
融合局部搜索策略求解DCMST的改进稳态遗传算法
2023-10-26 06:19鞠成安王妮娅HANZALA张书凡毛剑琳
重庆邮电大学学报(自然科学版) 2023年5期
鞠成安,王妮娅,HANZALA,张书凡,毛剑琳
(昆明理工大学 信息工程与自动化学院,昆明 650500)
0 引 言
在交通、通信、电路芯片设计等领域[1-6],度约束最小生成树(degree-constrained minimum spanning trees,DCMST)问题是一个重要的基本问题。实践中往往将问题模型简化为度约束最小生成树问题,考虑结点的脆弱性、能源的有限性等问题,在每个结点上增加度的限制,以确保图的畅通性、资源的合理分配。
对于度约束最小生成树问题,通常采用启发式算法[7-9]去搜寻其最优解。遗传算法作为一种启发式搜索优化算法,为求解DCMST问题提供了有效的途径。应用遗传算法对树进行编码一般分为点编码和边编码。文献[10]首次运用Prüfer点编码,利用遗传算法求解度约束最小生成树问题,国内也有很多人采用Prüfer编码对该问题进行求解[11-12]。但是,Prüfer编码在局部性与遗传性方面有很大的劣势,并且随着问题规模的增大表现会更差[13]。文献[14]提出一种边集编码方式,并证明了此种编码方式在遗传算法中有着很好的局部性与遗传性,尤其在数据规模较大的实例中展现了很好的优越性。文献[15]采用边集编码提出一种混合稳态遗传算法,该算法设计了针对该问题的交叉算子,具有更好的遗传性。在局部搜索方面,文献[16]提出蚁群算法中应用双边替换和单边替换的局部搜索策略,文献[15]中改进了单边替换的搜索策略,将其分为两个阶段,进一步提高了算法局部搜索能力。近年来,文献[17]针对大规模结点问题,提出一种嫁接和剪接的搜索策略,从正、反两方面出发加速搜索过程;文献[18]提出一种遗传交叉算子,以解决产生不可行后代解的问题;文献[16]对分支定界法进行改进,使其能在动态的环境中得到较为理想的结果;文献[19]提出一种新型智能搜索算法烟花算法,因其随机性强、精度高,具有较好的全局收敛性。
然而,以上算法仍然在收敛速度和局部搜索能力上有不小的提升空间,为此,本文提出了一种融合禁忌搜索并增强局部搜索的稳态遗传算法(improved hybrid steady-state genetic algorithm with local search strategy,IHSGA)。初始种群的质量直接影响算法的收敛速度和性能,生成高质量的初始种群是遗传算法成功的关键,为了能在生成初始解时形成较好的树结构,本文提出了服从边隶属度值的度约束初始生成树算法;在IHSGA算法后期,为了增强局部搜索能力,在局部搜索条件里设置了一个自适应变量,并提出“边替换+点替换”的局部搜索方法,进一步提高解的质量;为了防止对相同的子代进行大量重复的搜索,在遗传算法的基础上引入禁忌搜索策略;通过将该算法用于对DCMST问题进行求解,与混合稳态遗传算法[15]、ABA算法[8]得到的结果相比较,本文算法所得解的质量和稳定性都有较大的提高。
