
环境感知的自适应深度强化学习路由算法
2023-12-04 11:12侯诗琪
计算机工程与设计 2023年11期
李 婧,侯诗琪
(上海电力大学 计算机科学与技术学院,上海 201306)
0 引 言
路由选择是网络数据传输的关键技术[1],优化路由选择协议有助于提升网络服务质量。在大流量频繁的传输场景中,网络负载的波动性对传统路由选择协议提出了新挑战[2]。传统路由协议基于启发式规则或基于数据驱动。基于启发式规则的传统路由选择协议,例如开放最短路径优先协议(open shortest path first,OSPF)不能根据传输节点和链路的状态动态调整路由策略,并从历史决策中习得经验,避免遇到类似场景时再次做出不当决策。基于数据驱动的协议包括基于深度学习的协议和基于强化学习(rei-nforcement learning,RL)的协议。前者训练成本和部署成本高,在负载大幅波动的环境中无法一如既往地保障网络吞吐量;后者未能根据负载波动自适应调整参数,且广泛使用简单的ε-greedy策略,在训练初期,动作探索具有一定盲目性[3],波动的负载不仅延长了训练时间,而且使训练初期的网络吞吐量很低。此外,现有模型经验回放效率不高,很多优质经验未被采样就被抛弃,模型收敛速度仍有提升空间[4]。
为应对上述挑战,提出了基于环境感知的自适应深度强化学习路由算法,利用平均损失函数值调节探索和利用的程度,采用有限度探索和优先经验回放机制加速训练。仿真结果表明,该算法可保障并提升模型相对收敛前后的网络吞吐量,并显著缩短训练时间。
1 相关工作
路由选择可看作一类序列决策任务。对此类问题,比起基于深度学习的路由选择算法,强化学习更关注动作的长期收益,在与环境的交互中智能体可学得更优策略。
Boyan最先利用强化学习优化路由选择并提出了Q-routing[5],旨在为数据分组的传输选择时延最短的路径以避免拥塞。Daniel等提出了基于Q-routing和启发式规则相结合的拥塞感知路由算法QCAR[6],可感知网络环境变化动态调整下一跳选择,通过自适应避免拥塞,提高数据分组传输率,缩短端到端延迟。但模型对拥塞的判断过于依赖启发式规则。Kavalerov等提出了基于模糊逻辑的FQLRP[7],根据每个节点的剩余能量以及路由过程中一组节点的能量分布,决定下一跳。黄庆东等提出了低时延全回波Q路由算法AQFE-M[8],使用双曲正切算子根据不同网络情况调节学习率,减少了数据平均递交时间,降低路由间的振荡,提高了数据分组的投递率。邵天竺等提出一种路由抖动抑制的智能路由选择算法FSR[9],在提升转发性能的同时,缩短路由收敛时间,提升网络整体转发性能。沙鑫磊等提出一种双学习率自适应的Q路由算法DALRQ-routing[10],可根据网络延迟调整学习率,减少轮询操作造成的延迟抖动,加速算法收敛,提升网络稳定性。
尽管上述基于Q-routing的各类改进算法在提升网络性能和模型性能方面均取得了重要成果,但在网络优化问题中,智能体的动作空间和状态空间往往具有连续性,迫使Q表急剧增大,一方面,查表操作严重影响算法性能,另一方面,对Q表的存储和查找任务也消耗着网络设备宝贵的内存和计算资源。
