
基于朴素贝叶斯的学术论文推荐算法研究
2023-11-27 13:19严海兵朱振刚
苏州科技大学学报(自然科学版) 2023年4期
严海兵,周 刚,朱振刚,杨 萌
(1.苏州科技大学 图书馆,江苏 苏州 215009;2.苏州科技大学 机械工程学院,江苏 苏州 215009)
学术论文是对某个科学领域中的学术问题进行研究后表述科学研究成果的文章,其主体是期刊论文,是数字图书馆中交流最为活跃的部分。
国内外主流的数字图书馆检索平台收录的论文数量都达到了千万篇的级别,虽然可以在检索词层次帮助用户获得信息资源,但其智能化程度较低,无法在知识层面描述用户的兴趣和需求,导致检索到的信息资源空间较大,用户从这些海量信息中获取符合自己兴趣和需求的信息困难,信息过载。因此,数字图书馆迫切需要针对目标用户兴趣和需求的推送服务,即智慧化的“信息找人”推送服务。孕育于数据挖掘、知识发现、机器学习技术的推荐系统研究应运而生,优秀的学术论文推荐系统是数字图书馆智慧化的迫切需求。
1 学术论文推荐算法研究现状
推荐系统是一种智能个性化信息服务系统,可借助用户对资源的兴趣和需求建立用户信息模型、资源信息模型,并根据模型通过一定的智能推荐策略实现有针对性的个性化资源信息定制[1]。当前应用于学术论文推荐的主流推荐系统算法基本都是基于内容推荐算法[2]和协同过滤推荐算法[3]的改进算法。例如:王嫣然等人的一种基于内容过滤的科技文献推荐算法,针对科技文献建立文本特征向量模型,利用TF-IDF 计算特征关键词对文献的权重,然后使用余弦值计算用户已访问的文献与未访问文献的特征向量的相似度,为用户进行文献资源推荐[4],这是经典的基于内容推荐的研究算法。马鑫等的融合类目偏好和数据场聚类的协同过滤推荐算法研究,该算法引入类目偏好和语义偏好的概念,利用类目偏好比对高维用户—项目矩阵进行降维,然后利用协同过滤进行文献推荐[5]。宋楚平提出使用中图法图书二级分类类目代替图书本身,优化了用户对图书的评价矩阵,再用协同过滤推荐图书[6]。Noor Ifa da 等提出利用用户借阅记录和图书的关键词发生概率建立概率关键词模型,再用协同过滤推荐图书[7]。这些都是在经典的协同过滤推荐算法的基础上提出的改进推荐算法。
