 小波变换可以增强相位特征,从而提供更稳定的分离噪声能力。与上述变换域方法相比,可以实现更好的过滤效果,然而大量相似的区域搜索操作,大幅提高了计算成本。
近年来,深度学习已成功地应用于计算机视觉领域,如图像分类、目标识别和图像恢复等任务。更进一步,将深度学习应用于InSAR 干涉相位去噪的研究也开始涌现。例如Mukherjee 等人(2021)提出了一种基于卷积神经网络(convolutional neural network,CNN)的生成模型GenInSAR(generative CNNbased InSAR phase filter),用于直接学习InSAR 数据的分布,以进行相位滤波和相干估计。然而,由于只使用单一大小的卷积核的卷积层和大量使用dropout 层,限制了网络对相位特征的提取,大幅降低了网络训练速度以及去噪效果;Sun 等人(2020)提出了一种结合残差学习与密集连接(dense connection)的干涉相位去噪网络DeepInSAR(a deep learning framework for SAR interferometric phase restoration and coherence estimation),利用密集连接可以实现特征重用和缓解梯度消失问题,但由于密集连接进行通道叠加的原因,网络需要加深且需要频繁读取内存,拖慢了网络训练速度;Pu 等人(2020)提出一种用于InSAR 的具有尺度循环网络的相位滤波方法PFNet(phase filtering network);陶立清等人(2023)提出一种结合CNN 与自编码/解码器进行非监督学习的干涉相位去噪方法。对于上述两种方法,由于需要对输入的干涉相位图进行重采样或上下采样,减少了图像信息的使用,会对去噪结果产生消极的影响。此外,上述深度学习算法常常由于感受野受限,大多只关注局部特征而忽略了全局上下文信息,在特征提取方面仍然存在不少的提升空间。基于这些问题,本文提出了一种结合全局上下文与融合注意力的干涉相位去噪网络GCFA-PDNet(global context and fused attention phase denoising network),使用全局上下文不仅关注局部信息,还能提取相位全局信息,又可以使去噪方法具有非局部方法的优势;使用融合注意力增强网络的特征提取能力,强调关键特征,提取隐藏在复杂背景中的噪声信息,进而提高网络的效率和去噪处理的准确性。综合二者,可以提升网络的噪声抑制能力,且保留更多的相位细节,获得更高精度的结果。
1 干涉相位噪声模型
InSAR 干涉相位噪声可认为是零均值加性噪声(Lee 等,1998),从而包含随机噪声的干涉相位可以表示为
式中,φy表示含噪声的相位观测值,φx表示无噪声的干净相位,n代表均值为零且标准差为σ的噪声,且φx、φy、σ三者两两独立。由于三角函数的周期性,干涉相位被缠绕到(-π,+π]之内。此外,缠绕的相位在-π 与+π 之间产生的跳变所代表的高频信号应该被很好地保留,从而使用自然图像的去噪方法直接对干涉图像去噪是不可取的。为了解决这个问题,依据Wang等人(2016)的策略来处理复数域中的干涉相位,即将干涉相位拆分为实部与虚部,然后分别进行去噪处理。在复数域中,干涉相位可以表示为
式中,R为干涉相位的实部,I为干涉相位的虚部,二者可以表示为
2 GCFA-PDNet
2.1 整体网络结构
