
基于迁移学习的跨被试脑电疲劳驾驶检测
2023-10-09 13:56邱轶辉魏玲玲张卫平邱桃荣
南昌大学学报(理科版) 2023年4期
邱轶辉,江 琼,魏玲玲,张卫平,邱桃荣*
(1.南昌大学数学与计算机学院,江西 南昌 330031;2.九江学院计算机与大数据科学学院,江西 九江 332005)
交通意外一直是导致人类死亡的主要原因之一,并且其发生数量有逐年上涨的趋势[1]。有统计数据显示,由疲劳驾驶引起的交通事故占到交通事故总量的40%,并且往往导致更严重的后果[2]。因此,研究疲劳驾驶状态的识别对减少交通事故发生和改善道路安全环境具有重要意义。
针对疲劳驾驶状态的检测,国内外众多学者均进行了相关的研究。目前,检测方法可以分为主观评定法和客观检测法两大类[3]。一是主观评定法:通过驾驶员填写心理问卷或他人对驾驶员的评价来判断疲劳程度,常用的心理测量问卷有:斯坦福嗜睡表和卡洛琳斯卡睡眠尺度表[4]等,主观评定法操作简单,但只能离线检测用于事后分析。二是客观检测法:通过对驾驶员驾驶过程中产生的脑电图[5]、心电图[6]、眼电图[7]、肌电图[8]等生理信号和驾驶员头部面部特征及方向盘角度偏移等车辆特征进行分析来判断驾驶员的疲劳状态,其中脑电信号由于具有时间分辨率高、无创性、低成本等特性,已被认为是疲劳驾驶识别的“金标准”。
脑电图(Electroencephalogram,EEG)利用头皮上放置的电极检测和记录大脑内电信号的变化,通过分析EEG我们可以对大脑状态进行判断。已经有许学者对利用脑电信号判断疲劳驾驶状态进行了研究。例如,Mu等[9]提出了基于熵的特征提取方法,并筛选了特定电极用支持向量机(Support Vector Machine,SVM)进行分类,在自建数据集上得到了98.75%的平均准确率。针对SVM在处理高质量数据时表现良好但在面对复杂数据时表现不佳的问题,San等[10]提出了一种混合深度遗传模型来进一步弥补SVM在处理复杂不变性方面的不足,并用于疲劳驾驶状态的检测。刘卓等[11]将脑电信号作为函数型数据进行分析,着重研究其连续性和内部动态变化并分类。上述研究均在各自场景下对疲劳驾驶检测有一定贡献。
然而多上述研究多集中在对同一被试的脑电进行分析,由于脑电信号具有特异性和非线性特征,进行跨被试检测时会出现协变量偏移的问题,这导致跨被试的疲劳驾驶检测结果并不乐观。近年来也有学者注意到这一点,提出了许多结合迁移学习的跨被试EEG疲劳驾驶检测方法。例如Gu等[11]提出了一种几何保留迁移判别字典学习方法,通过将不同域的信号投影到公共子空间,得到一个共享判别字典,再利用图拉普拉斯正则化和主成分分析正则化分别对几何结构信息和判别信息进行挖掘,进行跨被试分类。Hong等[13]将域对抗神经网络与生成对抗网络相结合,通过解决EEG在不同被试之间分布不同的问题来增强跨域检测能力。Zanini等[14]提出了一种基于黎曼空间测地线的对齐方法(Riemannian space Alignment,RA)用于在黎曼空间减少域间差异。He等[15]针对RA需要一定标签和计算效率低的问题提出了在欧几里得空间对齐的方法(Euclidean-space Alignment,EA),并在多个数据集上明显提高了准确率。
然而EA需要大量源域数据用于计算参考协方差矩阵来对齐。这在意味着该方法在疲劳驾驶检测中只能用于事后分析,而不能用于实时检测。因此,本文从实际应用出发,提出一种利用基于源域数据和目标域数据参考矩阵相似度的加权平均对齐方法(Weighted Average Euclidean-space Alignment,WAEA)。该方法在仅有少量目标域样本可用时能对疲劳驾驶状态进行及时的判断,并结合基于模型的迁移学习方法,使用微调的技术提升跨被试疲劳驾驶分类准确率。