1 问题描述
给定一个无向连通加权图G(V,E,w),其中V是结点或顶点的集合,E是边的集合,wij是端点i和端点j之间连接的边eij∈E相关联的正权重,则度约束最小生成树问题旨在找到图G的最小生成树T,并且其每个结点要么是叶子结点,要么在T中最多连接d条边,即度不超过d,d是一个给定的正整数。

(1)
(2)
1≤di≤dc,i=1,2,…,n
(3)
(4)
(5)
xij∈{0,1},i,j=1,2,…,n
(6)
(1)—(6)式所述数学模型由DCMST问题的优化目标函数及约束构成,其中:(1)式为DCMST问题的优化目标;(2)式为生成树包含不同结点的n-1条边;(3)式为每个结点应满足的度约束条件,dc为给定的度约束值;(4)式表示生成树无为环路;(5)式为所有结点的度值和;(6)式表示当xij=1时,由结点〈vi,vj〉构成的边是生成树的一条边。
2 融合局部搜索策略的改进稳态遗传算法
2.1 初始解的生成
2.1.1 编码和解码
为了表示度约束生成树的一个可能的解决方案,即遗传算法中的染色体, IHSGA使用了边集编码[12]。按照这种编码方式,每个解包含一组边,数量为|V|-1。选择这种编码的原因是它不仅提供了较高的局部性和遗传性,而且对于特定问题的遗传算子有很强的适应性。
F(Ti)作为生成树可行解的适应度值,被计算为与其生成树相关联的边的成本之和。如果Ti的适应度值小于Tk,那么Ti会被认为是比Tk更优的解决方案。
2.1.2 服从边隶属度值的度约束初始生成树算法
目前的初始解生成方式都采用随机生成方法,生成的初始解的质量较差。通过采用服从边隶属度值的生成树算法来引导初始解的生成,可以提高初始种群的质量。该算法将每个点都视为一个中心,其余各点对于这个中心点都有一个隶属度,距离越近的点隶属度越大,反之越小。隶属度的大小由边的权重来确定,将一个中心点周围的边的权重取倒数,然后进行归一化操作,得到周围点的隶属度的和总等于1,即
(7)
(7)式中:uij为隶属度值,介于0~1之间;ωij为边eij的权值。
满足度约束初始解的生成过程如图1所示。
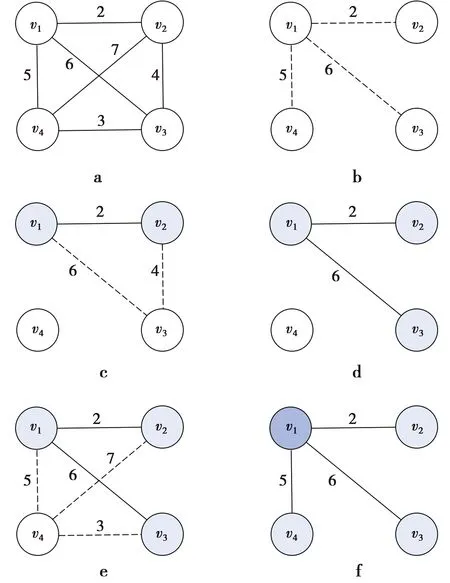
图1 初始解的生成Fig.1 Initial solution generation
图1a给出了一个赋予权值的完全图,在生成初始解前将每一个点都作为中心点,根据(7)式计算其余各点到中心点的隶属度,结果如表1所示。
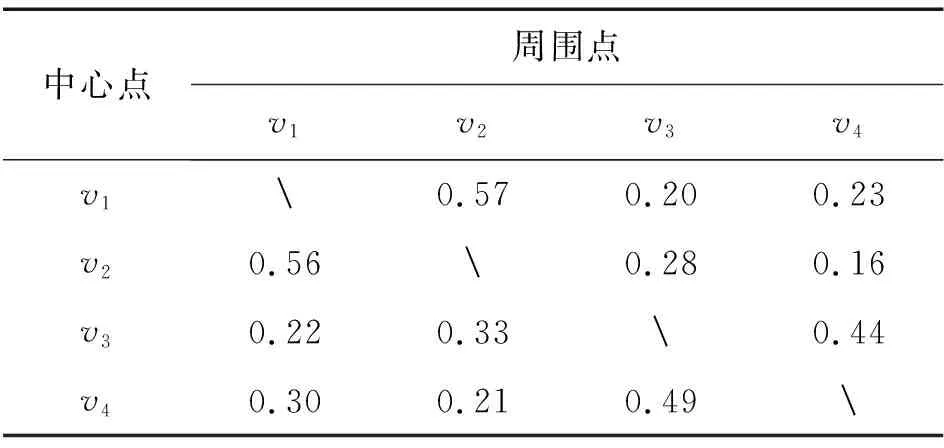