主流推荐算法优点很多,但应用于主体是学术论文的数字图书馆存在一定的不足。基于内容推荐算法中用户模型完全基于历史记录中的用户兴趣和需求,难以发现用户潜在兴趣和需求。推荐的结果会聚集在用户过去的项目类别上,如果用户不主动关注其他类型的项目,算法很难为用户推荐多样性的结果,也无法挖掘用户深层次的潜在兴趣和需求[8]。随着时间的推移,用户的研究课题发生变化,对学术论文的兴趣和需求也将发生改变。科学技术日新月异,新技术、新发现、新思想层出不穷,基于历史访问记录的内容推荐不符合学术论文推荐的基本要求。
协同过滤推荐算法能够满足用户对学术论文新动态推荐的需求,能有效地提高检索效果和效率,因此,应用于论文推荐系统的研究较多[9]。在应用中,它存在的不足是冷启动和稀疏矩阵问题:冷启动问题,因推荐系统是基于其他用户的行为而做出的,在系统运行初期,由于缺乏足够的数据记录,无法完成协同推荐;稀疏矩阵问题,是由于系统中用户数量和项目量的巨大,用户对项目的评价有限,据此建立的相似性矩阵稀疏,也无法完成协同推荐。数字图书馆学术论文更新量大,录入的期刊论文月更新量就达万篇,这些都会触发协同过滤推荐算法的冷启动和稀疏矩阵问题。为此多数学者都是围绕弥补冷启动和稀疏矩阵问题,提出其改进算法。
面对学术论文数量达到千万篇级别的数字图书馆,推荐算法的效率是非常重要的。基于内容推荐算法需要用文本特征向量模型表示每篇论文,且两两比较相似度,依据相似度推荐;协同过滤推荐算法冷启动和稀疏矩阵问题影响推荐算法的效率和效果,改进算法提升了效率,但其计算模式没有发生根本的变化,需要建立用户对论文的评价矩阵,计算用户与用户的相似度,依据相似用户推荐。该文研究通过预估用户访问学术论文的概率大小进行系统推荐,尝试从另一个角度解决学术论文推荐的算法。
2 朴素贝叶斯算法(Native Bayes)
