
基于编解码机制的水下图像语义分割*
2023-12-11 12:10王金康何晓晖邵发明卢冠林
舰船电子工程 2023年9期
王金康 何晓晖 邵发明 卢冠林
(中国人民解放军陆军工程大学 南京 210007)
1 引言
随着水资源的开发利用和深度学习的快速发展,基于深度学习的水下计算机视觉领域被越来越多研究者所关注。图像分割[1]作为计算机视觉的一个重要研究方向,已经有研究者将其用在水下图像对目标分类中。但由于水下环境复杂,水介质对光线的散射以及吸收效应,水下图像质量差,一般会存在色偏,对比度低、噪音以及光照不均的问题。这对水下图像分割的完整性和准确性提出了很大的挑战。传统的语义分割方法面临以下问题:
1)过深的卷积网络会降低特征图分辨率,导致一些关键信息丢失;
2)不同尺度目标的存在需要结合全局和局部信息,导致特征提取困难;
3)CNN的空间不变性造成定位精度的下降,目标与背景之间边界模糊。
近年来,随着深度学习技术的进步,基于深度学习的图像语义分割方法大放异彩。Deeplab V3+[2]针对FCN 的不足进行改进,通过图像金字塔[3]、空洞卷积[4]、空间金字塔池化[5]等技术有效扩大感受野,捕捉图像上下文信息,从而改善分割结果。但是稠密的网络结构导致分割速度慢,且Deeplab V3+算法对于小尺寸的目标分割效果不明显。Segnet[6]采用编解码机制,通过Uppooling 还原像素的空间位置信息,提高分割分辨率。但其网络训练参数过多,计算成本较高。DenseASPP[7]在ASPP的基础上采用密集连接,覆盖大范围的语义信息,对高分辨率图像有较好的分割效果,但是同时密集连接也导致计算量急速上升。DFANet[8]采用Xception网络作为主干结构,将高级上下文合并到编码的功能中,在分割速度和准确度之间取得有效平衡。DANet[9]提出自我关注机制的双注意力网络,增强场景分割特征表示的判别能力,显着改善了分割结果。Auto-APCNet[10]提出自适应上下文模块,自适应的构建多尺度上下文表示。CANet[11]开发了一种新颖的双分支密集比较模块,有效地利用来自CNN的多级特征表示来进行密集的特征比较,同时加入注意力机制融合来自不同支持示例的信息。MagNet[12]提出一个多尺度框架,通过多个放大级别逐步细化分割输出,进行从粗到细的信息传播。解决了局部图像模糊的问题,分割性能大大提高。SETR[13]将语义分割视为序列到序列的预测任务,通过编码transformer 建模全局上下文信息,提升分割精度。RobustNet[14]提出了一种新的实例选择性白化损失,将特征表示的高阶统计量中编码的特定于领域的样式和领域不变的内容分开,并选择性地只删除导致领域漂移的样式信息,以提高不可见区域分割网络的健壮性。基于深度学习的图像语义分割技术在鲁棒性特征的自主学习和分类过程中,表现出巨大优势,分割精度和速度较传统的语义分割技术有极大提升。
