
基于访问控制的可验证医疗区块链数据搜索机制
2023-10-26 05:36甘臣权杨宏鹏祝清意贾家庆李昆鸿
重庆邮电大学学报(自然科学版) 2023年5期
甘臣权,杨宏鹏,祝清意,贾家庆,李昆鸿
(1.重庆邮电大学 网络空间安全与信息法学院,重庆 400065;2.重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
医疗健康对于人们生活来说至关重要,对医疗数据的分析有助于各种疾病的诊断与预防[1-2]。电子健康系统和电子病历的使用为医疗数据的存储、共享、检索和追踪提供了便利。早期,医疗数据存储在各医疗机构本地服务器,造成了数据孤岛,不利于数据共享[3]。随着云计算的发展与应用,云服务器作为一个大容量的存储中心开始流行起来[4]。基于云的电子医疗系统既有利于数据共享,又有利于节省存储成本。但是,以服务器为中心的云服务往往面临单点故障和共谋攻击的威胁,无法完全保障医疗数据的安全性。
自中本聪发明数字加密货币比特币以来,其底层区块链技术[5]由于具有去中心化、不可篡改、透明等特点开始受到极大关注。以太坊Ethereum[6]和超级账本Hyperledger[7]相继诞生。区块链技术已被广泛应用于能源[8]、金融[9]、供应链[10]、医疗[11]等众多领域。在医疗领域,许多研究工作尝试构建医疗区块链存储电子病历(electronic medical records,EMR)[12],利用区块链特性来解决基于云的电子健康系统存在的安全问题。
现有基于区块链的电子医疗系统研究大多关注数据访问和共享过程中的安全性[13-14]和隐私保护[15-16],但当需要从医疗区块链上搜索所需数据时,往往需要按照顺序依次逐个遍历医疗区块链上所有区块。以Ethereum为例,由于医疗数据是通过智能合约调用相关函数上传到区块链中的一些额外数据,并以十六进制的形式存在交易中的“input”字段[17],在每次搜索时都需要遍历整条区块链,先获取块,再获取交易,最后获取交易中“input”字段进行解码获取数据[18]。然而,随着区块链逐渐增长,搜索耗时也会越来越长,显然搜索效率不高,也无法对医疗区块链上的数据进行分类,实现多条件查询。
为了加快区块链搜索效率,文献[19]提出了一种基于图形处理单元(graphics processing unit,GPU)的键值搜索查询方法,但无法查询存入链中的额外数据。文献[20]提出了一种基于区块链的EMR细粒度访问控制查询方案,支持块、不同块的相同属性以及两者的混合查询。由于授权、加解密无需医疗公钥基础设施,大大减少了查询时间。在此基础上,文献[21]提出了一个在块中构造新Merkle树来存储EMR的存储方法,支持所有参与者按照各自身份进行多条件查询,遗憾的是并没有实验验证。为了提高在块内的查询效率,文献[22]将比特币的挖掘能力转化为查询能力,结合布隆过滤器构建了一个物联网领域的查询模型,但该模型存在一定的误判率。类似地,文献[23]提出了一种存储容量可扩展的高效查询模型ElasticQM,从缓存、全局查询算法以及基于B-M树的区块内部结构3方面出发提升查询效率。虽然文献[19-23]对区块链内部结构进行修改提高了在每个块中的查询效率,但是都需要遍历整条链,故从整体上查询效率提升并不明显。
不同于上述研究,文献[24]提出了一种支持快速空间查询的时空数据处理方法,解决了块中因顺序遍历而导致查询速度低的问题。文献[25]提出了一种基于区块链具有公平性的可搜索加密方案,但该方案只关注了查询的准确性,并没有在时间上提高搜索效率。文献[26-27]利用数据库特性实现了低延迟和丰富的查询,但没有提供相应的验证机制,无法保证数据的正确性和可靠性。文献[28]的EtherQL假设服务器总是返回正确结果,但这假设明显与现实不符,无法实际应用。
为了弥补文献[26-28]的缺点,文献[29]以Hyperledger Fabric为例,结合MySQL提出了一种FabricSQL关系查询方案,并为存储在数据库中的交易数据设计了一种存储验证机制,从而保证数据不被篡改。然而,MySQL这种关系数据库,无法应对海量数据,且扩展性比较差。对此,文献[30]引入了HBase非关系数据库,并提出了一种支持验证的具有高吞吐量的查询方法。类似地,文献[31]也提出了一种在区块链系统中加入外联数据库的可验证查询层的方法。此外,为了实现高准确性和匹配性医疗数据搜索,文献[32-34]研究了相关的激励机制促使患者积极共享医疗数据。虽然利用数据库可以丰富数据查询功能和缩短数据搜索时间,但是文献[29-34]只是加快了单个块查询、交易查询以及用户余额查询,并没有考虑额外数据的分类搜索,自然无法支持不同身份用户对不同数据的查询。
针对以上述问题,本文提出了一种带有访问控制的可验证医疗区块链数据的搜索机制。首先,获取医疗区块链上的交易数据构建相应索引,并采用非关系数据库进行存储,借助数据库强大的查询功能加快数据搜索效率,实现多条件查询;其次,采用访问控制策略保证用户访问的合法性和数据的安全性,并设计了可验证机制防止数据库中的数据发生错误,确保访问数据的准确性;最后,在以太坊Ethereum、非关系数据库MongoDB和真实公开的医疗数据上进行了实验分析,展示了所提可验证搜索机制的有效性。
1 问题描述
在详细介绍可验证搜索机制之前,有必要对以下问题进行描述说明,以加强阐述。
问题1医疗区块链存储原始电子医疗数据为何可行?
