
一种结构优化的深度信任网络短时交通流预测
2023-11-16 12:21廖晓烨杨书敏辛东嵘
重庆交通大学学报(自然科学版) 2023年11期
张 阳,廖晓烨,杨书敏,辛东嵘
(1. 福建理工大学 交通运输学院,福建 福州 350118; 2. 同济大学 交通运输工程学院,上海 201804; 3. 福建理工大学 土木工程学院,福建 福州 350118)
0 引 言
近年来,随着人们对出行质量的需求不断提升,私人机动车数量大幅度增长。交通需求的快速增长导致一系列交通问题变得更加突出,道路堵塞、交通事故频发、尾气污染等已对社会发展和日常生活造成诸多不利影响。智能交通系统中的交通控制和诱导技术能够在不改建现有道路条件的前提下提升道路的通行能力从而有效的缓解交通拥堵,因而成为缓解交通拥堵的重要思路。
由于交通流的随机性、社会性、复杂性等特点,精准的短时交通流预测变成了一大难题。早期的短时交通流预测模型多基于统计学原理,其中最有代表性的为时间序列模型,时间序列模型常用于描述时间序列统计特性,并有效运用于参数化模型处理动态随机数据,根据交通流在时间上的连续性推导得出。这类方法在连续性数据的基础上拥有较高精度,但参数估计较复杂,且计算出的参数不能移植,模型没有自学习自适应能力,针对短时交通流数据的易突变性和波动性不能及时的扑捉和处理,预测精度往往不高[1]。随着机器学习等智能学习处理方法的出现,基于机器学习的短时交通流预测方法的预测精度及鲁棒性也得到较大的提升,其中有代表性的为支持向量回归模型以及神经网络与支持向量机的融合模型[2-3]。这类方法能够从大量的交通流历史样本中自学习找出数据内在规律,从而提升预测精度。然而这些模型所需要的大量精确的交通流历史数据不易获取,模型的实用性受到了较大的限制。为了实现“小样本”条件下的短时交通流预测,进一步提升短时交通流预测方法的实用性,基于深度学习的短时交通流预测方法逐渐成为该领域研究的主流方向。比较有代表性有长短时记忆神经网络模型和深度信任神经网络模型等[4-5]。这类模型拥有更强的自学习数据处理能力,能够在少量有代表性的精确交通流历史数据条件下实现精确预测。然而,该方法自身结构较为复杂,数据输入输出的方式和结构、训练数据的选取以及深度网络的层数等都会影响算法的精度和实时性。随着研究的不断推进,组合交通预测模型应运而生[6],其中具有代表性的为组合小波理论预测模型,该方法具有较强的拟合能力和较快的收敛速度。但该方法容易导致预测精度低、陷入局部最小值等问题[7]。
