
基于Retina-Face的人眼关键点检测算法研究
2023-10-29 01:32陈亮,郑伟
计算机仿真 2023年9期
陈 亮,郑 伟
(1. 北京交通大学电子信息工程学院,北京 100044;2. 北京交通大学国家轨道交通安全评估研究中心,北京 100044;3. 北京交通大学轨道交通安全协同创新中心,北京 100044)
1 引言
近年,机器学习和深度学习正日渐成为人工智能领域的研究热点和主流发展方向,得益于此,计算机视觉技术取得了巨大进展,广泛应用于生产生活的各个场景,利用计算机视觉技术检测人体疲劳就是其中重要应用。
检测人体疲劳可采用公认较为准确的方法之一:PERCLOS P80[1]。PERCLOS指的是眼睛闭合时间占某一特定时间的百分率,它可以实现非接触式检测,对被监测人员不产生影响,通常采用在单位时间(1min)内测量眼睛闭合程度超过80%的时间所占的比例(用P80表示)。因此,应用PERCLOS P80方法时,需要对人脸部,尤其是眼部的关键点进行准确而快速的定位[2,3]。因此,如何准确、实时、低运算成本地检测人眼关键点,是疲劳检测的基础之一。
在实际生产工作中,疲劳检测系统往往需要运行在功耗、计算能力有限的小型系统中,对人眼关键点检测算法要求更高效、更轻量化。目前常用的检测算法主要有:单阶段(Single-stage)目标检测算法,以YOLO算法[4]和SSD算法[5]为代表,将图像分成多个小区域,通过引入特征图金字塔(FPN,Feature Pyramid Networks)的方式,在不同尺寸的特征图上面设置规格不同的锚点框,从而完成各种尺寸目标的检测任务,单阶段算法的特点是直接完成从特征到分类、回归的预测,检测速度非常快,也正是因为从同一全连接层或卷积层实现目标检测,其网络精度方面相较于两阶段算法稍低一些;两阶段(Two-stage)目标检测算法,以R-CNN系列算法为代表,先提取检测物体的区域,再对物体的区域进行分类和回归,两阶段算法精度高但网络推理时由于分为两个阶段进行,因此推理速度较慢。
Retina-Face模型是专门为检测人脸而设计的单阶段多任务(Single-Stage Multitask)深度学习模型,其特点是轻量化、速度快、准确性较高[6],对各层级、多尺寸特征图信息利用较好。本文基于Retina-Face算法,设计了一种对眼部关键点进行回归的检测算法,采用轻量化主干网络提取特征,在保证算法精度的前提下,网络体量较小、推理速度较快,适合在低算力小型计算机上完成人眼关键点检测任务。
2 基于Retina-Face的人眼关键点检测算法设计
2.1 Retina-Face原理概述
Retina-Face[7]是Insight Face在2019年提出的人脸检测模型,其网络模型特点包括:单阶段目标检测、采用特征图金字塔[8,9]、上下文特征模块(SSH,Single Stage Headless Face Detector)[10]、多任务[11]、锚点框机制[12](Anchors)以及采用轻量级主干网络等等。
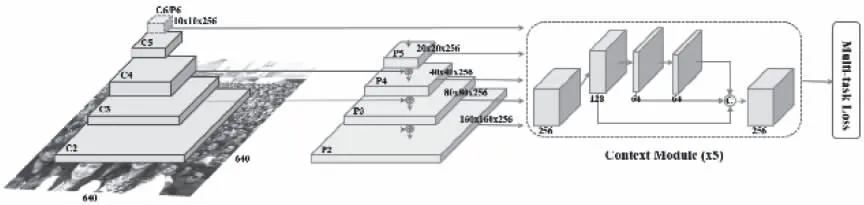
图1 Retina-Face网络结构图[4]
Retina-Face为了解决多尺寸人脸检测问题引入了FPN结构、SSH特征模块、锚点机制,在不增加网络运算参数前提下,提高了小尺寸人脸的检测能力。
Retina-Face采用多任务损失函数,包括:人脸分类、人脸框回归、人脸关键点回归、人脸密集点回归等4个损失函数,如式(1)所示。

(1)

图2 人脸5个关键点[4]
2.2 基于Retina-Face的人眼关键点检测算法设计
1)脸部关键点设计
Retina-Face原网络的人脸关键点是5个,分别是左右双眼、左右嘴角,以及鼻尖,因此需要重新设计脸部关键点。
通用的人脸关键点检测有包含Retina-Face的5个关键点,还有如OpenCVDlib库中的68个关键点[13]、WFLW[14]标注98个关键点的数据集等,如图3所示。在计算PERCLOS P80数据时,需要用到的是眼部关键点数据,因此为了尽可能减少计算资源消耗,采用双眼周围的12个关键点。人脸关键点及眼部关键点示意图如图3所示。

