
基于总线的兵棋推演实时数据采集管理设计与实现
2023-12-06 03:00李荣森李志强司光亚
指挥控制与仿真 2023年6期
李荣森,李志强,曹 毅,司光亚
(国防大学联合作战学院,北京 100091)
兵棋推演历史非常久远,从墨子解带为城算起,至今已2 000多年,期间人类战争也经历了不同形态的演变。兵棋推演是现代进行战争模拟和作战方案验证的重要手段,尤其是推演过程中产生的数据,是后续各类分析的基础。Creveld等在文献[1]中回顾了战争发展的历程,从大卫对歌利亚的战斗开始,一直到最新的兵棋推演。文献[2-3]针对数据本身进行了数据质量等分析。文献[4-10]进行了各种基于兵棋推演数据的作战分析,包括火力打击决策分析模型、指令下达特征、作战体系网络模型等。文献[11-13]进行了基于兵棋推演数据的挖掘、聚类、测量等研究。文献[14-17]提出了基于兵棋推演数据的不同作战方案评估方法。文献[18-22]对深度学习在兵棋推演数据分析中的应用进行了研究。文献[23]进行了基于兵棋推演数据的后勤物资储备精确计算,建立了后勤模型和规则算法。文献[24]开放了一个兵棋推演数据集。
可见,兵棋推演数据在各类分析中起着基础支撑的作用,因此必须有可靠的兵棋推演数据采集管理方案,以保证数据的高可用性。目前,美军比较典型的兵棋推演系统有JAS(原JWARS)[25]、JTLS、EADSIM、FLAMES等[26];国内的兵棋推演系统主要有某大型计算机兵棋系统、某大型仿真试验系统、XSIM[27]、墨子等;此外还有商业化的兵棋推演系统如CMANO等。这些系统在底层数据存储方面,JAS采用的是Oracle数据库;JTLS4.0 版本采用的是Oracle数据库,6.0版本更新为PostgreSQL数据库;EADSIM、FLAMES、华如XSIM采用的是本地数据文件方式;CMANO采用的是SQLite数据库;华戍墨子1.0版本采用的是SQLite数据库,新版本采用的是MySQL数据库;某大型计算机兵棋系统采用的是Oracle数据库,某大型仿真试验系统采用的是MongoDB数据库。
由于采用单机版磁盘数据库,原有兵棋推演系统在数据访问方面存在一些问题,对与推演数据相关的各类应用造成了不利影响。
1 原有数据采集管理机制
1.1 原有数据采集管理机制总体结构
原有数据采集管理机制总体结构如图 1所示。推演模型子系统将计算结果输出后,通过通信分发、网盘服务等模块,交由实时数据采集、历史数据采集、事件数据采集分别进行入库。最终的数据存储在单机版HDD磁盘数据库中。后续分析评估系统通过检索实时库、历史库、事件库,提供各类评估结果。
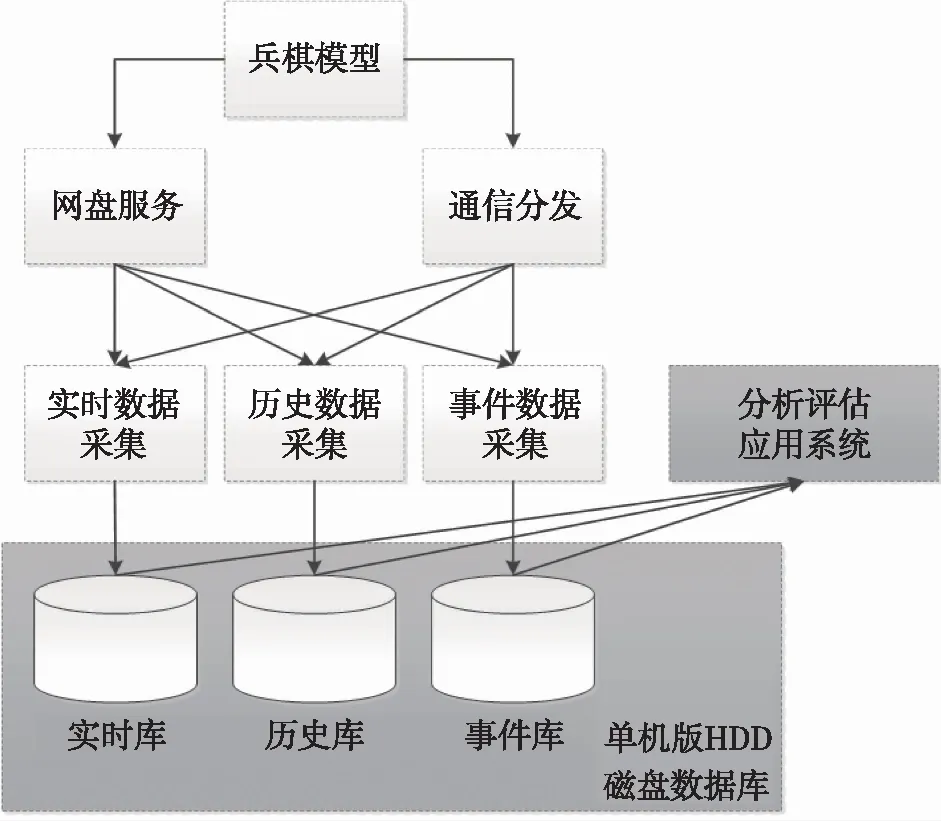
图1 原有数据采集管理机制总体结构Fig.1 Structure of original data collection and management mechanism
1.2 原有数据采集管理机制存在的问题
不可否认,原有机制采用这种结构有其优点:1)结构简单清晰,便于理解和实施;2)推演模型子系统和分析评估子系统共用一套数据库,相互之间不存在数据延迟问题;3)单机版数据库便于维护,故障率低。