本文提出的相位去噪网络GCFA-PDNet 如图1所示。网络主要由4 个全局上下文提取模块(global context extraction module,GCEM)、4 个融合注意力模块(fused attention module,FAM)和1 个全局残差连接组成。首先,使用1 个卷积核大小为3 × 3 的标准卷积,将图像通道数升为64,后接激活函数ReLU(rectified linear units)以提取干涉相位的底层特征。之后,经过4 个GCEM,可以充分利用全局上下文信息,获得更多更丰富的浅层和深层特征。同时,4 个FAM 模块可以使GCFA-PDNet 更加关注噪声信息,利于去除噪声的同时保持原始图像的细节。在此之后,将GCEM 与FAM 的输出拼接,浅层特征与深度特征融合后经过若干卷积层输出。最后,通过全局残差学习获得所需要的去噪图像。

图1 GCFA-PDNet网络结构Fig.1 Structure of GCFA-PDNet
2.2 全局上下文提取模块
对于包含大量干涉条纹和复杂的地面高程或形变信息的干涉相位图,每个干涉条纹都包含丰富的边缘信息,且相邻的干涉条纹常常具有相似性,在去噪任务中需要保持这些丰富的边缘特征以及在全局信息中识别出各个条纹。此外,干涉相位中的去相干噪声会阻碍上下文特征的提取。另一个问题是卷积核在每一层的局部感受野内融合空间和通道信息来构造特征,由于卷积具有局部感知的特点,只能对局部区域进行上下文建模,导致感受野受限。因此,简单堆叠多层卷积层进行建模,不仅计算量大,而且难以优化。针对现有的深度学习干涉相位去噪算法存在的以上问题,提出了全局上下文提取模块,以克服卷积神经网络关注局部特征的缺点,增强所提取特征中全局上下文信息的聚合,对整个输入特征图进行全局上下文信息提取,有利于提升网络的去噪能力和细节保持能力。全局上下文提取模块如图2所示,图中d后数字为膨胀卷积的膨胀因子,其最核心模块是全局上下文模块(global context block,GC Blcok)。

图2 全局上下文提取模块Fig.2 Global context extraction module
为获取局部特征,首先使用3 × 3 的标准卷积(Conv),后接批量归一化(batch normalization,BN)和激活函数ReLU,以防止过拟合。同时,为了挖掘周围的上下文信息,需要进一步扩大感受野(receptive field,RF)。为此,连续使用膨胀因子分别为2和3的膨胀卷积,其感受野计算为

图3 标准卷积与膨胀卷积的感受野的比较Fig.3 Comparison of receptive fields between standard convolution and dilated convolution((a)RF of standard convolution;(b)RF of dilated convolution)
GCBlock(Cao 等,2019)对非局部网络(nonlocal network)(Wang 等,2018)、压缩和激励网络(squeeze-and-excitation networks,SENet)(Hu 等,2018)两种方法取长补短。非局部网络使用自注意力机制建模像素对关系,利用全局其他位置的信息增强当前位置的信息(杨翠倩 等,2021),然而它对于每一个位置学习不受位置依赖的注意力图(attention map),造成了大量的计算浪费;SENet 使用全局平均池化对不同通道进行权值重标定,用于调整通道依赖关系,但仅采用权值重标定使其不能充分利用全局上下文信息。所以,结合了两种方法的GCBlock 不仅能够像非局部网络一样有效地对全局上下文建模,又能够像SENet 一样轻量。所以,增加GCBlock 到网络中,不仅可以获得更具多样性的浅层和深层特征,而且能够提取全局上下文信息,进而在去噪任务中结合非局部方法思想利用全局信息进行去噪,从而提供更稳定的分离噪声能力。
