
一步优化OSAHS 鼾声分类算法
2023-10-26 05:24余佳琪王冬霞马晓冬
实验室研究与探索 2023年7期
余佳琪, 王冬霞, 马晓冬, 张 严
(1.辽宁工业大学电子与信息工程学院,辽宁 锦州 121001;2.大连凡益科技有限公司,辽宁 大连 116033)
0 引言
阻塞性睡眠呼吸暂停低通气综合征(Obstructive Sleep Apnea-Hypopnea Syndrome,OSAHS)严重危害患者身体健康,鼾声的检测与分类作为诊断OSAHS的重要标志,已成为现阶段的研究热点。医院通过多导睡眠图(Polysomnography,PSG)对OSAHS 进行诊断。PSG法成本较高,不具备普适性。就此,提出一种简洁、高效的鼾声分类算法应用于临床诊断。
现阶段常采用人工切割标注[1-3],即分别通过人耳和PSG数据对齐的方式对整夜录音进行切割标注,复杂度较高,且易出现遗漏[4-5]。研究人员采用多阶段法对鼾声进行检测与分类,即有声段检测[6-7]、特征提取[8-9]和鼾声分类。鼾声分类方法的研究,主要采用两步分类实现[10]鼾声/非鼾声分类[11]、OSAHS患者鼾声/正常鼾声分类[8]。两步分类法过程复杂且计算量大。Luo 等[2]利用时域卷积网络(Temporal Convolutional Network,TCN)模型对患者鼾声、正常鼾声和非鼾声进行一步分类,准确率可达96.3%,但所选非鼾声数据集为理想集,不具备普适性。为解决上述问题,提出一步切割聚类的鼾声分类算法(BICVAD-CART-LDA algorithm,BVCL),以实现OSAHS 的辅助筛查。
1 BVCL鼾声分类算法
本文所用临床夜间实录鼾声数据包含OSAHS 患者鼾声、正常鼾声和非鼾声等多种声音。为实现复杂环境下实录鼾声的检测与分类,提出了一种BVCL 鼾声分类算法。
1.1 BV算法
1.1.1 BIC检测
切割点的检测[12-13]可视为统计学上的模型选择问题,通常以贝叶斯信息准则(Bayesian Information Criterion,BIC)作为判定标准,一般选择BIC 值小的模型。
将实录鼾声信号的特征序列建模成独立多元高斯过程xi~N(μi,Σi),其中xi∈Rd,i=1,2,…,N。提取实录鼾声的梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficient,MFCC)特征,xi作为从实录鼾声音频流中提取的特征向量序列,其中d为特征向量维数,N是特征向量个数。μi和Σi分别为xi的均值向量和协方差矩阵。
假设一段鼾声音频在第i时刻有一个跳变点,寻找跳变点可看作对模型H1:x1…xi~N(μ1,Σ1);xi+1…xN~N(μ2,Σ2)和模型H0:x1…xN~N(μ,Σ)进行选择的问题。
若存在跳变点,则模型H1的对数最大似然比
式中:N=N1+N2,N1和Σ1分别是{x1…xi}的特征向量个数和协方差矩阵,N2和Σ2分别是{xi+1…xN}的特征向量个数和协方差矩阵,“”为矩阵Σ的行列式。
因此,跳变点的最大似然估计
比较两个模型,H1将xi建模为两个高斯过程,H0将xi建模为一个高斯过程。这两个模型的BIC 值之差
式中:P=0.5[d+0.5d(d+1)]lnN为惩罚项;λ为惩罚项权重,一般取1。
因此,若式(3)为正,则采用2 个高斯过程的模型H1,即存在一个跳变点。所以,则表示此时有两个独立的鼾声音频分段,存在一个切割点;反之,,则表示此时只有一个独立的鼾声音频分段,没有切割点。