贝叶斯理论是一种用事件发生的先验概率和已知信息概率推测后验概率的数理统计方法,被广泛应用于机器学习的自动分类中。朴素贝叶斯算法是在贝叶斯理论的基础上进行了简化,即假定给定样本的分类属性之间相互条件独立[10]。虽然这个简化方式在一定程度上降低了贝叶斯分类算法的分类效果,但是在实际的应用场景中,极大地简化了贝叶斯算法的复杂性,并且实际应用效果较好[11]。
朴素贝叶斯算法先计算各个样本的先验概率,再利用贝叶斯公式计算各样本属于每一个类的后验概率[12]。算法高效稳定,多应用于数据分类分析,如杨晓花等利用贝叶斯算法对图书馆书目进行自动分类[13];丁童心等利用朴素贝叶斯算法进行人脸表情分类识别[14]。
朴素贝叶斯算法应用于文本分类时,算法的目的是为样本文本内容匹配最有可能的类别,就是分配文本到后验概率最大的类别中[15]。文中的研究是改进朴素贝叶斯算法应用到学术论文推荐中,推荐算法的目的是寻找学术论文内容匹配最符合目标用户的兴趣和需求,即推荐论文中后验概率最大的,最符合目标用户的,这里不同的目标用户可以类比作不同的类别容器。
朴素贝叶斯算法在学术论文推荐的工作过程可描述如下:
(1)为每个论文样本F 建立一个n 维特征向量F={w1,w2,…,wn},利用特征向量描述论文内容;
(2)计算后验概率P(U|F),U 为目标用户的需求论文集合;
(3)重复(1)(2),寻找P(U|F)值最大的前m 个样本论文{F1,F2,…,Fm}推荐给目标用户U。
根据贝叶斯公式
设其中P(F)、P(U)对于所有论文、用户均相同,因此只需要寻求计算P(F|U)最大值即可。用户需求论文集合的先验概率,这里假设特征属性w1,w2,…,wn不存在依赖关系,其取值是相互独立的,其中P(wi|U)可以依据用户学术画像特征词计算得到。
3 用户学术画像(User Academic Profile)
用户画像是指根据用户的属性、用户的偏好、用户的行为等信息抽象出来的标签化用户模型[16]。用户画像有多重维度的刻画,不同的应用场景有不同的标签化模型[17]。在数字图书馆推荐系统中,用户画像侧重于学术画像,可依据用户学术研究所属学科领域以及用户在系统中历史访问行为的数据中挖掘而来。数据分为显式的和隐式的,显式的是用户根据调查主动填写的,如用户的学科专业、所属领域、研究方向等;隐式的是根据用户访问行为和用户显示信息关联挖掘的,如用户曾下载过的学术论文、用户曾发表的学术论文等。