图3 人脸关键点及眼部关键点示意图
2)损失函数设计
针对人眼关键点检测,由于不需要对人脸密集点回归,并且密集点回归的计算量相对较大,因此损失函数中移除密集点回归损失函数。
3)网络结构设计
在原Retina-Face设计中,FPN特征图金字塔结构是为了可以对小尺寸人脸有更好地检测效果。但是通常情况下,工作场景中的疲劳检测,例如:在司机驾驶、调度员指挥、值班员盯控站场计划等场景中,采集图像中的人脸面积在原图中所占比例适中,因此,可以去除掉Retina-Face模型原有特征金字塔网络的P2和P6层结构,有针对性地保证中尺寸人脸检测结果的同时,减少不必要的网络推理计算过程。
简化后的特征金字塔网络结构如图4所示。
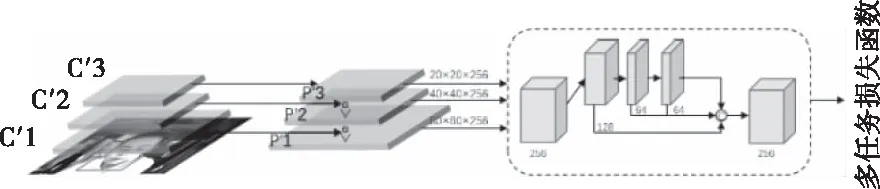
图4 重新设计的网络结构
4)图像数据Gabor预处理设计
在实际疲劳检测场景下,脸部易受复杂光照环境影响,从而影响算法检测效果。在传统图像数据处理方法中,Gabor滤波器在频域不同尺度、不同方向上提取相关的特征,经常用作纹理识别上,并取得了较好的效果,在一定程度可以突出眼部特征[15],另一方面,Gabor滤波器处理数据量少、速度快,因此本文采用Gabor滤波器对数据进行预处理,以达到提高算法准确率的目的。
3 基于Retina-Face的人眼关键点检测算法实现
3.1 人脸关键点损失函数设计
优化后的人脸关键点损失函数包含人脸分类、人脸框位置回归以及人脸关键点回归损失函数
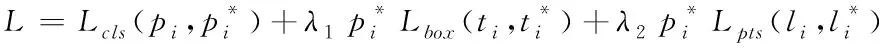
(2)
3.2 预训练模型迁移学习
在传统机器学习框架中,一个神经网络进行特定任务的训练时,需要充分的训练数据,获取足够的数据并对其标注也是一个相对耗时的过程。迁移学习在计算机视觉领域中是一种通用的方法,因为它不仅可以建立完成具体任务的精确模型,其训练耗时更短[16,17]。利用迁移学习,可以不用从零开始训练网络模型,而是从之前解决各种问题时学习到的模式开始,因为数据虽然不同,但是图像特征是通用的。
Retina-Face包含三个任务:人脸分类、人脸框检测、人脸关键点检测,当使用预训练网络权重文件进行预测时,对于人脸分类、人脸框检测无需再次进行训练,本文通过对前两者相关权重进行冻结,对眼部关键点检测权重进行单独训练,不仅可以大幅提高训练效率,由于预训练权重对人脸检测效果较好,还可以对关键点检测的准确性起到积极作用。
3.2 网络结构设计
1)采用MobileNet V1作为骨干网络
轻量化的卷积神经网络的研究目的和意义在于,参数计算较小的模型,其检测准确率仍保持较高水平。MobileNet V1作为轻量化网络的经典模型[18],其使用了深度可分离卷积(Depth-wise Separable Convolutions)来代替传统的卷积,在训练时参数的计算量和计算时间都得到很大程度的降低,较为适用于计算资源有限设备的深度学习网络[19]。
3.3 图像数据Gabor预处理
对原图的Gabor预处理过程为,分别提取三个方向的特征图[20]:0°、45°、90°,在每个方向上得到一张特征图,并以每张特征图为一个通道合成新图片,最后进行灰度化处理。如图5所示。

