
政务智能问答系统评价指标体系构建与测评问题编制
2023-12-21 10:58王芳魏中瀚连芷萱
图书情报知识 2023年6期
王芳 魏中瀚 连芷萱
1 引言
随着数字政府建设的深化,越来越多的行政部门开始采用人工智能(AI)技术改善公共服务[1-3]。截至2022年3月底,全国各省级政府门户网站或隶属的政务网站均已依托AI技术设置自动问答系统[4-5](港澳台除外,下同)。初步调研发现,各省级政府网站的智能问答系统表现参差不齐,超过半数的客服无法有效答复随机测试问题,延长了用户等待时间。根据行政负担理论,采用智能问答技术的目的是提高行政效率,降低公众承受的行政负担,但是“数字政府并不必然会降低行政负担,甚至在某些情况下还会加重一些群体的行政负担”[6]。政务问答系统语义理解能力的不足,影响了问答服务的智能化水平,在一定程度上给用户带来新的行政负担。为了提高行政效率,有必要对政务智能问答系统展开评价研究,了解其存在的问题,并提出应对策略。
目前,一些研究在政府问答系统测评方面进行了探索。其中,大部分研究以答案的准确率[7]、召回率、重复率等指标来衡量系统性能,有助于提高预设答案与问题的匹配能力,但是并不能引导提高系统理解用户需求的能力。如果知识库中的预设答案与问题应用场景的契合程度较低,即使是高精度的问答匹配能力也无法满足用户的主观需求。另外,现有研究提出的准确率、答案定性分类等指标虽然能够在一定程度上反映政务问答系统的语义理解能力,但是尚未形成系统性的评价指标体系与测评题目。为此,本文基于理论分析、文献回顾以及典型案例研究,提取与政府网站智能问答系统相关的评价指标,建立一套面向语义理解能力的评价指标体系,同时构建配套测试问题集,并通过对我国省级政府网站智能问答系统的实际评价检验指标体系和测试题集的有效性。
2 理论基础与文献回顾
2.1 行政负担理论
行政负担是指公民在与政府互动过程中面临的学习成本、心理成本和合规成本,在一些情况下,这种负担被用作政策工具[8-10]。20世纪70年代,学术界开始将行政负担与“官僚主义遭遇”(bureaucratic encounters)结合起来[11]。近年来行政负担被阐述为个人与行政组织交互时[9,12]产生的繁重体验[13]。其中,学习成本指公民为了享受某项行政服务不得不学习该服务相关的程序、文本等,如“如何获取该服务”,可以通过目标人群对某个项目缺乏了解的情况推断出来[9];心理成本是指公民在享受政府服务时的不适感,如参加某个不受欢迎的福利项目[9]、没有便利设施的等候空间[14]、被认为没有价值的个人等待时间[15],以及行政人员服务水平或态度带来的困惑、焦虑、沮丧、愤怒等;合规成本指用户因使用政府服务不得不付出请假、通勤等成本,比如参与面谈、培训所付出的时间成本[16]。Schaffer和Huang在行政负担理论的基础上提出“准入理论”[17-18],将公民获得行政服务的“门槛”过程化,论述了包括申请、交互、等待、审批等多个步骤和“准入”的组织规则。
行政负担会加剧社会不平等,繁琐程序会破坏政治效力和公民参与,为了降低行政负担,政策制定者需要降低目标对象的学习和合规成本,并以最小的心理成本构建互动[8]。廖福崇提出通过简政放权、放管结合、优化服务来消解行政负担[8]。为了减轻个人与行政组织交互过程中承受的行政负担,一些政府机构在其网站上设置了智能客服作为改善公共服务的辅助手段。但是此类设置是否真正降低了行政负担,还是又增加了新的数字负担,这还依赖于智能问答服务的质量,尤其是基于系统语义理解能力的对话质量和问题解决能力。因此,根据行政负担理论和门户网站的“准入”流程,可以从中“逆推”出一些评价指标,如系统的问题解决能力、性能、智能、界面设计,以及信息的准确性等。
2.2 政务信息服务质量评价