推演规模较小时,原有系统结构发挥了很好的支撑作用,一直以来运行良好。但随着推演规模的不断增大,推演数据量呈指数级增长,并且对分析评估的时效性要求不断提高,原有数据采集管理机制逐渐暴露出一些问题。问题一:推演模型子系统和分析评估子系统共用一套数据库,如果分析评估子系统大量访问数据并导致数据库“假死”,则推演模型子系统也不能正常写入数据。问题二:单机磁盘数据库性能有限,如果分析评估子系统进行较复杂的分析查询,则整个系统会进入“无限等待”状态,很长时间不能输出评估结果。问题三:推演模型子系统推演过程中会形成许多推演分支,各分支之间有大量的交叉数据,如不进行处理,将导致统计结果失真。以前对多分支数据的管理方式为手工在控制台输入命令进行分析和去重,效率低,工作量大,易出错。问题四:原有分析评估应用所有分析结果都直接查询原始数据,来自不同席位的多次重复查询导致大量资源浪费,同时查询效率低下。问题五:由于服务重连等原因,原始输出数据中存在重复记录等错误;而原有系统不进行纠错直接入库,导致分析结果严重失真。
针对这些痛点,兵棋推演系统的底层数据管理机制必须要进行重新设计,研发专用数据采集与管理平台。
2 新的数据采集管理系统总体结构设计
新的兵棋推演实时数据采集与管理系统包括数据采集、数据管理和数据服务3个子模块,总体架构如图2所示。
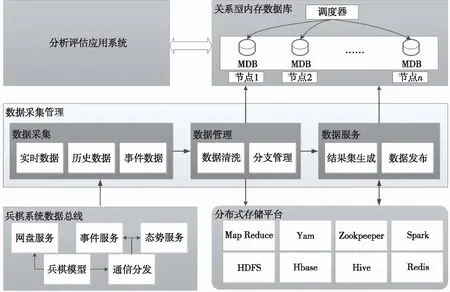
图2 兵棋推演实时数据采集与管理系统总体架构Fig.2 System architecture of real-time data collection and management system
数据采集模块采用基于总线的实时采集方式,从模型推演数据总线上实时采集态势信息和事件信息,经解析重组后,交由数据管理模块进行入库处理。
数据管理模块负责对采集到的数据进行清洗,同时对各数据段进行分析,形成精准的分支数据,然后将组织好的数据存储到分布式存储平台和内存数据库中。该模块同时负责对各类数据信息进行可视化编辑和管理。
针对不断变化的实时数据,数据管理模块设置两种实时数据备份方式。一是每隔一段时间(默认30 min)自动对实时数据生成快照;二是在推演系统每生成一个检查点时,同步生成实时数据快照。
数据服务模块负责对采集到的数据进行进一步加工,形成各系统直接可用的数据集,提供给上层应用系统,减少应用系统再次组织数据形成结果集的开销。该模块同时负责在检查点重启等操作引起数据分支变化时,将正确的数据从分布式存储平台发布到内存数据库。
各应用系统通过访问负载均衡下的内存数据库来查询和分析数据。内存数据库的高性能和低延迟特性,保证了各应用系统的访问效率。
该架构通过综合管理和内存数据库技术,解决了应用系统访问数据时的低效性和准确性差的问题;通过引入分布式存储平台,解决了长期运行时大量推演数据的存储成本问题。
3 各模块设计实现
3.1 数据采集模块
3.1.1 功能设计
数据采集模块根据系统配置信息从数据总线实时采集数据信息,包括配置管理、实时监控处理、实时信息处理、历史信息处理、事件信息处理等子模块,如图3所示。
