
面向骑行地图推断的轨迹数据质量提升方法
2023-11-29 04:20沈文怡吴问宇毛嘉莉
华东师范大学学报(自然科学版) 2023年6期
陈 杰,沈文怡,吴问宇,毛嘉莉
(华东师范大学 数据科学与工程学院,上海 200062)
0 引 言
随着非机动车保有量的大规模增加,互联网相关的非机动车行业蓬勃发展且已进入快速成长期.为方便快捷地到达目的地,人们常以非机动车作为交通工具.由于缺少专业精准的非机动车骑行导航地图,非机动车常常进入非机动车限行区域,导致在行程中花费较多的时间并存在安全风险.此外,骑行时若依赖更新不及时的两轮车导航软件所提供的线路前往目的地,则容易发生误入深山、林区等事件.构建并及时更新非机动车骑行地图能保证高效骑行线路规划,提升非机动车骑行体验感.随着非机动车相关服务的迅猛增长,出现了海量的非机动车轨迹数据,这些轨迹数据与所对应产生的行程、车辆、基准路网等数据,为骑行地图的推断提供了数据基础.由于受定位设备误差、非机动车骑行习惯等因素的影响,骑行轨迹数据集中存在大量异常数据以及定位信息缺失的情况,使非机动车骑行地图的推断面临严峻的挑战,因此急需设计一种轨迹数据质量提升方法,用来提升面向骑行地图推断的数据质量.
通过对真实非机动车骑行轨迹数据的分析与调研,非机动车骑行轨迹中除了轨迹数据普遍存在的带有方向、速度噪声的异常轨迹点以外,还存在热门骑行区域的徘徊轨迹段、带有违规转向与逆向骑行的违章轨迹段、信号漂移轨迹段以及信号缺失轨迹段等数据异常.徘徊轨迹段常见于非道路区域,伴有方向多变与低速行驶的现象.违章轨迹段则以非转向区域的转向以及逆行事件呈现,它们为道路拓扑的精准提取带来一定程度的干扰,需要及时发现并消除.信号漂移轨迹段和信号缺失轨迹段常发生在信号薄弱区域,需要利用历史轨迹数据对漂移行为进行有效识别以及基于稀疏数据对缺失轨迹进行恢复.非机动车骑行轨迹数据存在的质量问题具体如下.
(1)异常轨迹点: 骑行轨迹存在偏离其近邻的异常轨迹点,表现为与近邻点在时间、距离、方向上具有明显差异,如图1(a)所示.
(2)徘徊轨迹段: 考虑用户到达骑行终点附近需寻找停车位置,用户的轨迹方向无规律地跳变,其骑行速度较慢,骑行终点附近区域存在大量到达状态的轨迹点等,如图1(b)所示的商务区CBD(central business district)地下停车场(以红色圆圈标注).该部分轨迹段不属于在道路上的骑行状态,对于地图推断无意义.
(3)违章行驶轨迹段: 非机动车在行驶过程出现违规骑行行为,如逆向行驶、在非机动车限行道路上行驶、禁止转向区域的转向等,如图1(c)所示(以紫色线段标注).
(4)轨迹段缺失: 定位设备信号弱导致轨迹段缺失,如图1(d)所示,在信号较弱区域,被采样的轨迹出现大量轨迹点采样缺失的情况,导致相邻轨迹点的距离较远,即连续轨迹点间连接产生的轨迹段较长,使用这些长距离的轨迹段定位信号薄弱区域.
(5)轨迹段漂移: 当经过高架、隧道等区域时,GPS(global positioning system)信号无法准确定位,移动设备自带的惯导系统根据连续测得的运动方向和加速度推算车辆后续位置,即相对位置.当后续坐标系转换不恰当时,会出现整段漂移的情况,如图1(e)所示.
针对上述问题,本文提出了一个面向骑行地图推断的轨迹数据质量提升框架,具体如下.
(1)本文研究了非机动车骑行轨迹中存在的影响后续地图推断的数据质量问题,包括需要进行轨迹去噪的轨迹噪声中的异常轨迹点(方向噪声、速度噪声)和异常轨迹段(徘徊轨迹段、违章轨迹段)以及需要进行轨迹恢复的轨迹段缺失和轨迹段漂移.
(2)为了解决非机动车骑行轨迹存在的异常轨迹和数据缺失等低质量问题,本文针对异常轨迹点、异常轨迹段、轨迹段缺失及轨迹段漂移等制定了基于异常特征的检测方法,并进行了数据质量提升.
(3)本文使用真实轨迹数据,以非机动车轨迹的后续地图推断为标准,通过与现有轨迹数据质量提升方法进行对比实验,验证了本文所提出的方法能有效改进非机动车轨迹数据的质量,并且较大提升了后续的地图构建效果.
