
法律模糊性问题的“解码”与“计算”
2023-12-25 10:18刘东亮
现代法学 2023年6期
刘东亮
(西安交通大学 法学院,西安 710049)
宁要模糊的正确,也不要精确的错误。——[英]凯恩斯
推理就是计算,我们在无声的思维中加加减减。——[英]霍布斯
一、缘起:如何避免对司法解释的再解释
法律语言学的研究表明,明确性和模糊性都是法律语言的固有属性。法律语言的模糊性是一种客观存在,无法完全消除。①有语言学家指出,为了描摹千变万化的客观世界,语言必须具有一定的灵活性。模糊性是灵活性的重要组成部分。法律用语的模糊性,很多时候是基于立法策略上的需要。参见张乔:《模糊语义学》,中国社会科学出版社1998 年版,第38 页;丁建峰:《立法语言的模糊性问题——来自语言经济分析的视角》,载《政法论坛》2016 年第2 期,第19-28 页。即使如莎士比亚剧作《威尼斯商人》中的“一磅肉”这样看似非常明确的表述,实际上也是“血肉模糊”。在现实生活中,某些几乎完全由纯粹的数字构成的用语(如“12月31 日之前”),若未采取适当的立法技术措施,也会引发纷争。②例如,在1985 年的“美国诉洛克案”(United States v.Locke)中,联邦法律规定,土地权利人应当进行初始登记并每年进行更新登记。关于年度更新时间,法律规定,权利人应当在每年“12 月31 日之前”(prior to December 31)向州政府土地管理局提交年度更新登记申请,如果权利人未能满足这些要求,其不合要求的行为“应当不容置疑地被认为是权利所有人放弃了采矿权”。洛克家族向土地管理局提交了初始登记,以后也按照要求每年进行更新登记。但是,1980 年,他们在12 月31 日提交了年度更新申请——按照土地管理局的说法,迟了一天。由于登记申请迟延,政府通知洛克家族其权利被放弃,并随后宣布矿山被没收。这一案件后来上诉到联邦最高法院。详细案情参见 United Statesv.Locke, 471 U.S.84 (1985).法律中的模糊性如此普遍,以至于有人慨叹:法治的理想似乎根本不可能实现。③参见[英]蒂莫西·A.O.恩迪科特:《法律中的模糊性》,程朝阳译,北京大学出版社2010 年版,第1、233 页。
界定法律规范中俯拾皆是的“不确定法律概念”,通常的方法是通过解释明确其含义。因此,无论是法理学还是在部门法领域,对法律解释问题的研究都呈现出相当繁荣的景象。然而,解释总有局限性。解释不能解决所有的模糊性问题。在一般情况下,它甚至不是解决模糊性的最好办法。④参见[英]蒂莫西·A.O.恩迪科特:《法律中的模糊性》,程朝阳译,北京大学出版社2010 年版,第203 页。根据萨维尼的说法,解释是“对制定法内在思想的重构”。⑤参见[德]卡尔·恩吉施:《法律思维导论》,郑永流译,法律出版社2004 年版,第87-88 页。解释很容易偏离立法者的本意(如果真有的话)。而且,解释法律需要考虑四种要素(语法要素、逻辑要素、历史要素、体系要素),据此生成的文义解释、体系解释、目的解释和历史解释等多种解释方法,在选择时并不存在一个“确定的次序”。由此可能造成不同解释主体“公说公有理,婆说婆有理”,进而引发更多的纷扰。⑥参见苏力:《解释的难题:对几种法律文本解释方法的追问》,载《中国社会科学》1997 年第4 期,第12 页。
为了减少实践中大量的“对司法解释的再解释”现象⑦关于“司法解释的再解释”,参见韩耀元、王文利、吴峤滨:《司法解释之再解释若干问题——以近年来的刑法司法解释为视角》,载《人民检察》2014 年第23 期,第18-22 页。另据我们的调研,实践中“对司法解释的再解释”现象相当普遍,各种答复、会议纪要、指导意见等都是“再解释”的变种。,对法律模糊性问题的处理,需要在解释方法之外另辟蹊径。唯有如此,才能避免法律变成“补丁摞补丁的百衲衣”,才能跳出所谓的“明希豪森三重困境”(无休止的解释怪圈),才能防止中国学界重演德国法学曾经陷入的旷日持久的主观解释论和客观解释论之纷争却始终没有最终了断的尴尬局面。⑧参见雷磊:《再论法律解释的目标——德国主/客观说之争的剖析与整合》,载《环球法律评论》2010 年第 6 期,第 39 页;陈坤:《论法律解释目标的逐案决定》,载《中国法学》2022 年第5 期,第183 页。