1 相关理论与方法
1.1 欧式空间对齐
首先介绍原始的欧式空间对齐方法EA,其基本原理是使来自不同被试的数据分布更加相似,因此在源域数据上训练的分类器将有机会在目标域上上表现良好。EA计算每个被试的EEG试次的平均样本协方差矩阵,再通过数据对齐的方法将每个被试的样本协方差矩阵重新居中在单位矩阵处,使对齐的EEG试次被白化,降低数据的冗余性,这有利于后续的特征提取和分析。
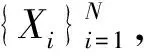
1)首先计算一个被试的平均协方差矩阵:
(1)
2)将R作为参考矩阵,对该被试所有样本执行对齐计算:
(2)
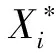
对源域和目标域的所有被试都进行上述对齐后就完成了EA。经过欧式空间对齐后,一个被试所有N个对齐数据的平均协方差矩阵为:
(3)
式中,I是单位矩阵。
经过EA对齐算法使所有被试的平均样本协方差矩阵与对齐后的单位矩阵相等,因此来自不同被试的空间协方差矩阵的分布会更相似,鉴于样本协方差矩阵是EEG信号的一个重要统计量,用户间的差异也会变小,这正是迁移学习想要达到的效果,该处理在传统机器学习和深度学习方法上都得到了验证。
然而通过式(1)可以看出EA对齐算法需要使用全部数据计算参考矩阵,这使得该算法在许多领域不适用,在疲劳驾驶领域上EA仅能用于事后分析,不能起到及时检测的作用。因此我们提出了一种改进的EA算法,使其能用于仅有少量目标域数据可用时的对齐。
1.2 改进的欧式空间对齐
当有少量目标域数据时可用,应当充分利用该部分数据进行对齐,然而传统EA仅用少量目标域数据计算得到的参考矩阵不能很好的代表目标域上的数据分布为降低数据过少时计算参考矩阵的偏差,考虑使用源域中参考矩阵进行辅助,并利用矩阵之间的余弦相似度作为权值,进行加权平均对齐WAEA。
1)由于源域数据全部可用,首先对源域数据进行EA,对源域中m个被试分别计算参考矩阵记为R1,R2…Rm,并对源域中每个被试数据对齐,方法同式(1)和式(2)。
2)利用目标域中可用的M个样本计算目标域上的部分参考矩阵RT:
(4)
由于计算RT使用的数据较少,不能很好的反映目标域上数据分布,且具有较大波动性,考虑加入源域中被试的参考矩阵用于对齐。
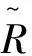
(5)
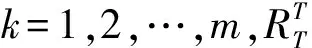
4)根据矩阵相似度使用最大最小归一化的方式为R1,R2…Rm赋予不同的权值:
(6)
式中,wk为Rk的权值,k=1,2,…,m,经过归一化后相似度较大的参考矩阵分配到的权重较大,且满足:
(7)
(8)
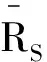
(9)
式中,RTS为融合参考矩阵,λ=min(M/N,1)为权衡参数,用于调整对齐中使用目标域参考矩阵的比重,当目标域中可用数据越多时使用RT作为融合参考矩阵的比重越大。
7)模型训练结束后,目标域剩余数据可用时,使用融合参考矩阵RTS对可用数据对齐:
(10)
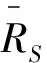
1.3 基于模型的迁移学习
基于模型的迁移方法假定相关任务的各个模型应该共享一些参数或超参数的先验分布,并通过共享这些模型参数来提升迁移效率。其思想是预训练模型已经学习了源域中的有用特征和模式,可以应用于目标域以提高性能。通过使用预训练模型,目标模型可以获益于源模型所获得的相关知识。微调是实现基于模型的迁移学习的一种方法,该方法指在源域上训练一个预训练模型,接着继续在目标域上继续训练全部或者部分网络参数[17]。