1 相关工作
1.1 轨迹去噪
目前实现轨迹去噪的方法主要可以分为以下两类: 第一类是基于近邻轨迹的离群去噪法,该方法以噪声轨迹的时空相邻轨迹为基准,比较噪声轨迹与这些基准轨迹在速度、方向和距离等特征上的差异以实现噪声轨迹的检测与去噪.文献[1-3]先对轨迹进行地图匹配获得未匹配轨迹,再使用kNN(knearest neighbor)算法获得密度离群轨迹点并舍弃.文献[4-5]首先基于采样间隔对轨迹进行分段、再删除距离较短或轨迹点较少的分段并对轨迹进行简化.该方法对于采样质量较高且不存在违规轨迹段的轨迹数据的去噪效果较好,但对于在非机动车骑行轨迹中存在的大量违章轨迹段和非道路区域的徘徊轨迹段不能很好检测与消除,这容易导致地图构建时出现大量错误.第二类是保留关键信息的轨迹简化法,通过保留最可信的部分轨迹并去除其余轨迹的方式以实现轨迹去噪[6-9].文献[7]保留与前一个点大于等于10 m 的点进行去噪,文献[8-9]随机选取轨迹点,并将其附近小距离阈值内的点的信息聚集到该点,每次操作完将该范围内的所有其他点进行删除,直到所有的轨迹点都处理完毕,该方法对于密集轨迹的去噪效果较好.非机动车骑行轨迹较为稀疏,使用该方法进行轨迹去噪则会遗漏大量轨迹数据使得数据更加稀疏,不利于骑行地图的推断.
1.2 轨迹恢复
目前对于缺失轨迹数据的处理方式主要可以分为以下3 类: 第一类是线性插值法,该方法在起始点和结束点之间进行线性插补.文献[10]通过假设轨迹是沿直线且均匀移动,以此来恢复缺失位置.当移动对象沿直线移动时,该方法填补效果良好,实际上移动对象可能存在沿曲线行驶或进行转向的行为,导致线性插补效果较差.第二类是基于历史轨迹数据的路径推理填补法,该方法首先需要基于历史轨迹数据生成可路由图,然后考虑图中点之间的转移概率进行路径推理.文献[11]提出了一种最大概率乘积算法,基于热门度指标,以广度优先的方式从构建的传输网络中发现最热门的路径.文献[12]将地理空间网格化,首先使用具有不确定性的历史轨迹数据构建可路由图,然后根据路由算法在图中搜索两点之间的Top-k路径(一系列点的位置).文献[13]提出了一种基于锚点的校准系统,将轨迹与一组固定的锚点对齐以完成轨迹恢复.当待处理的轨迹段位于信号薄弱区域时,该区域内历史轨迹数据非常稀疏,无法支持可路由图的生成和转移概率的计算.第三类是基于历史轨迹数据的位置预测填补法,该方法采用循环神经网络等深度学习模型对轨迹进行建模并使用历史轨迹数据进行训练,从而预测缺失的轨迹点位置.文献[14]设计了一种带有卡尔曼滤波器校准组件的子序列到序列模型,从不规则的低采样模型中恢复高采样率轨迹.该方法可以捕捉到轨迹序列中的时空依赖关系,但当训练的历史轨迹数据中存在大量缺失时预测效果存在波动.
2 概念定义及整体框架
2.1 概念定义
定义 2给定轨迹点pi与预设的距离阈值Ndis,以及轨迹点集合P,pi和pj之间的距离由Gdis(pi,pj)(实际地面距离)表示,pi的近邻点定义为
定义 3给定轨迹T{p1,p2,···,pn},长采样间隔轨迹段Li{pi,pi+1}满足以下两个条件:
(1)Gdis(pi,pi+1)>(1+α2)×adis,其中adis表示连续轨迹点间的平均采样距离间隔,α2为距离约束的调节参数,据实际数据分析设为0.5;
如图2 所示,橙色轨迹段是轨迹点对(ps,pe)的一条相似子轨迹.
2.2 整体框架
本文框架包括6 个部分: GeoHash 网格索引构建、异常轨迹点的消除、徘徊轨迹段的消除、违章轨迹段的消除、漂移轨迹段的校准和缺失轨迹段的恢复,如图3 所示.
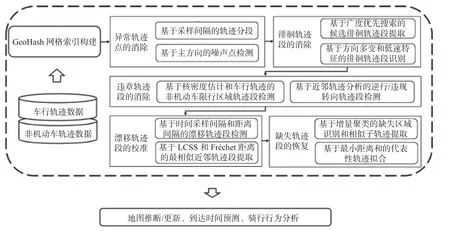
图3 整体框架图Fig.3 Global architecture
针对上述提到的非机动车骑行轨迹存在的数据异常与缺失问题,本文使用如图3 所示的策略.