本文在上述文献的基础上决定先对水下图像进行图像增强,再做下一步的语义分割。首先,我们采用密集连接的混合空洞卷积,相比Deeplab 系列算法等单纯的用多层空洞卷积而言,能够覆盖更大感受野,有效地保持了特征信息的整体性,减少信息丢失。其次,级联空洞卷积空间金字塔池化模块对特征图做细化处理,通过融合不同感受野下的图像特征来共享多尺度目标信息,这种方法在上述论文中是没有出现过的。最后,创造性的提出上下文信息聚合网络,通过将深层网络与浅层网络中的特征信息融合,细节信息更加丰富,对边缘细节的把握更加充分。
2 方法简介
为了解决水下图像语义分割过程中遇到的困难,本文提出一种基于编解码机制的上下文信息融合的水下图像分割算法,算法流程如图1所示。首先提出一种基于加权融合的多空间转换水下图像增强方法[27]对原始水下图像进行增强处理,其次通过具有50 个网络层、滤波器大小为1×1 和3×3、步幅为2 的基础网络Resnet50[15]进行特征提取,使用密集连接的方式将提取到的特征图输入到HAC块,通过一系列的连续扩张卷积组合级联,扩大神经元感受野。HAC块包含三个3×3空洞卷积,空洞卷积的扩张率分别为1、2、5。然后通过级联空洞卷积空间金字塔池化模块兼顾不同尺度的目标区域,丰富目标细节信息和更高层次的图像语义信息,CASPP 模块包含2 个1×1 卷积和三个3×3 空洞卷积,空洞率分别为5、9 和13,过滤器数量为256个。以上两个部分组成编码器,实现对水下图像的语义边缘信息提取和融合。解码器创造性的采用上下文信息聚合机制,通过双线性插值将深层网络与浅层网络的特征信息融合,并使用3×3 卷积对特征进行微调,更加充分地把握图像边缘细节,大幅度减少了图像特征信息的丢失。最后采用双线性插值法进行2倍的上采样,得到最终的图像分割结果。
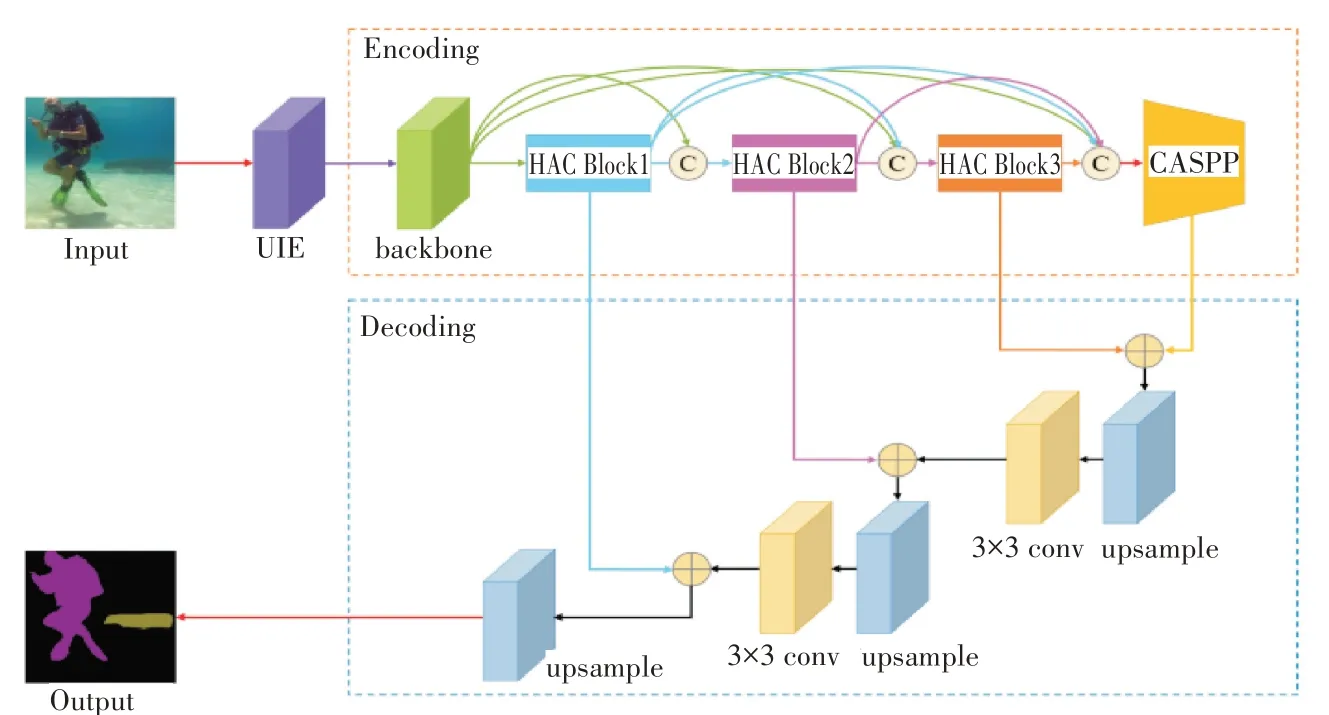
图1 基于编解码机制的水下图像分割算法框架
2.1 加权融合的多空间转换水下图像增强
针对质量不佳的水下图像,由于其对比度低、存在色偏、细节模糊,直接进行语义分割效果不好,我们先对水下原始图像进行增强处理。多空间转换水下图像增强算法流程图如图2所示。
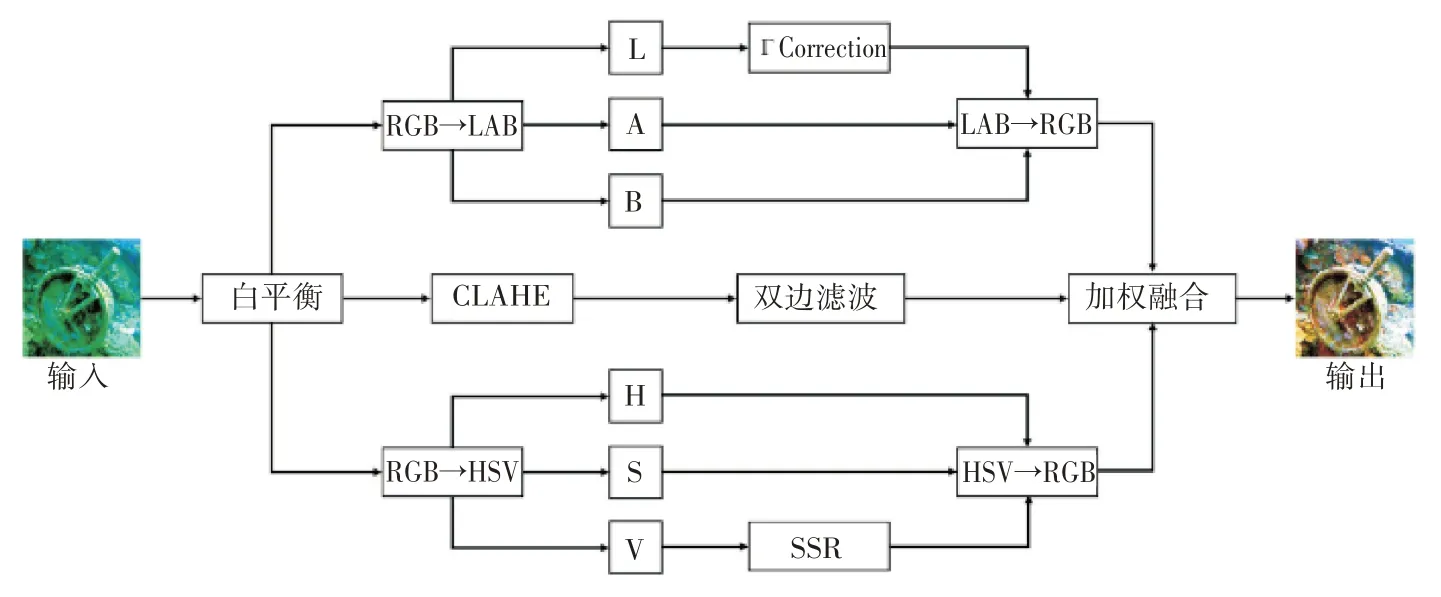
图2 加权融合的多空间转换水下图像增强算法流程图