说到“在解释方法之外另辟蹊径”,实际上已有学者明确提出过这一问题。⑨参见谢晖:《法律的意义模糊及其救济方法》,载《法制与社会发展》2009 年第1 期,第122 页;焦宝乾、赵岩:《法律解释观念的论证转向与方法转型》,载《法学论坛》2022 年第4 期,第28 页。但既有的研究基本上因循传统法律推理和论证的路线,一定程度上仍然是在解释方法的圈子里打转,没有完全走出“解释”的窠臼。
事实上,近年来跨学科方法的兴起已经给研究模糊性问题提供了很多有益的方法论上的启示。以“不确定法律概念”为例,从信息科学的角度很容易理解:概念是对信息的抽象和封装。将封装起来的数据进行信息还原转换成原来的内容,称为“解码”,这是概念形成的逆向工程。“不确定法律概念”含义的确定,即可以通过适当的解码来完成。在计算科学领域,解码属于“计算”的一种形式。不仅如此,按照认知科学的观念,“推理就是计算”。①“计算”不仅仅是数字的加减乘除,在更一般的意义上,计算是信息处理,是对事物表征状态的转换。“推理”是从一个或几个已知命题推出新命题。因而,从认知科学的角度而言,推理和计算是等价的。由于信息不完备造成的模糊性事实,也可以通过“计算”方法来确认,进而作出相对客观的事实判断。维纳(Norbert Wiener)曾经指出,在某种意义上,人脑就是一个控制和计算的装置。②参见[美]N·维纳:《控制论》,郝季仁译,科学出版社2009 年版,第149 页。因而,认知科学认为,人类的思维过程也是一种计算(心智计算)。
法律中的模糊性问题,究竟如何通过“解码”和“计算”方法分析处理,需要先从“模糊逻辑之父”拉特飞·扎德(后文简称扎德)提出的模糊逻辑理论说起。
二、模糊逻辑理论的起源与发展
逻辑学作为专门研究人类思维规律的科学,同其他学科一样,伴随着人类的认识水平经历了一个不断深化发展的过程。其演变的主线可概括为:传统逻辑→经典逻辑→非经典逻辑。③参见余静:《传统逻辑、经典逻辑与非经典逻辑》,载《湖南科技大学学报(社会科学版)》1991 年第1 期,第42-45 页。模糊逻辑作为非经典逻辑的一个分支,其产生是对经典逻辑局限性的突破。
(一)经典逻辑的“软肋”和精确性崇拜
19 世纪的两位伟大学者康德和开尔文曾各自独立提出一个十分相近的方法论命题:只有具有定量研究性质的学科才属于科学。④康德认为,在任何特定的理论中,只有其中包含数学的部分才是真正的科学。开尔文宣称,一门科学如果不是定量的,就不能算是科学。参见苗东升:《模糊逻辑趣谈》,中国人民大学出版社2020 年版,第6 页;[美]M·克莱因:《数学:确定性的丧失》,李宏魁译,湖南科学技术出版社2000 年版,第42 页。这一关于数学工具和定量分析方法的命题,已成为现代科学的基本信条之一。长期以来,该命题蕴含的观点在科学界乃至社会大众中都有广泛的市场。人们普遍尊重精确的、严格的、定量化的事物,贬低甚至蔑视模糊的、不太严格的、定性表述的事物;认为精确总是好的,模糊总是不好的,越精确越好;断言科学的方法必定是精确的方法,相信精确化具有绝对的科学性,科学技术的精确化努力永无止境,等等。有人将这种观点称为“精确性崇拜”(precision worship)。⑤SeeCoping with the imprecision of the real world: An Interview with Lotfi A.Zadeh, 27 Communications of the ACM 304, 311 (1984).“精确性崇拜”有其深层的进化心理学基础。我们生活在一个纷繁复杂而充满不确定性的世界,风险与野性总是在伺机而动。为了生存,人类要像丛林中的动物一样保持警觉。出于降低复杂性、掌控外部世界和自身命运的人类本能需要,对事物的精确化理解成为不确定世界的理性选择。心理学上称这种心理表征为“控制性思维”(controlled thinking)。⑥控制性思维的表现形式是“如果……那么……”。著名心理学家皮亚杰(Jean Piaget)将控制性思维称为“形式运算”的思维。参见[美]雷德·海斯蒂、罗宾·道斯:《不确定世界的理性选择——判断与决策心理学》(第2 版),谢晓非、李纾等译,人民邮电出版社2013年版,第3 页。