政务智能问答本质上是一种政务信息服务。信息服务是一种通过研究用户、组织用户、组织服务将有价值的信息传递给用户,最终帮助用户解决问题的服务活动[19]。一些研究通过对信息服务要素的拆解建立相应的评价体系,如胡昌平[20]借助ISO9000质量标准建立了信息服务技术质量认证指标体系,包括服务技术条件与设施质量、服务过程质量、服务效用质量三个维度,分别评价信息服务的基础建设、系统交互与信息质量三个方面。政务信息服务是指政府部门通过官方媒体、政府网站、行政许可中心、图书馆、档案馆多种渠道满足公众信息需求的活动,包括信息告知、主动信息公开、依申请公开、数据开放等方式。王芳等构建了地方政府网站信息公开的评价指标体系,包括公开内容、公开方式、监督保障、信息安全、信息组织、信息表达方式、互动交流等七个维度[21];之后又从用户视角构建了政府数据质量评价指标体系,包含数据源、数据集、数据环境三大维度和可靠性、规范性、真实性、准确性、适配性等15个指标[22]。
2.3 智能问答系统测评研究
问答服务广泛应用于电子商务、知识社区、医疗健康等场景,主要包括以机器智能为主的智能问答和以人类智能为主的社区问答两大类。政务智能问答系统的主要功能是为公众提供政务信息咨询服务,其评价不仅涉及信息服务质量评价、智能问答系统测评,而且也有必要借鉴社区问答系统(例如知乎)评价和电商平台智能客服评价的相关研究成果。
(1)智能问答系统测评
“智能问答系统”测评研究最早可追溯至上世纪50年代的“图灵测试”[23]。经过半个世纪的发展,针对智能系统的测评可分为问题解决能力、回复质量、用户易用性、场景适用性四个方面。
在问题解决能力方面,1999年举办的TREC(文本检索会议)首次引入“问答测评”(简称QAtrack)环节以测评检索系统的问题解决能力。QAtrack将MRR(Mean Reciprocal Rank,是将标准答案在系统给出结果中的排序取倒数作为它的准确度,再对所有问题取平均得到的指标)、准确率(Accuracy)、置信权重分数(CWS)作为主要评价指标。吴友政等据此建立了汉语问答系统测评平台(简称EPCQA),采用MRR、事例召回率、事例准确率、片段召回率以及片段准确率等指标来测评问答系统的性能[24]。Noraset等基于维基百科知识库构建了能够回答泰语问题的问答系统“WabiQA”,主要指标有准确率、召回率以及F1值[25]。
在回复质量方面,问答系统评价常常借用机器翻译的评价指标。例如2002年IBM研发的BLEU系统以词重叠度来测评回复生成质量,认为回复语句与参考答案之间的词语共现次数越多则回复生成质量越高[26]。在BLEU基础上改进的METEOR系统,运用WordNet计算特定的序列匹配、同义词、词根和词缀、释义之间的匹配关系作为测评指标[27]。在词重叠度的基础上,也有学者通过计算词、句相似度来测评回复生成质量,如Greedy Matching、Embedding Average、Vector Extrema等基于词向量的方法[28]和句子语义相似度方法[29]。
在用户易用性方面,腾讯AI Lab的李菁等人构建了一个大规模人工标注中文对话数据集,而后邀请专业人员根据系统回复的相关性、连贯性、信息性、趣味性等指标对文本数据进行五级评分[30]。Roque等借助可用性测试量表,邀请17位医护人员与患者对智能问答系统所回复的伤口处理相关信息质量进行评价,指标主要包括学习性、效用性、记忆性、容错性以及满意性[31]。
在场景适用性方面,Diekema等对航天工程问答系统进行了多维度评价,指标包括系统性能(速度、可靠性)、答案质量(完整性、精确性、相关性等)、数据库内容(数据源质量、规模、时效性)、用户交互(文本理解能力、问题格式化能力等)和用户期望[32]。顾丽燕等根据用户满意度、运营状况、智能水平和技术先进性4个维度对不同的智能客服机器人进行了场景对应评价,其中用户满意度指标包含问题解决率以及答案满意率,两指标均需用户主观评价[33]。
(2)电子商务智能客服相关研究