为了解决上述问题,笔者提出一种改进花朵授粉算法与结构优化的深度信任网络短时交通流预测方法(MFPA-DBN)。首先,根据预测数据的类型和时空特性,确定深度信任网络短时交通流预测模型的输入端数量和结构,并构建模型框架,利用MFPA算法寻找模型最优初始权值等;其次,根据输入数据确定深度信任网络预测模型的输入层显层节点的分布形式、能量函数的转换关系式以及数据在显隐层及隐隐层之间的等效转换形式;最后,由于模型结构对预测精度的影响较大,隐层结构层数由优化算法根据目标函数值动态选取,进一步提升算法的预测精度和泛化性。
1 深度信任网络短时交通流预测模型
交通流在时间和空间上具有一定的演变规律,针对这些演变规律对未来的交通流进行合理、科学的预测就是城市道路交通流预测[8]。传统的短时交通流预测往往只考虑预测节点的历史交通流数据,而忽略了交通流数据在时空上的演变规律,预测效果往往不佳[9-10]。为了克服这一不足,同时考虑预测节点的历史交通流数据、临近周边重要节点的历史交通流数据,以及历史数据中临近周边节点交通流驶向预测节点的交通数据。利用交通流数据,把握交通流数据在时间、空间上的演变规律,以期能够提升预测精度。
为了同时对上述3种数据进行处理,笔者建立的深度信任网络回归机模型由3个带高斯分布函数显层转换节点受限波兹曼机输入端、若干层受限波兹曼机中间层以及支持向量回归机输出层三部分构成,每个输入端通过相应的数据学习得出一个输出结果,最终融合3个输出节点的预测结果得出最终的预测值。模型框架图如图1。
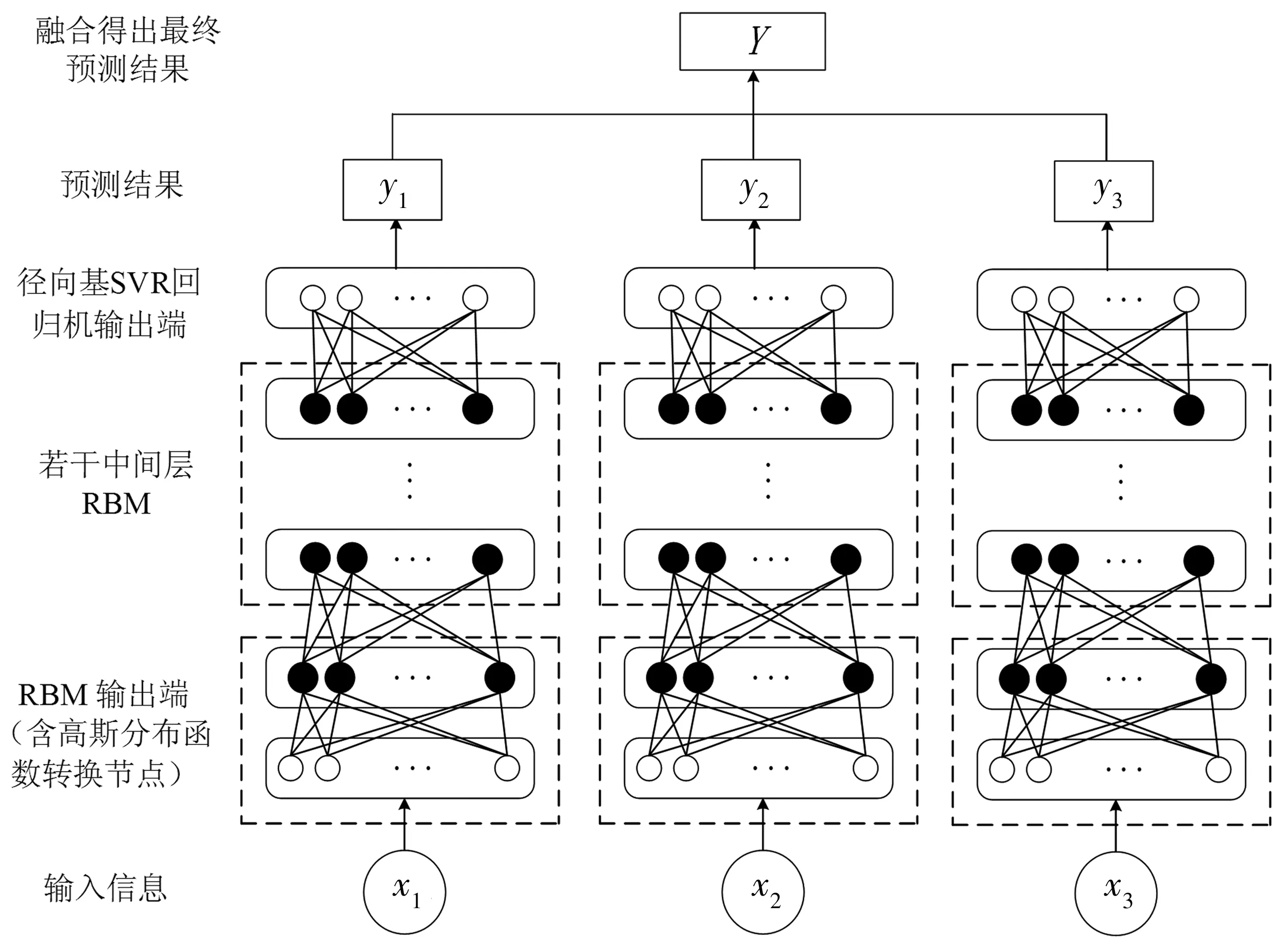
图1 深度信任网络短时交通流预测模型框架示意Fig. 1 Schematic diagram of framework of short-term traffic flow prediction model with deep belief network
笔者提出的深度信任网络短时交通流预测模型构建带高斯分布函数显层的输入层,其能量函数的转换关系式为:
(1)