GCBlock 如图4所示,首先采用1×1卷积和softmax 函数提取注意力权重,通过矩阵相乘实现注意力建模(context modeling),之后通过在两个1 × 1卷积之间插入LayerNorm+ReLU 进行特征变换(transform),最后使用残差连接将全局上下文与每个位置的特征聚合。图中,C表示特征图的通道数,H和W分别为特征图的高和宽,⊗代表乘法(multiply)。r为通道压缩比率,设置为4。Layer Normalization 层的作用是在通道维度对相位数据进行归一化,进而可以降低优化难度且作为正则化提高泛化性。

图4 GCBlock网络Fig.4 GCBlock network
2.3 融合注意力模块
为了进一步平衡去噪和纹理,保留两者之间的关系,对特征图进行加权处理,达到增强目标特征和抑制噪声的目的,受Liu 等人(2022)的启发,构建了一种融合注意力模块FAM,如图5 所示。通过GCEM 所得的特征图fm经过一个1 × 1 的标准卷积后,通道数降维为原来的一半,然后将其并行送入通道注意力模块(channel attention block,CAB)和空间注意力模块(spital attention block,SAB),再将二者输出拼接,从而保持原始输入的通道数,最后通过一个标准3 × 3 卷积输出。FAM 不仅在通道层面提高效率,还可以专注于图像中的显著信息,例如去相干严重的区域和干涉条纹边界,而忽略次要的信息,例如单个条纹内部相位梯度缓慢的部分,从而提高去噪的效率和信息处理的准确性。
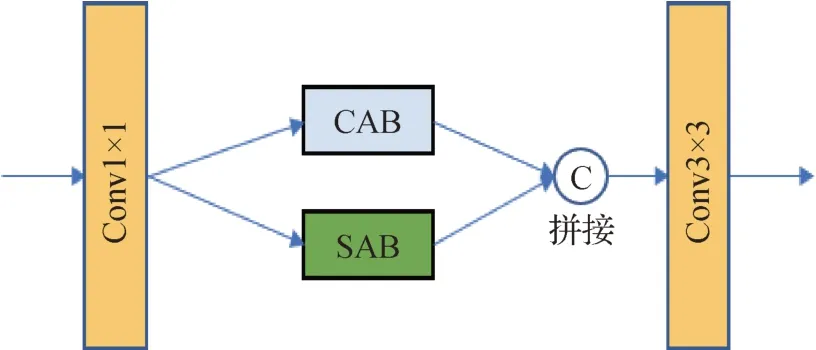
图5 FAM模块结构Fig.5 FAM module structure
2.3.1 通道注意力模块
CAB方法可以通过获取每个特征通道的某种权重,并依据这个权重对当前任务有效和无效的特征分别进行增强和抑制(卢正浩和刘丛,2021),从而利用通道注意力方法可以提高去噪的效率和信息处理的准确性。相较于SENet,Wang 等人(2020)认为捕获所有通道的依赖关系是低效并且是不必要的,且一维卷积具有良好的跨通道信息获取能力,基于上述观点,本文使用的CAB模块如图6所示。

图6 通道注意力模块Fig.6 Channel Attention Module
首先,将已经通道降维的特征图fm经过全局平均池化(global average pooling,GAP)处理,为了在降低模型复杂度的同时,增强网络的跨通道信息的获取能力,使用一维卷积(Conv1D)替代SENet 中的两次全连接。对于一维卷积,其卷积核大小为k的计算式为
式中,C为输入一维卷积的输入通道数,w和b为常数,分别是预设权重与偏置,一般设置为w=2、b=1,|x|odd表示为最接近x的奇数。之后用sigmoid 对1 维卷积的输出进行非线性激活。最后将激活后的特征图与fm相乘,得到CAB 模块的输出fCA,即实现通道注意力。
2.3.2 空间注意力模块
因为受真实空间地形影响,干涉相位不同区域的噪声分布可能不均匀,使用SAB 使网络更专注于具有更多有用信息的特征,例如失相干严重的像素和高频率干涉条纹区域,从而提取更丰富的特征,利用这些特征增强网络对噪声的抑制能力并获得不俗的相位细节保持能力。受Liu 等人(2021)的启发,构建的SAB如图7所示。

图7 空间注意力模块Fig.7 Spatial attention module
在SAB中,为了关注空间信息和减少计算参数,使用两个卷积核大小自适应变化的卷积层进行空间信息融合。其中,通道缩减比r设置为4,卷积核大小k随FAM 使用次数n而变化。即k=2n-1,n=1,2,3,4。相较于传统的空间注意力机制,由于最大池化操作减少了信息的使用,产生了消极的影响,这里删除了池化操作以进一步保留特性映射。输入fm,通过SAB后,其大小与尺寸保持不变,即
式中,conv1,conv2 分别代表输出通道数为C/r、C的标准3 × 3 卷积。最后,输入特征fm元素乘以获得的权重,获得SAB模块输出。