科学推理是控制性思维的一种原型。在常规科学时代,人们借助于亚里士多德传统逻辑发展起来的经典逻辑(数理逻辑),使用精确方法取得了巨大的成功。人类得以趾高气扬地俯瞰周围的世界,吹嘘自己掌握了宇宙的许多秘密(实际上是一系列数学定理)。①参见[美]克莱因:《数学:确定性的丧失》,李宏魁译,湖南科学技术出版社2000 年版,第2 页。无疑,这反过来进一步强化了精确性崇拜。精确性崇拜在有着“法国的牛顿”之称的数学家、天文学家拉普拉斯那里达到了高潮。他放言:只要有适当的参数,就可以计算出宇宙包括其中任何一个原子的过去和未来。②参见[法]P.-S.拉普拉斯:《关于概率的哲学随笔》,龚光鲁、钱敏平译,高等教育出版社2013 年版,第4 页。这一论断被称为“拉普拉斯之妖”。然而,到了20 世纪20 年代,海森堡等人提出的“不确定性原理”(又称“测不准原理”)粉碎了“拉普拉斯之妖”的虚幻缥缈:不可能同时精确地测量出一个粒子的位置和动量。量子力学上著名的思想实验“薛定谔之猫”所揭示的“生—死的叠加态”,更直接暴露出经典逻辑(二值逻辑)的局限性:在“真”“假”之外,可能存在第三种状态。③“经典逻辑”或称“古典逻辑”,与“传统逻辑”或“亚里士多德逻辑”相对应。经典逻辑是二值的命题演算与谓词演算,即狭义的数理逻辑。经典逻辑或数理逻辑是二值逻辑。在经典逻辑中,任何命题的值要么为真,要么为假,不存在第三种情况。因此,经典逻辑属于“二值逻辑”。参见余静:《传统逻辑、经典逻辑与非经典逻辑》,载《湖南科技大学学报(社会科学版)》1991 年第1 期,第43 页。
事实上,即使没有“测不准原理”或“薛定谔之猫”这些科学理论的解说,仅凭常识和观察,生活中的经验也能够让我们知晓:世界不是简单的非黑即白,而是有许多灰色地带,模糊性普遍存在。虽然经典逻辑以其严格性、精确性和无歧义性显示出逻辑数学化、形式化的强大威力,但是其内在的局限性使得其无法处理现实世界的许多复杂问题。必须引入三值逻辑、多值逻辑,甚至是无穷连续值逻辑,人类的思维才能够跳出“非此即彼”的藩篱。
(二)模糊性:不确定性的主要来源
如前所述,我们生活在一个纷繁复杂而充满不确定性的世界。在常规科学时代,人们相信确定性是科学的本质。从20 世纪20 年代开始,随着后常规科学时代的来临,人们越来越认识到,科学同时具有两个截然相反的特征:确定性与不确定性。并且,与确定性相比,不确定性更接近科学的本质。20 世纪30 年代的哥德尔不完备性定理进一步表明,不仅过去备受推崇、被认为公理化的演绎方法存在缺陷,就连作为自然科学定量分析之基础的数学本身也宣告了确定性的丧失。④参见[美]克莱因:《数学:确定性的丧失》,李宏魁译,湖南科学技术出版社2001 年版,第4 页。
归根结底,不确定性源于复杂系统的非线性特征。有人说,不要以为在土里插一支温度计,就能测量出整个地球的温度。相比之下,人类社会比地球的结构更为复杂。即便是牛顿,也无法写出一个能解释就业水平、选举结果或犯罪率下降趋势的三变量方程。在当下的信息社会,我们正面临着一个由技术进步引发的悖论:信息传播速度的加快和行为主体做出反应时间的缩短,使得我们在对世界的了解更为深入的同时,世界也变得更复杂,不确定性随之增加。⑤参见[美]斯科特·佩奇:《模型思维》,贾拥民译,浙江人民出版社2019 年版,第12、20、496 页、