上述方法仅对鼾声进行单切割点检测,进一步提出一种多切割点BIC检测算法:设置一个检测窗口,通过BIC检测算法判断在当前窗口范围内是否存在切割点,若存在切割点,则该窗口继续移动,且窗口大小不进行调整;反之,则调整窗口的上限。重复上述过程直至检测窗口的上限超出整段音频的终点。
1.1.2 VAD检测
语音端点检测(Voice Activity Detection,VAD)算法[12]常用短时能量(Short Time Energy,STE)和短时过零率(Zero Crossing Rate,ZCR)判别语音信号和非语音信号。信噪比较大时,STE >ZCR,而非语音信号的STE <ZCR。因此,可利用STE 和ZCR的大小直接判别语音信号和非语音信号。
为解决起始带噪静音段终止点无效切割,提出利用VAD 技术快速筛选无效切割点。利用多切割点检测算法对处理后的切割点进行音频分段和VAD检测,若检测有语音端点,则不处理;反之,则剔除该切割点。
1.1.3 BIC聚类
切割后的实录鼾声音频片段还需进行标注,才能用于后续的分类训练。基于此,为提高标注效率,提出实录鼾声的BIC聚类算法。
假设S={si:i=1,2,…,M}为切割后实录鼾声音频片段的集合;χi=为从第i段提取的MFCC特征向量;为MFCC特征向量χi的总样本大小;={ci:i=1,2,…,k}为有k个簇的聚类,把每个簇ci看作是一个多元的高斯分布ci~N(μi,Σi)。每个簇的参数数量为d+0.5d(d+1),ni是簇ci中的样本数。由前文BIC算法原理可知:
以切割后的实录鼾声信号为节点,依据距离度量连续合并2 个最近的节点。S={s1,s2,…,sk}是当前的节点集;s1、s2是候选的一对合并节点,合并后的新节点是s。将当前的聚类S与新的聚类S′={s,s3,…,sk}进行比较。将每个节点si建模为多元高斯分布N(μi,Σi)。由式(4)可见,通过合并s1、s2,BIC值
式中:n=n1+n2为合并节点的样本数量;Σ是合并节点的样本协方差矩阵。若式(5)为负,则2 个节点不合并。
采用式(5)作为BIC 的距离度量,同时利用节点的MFCC特征作为初始点,遍历其余节点,计算每个节点与初始点间的BIC 距离。设置BIC 距离阈值,确定该段是否与初始点位于同一类簇中,实现OSAHS患者鼾声、正常鼾声和非鼾声的聚类,输出带标签的数据集送入分类算法(CART-LDA algorithm,CL)。
1.2 CL算法
1.2.1 CART模型
就分类而言,尽可能选择“纯度”最高的特征让划分后的样本都属于同一类。基尼系数(Gini)作为判别数据“纯度”的指标,在大数据量问题上,具有运行速度快的优势。
分类回归树(Classification and Regression Tree,CART)是以最小Gini 系数来选择最优特征并构建二叉树的分类模型。经切割聚类算法(BIC-VAD algorithm,BV)处理后的实录鼾声数据集为D,若从中提取的特征为F,以特征F作为划分指标,将数据集D划分为两部分D1和D2,则在特征F条件下的Gini 系数为:
式中:Di为Dk部分第i类的样本;C为实录鼾声所含类别数。
1.2.2 CL分类
经过CART模型特征选择后的最优特征集中包含MFCC等高维度特征,算法的维数与复杂度呈指数级增涨;同时,现阶段两步分类法[8,11]过程复杂且一步分类法[2]准确率不高。基于此,提出实录鼾声的CL 分类算法,既保留CART模型计算速度快,并且使用Gini系数能有效选择最优特征的优点,还引入线性判别分析(Linear Discriminant Analysis,LDA)算法[14]进行特征降维,节约模型训练时间,去除数据冗余,提高算法的分类准确率。