问题2医疗区块链为何需要数据搜索与访问控制?
问题3医疗区块链依序逐块数据搜索为何效率不高?
问题4采用数据库辅助医疗区块链数据搜索为何可行?
针对问题1,当前医疗区块链处理电子医疗数据的方式可以分成2类:第1类是链上只存储电子医疗数据对应的哈希值,原始电子医疗数据存储在云服务器中[29],这样做的优点是可以减少块的存储空间,缺点是无法完全保证原始电子医疗数据的安全性与正确性,因为云存储无法防止共谋攻击,一旦发生删除或篡改有可能无法恢复;第2类是链上存储原始电子医疗数据[12,20-21,34],优势是可以弥补第1类存储的缺点,不足是占用块存储空间较多,会影响医疗区块链的整体性能。
本文充分考虑上述2类处理方式的优缺点,将占用空间较小的文本型原始电子医疗数据采用第2类存储,占用空间较大的(比如:CT图像)仍然采用第1类存储。实际上,第1类存储可以转化为第2类存储,因为可以采用统一的模式对所有原始电子医疗数据处理成占用空间较小的文本型数据。比如:将包括CT图像在内的原始电子医疗数据都采用文本型关键信息描述,然后采用数据压缩技术进一步减少空间占用。图像型数据,就算被篡改或删除,链中的文本型描述也可以查看和校验,实在不行可以对患者重新扫描生成最新的。为了描述方便,本文只研究第2类存储。
针对问题2,无论是电子医疗数据是否存储在医疗区块链上,日常的医疗诊断、第三方机构(比如保险公司)办理业务,都需要通过医疗区块链查询患者的电子医疗数据,随着医疗区块链数据的不断增多,要在海量数据里精准快速地查找离不开搜索机制,就像在互联网搜索过程中离不开搜索引擎一样。医疗区块链上存储的医疗数据具有敏感性与隐私性,无法完全将互联网搜索引擎照搬到区块链中来。
医疗区块链数据搜索不能像互联网中搜索引擎一样不区分内容或用户身份,不同用户对医疗区块链上的医疗数据搜索范围肯定不一样。医疗机构每天需要对某种疾病进行研究或对不同患者进行治疗,一般需要搜索全部医疗数据;患者一般只能搜索自己的医疗数据;第三方机构一般只能搜索与之相关人员的医疗数据。为了保障医疗数据的安全性与隐私性,必须区分不同用户的搜索权限,这就需要采用访问控制。
针对问题3,若依序逐块进行数据搜索,每一次都要从头开始逐块遍历,虽然可以找到相应结果,但是随着医疗区块链数据的不断增多,这样的“穷举法”在海量数据里查找无疑会越来越耗时。此外,依序逐块搜索提供的查询功能比较单一,无法满足医疗区块链中不同用户的多条件访问需求,这也会导致搜索效率不高。
针对问题4,数据库是按照数据结构来组织、存储和管理数据的仓库,可以提供丰富的查询功能,在各行各业得到了广泛应用。在医疗区块链数据查询方面,文献[29-31]已经尝试采用关系数据库或非关系数据库进行辅助查询,这表明医疗区块链数据搜索采用数据库是可行的。
结合上述问题,本文提出了一种带有访问控制、可验证医疗区块链数据的搜索机制。为了提高搜索效率、实现多条件查询和防止数据篡改,本文采用链上存储原始电子医疗数据和非关系数据库进行辅助搜索。
2 可验证搜索机制
本文假设各个医疗机构通过协商组成一个联盟链,其系统模型如图1所示。模型共有5个实体:患者、医疗机构、联盟链、数据库、其他访问用户。搜索机制包含3个阶段:电子医疗数据链上存储、交易数据链下存储以及可验证搜索。

图1 系统模型Fig.1 System model
2.1 医疗数据链上存储
当患者前往医疗机构就医时,医生负责对患者进行诊断治疗,相应生成的医疗数据将会上传到医疗区块链中,上传规则可参照文献[34]。存储在区块链上的医疗数据对加入医疗区块链系统中的所有用户都可见,为保护患者隐私,在数据上链前需要判断是否存在敏感数据需要进行加密处理,加密细节可借鉴文献[35-36]。
本文所涉及的电子医疗数据主要包含病历id、患者姓名、年龄、性别、电话、地址、疾病类型、诊断信息、图像对应的哈希值、文本型关键信息及其在本地云中的存储位置、医院id、部门id、医生id等信息。首先,将这些存入数据全部拼接并进行哈希,生成一个哈希值,即

(1)
上传医疗数据所用的智能合约为数据上传合约(dataupload contract,DUC),电子医疗数据通过函数uploadEMR(string id_c_n,string name,uint age,…)进行上传。