3.1 特征词来源
在该文研究中,笔者力图用描述用户兴趣和需求的特征词来标签化用户学术画像,这些特征词来源如图1 所示。显式中学术前沿的特征词可以来自大数据的分析、行业领域专家推荐的研究热点词;研究方向的特征词来源于用户的自定义。隐式中的特征词都来自不同的学术论文,浏览过的、下载过的、发表过的,这些表示用户专注的学术研究。提取的特征词来源于描述论文内容特征的标题、文摘和关键词,通过分词技术抽取能描述论文内容有实际意义的词,去除不能表述实际意义的虚词、通用词等停用词[18]。
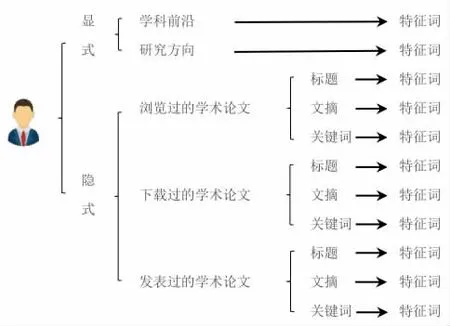
图1 用户学术画像
3.2 特征词加权计算
特征词来源于用户感兴趣的学术论文,多篇论文中都涉及相同特征词,说明用户对这一领域关注多,兴趣度大。用户的兴趣点、研究方向随着时间会有所变化,因此提取特征词的论文发表的时间应该在加权中有所反映。一篇学术论文可用字典数据结构表示为F={‘w1’:k,‘w2’:k,…,‘wn’:k},键w 为特征词,值k 为其权重,k 的初始值为decay(x)。其中Nowyear()为当前年,Pubyear()为论文发表年,论文发表时间x=Nowyear()-Pubyear(),decay(x)是自定义的时间衰减函数。
经过多次测试比较,最终自定义的时间衰减函数是y=decay(x)=1/e0.2x,x≥0,如图2 所示。
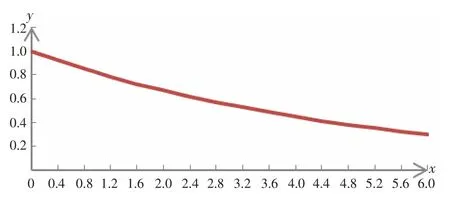
图2 时间衰减函数y=decay(x)
该函数较好地模拟了特征词的出现随着时间的流逝,对用户的影响力不断衰减,权值从1 趋近于0。
基于加权特征词字典的用户学术画像建立流程如下:(1)初始化用户字典U={‘ws’:1,‘wt’:1},ws、wt来源于学科前沿和研究方向的系列特征词,初始权值为1。(2)循环归并用户画像,归并学术论文字典于用户字典U=U∪F,F={‘w1’:k,‘w2’:k,…,‘wn’:k},即U={w:U[w]+F[w] for w in U if w in F},U 和F 中相同特征词w的权值相加生成U={‘w1’:k1,‘w2’:k2,…,‘wn’:kn}。
