
基于Hadoop的智能调度云数据中心关键技术探析
2023-12-06 14:26刘宇
电气技术与经济 2023年9期
刘 宇
(国网山西省电力公司忻州供电公司)
0 引言
电力调度系统在整个电力系统内占据着重要地位。在当前电网互联程度持续提升、智能电网建设程度逐步加深的大背景下,电网调度工作的展开难度随之提高。此时,需要落实对电力调度系统的更新,特别是要进一步优化电力计算平台,完成智能电网调度系统的构建,满足现实调度工作需要的强数据存储与计算能力要求。
1 基于Hadoop的智能调度云数据中心的构建需求分析
基于Hadoop的智能调度云数据中心的设计与构建期间,需要着重把握以下几项需求与目标,即有:
第一,实现对现有电力系统IT资源的整合。相应智能调度云计算数据中心的搭建必须要能够对现有的电力系统IT资源实施整合处理,以此促使所有资源均可以得到有效利用。可以搭建起新的数据中心,切实对云计算最基本的点进行满足,按需分配;形成并应用统一调用计算、存储以及服务形式的运行机制。第二,保证数据中心基础设施的高度可靠。使用HA设计处理重要资源,促使基础设施的可靠性水平得到进一步提升。例如,将双机热备冗余配置在核心网络内;针对重要数据库实施HA配置等等。第三,确保网络结构具备可拓展性。保证可以弹性调整数据中心的规模,以此实现对当前以及未来业务增长条件下所产生的更大基础设施扩展需求的切实满足。第四,可以实现海量数据存储以及强大的计算能力。可以实现对来源于在线监测设备、智能电表等多种设备所采集与产生的大量实时性数据信息的有效存储以及在线分析,以此为电网的大规模快速调度以及控制工作的优化展开提供有力支持。
2 基于Hadoop的智能调度云数据中心的总体架构分析
电力调度系统的规模相对较大且分布广泛,实际承担着的调度任务较多,对于实时性的要求也保持在更高水平。同时,大量调度业务的展开均针对本区域内的电网完成,如果在整个系统云内提交所有区域的业务计算,势必会产生极为严重的网络阻塞,无法切实满足实时性要求,也会产生一定的资源浪费问题。就当前电力系统的分级调度而言,其层次性较为明显、清晰,可以此为切入点完成智能电网云计算调度体系的构建,合理协调电力系统资源,提升智能电网调度云计算平台的资源利用率。在此基础上,结合对这种具备较多层次的云平台的应用,促使冗余的数据备份成为现实。基于这样的情况,可以完成三级智能调度云体系结构的搭建,如图1所示。
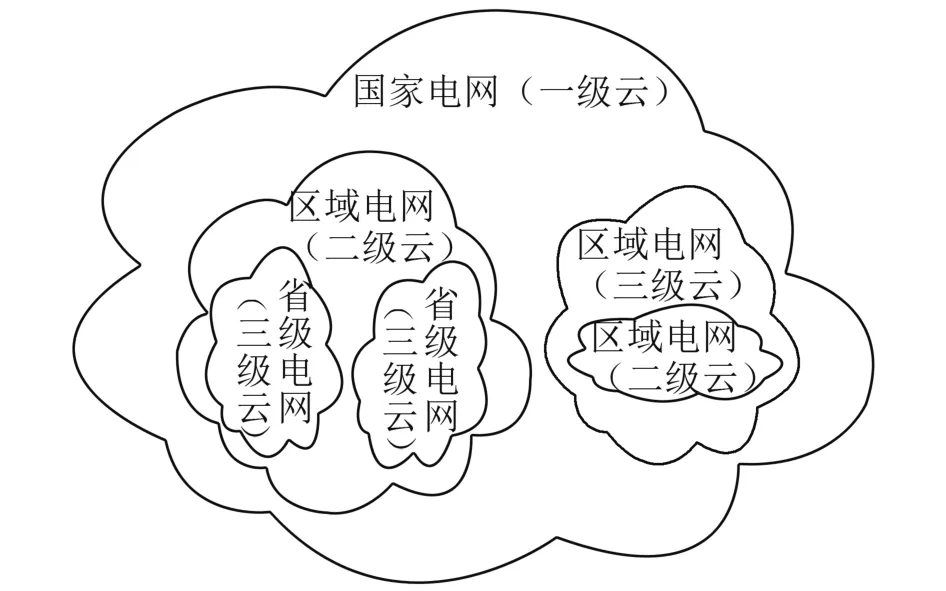
图1 基于云计算的智能调度体系架构图
结合智能电网调度云计算数据中心的构建需求与目标、相关技术与理论支持,完成基于Hadoop的智能调度云数据中心的总体架构的构建,如图2所示。在本研究所设计的基于Hadoop的智能调度云数据中心内,可以进一步细化出应用接口层、高级应用层、平台服务层、基础设施层这几个层次,每一个层次均为上一个层次提供服务[1]。其中,应用接口层主要承担着接入电力系统内部网的任务,同时提供用户认证、访问控制、Web Service等服务;高级应用层主要提供稳态分析、经济评估、网损计算、潮流分析、状态分析、EMS等服务;平台服务层内包含着并行编程模型、云计算测试开发工具等,主要提供数据管理服务,具体而言,可以实现数据维护、版本管理以及日志管理等功能;基础设施层主要可以划分为基础软件以及基础硬件这两部分,在基础软件内包含操作系统、虚拟化管理软件、分布式文件系统、状态监测等,基础硬件内包含大规模计算机集群、海量数据存储系统、高速通信网等等。
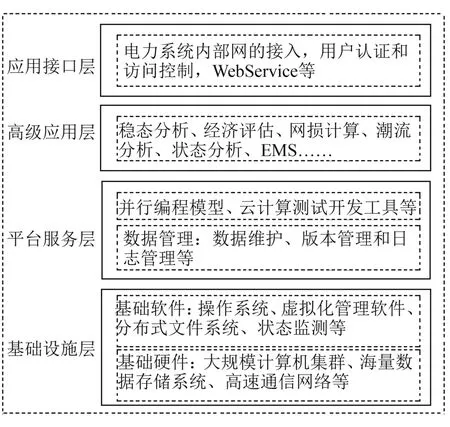
图2 基于Hadoop的智能调度云数据中心的总体系架构图
3 基于Hadoop的智能调度云数据中心的具体结构设计与实现
3.1 网络结构