加权融合的多空间转换水下图像增强算法流程如下:首先对输入图像进行白平衡处理,以消除或减轻输入图像的色偏问题。之后,经过白平衡处理的图像分别进行三个支路的后续处理。第一条支路将图像从RGB 通道转化为LAB 通道,并对L通道进行伽马校正,以调节图像整体亮度,最后再转化为RGB 通道。第二条支路对图像先后进行CLAHE 处理和双边滤波处理,去除噪声的同时提高图像的清晰度。第三条支路将图像从RGB 通道转化为HSV通道,并对V通道进行单尺度retinex处理,保证图像的色彩饱和度,提高细节处理,最后再转化为RGB 通道。对三条支路的处理结果进行加权融合,得到图像的最终增强效果。
2.2 密集连接的混合空洞卷积模块
Deeplab系列网络使用多层连续空洞卷积进行特征提取,但在感受野扩大的同时,会造成“gridding issue”,这是因为在使用多层空洞卷积后,会对输入的采样变得很稀疏,从而导致一些局部信息丢失,特征图整体连续性信息被忽视。为了解决这个问题,我们采用不同空洞率的混合空洞卷积,小空洞率用来提取本地信息,大空洞率用来提取长距离信息,这样既可以获取更宽阔的区域信息,又能在保持感受野不变的情况下提高信息利用率。如图3,我们以空洞率为1,2,3 的混合空洞卷积为例,在一开始就保留完整连续的3×3 区域,之后几层的空洞率设置又刚好保证拼起来感受域的连贯性,虽然有所重叠,但是密不透风,可以有效地保持了特征信息的整体性。它的结构需满足公式:

图3 不同空洞率混合空洞卷积的覆盖效应
其中,ri为第i层的空洞率,Mi为在第i层插入的最大空洞数量,若卷积核大小为k*k,则需要满足Mr≤k,这样就可以覆盖所有空洞。
通过密集连接的方式将空洞卷积块连接到一起,获得越来越大的感受野的同时,对多尺度的语义信息做编码,不同特征图对来自不同尺度的信息做编码,最终输出特征不仅覆盖大范围的语义信息,而且以非常密集的方式覆盖信息编码。
2.3 级联空洞卷积空间金字塔池化模块
对于质量低下的水下图像,层层卷积下使特征图分辨率逐渐减小,这对于水下图像分割来说更加困难,会导致目标细节的缺失和各像素关联性的弱化。针对这个问题,我们使用空洞率分别为5,9,13 的三个空洞卷积并联对特征图做细化处理,同时兼顾不同大小尺度的目标区域,丰富目标细节和更高层次的图像语义信息。此外,利用级联融合的方式,将三个并行空洞卷积后的特征图级联相加,通过融合不同感受野下的图像特征来共享多尺度目标信息,不同空洞率卷积相互依赖,将不同感受野下的特征信息进行级联整合,进一步提高全局像素信息的关联性和连续性。最后通过维度拼接的方式将得到的5 个特征图在通道维度上进行融合,获得包含更多边缘细节和高级语义的特征图。级联空洞卷积空间金字塔池化模块结构图如图4所示。