电子商务智能客服得到较为深入的研究,尤其是用户视角的实证研究,可以为政务智能问答服务评价提供借鉴。王旭勇从客服管理投入的视角构建了企业智能客服评分指标体系,包括客服服务投入程度、客服服务知识管理水平、新型技术应用等维度[34]。宋双永等提出智能客服在解决客户高频业务问题的同时,也需要提供类人服务以提高客户整体满意度,包括用户情感检测、用户情感安抚、情感生成式语聊、客服服务质检、会话满意度预估和智能人工入口[35]。宋倩茜与马双发现,随着技术的不断升级,人工智能在反应速度、回答问题的准确性上有很大提升,在功能价值和体验价值方面与人工客服的差距正在变小,但在给予顾客情感价值方面仍有较大差距[36]。吴薇等发现拟人化、AI精确性、AI灵活性、AI及时性和AI可靠性可提升消费者的认知满意度或服务绩效确认[37]。吴继飞等发现,消费者认为智能客服在不确定性高的需求状态下更缺乏能力,进而导致智能客服厌恶效应,通过赋予智能客服应对不确定性能力的策略,可以有效削弱厌恶效应[38]。
(3)社区问答服务测评
社区问答平台的回复者主要是掌握专业知识的个人,目前也在尝试使用智能客服,其信息质量受到问题本身及回复者等多方面因素影响。社区问答研究中关于回复信息质量的评价指标对于本研究有一定的借鉴意义,比如:李翔宇等[39]构建的社区问答回复质量评价指标体系中的内容维度与认知应用维度;沈洪洲等[40]发现文本长度、情感强度、标记数量三个指标与用户满意度正相关;沈旺等[41]提出的社会化问答信息可信度评价模型包含的信息源、信息内容和结构、媒介三个维度。Zhu等[42]针对Answerbag构建的回复质量评价指标体系,包含简明性、易读性、完整性、相关性、真实性、文明性和信息量七个指标;鲍时平[43]从文献中归纳出社会化问答平台质量评价体系,包含平台设计、平台运行、信息内容、信息服务四个维度和16个三级指标。
2.4 政务智能问答系统的语义理解能力
智能问答系统可分为开放领域问答系统和限定领域问答系统[44]。开放型智能问答系统不限制对话主题范围,如ChatGPT、“小度”聊天机器人、科大讯飞聊天机器人等;而限定领域问答系统则主要为提问者解决特定领域的问题,如订票助手、电商客服等。与ChaGPT等聊天机器人相比,限定领域问答系统对于专业性和准确性都有更高的要求。政务智能问答系统是一类针对公共服务事项的限定领域问答系统。例如,哥伦比亚政府采用FAQ文档库、本体扩展词、语义网以及EuroWordNet等技术为公众提供政务咨询[45];广州市政府信息化中心推出的智能服务机器人云平台系统,可以实现多轮会话以及模糊问题引导[46]。
政府网站的目标用户覆盖面广泛,受教育水平、信息素养以及对政府事务的了解程度各不相同。为降低用户使用政府网站智能问答系统的行政负担,需要不断提高系统的语义理解能力。智能问答系统涉及自然语言理解(NLU)、状态跟踪器、对话策略、自然语言生成(NLG)等技术[47]。其中,NLU是体现问答系统语言与逻辑智能的关键,其下游任务有检索、问答等[48-49]。NLU技术包括共指消解、命名实体识别、文本推理、情感感知、知识推理等多种任务[50]。在政务智能问答实践中,用户的知识背景与表达习惯存在个体差异,最终输入到问答系统的语句具有明显的口语化特征[51]。这些口语化的语言表达不一定符合逻辑和语法规则,而且掺杂了许多无用词汇,为智能问答系统的答疑制造了障碍。
衡量系统是否真正理解用户意图的最直接标准是在接收用户信息后能否通过反馈答案达到用户的指定目标[52]。政府网站智能客服系统的主要目的是理解和满足用户的政务咨询需求,因此需要具备同义文本理解、上下文感知、自动纠错、多语种翻译等能力。王友奎等[4]采用模拟用户的方法,利用测试关键词与问句对我国政府网站问答系统的知识储备进行了测评,发现整体上仍处于起步和摸索阶段。为了进一步评估政府网站智能问答系统的语义理解能力,本研究依据系统对不同类型语言问题的解答情况来判断其语义理解能力。由于各网站后台对所采用的自然语言理解技术进行了加密管理,无法得到具体的技术细节,因此本文将按照语言学规则编制相应问题,通过不同类型的问题测试结果反推政府网站智能客服的语义理解能力。
3 政府网站智能问答系统评价指标体系构建