第一,使用基于GeoHash 的单元划分方法将低质量区域分割成固定大小的网格,并对轨迹点建立GeoHash 网格索引以加速后续基于近邻范围的异常检测与数据恢复;第二,采用基于近邻轨迹点的主方向与速度的轨迹噪声检测方法,识别转向异常点和速度异常点并予以消除;第三,根据方向多变和低速特征,基于网格采用广度优先搜索(breadth first search,BFS)方法识别与较大范围时空近邻不同的徘徊轨迹段并消除;第四,使用核密度估计和基于网格的近邻轨迹分析,检测违章行驶轨迹段并消除;第五,利用漂移轨迹段的采样间隔与历史轨迹平均采样间隔的差异,以及漂移轨迹段与空间近邻轨迹移动行为的不一致性检测漂移轨迹段,利用LCSS 和Fréchet 距离计算提取最相似近邻轨迹段以替换漂移轨迹段实现校准;第六,根据近邻轨迹点间的平均采样间隔提取具有较长时间(或距离)间隔的轨迹线段,使用增量聚类方法对其进行聚类以识别缺失轨迹所在区域,基于该区域的历史轨迹数据获取相似子轨迹,再采用最小距离和的拟合方法实现对缺失轨迹的恢复.
3 面向骑行地图推断的轨迹数据质量提升方法
3.1 GeoHash 网格索引构建
面向地图推断应用中所存在的异常轨迹大多数与其周围近邻轨迹数据存在差异,在进行异常检测时,需要提取其周围轨迹数据信息,以得到正常轨迹的相关特征并进行异常判定,由于轨迹数据的海量性,如果直接对全量轨迹数据进行搜索就会耗费大量时间.为了解决该问题,本文使用GeoHash 网格索引,以网格的方法对轨迹数据信息进行索引,用于提升后续异常数据检测的近邻轨迹搜索效率.
首先使用基于GeoHash 的网格单元划分方法将数据异常区域分割成固定大小的网格.然后对骑行轨迹数据中轨迹点的方向、相邻轨迹点间的方向变化与速度变化、相邻轨迹点之间采样时间差进行计算.最后在此基础上结合轨迹点所处的行程状态(如“骑行中”“到达骑行终点附近”)信息形成轨迹点的衍生属性,对轨迹数据建立GeoHash 网格索引.
GeoHash 是一种地理编码算法,可以在时间复杂度O(1)(O为时间复杂度符号)下将GPS 坐标按照不同的编码长度定位到不同大小的地理网格单元中,同时,对于不同GPS 坐标所对应的编码公共前缀长度越长,其所在位置则越近.考虑到国家标准的车道宽度为3.50 m 至3.75 m,设置对应GeoHash编码长度为9(即对应网格单元的长、宽均为4.80 m).
3.2 异常轨迹点消除
由于受采样设备和信号的影响,原始轨迹中存在偏离其周围轨迹的异常轨迹点,表现为与周围近邻轨迹点在方向和速度上存在较大差异.前者称为转向异常点,后者称为速度异常点.异常轨迹点使轨迹产生较大波动,甚至产生错误的道路拓扑信息,不利于骑行地图的准确推断,应将其视为噪声并消除.
考虑异常轨迹点与其周围轨迹在方向和速度上的差异,采用基于近邻轨迹点的主方向与速度的轨迹噪声检测方法,识别转向异常点和速度异常点并予以消除,方法具体如下.
第一,统计相邻轨迹点间的采样时间间隔,以平均采样时间间隔αtime作为轨迹段划分的阈值对轨迹分段以得到时间采样间隔正常的轨迹;第二,按照国家标准非机动车的上限速度tspeed为25 km·h–1,以上限速度为阈值检测速度异常点并对其进行删除的轨迹点以消除速度异常点;第三,基于少数转向异常点与其大多数近邻轨迹点的方向差异特性,先用GeoHash 网格查找待检测轨迹点的近邻;第四,对近邻点按照方向将其划分为8 个不同方向(与正北相差角度为(i0,1,2,···,7)的8 个方向)类;第五,考虑道路有单向/双向道,如待测轨迹点方向不属于轨迹点数量最多的两个方向,则将其视为转向异常点予以删除.近邻点的方向代表了待检测轨迹点周围大多数轨迹点的正常方向,如果待测轨迹点方向与之相差较大,则认为其方向存在异常,考虑到国家标准的车道宽度为3.50 m 至3.75 m,设置比车道略宽的距离阈值,可取tdis4.00 m .