DeepConvNet[18]是一个常用于EEG分类的深度神经网络模型,该模型由5个卷积层组成,其中一个softmax层用于分类,该网络在P300视觉诱发电位、错误相关负波、运动相关皮层电位和感觉运动节律等任务中都有良好表现,本文使用DeepConvNet提取特征分类,并使用微调方式进行模型迁移。
2 实验与结果分析
2.1 测试环境
本文的研究是在一台装有Windows 10操作系统的图形工作站上完成的,处理器为两颗lntel(R)Xeon(R) CPU E5-2620 v4 @2.10 GHz,运行内存16 GB,图形卡为NVIDIA Quadro M2000。采用Python3.6作为编程语言通过Anaconda搭建实验环境,使用jupyter notebook和Pycharm编写实验代码,机器学习框架是sklearn,深度学习框架是Keras,backend采用TensorFlow。
2.2 测试数据集
本次实验数据来源江西科技学院信息技术研究所,共25个被试,采样率为1 000 Hz,通道为30通道,对每个被试分别采集300 s的非疲劳和疲劳EEG数据。实验中首先要求被试驾驶20 min,取最后5 min的数据标记为非疲劳数据,并通过疲劳调查表验证被试的非疲劳状态。然后要求被试连续驾驶30 min后填写疲劳调查表,如果认定被试处于疲劳状态则取最后5 min采集的数据作为疲劳数据,否则要求被试继续驾驶30 min,直至获取疲劳数据。
2.2.1 数据预处理
对原始数据进行0.01~70 Hz的带通滤波,进行伪迹去除,基线漂移去除等降噪处理后,提取每个受试者第150~250 s的数据,用1 s的滑动窗口不重叠的方式得到每人每类100个样本用于后续分析,即每人共200个样本,其中疲劳样本和非疲劳样本各一半,每个样本尺寸为30*1 000。
2.2.2 数据集划分
采用留一法依次选择25个被试的1个被试作为目标域,剩余24个被试作为源域,将选中的目标域数据分别按照一定比例划分成两部分,将较小部分目标域数据加入源域数据作为训练集,剩下的较大部分目标域数据作为测试集,模拟在不同比例目标域数据可用时的情况,比例划分设定为5%、10%、15%、20%、25%、30%。
2.3 实验结果与分析
2.3.1 预训练结果
首先讨论目标域可用比例为5%时的情况,将DeepConvNet在训练集上进行预训练,打乱训练集后选取80%数据作为预训练上训练集,剩余20%作为预训练上测试集。使用Adam作为优化器,设定学习率为0.05,动态调整学习率训练100个epoch,为了体现对齐的效果,分别在原始数据和EA后的数据上进行预训练,结果如表1所示,所有结果均为留一法试验后的平均值,下同。

表1 对齐与不对齐时预训练结果/%Tab.1 Pre-training results when aligned and unaligned/%
表1中可以看出经过对齐后的预训练效果结果无论在准确率还是F1分数还是精度或是召回率都优于使用原始数据预训练的效果。
2.3.2 预训练模型在目标域上的直接测试结果
使用2.3.1中得到的两个预训练模型,分别在原始目标域数据、EA后目标域数据、WAEA后目标域数据上直接测试,结果如表2所示。从表2中可以看出,使用对齐数据预训练的模型比使用原始数据预训练的模型分类效果更好,其准确率最高提升了4.11%。然而无论是在原始目标域数据上还是对齐后的目标域数据上,直接使用预训练的模型测试效果都较差,这是由于EEG的个体特异性导致的。为此我们使用模型迁移学习中微调的方式提高模型的跨被试疲劳驾驶EEG识别准确率。
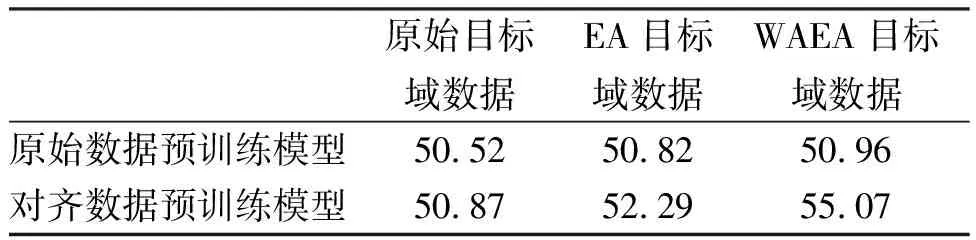