LDA算法是通过投影的方式去除数据之间冗余。假设有两类数据(OSAHS患者鼾声和正常鼾声),实录鼾声样本xi∈Rd,其中维数d=2;所有类别为ci的样本集。所有鼾声数据xi投影到单位向量ω后,其均值为
式中:ai为xi在单位向量ω上的偏移或者坐标,表示做了一个映射Rd→R,即通过投影将d维向量降到一维;μ1和n1分别为样本集D1的均值向量和样本数。同理,样本集D2的均值向量μ2,投影后的均值m2=ωTμ2。为使投影后的鼾声数据能准确分类,这两类鼾声数据的中心距离越远越好,即要使m1-m2最大。但该条件不能保证能正确地对每一个数据进行分类,还需考虑每一类数据的方差,方差大表示两类数据之间有重叠,方差小表示无重叠。
LDA算法未采用方差,而采用散布矩阵
式中:
对式(10)求导,得:
式中,令λ=J(ω),λ为常量。
LDA算法仅适合二分类问题,为实现OSAHS 患者鼾声、正常鼾声和非鼾声的3 分类,对上述算法进行改进,即可计算S-1B对应的最大特征值的特征向量。
式中:μ为整个实录鼾声样本的均值向量;ni、μi分别为第i类中样本个数和均值向量。
CL分类算法的基本思想:利用CART模型进行最优特征选择;计算每一类的协方差矩阵Si,i=1,2,3,并计算S-1B的特征向量Q=[ω1,ω2,…,ωd],其中ω1,ω2,…,ωd对应的特征值满足λ1≥λ2≥…≥λd,矩阵W=[ω1,ω2,…,ωk]由Q中前k个特征向量组成,其中k<d;对原实录鼾声数据X进行投影:
式中:X为原始数据集;Y为将X向子空间W =span{ω1,ω2,…,ωk}投影后得到的分类后的数据集。
1.3 BVCL算法
图1 为BVCL算法流程。将临床夜间实录鼾声作为输入,经分帧加窗处理后,从音频信息中提取MFCC特征,通过BIC 检测算法实现多切割点检测;利用VAD检测算法筛选无效切割点;通过BIC 聚类算法将切割后的片段进行聚类,输出带标签的数据集送入CL算法,从音频信息中提取MFCC、频谱带宽、色度频率等26 个特征,对OSAHS患者鼾声、正常鼾声和非鼾声进行一步分类。

图1 BVCL算法流程
2 仿真结果与分析
为验证所提算法的有效性,以某医科大学附属医院整夜实录鼾声数据作为输入,对OSAHS 患者鼾声、正常鼾声和非鼾声进行切割聚类和分类,并利用k折交叉验证[15](k= 10)和受试者工作特征(Receiver Operating Characteristic,ROC)曲线来评估分类模型的性能。
2.1 实验参数设置
实验数据包含13 例OSAHS患者和6 例正常打鼾者。采用PSG 监测系统监测受试者整晚(约9 h)的PSG信号,同时将麦克风放置在距离受试者口鼻之上约45 cm处,以8 kHz的采样频率和16 bit采样精度采集声信号后保存于录音机中,获得原始睡眠鼾声信号。
鉴于整夜实录鼾声较长,将其分成15 min 文件长度进行处理。利用BVCL算法从实录鼾声信号中提取有声段进行切割聚类,共计23897 个声音片段,作为分类阶段的样本集。从这些带标签的片段中提取MFCC、频谱带宽、色度频率等26 个特征作为训练对象,从样本集中随机抽取19118 个样本(约占总数据的4/5)作为训练集,其余4779 个样本作为测试集,进行算法模型的训练和测试。
2.2 仿真结果
(1)验证算法切割聚类性能。为验证BVCL算法的快速切割聚类能力,表1 为相应的仿真结果。