交易发起者用这些十六进制数据来告诉合约运行的特定函数。生成的十六进制数据由函数的标识符以及12组参数组成。其中,函数标识符是该函数签名的前8个字符,它告诉智能合约找到具体的某个函数。紧接着是12组以32字节为一组的参数,它告诉智能合约往函数中传递的值。
此外,针对一个块中可能会出现无法存放一份完整电子医疗数据的情况,将其分组之后,生成多笔交易存储在多个块中,并使用id-count-num关联将其分割成多条交易的电子医疗数据。id-count-num中,id表示病历id,将分组的数据关联起来;count表示总共被分割成几条交易;num表示第几条交易,它用来拼接字段的先后顺序。id-0-0表示数据没有被分割。
本文以以太坊为例在图2中描述了区块交易结构以及input字段的组成部分。为了简单起见,图2中只列出了函数的前3个参数,同时在表1中对交易结构的字段进行了解释。

表1 交易结构中主要字段解释Tab.1 Main fields in the transaction structure are explained
2.2 交易数据链下存储
将医疗区块链中的交易数据导入数据库前需要考虑如何设计数据库中的表来进行存储。非关系数据库类型繁多,且不同类型数据库设计方式也不同。由于每份电子医疗数据可以以文档的形式出现,故本文选取面向文档类型的非关系数据库MongoDB来进行设计,在MongoDB中的集合就相当于关系数据库中的表。由于本文关注的是如何搜索患者的电子医疗数据,故只需往数据库里存储input字段中包含的医疗数据以及可以定位交易信息的N、H(具体含义见表1),定位交易信息主要用于后续的验证。
本文的电子医疗数据主要包含患者个人信息(patientInfo),医院信息(hospitalInfo),患者病历信息(EMRInfo)。将医疗区块链中的医疗数据存储到数据库后,为了后续验证医疗数据的正确性和完整性,还需要提取区块信息(blockInfo),用于定位医疗数据存储于哪笔交易。它们包含的主要字段如下。
patientInfo
{
"id" : 1,
"name" : Bob,
"age" : 20,
"sex" : Male,
"phone" : ***,
"address" : Chongqing
}
hospitalInfo
{
"id" : 1,
"hosId" : 2,
"depId" : 3,
"docId" : 4
}
EMRInfo
{
"id" : 1,
"type" : "Enterogastritis",
"info" : "Diarrhea, vomiting, and abdominal pain",
"phoHash" : "0x0dff12a2",
"phoLocation" : "/mnt/dbfs",
"phoDescription" : Nothing
}
blockInfo
{
"id" : 1,
"blockNumber" : 10,
"transactionIndex" : 1,
"hash" : "0xac12d5dd"
}
通常情况下,电子医疗数据中4部分数据分别存储在4个集合中,并通过绑定id关联在一起。当查询一份满足条件的电子医疗数据时需要通过关联的id将4个集合中关联的数据都显示出来。在这种情况下,查询性能会比较慢,且在更新或添加数据时,4个集合都需要操作。本文使用一对一内嵌文档模型。所谓一对一就是一份电子医疗数据只对应一个患者,通过内嵌文档模型将4种信息作为单个文档内嵌在主文档中,添加、删除、修改、查询只需要操作一个集合即可。这样更易于管理,消除了因关联4个集合而带来的性能影响。一对一内嵌文档模型的数据结构设计如下。
{
"id" : 1
"patientInfo" : {
"name" : "Bob",
"age" : 20,
"sex" : "male",
"Address" : "Chongqing",
"phone" : ***
}
"hospitalInfo" : {
"hosId" : 2,
"depId" : 3,
"docId" : 4
}
"EMRInfo" : {
"type" : "Enterogastritis",