2.4 上下文信息聚合网络
图像在不同网络深度具有不同特点的特征信息,浅层特征图尺度大,具有较多的特征信息,利用浅层网络可以将目标进行简单的区分,但由于卷积核以及计算资源的限制,网络只能在小感受野的范围内提取到具有颜色、纹理等细节信息的图像局部特征;在深层网络中,特征图经过层层卷积和下采样,分辨率减小,特征图尺寸降低,感受野也增大,网络能够在全局范围内提取到较为明确的位置、类别等高级语义信息,但由于缺失几何空间细节信息,在标定目标位置类别时对于边缘细节信息的准确度不够。通过将深层网络与浅层网络中的特征信息融合,能够大幅度减少图像特征信息的丢失,使得图像在保证位置类别准确的情况下,细节信息更3加丰富,对边缘细节的把握更加充分。
上下文信息聚合网络如图5所示。首先,将级联空洞空间金字塔池化模块输出的特征图F4 与空洞卷积块3 提取的特征图F3 进行逐像素相加操作;然后经过2 倍上采样增大特征图分辨率,并空洞率为2 的空洞卷积结合相邻像素的特征信息,对特征图的上采样特征进行细化处理;接着将处理过的该特征图与空洞卷积块2 的特征图F2 进行加和操作,再经空洞卷积细化处理后与特征图F1进行相加融合,获取有效的图像目标空间信息与物体边缘信息:最后经过2 倍上采样后得到分割结果。利用自底而上的方式将各路径特征信息进行聚合,使得深层图像语义信息逐渐与图像浅层边缘线条、形状位置等细节信息融合,在传达强定位信息特征的同时传达强语义信息特征,捕捉清晰的目标边界信息,细化分割结果,有效提高物体分割的精度。
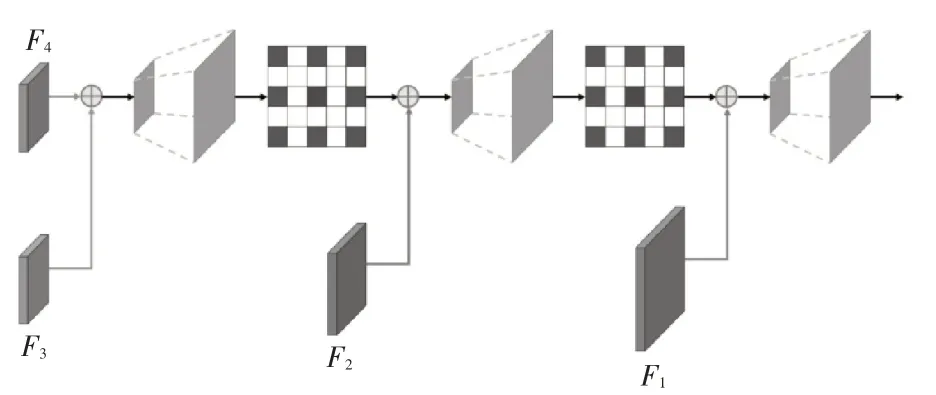
图5 上下文信息聚合模块结构图
3 实验分析
3.1 数据库
为了完成水下图像语义分割的研究,我们对RUIE[16]和UIEBD[17]两个开源水下图像数据集合并以构建一个水下图像分割数据集。我们对其中的3000 张图像采用Resize 操作将大分辨率图像进行像素聚类,对小分辨率图像进行像素插补,在一定程度上对图像信息进行提取并按512×512 分辨率重排像素点,以致达到统一像素。按照COCO 数据集的标注格式,通过LabelMe 软件以手工标注的方式进行标注。我们的标注包括海鱼、潜水员、珊瑚、礁石、雕塑、章鱼、海龟、水草、Mobula、海胆、扇贝、海星12个类别。
3.2 实验设置
我们的水下图像分割方法在PyTorch软件中进行了实验。运行平台为:Windows 10 64 位操作系统、NVIDA GeForce RTX 4000、8 GB DDR3 内存、英特尔酷睿i7-6700U、CPU@4.00 GHz。我们的算法运行在GPU 上。
