
基于神经网络和遗传算法的高密集WLAN公平性保障算法
2023-11-21 12:56蒋雨瑾杨奇杨懋李波闫中江
西北工业大学学报 2023年5期
蒋雨瑾, 杨奇, 杨懋, 李波, 闫中江
(西北工业大学 电子信息学院, 陕西 西安 710072)
为了满足用户在各类场景下对无线业务日益增长的要求,无线接入点(access point,AP)的覆盖越来越密集,频谱资源愈发紧缺。无线局域网(wireless local area network,WLAN)标准IEEE 802.11中采用的是空闲信道评估机制(clear channel assessment,CCA)通过检测信号能量大小来判断信道的忙闲状态,而高密集WLAN部署环境意味着AP能够侦听到更多同一信道的其他AP,使得网络中的冲突退避更容易发生,造成WLAN吞吐量公平性下降,严重影响网络服务质量(quality of service,QoS)。吞吐量是衡量WLAN性能的关键性指标,因此如不加特殊说明,本文的公平性指吞吐量公平性。
为了改善这一问题,学者们在物理层和媒体访问控制(medium access control,MAC)层中提出了许多基于资源分配算法的方案。在物理层提出的设计大多是基于功率以及速率的方法[1-4]。文献[1]中,作者根据相邻节点与吞吐量严重下降的AP接收到的信号强度动态调节载波侦听阈值,该动态调整阈值的算法能够明显提高网络的下行吞吐量。在文献[2]中,作者提出了基于信号发射功率的算法,该算法是通过AP间合作交换彼此当前时刻的吞吐量和所发送的数据包大小调节信号发送功率。在文献[3]中,作者提出了一种新的鲁棒速率自适应算法,其主要原理是根据短时间的信号路径损耗调节物理层速率,并使用自适应请求发送帧来维持碰撞发生速率。在文献[4]中,作者设计了一种局部搜索算法同时改进了传统AP布局位置和信道分配方案的搜索算法。在MAC层中提出的方案有自适应竞争窗调整、准入控制[5-6]等算法。在文献[5]中,作者对在CSMA/CA 机制下的竞争窗口进行优化,该算法的原理是在每个干扰节点中设计并实现一个控制器,同时根据本地的2次平均信道状态值对竞争窗大小进行动态调节,最终使得信道状态收敛到最佳值。在文献[6]中,作者对准入控制技术进行了详细研究和讨论,但没有提出有效的参数优化方案。总而言之,影响WLAN性能的因素众多,但传统的基于资源分配方案选取的优化参数较少,对WLAN性能提升有限。已有研究提供了一些提升公平性的有价值思路,但还存在一些不足之处。其中只针对竞争窗口值或发送功率的单一参数调节方案缺少对整网公平性的衡量,并且产生竞争窗口值的机制具有随机性,而单一功率调整会在一定程度上影响通信范围和质量,给高密集WLAN带来新问题。动态的信道分配和切换技术会影响网络稳定性,同时面临信道资源紧缺问题,信道分配方法难以满足高密集部署场景。