"info" : "Diarrhea, vomiting, and abdominal pain",
"phoHash" : "0x0dff12a2",
"phoLocation" : "/mnt/dbfs"
}
"blockInfo" : {
"blockNumber" : 10,
"transactionIndex" : 1,
"hash" : "0xac12d5dd"
}
}
注意:这些字段只是作为一个例子便于讲解,而实际应用中可能是其他字段属性。于是,可以将举例的字段属性抽象成一组字段属性:属性1,属性2,…,属性n,对应值分别为1,2,…,n。具体的字段属性和数量由实际情况确定。
下面将介绍如何处理区块链中的医疗数据,并将其存储在数据库中从而实现对医疗数据多条件搜索,具体处理过程见算法1。在这里,政府部门可以作为一个可信机构充当医疗区块链系统中的搜索方,负责将区块中的医疗数据处理入库并对系统进行维护。
利用数据库,可以根据搜索条件查询对应的所有数据。另外,本文对区块链中医疗数据的入库处理进行持久化处理,当发生故障或更新时,需要暂停工作,在下次继续工作时,可以直接从上次同步的区块高度开始继续处理区块中的医疗数据,这样可以避免每次都从头处理区块中的医疗数据。
算法1医疗区块链中数据处理过程
输入:区块号
输出:true or false
1.定义包含
2.定义5个文档document0,document1,document2,document3,document4;
3.定义3个字典,分别包含patientInfo,hospitalInfo,EMRInfo所对应的字段;
4.定义两个字典map_data和map_count;
5.for(访问第1个到最后一个区块)
6. {
7. 访问区块中的所有交易;
8. if(交易为空)
9. { 跳转到步骤4; }
10. for(访问每笔交易)
11. {
12. 访问交易中的,input和;
13. result = input解码,生成数据为
14. first = 获取result第1个元素的value;
15. 分隔first,分别获取id,count,num;
16. if(count != 0)
17. {
18. if(id不在map_data和map_count中)
19. {
20. 创建一个长度为count的数组arr;
21. 将result存入arr的第num个位置;
22. 将
23. 将
24. }
25. else
26. {
27. 将result存入map_data中id对应arr的第num个位置;
28. 将
29. if(map_count中id对应的值 30. {跳出本次循环继续下一次循环; } 31. result = 按顺序合并id对应map_data的arr的所有元素,如果有重复字段,则将对应的值按顺序全部拼接,id-count-num变为id; 32. 清除map_data和map_count中的id; 33. } 34. } 35. for(访问result列表) 36. { 37. k=访问 38. v=访问 39. if(k在patientInfo中) 40. { 将k和v以key-value的形式存入到document1; } 41. else if(k在hospitalInfo中) 42. { 将k和v以key-value的形式存入到document2中;} 43. else 44. { 将k和v以key-value的形式存入到document3中; } 45. } 46. 将、、以key-value的形式存入到document4中; 47.将document1、document2、document3、document4合并到document0中; 48. 将document0插入到数据库中; } 虽然区块链本身具有防篡改特性,但是当把数据处理存储到数据库之后就无法保证返回结果与区块链中的原始数据的一致性。本文提出了一种支持搜索的验证机制,根据用户身份不同,加入了一个访问控制。本文工作框图如图3所示。 图3 可验证搜索工作框图Fig.3 Verifiable search work diagram 2.3.1 访问控制 本文访问控制是通过智能合约实现的,访问控制流程如图4所示。