配置管理模块对采集数据源进行配置,如对态势服务节点、事件服务节点信息配置,也包括对采集间隔、监控频率、推演想定、输出数据库等信息配置。
实时监控模块对采集过程进行实时监控,在线监测数据源更新情况,监测数据处理量、处理速率、模型各服务节点输出状态等,保存并提示采集过程异常情况。
实时信息处理模块主要功能是处理实时信息,并存入缓存队列;历史信息处理模块主要功能是处理历史信息,并存入缓存队列;事件信息处理模块主要功能是处理事件信息,并存入缓存队列。
3.1.2 功能实现
数据采集模块的具体实现如图4所示。
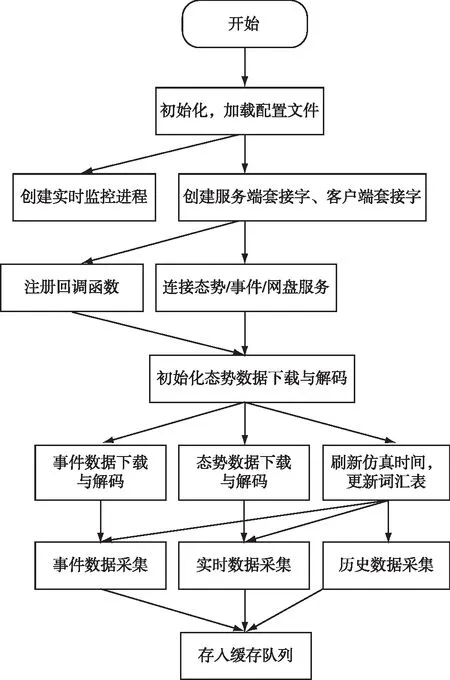
图4 数据采集模块程序流程图Fig.4 Program flow chart of data acquisition module
1)配置管理
程序启动后,首先读取配置信息。包括用于确定数据实时性的采集间隔、用于采集程序注册认证的想定名称和程序标识码、用于网盘挂载的网盘服务器IP地址和本地挂载路径、用于实时信息定时快照的快照间隔、用于服务接收的态势服务源和事件服务源等参数,以及数据管理模块用到的实时数据库地址、账号,分布式存储平台地址、账号,分支管理服务端地址端口等。
需要说明的是,用于确定数据实时性的采集间隔并不是越小越好。一方面是因为过小的采集间隔将导致程序“睡眠”时间缩短,增加服务器处理负载。另一方面是因为采集的总线数据也不是连续无间隔输出,而是类似于波浪一样的脉冲式输出,既有连续且较小的持续流量,也有集中的“波峰”。采样间隔在不大于一个“波峰波谷”周期的前提下,越大越好。具体最佳值要根据推演环境现场确定,通常在10~60 s之间。
2)实时监控
配置信息处理完毕后,随即创建多个子线程/进程,包括用于程序状态监控的实时监控进程,用于处理用户终端命令输入的终端服务线程,分别用于采集态势数据和事件数据的态势服务线程和事件服务线程等。然后,注册各类回调函数,校验并修正各类配置信息,进入程序主循环。
程序运行期间,实时监控模块主要负责监控以下信息:采集的数据量和处理速度,生成的结果集数据量,态势信息源的服务状态,事件信息源的服务状态,网盘服务状态,模型通信分发服务状态,模型输出服务状态。
如果其中有出现异常的,先尝试进行修复,如果修复不成功,及时进行告警提示。
3)实时信息处理
初始化完毕后,开始接收并处理各类数据。第一批数据(初始化帧),在态势服务线程连接上态势服务后立即下发,其中包含各类实体和目标的初始状态。当前时刻已经经过的模拟时间片数会随着其中的仿真状态数据一并下发(后续模拟时间片数的更新也随仿真状态下发)。然后通过读取网盘中保存的初始仿真时间可以计算出当前的仿真时间,这个时间随后被更新到缓存队列的各条记录中。与此同时,网盘中的词汇表也会被解析到程序缓存中,以便对数据中的各类编码进行替换。
初始化数据下发完毕后,就开始了正常的态势数据下发与处理,处理方法一样,区别仅在于数据量的大小和详细程度。这些态势数据最终会被转换成通用数据格式,存入共享缓存,并随着时间的推进不断更新。