2.4 残差学习与损失函数
残差连接(He 等,2016)旨在解决非常深的神经网络上的性能退化问题,在本文中,利用全局残差连接来预测实部和虚部通道的残差。所提出的模型被训练来预测残差,而不是直接输出估计干净成分,故图1 中最后一个卷积层的输出为干涉相位的噪声映射。将残差相位设为ri,原始噪声相位设为yi,原始无噪声相位设为xi,则网络获得的残差相位ri可以表示为
根据本文所提出的噪声模型即式(1),此时网络学习的目的在于找到函数H(yi;w),w为网络可训练的权重参数,使得训练结果可以估计残差相位ri,则有
对于批量样本数量为N的训练样本的干涉相位实部和虚部通道,采用均方误差(mean square error,MSE)作为损失函数,具体为
式中,wr|i为网络对干涉相位实部或虚部的训练参数。和分别为干涉相位实部或虚部的原始噪声相位和原始无噪声相位。
3 实验结果与分析
3.1 训练数据
实际中,InSAR 干涉相位图缺乏无噪声的真实数据,而网络训练通常需要大量标记样本,因此采用模拟干涉相位图像作为训练集,以验证所提出方法的有效性并评估其性能。实验在Sun 等人(2020)的模拟数据集上进行,其优势是模拟了不规则形变信号和地面反射现象以及非平稳噪声条件。实验使用该数据集中的9 种不同配置,通过组合3 个不同水平的加性白高斯噪声(SL、SM、SH,即噪声标准差分别为0.1、0.2、0.3)和相位条纹的3 个频率(FL、FM、FH)来代表其中某一种噪声类型数据。例如,具有低水平噪声、高条纹频率的数据集,用SL-FH 表示。在实验中,对于每种噪声类型,生成了 100个随机样本,每个样本的图像分辨率为 1 024 × 1 024 像素。其中一半用于训练,其余用于测试。通过在所有9 个数据集上使用无噪声图像训练单个模型,评估GCFA-PDNet模型的学习能力和泛化能力。
3.2 参数设置
实验在10.0.130 版 本CUDA、7.6.5 版 本CUDNN、Intel Xeon Silver4144 @2.2 GHz 处理器,Nvidia Tesla P100(16 GB)显卡环境下进行。采用的框架为Tensorflow1.14,网络参数更新采用Adam 优化器,网络每次训练的样本数为64,初始学习率设为0.001,并且每4 000个迭代轮次(epoch)学习率大小下降一半,共训练16 000 个迭代轮次,训练完成单个子数据集需要2 h。
3.3 评价指标
对于模拟干涉相位图像的实验,选择峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity,SSIM)作为评价指标,越大的PSNR说明滤波后的相位与干净的相位的差距越小,然而它没有考虑图像中各像素间的相关性。因此,为了评价去噪图像的整体去噪质量,采用SSIM 来评估过滤后的图像的结构相似性。更高的SSIM 意味着在过滤过程中相位结构信息得到更好的保留。对于SSIM 指标,其范围为[0,1],值越大表示结构信息保留得越好。
对于真实的干涉相位,由于不存在无噪图像做参考,从而无法使用上述两种指标来评价去噪性能。除了在视觉上主观评判真实干涉相位图像去噪性能,还可以使用残差点数(number of residues,NOR)与相位标准偏差(phase standard deviation,PSD)作为客观评价指标。NOR 可以反映滤波方法抑制噪声的能力。滤波后的干涉相位的 NOR 越小,抑制噪声的能力越强。残差点的定义取决于相位梯度在2 × 2像元形成的最小闭合路径积分。对于干涉相位图像,相邻像素之间的相位梯度的计算式为