以神经拟合代替Q表更新为核心思想的深度强化学习(deep q network,DQN)[11]为上述问题提供了解决方案。Jalil等提出了基于深度强化学习和优先经验回放[12](perio-rity experience replay,PER)的路由选择DQR[13],其奖励函数可对时延和吞吐量等服务质量(quality of service,QoS)指标进行优化,降低延迟的同时最大化带宽。高飞飞等提出了基于集中式部署的SDMT-DQN和DOMT-DQN[14],旨在提升数据抵达率,降低拥塞概率。周鹏等使用部分可观察马尔可夫决策模型对环境建模,把模拟退火算法的思想引入贪心函数ε。可实现网络资源的合理分发[15]。曹茜等提出一种基于高奖励值和时序差分误差的优先经验回放算法HVPER[16],一定程度上提升了模型训练效率,加快了模型相对收敛速度。张宇超等提出了基于模型融合的深度强化学习多最优路由路由通用方案[17],增加了路由策略灵活性。
基于DQN及其各类改进算法解决了Q-routing的瓶颈问题,但存在的共性问题是智能体在探索阶段网络性能较差,未能权衡好探索和利用的关系;在负载变化频繁的网络环境中,模型自适应性还有待提高。
2 问题描述
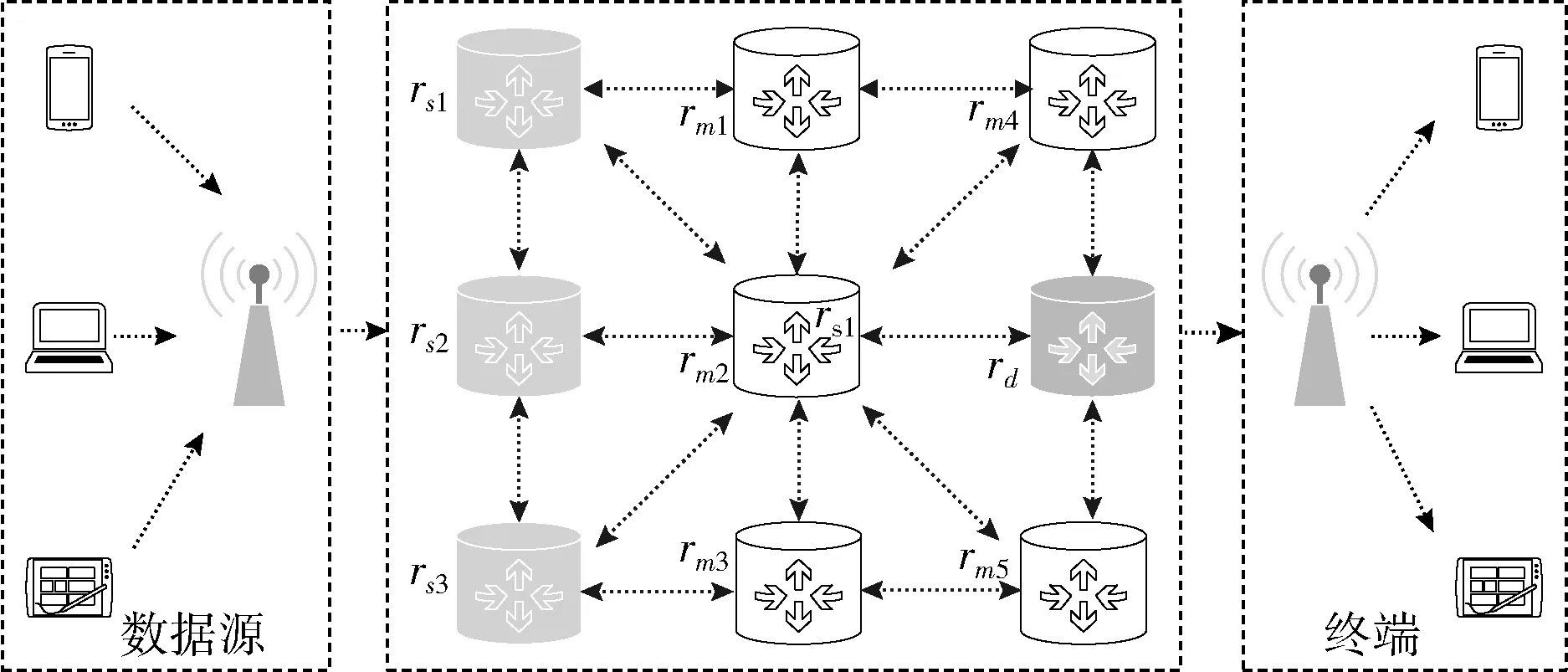
图1 网状网络拓扑结构
=Ns+Nm+Nd
(1)
该拓扑结构可表示为有向图G=(V,E ),V表各个路由器结点,E代表各路由器的连接关系,E满足E={(i,j)|(i,j)∈V×V,i≠j}。
网络架构采用集中式控制的软件定义网络(software defined networking,SDN)[18],包括数据层、控制层、应用层。图1所示的路由器位于数据层,仅执行转发操作。控制层提供应用程序和数据层之间的通信接口,路由策略计算、转发规则更新等依赖控制层的控制器。每时隙控制器与路由器进行通信收集传输任务信息并存储至任务队列QT。假设每个时隙内,数据分组可从一个路由器传输到下一个路由器或是被丢弃,任务队列中所有待处理任务均可被处理。
对于从源路由器rs转发的数据分组,需为其生成一条转发路径,通过目的路由器rd送达终端,并使网络吞吐量最大。
3 DQNPES详细设计
DQNPES(deep q network with priority experience replay and self-adaptability)总体架构如图2所示,采用了深度强化学习(deep q network,DQN)[19]思想。DQNPES包括两个实体:一是环境实体;二是智能体(agent)。

图2 DQNPES架构
3.1 环 境
路由选择问题具有马尔可夫性[20]。控制器与路由器通信获取当前网络状态,并计算下一跳,路由器根据控制器的策略转发分组,网络状态随之改变。路由选择问题的当前状态是过去状态的汇总。
由于网络拓扑结构动态变化,且各路由器并行转发分组,智能体所观测的状态是片面的。针对此问题,使用部分可观测马尔可夫决策模型构建智能体(partially observable Markov decision processes,POMDP)[21]。POMDP可表示为M=(S,A,P,R)。S为网络状态集合,为无限集,S={s0,s1,…,st,…};A为当前节点合法下一跳集合,为有限集,A={a0,a1,…,an};P为状态转移概率函数,P(s′|s,a) 表示在状态s下执行动作a转移至s′的概率。R为路由器执行转发操作后网络环境的奖励反馈。R(s,a,s′) 表示状态s下执行动作a到达状态s′时的奖励。
3.1.1 状态