评价指标体系的构建过程一般包含指标提取、指标体系构建、指标权重确定、评价测试四个阶段。政府网站智能问答系统的评价指标来源主要为文献分析和案例研究。首先,对相关文献和理论进行分析,从中提取相关指标(见表1);其次,对省级政府门户网站的智能问答系统进行初步调查,根据试用体验选择3个系统进行案例分析,提取可用指标;再次,借助德尔菲法,根据各指标内涵进行取舍合并和归纳分层;第四,运用AHP层次分析法、专家调查、小组讨论等方法确定各指标权重;第五,构建部分指标的测试题集;最后,对指标体系进行评价测试。
3.1 政务智能问答系统评价相关指标提取
3.1.1 文献指标提取
通过文献分析初步选取24个指标,根据指标的隶属关系将其划分为系统、信息、用户三大类,如表1所示。
3.1.2 案例指标提取
为进一步贴合政务咨询的应用场景,对现有30个省级政府网站的智能问答系统进行试用体验,对表现优异的系统进行案例分析,将其服务功能转化为评价指标。根据准入理论,按照“使用前-使用中-使用后”的顺序记录试用体验。依据试用结果,选取上海(政务助理小申)、浙江(智能客服小浙)、广东(智能问答平台)三个便捷性高、服务意识强的系统作为典型案例。通过对案例系统试用记录进行编码分析提取评价指标,如表2所示。

表2 案例指标提取Table 2 Extracting Indicators from Cases
3.2 基于行政负担理论的指标分析
政府利用数字技术的目的是通过自动化、智能化、替代等具体方式降低公民行政负担,但如果技术使用不当也会导致行政负担不降反升[6]。为降低用户使用政务智能问答系统的学习成本,系统需要快速、准确地理解用户含糊、不完整或不准确的提问;为降低用户因使用系统的合规成本,需要尽可能缩短系统反应时间,提高交互效率;为降低用户的负面情绪与心理成本,需要通过友好、人性化的交互设计和富有情感的信息表达改善用户体验。基于行政负担理论对评价指标进行分析和归纳,结果如表3所示。其中,上下文感知、同义理解、自动纠错、多语种翻译等指标反映了系统的语义理解能力。

表3 基于行政负担理论的指标分析Table 3 Indicator Analysis Based on the Theory of Administrative Burden
3.3 指标分层
用户向智能问答系统提问的过程实质上是人机交互的过程,因此对问答系统的评价应该在关注语义理解能力的同时,关注用户体验。将所提取的指标进行整合、取舍和分层,最终形成以降低用户行政负担为目标的“问题解决质量”“服务交互质量”与“基础建设质量”三大维度,如图1所示。其中,“问题解决质量”最为核心,旨在降低用户的合规成本,对应了回复信息的质量与效率;“服务交互质量”对应用户与客服的交互过程,用于衡量系统的交互能力,旨在降低用户的学习成本和心理成本;“基础建设质量”用于衡量系统建设情况,旨在降低用户的学习成本、心理成本和合规成本。其中,B1问题解决质量与B3基础建设质量都需要系统的语义理解能力给予支撑。

图1 政府网站智能问答系统评价维度Fig.1 Evaluation Dimensions of the Intelligent Q&A Systems on Government Websites
3.4 指标权重确立
权重可以有效衡量各指标对于评价总目标的贡献程度,体现评价的价值导向作用[56]。本文结合层次分析法(AHP)和专家调查法确定一级指标和二级指标的权重,三级指标权重则通过案例分析与小组讨论予以分配。
3.4.1 专家调查
运用层次分析法(AHP)建立指标递阶层次结构,通过 Saaty 的“1-9 标度法”构建判断矩阵,邀请相关专家对各层次要素进行两两比较评分。评分专家来自高校电子政务或信息系统领域、政府信息化或业务部门以及互联网企业产品业务领域。共计发放专家调查表24份,收回20份。利用在线分析软件SPSSPRO对20位专家构建的80个判断矩阵进行一致性检验,有14位专家的评分通过了一致性检验,通过率达70%,表明由此确定的权重值可行性较高。
3.4.2 权重计算
