
基于双视图特征融合的糖尿病视网膜病变分级
2023-11-29 04:20姜璐璐孙司琦邹海东陆丽娜
华东师范大学学报(自然科学版) 2023年6期
姜璐璐,孙司琦,邹海东,陆丽娜,冯 瑞,
(1.复旦大学 工程与应用技术研究院,上海 200433;2.上海市眼科疾病精准诊疗工程技术研究中心,上海 200080;3.复旦大学 计算机科学技术学院 上海市智能信息处理重点实验室,上海 200433;4.复旦大学 上海市智能视觉计算协同创新中心,上海 200433;5.上海交通大学附属第一人民医院,上海 200080;6.上海市眼病防治中心,上海 200040)
0 引 言
糖尿病视网膜病变(diabetic retinopathy,DR)是糖尿病的重要并发症之一.我国DR 患病率高达15%~ 43%,DR 是成年人致盲的首要原因[1].对DR 患者进行早期筛查、诊断和治疗能有效防止其视觉受损及失明.因此,DR 大规模筛查一直是防盲治盲的重要任务之一.
彩色眼底照相是一种简单且高效的DR 筛查手段.在社区筛查中,常使用双视图拍摄法对同一只眼睛从2 个不同视角进行拍摄,得到以视盘为中心和以黄斑为中心的2 张图像,如图1 所示.由于基层操作人员技术能力有限、老年人瞳孔较小配合度较低等原因,导致从社区筛查采集到的图像往往质量较差,存在周边区域不可读、眼底结构不清晰等问题.而双视图的眼底图像对中既有相同区域,也有不同区域的互补信息,其相互结合能够获得较单视图更为完整的信息,可以有效解决单视角下图像遮挡和视场受限等问题.
随着糖尿病人群的增多和眼科医师的相对缺乏,传统的人工DR 筛查方法已不能有效应对 DR 患病率和致盲率持续增高的双重挑战.近年来随着人工智能(artificial intelligence,AI)的飞速发展,基于彩色眼底图像的AI 辅助诊断算法在DR 筛查中展现出了良好的灵敏度和特异度,不仅缓解了眼科医师和阅片医师的负担,也在一定程度上弥补了眼科医疗资源分布不均的不足.
然而,现有的DR 分级算法普遍存在两个问题: 第一,由于眼底病灶在图中占比率极小,普通的DR 分级模型使用图像级标签进行训练,准确度低且诊断结果可解释性差;第二,目前大多数模型基于单张图像训练,不能有效利用彩色眼底照相中多个视图的信息.
针对以上问题,本文提出了一种基于双视图特征融合的DR 分级算法: 首先,将自注意力机制引入DR 分级,以减小图中背景无关特征的影响,同时增强重要特征对分类结果的影响;其次,提出了一种跨视图注意力模块,挖掘双视图图像对之间的语义联系,提高DR 分级的准确性.
1 相关工作
1.1 双视图融合技术
在基于医学影像进行诊断与疾病分级时,医师通常会综合多个视角拍摄的影像作出更加可靠的决策.一般而言,双视图融合技术可以分为数据层融合、特征层融合和决策层融合这3 种类型.其中,特征层融合即对原始数据进行特征提取后,在特征级别进行融合.目前,已有大量研究通过构建卷积神经网络(convolutional neural network,CNN)进行双视图医学影像分析,这些方法可以分为全局特征融合方法和区域特征融合方法这两类[2].
(1)全局特征融合方法是指融合各视图CNN 分支全局池化后的特征.以乳腺X 线摄像为例,基于矢状面的CC(craniocaudal)视图和中侧面的MLO(mediolateral oblique)视图,Wu 等[3]讨论了在单一网络中组合各视图卷积分支的多种方法,从而得到使乳腺癌分类准确率最高的组合方法.CT(computed tomography)肺部影像中也有类似应用,如Wang 等[4]提出了一种双视图CNN,用于从CT 图像中的轴向、冠状面和矢状面视图分割肺结节.然而,全局特征融合的方法不能关注到图像的细节特征,也忽视了视图之间的潜在联系.