各路由器缓冲区情况以及数据分组状态均会影响智能体决策。每时刻的状态st表示为st=[Dt,Lt],其中Dt=[D1,t,D1,t,…,D],Di,t表示t时刻第i个路由器缓冲区的数据总量;Lt表示每时刻数据分组的位置,是长度为的one-hot编码变体,Lt=[L1,t,L2,t,…,L],Li,t∈{-1,0,1}。数据分组不可被分割,因此每时刻有且仅有一个Li,t为1或-1。Li,t为1,表示t时刻数据分组在第i个路由器中;Li,t为-1,表示t时刻数据分组在第i个路由器被丢弃。
3.1.2 动作
对于路由选择问题,动作是指从分组当前所在路由器选择一个路由器ri作为下一跳。
3.1.3 状态转移概率
POMDP的求解目标是确定策略π(s),即为每个可能的状态s指定动作。由于动作选择具有不确定性,用状态转移概率P(s′|s,a) 来描述。状态转移概率与当前状态和动作选择策略有关。
3.1.4 奖励函数
为寻找最优策略,需定义每时刻智能体可从环境获得的奖励R(s,a,s′)。为减少丢包,降低拥塞程度,提高吞吐量,R(s,a,s′) 包含因数据分组被丢弃的惩罚性奖励以及被正常转发时的即时奖励,如式(2)所示。
智能体在以下情况获得惩罚性奖励,且任务传输终止:①当下一跳路由器的缓冲区无法存储数据分组时,路由器负载过大;②当下一跳不是当前节点的邻居节点,动作非法;
智能体在以下情况获得即时奖励:①数据分组每被转发一次需要消耗资源,智能体获得负向奖励Rhop;②当下一跳是目的路由器,智能体获得正向奖励Rarrive。设置正向奖励有助于加速模型收敛
(2)
Ro=Rhop+φRarrive,φ∈{0,1}
(3)
仅用每个时刻的奖励评估策略是片面的。当前状态蕴含了已执行动作产生的影响。因此,最近的奖励应被重视,在未来,这一奖励也应被考虑到。引入Gπ(s)来记录POMDP累计奖励
Gπ(s)=R0+γR1+γ2R2+…+γtRt+…=

(4)
其中,γ为折扣因子,表示当前奖励在未来重要程度,会随时间衰减,γ∈[0,1]。Gπ(s)随动作的随机性而变化,但Gπ(s)的期望值为定值。为评估π(s),引入状态价值函数Vπ(s) 和状态动作价值函数Qπ(s,a) (下文称Q值),定义如下
Vπ(s)=π(Gπ(s))=
∑s′P(s′|s,a)[R(s,a,s′)+γVπ(s′)]
(5)
Qπ(s,a)=∑s′P(s′|s,a)[R(s,a,s′)+γVπ(s′)]
(6)
Vπ(s) 与Qπ(s,a) 相辅相成。Vπ(s) 由从状态s0到达状态st的所有状态动作价值表征,Qπ(s,a),由后续状态st的动作价值表征。通过价值迭代,可求得最优策略π(s)
(7)
3.2 智能体
在对环境建模的基础上,设计了基于值的强化学习框架,即智能体(下称模型)。智能体的两大任务是在线动作决策和离线学习。为加速智能体学习,提升网络吞吐量,本文针对动作决策和离线学习进行了优化。
3.2.1 模型结构
智能体包含两个结构完全一致的神经网络eval_network和target_network。
在动作决策时,eval_network输入层为当前网络状态,输出层为每个动作的Q值,作为智能体下一跳选择的参考。对于每一次决策,智能体将经验以状态转移元组 (st,a,Rt+1,st+1) 的形式存入经验回放池。
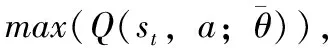
s′t=argtan(st)×2÷π