4)历史信息处理
与实时信息的处理过程类似,首先也是接收数据、解码、格式转换。然后存入缓存历史信息处理。不同之处在于对缓存队列的管理。
处理实时信息时,缓存队列是不断更新的,每个实体仅维持一条最新的状态记录。而处理历史信息时,缓存队列的更新操作被替换成了增长操作。也就是说,如果某个实体的态势发生了变化,则在历史信息缓存队列中,变化后的态势是作为一条新的态势记录插入到缓存队列中的,而态势变化前的那条记录维持不变。
历史信息会设置对应的数据段号字段用于记录各条数据归属的数据段,而实时信息是没有这个字段的。
5)事件信息处理
事件信息的处理与历史信息类似,也是变化信息被作为新的纪录插入缓存队列;不同之处在于每条事件信息自带事件发生时的仿真时间,不需要额外计算仿真时间。同时,后续过程中数据段号的计算也是依赖于这个自带的仿真时间,而不是像历史信息一样,依赖于当前仿真时间。
3.2 数据管理模块
3.2.1 功能设计
数据管理模块对不同分支的数据进行管理,包括数据段计算、分支树维护、数据清洗、内存库存取、分布式存储平台存取等子模块,如图5所示。
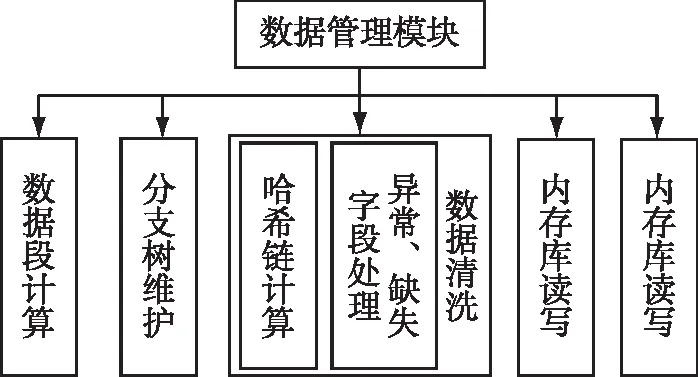
图5 数据管理模块功能结构图Fig.5 Functional structure of data management module
数据段计算主要用于计算各条数据记录的数据段号,更新该条记录。分支树维护主要维护推演数据的分支树型结构,将新生成的数据段插入分支树中的正确位置,为后续的数据发布提供计算基础。
数据清洗主要进行基于哈希链的数据去重,以及对各条记录中出错的异常、缺失字段进行自动更正(目前还不能对全部字段错误全自动处理),其中哈希链计算主要用于计算各条数据记录的组合哈希,存入程序缓存。
内存数据库存取和分布式存储平台存取模块主要负责将数据组织成对应平台的数据形式,并进行存取。
3.2.2 功能实现
数据管理模块的具体实现如图6所示。

图6 数据管理模块程序流程图Fig.6 Program flow chart of data management module
1)分支树维护
数据管理模块启动后,首先读取数据段配置文件,构建初始分支管理树。根据每条记录的数据段号和父数据段号,确定对应的挂载关系。所有的数据记录按照各自的数据段号,分别归属到不同的分支中,并根据需要,进行相应的数据调度。
后续新的数据段产生后,计算其对应的父数据段号,挂载后形成新的分支结构。新产生的该数据段内的数据,也都归属到这个数据分支。
2)数据段计算
对于不同类型的数据,采用不同的数据段号计算方法。首先,实时信息数据由于是不断更新的,都对应的是最新的数据段,故不计算其数据段号。其次,历史信息数据在采集完成后,用当前数据段号作为其数据段号。
事件数据的数据段号计算方法略微不同。由于采集完毕的每条事件数据都会包含一个仿真时间,且事件数据存在长时间延迟的情况(比如很久以前的事件数据突然被接收,而此时的数据段号比彼时的数据段号已经变化了很多),所以用事件数据记录内的仿真时间计算数据段更合适,可以避免直接复制当前数据段号引起的错误。根据指定的仿真时间,沿着当前分支在分支树中查询对应时间段的数据段号并赋值。如果发生跨分支的情况,则查询失败,赋默认值。