图5 Gabor特征图
人眼的Gabor特征与原图有一定的相似性,Gabor滤波器能够保留图像纹理变化特征的同时,用来提取图像的边缘信息,突出了眼部特征,降低了特征冗余。通过对图像数据进行Gabor预处理,进一步保证了模型对眼部特征点回归的准确率。
4 试验验证与结果分析
4.1 试验环境及实验数据集
本文算法实验环境是:操作系统windows10,CPU为:IntelXeon 6230,内存32G,显卡型号为NVIDIA Geforce GTX 2080Ti,显存11G。编程环境和深度学习框架分别是python3.6和Pytorch。
目前,常用的人脸检测质量评估的公开数据集有:Wider-Face[21]、300W、300VW、WFLW等数据集,由于公开数据集中包含许多不清晰的人脸图片,且多为睁眼图片,与应用PERCLOS方法检测疲劳的实际使用场景较为不同,因此本文除在公开数据集中选取大小适中、清晰的人脸图片以外,还采集戴眼镜、不戴眼镜、正面、侧面和光照不均匀等多种情况,的数据,并从Eyelink8[22](眨眼数据集)中眨眼图片进行标注,共计10000张图片,共同作为本文的数据集。
4.2 试验过程
采用带动量的随机梯度下降法(stochastic gradientdes-cent,SGD)优化器进行训练,动量大小采取经验数值0.9,采用交叉验证方法,训练集与验证集比例为8∶2。
训练时,设置真实人脸框和锚框的交并比(IoU,Intersection over Union)的正例样本阈值为0.5(经验值)、负例样本阈值为0.3,但此时绝大部分样本会被认为是负样本,造成样本不均衡,为了避免该问题,正负例样本数量的比例控制为3:1。
数据增强可以有效提升模型鲁棒性[23],本文按照随机选择0.3、0.45、0.6、0.8、1.0尺寸对原图进行剪裁,并将图像缩放到640×640,并以0.5概率进行随机镜像和颜色扰动,以达到增加更多人脸数据,提高模型表现能力的目的。
4.3 试验结果分析
在公共数据集、自制数据集上划分的测试集进行测试,通过归一化平均误差(NME,Normalized Mean Error)进行对比。NME是人脸关键点检测常用的评价指标
x代表关键点真实位置,y代表网络预测值,d代表两个外部眼角的欧式距离。NME越小,代表模型预测的结果越好。
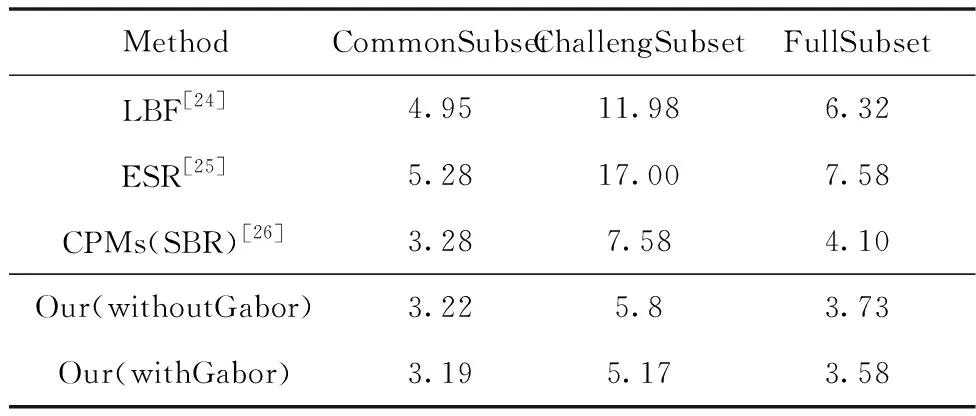
表1 与其算法在300W数据集的NME对比
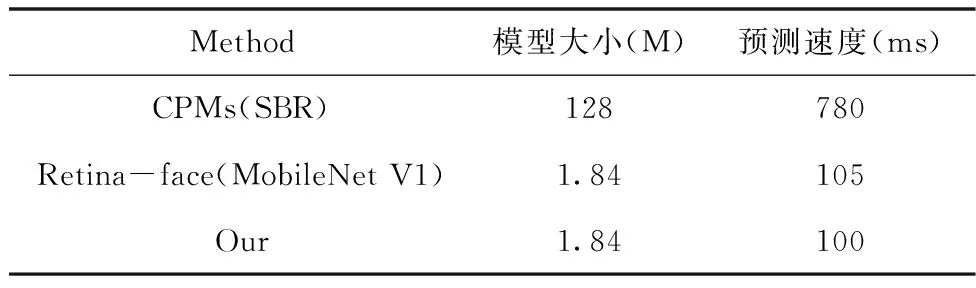
表2 不同算法的模型大小和自制数据集预测速度

表3 在自制数据集上不同睁眼程度NME对比
5 结论
本文通过修改网络结构、增加传统图像处理方法,提出了一种基于Retina-Face模型的人眼关键点检测算法,在300W数据集和自采数据上,推理的速度是100ms、NME是3.58,同时,采用Gabor预处理方法相较于未采用Gabor语出方法,NME提高0.15%;在自制数据集的不同睁眼程度的推理方面,NME分别是3.20/3.25/3.21,模型参数量仅有1.8M。在保证时效性和关键点检测准确率的同时,进一步减少了模型参数量,为基于计算机视觉的实时疲劳检测打下了基础。在下一步研究中,可以对数据集进一步扩充,采集覆盖多个年龄段人群的人脸数据,提升算法的鲁棒性和准确性。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
少儿美术·书法版(2021年9期)2021-10-20
快乐语文(2019年9期)2019-06-22
中学生数理化·八年级物理人教版(2018年11期)2019-01-31
动漫星空(2018年9期)2018-10-26
优雅(2016年12期)2017-02-28
电影故事(2016年5期)2016-06-15
发明与创新(2015年33期)2015-02-27
中国卫生(2014年2期)2014-11-12