一般认为,不确定性的来源主要有三种:随机性、模糊性和信息的不完备性。⑥参见王永庆:《人工智能原理与方法》(修订版),西安交通大学出版社2018 年第2 版,第156 页。随机性是指某个事件在未来发生或者不发生,事前无法确定。最典型的随机性是抛硬币,正面朝上还是反面朝上都有可能,抛掷之前难以准确预言。①但也有研究表明,抛硬币是一个预先确定的机械过程,它并不是真随机的。参见[英]伊恩·斯图尔特:《谁在掷骰子? 不确定的数学》,何生译,中国工信出版集团、人民邮电出版社2022 年版,第55 页。处理随机性的有效工具是概率论。不过,在法律领域,基本上不涉及随机性,需要用概率论处理的问题多源于信息的不完备性,例如,刑事诉讼的“排除合理怀疑”和民事诉讼的“盖然性规则”等,它们要处理的事实是发生在过去的事实,与随机性无关。
在理论上,随机性是事物的一种内在特性,但是在现实生活中,绝对意义上的真随机现象几乎无法遇到。易言之,很多看似随机的现象,实际上是由信息的不完备性造成的。②有人认为,大多数随机性都是“反知识”,它们把世界隐藏在迷雾中。真正的随机性只存在于量子世界。参见[美]纳西姆·尼古拉斯·塔勒布:《黑天鹅:如何应对不可预知的未来》,万丹、刘宁译,中信出版集团2019 年版,第213 页。虽然从性质上来说,信息是普遍存在的,在整个宇宙时空中,信息是无限的,即使在有限的空间内,信息也是无限的,但信息同时具有相对性,囿于认识主体的认知能力和采集手段的限制,实际能获得的信息都是有限和不完全的。③参见钟义信:《信息科学原理》,北京邮电大学出版社2013 年第5 版,第85 页。
信息的不完备性造成人们对事物的认识不充分或者模糊不清。与随机性和信息的不完备性不同,模糊性源于事物的类别归属不明。一个具体对象是否属于某个抽象概念常常不能明确判定,因为很多事物之间并非泾渭分明,而是存在一系列的过渡状态。例如,白天和黑夜之间不存在一条截然的分界线,《中华人民共和国行政强制法》(后文简称《行政强制法》)上规定的“夜间”(该法第43 条禁止“夜间”采取强制执行措施)因而成为典型的“不确定法律概念”。某个具体时间点究竟是否属于“夜间”,有时会产生认定上的困难。④以“《行政强制法》第四十三条”和“夜间”为关键词检索中国裁判文书网可以找到的裁判文书有318 篇(检索时间:2023 年5 月24 日)。其中很多争议围绕凌晨四点、五点或六点是否属于“夜间”,后文详论。
与其他两种原因相比,模糊性是更普遍的不确定性之来源。倘若把由于信息的不完备性所造成的认识上的模糊也视为模糊性的话,那么可以认为,不确定性主要指的就是模糊性。特别是在法律领域,不确定性基本上等同于模糊性,包括法律语言的模糊和待证事实的模糊。前文指出,法条上的“不确定法律概念”俯拾皆是,这种“不确定”指的是法律语言的模糊。待证事实的模糊,则是指由于信息的不完备性(证据不充分)所造成的诉讼认识上的模糊。它们共同织就了法律程序中的“重重迷雾”。
众所周知,从17 世纪法国数学家帕斯卡、费马等人对博弈游戏的研究开始,关于随机性的数学理论——概率论与统计学的发展至今已经相当成熟。与其相比,研究模糊性问题的模糊逻辑理论则时间较短,目前仍处于发展完善的过程当中。
(三)模糊逻辑理论的产生与发展
1923 年,英国哲学家罗素(Bertrand Russell)在《论模糊性》一文中指出,所有的语言都是模糊的,我们所有的认识也都是模糊的。模糊性无处不在,差别仅在于模糊的程度。⑤参见[英]伯特兰·罗素:《论模糊性》,杨清、吴涌涛译,载《模糊系统与数学》1990 年第1 期,第16-22 页。针对著名的“秃头悖论”,罗素指出传统逻辑的排中律不适用于模糊概念,从哲学和逻辑上为模糊理论作了铺垫。①“秃头”是一个模糊概念。秃头和非秃头的划分,并非由哪一根头发起决定性作用。因而,“秃头悖论”并不真实存在。与“秃头悖论”一样著名的是所谓的“谷堆悖论”。这类悖论被称为“连锁悖论”。在此类由演绎推理而导致的悖论中,一个前提的轻微不精确,经过一连串推理被放大,最后会得到荒谬的结果。参见陈波:《思维魔方:让哲学家和数学家纠结的悖论》,北京大学出版社2014 年版,第65-72 页。该文因此在模糊理论发展史上有重要意义。不过,罗素的研究虽然在前,但其工作主要是对模糊性的哲学论述,还未涉及模糊性的具体刻画,因而尚不能算是模糊逻辑产生的标志。②罗素的讨论引出了多值逻辑问题,但多值逻辑本质上还是精确逻辑,跟模糊逻辑有质的区别。罗素之后,1937 年,美国量子哲学家布莱克在《科学哲学》杂志上撰文《模糊性:逻辑分析的一个练习》,在模糊性的定量化、形式化描述道路上迈出重要一步。在布莱克之后的30 年中,学术界对模糊性的探索基本处于停顿状态,直到1965 年扎德的著名论文问世。参见苗东升:《模糊逻辑趣谈》,中国人民大学出版社2020 年版,第26-27 页。