3)哈希链计算
将整条数据输入,转换为字符型缓冲区,然后使用MD5、SHA1、RIPEMD160、CRC32等哈希算法分别计算对应的哈希值,得到组合哈希。然后与程序缓存中的哈希链做对比,如果发生冲突则说明是重复数据,进行丢弃,否则转入下一步处理。
4)异常/缺失字段处理
该模块主要是对数据中存在的一些错误进行自动修正。对数据的修正首先是根据各表之间的关联关系,通过ID进行关联后,抽取曾经出现过的合理值进行替换,由于聚类分析、回归分析、牛顿插值等方法计算量较大,如果每个字段都采用此类方法,则服务器负载较重,且程序吞吐量得不到保证,所以仅在推演结束后才能采用,实时数据采集用的是简化方法。对于不能通过关联关系修正的数据,则“一例一案”地采用不同的方法进行修正。
对于错误的字段,典型的如事件记录中,一个事件系列结束后,最后一条记录的更新状态应该是“V”,而有些情况下该状态却被标记为“UN”,此时就自动地把“UN”修正为“V”。再如实体名称中,按标准是不允许出现“,”符号的,但某些情况下却出现了“,”符号,此时根据具体情况,直接删除或采用“_”替换。
对于缺失的字段,如果是数值型的,一般用0进行填充,如果是字符型的,则用“NULL”或“{INVALID}”进行填充。
由于数据出错的类型较多,且在不同的环境中会出现不同的错误(包括新的错误类型),所以此处只是进行了力所能及的修正,并不能涵盖所有情况。
5)内存数据库存取
该模块主要是把缓冲队列中处理好的各类数据写入内存数据库。为提高写入性能,采用批量写入的方式。首先,构造基础SQL语句,循环对写入缓冲区变量数组赋值,然后,把基础SQL和缓冲区数组统一提交给数据平台。对于批量写入失败的情况,再区分处理:如果是由于资源竞争引起,则再次尝试单条逐个写入;如果是由于数据格式错误或底层服务异常引起,则进行错误告警。
6)分布式存储平台存取
该模块主要是把缓冲队列中处理好的各类数据,写入分布式存储平台。由于是同一个采集管理模块同时支撑两类数据平台,所以此处以CSV文件为中介。首先采集管理模块把要写入的数据输出到CSV文件中,然后另外启动一个进程,将CSV文件“load”到分布式存储平台。如此可以保证两套平台异步并行处理,不会因一套平台的某个操作阻塞,而卡住另一套平台的处理。
3.3 数据服务模块
3.3.1 功能设计
数据服务模块主要提供结果集生成和分支数据发布两类服务,包括基于态势的结果集生成、基于事件的结果集生成、混合型结果集生成、分支数据发布等子模块,如图7所示。生成结果集的目的主要有2个:一是规范分析流程,保证数据和指标都相同时,分析结果相同;二是降低分析时需要处理的数据量,提高系统效率。
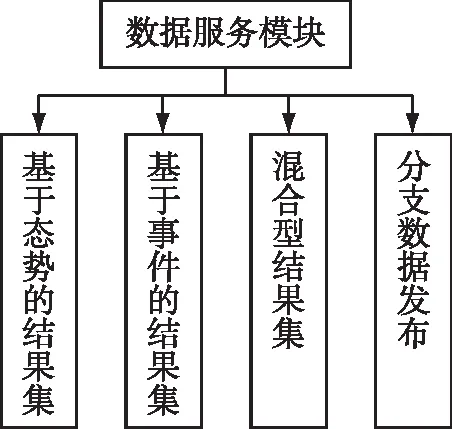
图7 数据服务模块功能结构图Fig.7 Functional structure of data service module