3.3 徘徊轨迹段消除
由于非机动车骑行场景的特殊性,骑行者常常进入一些非道路区域,例如居民区、商圈等.在这些区域中,骑行者往往不能直接快速到达目的地,而是在小区域范围内花费大量时间骑行.同时由于轨迹采样本身存在的随机误差,所采样的轨迹会在其真实轨迹附近产生随机分布,轨迹会呈现出随机徘徊的状态,这样的轨迹段不仅无法呈现出道路的拓扑结构,其存在更会影响附近区域路口和道路的识别,并影响骑行地图的最终构建,需要对徘徊轨迹段识别并消除.
如图1(b)所示,非机动车骑行轨迹的徘徊轨迹段位于骑行行程所涉及的非道路区域,该类区域是大量状态为“到达骑行终点附近”的轨迹点所在区域,同时,徘徊轨迹段常伴有方向多变且速度相对于正常骑行轨迹速度较小等行为.
第一,根据这些特性,基于广度优先搜索(BFS),搜索待检测轨迹点的近邻点,考虑到非道路区域相较于道路区域的轨迹稀疏特性,这里设置近邻点距离阈值Ndis=8 m 以提取更多的近邻轨迹点;第二,基于得到的近邻点,统计其中状态为“到达骑行终点附近”的轨迹点的数量在近邻轨迹点中的占比,当占比超过状态为“骑行中”轨迹点数量的在近邻轨迹点钟的占比时,将该区域视为与非机动车骑行相关的热门非道路区域,如果一段轨迹连续多个轨迹点位于热门非道路区域,将其视为候选徘徊轨迹段;第三,统计候选徘徊轨迹段内轨迹点的方向并将其划分到8 个方向类;第四,考虑到道路骑行轨迹可能偶发转向行为以及转向前后骑行方向不变的特性,如果候选徘徊轨迹段内轨迹点的方向类超过两个,且轨迹段内部由点连接成的线段存在空间交叉的情况,同时该候选徘徊轨迹段内轨迹点的平均速度小于在道路骑行时的平均速度(这里设置平均速度αspeed4.0 m·s-1),就判断该候选徘徊轨迹段为徘徊轨迹段予以删除.
3.4 违章轨迹段消除
如图4(a)所示,黄色轨迹是上海市延安高架路附近的非机动车骑行轨迹,红色轨迹是一条在机动车区域内行驶的骑行轨迹,此类轨迹将会对合规的骑行地图构建、路径规划等应用造成精度损失.鉴于网格下轨迹点密度的稀疏性会影响机动车的车行区域的平滑性,利用核密度估计来计算各网格单元内的骑行轨迹与(汽车)车行轨迹密度,根据车行区域内轨迹密度应显著大于骑行轨迹密度的特性,判定其属于非机动车限行区域的网格单元.

图4 非机动车限行区域轨迹的消除Fig.4 Elimination of trajectories in non-motor vehicle restricted areas
基于上述步骤识别的限行区域网格单元,对骑行轨迹进行遍历,当相邻轨迹点连接形成线段覆盖的限行区域网格单元的占比超过阈值tprop(设置tprop0.1 以保证限行区域内骑行、车行轨迹的差异显著性),判断该线段为异常轨迹段;当异常轨迹段存在连续轨迹点间长度超过距离阈值dlen(这里,以时间平均采样间隔与骑行限速的乘积设置dlen84 m)时,判定其为异常行驶轨迹段并消除,效果如图4(b)—(c)所示.
用户骑行非机动车时在前往目的地过程中由于抄近道等原因,存在着逆向行驶和违规转向(如横穿马路)的行为,这些行为本身并不符合道路交通法则,对骑行地图的构建会产生较大误差.
用户骑行非机动车时由于抄近道具有逆向行驶和违规转向(如横穿马路)行为.如图5(a)所示,蓝色轨迹与其所在道路(黑色箭头标注)方向相反,该轨迹为逆行轨迹,紫色轨迹区域存在违规转向行为,表现为在马路中间穿行,属于违规转向,具体违章轨迹段消除的方法如下.

图5 违章行驶轨迹段示例Fig.5 Illustration of illegal driving
第一,考虑到逆行和违规转向轨迹段与其大多数近邻轨迹点在方向以及方向变化上均存在较大差异,故先通过范围提取待检测轨迹点的近邻点,并将近邻点根据方向与方向变化划分到8 个方向类中.第二,当近邻点的方向大致相同时(以大多数近邻点的方向为主方向,设置不属于主方向的方向占比阈值tprop0.1),判定该轨迹点所处道路为单向道.第三,若当前轨迹点方向与主方向相反(即与主方向相差180°),判定该轨迹点存在逆行行为.若连续轨迹点序列中不存在逆行行为的轨迹点占比低于设定的阈值(tprop0.1),则判定该轨迹点序列为逆行轨迹段应予以消除,如图5(b)所示.第四,当轨迹点方向不属于近邻点主方向,且其方向变化不同于其近邻轨迹点的方向变化时(取不属于主方向变化的占比阈值tprop0.1),判定该点有违规转向行为.第五,当连续轨迹点序列的方向属于主方向的占比低于阈值(tprop0.1)且存在违规转向行为的轨迹点,判定该轨迹点序列存在违规转向行为应予以消除.