无线局域网络日益复杂多变,采用传统模型方法对复杂网络环境建模越来越困难。而神经网络黑盒优化是一个仍在发展的新兴研究领域,现有的结合机器学习的无线局域网参数调优研究大多针对的是AP的发送功率以及信道分配[7-8]。文献[7]采用了分布式强化学习方案,AP间信息不互通,各自进行强化学习,并求得各自的最优参数配置。文献[8]采用深度Q-learning强化学习网络 (DQN) 对无线通信网络进行优化。但目前采用优化算法与神经网络结合来对高密集无线局域网调优的研究较少。
针对高密集WLAN中的同频干扰问题,本文基于神经网络和遗传算法提出了一种网络参数调优方法。神经网络具有强大的非线性拟合能力和学习能力,遗传算法可以在解空间内进行全局搜索,因此在处理复杂系统优化问题时,能有效地避免陷入局部最优解。故本文在神经网络可以构建数值间复杂的映射关系能力的基础上,结合遗传算法优秀的全局搜索能力来优化WLAN参数。该方法的核心思想是利用来自精准、一体化的仿真平台[9-10]的有限次网络仿真数据结果对神经网络进行训练,得到AP个数、发射功率、距离、能量检测阈值、最小竞争窗口以及带宽这些参数和网络公平性之间的映射关系,利用这一具有强大的拟合建模能力的神经网络模型作为遗传算法的适应度函数,能够起到优势互补作用。通过遗传算法对发送功率、能量检测阈值以及最小竞争窗口的最优参数组合配置,保障小区间的公平性。
1 问题分析与研究现状
1.1 公平性问题分析
IEEE 802.11中的CSMA/CA(carrier sense multiple access/collision avoidance)机制采用空闲信道评估,通过检测信号能量来判断信道忙闲状态,在协议中,CCA主要分成2种方法:载波侦听(carrier sense)以及能量检测(energy detection)。
载波侦听:载波侦听用作检测数据包的preamble,即识别数据包的起始边界。802.11中的preamble部分采用特定的序列所构造,发送方和接收方都已知该序列,监听节点会不断对信道信号进行采样,用其做相关运算,其计算值会与载波侦听阈值进行比较判断。若大于该值,则认为检测到了一个信号,若小于则没有检测到。节点在识别到数据包起始部分后,通过解调出数据包内部的相应字段来识别出数据包的终止边界。
能量检测:该方法能够识别数据包中的能量。其直接利用物理层接收到的能量大小来比较判断是否有信号,若信号强度大于能量检测阈值,则认为信道是忙,若小于该阈值,则判断信道为闲。当同一信道有多个AP时,由于发送信号覆盖范围的重叠,在CCA机制下会出现一些AP对信道忙闲状态的错误判断,导致AP传输数据包的机会大幅下降,出现不断进行等待退避或不断发送数据包但节点无法正确解析发给自己的数据包preamble的情况。
线上线下学习内容高度契合,各有分工:线上完整精讲、细讲知识点、重概念原理和“广度”学习,线下教师部分精讲,理清脉络,重案例点评和“深度”学习。