表1 隶属度值Tab.1 Membership value
随机选择一个点v1(如图1b),根据计算好的隶属度,以隶属度值选择下一个点v2(如图1c),将v1、v2两点放入集合U中并将其度值加1,代表这两个点都已经连接了一条边,同时把边ev1v2添加到集合Ti中;此时以v1、v2作为中心点,根据表1选择出两条以v1、v2为端点的边,如图1c中的边ev1v2、ev2v3,再根据表1的隶属度值选择边,若选择到了边ev1v3,那么就将v3放入集合U中并将点v1、v3的度值加1。在每次加边的过程中都会判断与其相关的点是否超过了度的约束且生成的子树不会成环。在初始解生成过程中,如果出现了满度的点(如图1f的点v1),那么在下一次寻边时就不会考虑该点周围的边。此后,该算法每次迭代都会搜索到一条边,直到集合U中包含了图中所有的点,此时已经构造了一个可行的度约束生成树Ti(如图1f)。每生成一个初始解都要对照目前种群里的每个解检查解Ti的唯一性。如果当前生成的新解是唯一的,则将其包含在群体中,否则将其丢弃。
一般的遗传算法随机产生的初始种群质量较低,但初始种群的质量往往影响着算法的收敛速度,本文采用一种服从边隶属度值的度约束生成树算法和随机方式的种群生成方法,在保证种群多样性前提下,使部分子树有更好的结构。
2.2 基于二元竞争选择法与最大边距法的交叉算子
文献[15]提出的交叉算子是一种针对特定问题的算子,它试图在新生成的子代中尽可能多地继承父代个体的好边,同时保持子代的所有非叶子结点的度约束。但是在算法后期种群的适应度值相差不大,该交叉算子并不能很好地让子代继承到父代优秀的结构,所以本文在交叉算子的父代选择策略上采用二元竞争选择法与最大边距法相结合的方法(BST-maxdis)表示为
(8)
(8)式中:p1,2代表交叉算子选择出来的父代;BST为二元竞标赛选择算法;max{dis(T1,T2,T3,T4)}是在候选解中选出边的距离最远的两个父代,Niter为迭代的代数;n为设置的总迭代次数。
在算法迭代前期使用二元竞争选择法对父代进行选择,能够尽量让子代继承适应度值小的父代的边,让种群向好的方向发展,但在算法后期种群的适应度值相差不大,所以选择边距较大的两个父代进行交叉,使子代继承不同的树结构,提升种群的多样性,防止算法陷入局部最优。
2.3 改进的局部搜索策略
2.3.1 局部搜索条件的改进
因为有度约束的要求,满度的点可能会有更多、更好边的组合。因此,要对此类点进行局部搜索。为了进一步提高当前生成的子代Tc的质量,在文献[15]的基础上,考虑到算法后期局部搜索能力较弱的问题,本文给出局部搜索的应用条件为
(9)