在训练参数设置中,我们设置初始学习率为0.01,采用带动量的随机梯度下降法(SGD)进行网络优化。动量参数为0.9,权重衰减正则项为0.00005,批量大小为16。
3.3 评价指标
本章使用OA,IOU 和MIOU 作为综合评价指标评价网络的分割效果。
OA代表总体精度,表示分类正确的样本个数占所有样本个数的比例,表达式如式(2)所示。
IOU表示每类目标数据分割的预测值与真实值之间的交集和并集之比,表达式如式(3)所示,MIOU即每类目标IOU的平均值,表达式如式(4)所示。
其中,k表示分割类别数量,包括背景的话,则有k+1个类别。
3.4 实验结果
为了直观地表现我们提出的算法的有效性,将本文算法与现有最先进的4 种经典分割算法在合成数据集上的对比结果如图6所示,从左到右分别为原始图像、强化图像、Deeplab V3+、DFANet、APCNet、CANet和本文方法的分割效果图以及真实值。

图6 水下图像语义分割的定性比较
水下图像由于产生色偏现象,导致图像的对比度降低,从图6 实验结果可以看出,我们的方法在色偏现象严重的水下图像分割中效果最好。纵向来看,Deeplab V3+在对原始图像进行语义分割的时候由于对比度下降会漏掉一下图像信息,不能对每个目标都进行充分的分割,(c)中的礁石和(d)中上侧的礁石和鱼,(e)中零星的海星和贝壳都没能分割出来,而且边缘定位不准确。DFANet较Deeplab V3+稍有改善,但是对于(c)中的章鱼分类不正确,而且(d)中的上侧礁石和(e)中较小的海星和贝壳未能捕捉到。APCNet对于水下图像的分割效果稍好,但是已经捕捉到的轮廓分割信息过多,如(a)中潜水员分割边界出现宁滥勿缺的现象。相比前几种方法,CANet 分割效果较好但是对于图片(c)这种对比度很低的图像不能取得良好的分割效果。与其他算法相比,我们的方法分割对象完整,定位准确,虽然有不同程度的漏检和边界不清晰的问题出现,但是我们的方法取得的分割结果与真实值最为接近。横向来看,对于a、b、d 这类边界模糊的图像,我们的方法的分割结果边界清晰,最接近真实值;对于c、e 这类对比度低的图像,经过图像增强后的效果还是显而易见的,我们的方法对一些容易漏检的小目标定位准确,而其他方法都存在不同程度的漏检和误检。总的来说,相比其他方法,本文提出的方法在分割完整度、定位精准度、边界清晰度、细节方面都是最好的,可以对水下图像不同类别对象进行有效分类,语义分割效果最好。
本节的客观评价使用3.3小节中提到的图像质量评价指标对分割精准度进行评价测试,表1 展示了数据集中所有类别目标的平均交并比和整体精准度。黑色加粗表示最优结果。