3.5 漂移轨迹段校准

图6 轨迹校准与恢复Fig.6 Calibration and recovery for trajectory
3.6 缺失轨迹段恢复
由于部分区域定位信号弱,存在连续轨迹点间的时间远长于平均采样时间间隔和距离远大于平均采样距离间隔的情况,称为较长采样间隔线段.因此,首先检测发现较长采样间隔线段,然后对其进行增量聚类以定位信号弱的区域.
先维护一个较长采样间隔线段簇的集合,当检测到一条较长采样间隔线段Li时,通过计算Li与现有较长采样间隔线段簇的代表轨迹之间的距离,搜索距离Li最近的较长采样间隔线段簇(满足Li与其的距离小于指定阈值β),将Li插入该簇并重新计算所在簇的代表轨迹.如未找到,将Li单独作为一个簇,β的值按照公式 m in{,β}计算得到,其中llen表示较长采样间隔线段的长度.较长采样间隔线段簇Ck的代表轨迹的起点lcs和终点lce由以下公式计算得到,其中为Li的起点,为Li的终点.
线段间的距离采用豪斯多夫距离方法,该方法结合平行距离、垂直距离和角距离等对线段之间的距离进行评测.当长采样间隔轨迹段簇的数量超过内存所能保存的最大数量m时,合并两个距离最近的簇.当轨迹簇Ck的线段数Nnum大于预设阈值tnum(tnum10)时,将该簇所在区域视为弱信号区域.针对弱信号区域内的缺失轨迹,以位于这些区域的长采样间隔轨迹段的两个端点(Sst,Eed)为查询点,从历史轨迹中提取相似轨迹段集合.分别计算相似轨迹段集合中轨迹段之间的Fréchet 距离,找出与其相似轨迹段之间距离之和最小的轨迹段,将其作为参考轨迹段.
考虑到基于距离计算得到的参考轨迹段具有不稳定性,使用参考轨迹段附近的轨迹点对参考轨迹段进行校准,具体方法为: 首先将Sst视为代表轨迹点rps;再依次以参考轨迹段的轨迹点pi+k(0 ≤k≤m)为圆心,以道路宽度d为半径,找出该区域内的所有轨迹点,并在这些轨迹点中筛选出与轨迹点pi+k的方向夹角小于阈值tangle的轨迹点集合Sp(tangle设置为10°),将Sp中轨迹点的平均位置点作为这些轨迹点的代表轨迹点pi+k.
为保证代表轨迹的平滑性,若连续两个代表轨迹点间的距离小于平滑度阈值tsm(实验中设为30 m),跳过当前代表轨迹点遍历.直到Eed与当前轨迹点之间的距离小于平滑度阈值tsm,将Eed作为最后一个代表轨迹点pe,以完成代表轨迹段地提取,并使用该代表轨迹段替换与之对应的较长采样间隔线段,当代表轨迹段替换完成后即完成缺失轨迹段的恢复,如图6(b)所示.
4 实验结果与分析
为了验证框架的有效性,本文基于真实轨迹数据集进行对比实验和消融实验.通过与各种路口检测和道路生成中的预处理方法进行对比,并分析不同步骤带来对应路口检测和道路生成效果的提升,观察路口检测和道路生成在本文方法基础上路口检测准确性与道路生成质量上的效果差异来验证本文框架的有效性.
4.1 实验数据集
骑行轨迹数据: 本文使用2020 年06 月到2021 年06 月的上海真实非机动车骑行轨迹,包含约80 万个GPS 坐标点,1.6 万条轨迹.
车行轨迹数据: 本文使用2020 年06 月01 日的上海真实车行轨迹数据,包含约360 万个GPS 坐标点,1 万条轨迹.
路网数据: 本文使用上海市2020 年的OSM(openstreetmap)骑行路网数据.
4.2 实验环境
实验时使用的Python 版本为 3.7.3,服务器操作系统为 CentOS Linux release 7.2.1511,硬件环境为 48 核Intel(R)Xeon(R)CPU E5-2670 v3 @ 2.30 GHz,内存125 GB.