(9)式中:Tgb是当前种群中最佳的解决方案;Tc是当前生成的子代;F(Tgb),F(Tc)分别表示Tgb,Tc的适应度值;α×ek/kmax是根据经验确定的自适应变量,会随着迭代次数k值的增加而增大;dis(Tgb,Tc)表示Tgb和Tc之间的距离,以Tgb与Tc相异的边来表示,neq表示Tgb与Tc共同边的数量。
(9)式在算法前期对适应度值要略低于Tgb,但没有距离Tgb足够远的子代进行局部搜索,这样不仅增强了前期的全局搜索能力,也节省了计算时间;在算法的后期,因为α×ek/kmax是一个随着迭代次数k增加而增大的自适应变量,所以能够针对dis(Tgb,Tc)较小时的Tc,对其进行局部搜索,进一步提高当前解的质量。
2.3.2 局部搜索方法的改进
文献[15]运用了“边替换”进行局部搜索,先随机选取一条边,然后在该边的所有候选非相邻边中选取一条边替换它,使得当前解得到一定提升。IHSGA在该方法的基础上提出“点替换”的局部搜索策略,进一步增强算法的局部搜索能力。“点替换”的中心思想是将一个子树的叶子结点进行两两替换,在替换的过程中找到更优的组合,使整个树的结构更加紧凑,从而达到减小总权重的目的。定义一个针对叶子结点交换的增益函数定义为
gain(i,j,u,v)=F(T1)-F(T2)=
ωij+ωuv-(ωiv+ωuj)
(10)
(10)式中:结点j、v为叶子结点;结点i、u为树的固定结点;T1为叶子结点交换前的树;T2为叶子结点交换后的树。
在点替换的每次迭代过程中,当叶子结点交换后的增益函数为正值时,就允许本次结点交换,否则就放弃交换。
2.4 禁忌搜索策略
稳态遗传算法在后期产生了大量结构相似的子代,为了减少对大量结构相似的解进行搜索的工作量,引入禁忌搜索。禁忌搜索算法是一种全局逐步寻优的搜索算法,模拟人的思维模式,用长期记忆或短期记忆来诱导算法跳出局部最优解,避免重复低效搜索。借助禁忌搜索的记忆功能,可以将已经进行过局部搜索的子树放入禁忌表中。
禁忌表中的解并非完全被隔绝,也可以通过特赦准则对优秀的解进行释放,保留当前种群最优个体的结构,引导种群向更好的方向发展。其它禁忌表中的解需要度过预设的禁忌周期,才可解除禁忌。禁忌表中元素的邻域结构的条件定义为
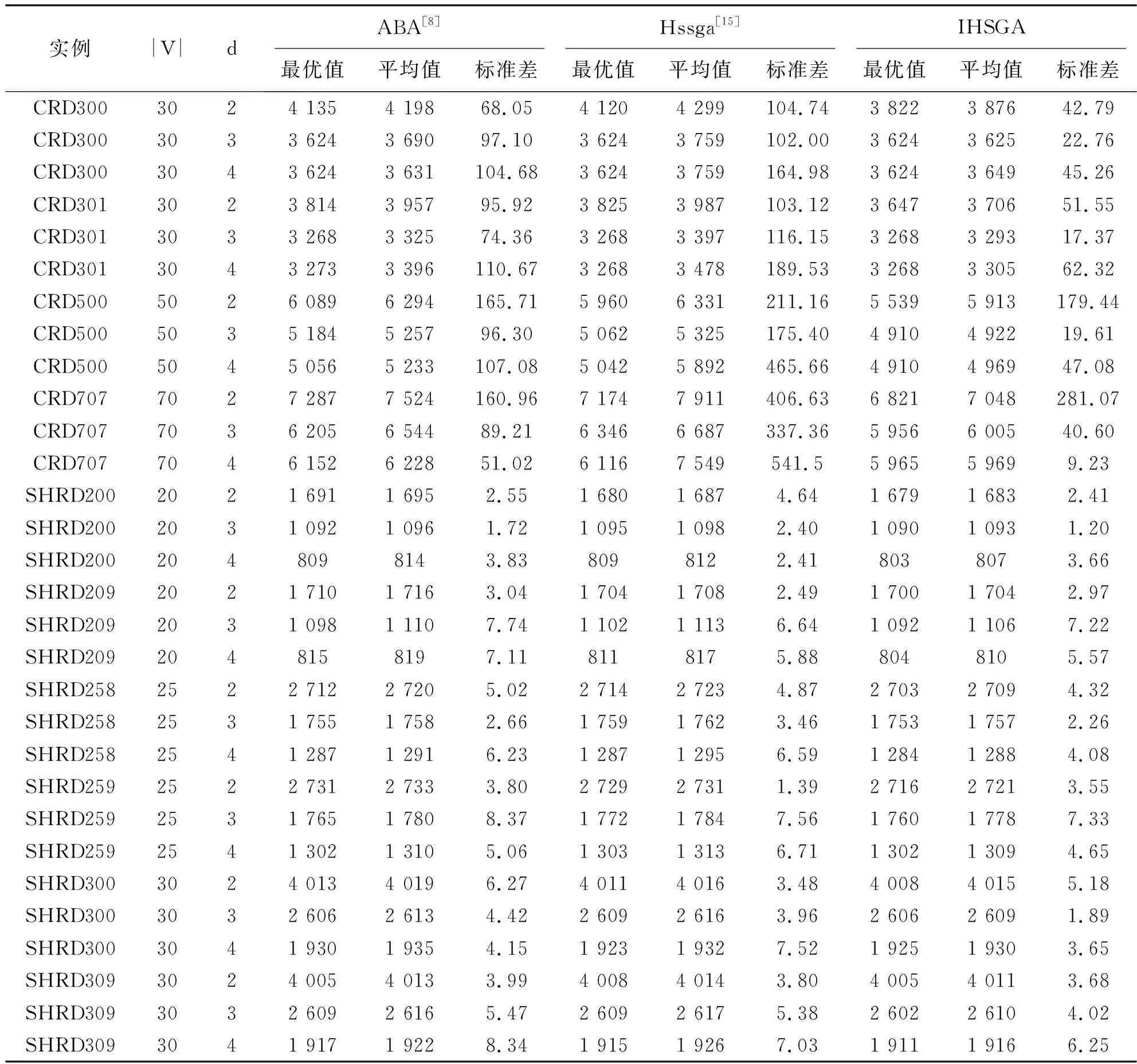
dis(TTS,Tc) (11) (11)式中:TTS为禁忌表中的解。 加入禁忌搜索后,可以防止算法相同或相似的解进行大量重复的搜索,提高了算法的运行效率。 在文献[15]给出的稳态遗传算法中,还应用了一个附加的扰动策略,以便在整个搜索过程中保持种群的多样性。本文在该算法的基础上改进初始解的生成方式,引入了禁忌搜索并改进了局部搜索策略。通过服从边隶属度值的度约束初始生成树算法来引导初始种群的生成,有效提高初始种群的质量;在种群中选取适当的父代进行交叉操作或变异操作,再通过禁忌搜索和改进的自适应质量-距离特征公式和改进的搜索策略进行局部搜索,以进一步提高当前子代的质量。