表1 切割聚类仿真结果
结果表明,将BVCL 算法切割后的声音片段与经由专业人员标注后的片段进行比较,BVCL 算法的平均准确率为98.99%,能有效从实录鼾声信号中切割聚类出OSAHS患者鼾声、正常鼾声和非鼾声。与人工切割标注法[1-3]相比,未用算法之前人工需要45.38 h,使用该算法后只需6.75 h,时间节省了38.63 h,为快速检测鼾声提供了前提,且准确率提高了3.32%。切割聚类后输出带标签的数据集,经人工修正至100%准确率后,作为分类模型的输入集。
(2)验证算法分类性能。为验证BVCL算法的分类效果,选取切割后片段80%为训练集,20%为测试集。图2 所示为算法分类结果。

图2 BVCL算法分类结果
如图2 所示,在临床复杂环境下,BVCL 算法的分类准确率可达99.15%,且具有较强的抗干扰能力。
k折交叉验证能有效解决过拟合与欠拟合的不足,且可靠性较高。利用k折交叉验证(k=10)验证BVCL算法分类性能。将样本随机均匀分为k组,每组数据分别作为一次测试集,其余k-1 组作为训练集。采用平均分类准确率作为分类模型的评价指标。图3所示为k折交叉验证结果。

图3 k折交叉验证结果(k=10)
由图3 可见,BVCL 算法的平均分类准确率为99.02%,极差为0.24%,具有较强的鲁棒性。图4 所示为CART、LDA和BVCL算法的ROC 曲线。ROC 曲线下面积为AUC(Area Under Curve),AUC 的取值范围一般为0.5 ~1.0,AUC越接近1.0,分类效果越好。

图4 ROC曲线
由图4(a)可知,采用CART 模型分类的AUC 为0.919;由图4(b)可知,采用LDA 算法分类的AUC 为0.888;而采用BVCL算法分类的AUC为0.990。结果表明,BVCL算法的分类效果更好。
(3)算法对比。所提BVCL算法将两步分类过程简化为一步,与文献[8,11]中的算法相比分类准确率提高了4.08%;与文献[2]中的一步分类法相比,论文所用数据均来自临床夜间实录,更具普适性,且分类准确率提高了2.85%。图5所示为各算法仿真结果对比。
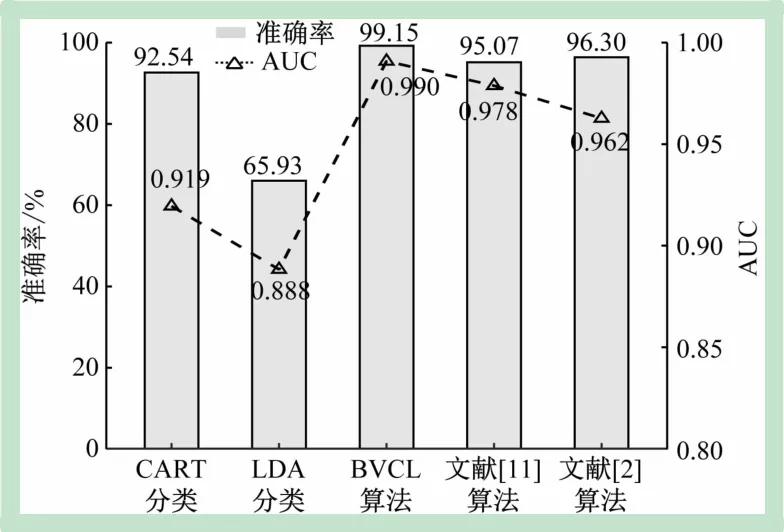
图5 各算法仿真结果对比
如图5 所示,BVCL算法的分类准确率和AUC 均优于对比的算法。结果表明,BVCL 算法的准确率和分类效果均有提升。
综上,在临床复杂环境下,BVCL算法的准确率可达99.15%,且分类效果更好,能快速实现OSAHS 患者的辅助筛查。
3 结语
由于临床诊断OSAHS 费用昂贵、操作复杂,寻找一种低成本、易于操作的方法来辅助筛查OSAHS具有广阔的前景。考虑到临床实测环境复杂导致OSAHS鼾声检测准确率不高,提出一步切割聚类的鼾声分类算法(BVCL)。仿真表明,该算法在大量数据快速切割聚类以及OSAHS检测分类方面具有良好的性能,为便携式睡眠鼾声监测设备走向实际提供一种快速实现的手段。未来将继续优化算法针对低信噪比环境下的分类性能,同时提取并筛选更多分类效果好的特征。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
学苑创造·A版(2019年11期)2019-12-05
中国交通信息化(2018年5期)2018-08-21
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
人生十六七(2015年26期)2015-08-22