以14份有效调查结果计算指标权重。首先,计算14位专家权重评分的算术平均值,得到层次单排序结果。通过加权得到最终的层次总排序计算结果,如附录1所示。三级指标涉及特定领域的问题与功能,在专家尚未对实际政务问答系统案例进行分析时,难以对细化指标权重做出合理赋值,所以采用案例分析与小组讨论的方式确定三级指标的权重。在此过程中,3名讨论小组成员均为南开大学政府大数据课题组成员,该课题组具备15年以上电子政务领域的理论研究基础与实践调查经历。在正式讨论之前,3名小组成员分别挑选了10个省级政府网站中的智能客服系统进行深度试用体验,结合专业知识根据不同的表达习惯对五种类型的问题进行初步测试,同时记录各系统的附加功能情况。在试用结束后,3人将试用情况汇总,进入集体讨论环节。讨论结果认为应当结合系统的实际表现与问题类型出现的频率,对C1对应的五个三级指标进行权重确定,讨论过程如表4所示:

表4 小组讨论分析过程Table 4 The Process of Group Discussion and Analysis
考虑到纠偏能力以及交互回复能力虽然能更好地体现系统语义理解能力,但在实际的案例体验中小组成员发现多数系统语义理解能力不强,若将错误型、省略型问题权重设置过高将拉低整体测评水平。最终,将C1的三级指标权重做如下排序:高频型问题>同义型问题>错误型问题>省略型问题=英文型问题。同时,通过对不同问题个数的设置进行指标权重的区分:共设置问题100个,其中高频型问题60个,同义问题20个,错误式问题10个,省略式问题5个,英文问题5个。
在指标C3“信息质量”中,基于目的性和效用性原则,3位成员均认为信息完整性远比信息规范性重要,外加在本研究中完整性指标比规范性指标更具可测性,故将完整性权重设置为80%,规范性权重设置为20%。
在指标C7“功能建设”中,小组成员认为“地区导航”与“热点服务”分别有利于用户具体化、便利化解决问题,故两者权重可划为等同,而具备使用说明对于用户使用系统起到重要的引导作用,可以减少用户的试错成本,其重要性同样不可忽视。输入联想功能虽然可以帮助用户快速输入问题,但该功能属于“锦上添花”型功能,系统若不具备,用户可以手动录入。基于上述考虑,作者将“具备使用说明”“地区导航”“热点服务”三者权重均设置为30%,“输入联想功能”设置为10%。
在指标C8“系统性能”中,运行稳定性强的系统可以保障用户的交互体验,终端兼容性强的系统可以允许用户在移动设备中进行提问,二者难分伯仲,故将其权重均设置为50%。
最后,二级指标C2、C4、C5、C6、C9下各仅包含一个三级指标,故直接继承上级指标权重。由此,全部指标权重设立完成,形成完整的政府网站智能问答系统评价指标体系,共计3个一级指标,9个二级指标和18个三级指标,如表5所示。
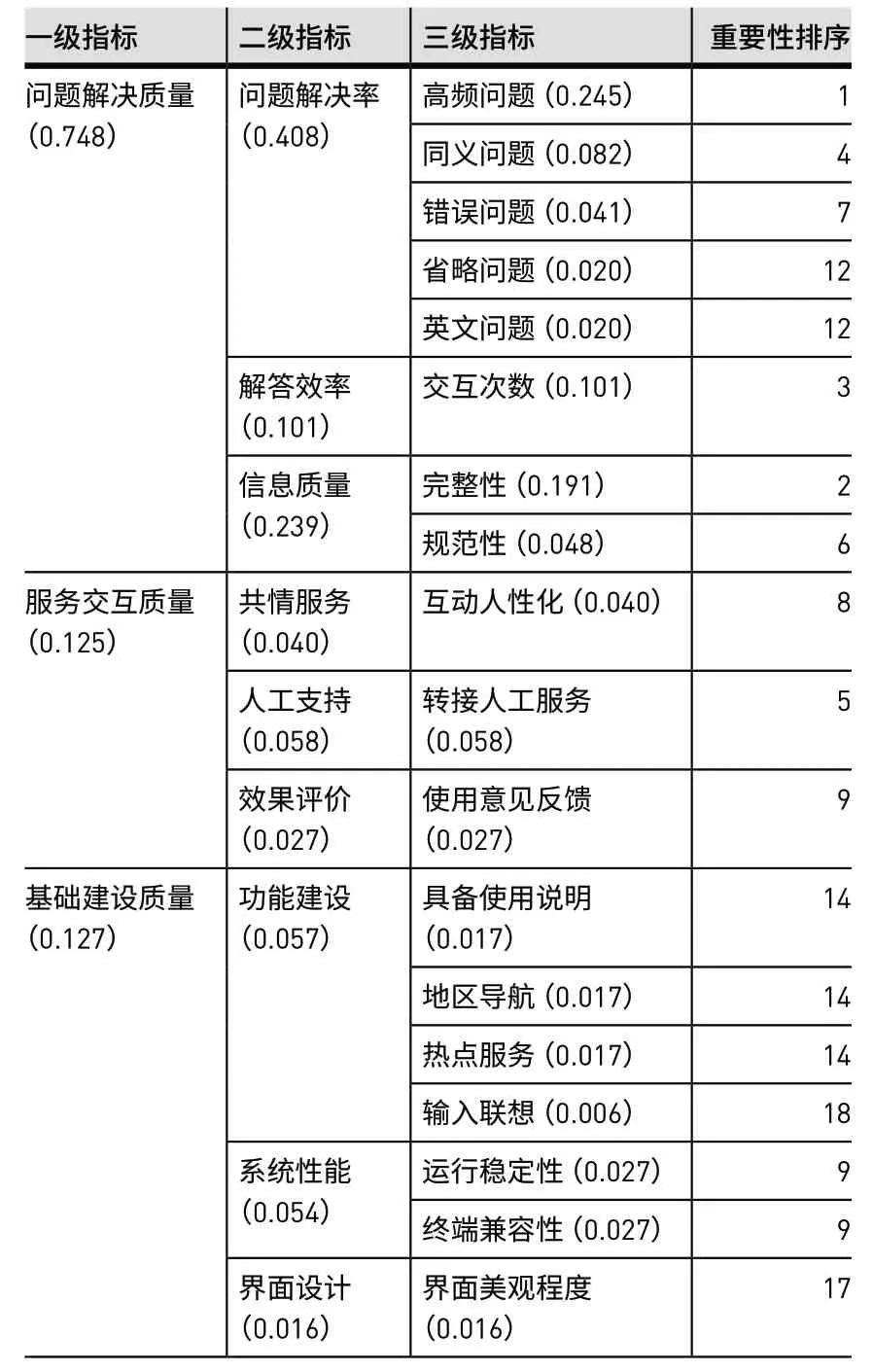
表5 政府网站智能问答系统评价指标体系Table 5 The Evaluation Index System for Intelligent Q&A Systems on Government Websites
4 测评问题的编制
如表5所示,问题解决质量是问答系统评价的首要目标,而语义理解能力则是提高问答系统问题解决质量的关键所在。在进行实际测评的过程中,问题解决质量维度的指标主要通过构建测试题集进行客观评分。为了从同义文本理解、自动纠错、上下文感知、多语种翻译等多个方面测评智能客服的语义理解能力,构建五种不同类型的问题,包括高频问题、同义问题、错误式问题、省略式问题和英文问题五类。服务交互质量和基础建设质量两个维度的评分主要是评分者在测评过程中,通过观察、测试和分析比较进行评分。
4.1 高频问题的编制
本文将“高频问题集”定义为含有高频政务事项主题词的标准化问句集合。因无法获取各系统后台的知识库数据,也难以穷尽公民的全部咨询事项,因此通过获取高频政务事项主题词的方式构建政务咨询问题,从对高频问题的解答质量来推断系统知识库储备的丰富程度。高频问题集的制作思路如下。