具体流程如算法1所示。 算法1融合局部搜索策略的改进混合稳态遗传算法(IHSGA) 输入:一个连通带有权值的无向完全图G(V,E,w),正整数常量d 输出:带有度约束的最小生成树Tgb 1.生成初始解种群 2.Tgb→ 当前种群中的最优解 3.while未达到终止条件 do 4.BST-maxdis (T1,T2,…,Tpop) →p1,p2 5.交叉、变异 →Tc 6.ifTc不在禁忌表里 then 8.Tc进行局部搜索//局部搜索 9.end if 10.end if 11.ifTc是唯一解 then 12.ifTc适应度值优于Tgbthen 13.Tc→Tgb; 14.end if 15.end if 16.end while 仿真采用欧几里得(CRD)和非欧几里得(SHRD)两个典型的标准算例[20]。其中,前者由大小从50到100个顶点不等的图形组成。这种图中的顶点是在二维平面中均匀随机生成的,边权重是两个顶点之间的欧几里得距离。由于欧式距离形成的图复杂度较低,因而文献[17]构建一个较难的人工算例。该数据集由大小从15到30个顶点不等的图形组成。第一个结点通过长度为ll的边连接到所有其他结点,第二个结点通过长度为2l的边连接到除第一个结点之外的所有结点,以此类推构造点之间的非欧几里得距离。通过在1和18之间增加均匀分布的扰动来稍微随机化这个参数。这降低了存在大量最佳解决方案的可能性,但不会改变问题的潜在复杂性。实验中参数设置如表2所示。 表2 实验参数表Tab.2 Experimental parameter 为了验证所提出算法的有效性,本文与混合稳态遗传算法(Hssga)[15]和改进蚁群算法(ABA)[8]在标准算例上进行实验比对。每个算例在3种算法上单独运行50次,将度约束分别设置为2、3、4,对运行结果的最优值、均值和标准差进行比对。本文实验环境是Core(TM)i7-8700K CPU@3.70GHz,内存32GB,开发工具是python3.7。 表3报告了3种算法在CRD和SHRD实例上的运行结果。表3中,实例名称数字的前两位代表数据的顶点数,最后一位代表数据集的编号;|V|列表示与其实例对应的顶点数;列d表示对其对应实例的度约束。 表3 仿真实验对比Tab.3 Simulation experiment comparison 从表3可见,CRD数据集上的表现,IHSGA算法能够得到更优的最优值,且平均值和标准差有明显的改善,说明IHSGA算法输出的结果有更好的稳定性。对于SHRD数据集,IHSGA算法在最优值上略优于其他两种算法,且3种算法得到的标准差都比较小,可见IHSGA算法在稳定性方面也有一定程度的优化。