为了确保每个终端都能被服务,企业网或者校园网的AP位置可以根据用户以及环境的需求进行部署,AP的数量和密度往往较大。即使采用频率复用技术,但由于WLAN的工作带宽较大,且工作在非授权频段,所能配置的互不干扰的频率有限,因此小区间仍然会出现工作带宽重叠且相互干扰的问题。如图1a)所示,A和B、C和B之间互相感知的接收信号强度指示(received signal strength indication,RSSI)在能量检测阈值与载波侦听阈值之间,而A和C之间互相感知的RSSI小于载波侦听阈值。A和C可以同时退避竞争信道并发地发送数据,互不干扰。但由于信道能量检测阈值较大,会让A和B、B和C,都认为信道是空闲而不停地发包,导致A发的包、B发的包及B和C发的包会发生重叠,各节点不能正确解析包的preamble,最终造成整网的吞吐量下降。又如图1b)所示,此场景中,A和B、C和B之间互相感知的RSSI大于能量检测阈值,A和C间互相感知的RSSI小于载波侦听阈值。在WLAN的CSMA/CA机制下,A和C可以同时竞争信道,互不干扰,而对于B,一旦A或者C发送数据包时,B就会监听到信道繁忙,需要等待信道空闲。最终导致A和C将以很大概率占据信道,B难以抢占到信道无法进行数据的发送,从而导致B的吞吐量大幅下降,恶化网络公平性。

图1 公平性恶化问题示意图
可以看出,该机制使部分节点的传输机会下降及传输失败次数增加,将直接导致这部分节点和整网吞吐量下降,进而使得网络中各小区吞吐量差异过大。假设网络中共有N个AP,Ti为第i个AP的吞吐量,采用最小-最大公平性指标[11]d衡量WLAN中同频干扰问题的严重性,计算公式为

(1)
WLAN中的多种网络参数与公平性之间存在特定函数关系,在对公平性优化问题中,可以据此关系找到d的极大值点与对应参数配置值,从而实现对WLAN公平性的优化,本文提出一种优化算法,利用神经网络得到优化参数与吞吐量间的函数关系,并利用遗传算法来求解该问题。
1.2 采用机器学习优化无线网络参数的相关研究
无线网络参数调优问题本质上被视为求最优解问题,WLAN日益复杂,构建相应模型也变得困难。强化学习算法(reinforce learning,RL)是在机器与环境的交互过程中,根据环境返回的收益优化目标。强化学习在无监督的优化问题中证明了其应用价值,现已有较多学者针对蜂窝网络下的资源分配问题提出了基于强化学习、深度强化学习和神经网络方面的方法。文献[12-14]采用深度学习中的Q学习算法(deep Q network,DQN)对功率进行合理分配使得整体速率达到最大值。除了强化学习这类动态规划方法外,也有学者指出监督学习同样可以应用于网络参数调优。文献[15]同样采用了深度学习,逼近最小加权均方误差算法,取代传统方法中的使用近似迭代来求最优解,该方法是使用多收发器对功率进行控制。
在很多高密集AP场景下,采用机器学习对WLAN参数进行优化的相关方法并不全面。文献 [16]只适用于状态空间较少的场景,主要使用了分布式强化学习动态地对无线信道与发送功率进行分配与调节。另外由于无线局域网络环境复杂,若使用强化学习进行参数优化则需要不断使得网络运行状况发生改变并要求网络环境即时反馈收益,在算法运行期间可能会影响到网络环境。同时也面临着算法复杂度高、运行时间长、难以收敛等挑战。