方案中包含了5组智能合约:用户合约(user contract,UC)、访问合约(access contract,AC)、搜索合约(search contract,SC)、行为合约(behavior contract,BC)以及撤销合约(revoke contract,RC),详情如下。 图4 访问控制流程图Fig.4 Flowchart of access control UC:该合约主要的作用是用户注册和用户身份验证,合约包含以下函数。 • register(string identify,string name)。在本文方案中,凡是加入医疗区块链系统的用户都需要调用此函数进行身份注册并进行分类。其间,系统会为注册用户生成一个由数字和字母组成的地址作为假名与真实身份关联,用户可以使用假名参与访问过程。注册信息会存放到一个用户列表,并由医疗区块链系统进行维护。方案中本文将用户分为4类:未注册人员、医疗机构、患者和第三方(如银行、保险公司、个人),分别用0,1,2,3代替。 • isValidUser()。在用户发送搜索请求之前,用户调用此函数进行身份验证。该函数会获取用户的假名并发送给医疗区块链系统,医疗区块链系统会根据假名从用户列表中进行匹配,并验证其身份,最终返回身份验证结果。 AC:该合约主要用于定义用户的访问控制策略。经过医疗区块链系统验证之后,决定访问用户是否有权限访问电子医疗数据。如果用户为医疗机构,则无需授权,可以直接访问所有医疗数据。如果用户为患者本身,只允许访问自己的医疗数据。如果用户为第三方或者患者想要访问其他患者的医疗数据,需要经过授权之后才可以访问,合约包括以下函数。 • grant()。用户经过身份验证之后,医疗区块链系统调用此函数进行授权。同时,允许设置相应的访问时间,它接受以秒为单位的值。 • getResult()。该函数用于返回请求之后的授权结果。 SC:当用户经过授权之后,则可以通过此合约根据自己的查询条件发送查询语句到搜索方,合约包含以下函数。 • search(string s)。用户调用此函数,发送自己的搜索条件,可以发送多次。 BC:该合约主要用于判断用户在整个访问过程中的恶意行为。若用户存在恶意行为(例如,频繁请求、无效请求、无权限请求等),则需要记录该行为,并进行相应的惩罚,合约包含以下函数。 • illegalActs(string depict)。当用户发生恶意行为时,医疗区块链系统调用该函数,记录用户的非法行为。同时,记录该用户的非法行为次数。 • setPunishTime()。当用户存在恶意行为时,医疗区块链系统记录其行为之后会调用该函数设置惩罚时间,其间不允许用户进行访问操作,只有惩罚时间结束之后才可以继续访问。 RC:该合约主要用于撤销用户的访问控制权限。在整个访问过程中,如果用户泄漏了电子医疗数据,医疗区块链系统可以实时撤销用户的访问权限。此外,当用户访问时间结束或者用户访问结束时,医疗区块链系统也会撤销访问权限,合约包含以下函数。 • deleteAccessByTA()。当发生上述任何一种情况时,医疗区块链系统会调用此函数,撤销用户的访问权限。 2.3.2 搜索 经过访问控制之后,用户通过客户端输入搜索条件,然后生成一条查询语句s,并通过SC中的search(string s)函数向搜索方发送搜索医疗数据请求。该函数主要涉及一笔带有搜索请求数据的转账交易。由用户向搜索方发送一笔转账交易,充当搜索医疗数据的费用,并通过search函数中传递的参数作为请求搜索的数据。 搜索阶段除了从数据库获取医疗数据之外,还支持从区块链以及客户端缓存上搜索。最终,由搜索方返回搜索结果集resultSet为 resultSet={idi,{patientInfoi,hospitalInfoi, EMRInfoi,blockInfoi}} (2) (2)式中,i∈1,2,…,n。 整个搜索过程可以分为3种情形。 情形1用户都会有一个客户端缓存,每成功完成一次搜索请求之后,都会将搜索结果缓存在本地。在下一次搜索相同数据的时,就会先从本地缓存中进行查找并获取结果集resultSet。 