在SHRD200、SHRD259、SHRD300数据集中IHSGA算法的标准差要大于Hssga算法,导致这种情况的原因是:IHSGA算法虽然整体结果要优于Hssga算法,但是在数据离散程度大于Hssga算法。 为了进一步展示IHSGA算法相较于Hssga算法的优越性,图2—图3分别展示了算法在迭代中种群的平均适应度值、种群最优值的变化情况。本次实验随机选择了两个标准算例(SHRD258、SHRD300),且d取值为3。图2表明,IHSGA算法得到的初始种群要优于Hssga算法,且收敛得更快。图3表明,IHSGA算法在1 000代左右就找到了当前最优解的发展方向,且在3 000代之前找到最优解,而Hssga算法需要在更多的迭代次数后找到最优解,说明IHSGA算法有更好的局部搜索能力。由以上分析可得,IHSGA算法能够得到更优的解,并且具有很好的稳定性,能够在度约束最小生成树问题中得到很好的应用。 图2 平均适应度值变化曲线Fig.2 Variation curves of the average fitness value 图3 最优值适应度值变化曲线Fig.3 Variation curves of the best fitness value 针对混合遗传算法存在求解质量不稳定、局部搜索不彻底等问题,本文以初始解和局部搜索为优化目标,提出一种服从边隶属度值的度约束初始生成树算法,在生成初始解时进行优化。首先,设置自适应变量对局部搜索的条件进行改进并提出点替换的搜索策略,克服原算法对部分解不能深入搜索的缺点;然后,在交叉算子的父代选择中,提出二元竞争选择法与最大边距法相结合的方法,使产生的子代具有更好的结构;最后,加入禁忌搜索,防止算法对相同或相似的解进行大量重复的搜索。实验证明本文算法在迭代次数相同的前提下,种群平均适应度要明显优于对比算法,并且标准差也较小,得到的结果是比较稳定的。实验结果说明融合禁忌搜索并改进局部搜索的混合稳态遗传算法是一种有效可行的改进方法。未来将结合移动机器人网络问题做进一步探索。2.5 融合局部搜索策略的改进混合稳态遗传算法流程
3 仿真测试与分析
3.1 仿真设置

3.2 算法测试结果与分析


4 结 论
猜你喜欢
大学教育科学(2022年6期)2022-12-06
——基于人力资本传递机制
贵州财经大学学报(2022年5期)2022-11-16
交通科技与管理(2022年19期)2022-10-12
东北财经大学学报(2017年6期)2017-12-15
——基于子女数量基本确定的情形
中南财经政法大学学报(2017年1期)2017-02-08
电讯技术(2016年8期)2016-11-02
科技传播(2016年17期)2016-10-10
广西林业科学(2016年2期)2016-03-20
广西林业科学(2016年1期)2016-03-20
广西林业科学(2016年4期)2016-03-16