基于态势的结果集生成主要是生成各种对态势数据简单分析后得到的结果集。基于事件的结果集主要是生成各种对事件数据简单分析后得到的结果集。混合型结果集生成主要是生成需要综合分析态势数据和事件数据的综合型结果集。
分支数据发布主要是根据用户选定的数据分支或检查点信息,将正确的分支数据发布到目标库。
3.3.2 功能实现
数据服务模块的具体实现如图8所示。其中,结果集生成的流程如图8a)所示。当有新的态势数据加入数据缓存队列,就启动一个检查例程,看是否符合结果集的计算条件,如果不符合则略过该条数据,否则进行相应的结果集生成。
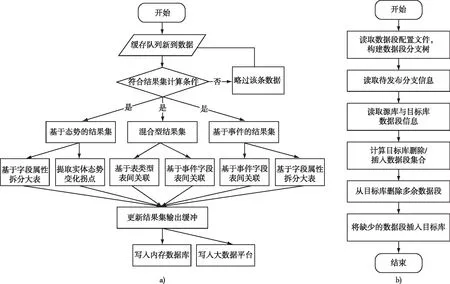
图8 数据服务模块程序流程图Fig.8 Program flow chart of data service module
1)基于态势的结果集生成
部分结果集仅依赖于态势数据即可生成。主要有基于字段属性拆分大表、监控实体态势拐点等。
对于第一类,将原先数据量较大的一张表,根据指定字段的不同取值,分门别类地放入不同的子表内。如可根据视图字段,将同一个视图的数据放入一张表。经过这样拆分后的数据子表,数据量可降低一个数量级,大大加快在后续统计分析中的响应速度。
对于第二类,按照不同的实体ID,分别监控其态势变化,在态势出现拐点时及时进行记录。比如,监控实体的受损信息,当实体轻微受损、严重受损、被修复、被消灭时,分别进行记录。如此处理后,结果集记录的都是重要的拐点信息,相比于原始无差别的定时采样,数据量大大减少,后续分析中不需要再处理无关的背景数据。
2)基于事件的结果集生成
部分结果集仅依赖于事件数据即可生成。主要有基于字段属性拆分大表、基于事件字段表间关联等。
对于第一类,类似于基于态势数据做的大表拆分。如可根据实体类型进行拆分,将不同实体类型的事件数据分开存放,同样可以减少数据量。
对于第二类,主要是利用程序直接计算的快捷性,将大表关联后的结果直接写入数据集,避免后续使用SQL语句进行大表关联的巨大开销。如可直接将打击事件与打击详情进行基于事件ID的关联,结果直接写入新的详细打击情况表。
3)混合型结果集生成
部分结果集需要综合利用态势信息和事件信息生成,主要有综合详情、关联分析等。
对于第一类,可按照详情种类,将对应的事件表与实体表做关联,结果写入综合详情表。如对于交战事件详情,可将交战事件与实体信息以及词汇表进行综合关联。
对于第二类,可按照分析类型,将对应的事件表与实体表做关联。如对于火力打击关联分析,可首先提取指令事件中的ID等信息,然后与开火事件、实体信息、词汇表进行综合关联。
4)分支数据发布
分支数据发布的流程如图8b)所示。模块启动后,首先读取分支配置信息,生成分支树;然后读取待发布分支信息,并与分支树作比较,生成目标分支数据段集合;其次读取源库和目标库数据段信息,与目标分支数据段集合作比较,计算出需要删除的数据段和需要插入的数据段;最后从目标数据库中删除需要删除的数据段,从源库中将需要插入的数据段插入目标数据库。
4 新机制与原有机制比较
4.1 新机制与原有机制的不同之处
不同之处主要有以下几点:
1)原有机制下,推演模型子系统和分析评估子系统共用一套数据库;新机制实现了数据库的分离,各自使用自己的数据平台。