现在基于机器学习对网络参数调优算法主要有监督学习、非监督学习以及强化学习,这些方法技术已经在资源分配算法得以应用。文献[17]作者把WLAN的容量优化过程分解为发射功率控制、数据链路调度以及网络流量管理等问题。并利用支持向量机(support vector machines,SVM)和深度置信网络(deep belief network,DBN)得到非线性优化问题的近似解。该算法主要利用SVM来识别每个数据链路是需要断开还是以最大功率支持,然后采用DBN得到最佳功率值。仿真结果表明这一基于机器学习的算法十分有效。另外,文献[18]提出了由AP获取信息并分布式执行的发送功率动态分配算法。该算法中AP可从其相邻AP获取信道状态和服务质量信息,来调节其本身的信号发射功率。该方案的目的是使其提出的加权目标函数达到最大值,以实现每个AP的吞吐量呈比例或者整网达到最大吞吐量。在蜂窝网络应用中,文献[19]分别将基于策略的蒙特卡罗策略梯度(REINFORCE)、基于行为的深度确定性策略梯度(deep deterministic policy gradient,DDPG)及基于值的深度Q学习(deep Q learning,DQL)算法应用到发送功率调节中。最终结论为相较于基于模型的方法,基于数据驱动的方法在速率方面表现更为优异,而其中DDPG在鲁棒性方面的表现最优。但这些只是针对无线网络中某单一方面或特点的应用,并不是机器学习在WLAN中的研究与应用。
2 基于神经网络和遗传算法的公平性保障算法
2.1 基本思想
具有至少一个S型隐含层、线性输出层以及偏差的3层BP神经网络能够以任意精度逼近任何非线性连续函数。本文搭建的神经网络输入节点为网络的一些基本参数配置,输出节点为网络中AP最小吞吐量与最大吞吐量的比值d,该值能够衡量网络中的公平性。通过大量数据训练得到该问题的神经网络模型,并利用测试集进行测试验证,若误差足够小则达到训练效果,否则需要不断调整各层参数或数据集的规模直到输出与期望之间达到误差要求。
神经网络可以看作是一个从n维输入映射到n维输出的黑盒函数,通过神经网络建立WLAN参数与其公平性间的非线性拟合关系,即可简化构建WLAN公平性模型的步骤,并且神经网络的输入数据集可以实时改变,故该神经网络模型也能够动态地对网络性能进行有效评估。
2.2 详细设计
如图2所示,首先改变AP数量、距离、发送功率,能量检测门限、最小竞争窗口值以及带宽参数并基于一体化仿真平台[9-10]得到有限组数据结果,形成训练集和测试集。通过不断修改模型参数和增加数据集训练得到满足误差要求的神经网络模型,将WLAN基本参数输入到模型中,即可得到网络公平性衡量指标d。遗传算法的关键环节之一是适应度函数的设计与计算,由于影响高密集WLAN公平性的因素较多,难以对其进行建模,但神经网络具有强大的拟合能力,从而可以作为遗传算法的适应度函数。通过遗传算法的不断迭代和评估,可以得到WLAN参数配置结果。

图2 参数优化流程图
2.3 神经网络