情形2在本地缓存没有满足用户的请求结果时,就会请求搜索方,搜索方根据用户发送的查询条件通过数据库进行查询,如果没有对应的结果就会返回未查询到的信息,否则把查询到的结果集resultSet返回给用户。 情形3由于链下存储存在无法及时将数据处理并存储到数据库的情况,本文考虑了以下两个方面。 1)入库操作由于故障等原因会暂停工作,区块链上的数据会持续更新,从而导致更新后的区块数据没有处理。 2)在区块链网络中,会涉及到网络延迟,也会出现区块数据没有处理的情况。 基于此,搜索方会保留处理的最终区块高度He,当接收用户的查询请求时,执行完数据库查询之后,会从高度为He+1的区块开始进行链上搜索,由于此阶段所得的数据来源于区块链而不是数据库,故无需进行额外验证。 2.3.3 验证 为了保证数据库中的数据没有被篡改过,本文设计了一种验证机制。在该机制中,区块链系统共涉及两方面验证。一方面是定期对数据库进行验证。另一方面是对搜索结果进行验证。 定期验证。在将链上的医疗数据经过处理存储到数据库之后,医疗区块链系统会定期(比如每隔1个月)对数据库中的数据进行验证,并可以对被篡改过的医疗数据进行更正。验证步骤如下。 1)在将区块链中的医疗数据处理到数据库之后,MongoDB会按写入的顺序进行存储,那么就会按区块的顺序从头开始存储,只有发生更新的时候,数据就会跑到数据库的最后面。因此,需要事先对blockInfo中的blockNumber字段建立索引,以提升查询某个块对应数据的速度。 2)医疗区块链系统从区块链中的第1个块开始,获取N以及里面的交易在块中的索引集合IN={1,2,…,k},k表示索引。首先,使用数据库查询区块号为N的所有医疗数据,并对索引值n升序排序,然后依次获取这些医疗数据的交易n,并与IN中的索引值进行匹配,确定两边医疗数据包含的索引值是否对应。如果全都对应,则执行步骤3);如果数据库中少了对应的索引,即有数据遭到删除,则区块链中对应索引的交易数据进入处理阶段;如果数据库中的索引相比于区块链中的数据多出来了,即增加了额外的数据,则执行删除操作,最后再执行步骤3)。 4)医疗区块链系统会从数据库尝试获取比目前最高区块高度还高或者区块号为负数的数据。如果有,则全部删除,否则不做任何处理。 搜索结果验证。在区块链接收到用户请求后,会通过数据库查询到所有满足条件的医疗数据并进行分页供用户浏览查看,用户在浏览医疗数据的同时,医疗区块链系统对所有结果进行分页验证,这样可以节省用户等待时间。同时,支持返回正确的验证结果并对数据库中被篡改过的医疗数据进行更正。验证步骤如下。 1)当用户浏览某一页的医疗数据时,医疗区块链系统会计算该页每条数据的哈希值,即H(m)=SHA-256(id‖患者姓名‖…‖医生id)。 2)获取每份医疗数据对应的blockInfo部分,通过blockInfo中的N先定位区块,接着根据n定位对应的交易位置。 当用户查看像CT这种占有较大空间的医疗数据时,还需要根据EMRInfo中的图像存储位置,从相应的云上进行下载并生成哈希值,然后与EMRInfo中的图像哈希值进行对比,并判断是否被修改过。 本节将对所提可验证搜索机制进行实验分析,以展示其优越性。首先介绍用于实验的环境配置和数据集,然后进行性能分析,包括与文献[6,33]的对比分析。 本文使用Java和MongoDB进行环境部署,并模拟所提可验证搜索机制中涉及的多个功能部分,并在两台不同的设备上创建了多个虚拟以太坊节点,设备配置如表2所示。 表2 设备配置Tab.2 Device configuration 在两台设备上分别安装Ethereum的geth客户端,并通过geth客户端创建多个以太坊节点充当不同角色,将所有节点组成一个医疗区块链系统。在这里所有节点均可充当矿工,并随机选取一个节点部署智能合约,用于医疗机构上传患者的EMR,使用web3.js与geth客户端进行交互。为了方便操作,使用Java调用web3.js API,通过HTTP请求私有以太坊网络进行通信,通过里面的封装类实现获取私有以太坊网络上的相关数据。此外,在其中一台设备上安装MongoDB数据库,使用Java调用MongoDB API与本地数据库进行通信。