深度信任网络短时交通流预测模型中,第1层的显层节点和中间隐层节点对应转换的条件概率为:
p(vi=1|h;θ)=
(2)
(3)
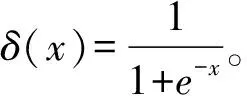
E(v,h;θ)为能量函数,用来实现中间层信息间的等效转换,其计算公式为:
(4)
式中:ωij为权值参数;βi为显层节点;θ=(ω,β,α)为RBM微调参数;I、J分别为显层结构与隐层结构数量;αj为隐层节点的偏移量。
RBM权值的更新公式为:
Δωij=Edata(vihj)-Emodel(vihj)
(5)
式中:Edata(vihj)为数据集的期望值;Emodel(vihj)为模型中既定的期望值。
经过RBM中间层数据学习,其输出作为径向基SVR回归机层的输入,经过回归机得出单组数据的预测结果,根据历史数据的关联性将3个径向基输出结果y相融合,得出预测结果Y,其计算表达式为:
Y=w1y1+w2y2+w3y3
(6)
式中:w1、w2、w3分别为学习参数,反映了预测节点的历史交通流数据、临近周边重要节点的历史交通流数据以及历史数据中临近周边节点交通流驶向预测节点的交通数据这3种数据对最终预测结果的影响程度。
2 结构优化的深度信任网络短时交通流预测模型
深度信任网络短时交通流预测模型中,隐层结构的数量对预测的准确性有较大的影响。为了保证算法的实用性,提出一种改进花朵授粉算法对深度信任网络短时交通流预测模型的隐层结构进行优化,避免随意构建而导致模型陷入局部最优解及实用性降低。
2.1 改进花朵授粉算法
花朵授粉算法(flower pollination algorithm,FPA)是一种受自然界植物授粉开花过程规律启发,而生成的一种新型算法[11]。花朵授粉算法相较于其他群体算法,结构简单,步骤较少,编程简洁容易;且控制的参数较少,在算法演绎过程中的调参工作量少;花朵授粉算法的实用性和通用性强,在很多研究领域上均可使用。但面对一些复杂的实际问题时,收敛速度的快慢以及是否会陷入局部最优解等问题是该算法模型需要克服的重点。笔者在算法内加入线性权重,可以改进花粉算法的性能。改进的花朵授粉算法可以有效的解决模型陷入局部最优解及实用性降低的问题。
为了更好的模拟花朵授粉的过程,对花粉授粉算法进行如下假设:
1)一株植物仅开一朵花,有且仅有一个花粉粒子。
2)局部授粉的过程即为非生物自花授粉,用式(7)表示:
(7)