(2)区域特征融合方法是将图像分成不同区域,挖掘不同区域之间的联系.Wang 等[5]提出了一种基于区域的3 步方法: 第一步,从乳腺X 线摄像的每个视图中提取大量感兴趣区域(region of interest,ROI);第二步,使用基于注意力驱动的CNN 从每个ROI 中提取单视图的特征;第三步,通过一个基于长短期记忆网络(long short-term memory,LSTM)的融合模型将各视图的特征与其他临床特征相结合.然而,区域特征融合方法的局限性在于需要对图像划分区域并进行图像配准,配准的精度直接影响融合效果.
为避免上述问题的出现,本文提出了双视图特征融合方法: 无须图像配准,在模型卷积部分的中间层融合双视图特征,挖掘视图间的语义联系,从而提高模型性能.
1.2 注意力机制
近年来,注意力机制广泛应用于计算机视觉领域的研究,其形式与人类的视觉注意力相似.人类视觉通过快速浏览图像的全局信息,且关注图像中的重要区域并忽略不相关的部分,从而获取更多细节信息.
在医学图像分析领域,注意力机制的重要性更加直观.医学诊断的重点是观察小的局部异常区域,而大部分正常图像部分则不那么重要.特别地,注意力机制在DR 辅助诊断算法中有着大量的应用.Wang 等[6]提出了一种Zoom-in 网络,可以同时进行DR 分级和生成病变区域的注意力图,该网络由3 个部分组成: 用于提取特征并输出诊断结果的主干网络、用图像级别的监督学习生成注意力图的注意力网络,以及模拟临床医师检查时放大操作的检查网络.Lin 等[7]提出的基于抗噪声检测和基于注意力融合的框架,可以进行5 类DR 分级: 首先,利用CNN 提取特征,将特征输入到中心样本检测器中以生成病变图;然后,把病变图和原始图像送入所提出的注意力融合网络.该网络可以学习原始图像和病变图的权重,减少了无关信息的影响.Zhao 等[8]提出用具有注意力机制的双线性注意力网络进行DR 分级: 首先,将ResNet 中提取的特征输入注意力网络,可更加关注到决定分级的关键性区域;然后,采用双线性策略训练两个注意力网络,并进行更细粒度的分类.
自注意力机制在Tansformer[9]中被提出,是注意力机制的改进与优化,并在自然语言处理领域迅速得以进展.2018 年,Wang 等[10]提出了一种新型Non-local 网络,将自注意力机制首次引入计算机视觉领域,在视频理解和目标检测任务上取得了卓越的效果.最近,各种深度自注意力网络(视觉Transformer)[11-13]的出现,更展现了自注意力机制的巨大潜力.
值得注意的是,在以上方法中,注意力图是从单视图中推断出来,不能应用于双视图眼底图像的DR 分级场景中.而本文提出的跨视图注意力机制是结合应用场景对自注意力机制的一种创新性改进,能够使模型更适应下游任务.
2 算法介绍
2.1 模型架构
本文提出的基于双视图特征融合的DR 分级模型架构如图2 所示,其由3 个主要部分组成: 特征提取部分、特征融合部分和特征分类部分.图2 中,C 是concatenation 运算,S1,S2为输出特征.

图2 模型架构Fig.2 Model framework
(1)特征提取部分: 主干网络从成对的眼底图像中提取特征表示.在本文研究中,为节省计算资源,提取眼底图像对的特征使用了共享的主干网络,采用去除完全连接层的ResNets[14]作为主干网络,并加载模型在ImageNet 上预先训练好的参数.
(2)特征融合部分: 首先,单视图经过自注意力模块过滤掉单张图像内的无关信息,提取重要信息,同时跨视图注意力则捕获所提取的图像对特征表示的像素之间的空间相关性;之后,将增强后的特征全局池化进行拼接.
(3)特征分类部分: 使用全连接层得到DR 分级结果.
给定眼底图像对{I1,I2},I1和I2分别表示眼底图像对视图1 和视图2 的图像.I1和I2经过主干网络后,提取的特征分别为F1和F2,且I1,I2RH×W×3,F1,F2Rh×w×c,其中,H和W分别表示输入图像对的高度和宽度,h、w、c分别是被提取特征的高度、宽度和通道数.F1和F2经过多视图特征融合模块后的特征图为S1和S2,特征通道数为c1; 经过全局池化和拼接后的通道数为c2.