目前常使用反向传播算法(backpropagation,BP)来训练神经网络。BP算法包括学习和识别两部分,学习过程可分为正向传播和反向传播两部分。正向传播开始时,以任意值作为神经元权值的初值,选取输入数据集中任意一组作为输入,传入隐层处理,最终在输出层得到对应输出。若输出值与期望值存在较大的误差,需要通过误差的反向传递过程,调整各层神经元权值。
本文在搭建神经网络模型中选取了6个与输出公平性特征相关性较大的网络参数,即6维输入特征,能够降低神经网络的运算复杂度,加快拟合无线局域网络环境信息的速度,神经网络的输出为一维特征d。
最终搭建的神经网络模型如图3所示,各层神经元个数以及所选取的激活函数如表1所示。
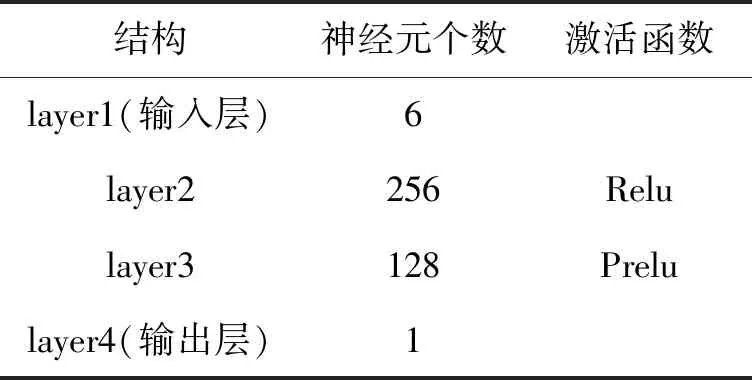
表1 神经网络基本参数表

图3 无线局域网络多层神经网络拟合模型
2.4 遗传算法
遗传算法是数学领域中通过计算找到最佳解决方法的一种搜索算法,其属于进化算法。该算法是由生物界的进化规律演变而来的,随后成为计算机科学领域中被广泛应用的一种优化和搜索的机制。
本文需要求解的网络参数配置为AP发送功率、能量检测门限以及最小竞争窗这3个参数。该算法首先需要基于现有的模型对求解问题进行编码并形成随机遗传种群,再通过基于选择概率和适应度函数的选择性复制、交叉、变异对最终解的适应性评估的满足情况进行验证。若其最终解经过验证后满足迭代收敛条件,则说明该解是最优的。具体流程如图4所示。
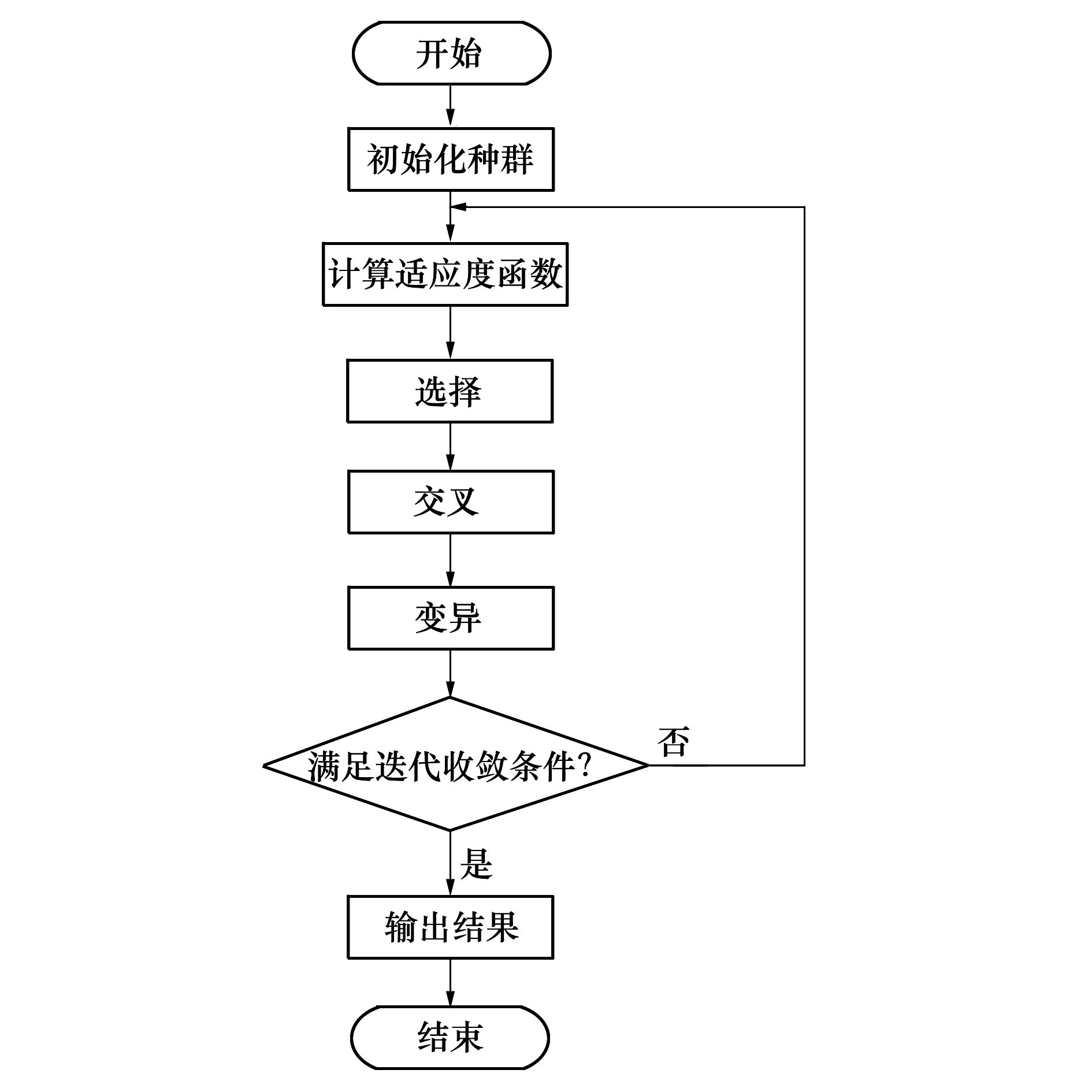
图4 遗传算法流程图
初始化:设定交叉概率Pc和变异概率Pm。假设群体中某个染色体表示为c=(x1,x2,…,xn),其中n表示选取的WLAN参数个数,xi表示第i个参数的取值。
适应度函数计算:这部分利用已经训练完成并达到误差需求的多层神经网络模型进行输出,即染色体中每一位的对应值作为神经网络模型的输入,其输出则为适应度函数值。
选择:采用精英保留策略让上一环节中适应度函数值最大的个体直接进入到下一代进化中。
交叉:所有染色体按照次序并随机完成配对。若染色体个数为奇数,则适应度函数值最大的染色体将不再进行配对。随后采用均匀交叉算子,即一对染色体的索引i处的基因会以交换概率Ps进行交换。经验研究表明,均匀交叉既能保持良好的信息交换特质,又能更优地搜索设计空间。
变异:采用两点交叉变异算子。首先在所有染色体上设置随机的2个交叉点,再根据变异概率Pm交换所设定的2个交叉点之间的部分染色体。
不断重复适应度函数计算、选择、交叉以及变异这4个环节,直至满足迭代收敛条件,将遗传算法最终输出结果的对应解作为最优参数配置。
3 仿真验证
3.1 仿真环境及参数设置
本文采用基于NS3的下一代WLAN一体化仿真平台[9-10],仿真参数如表2所示。

表2 仿真参数表
3.2 仿真结果及分析
神经网络模型训练完成后的最小相对误差值为0.037%,最大相对误差值为2.1%,从图5中测试集数值与BP神经网络预测值对比可以看出该神经网络的训练已满足误差要求。