首先,使用八爪鱼数据采集软件,爬取山东、江苏、上海、贵州等26个省级政府网站的公民留言板、市长邮箱共7,632条原始数据,剔除空值及字符数小于3的文本后,保留7,021条数据。随后利用“微词云”在线分词工具对7,021条数据进行分词处理并构建词库。与此同时,选取23个具备问题推荐模块的政府网站智能客服系统,通过人工下载的方式获取全部推荐问题文本,进行分词处理并构建词库。通过人工筛选的方式去除无实义动词和名词。将两个词库中的高频政务词语进行对比,重复率接近75%。由此判断,政府网站上公民留言的高频问题与智能客服推荐的用户常问问题具备较高相似度,利用公民留言的政务词语进行问题编制具备代表性和一定的补充作用。
按照词频将最高频的60个主题词作为问题构建的关键词。随后,将60个关键词作为查找项分别在国务院提出的全国高频政务服务事项清单、济南市100项高频事务清单等7份高频政务事项清单中进行对比,重合率接近88%,以此对高频词选择结果进行二次验证。提取高频事项清单中的对应事项,改编成高频问题集,排名前21的高频问题见表6。

表6 排名前21的高频问题汇编表Table 6 The Top 21 High-frequency Questions
4.2 同义问题编制
因不同用户存在知识水平与表达方式的差异,外加部分系统不能提供规范的提问句式,因此有必要模拟这类应用场景进行同义问题的编制。根据用户对咨询事务描述的清晰程度进行同义改写,将其划分为表述清晰、表述欠妥、表述模糊三个等级:
(1)表述清晰的问题:表现为用户可以明确具体的办理事项,同时能够用精简的语言表述自己的咨询需求,上文中编制的标准化高频问题均属此类。然而在实际中,用户往往因用词习惯不同,易将同义不同形的术语或概念使用到提问中,但其目的均是对相同问题进行发问[57]。在政务事项中,该现象主要集中在政务名词或动词的同义替换方面,如:Q1:“怎样申领建筑施工企业安全生产许可证?”与Q2:“怎样申领建筑施工企业安许证?”,两问句的区别在于“安全许可证”与“安许证”,后者为前者简称,两者形异义同。再如Q3:“如何补交住房公积金?”与Q4:“如何补缴住房公积金?”,两者的差别在于实义动词“补交”与“补缴”形异义同。
(2)表述欠妥的问题:表现为用户知悉要办理的政务事项,但用词构句欠妥。例如Q5:“非机动车如何登记?”与Q6:“电动自行车如何登记?”,Q5的“非机动车”与Q6的“电动自行车”为包含关系,但用户可能会根据自身实际情况使用“电动自行车”进行提问。
(3)表述模糊的问题:表现为用户仅仅明了自身问题,但无法清晰表达该问题对应的政务事项。如Q7:“如何对流动人员的人事档案进行接收?”与Q8:“本科毕业后去英国留学,学生档案将如何保管?”,与Q7相比,Q8的提问者难以将留学人员与流动人员对应,其次,学生档案与人事档案的表述相比不够正式。在此类表述不清晰的问题中,用户易引入无用词汇,从而可能导致问答系统的识别错误。通过构建此类问题恰好能测试智能问答系统的精准识别能力。
依据上述三种规则对问题进行同义改编,因不同系统存在差异,在进行系统测试时,尽量保持各类型问题数量与比例的均衡。
4.3 错误式问题编制
错误问题的输入是为了测试智能客服对于错误文本的自动校对能力,包括对文本的自动查错与自动纠偏。借鉴刘亮亮[58]对中文文本错误的分类,以逆向思维对正确问题进行错误式改编。刘亮亮认为中文文本在问答系统中容易出现四类错误,分别为:替换错误、多字错误、缺字错误以及标点错误。替换错误指文本中的某个字被同音或形似字符替代的错误,多字错误指输入过程中某个字重复输入导致的错误,缺字错误则指少字或词导致文本不完整的错误,标点错误则指标点用法不当的错误。经试用体验并结合用户输入习惯可知,前三种错误在实际的键盘输入过程中较为常见,最后一种标点错误虽时有出现,但由于问答系统对该类型错误的感知性较低,故针对前三种错误类型各设置3道改编问题,对最后一种错误类型仅设置1道问题,共编制10道错误式问题。
4.4 省略式问题编制