4 基于朴素贝叶斯的学术论文推荐算法(Native Bayes Filtering,NBF)
该推荐算法是有监督学习的机器学习算法,算法流程如图3 所示。用户曾发表的论文、浏览的论文、下载的论文都是已知用户感兴趣和需求的内容,在推荐的论文中用户依据兴趣和需求对部分论文浏览或下载,相当于对这些被推荐的论文进行了推荐效果的正向评价。这些论文集作为用户画像的来源,同时也是学习算法的数据训练集,通过每次用户的评价,用户学术画像的系数会发生调整,以此提升算法的推荐效果。
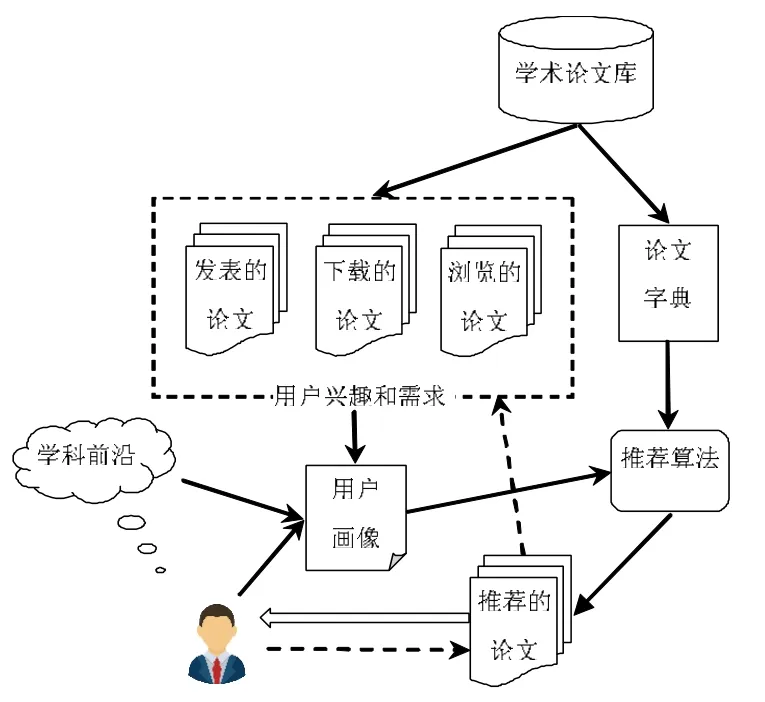
图3 基于朴素贝叶斯的学术论文推荐算法推荐流程
根据上文3.2 中所述的用户学术画像特征词加权计算,U={‘w1’:k1,‘w2’:k2,…,‘wn’:kn},得出P(wi|U)=,wi∈U。根据上文2.1 中的推理,论文推荐度←P(F|U)←P(F|U)=,wi∈F。对于所有特征词w,当∀w∈F 且w∉U 时,P(w|U)→0。
根据表1 的计算过程,用户A 的学术画像U={‘智慧图书馆’:5.8,‘协同过滤’:3.4,‘内容推荐’:3.6,‘人工智能’:1,‘个性化’:2.27,‘情景感知’:2,‘知识图谱’:0.67},因此,P(‘智慧图书馆’|U)=0.31,P(‘协同过滤’|U)=0.18,P(‘内容推荐’|U)=0.19,P(‘人工智能’|U)=0.05,P(‘个性化’|U)=0.12,P(‘情景感知’|U)=0.11,P(‘知识图谱’|U)=0.04。
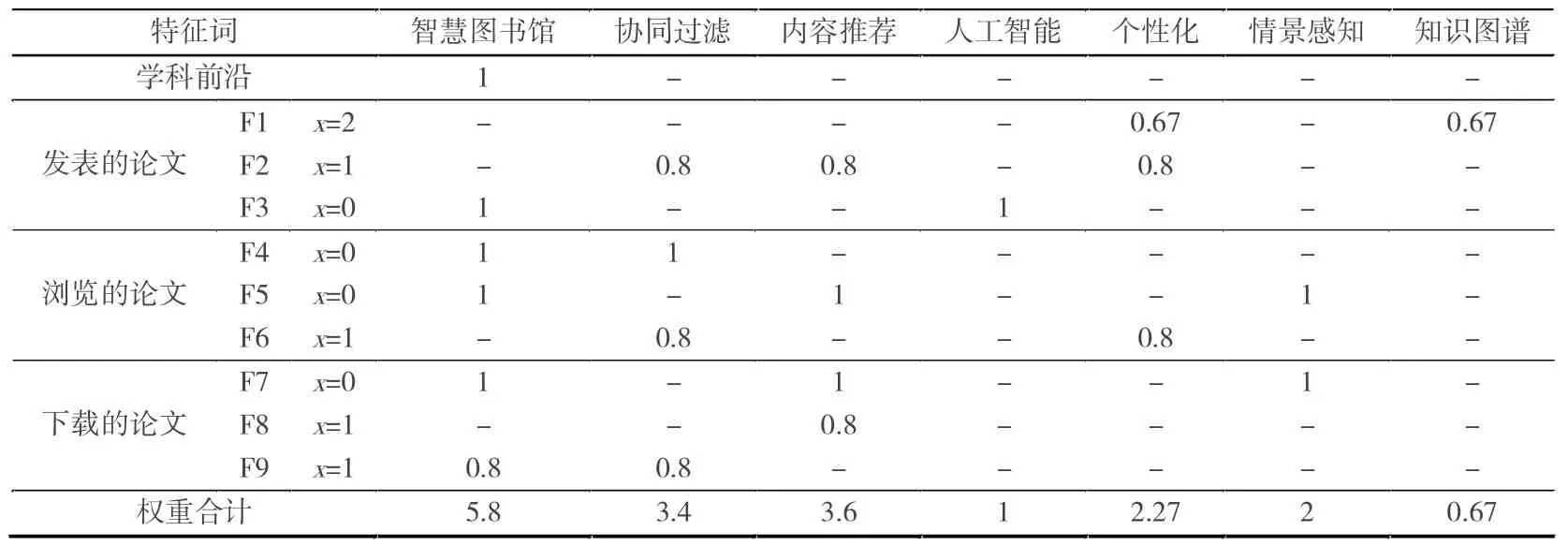
表1 用户A 学术画像特征词加权计算过程
通过分词技术,每篇学术论文对应一个特征词字典,比对用户学术画像中出现的特征词的先验概率可以计算P(F|U)值。表2 为简化的论文推荐度计算过程,F11-F15 为5 篇学术论文,用特征词字典表示,其中w为论文中出现而用户学术画像中未出现的任意特征词,P(w|U)→0,为便于比较和计算,统一设定P(w|U)=0.01。通过推荐度的计算,论文的推荐顺序为:F12>F11>F13>F15>F14。