图5 神经网络模型预测结果 图6 AP个数为3的吞吐量结果对比图 图7 AP个数为6的吞吐量结果对比图
图6为AP个数为3的仿真结果对比图,从图中可以看出在没有进行参数优化的802.11ax场景下,AP2的吞吐量远小于AP1与AP3的吞吐量,采用本文算法得到的参数配置进行仿真后,AP2的吞吐量提高了70.77%,结果表明该参数配置能够改善小区间公平性问题。基于神经网络和遗传算法的方案吞吐量输出结果与在仿真平台中单独使用遗传算法对网络参数求最优解的吞吐量输出结果基本一致。
图7为AP个数为6的仿真结果图,从图中可以看出未进行参数优化的802.11ax场景下,AP2、AP3和AP5的吞吐量远小于AP1与AP6的吞吐量,采用本文算法优化后的参数进行仿真后,AP2、AP3和AP5的吞吐量分别提升了10.31%,27.53%和64.6%,提高了网络的公平性。基于神经网络和遗传算法与单独使用遗传算法的2种方案对吞吐量的输出结果也基本符合。
图8展示了3种方案在不同AP个数场景下的整网总吞吐量对比情况,基于神经网络和遗传算法与单独使用遗传算法的2种方案对整网总吞吐量皆有提升。AP个数为3时,分别提升了16.11%和15.05%,AP个数为6时,分别提升了3.81%和3.25%。因此,公平性问题得到改善的同时,整网总吞吐量也得到了提升。

图8 不同方案下整网总吞吐量结果对比图
从仿真结果对比中可以看出,基于神经网络与算法得到的参数配置使得网络公平性得到提高,如表3所示,3APs场景下AP最小吞吐量与最大吞吐量比值由40.79%提高到86.40%;6APs场景下AP最小吞吐量与最大吞吐量比值由37.27%提高到了79.11%。本文提出的算法与单独使用遗传算法的仿真结果基本符合,表明多层神经网络训练效果良好、误差小,且前者的耗时更短、灵活性更强。尽管神经网络和遗传算法需要引入一些计算和存储开销,但由于遗传算法具有并行计算特性,而神经网络也可以采取离线(或者准离线)学习的方式进行,因此可以降低算法的计算和存储开销。

表3 参数优化方案效果对比
4 结 论
为了改善高密集WLAN中的小区间公平性问题,本文提出了一种基于神经网络和遗传算法的参数调优方案,通过多组仿真数据对神经网络进行训练与验证,使其充当遗传算法中的适应度函数,最终得到最优组合参数取值,在对应参数配置下得到的仿真结果表明网络公平性得到大幅提高。本文方案设计简单,灵活性强,能够在下一代WLAN下具有较强的应用价值。
猜你喜欢
电脑与电信(2018年12期)2018-03-23
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
统计与决策(2017年2期)2017-03-20
集装箱化(2016年12期)2017-03-20
高中生学习·高二版(2016年11期)2016-12-01
智能系统学报(2015年4期)2015-12-27
中国卫生(2015年3期)2015-11-19