通过Java将区块链与MongoDB建立联系,将从区块链提取的数据存入数据库中。 由于没有公开可用的电子医疗数据库,本文采用医疗保险和医疗补助服务中心(centers for medicare &medicaid services CMS) 2019年第2组公开报告的临床医生使用数据[37]。该数据集包含10个属性,1 479 394条数据。 所提可验证搜索机制的性能主要依赖于区块链平台、智能合约以及数据库,接下来将详细分析该机制的效率,展示其可行性。 1)搜索时间成本。为测试所提可验证搜索机制在时间上的搜索效率,本文随机对某一疾病进行搜索。例如,搜索测试数据集中spec=“HYPERTENSION”的患者临床数据。通过语句:db.medical.find({spec:"HYPERTENSION″})进行查询,其中,medical表示数据所在的集合。同时测试了在不同交易数量中的搜索时间(10000到100000笔交易数据),并与以太坊[6]、文献[33]进行了对比,其结果如图5所示。 图5 搜索时间比较Fig.5 Search time comparison 从图5可以看出,虽然随着数据量的增大,搜索时间也在不断增加,但是本文搜索时间明显比另外两个增长缓慢,且仍是毫秒级。文献[33]是将整个区块链结构进行同步,效率会比较慢,本文只是将交易中的医疗数据同步到数据库,其余不作处理,这样提高了搜索医疗数据的效率。通过数据库中存储的每份医疗数据所在区块链中的位置可以快速定位并进行验证,这表明本文机制具有较高的搜索效率。 此外,在10万条数据中,本文还测试了所提可验证机制在单条件和多条件搜索下有无索引的搜索时间对比。这里单条件表示符合单个字段对应的医疗数据,比如spec=“HYPERTENSION” 患者的临床数据,用户通过客户端向医疗区块链系统发送查询语句db.medical.find({spec:"HYPERTENSION″})。多条件表示符合多个字段对应的医疗数据,这里我们只测试两个条件的搜索时间。例如,要搜索{spec=“HYPERTENSION”,lst_nm=“LARSON”}的患者临床数据,则用户通过客户端向医疗区块链系统发送查询语句 db.medical.find({ spec:"HYPERTENSION", lst_nm:"LARSON" }) 来实现。单条件与多条件在有无索引下的搜索时间对比如图6所示。由图6可知,多条件搜索比单条件搜索耗时要少,即搜索越精确,耗时越少;有索引比无索引耗时要少。 图6 单条件与多条件在有无索引下的搜索时间对比Fig.6 Search time comparison between single criteria and multiple criteria with or without indexes 最后,以10万条数据为例,根据不同的用户类型,并根据访问控制,测试了不同用户搜索自己所在范围时所消耗的时间,其结果如图7所示。首先,医疗机构会搜索患者临床治疗时所处的医学专业,本次测试搜索了spec=“PATHOLOGY”和spec=“ANESTHESIOLOGY”历史临床数据,搜索时间根据数据量的不同而不同;其次,患者只可以搜索自己的临床数据,搜索时间大致在50 ms左右;而第三方被允许搜索一个至多个人的临床数据,根据搜索用户的数量不同其搜索时间也不同。相比较,患者搜索自己的数据用的时间相对较少。 图7 不同用户搜索不同范围数据的时间比较Fig.7 Timecomparison of different users searching different ranges of data 2)验证时间成本。本文使用块定位数据以及所提机制的定位方法(根据块和交易在块中的序号定位)测试了平均每条数据验证所花费的时间,包含验证正确数据和验证被篡改过的数据,还对一次性验证与分页验证进行了对比。其中,图8是通过将数据记录到Excel中生成的,图9是将所得的实验数据通过Matlab生成。图8—图9中每个值都是通过对数据验证时间平均取100个度量来计算的。 图9 对比验证Fig.9 Validation comparison 由图8可以看出,根据块和交易在块中的序号定位进行验证所耗费的时间明显比根据块定位进行验证所消耗的时间短;有错误数据消耗的验证时间比无错误数据消耗的验证时间长。