表2 论文推荐度计算
5 实证分析
为了验证文中NBF 推荐算法的有效性,从万方数据数据库中获取相关期刊论文的数据。实验测试算法中选取论文特征词数量M 与描述用户学术画像特征词数量N 的最优取值。推荐的学术论文是否满足用户的兴趣和需求以用户是否浏览、下载过为依据;浏览、下载过的论文被补充进描述用户学术画像。最后在相同的实验环境及数据条件下,对文中的NBF 推荐算法与传统的基于内容推荐算法(CBF)、协同过滤推荐算法(CF)进行实验测试,比较3 种推荐算法的查准率P、召回率R、F1值及运行时间等评价指标。
5.1 数据来源
选取包含篇名、文摘、关键词的论文数据1 000 条,涉及学科有环境科学、材料科学、计算机科学、电子信息、土木工程、机械工程、数学、物理、化学、生物,每个学科相关论文100 篇。选取测试用户20 人,每一学科涉及2 人,其中10 人有已发表论文,包含于选取数据中1 篇到5 篇不等。
5.2 实验过程
在Win dows 系统环境下使用Python3.5 对文本数据进行分析,使用jieba 库进行中文分词,去停用词,计算每篇论文的特征词权重,筛选出权重较大的前M 个特征词,形成特征词字典,表示对应论文。根据测试用户所属学科专业和已发表的论文,初始化用户学术画像。在模拟环境下,测试用户浏览、下载论文,系统算法反馈推荐的论文,用户再根据推荐论文,选取需求的论文浏览、下载评估推荐的准确性。算法通过这样的多次学习训练,一次次地加权计算出描述用户的特征词,选取权重较大的N 个特征词,建立字典描述用户学术画像。
5.2.1 实验1 不同特征向量维度下的算法平均推荐准确率
实验确定M、N 特征词数量。令M=5,改变N 的取值,测试结果如图4 所示,随着N 值的增大,平均推荐准确率逐渐提高,到达30 后趋于平稳,因此取N=30,继续M 值的测试。