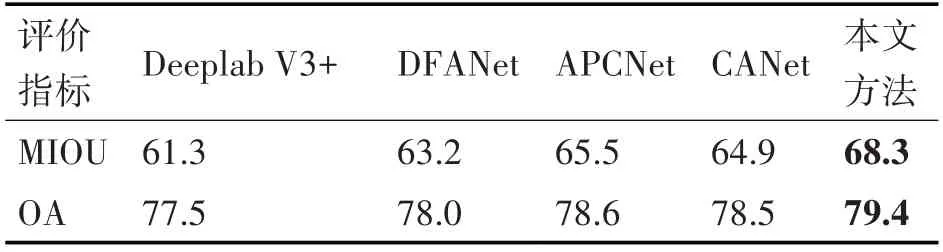
表1 不同方法的MIOU和OA测试结果对比
我们可以看出,本文方法在大多数类别目标分割中的IOU值是最大的,在所有类别平均交并比和整体精准度是最高的,从客观数据上分析分割效果是最好的,这与主观评价基本一致。
表2 展示了我们的方法与其他算法在CUOID数据集上的参数、浮点数和FPS 的比较结果,可以看出我们的方法相对来说参数较少、浮点数小,对计算资源占用小。同时检测速度相对来说比较快,FPS 达到125。综合来说,我们的方法在检测精度和速度方面有良好的平衡。
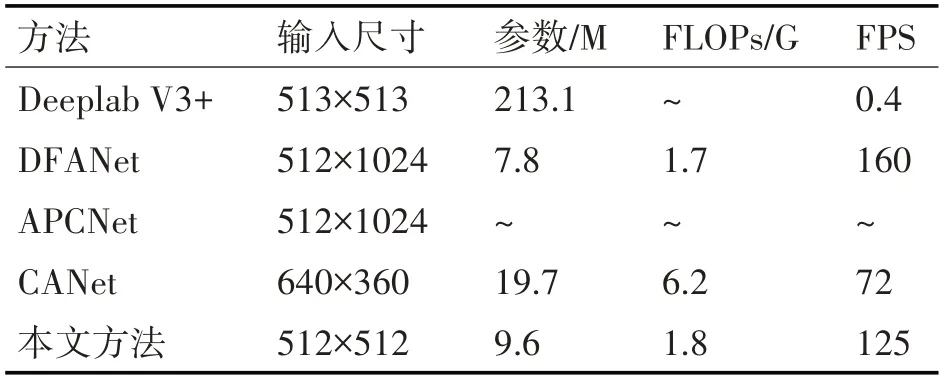
表2 不同方法计算资源对比
3.5 消融实验
我们在合成数据集上验证了我们的方法中每个模块对算法性能的影响。表3 显示了在特征提取网络框架上添加不同模块的消融实验结果。从实验结果来看,每一个模块的添加都具有一定的效果,图像语义分割的精准度都有提高,其中图像增强模块的添加对水下图像语义分割效果增强影响最大。添加了4 个模块的网络客观评价指标均达到最高,这表明4 个模块缺一不可,综合起来对水下图像的分割效果最好。

表3 消融实验结果对比
4 结语
本研究设计了一种编解码机制的水下图像语义分割算法。相比于当前流行的语义分割算法,我们聚焦水下图像,针对水下图像的特点,基于加权融合的多空间转换对水下图像进行增强处理,通过骨干网络得到边界特征图,将混合空洞卷积进行密集连接以在扩大感受野的同时消除“gridding issue”问题,通过级联空洞卷积空间金字塔池化模块丰富目标细节信息。采用上下文信息聚合机制将浅层网络和深层网络的特征进行融合,大大减少信息丢失。实验表明,我们的方法对比当前主流语义分割算法,无论是主观感受还是客观数据上都是最好的,在分割完整度、定位精准度、边界清晰度、细节方面远超其他先进算法,我们提出的方法可以对水下图像进行有效分割。
本文提出的方法使得分割效果得到改善,但是对区分度不大的目标还是会出现误判漏判的情况,我们下一步的工作将着重改进这方面问题,并将结合目标检测,图像增强,深入剖析算法机理,对水下图像处理进行系统性的分析和改进。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
故事作文·高年级(2017年2期)2017-03-01
现代语文(2016年21期)2016-05-25
新闻传播(2015年20期)2015-07-18
大连民族大学学报(2015年2期)2015-02-27
电视技术(2014年19期)2014-03-11
世界科学(2013年11期)2013-03-11