这是因为有错误数据的验证需要增加对错误数据的替换步骤,增加了时间成本。由于搜索结果返回的数据量是不确定的,本文测试了返回1—100条结果时,分页验证与一次性验证所有结果所消耗的时间,其结果如图9所示。从图9可以看出,随着搜索的数据越来越多,如果一次性对所有搜索结果验证,消耗的时间会越来越多,整个验证过程的时间就会随之增加。 3)交易数据入库处理的时间成本。首先,本文分析了在关系型数据库MySQL与非关系型数据库MongoDB下,单笔交易和单个块中数据处理的时间开销对比,将所得数据记录到Excel表格中,并生成如图10和图11所示的柱状图,所得数值都是通过对每个过程的时间开销取100个度量来计算其平均值。主要包括提取数据时对数据处理的平均时间以及处理完毕后插入数据库的平均时间。从图10—图11中可以看出,使用MongoDB时,每笔交易整个过程的处理时间仅在7 ms左右,平均每个区块整个过程的处理时间仅在500 ms左右。而使用MySQL时,每笔交易整个过程的处理时间仅在12 ms左右,平均每个区块整个过程的处理时间在850 ms左右。通过对比,MongoDB处理的时间会更短一些。虽然处理整条链消耗时间可能会比较长,但是会大大缩短搜索的时间。 图10 单笔交易中医疗数据入库处理时间成本分析Fig.10 Time cost analysis of medical data entry and processing in a single transaction 图11 单个块中医疗数据入库处理时间成本分析Fig.11 Time cost analysis of medical data entry processing in a single block 4)Gas成本开销。在搜索机制的整个过程中,需要通过智能合约来执行需要的操作,这会消耗一定的gas值,而这些gas只是用于测试,并不用于真正的交易。表3为方案中所涉及智能合约的部署成本,图12为智能合约所包含函数的执行成本。从测试结果来看,一方面,如果合约中的逻辑代码比较多,则合约部署所消耗的gas会多一点;另一方面,调用合约时,输入的数据量多,则消耗的gas也会变多。最后,也可以采用一些绿色节能的共识算法来进一步降低gas成本的消耗。 表3 智能合约部署成本Tab.3 Gas cost of smart contract deployment 图12 智能合约部署和执行成本Fig.12 Costs of smart contract deployment and implementation 区块链的搜索方式大都按照顺序依次遍历整条链,且用户无法按照不同用户类型搜索所属范围的医疗数据。为此,本文提出了一种带有访问控制的可验证医疗区块链数据搜索机制,借助于非关系数据库,不仅提高了数据搜索速度还丰富了查询功能。访问控制的使用确保了不同用户只能搜索自己权限范围内的医疗数据。为了保证搜索的数据不被篡改,本文设计了一种分页验证机制,使用户在查看所搜索结果的同时对搜索结果进行验证。最后,在以太坊Ethereum、非关系数据库MongoDB和真实公开的医疗数据上的实验结果证明了所提可验证搜索机制的有效性。2.3 可验证搜索



3 实验分析
3.1 环境配置

3.2 数据集
3.3 性能分析


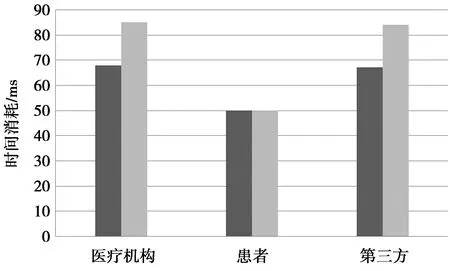



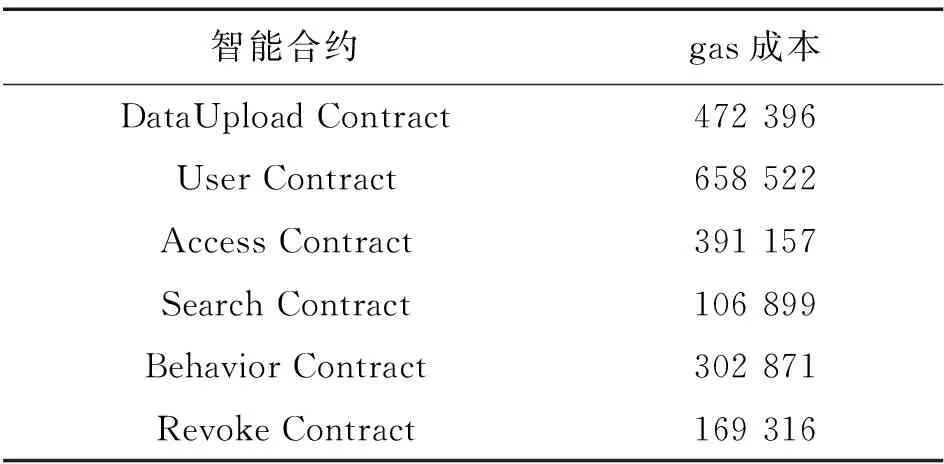
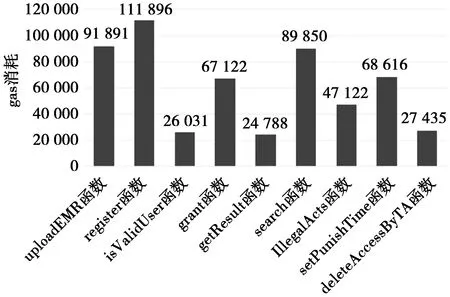
4 结束语
猜你喜欢
科学(2020年5期)2020-11-26
流程工业(2020年11期)2020-02-28
科学(2020年6期)2020-02-06
传媒评论(2018年4期)2018-06-27
软件导刊(2018年5期)2018-06-21
现代企业文化(2018年13期)2018-06-09
长春工程学院学报(自然科学版)(2018年1期)2018-04-20
当代旅游(2015年8期)2016-03-07
中国工程咨询(2011年4期)2011-02-14