3)生物异花授粉视作一个全局授粉过程,花粉由昆虫等生物携带,具有Levy飞行规律,过程用式(8)表示:
(8)

(9)
式中:S、S0分别为步长与最小步长;λ=1.5;Γ(λ)为标准的Gamma函数。
为了更好的遵循Levy分布产生的随机步长,引入Mantegna方法,实现Levy的稳定分布。用式(10)表示:
(10)
式中:V~N(0,1);U~N(0,σ2),σ2用式(11)表示:
(11)
为了提升搜索的能力,采用线性权重对局部授粉的搜索能力进行优化,用式(12)表示:
(12)
式中:ωmax、ωmin分别为最大、最小权重;Imax、I分别为最大迭代次数、当前迭代次数。
因此,生物异花授粉过程变更为式(13)表示:
(13)
4)花粉使用转换概率p决定进行局部寻优或全局寻优,p在[0,1]之间。
2.2 MFPA-DBN短时交通流预测实现步骤
采集预测节点的历史交通流数据、临近周边重要节点的历史交通流数据以及历史数据中临近周边节点交通流驶向预测节点的交通数据作为训练数据。以预测值与真实值的平均绝对误差最小为寻优目标函数,如式(14):
(14)

提出的预测模型主要实现步骤如下:
步骤1根据实验需求,采集短时交通流样本数据,其中包括预测节点、临近周边重要节点、临近周边节点交通流驶向预测节点等相关地点的历史交通流数据。
步骤2构建深度信任网络短时交通流预测模型,设置包括3个带高斯分布函数显层转换节点受限波兹曼机输入端、受限波兹曼机中间层以及支持向量回归机输出层,初步设定显隐层节点数、隐层层数、支持向量回归机的核函数等参数指标。
步骤3处理数据,将数据分成训练组与预测组,对网络权值等进行随机赋值。根据式(1)对输入数据进行归一化处理,根据式(2)~式(4)实现数据信息在隐层结构的传递,比较训练数据和测试数据的差异,根据式(5)调整权值提高训练模型的精度。初始化种群数、转换概率、最大迭代次数等输入到深度信任网络中,将网络输出与实际值的误差作为FPA适应度函数值。计算各花朵的误差值并找到最优解。
步骤4判断随机生成数Rand与p的大小关系, 若Rand 步骤5判断迭代的终止条件是否被满足。若满足,得到最优的权值,将其值赋予深度信任网络。若不满足终止条件,则将流程跳转到步骤4,再一次进行迭代。 步骤6根据优化得出的隐层结构建立最终的结构优化深度信任网络短时交通流预测模型。利用训练好的短时交通流预测模型对实际数据进行预测,验证预测效果。 基于MFPA-DBN的交通流预测流程图如图2。 图2 基于MFPA-DBN的交通流预测流程Fig. 2 Flow chart of traffic flow prediction based on MFPA-DBN 本次实验分别采集了2021年08月21日至08月29日共9天的福州市某次干道交通量、临近该次干道的两个交叉口的总交通量以及两个交叉口中驶向该次干道的总交通量共3类交通流流量数据作为实验样本,实验路网结构图如图3。样本采集间隔为5 min,其中福州市某次干道交通流量共采集288×12组数据,临近该次干道的两个交叉口总交通量共采集288×12组数据,两个交叉口中驶向该次干道的总交通量共采集288×12组数据分别对应模型的3个输入端口。选取前7天的3类采集数据作为3个输入端口的训练样本集,对笔者提出的算法模型结构进行训练;同时,选取最后两天的采集数据作为测试集,用于验证算法的预测性能。 图3 实验路网结构Fig. 3 Structure diagram of experimental road network 实验基于Windows10操作平台,应用Python3.7进行编程,其他硬件、软件配置见表1。 表1 实验平台Table 1 Experimental platform 选择平均绝对误差(EMAE)、根均方误差(ERMSE)、R-Square(R2)和相对误差(EMRE)作为评价指标,对本文模型的精度进行评估。由式(15)~式(18)表示: (15) (16) (17) (18) 为了提高预测模型的实时性,采用离线训练的模式对模型进行训练。通过设置算法所需的参数,将笔者提出的结构优化的深度信任网络短时交通流预测方法(MFPA-DBN)和结构固定的深度信任网络短时交通流预测方法预测性能进行对比,验证方法的有效性。 3.4.1 相关参数的设置 结构优化的深度信任网络短时交通流预测算法的主要参数选择如下:优化算法中转换概率p取值为0.8;总迭代次数为120;种群数量取值为25,深度信任网络中每层的神经节点数为80,隐层结构层数由优化算法根据目标函数值动态选取。 结构固定的深度信任网络短时交通流预测方法中每层的神经节点数为80,隐层结构层数分别选择为固定值10层、20层和32层。 3.4.2 算法性能比较 在已经训练好的MFPA-DBN模型中,输入测试集数据,预测得出08月29日每15 min 的交通流量。同时,将原始实验集数据直接利用10层隐层结构深度信任网络短时交通流预测模型(10-DBN)、20层隐层结构深度信任网络短时交通流预测模型(20-DBN),以及32层隐层结构深度信任网络短时交通流预测模型(32-DBN)进行预测,并将预测结果与MFPA-DBN模型进行比较,结果如图4。 图4 结构优化与结构固定的深度信任网络预测结果比较Fig. 4 Comparison of prediction results of deep belief network with optimized structure and fixed structure 利用EMAE、ERMSE、R2、EMRE作为评价指标,MFPA-DBN模型、10-DBN、20-DBN和32-DBN模型的预测结果如表2。