1965 年,加州大学伯克利分校电气工程与计算机科学系教授扎德发表《模糊集》一文,揭开了模糊逻辑理论的序幕。③See L.A.Zadeh, Fuzzy sets, 8 Information and Control 338, 338-353 (1965).扎德指出,在现实生活中,很多事物和对象,例如“高个子”“漂亮的姑娘”等等,这些外延不明确的模糊概念很难用传统的普通集合进行描述。因为,普通集合的特征函数仅能取两个值(0 和1),论域(作为科学研究对象的一个非空集合)中的任何一个对象(元素)与集合之间的关系只能是属于或不属于的关系,这种在19 世纪后期发展起来的康托尔集合论(Cantor’Sets)不能处理广泛存在的模糊性问题。
从表征普通集合的“特征函数”中得到启发,扎德创立了他称之为“模糊集合”的理论。在模糊集合中,一个对象是否属于某集合的特征函数可以在[0,1]中取值,从而突破了传统的二值逻辑的束缚。易言之,模糊集合理论的核心思想是把取值仅为1 或0 的特征函数扩展到可在[0,1]中任意取值的隶属函数,并把取值称为某元素对集合的隶属度。而特征函数取值为1 或0 的普通集合,可视为模糊集合的一个特例。扎德的这一创举使人类获得了一种新工具,使原本被认为含混不清、难以捉摸的模糊事物有了对之进行数学描述的可能。因此,尽管扎德当时尚未明确提出模糊逻辑的概念,但这篇论文为模糊逻辑奠定了必要的数学基础,因而被广泛认为是模糊逻辑理论的“初试啼声”。④1966 年,贝尔实验室科学家马里诺斯(P.N.Marinos)在其工作论文“Fuzzy Logic”中首先使用了模糊逻辑一词。See P.N.Marinos, Fuzzy Logic, Bell Telephone Labs, Inc., Holmdel, New Jersey, Tech.Memo.66-3344-1 (August 1966).
在该文中,扎德还提出了模糊关系的重要概念。在现实世界,很多事物之间的关系并不十分明确,无法简单地用“有”或“没有”来衡量,而需要考虑有关系的程度,这种关系即模糊关系。也就是说,模糊关系是把关系概念扩展到模糊集,用以表示事物之间相关的程度如何。模糊关系在现实生活中非常广泛,如身高与体重、文化程度与犯罪率、体育活动与健康水平,乃至气候、食物、生活方式和生育率等等之间都存在模糊关系。
模糊集理论揭示了事物性质的渐变性和模糊关系的广泛性,它的产生具有划时代意义。不过,尽管其思想十分新颖独特,但扎德的论文起初并未引起太多关注。直到20 世纪70 年代,由于人工智能研究的蓬勃兴起,需要从技术上处理很多传统方法不能解决的不确定性问题,模糊逻辑才迅速成为一个热门的研究领域。
(四)模糊推理(近似推理)的基本方法和特征
在扎德提出模糊集理论之前,使用常规数学对模糊性表示与处理一直存在困难。1973 年,扎德提出一种新方法,用以分析常规数学无法处理的复杂系统和决策过程。该方法有三个显著特点:以语言变量取代或者辅助数值变量;以模糊条件语句刻画变量之间的简单关系;以模糊算法描述变量间的复杂关系。这三个特点构成了模糊推理的基本特征。①See L.A.Zadeh, Outline of a New Approach to the Analysis of Complex System and Decision Processes, IEEE Trans.On Systems, Man and Cybernetics, Vol.1, no.1, 28-44 (1973).