(8)
(9)
Loss(θ)=[(target_Q-Q(st,at;θ))2]
(10)

3.2.2 动作选择
下一跳的选择基于有限探索机制和改进的自适应ε-greedy机制,ε是权衡动作选择策略的因子。智能体训练初期,广泛的探索可提升获得更优解的概率[3]。但盲目探索不利于提升训练初期的网络吞吐量,影响用户体验。针对这一矛盾,引入了有限度探索机制。动作选择算法如算法1所示。智能体以ε的概率选择具有最大状态价值函数值的动作,以1-ε的概率从当前节点的邻居中优先选择满足缓冲区阈值条件的动作a。若这样的动作不存在,则随机选取当前节点的一个邻居作为下一跳。有限探索为智能体的学习积累了更多优质经验,有助于智能体更快学到良好的策略。
算法1:下一跳选择
输入:网络拓扑G、网络状态s、送达的目的节点dst
输出:下一跳动作a
(1) 从状态s中提取数据分组当前位置i
(2) 随机生成一个0到1的数m
(3)ifm≤εdo

(5)returna
(6)else:
(7)forneighborinneighborsofrido
(8)ifneighbor的缓存大小+分组数据量 <阈值do
(9)a=neighbor
(10)returna
(11)endfor
(12)else:
(13) 从ri的邻居中随机选择一个返回
由于损失函数值可以反映预估Q值和实际Q值的差距,进而反应智能体的学习程度。自适应的ε有利于智能体在与环境交互过程中形成更多有价值的经验。损失函数值较大时,表明智能体尚未学习充分,未能有效应对网络负载变化,这时需要加大探索,利用有限探索机制积累优质经验;当损失函数值较小时,表明神经网络已相对收敛,智能体已能应对网络负载变化,这时依据当前行为策略挑选出来的大多数动作对于最优策略的学习是有利的,智能体对环境的探索程度可适当降低。ε更新方法如式(11)。在训练初期,为智能体设置一个较小的初值ε0,并保持一段时间(即Tstate1),随后,ε随着智能体多次训练的平均损失函数值更新,若更新过程中ε超过阈值时,将ε重新调整为阈值εmax。
对ε的改进不仅提高了智能体对环境的自适应程度,也降低了智能体对启发式规则的依赖
(11)
3.2.3 优先经验回放

(12)
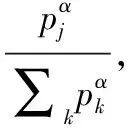
由于有偏采样引入了偏差,为保证有偏采样学到的策略与均匀采样的策略相同,使用重要性抽样权重wj(下称isweight)纠正偏差。考虑到稳定性,使用最大权重值进行归一化。β为退火因子,在学习结束时β将从初始值退火到1,与α共同作用以校正偏差。n为采样数
wj=(n·p(j))-β/maxiwi=
(n·p(j))-β/maxi(n·p(i))-β=
(p(j))-β/maxi(p(i))-β=(p(j)/minip(i))-β
(13)
综上,DQNPES伪代码如算法2所示。在动作决策阶段,控制层为每一个传输任务做出下一跳决策,并把指令分发给响应路由器进行分组转发。并将经验和优先级存入经验回放池。在学习阶段,优先级权重按照经验采样数分段后随机选取,并选取该权重对应的经验,依照式(13)计算重要性抽样权重。
算法2:DQNPES
输入:网络拓扑、网络状态
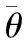
(1) 初始化任务队列,模型参数
(2)forepisode = 1,2,…,Mdo