4.3 评价标准
为定量评价本文框架对地图推断算法的有效性,将地图推断算法得到的结果与真实路网数据进行比较.文献[15]将地图推断算法分为道路提取[16]、交叉链接[6,17-18]和增量分支[7]3 类,在本实验中将基于这3 类方法进行定量评估,根据不同的地图推断原理,实验主要涉及路口检测和道路生成两部分,其中交叉链接方法的路口检测较为重要,而道路提取和增量分支工作更多体现在道路生成上,相关评价标准如下.
(1)路口检测: 使用精确率nP、召回率nR、F1分数作为评估标准,其中真实位置从OSM 路网数据中获得,Ltru表示真实路口数量,Ldet表示检测到的路口数量,Lcor表示正确识别的路口数量.F1值越高表示性能越好,精确率nP、召回率nR、F1分数分别定义为
(2)道路生成: 将生成的道路与真实的OSM 路网进行地图匹配,使用精度指标准确的数量AN,准确的长度AL以及正确匹配百分比CMP来评估实验效果.Cwnu表示正确匹配的道路数量,Gwnu表示生成的道路数,Cwle表示正确匹配的道路长度,Gwle表示生成的道路长度,Cpnu表示正确匹配的样本点数,Gpnu表示需要匹配的样本点数,其中
4.4 对比算法
为了说明本文框架的有效性,将其搭建在现有的地图推断算法上进行比较.
(1)CITT[4](a three-phase calibration framework for road intersection topology usingtrajectories):由轨迹数据质量提升、核心区检测和影响区内拓扑结构校准构成的路口校准框架.
(2)Huang19[17]: 通过将主路口与次路口分别检测再合并的方式获取路口信息,使用DBSCAN(density-based spatial clustering of applications with noise)方法对收敛点和约束收敛点聚类以提取路口位置.
(3)SLC[16](spatial-linear clustering): 结合路网线性特性,使用空间线性聚类算法生成空间线性簇,利用基于几何的方法提法空间线性簇的代表轨迹.
(4)Cao09[7]: 引入吸引力模型调整轨迹点的位置,并根据轨迹点与图节点的距离、方向差异依次将轨迹点合并或者插入已有图中.
算法(1)、(2)用于路口推断质量的评估,算法(3)、(4)用于道路生成质量的评估.
4.5 实验效果
本文基于上述真实非机动车骑行轨迹数据、实验环境和评价标准进行数据质量提升实验,图7(a)为没有进行数据质量提升之前的非机动车骑行轨迹可视化效果图,可以看出原始轨迹存在大量的轨迹漂移等低质量现象.通过本文的非机动车骑行轨迹的数据质量提升方法对其进行数据质量提升后得到的效果图来看,轨迹质量得到了显著提升,如图7(b)所示.
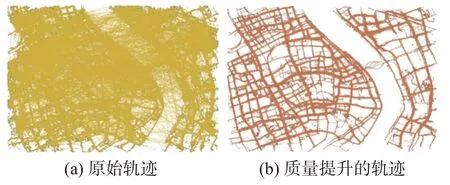
图7 轨迹质量提升例子Fig.7 Example of trajectory quality improving
为了证明本文方法对骑行地图推断相关应用的提升,本文基于公开的骑行路网和现有地图推断应用的预处理方法进行路口发现和路网生成的评估实验.选取的路口发现方法包括CITT 和Huang19,而选取的路网生成方法包括SLC 和Cao09.对于路口发现,所选取的进行量化评价的指标包括精确率、召回率和F1.对于路网生成,选取的进行量化评价的指标包括CMP、AL和AN,同时对实验结果进行了可视化.
4.5.1 基于路口发现的数据质量提升评估
表1 为基于所选定的路口发现方法,并且分别在原始预处理和本文数据质量提升基础上进行路口发现实验的数据结果,其中CITT 和Huang19 对应基于原始预处理方法的结果,CITT+proposed和Huang19+proposed 对应基于本文数据质量提升方法的结果.

表1 路口发现的数据质量提升对比实验结果Tab.1 Quantitative evaluation metrics for intersection finding
表1 所示的实验结果可以看出,采用本文数据质量提升方法得到的轨迹数据进行路口发现在精确率、召回率以及F1上相比原先的预处理方法有一定程度的提升.图8(a)为原始CITT 预处理方法后的路口发现效果图,图8(b)为基于本文数据质量提升方法后使用CITT 方法的路口发现效果图,热门区域内的徘徊轨迹被明显消除,图8(c)为原始Huang19 预处理方法后的路口发现效果图,图8(d)为同一区域的本文数据质量提升后使用Huang19 方法的路口发现效果图,噪声轨迹被大量消除.