2)原有机制下,数据采集基于通信分发传输协议;新机制下,数据采集基于事件服务和态势服务协议。
3)原有机制下,采用的是单机磁盘库;新机制下,采用的是结合了内存数据库和分布式存储平台的混合型数据平台。
4)原有机制下,没有进行多分支管理,所有数据全部无差别地存放在一起;新机制下,进行了基于数据段的非确定性多分支数据管理,所有数据按照分支树进行组织。
5)原有机制下,没有进行数据集的提取操作,所有查询全部针对原始数据直接进行;新机制下,引入了基于数据集的数据治理方法,绝大部分查询可以查询治理后的数据集结果。
6)原有机制下,没有进行数据去重;新机制下对重复数据进行了去重处理。
7)原有机制下,对缺失字段和异常字段没有进行处理;新机制下,自动化处理了缺失字段和异常字段。
8)原有机制下,数据存储上采用的是分库不分表的存储方式;新机制下,数据存储上采用的是分表,但不分库的存储方式。
4.2 新机制带来的好处
对应于以上改进措施,新机制带来的好处主要如下:
1)模型推演子系统和分析评估子系统数据平台的分离,确保了相互之间不再因数据平台而相互阻碍。再也没有发生过因一方对数据平台的大量访问,导致另一方无法运行的情况。
2)数据总线采集协议的升级,保证了新机制下事件数据可以采集多份,提高了安全性和应用灵活性。相比于原机制下事件数据只能写入一个数据库,解决了单点瓶颈问题。
3)混合型数据存储平台的采用,既解决了单机磁盘库容量有限的问题,又解决了磁盘型数据库性能问题。分布式存储平台可以存储海量数据。关系型内存数据库可以保证数据的高速访问。
4)多分支管理技术的引入,确保了每次进行分析的都是正确的数据。解决了以往分析评估时,因基础数据有脏数据而导致的评估结果严重失真问题。
5)基于数据集的数据治理,提供了可以直接使用的结果集,不必每次都查询原始数据,节约了大量资源。同时,由于结果集是以列式存储方式存储在内存中的窄表,速度和利用效率更好。相比于原机制下以行式存储方式存储在磁盘中的大量宽表,数据访问性能得到了极大提升。
6)数据去重,缺失字段和异常字段的处理,极大地提高了分析结果的准确性。
7)原有分库不分表的存储方式,虽然较好地减轻了数据写入时的压力,提高了写入性能;但查询时因为有大量的跨库数据传输,且没有通过分表进行数据筛减,降低了性能。新机制下的分表不分库,通过杜绝大批量跨库数据传输,同时对单条SQL涉及的数据进行筛减,极大地提高了综合性能。
5 系统运行结果
在CentOS7.9上,使用C++版eclipse 进行了系统实现,总计约20万行代码(不含内存数据库和分布式存储平台部分)。共采集生成了4大类225张数据表。目前系统运行稳定,已支撑多场重要推演。
图9是系统运行过程中生成的部分数据段配置信息,可见本次运行的分支信息还是比较多的,如不进行处理,将会导致存在大量的重复数据,致使各类统计结果偏离甚至翻倍。

图9 数据段配置信息Fig.9 Snapshot of data segment info config file