2.2 双视图特征融合
针对眼底病灶微小、普通的DR 分级模型准确度低等问题,本文将自注意力机制引入模型,以降低图像的噪声影响,同时增强病灶细节特征的学习;同时针对双视图眼底图像对存在互补的关系,提出了一种跨视图注意力模块,挖掘双视图图像对之间的语义联系,以提高DR 分级的准确性.
2.2.1 自注意力模块
图3 展示了针对单视图的自注意力(self-attention,SA)模块细节,其中,reshape 为重塑操作,用于改变数组形状.给定视图1 和视图2 利用主干网络提取的特征F1和F2,首先,将每个视图的特征转换为查询(query,q)特征、键(key,k)特征和值(value,v)特征.F1和F2通过1 × 1 卷积变换后的查询特征、键特征、值特征分别为F1q、F1k、F1v和F2q、F2k、F2v,其中,F1q,F1k,F2q,F2kRh×w×c′,F1v,F2vRh×w×c′′,c′和c′′代表特征的通道数,且c′c′′.相应公式为

图3 针对单视图的自注意力模块Fig.3 Self-attention module for single view fundus images
其中,linear 代表参数为θ的1 × 1 卷积.
然后,将F1q和F1k大小变换到 Rh×w×c′,并通过计算,再使用softmax 函数归一化后得到视图1 空间注意力图F1_Att. 当用于多标签分类问题时,使用sigmoid 函数.同理可以得到F2_Att.相应公式为
将F1v大小变换到 Rh×w×c′′,将F1v和F1_Att做矩阵乘法,并将其大小变换到 Rh×w×c.
最后,把得到的F1_self乘上参数α并和原矩阵F1相加,得到经过自注意力机制的最终结果.视图2 同理.相应公式为
其中,α1和α2是可学习的参数,初始化为0,并在训练中不断优化.最终得到的和是空间注意力图与原特征图的加权融合.
经过自注意力模块后的视图特征具有单视图的全局上下文信息,并根据注意力有侧重性地聚合上下文,增强了眼底病灶特征的学习.
2.2.2 跨视图注意力模块
受跨模态特征融合中的跨模态注意力机制的启发,本文提出了跨视图注意力(cross-attention,CA)模块.图4 展示了针对双视图的跨视图注意力模块细节.此模块中,将视图1 与视图2 的特征分别变换为查询(query)特征、键(key)特征和值(value)特征的步骤与自注意力模块一致,不再赘述.

图4 针对双视图的跨视图注意力模块Fig.4 Cross-attention module for dual-view fundus images
相互引导的双向关系捕捉了眼底图像对中每个位置之间的重要性.以F1→2为例,每一行表示视图1 的一个像素点位置与视图2 所有像素位置之间的关系权重,通过与视图2 的特征F2v矩阵相乘,大小变换后得到由视图1 引导的视图2 加权信息F2_cross,该特征将更多地倾向于关注视图2 中与视图1 相关的特征信息.同理,可以得到由视图2 引导的视图1 加权信息F1_cross,该特征重点挖掘视图1 中与视图2 相关的特征关系.相应公式为
将视图1 得到的注意力特征与跨视图注意力特征进行拼接,拼接后的特征既有视图1 内部的重点信息,也融合了与视图2 相关的特征信息.利用1 × 1 卷积层将连接的特征转换为输出特征S1.同理可得到S2.相应公式为
其中,S1,S2Rh×w×c1.
3 实验结果与分析
3.1 实验基础设置
本文采用ResNet-18、ResNet-34、ResNet-50 和ResNet-101 作为主干网络的特征提取器,参数从ImageNet 预训练中初始化.为了适应不同采集相机造成的不同图像分辨率,首先将所有眼底图像的尺寸调整到(512 × 512)像素.为了进行训练,从调整后的图像中随机裁剪(448 × 448)像素大小的块,测试时使用中心裁剪.本文使用Pytorch[15]框架,采用SGD(stochastic gradient descent)随机梯度优化器,使用交叉熵损失函数;采用poly 策略动态调整学习率,初始学习率设置为0.007,动量因子为0.9,迭代次数为50 次.