对比分析多种网络结构,能够了解到BCube网络结构所具备的应用优势更为明显,但是将其引入智能电网调度云计算数据中心内,依然会表现出一定的不足与缺陷,具体有:第一,该网络结构以服务器为中心,主要应用服务器实现执行路由,促使服务器实际所承担着的任务负载大幅度增加,使得server的可用带宽显著下降,网络延迟更为明显[2]。第二,该网络结构实际具备的扩展性偏低,仅仅能够支持4096台服务器。但是,对于智能调度云数据中心而言,其实际包含着上万台甚至是上百万台服务器,无法满足扩展性要求。
基于这样的情况,在本次进行基于Hadoop的智能调度云数据中心的设计与构建期间,围绕上述缺陷对BCube网络结构进行了优化调整,生成PCube网络结构算法,并将其设定为本智能调度云数据中心的网络结构。
在PCube网络结构内,任意一个server外边均对应一个swtich的连接,在swtich的支持下实现对流量的转发,此时流量并不通过server完成处理。基于此,可以将swtich简单理解为server的转发代理。实际上,swtich可以切实参考实际所需要完成的扩展性要求,为1~4个server提供代理服务。对于PCube网络结构而言,也包含在递归网络结构的范畴内,主要由两种设备构成,即商用小型交换机、单口server。单一小的n口swtich与n个swtichp的连接、任意一个swtichp连接单个server,能够构成PCube0;n个PCube0以及n个n-port的swtich共同构成PCube1;n个PCubek-1以及n个n-port的swtich共同构成PCubek。
在构建PCubek期间,需要完成的主要操作步骤如下所示:利用n+1个swtich以及n个server共同构成PCube0;在该层中,直接连接第i个swtich以及第i个server,在k不低于1的条件下,n个PCubek-1能够构成PCubek;利用0至n-1的数字标记n个PCubek-1,利用0至nk-1的数字标记每一个PCubek-1中包含着的swtichp;进行连接处理,在第k层第i个swtich的第j个端口上,连接第j个PCubek-1中的第i个swtichp;在n取值为4、k取值为1的条件下,搭建起的PCube1结构如图3所示。
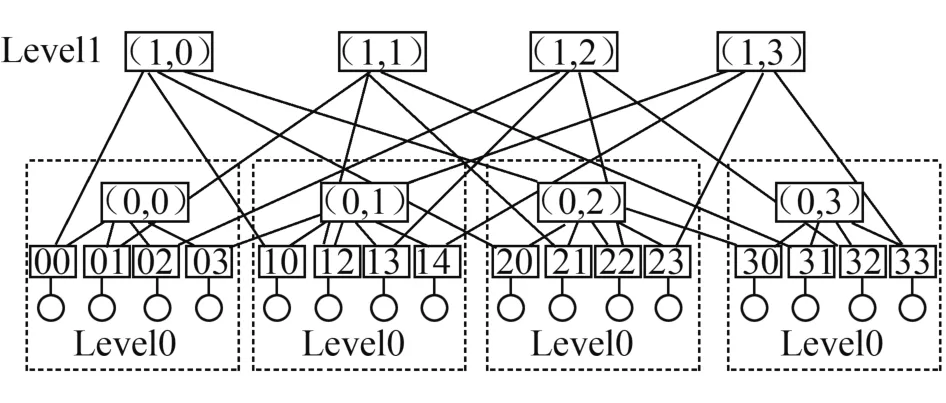
图3 PCube1结构图
3.2 数据存放
(1)任务调度与副本复制集成
在用户层范围内,不同的调度员实际所完成的调度任务不尽相同,由Hadoop集群的Namenode节点统一实现对任务的统一提交;对于Namenode节点而言,其主要依照既定的任务调度策略,在多个不同的Data Node上分发不同的计算任务。计算以及存储任务的执行均由Data Node完成。本地或是其他计算节点为计算任务的展开提供所需要的数据,基于这样的情况,在本地内未存储相应数据时,还要进一步执行数据请求任务,按照设定的副本策略,由Data Node落实对多个副本的存储任务的执行。
(2)CoHadoop副本存放
在文件系统内进行新文件的创设期间,Namenode会迅速在Locator Table内落实表中是否已经纳入了对应文件所具备的Locator值的表项查找,若是发现存在对应文件所具备的Locator值,则迅速在该表项的文件列表内加入相应文件;在其他文件所在的Data Node中,所包含着的存储空间充足的Data Node节点实现对文件数据块的保存。若是发现不存在对应文件所具备的Locator值,则迅速在Locator表内落实一项新记录的创设,应用(Locator,File)的形式;切实参考HDFS默认的存储策略,将相应文件块的三个副本在不同的机架内存储。
(3)基于数据挖掘的数据副本存放
CoHadoop使得原有的数据存储策略发生改变,但是,其单纯能够让应用自行完成对相关文件的确定与选择,随后针对相关文件进行同样的Locator的设定[3]。但是,结合对智能电网调度的现实任务展开情况来看,大量应用需要利用其他数据库相关文件资料、历史数据资料。基于此,应用难以在初始化运行期间对相应文件相关做出决定,此时需要一种方法,依托对Hadoop集群的利用,实现对文件相关情况的智能判断,以此实现对HDFS的存储效率的优化,推动应用运行期间IO的效率性提升。