省略式问题指连续发问、无错误的中文问题,设置该类问题是为了测试问答系统的多轮交互能力。部分用户在使用过程中存在连续追问的情形,但由于个人表达习惯差异,用户容易对追问语句进行省略式输入。其中,零形回指的情形最为常见。零形回指是一种在语义上在前文已出现所指对象,而在形式上却无实在词语的回指形式,是汉语中重要的回指形式之一[59]。例如Q1:“今天上海的天气怎么样?”与Q2:“那明天的怎么样呢?”,两问句建立在衔接语境当中,问句Q2采用零形回指,指代的先行词是Q1中出现的上海天气,故Q2的完整形式应是:“那明天上海的天气怎么样呢?”。要想在该提问方式下获得正确答复,要求智能问答系统具备上下文语境分析的能力,通过对Q1与Q2的综合语义理解,正确识别用户意图。
因政务事项咨询中实义动词至关重要,因此不采用零形回指指代谓语,而只以指代主语与指代宾语的方式构建省略式问题。现针对两种方式各举一例:针对“省略主语”构建问题Q3:“退役士兵有哪些优待政策?”与 Q4:“有哪些安置条例?”。针对“省略宾语”构建问题Q5:“补办身份证的条件是什么?”与Q6:“应当去哪里办理呢?”。
4.5 英文问题编制
编制英文问题的目的是测试智能客服的英文理解能力。虽然中文问题文本字符数较短,但翻译成对应英文问题后,文本字符数超出部分问答系统的字数限制,无法进行测试。为保障测试的一致性,提取中文问题中的主题词,对60个主题词进行翻译,最终以包含政务主题词的英文短语形式进行提问。
基于上述规则构建的问题实例详见附录2。
5 评价指标体系检验
为了检验评价指标体系的可用性,于2022年3月15日至16日对能够正常运行的30个省级政府网站的智能问答系统进行统一测评。交互服务质量与基础建设质量由课题组两位成员依据评分细则进行独立评分,问题解决质量则由两位评分人运用测试题集进行独立评分,之后进行一致性信度检验,并通过协商得到最终评分结果。受篇幅影响,本研究只简要报告测评结果作为指标体系可用性的检验,详细的测评过程另文发表[60]。
经过整体测评,在满分为5分的情况下,30个省级政府网站智能问答系统最终得分位于[0.86,4.10]区间之内,平均得分为2.73,中位数为2.72,以3分为及格线,仅有9地系统达标,不及三分之一(见图2)。其中,上海市以4.10分的成绩位居第一,浙江省以4.07分的成绩次之。上述评价表明结果,本研究所构建的政府网站智能问答系统评价指标体系区分度良好,可以反映政府网站智能问答系统的实际情况,具有较强的可用性。

图2 省级政府网站智能问答服务整体得分排名Fig.2 Score Ranking of Intelligent Q&A Services on Provincial Government Websites
6 结论、讨论与展望
优质的政府网站智能客服系统能够更好地理解公民的政务服务需求,降低咨询服务过程中的行政负担和人工成本。本文通过理论回顾、文献分析与案例研究,构建了政府网站智能客服评价指标体系,并基于专家调查法和层次分析法确定了指标权重。该评价指标体系包括问题解决质量(问题解决率、解答效率、信息质量)、服务交互质量(共情服务、人工支持、效果评价)、基础建设质量(功能建设、系统性能、界面设计)3个一级指标,9个二级指标和18个三级指标,并运用专家调查法和试测评确定了指标权重。该指标体系反映了提高政府网站语义理解能力、降低用户行政负担的评价导向。
同时,针对“问题解决率”指标,本研究依据政府网站常问问题和高频问题推荐,根据用户的表达方式及输入习惯,通过同义、错误、省略、英文转换等四种方式的改写,编制对应的问题,用于测试系统的语义理解能力。对我国30个省级政府网站智能问答系统的评价结果表明,该评价指标体系与测评问题与政府网站的应用场景相适应,能够较为精准地定位现有政府网站智能问答系统在实践中面临的语义理解问题。