随后,令N=30,改变M 的取值,测试结果如图5 所示,随着M 值的增大,平均推荐准确率逐渐提高,到达35 后趋于平稳。因此取M=35 为最优解。
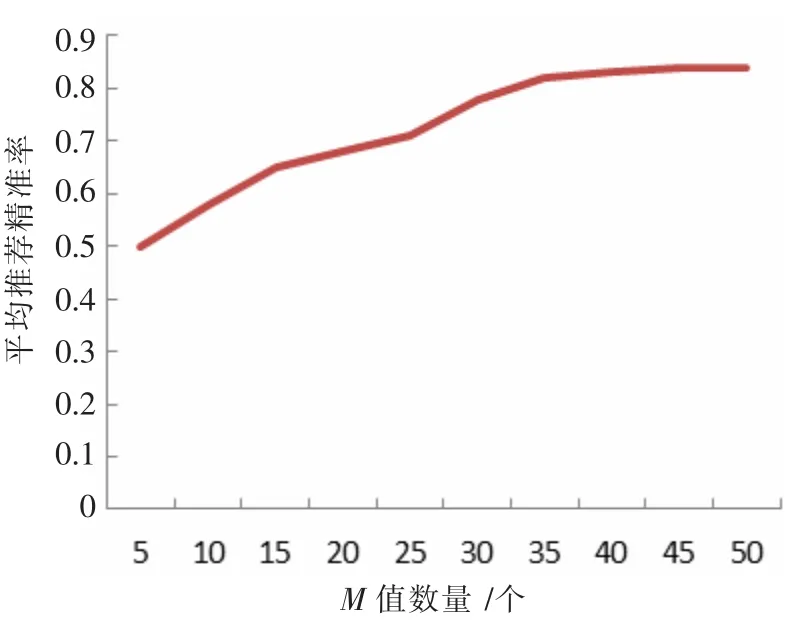
图5 N=30 时平均推荐准确率趋势图
通过实验确定N 值和M 值,确定用户画像特征词和学术论文特征词向量的最优维度。取N=30、M=35 个经验最优值,是为了下一步NBF、CBF、CF 的比较测试。
5.2.2 实验2 文献检索基本性能指标比较测试
取N=30、M=35,测试文中的NBF 推荐算法随着推荐论文数量从20 至60 每次增加5 的不同情况下的查准率P、召回率R、F1值及运行时间的变化情况。在相同的模拟实验环境下,引入CBF、CF 推荐算法进行测试,作为性能参照。其中CBF、CF利用TF-IDF 计算特征关键词对论文的权重,使用余弦值计算两个特征词向量的相似度,为用户进行资源推荐。
如图6 所示三种推荐算法随着推荐论文数量的增加,查准率P 都有所下降。NBF 和CBF 算法在推荐论文50 篇内,性能接近,50 篇后NBF 趋于平稳,较优。CF 算法在推荐中遇到了冷启动问题,在模拟测试中性能较差。
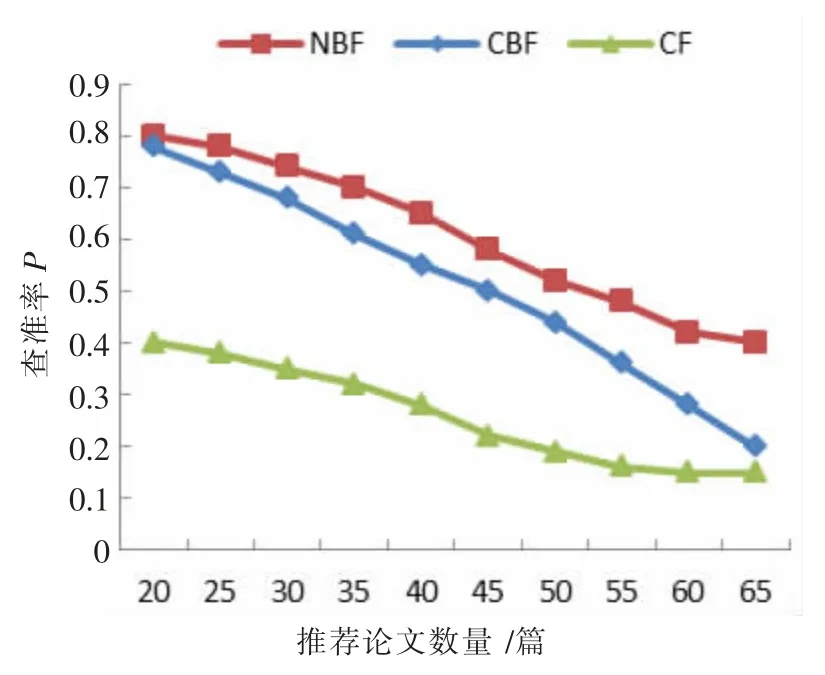
图6 三种推荐算法随推荐论文数量查准率变化图
如图7 所示三种推荐算法随推荐论文数量的增加召回率变化趋势。NBF 推荐算法明显好于CBF 和CF算法。CF 依然在推荐中遇到了冷启动问题。
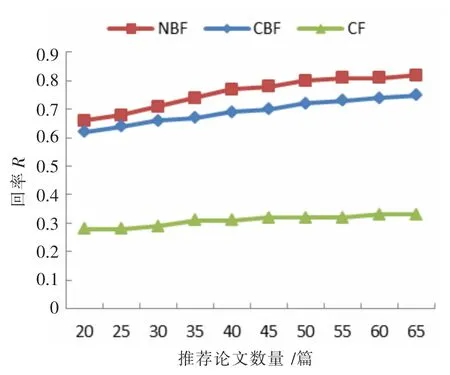
图7 三种推荐算法随推荐论文数量召回率变化图
F1值是同时兼顾推荐算法的查准率和召回率的重要性能指标,可以根据公式F1=(2PR)/(P+R)进行计算,如图8 所示。NBF 仅在推荐20~25 篇论文时与CBF 相当,其他推荐数量时,均优于CBF 和CF 算法。
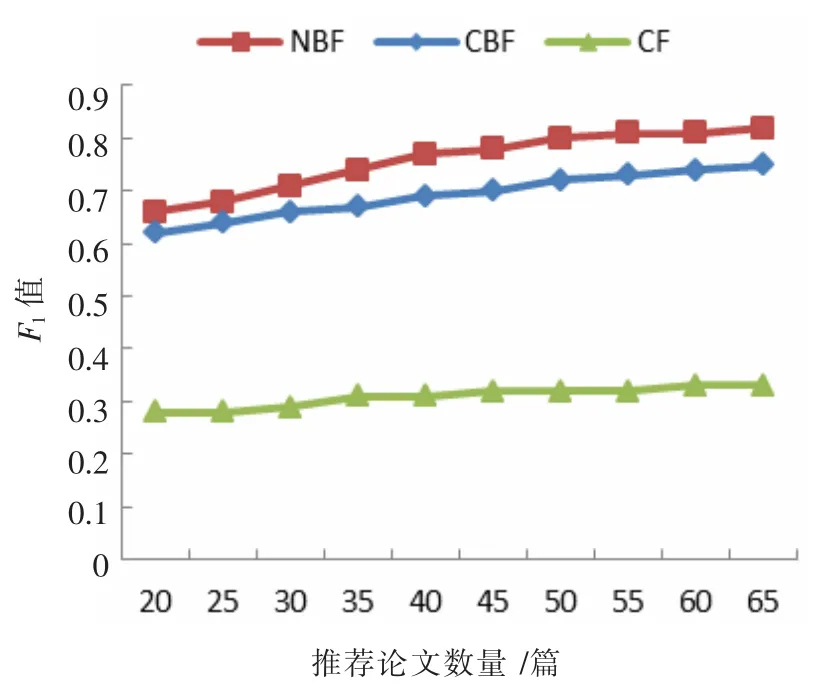
图8 三种推荐算法随推荐论文数量F1 值变化图
5.2.3 实验3 推荐算法运行时间比较测试