图10 采集数据量随时间变化图Fig.10 The change of the amount of collected data over time
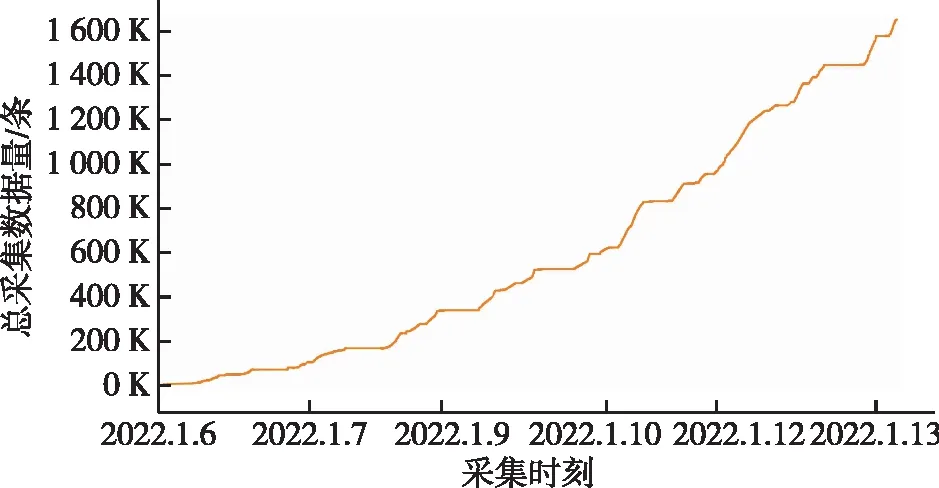
图11 采集数据总量随时间变化图Fig.11 The total amount of collected data over time
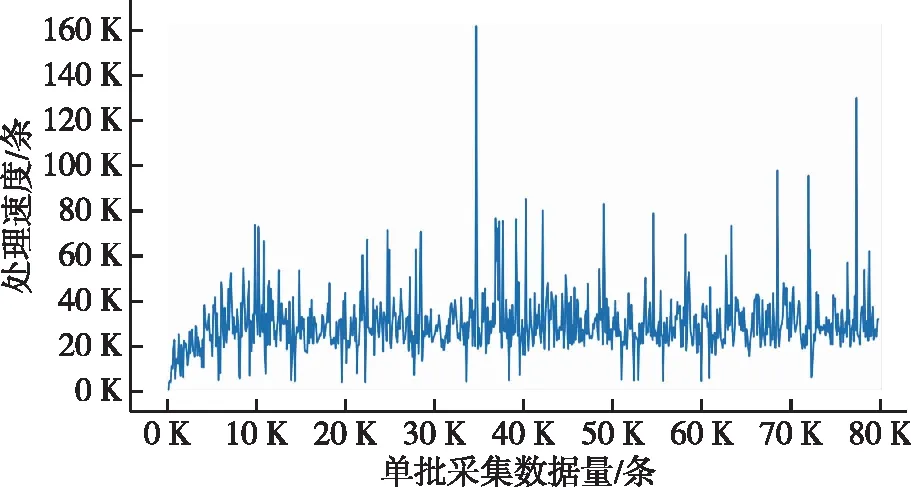
图12 采集数据处理速度随数据量变化图Fig.12 The processing speed of the collected data over the amount of collected data
对系统的采集效率进行了测试,数据采集节点测试环境配置为:12 Core 2.2GHz CPU,128GB DDR4 RAM,2TB SSD,华为CloudStack云平台。图 10是采集到的数据量随时间的变化曲线,可见数据分布并不是均匀的,有波峰,有波谷,并且波峰的高度和间隔也是随机的。图 11是采集的数据总量随时间变化曲线,可见呈波浪状阶梯上升。图 12是系统采集数据时的处理速度,当数据量大时,批处理的优势体现出来,处理速度较快,数据量小时,基本为逐条处理,没有批处理优势,处理速度较慢;但受资源竞争等因素影响,处理速度并不是恒定不变的,也具有一定的随机性。
对采集后的数据访问速度进行了测试,单表数据量1亿条(总数据量10亿条)情况下,count查询响应时间基本小于0.1 s,简单组合查询响应时间约0.2 s,大表间复杂多表关联操作响应时间在1 s左右。原有机制下,这几个数值分别为约3 s,约2 min,约7 h(原运行环境配置为16Core 2.0Ghz CPU,16GB DDR4 RAM,4TB HDD)。
6 结束语
从系统运行的实际需求出发,设计实现了基于总线的兵棋推演数据实时采集管理平台。从实际运行情况看,较好地解决了推演数据实时采集和服务问题。基于总线的实时采集和数据清洗,保证了数据采集的速度,提高了采集数据的质量。基于数据段的分支管理,保证了提供给应用系统的数据的准确性。数据集和内存数据库的采用,极大地提高了应用系统访问数据的速度。分布式存储平台的引入,解决了大批量数据的低成本存储和灵活检索。
与原有机制相比,实现了数据采集管理平台从无到有的转换。基于数据段的分支管理和数据清洗等功能,都是首次实现,相比于原有机制是零的突破。从整体效果上看,实现的数据管理平台不管是访问速度还是数据准确性,以及可支持的推演和评估模式的灵活性,都有了较大的提升。
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
军事文摘(2020年19期)2020-10-13
电子制作(2019年13期)2020-01-14
学生天地(2019年28期)2019-08-25
军事运筹与系统工程(2019年3期)2019-08-13
数学物理学报(2018年1期)2018-03-26
军事运筹与系统工程(2018年4期)2018-03-26
军事运筹与系统工程(2018年2期)2018-02-16