3.2 数据集介绍
在本文自建的双视图数据集DFiD 和公开的数据集DeepDR[16]上,采用五折交叉验证法进行了实验验证.数据集DFiD 有3 212 对共6 424 张双视图眼底图像;数据集DeepDR 包含了400 对共800 张双视图眼底图像.数据集的分布如表1 所示,且采用DR 五级标注: DR-0 级表示无DR;DR-1 级表示轻度非增生型DR;DR-2 级表示中度非增生型DR;DR-3 级表示重度非增生型DR;DR-4 级表示增生型DR.
3.3 评价指标
采用二次加权kappa 系数、调和平均值(F1)和ROC(receiver operating characteristic)曲线下面积(area under curve,AUC)作为评价指标.二次加权 kappa 可以表示有序多分类问题中不同评估者的评估结果的一致性,它对分级的差异进行惩罚,惩罚幅度与预测值与真实值之间距离的平方相关.F1值是精确度和敏感度的调和平均值.相应公式为
式(14)—(16)中:P为精确度(precision),即PPV(positive predictive value),阳性预测值,表示真阳性样本在所有预测阳性样本中的比例;RTP真阳性率(true positive rate,TPR)又称敏感度(sensitivity),表示正确识别的阳性比例;NTP表示真阳性(true positive,TP)样本的数量;NFP表示假阳性(false positive,FP)样本的数量;NFN表示假阴性(false negative,FN)样本的数量.
3.4 不同主干网络与融合策略的实验对比
本文在自建的双视图眼底图像数据集DFiD 上进行了对比实验,分别对比了不同主干网络和不同特征融合策略的结果,其中,用于对比的融合策略是全局特征融合方法.实验结果如表2 所示.
由表2 的结果可知,使用更深的主干网络作为特征提取器可以获得更好的分类性能.同样,在使用本文提出的特征融合方式的情况下,使用ResNet-101 为主干网络与使用ResNet-18 的主干网络的结果相比,二次加权kappa、F1、AUC 分别提高了4.9%、2.4%和2.6%.
在使用相同的主干网络的情况下,本文提出的特征融合策略相比于全局特征融合方法,其结果都更优越;在使用最优的特征提取器ResNet101 的情况下,本文提出的融合策略比全局特征融合方法的二次加权kappa、F1、AUC 分别提高了6.1%、4.2%和3.0%.这证明了本文提出的双视图眼底图像特征方法能够显著地提高分类准确性.
3.5 与公开方法的对比
本文选取两种公开的与本文方法类似的双视图眼底图像特征融合算法同本文方法进行了实验对比,实验结果如表3 所示.其中,AUBNet(attention-based unilateral and bilateral feature weighting and fusion network)[17]是一种基于注意力的单侧和双侧特征加权和融合网络,由特征提取模块、特征融合模块和分类模块组成,利用特征提取模块进行两级特征加权和融合来获得双眼的特征表征,最后利用分类模块进行多标签分类;DCNet(dense correlation network)[18]由主干神经网络、空间相关模块和分类器组成,空间相关模块提取眼底图像对特征之间的密集相关性,并融合相关的特征表示.
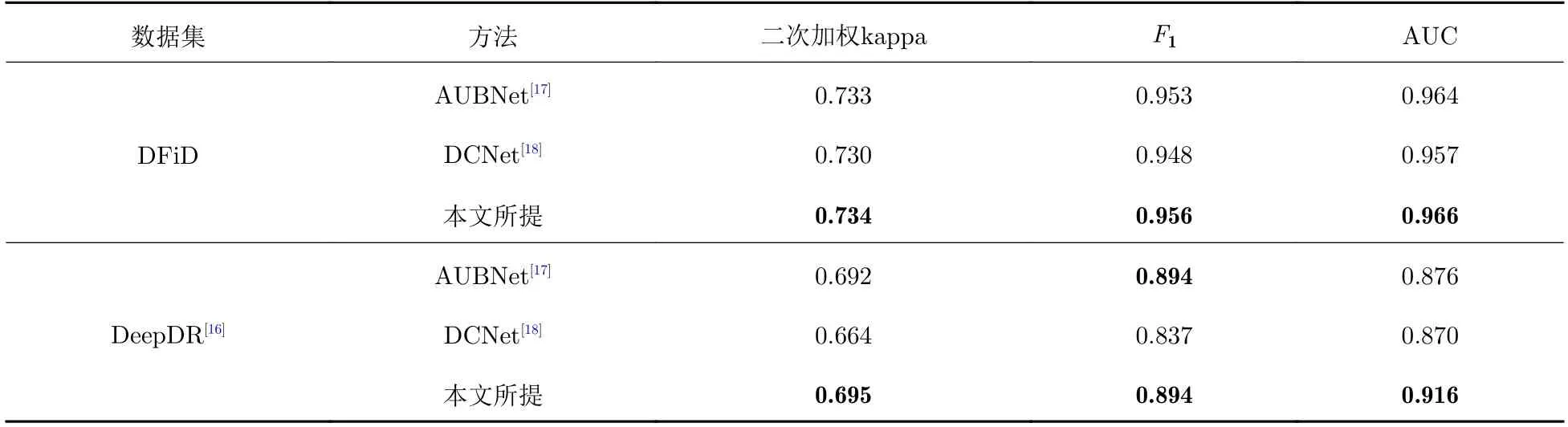
表3 与公开方法的对比Tab.3 Comparison results with public methods