运用算法扫描数据库落实第一棵FP-树的生成,在此基础上,算法会多次遍历该FP-树并实现对新FP-树的构建。在此过程中,实际所消耗的内存资源以及CPU保持在相对较高的水平。对于条件树TX的项目投标中的所有项,在遍历2次TX的条件下实现条件FP-树TXU{i}的生成;在完成第一次遍历后,可以确定出所有包含在条件模式内的频繁项集;进行项目表头的建立,推动FP-树初始化;结合第二次遍历实现新树的生成。在FP-数组的算法的支持下,能够促使遍历FP-树的次数有所降低,实现对CPU资源的更好节约,使得遍历时间显著缩减。在初始化TX期间,需要让其包含一个新的属性。
在智能调度系统内,可能会使用相同文件中的数据展开对不同调度任务的计算,单一以此任务的执行可以直观理解为一个事件T,调度时所需要的文件设定为A、B、C等,在多次任务的执行后,会生成形式为下表的数据集,结合FP挖掘算法的应用,可以在相应数据集内提炼出文件的相关性,同时给予相关文件以同样的Locator。
3.3 任务调度
(1)Map Reduce
对于Map Reduce而言,其属于一种可以实现海量数据处理的编程模型,在大型集群中能够为对应程序的顺利运行提供有力支持,同时也可以在进行大数据处理期间发挥出理想的容错能力[4]。在Map Reduce的工作期间,主要向大量的机器内分发待处理的海量数据;结合用户的要求,将数据转变为<Key,Value>对并实现保存。实际中,Map Reduce向集群内的所有块服务器分发任务;在本地服务器内对分发的任务实施并行处理;针对获取到的结果展开第一步合并操作;按照一定映射规则,各个块服务器将得到的结果传递至指定机器内,实施合并处理;在指定的块服务器内,获取对应的处理结果。
(2)任务调度算法
在本次基于Hadoop的智能调度云数据中心的设计与构建期间,主要针对公平任务调度算法进行改进,以此为任务调度的实现提供支持。此时,所应用的更新缺额计算方法如下所示:
其中,time Delay代表着任务等待时间;time Used代表着任务运行时间。依托这样的参数选择,能够避免计算时间对已经运行时间很少、等待时间较短的任务,降低缺额最小化问题的发生概率。
进一步应用模拟退火智能算法完成对最优解的获取,更新作业选择策略。使用的已完成作业的总时间计算方法如下式所示:
其中,第j个pool中第i个作业的已运行时间使用t(i,j)表示,i取值为1,2,…,n;j取值为1,2,…,m。在没有作业运行时,已完成作业的总时间为0。
在相同的pool内,作业队列运行时间保持在相对平均的状态。使用下式完成对某一队列已经完成运行作业的平均时间,即有:
目标函数为:
其中,α和β均保持在0~1的范围内。
建立如下的数据模型:
设定当前解为Si=S;设定新产生的解为Si+1;
4 结束语
综上所述,结合智能电网调度云计算数据中心的构建需求与目标、相关技术与理论支持,形成应用接口层、高级应用层、平台服务层、基础设施层这几个层次,以此搭建起基于Hadoop的智能调度云数据中心的总体架构的构建。同时,通过改进网络结构以及任务调度算法,提升智能调度云数据中心的性能水平。
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
制造技术与机床(2019年4期)2019-04-04
测控技术(2018年7期)2018-12-09
电子测试(2018年11期)2018-06-26
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
信息通信技术(2015年6期)2015-12-26
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