需要讨论的是,本研究开始于2021年9月,在论文修改完成之后刚好赶上ChatGPT大热。ChatGPT强大的对话能力对政府网站的智能问答系统提出了挑战,同时也对本研究构建的政府网站智能问答系统评价指标体系的适用性提出了考验,但目前看来并不会影响该指标体系对政府网站智能对话系统的应用价值。首先,与面向通用领域的聊天机器人ChatGPT不同,政务智能问答系统是一种面向特定公共服务领域的机器人,所面临的用户问题具有显著的领域特征,对回复的专业准确性和效率都有更高的要求,而通用聊天机器人的优势则主要在于语言生成,而非专业知识。其次,由于每个地方政府在法规政策和隐性知识积累上具有极大的不同,如果将依据大规模语料训练的ChatGPT应用于地方政府网站或部门网站,则还需要专门语料加以训练。考虑到每一种特定的政策法规并不具有大规模特点,因此面向通用领域的聊天机器人未必适用于地方政府网站。第三,本研究所构建的评价指标体系对于ChatGPT也是适用的,因为ChatGPT的评价也需要对其问题解决率、解答效率、信息质量、共情服务、人工支持、效果评价、功能建设、系统性能、界面设计进行评价和优化。最后,考虑到评价指标体系主要以评价结果、交互质量和基础建设为评价内容,它对非政府网站的智能问答系统评价也具有适用性。
未来,随着政府网站智能问答系统性能的提升,相关的评价研究工作应加强指标的细化,比如在问题解决质量方面加入MRR 评价指标,在均能正确回复的问答系统中凸显差距,实现优中选优的目的。除此之外,研究者可选取更多的测试问题并进行更多样式的改写,也可采取众包的测试方法对受测系统进行更加全面的认知。通过精细化测评,推动政府网站的智能问答系统向着更具智能化、人性化和个性化的方向发展。
作者贡献说明
王芳:研究选题及思路制定,指导研究环节,论文修改定稿;
魏中瀚:研究方案设计,数据获取、标注与分析,实验开展,论文撰写及修改;
连芷萱:参与研究方案设计,数据获取与标注,论文修改。
支撑数据
支撑数据由作者自存储,E-mail:wangfangnk@nankai.edu.cn。
1.王芳,魏中瀚,连芷萱.测试题集.txt.测评问题数据集.
2.王芳,魏中瀚,连芷萱.测评结果.xlsx.30个省级政府网站的智能问答系统测评结果.
附录1
Appendix 1

层次总排序权重计算(保留三位小数)Calculation of Total Hierarchical Ranking Weights(Calculating to Three Decimal Places)A 权重值B1 问题解决质量 0.748 B2 服务交互质量 0.125 B1 层次权重值C1 问题解答率 0.546 C2 解答效率 0.135 C3 信息质量 0.319 B2 层次权重值C4 共情服务 0.321 C5 人工支持 0.465 B1 C1 C2 C3 B2 C4 C5 B3 基础建设质量 0.127 C6 效果评价 0.214 B3 层次权重值C7 功能建设 0.448 C8 系统性能 0.430 C9 界面设计 0.122 层次权重值 问题解答率 0.408 解答效率 0.101 信息质量 0.239 层次权重值 共情服务 0.040 人工支持 0.058 C6 效果评价 0.027 B3 层次权重值C7 功能建设 0.057 C8 系统性能 0.054 C9 界面设计 0.016
附录2
Appendix 2

测评问题改编实例Case of Testing Questions Adaptation
猜你喜欢
数学物理学报(2022年5期)2022-10-09
计算机应用(2018年12期)2019-01-08
商周刊(2018年26期)2018-12-29
文苑(2018年23期)2018-12-14
文苑(2018年19期)2018-11-09
文苑(2018年17期)2018-11-09
文苑(2018年21期)2018-11-09
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
领导决策信息(2017年11期)2017-05-17
集美大学学报(自然科学版)(2015年1期)2015-02-28