式中,i和j分别代表相位数据行、列方向上的序号;r和a代表距离向(range)、方位向(azimuth)对应行、列方向。这两个方向上,相邻样本数据差的缠绕值可作为连续相位梯度。wrap代表相位缠绕操作,即将{ }内的值限定在(-π,+π]内,其定义为
对于给定的一个像素点(i,j),其是否为残差点的判定式为
若Q不等于0,则该点为残差点。此外PSD可用来衡量噪声分布的离散程度。PSD 的数学表达式为
式中,w为检测样本窗口,φi,j为窗口内各点相位值,为窗口内相位均值,N为窗口内样本个数。PSD值越小,噪声分布越集中,干涉图质量越好。
3.4 模拟干涉相位图像实验
对上述测试数据进行实验,并将模拟数据中的5 类测试图像进行对比,展示所有模拟数据的实验评价指标。选择Goldstein、NL-InSAR、InSARBM3D、DeepInSAR和PFNet方法进行对比实验。
表1 和表2 展示了上述方法与所提出的方法在9 种不同失真条件下获得的平均PSNR 和平均SSIM指标。由表中可知,所提出的方法在9 种不同类型的噪声数据下均取得了很好的效果,获得的平均PSNR相较于Goldstein、NL-InSAR、InSAR-BM3D、DeepInSAR 和PFNet 分别高出7.30 dB、6.21 dB、4.22 dB、1.64 dB 和1.45 dB,SSIM 值也优于其他算法。表明GCFA-PDNet 在增强去噪能力的同时,可以更好地保持相位结构信息,即条纹边缘等细节信息会更加清晰。
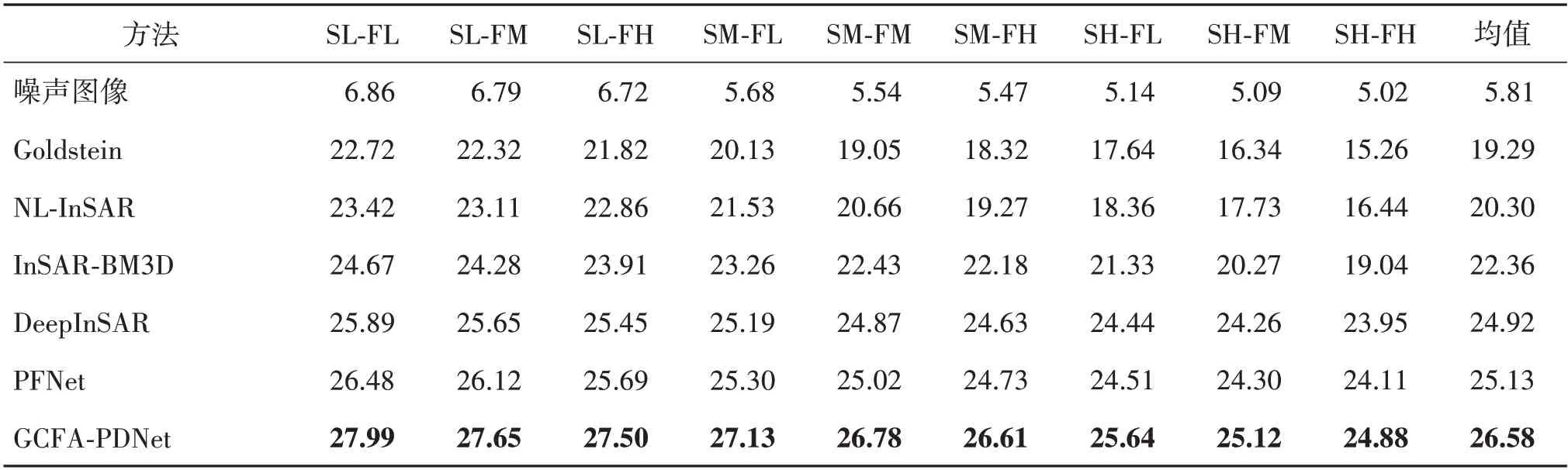
表1 9种类型的相位数据去噪后的PSNRTable 1 PSNR of 9 types of phase data after denoising/dB

表2 9种类型的相位数据去噪后的SSIMTable 2 SSIM of 9 types of phase data after denoising
Goldstein 与NL-InSAR 两种去噪方法在低噪声水平下PSNR 指标都表现不俗,但与深度学习去噪方法对比仍有一定差距,随着噪声水平提高,二者的指标都剧烈下降,差距进一步扩大。在同一噪声水平条件下,从SSIM 指标可以看出,它们的数值低于其他算法,随着相位条纹频率的增加,二者下降幅度大于其他算法,表明它们并没有良好的结构保持能力;InSAR-BM3D 相较于前两种非深度学习方法,在中、低水平的失真条件下有着较大提升,然而随着噪声水平或条纹频率的提高,也出现了评价指标较大幅度的下降。对比另外3 种深度学习方法,在低噪声水平的条件下,GCFA-PDNet 相对于PFNet 和DeepInSAR 有一些提升,随着噪声水平的提高,前者的两种评价指标没有后二者下降的幅度大,在相位条纹的中、高频率条件下,GCFA-PDNet 有着更加优秀的表现,说明其具有更强的泛化能力。通过统计分析证明,所提出方法可以在有效去除噪声的同时,有效地保持结构信息。
图8 展示了在同一相位条纹频率(FM)条件下,不同噪声水平(SL、SM、SH)的3 种噪声数据的去噪结果。其中,第1、2、3 行分别代表SL-FM、SM-FM 与SH-FM类型数据的处理结果。蓝色—红色代表相位变化由-π~+π。

图8 SL-FM、SM-FM与SH-FM类型数据的处理结果Fig.8 The processing results of SL-FM,SM-FM and SH-FM type data((a)ground truth;(b)noisy-images;(c)Goldstein;(d)NL-InSAR;(e)InSAR-BM3D;(f)DeepInSAR;(g)PFNet;(h)ours)
图9 展示了在同一噪声水平(SM)条件下,不同相位条纹频率(FL、FM、FH)的3 种噪声数据的去噪结果。第1、2行分别代表SM-FL 与SM-FH 类型数据处理后的结果。