由表3 的结果可以看到,在数据集DFiD 上,本文提出的方法各项指标都取得了最优表现;在数据集DeepDR 上,本文提出方法的二次加权kappa 和AUC 值都取得了最优表现,F1值达到了与AUBNet的F1值相等.由实验结果可知,本文提出的方法是十分优秀的,不仅在内部数据集上有效,在完全公开的数据集上也表现优异.这证明本文提出的双视图特征融合方法能够有效地挖掘视图之间的相关性.
3.6 消融实验
为了验证所设计的模块对提高分类性能的有效性,本文在以ResNet-101 为主干网络的情况下,分别加入自注意力(SA)模块和跨视图注意力(CA)模块.用于对比的网络结构包括ResNet-101 主干网络(提取特征后直接拼接)、加入SA 模块的网络、加入CA 模块的网络,以及加入SA 模块和CA 模块的网络.实验结果如表4 所示.

表4 数据集DFiD 上的消融实验结果Tab.4 Ablation results on DFiD dataset
表4 的实验结果表明,SA 模块和CA 模块都能有效地提高DR 分级准确性.自注意力能够关注到单视图中关键病灶部位,而跨视图注意力能够通过双视图的关联更加可靠且全面地挖掘病灶特征.
此外,本文可视化了测试数据集DFiD 中的样例,结果如图5 所示.图5 是使用Grad-CAM(gradient-weighted class activation mapping)[19]得到的可视化结果.此样例的真实结果为DR-2 级.从图5(a)和图5(b)所示的原始图像对来看,图5(a)所示的图像1 图像清晰,可以明显看到眼底病灶;而图5(b)所示的图像2 图像质量较差,几乎看不清细节.在实际应用中也常会出现这种情况,即如果双视图中有一方图像质量较差,对最终的分类结果并没有帮助,甚至会引入噪声.图5(c)显示了模型不能准确地关注到图像显著区域,特征响应范围过大.图5(d)加入SA 模块和CA 模块后能够消除背景以及噪声信息的干扰,进一步细化了注意力区域,准确定位到了病灶区域.实验结果和可视化结果都证明了本文提出的特征融合方法的有效性.

图5 可视化结果Fig.5 Visualization results
4 总结
本文提出了一种基于双视图特征融合的DR 分级算法,并在自建的数据集DFiD 和公开的数据集DeepDR上进行了实验.本文算法主要包括特征提取、特征融合与特征分类,其中特征融合部分,引入了自注意力机制挖掘单视图病灶区域的上下文信息,并设计了融合双视图特征的跨视图注意力模块.实验结果表明,本文所提出的各模块可有效地提高DR 的分类性能.最后采用 Grad-CAM 方法对本文模型进行了可视化解释,为模型推理提供了可见的预测依据.
在后续研究工作中可部署模型到移动端和PC 端,搭建眼底图像检测系统,让用户在完成眼底照相后,能快速地得到初步筛查的结论,以缓解基层医院缺乏眼科医师的难题.
猜你喜欢
军事文摘(2024年2期)2024-01-10
小雪花·成长指南(2022年1期)2022-04-09
广东教育·高中(2022年1期)2022-03-16
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
传媒评论(2017年3期)2017-06-13
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
第二课堂(课外活动版)(2016年2期)2016-10-21
新课程研究(2016年21期)2016-02-28