表2 不同预训练模型在不同处理的目标域上的准确率(单位:%)Tab.2 Accuracy of different pre-trained models on different processed target domains(unit:%)
2.3.3 预训练模型的微调结果
使用目标域中5%的数据,对DeepConvNet进行微调,微调层次为所有隐藏层,使用Adam作为优化器,设定学习率为0.001,动态调整学习率训练50个epoch。在目标域数据、EA后目标域数据、WAEA后目标域数据上分别微调,结果如表3所示。
可以看到经过微调后各个模型准确率均有了较大提升,其中表现最好的组合是在对齐数据上预训练,WAEA目标域数据集上微调后测试。同时我们发现训练集和测试集都对齐或都对齐得到的效果更好。
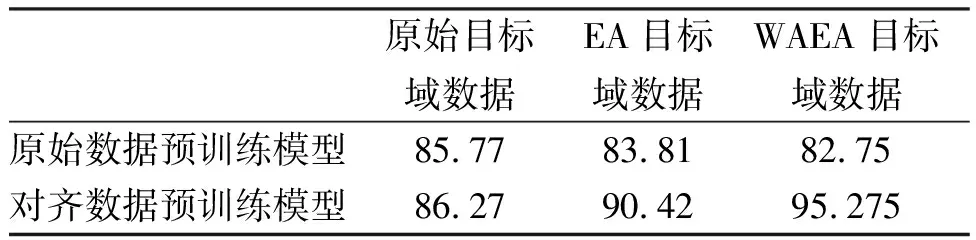
表3 不同预训练模型在不同处理目标域上的微调后准确率/%Tab.3 Accuracy of different pre-trained models after fine-tuning on different processing target domains/%
2.3.4 不同目标域可用比例下的微调结果
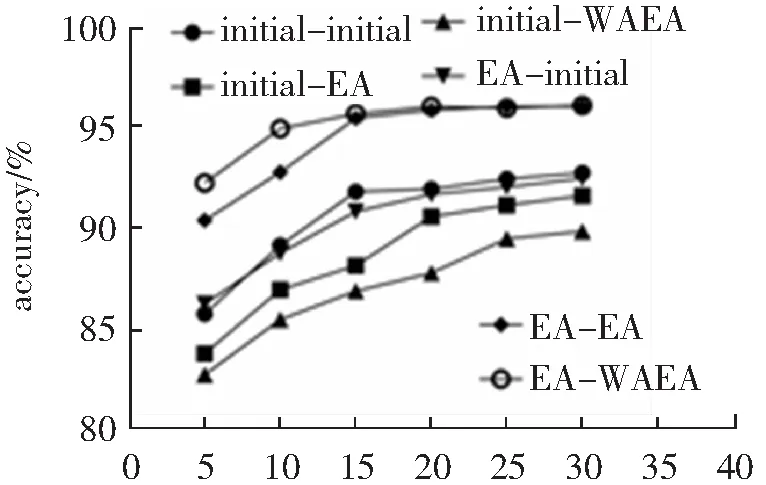
按照5%、10%、15%、20%、25%、30%的比例划分目标域,对训练集和测试集用不同的处理,重复预训练后微调的步骤,以目标域划分比例为α、平均准确率为accuracy绘制折线图,如图1所示。
图1中initial-initial表示在原始数据上预训练并在原始数据上微调的组合,类似的initial-EA表示在原始数据上预训练并在EA后的数据上微调的组合,以此类推。由图1可知,表现最好的组合依旧是EA-WAEA,在5%~30%的目标域可用比例中都保持对其他方法的领先。并且我们注意到EA-EA的结果随着目标域数据可用比例的提高,越来越接近EA-WAEA的结果,这是由WAEA的计算公式决定的,由式(9)可知当目标域比例越来越大时,WAEA会与EA相似,但是WAEA在目标域可用比例较小时比EA有较大领先,这是由于少量数据不足以计算出可靠的参考矩阵,WAEA利用源域中数据一定程度上解决这这个问题。另外我们发现,与表3类似的,使用对齐后的数据微调结果比不对齐的结果都要好。
α/%
3 结束语
本文结合欧式空间对齐方法和模型迁移学习对EEG疲劳驾驶信号进行跨被试少样本分类。首先对源域中被试进行EA并对目标域中被试使用WAEA以减少被试之间差异,用对齐后的源域数据和少量目标域数据对DeepConvNet进行预训练,并在WAEA后的少量目标域数据上微调。实验证明WAEA通过引入源域中参考矩阵,并利用矩阵的余弦相似度计算加权平均参考矩阵,能够弥补EA在样本较少时准确率较低的问题,同时我们发现对齐后的微调效果比使用原始数据的微调效果更好。该方法为迁移学习在EEG疲劳驾驶信号跨被试分析中提供了新方法,为有少量目标域时的对齐提供了一种新思路,并说明了对齐在迁移学习中的必要性。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
计算机技术与发展(2020年11期)2020-12-04
中国交通信息化(2018年5期)2018-08-21
电线电缆(2018年2期)2018-05-19
家庭影院技术(2017年10期)2017-11-23
电子与信息学报(2015年12期)2015-08-17
教育科学论坛(2014年8期)2014-03-01
中国工程咨询(2011年12期)2011-02-13