在相同的运行环境下,三种推荐算法随着推荐论文数量的增加,运行时间的变化如图9 所示。NBF 算法平均运行时间为4.9 s,CBF 算法平均运行时间为6.9 s,NBF 比CBF 运行效率提高了29%。CF 算法因为测试用户数量少,影响了实验效果。
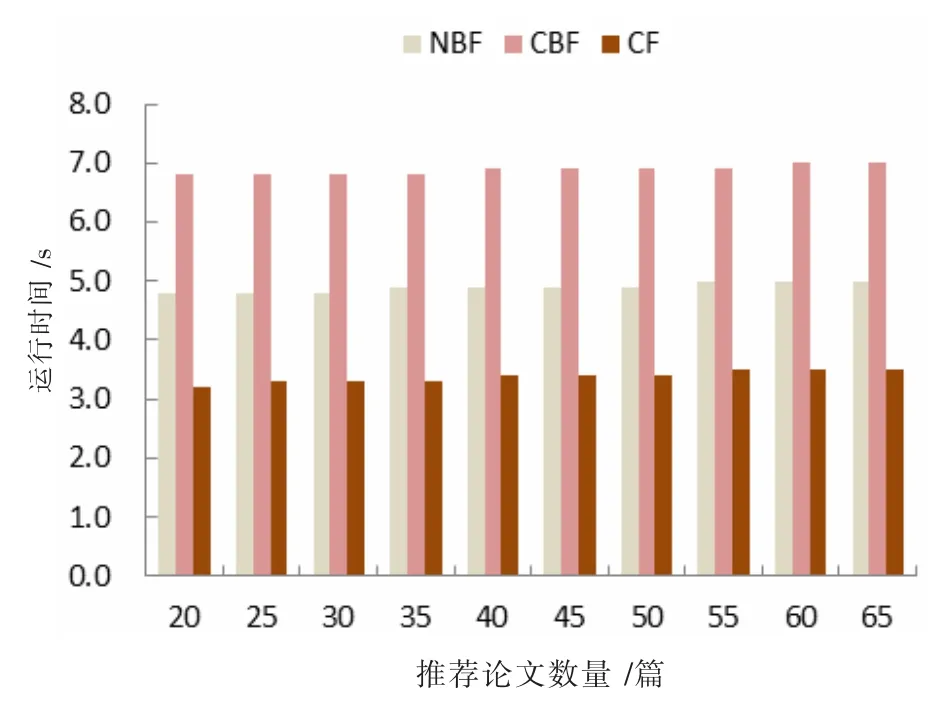
图9 三种推荐算法随推荐论文数量运行时间变化图
实验结果表明当N=30、M=35 时,文中研究的NBF 算法在测试指标查准率P、召回率R、F1值、运行时间方面明显优于CBF、CF 算法。实验中CF 算法使用的是基础的协同过滤算法,没有消除CF 算法中固有的冷启动问题等不足,因此这里的CF 算法表现较差。该实验不能表示其他学者的CF 改进算法的测试结果。
6 结语
学术论文是国家地区科学研究、高等教育的重要文献保障资源,如何提升学术论文的有效利用率是图书情报学研究撬动科研能力提升的杠杆。学术论文有其自身的特点:学科专业性强,内容分类细,月更新量大,同时学术论文还是数字图书馆的主体,其主流数字图书馆检索平台收录的论文数量多达千万篇[19]。在海量的资源中,基于用户学术画像,推荐用户有效论文极其重要。基于朴素贝叶斯的学术论文推荐算法NBF,是依据贝叶斯分类算法提出并改进的,在模拟测试的环境中性能优于主流CBF、CF 推荐算法,在实际应用中具有一定的价值。文中的研究是从预估用户访问学术论文的概率入手思考推荐算法的,可以为图书馆个性化推荐服务提供了新的思路。
猜你喜欢
系统医学(2023年18期)2024-01-10
系统医学(2023年13期)2023-10-26
系统医学(2022年17期)2022-11-07
小哥白尼(神奇星球)(2022年3期)2022-06-06
系统医学(2022年2期)2022-05-05
新世纪智能(高一语文)(2020年9期)2021-01-04
非公有制企业党建(2020年10期)2020-10-27
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
中文信息学报(2015年4期)2015-04-21