(3)forT = 1,2,…,50do
(4) 数据源生成数据,并把传送任务添加到队列
(5) 控制器获取各路由器状态
(6)fortask = 1,2,…,N (N为队列任务数目)do
(7) 根据分组送达的目的地选取相应智能体
(8) 获取网络状态,输入到eval_network
(9) eval_network按照算法1选择动作
(10)endfor
(11) 为队列中所有分组执行转发操作
(12) 初始化经验优先级为1或最大优先权重值,并存入经验回放池
(13)ifT %5 ==0do
(14) 随机选取优先级,从经验池中随机选取经验j~p(j)
(15) 依据式 (13) 计算重要性抽样权重isweight
(16) 根据式 (9) 计算target_Q值
(17) 根据式 (10) 计算损失函数,用梯度下降法更新参数
(18) 计算δj=target_Q-Q(st,at;θ) 并更新经验优先级
(19) 根据式 (11) 更新ε
(21)endfor
(22)endfor
4 实验仿真与结果分析
4.1 实验设计
4.1.1 实验环境
仿真环境基于Networkx[22]。假设源路由器和目的路由器可及时将接收到的数据分组转发,缓冲区大小无限制,其余路由器缓冲区设为40 MB。数据源产生的数据分组数目符合泊松分布[23]。每时隙数据源生成的数据总量由概率参数ρ控制。数据源有ρ的概率产生大的数据分组,1-ρ的概率生成较小的数据分组。实验设定部署了不同模型的网络环境在每时隙生成的数据分组数目和数据量保持一致。
DQNPES的神经网络部分采用 Keras实现[24],根据目的路由器的数目,确定需要训练的神经网络个数。每个神经网络输入层、输出层的神经元个数分别是2和。模型神经网络参数一致。
4.1.2 实验模型
为评估算法性能,实验选取以下算法:
OSPF:网络中的各路由器通过泛洪法获取整个区域的拓扑结构,到各节点最优路径通过Dijkstra方法计算。
QCAR[6]:考虑两跳的拥塞状态,采用随机选取不拥挤节点和选取具有最大Q值的节点相结合的方式决定最佳下一跳,将流量分配到多条路径。
DOMT-DQN[14]:算法依照目的节点个数确定神经网络的个数。每个神经网络基于Nature DQN[19](下称DQN)根据目的节点选择对应DQN产生下一跳。
DQNP[12]:在DQN的基础上引入优先经验回放机制。
HVPER[16]:算法中经验回放优先级的定义结合了TD error与奖励,优先考虑具有高奖励值和高时间差分误差的经验。
DQNPE:在DQNP基础上引入自适应ε。
4.1.3 实验思路
(1)为验证加入自适应ε能有效权衡探索和利用,加速训练,将DQNPES与以下模型变体对比:
DQNE:在DQN基础上引入自适应ε。
DQNC:采用线性递增的方式调整ε,更新方式如式(14)所示
(14)
DQN:在整个训练过程中,ε保持不变。
(2)为验证正向经验积累对于网络吞吐量的提升程度,将DQNPES与表1所示的模型变体作对比。

表1 模型变体
(3)为验证有限探索和自适应ε改进共同对网络吞吐量、数据送达率等指标的提升程度,调整ρ大小,比较DQNPES、HVPER、DQN、QCAR、OSPF对上述指标的影响。各算法所在环境ρ保持一致。每时隙数据源生成数据完全相同。
4.2 结果分析
为清晰呈现实验结果,绘图时进行了平滑处理。