图9 SM-FL与SM-FH类型数据处理后的结果Fig.9 The processing results of SM-FL and SM-FH type data((a)ground truth;(b)noisy-images;(c)Goldstein;(d)NL-InSAR;(e)InSAR-BM3D;(f)DeepInSAR;(g)PFNet;(h)ours)
结合对表1、表2 的定量与对图8、图9 的定性分析可知,在同一相位条纹频率条件下,随着噪声水平的提高,各种方法的去噪效果出现不同程度下降;在同一噪声水平的条件下,随着相位条纹频率的提高,各种方法的去噪效果也出现不同程度下降。由此可见,干涉相位噪声水平和相位条纹频率是影响去噪的关键因素。
在同一相位条纹频率(FM)下,结合图8 可知,Goldstein 虽然有良好的去噪性能,但是得到的图像不够清晰,在图像细节方面,随着噪声水平提升,纹理失真与边界伪影明显,在某些区域的边缘,无法保持原来的结构信息。NL-InSAR 在中、低噪声水平条件下,去噪效果与细节保持相较于Goldstein 有所提升,随着噪声水平提升,其去噪能力削弱得也比较明显。InSAR-BM3D 的去噪效果相较于前两种方法有较大提升,然而在高噪声水平下其细节保持能力弱于另外3 种深度学习算法。相较于前面3 种非深度学习去噪算法,DeepInSAR 在去噪和纹理保持方面都有较大提升,但在局部条纹边缘仍然存在少量的失真。对于PFNet,与DeepInSAR 相比,其去噪效果展现出略微提升,在这3 种深度学习算法中可以发现GCFA-PDNet 处理图像的整体效果最佳,GCFAPDNet 在保持去噪性能时,也表现出了更好的细节保留效果,相位条纹的边缘更加清晰。
在同一噪声水平(SM)下,结合图8 第2 行与图9,Goldstein、NL-InSAR 和InSAR-BM3D 3 种方法随着相位条纹频率的提升,去噪效果出现不同程度的明显下降,如残留噪声增多、边缘变得更加模糊以及边界伪影增多等;在中、高相位条纹频率的条件下,深度学习方法的优势得以体现,3 种深度学习方法均取得了不俗的效果,但它们之间仍然存在细微的差别,通过对比图9(f)(g)(h)第1 行可以看出,GCFA-PDNet 具有更好的边缘保持能力,PFNet 和DeepInSAR 均存在将部分噪声点误判为条纹边缘的现象,通过对比图9(f)(g)(h)第2 行可以看出,GCFA-PDNet 达到了最佳的去噪效果,PFNet 仍存在少量边界伪影,而DeepInSAR 则在图像的边界出现了少量失真。综合上述对比分析,在中、高水平相位条纹频率或噪声水平的条件下,图像所包含的特征与结构信息更加丰富,GCFA-PDNet 使用了全局上下文提取模块与融合注意力模块,加强了网络的特征提取能力,并充分使用全局上下文信息进行去噪,且充分利用了网络的浅层特征和深层特征,从而GCFA-PDNet 比 PFNet 和DeepInSAR 在去噪性能方面有所提升,且在纹理保持方面,GCFA-PDNet 的表现更好,具有更加稳定的细节保持能力,去噪结果最清晰,取得了最优的性能。
3.5 真实干涉相位图像实验
对于真实干涉相位,由于不存在无噪图像做参考,故无法测得其噪声水平。干涉图的相干性是显示干涉相位可靠性的关键指标(Deledalle 等,2011),相干值越大,干涉图质量越好。为了进一步验证所提出方法的性能,在没有多视处理的条件下,在由ENVISAT-ASAR(Bam,Iran)数据生成的干涉图中,裁剪出两幅尺寸为1 000 × 1 000(方位向×距离向)的图像作为测试样本,如图10(a)所示,其中,区域Ⅰ、Ⅱ分别为高、低相干区域,二者平均相干系数分别为0.76 和0.43,图10(b)是其相干系数图,相干系数范围为0(黑)到1(白)。