1.以语言变量取代或者辅助数值变量
所谓语言变量,是指以自然语言或人工语言中的词语而非以数字为值的变量。②李连江教授认为,把variable 译为“变项”比译为“变量”更好。“变项”指变化的东西,让人思考变项之“变”;“变量”则会让人专注于“量”的变化。参见李连江:《戏说统计续编:文科生的量化操作指南》,当代世界出版社2019 年版,第204 页。——从这个意义上来说,将“linguistic variable”译为“语言变项”更能说明问题,但本文暂从通行译法。一般来说,文字不如数字精确,这是其缺点,但也是其优点。因为语言变量可以提供一种近似的表征方法,表示那些太复杂或定义不完善而无法用数值描述的现象。
例如,形容词“漂亮”是对人的复杂外貌特征的概括。它可以视为一个模糊集合的标签,表示一个被称为“漂亮”的模糊变量所施加的约束。从这个视角来看,“很漂亮”“相当漂亮”“非常漂亮”等措辞是“很”“相当”“非常”等修饰语(语言算子)在被称为“漂亮”的模糊集上运算的结果。这些修饰语所形成的模糊集合,连同被标记为“漂亮”的模糊集,共同起着描述人的外貌的作用。
语言变量最重要的作用在于,在逻辑推理中,前提和结论的“真”被作为具有不同等级的值来处理,从而得到模糊逻辑。模糊逻辑衡量的是事物真实的程度,而不是我们对事物是否真实的判断。③[英]郑乐隽:《逻辑的力量》,杜娟译,中信出版集团2019 年版,第206 页。易言之,把“真”作为语言变量来处理,承认真值的等级性,所进行的推理即近似推理,这是一种不十分精确但也并非十分不精确的推理方式。④See L.A.Zadeh, The Concept of a Linguistic Variable and Its Application to Approximate Reasoning Ⅰ, 8(3) Information Sciences 199,205 (1975).模糊推理和近似推理是同义语。在法律领域使用“模糊推理”一词,容易产生“葫芦僧判断葫芦案”之嫌,故本文多数情况下特别是在涉及法律问题时使用“近似推理”一词,其他情形则根据具体语境选择使用“模糊推理”或“近似推理”。由于“真”成为语言变量,在经典逻辑中不能容许的不确定性在模糊逻辑中是有意义的。
语言变量的使用为近似推理提供了可能。从信息科学角度而言,语言也是一种模型,是一种我们用于相互沟通的近似值。人脑处理信息的方式就是通过一系列近似值获得的。⑤参见[美]纳特·西尔弗:《信号与噪声》,胡晓姣、张新、朱辰辰译,中信出版社2013 年版,第194 页。在人类认识世界的过程中,“近似”具有普遍性,即便牛顿物理学也是广义相对论的近似。或许可以说,我们如今了解的一切,都只是我们目前尚未完全了解的某种东西的近似。⑥参见[意]卡洛·罗韦利:《现实不似你所见》,杨光译,湖南科学技术出版社2017 年版,第32 页。
语言变量的另一重要功能是连通概率论和逻辑领域。在运用概率论方法时,如果把概率作为语言变量处理,其子集可以是“{完全不可能,几乎不可能,基本不可能,不太可能,或多或少可能,完全不确定,有可能,很可能,非常可能,极有可能,几乎可以肯定}”。①当然,这一模糊语言集实际上是一个连续的无穷元素集,就像白光由七种颜色组成但七种基础颜色中间还有过渡色一样,它们是连续变化的光谱。不过,这个简化为包含11 个元素的离散的、有限元素集,已经足以帮助我们解决现实生活中遇到的各种“可能性”的判断问题。这意味着,用语言变量表示的概率(语言概率)可以取代数值化的概率(…0.6,0.7,…),从而为人类日常生活中广泛使用的“词语计算”“软计算”等概率推理方法提供了基础。
2.以模糊条件语句刻画变量间的简单关系