图8 路口发现提升对比Fig.8 Example of road generation improving
徘徊轨迹段使得非道路区域内存在着大量不属于道路范围的轨迹,并且在密度、方向等因素上对真实路口的检测特征存在较大影响,使CITT 方法检测到更多的不在道路上的小路口同时对真实路口的检测准确性下降,数据质量提升前后使用Huang 方法进行路口发现的可视化效果相差较大,其原因为Huang19 方法利用道路上的转向点进行聚类,由于徘徊轨迹段的存在,会存在大量的非道路区域转向点,影响路口的识别.
表2 为数据质量提升基于路口发现方法的消融实验,从表2 可知数据质量提升的每一步骤都提升了路口发现的效果,其中徘徊轨迹段的消除对路口发现的影响最大,非道路区域中存在的大量徘徊轨迹段,其方向和速度等特征会影响到路口的准确发现,使得路口位置偏移或得到错误路口,异常轨迹点消除和违章轨迹段消除可以减少道路中间的异常点对路口发现准确率的影响,减少将道路中间位置识别为路口的概率,漂移轨迹段校准可以将轨迹校准到其真实道路上以识别路口真实位置,缺失轨迹段恢复则可以提升轨迹稀疏区域的路口识别效果.
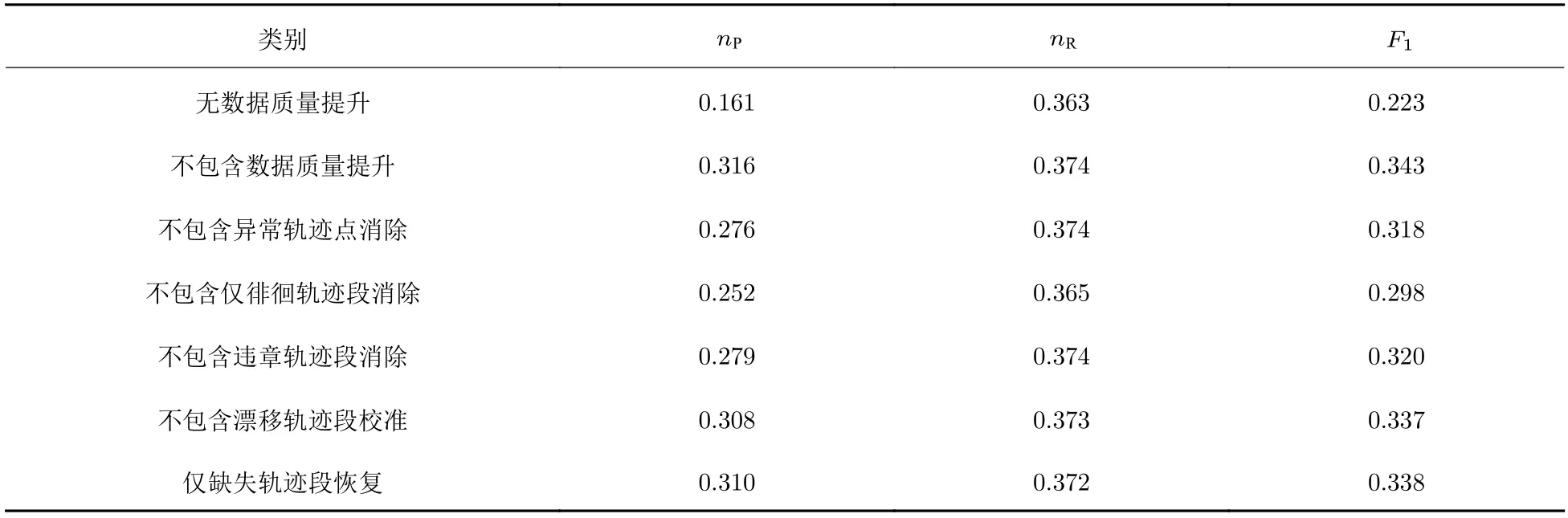
表2 路口发现的数据质量提升消融实验结果Tab.2 Ablation experiment for intersection finding
4.5.2 基于路网生成的数据质量提升评估
表3 为基于选定的道路生成方法,并且分别在原始预处理和本文数据质量提升基础上进行道路生成实验的数据结果,其中SLC 和Cao09 对应基于原始预处理方法的道路生成结果,SLC+proposed和Cao09+proposed 对应基于本文数据质量提升方法的道路生成结果.

表3 道路生成的数据质量提升对比实验结果Tab.3 Quantitative evaluation results of road generation
从表3 所示的实验结果可以看出,采用本文数据质量提升方法的数据进行道路生成时在CMP、AL、AN等量化指标上都有着较为显著的提升.图9(a)为原始的SLC 预处理后的道路生成效果图,如图9(b)所示为本文数据质量提升后的使用SLC 方法进行道路生成的效果图,生成的路网缺失情况减少且热门区域内的徘徊轨迹段不影响路网生成,如图9(c)所示为原始的Cao09 预处理后的道路生成效果图,如图9(d)所示为本文数据质量提升后使用Cao09 方法进行道路生成的效果,所生成的路网冗余情况明显减少.