通过对比4个指标可知,隐层结构层数的选择对算法的预测精度有直接的影响,提出的MFPA-DBN模型预测结果优于其它3种结构固定的深度信任网络短时交通流预测方法,20-DBN模型预测结果次之,32-DBN模型预测结果仅优于10-DBN模型,10-DBN模型预测结果最差。 表2 结构优化与固定的深度信任网络预测结果Table 2 Prediction results of deep belief network with optimized structure and fixed structure 将笔者提出的结构优化的深度信任网络短时交通流预测方法(MFPA-DBN)与文献[3]提出的CNN-SVR模型、文献[7]提出的TGWO-BP模型、文献[12]提出的GA-LSTM模型的预测效果进行比较,最后得出结果。 3.5.1 算法性能比较 在已经训练好的MFPA-DBN模型中,输入测试集数据,预测得出08月29日每15 min的交通流量。同时,将原始实验集数据利用目前的CNN-SVR模型、GA-LSTM模型、TGWO-BP模型进行预测,并将预测结果与MFPA-DBN模型进行比较,如图5。在24 h预测结果及早高峰预测结果比较中,笔者提出的MFPA-DBN模型相对于其他3种预测方法更贴近真实值,但在16:00—17:00时间段内,MFPA-DBN模型部分预测结果陷入局部最优,一方面由于笔者预测模型(MFPA-DBN)综合考量了有效性与实时性两个因素。为了实现算法在预测时,模型的有效性、实时性能够达到相对最优,在实验过程中适当地对寻优迭代次数作了限制;另一方面由于该时间段内交通量发生了突变,数据波动性较大,对模型的预测效果造成了影响。尤其是16:15—16:30这个时间段模型明显陷入局部最优,但此问题并不影响模型其在实际情况下的使用,可通过放开对实时性因素的考量,增加模型的寻优迭代次数来规避陷入局部最优的缺陷,达到较优的预测效果。 为避免实时性因素对文中模型(MFPA-DBN)的预测效果造成不利的影响,笔者将MFPA-DBN模型的迭代次数分别增加到175次和225次,将迭代次数增加的MFPA-DBN模型与迭代次数为120次的MFPA-DBN模型、CNN-SVR模型、TGWO-BP模型、GA-LSTM模型预测效果进行对比,最后得出结果。预测结果如图6。利用EMAE、ERMSE、R2、EMRE作为评价技术指标,评价结果如表3。通过对比4个指标可知,笔者提出的MFPA-DBN模型预测结果精度最高,其预测性能优于其他3种短时交通流预测方法。同时增加MFPA-DBN模型的寻优迭代次数后,有效解决该模型陷入局部最优解的问题。 3.5.2 结构优化的深度信任网络模型计算效率分析 短时交通流预测模型的计算效率是算法实用化的关键。为了验证算法的计算效率,笔者以算法运算时间为评价指标对其进行评估,仍然与CNN-SVR模型、GA-LSTM模型、TGWO-BP模型进行比较。本实验采取离线训练模型后在线预测数据进行短时交通流预测,算法的计算效率如表4。由表4、图6可以看出,对MFPA-DBN模型的迭代次数进行增加,可以有效避免模型在个别时间段陷入局部最优的缺陷,提升算法的预测精度。但随着迭代次数的增加,模型的计算效率下降。笔者提出的算法实时性虽然不是最优,但其预测精度较高。若综合考量实时性与有效性两种因素,将文中模型的迭代次数设置为120次可达到实时性、有效性结果相对最优,且其与实时性最优的算法差距较小,计算效率仍然较高,可以满足实际使用需求。 图5 深度学习模型预测结果比较Fig. 5 Comparison of prediction results of deep learning model 图6 模型预测结果比较Fig. 6 Comparison of model prediction results 表3 预测结果对比Table 3 Comparison of prediction results 表4 不同算法的计算效率对比Table 4 Comparison of calculation efficiency of different algorithms 笔者提出一种结构优化的深度信任网络短时交通流预测方法,通过构建可同时训练3种与预测节点相关的交通流数据的深度信任网络模型来增强预测的时空关联性。为了进一步提升预测模型精度,提出一种优化的花朵授粉算法,以预测值与真实值的平均绝对误差最小为寻优目标函数,优化深度信任网络短时交通流预测模型结构,动态选择合适的预测模型隐层结构参数。 利用实际交通数据进行方法验证,实验结果表明,笔者提出的结构优化深度信任网络短时交通流预测方法预测精度优于CNN-SVR、GA-LSTM、TGWO-BP模型,预测效果较好,实时性也能满足实际需求。由于该模型方法(MFPA-DBN)只针对常规天气下的交通流数据进行预测,未考虑特殊天气变化带来的影响,未来可针对天气变化的因数进一步拓展研究。
3 实验结果与分析
3.1 样本的采集及选取

3.2 实验平台

3.3 模型评价指标

3.4 结构优化的深度信任网络短时交通流预测性能的影响分析


3.5 结构优化的深度信任网络模型预测性能与经典算法性能比较




4 结 语
猜你喜欢
人民珠江(2019年4期)2019-04-20
桃之夭夭B(2017年2期)2017-02-24
知音海外版(上半月)(2016年12期)2017-01-13
西南交通大学学报(2016年3期)2016-06-15
中国工程咨询(2016年1期)2016-02-14
高中生·青春励志(2014年11期)2014-11-25
数学年刊A辑(中文版)(2014年1期)2014-10-30
计算机工程(2014年9期)2014-06-06
机械工程与自动化(2014年3期)2014-05-07
上海电机学院学报(2013年3期)2013-03-11