(1)图3展示了训练轮次与网络吞吐量、数据送达率、损失函数值、数据分组平均路径长度的关系。根据图3(a)和图3(b),在训练初期,DQNPES使网络吞吐量、数据送达率高于其它算法所在环境,DQNE次之。这验证了引入自适应ε机制的有效性。在训练初期,智能体需要进行大量的探索来尝试更多的选择,以学习更优策略。根据图3(c),DQNPES在达到相对收敛后,平均路径长度略长于其它算法,但对吞吐量的提升显著,这反映了路由选择策略的灵活性,分组沿着负载较小的方向传输,反而可以更快到达。图3(d)反映了各个算法的收敛速度。在自适应ε机制的作用下,DQNPES最先达到相对收敛,DQNE次之,验证了自适应ε机制加速模型收敛方面的有效性。
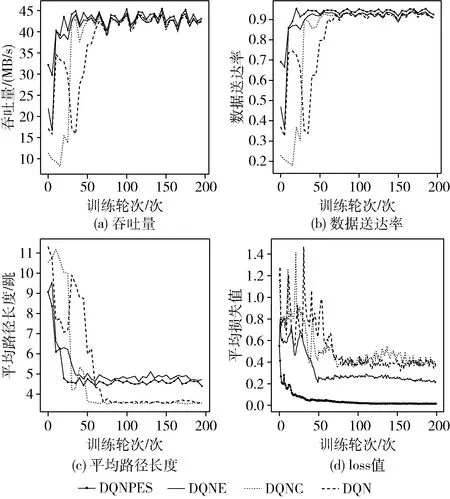
图3 网络性能与训练轮次
(2)正向经验积累对吞吐量提升的验证
根据图4,4个算法使网络吞吐量在训练50轮时就达到了相对稳定的状态。与上一实验中未引入优先经验回放机制的算法相比,优先经验回放机制在提升模型收敛速度方面具有优势。尽管训练初期,DQNPES的表现略逊色于HVPER,由于对动作探索范围有所约束,其波动远小于DQNPE和DQNP,在后期,DQNPES所在环境网络吞吐量和数据送达率最高,验证正向经验的积累有助于提升网络吞吐量。

图4 网络性能比较
(3)算法有效性验证
图5是ρ=0.4时各算法所在环境吞吐量和数据送达率随训练轮次的变化情况。DQNPES使数据送达率,吞吐量均达到了最高,且在训练初期,性能也优于除QCAR之外的算法。在训练后期,DQNPES表现优于其它算法。这验证了引入自适应ε和有限探索机制的深度强化学习算法的有效性。

图5 ρ=0.4时的网络性能与训练轮次关系
表2记录了各算法在训练100轮之后所在环境平均吞吐量和平均数据送达率随ρ变化的情况。当ρ从0.2增加至0.8时,数据源每时隙产生的数据总量递减,各算法平均吞吐量也因此呈递减趋势,但DQNPES的平均吞吐量始终高于其它算法。ρ为0.2时,网络负载总体水平最大,丢包情况最为严重,但DQNPES仍使送达率保持在93%,算法优势最为显著。这验证DQNPES所做改进提高了网络数据传送能力。

表2 ρ与模型
5 结束语
为提升负载变化频繁的传输场景的网络吞吐量,提出一种基于SDN架构的具有环境感知的自适应深度强化学习路由算法DQNPES。与基准算法相比,该算法可根据平均损失动态调整ε-greedy策略,并通过有限度动作探索积累正向经验,避免了网络出现大规模拥塞,结合优先经验回放机制,加速了智能体学习,降低了训练成本。实验验证正向经验的积累对于提升网络吞吐量的有效性。DQNPES可在大流量、负载波动频繁的情况下保障并显著提升从智能体训练初期到相对收敛的网络吞吐量和数据传输率。
猜你喜欢
科教新报(2022年24期)2022-07-08
科教新报(2021年23期)2021-07-21
网络安全和信息化(2018年3期)2018-11-07
大众用电(2018年7期)2018-04-12
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
集装箱化(2016年12期)2017-03-20
电测与仪表(2014年16期)2014-04-22
集装箱化(2014年2期)2014-03-15
计算机工程(2014年6期)2014-02-28