图10 测试样本Fig.10 Test sample((a)ensemble of the Interference graph;(b)coherence coefficient plot)
对于定性评估,区域Ⅰ、Ⅱ去噪结果及其细节图如图11 所示。综合这两个区域的实验结果可知,在高相干性的条件下,各种方法都取得了不错的效果,然而综合去噪与细节保持能力,GCFA-PDNet 取得了最好的效果。在低相干性条件下,Goldstein 和NL-InSAR 的噪声抑制能力不足,保留了更多的噪声,InSAR-BM3D 相较于前二者有所提升,但出现了过度平滑的趋势;DeepInSAR 的结果过于平滑,丢失了大量微小细节,PFNet 虽然保留了更多细节但也残留了更多的噪声,图像整体质量稍差,而所提出方法在去噪能力和细节保持方面达到更好的平衡,在3种深度学习方法中取得了最优表现。

图11 区域 Ⅰ、Ⅱ的去噪结果Fig.11 Denoising results of regions I and Ⅱ((a)noisy-images;(b)Goldstein;(c)NL-InSAR;(d)InSAR-BM3D;(e)DeepInSAR;(f)PFNet;(g)ours)
为了验证上述定性分析,计算了图11 的定量评价指标NOR。此外,由于部分残差点无法完全过滤,计算了残差点减少的百分比(percentage of residual point reduction,PRR),以更清楚地显示噪声抑制能力,结果如表3 所示。可以发现,在高、低相干区域,Goldstein 和NL-InSAR 方法去噪表现最差;在高相干区域,InSAR-BM3D 与深度学习方法差距进一步缩小,然而在低相干区域其去噪能力的不足便体现出来;对比3 种深度学习方法的评价指标,在去噪能力、相位质量方面,GCFA-PDNet 相对于其他二者均有提升。结合定性与定量分析,可知所提出的方法在5 种方法中达到了去噪与结构保持能力之间的最佳平衡,具有更好的鲁棒性。综合上述分析,GCFA-PDNet 更适用于低相干性区域、高相位条纹频率的干涉相位图像,即在实际情况中,对于地形复杂或地表形状快速变化的区域进行去噪,本文方法具有独特优势。

表3 真实数据在不同方法处理后的评价指标Table 3 Evaluation indicators of real data processed by different methods
4 结论
本文设计了一种结合全局上下文和融合注意力机制的干涉相位去噪网络,将全局上下文提取模块融合注意力模块应用于干涉相位去噪,具体结论如下:1)全局上下文提取模块具有强大的特征提取能力,使用该模块去噪具有非局部方法的优势,实验表明其取得了显著改进的去噪结果。2)融合注意力模块不仅增强了网络的特征表达能力,更使网络加强了对相位结构、噪声的关注。融合上述两个模块获取的深层与浅层特征结构能够被网络最大限度地使用,从而达到最优的去噪结果。
在未来的工作中,为了应对真实干涉相位的复杂噪声,可以考虑使用生成对抗网络模拟更接近真实的干涉相位图像噪声,提高噪声的质量,以训练更强大的模型去噪能力。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
小福尔摩斯(2019年2期)2019-09-10
小学生必读(低年级版)(2019年9期)2019-04-13
小学生必读(低年级版)(2019年10期)2019-04-13
金桥(2018年4期)2018-09-26
空间控制技术与应用(2015年3期)2015-06-05
遥测遥控(2015年2期)2015-04-23
中国卫生(2014年5期)2014-11-10
娃娃画报(2014年9期)2014-10-15