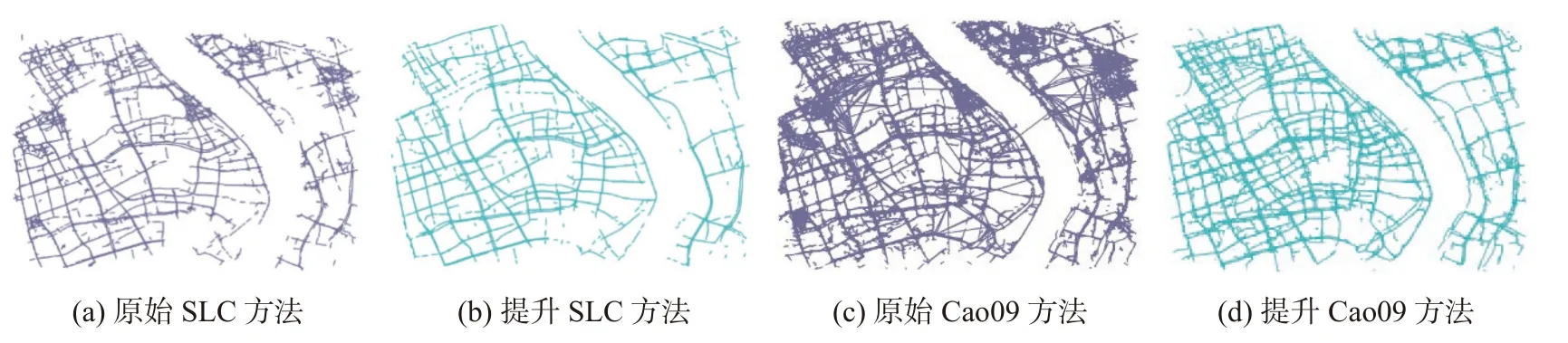
图9 道路生成提升对比Fig.9 Comparison of road generation improving
异常轨迹段使得原始轨迹数据中存在大量不适合用于道路生成的轨迹,它们或者不在道路范围内,或者产生了错误的道路连接信息.漂移轨迹段和缺失轨迹段则使得道路缺失了连接信息,无法完成道路的生成,从而本文所提出的数据质量提升方法可以有效提升道路生成的效果.
表4 为道路生成的数据质量提升消融实验结果,其中Step1 为异常轨迹点的消除,Step2 为徘徊轨迹段的消除,Step3 为违章轨迹段的消除,Step4 为漂移轨迹段的校准,Step5 为缺失轨迹段的恢复,表4 展示了数据质量提升方法的不同步骤在道路生成的3 个评价指标中都得到了提升.其中徘徊轨迹段的消除和违章轨迹段消除对道路生成的影响最大,徘徊轨迹段的消除可以减少非道路区域中的大量徘徊轨迹,违章轨迹段的消除则可以减少道路区域的逆行轨迹和大量非骑行区域的轨迹,这些轨迹质量提升步骤最终减少了错误道路的生成.异常轨迹点的消除可以减少道路上的转向异常点和距离异常点.漂移轨迹段校准步骤可以使得轨迹校准到其正确道路上,缺失轨迹恢复步骤可以恢复信号薄弱区的轨迹,能有效提升道路生成应用的效果.

表4 道路生成的数据质量提升消融实验结果Tab.4 Ablation experiment for road generation
5 结 论
针对在骑行地图推断的应用中非机动车骑行轨迹数据存在的大量异常以及定位信息缺失的情况,本文提出了一种面向骑行地图推断的轨迹数据质量提升方法,分别包括GeoHash 网格索引构建、异常轨迹点的消除、徘徊轨迹段的消除、违章轨迹段的消除、漂移轨迹段的校准以及缺失轨迹段的恢复.基于真实的轨迹数据的实验结果表明,本文所提出的方法在基于非机动车骑行轨迹的路口发现和道路生成中对现有方法有着较大的提升效果.考虑到不同场景下的骑行地图推断所需骑行轨迹与其对应的业务相关性较强,在不同应用上的数据要求存在差异,未来拟考虑增加相关信息,基于不同骑行地图应用制定针对性的数据质量提升方法.
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11
计算机应用(2022年2期)2022-03-01
计算机应用(2021年4期)2021-04-20
计算机应用(2021年1期)2021-01-21
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
数学年刊A辑(中文版)(2019年3期)2019-10-08
现代装饰(2018年5期)2018-05-26
北京航空航天大学学报(2017年6期)2017-11-23
中国三峡(2017年2期)2017-06-09