人脑和计算机的工作原理不同,它不需要(主要是难以)“精确计算”问题的答案。②冯·诺伊曼指出,人脑的语言并不是数学语言,而是统计性质的语言。人类神经系统对精确度的要求并不高。而且,人类是信息的有限能力加工者(limited-capacity processors),人脑在1 秒钟内只能处理大约50 比特的信息量,从而限制了精确计算的可能。参见[美]冯·诺伊曼:《计算机与人脑》,甘子玉译,北京大学出版社2010 年版,第71-77 页;[美]凯瑟琳·加洛蒂:《认知心理学:认知科学与你的生活》,吴国宏等译,机械工业出版社2015 年版,第7 页;[美]赫伯特A·西蒙:《管理行为》,詹正茂译,机械工业出版社2014 年版,第215页。在人类的思维过程中,普遍存在着模糊性,思维的要素主要不是数字而是语言变量形式。诸如,“若A,则B”的模糊条件语句常常用于日常论述,其中,A 和B 都是具有模糊含义的用语。例如,“若苹果红了,则苹果熟了”,“红”和“熟”都是模糊集合的名称,它们之间存在非精确但高度相关的模糊关系。
模糊条件语句可用于简单的模糊推理,即由已知的模糊知识和事实证据推出模糊结论。仍以“若苹果红了,则苹果熟了”为例,这是一条经验法则,可以作为推理的大前提。如果放在我们面前的一个苹果“有点红”(小前提),那么就可以推断出:“这个苹果差不多熟了”(结论)。这里的“有点”“差不多”是模糊化算子或称“模糊语言算子”,其作用是将非模糊集合转变为模糊集合或增加模糊集合的模糊性。扎德将此推理过程用数学方法概括为:先由知识“IF x is A THEN y is B”求出A与B 之间的模糊关系R,然后通过R 与相应证据(x is A’)的合成,求出模糊结论(y is B’)。由于该方法是通过模糊关系R 与证据的合成求出结论,因此被称为“基于模糊关系的合成推理”。③See L.A.Zadeh, Outline of a New Approach to the Analysis of Complex System and Decision Processes, IEEE Trans.On Systems, Man and Cybernetics,Vol.1, no.1:28, 36-38 (1973).在后来提出的词语计算理论中,扎德称这种情形为“模糊约束传递”,即在事实证据(小前提)与规则性知识(大前提)的事实特征相匹配的条件下(存在模糊关系R),前提中的模糊约束传递给结论,结论中的模糊约束再经语言近似(使用语言变量)重译为用自然语言表示的命题。④See L.A.Zadeh, Fuzzy Logic = Computing with Words, 4(2) IEEE Trans.On Fuzzy Systems 103, 105 (1996).仍以“苹果红了”为例,由于作为事实的某个苹果“有点红”,那么,推理结论是这个苹果“差不多熟了”。
由于“若A,则B”这种“if-then”格式的模糊条件语句(人工智能科学称之为“模糊产生式规则”)是一种有效的知识表示方法,很适合表达人类专家的经验性知识,因而被广泛用于各种基于规则的专家系统的构建,进行简单情形下的模糊推理。
3.以模糊算法描述变量间的复杂关系
如果变量间的模糊关系比较复杂,则需要借助模糊算法进行处理。概略地说,模糊算法是模糊指令的有序集合,这些指令的执行可得到特定问题的近似解。对于复杂系统及决策过程,在传统数学方法难以奏效时,模糊算法是获得近似分析结果的工具。日常生活中,模糊算法普遍存在,我们走路、开车、停车、做饭、查找电话号码等,都会有意无意地使用模糊算法。在程序设计、运筹学、心理学、管理学以及医疗诊断等专业领域,模糊算法都有众多应用的实例。
模糊算法包括模糊定义算法、模糊生成算法、模糊关系及行为算法、模糊决策算法等。对于不同的待解问题,模糊算法可提供描述非明晰定义的概念、关系及决策规则的工具。①See L.A.Zadeh, Outline of a New Approach to the Analysis of Complex System and Decision Processes, IEEE Trans.On Systems, Man and Cybernetics, Vol.1, no.1: 28, 38-43 (1973).另参见徐宗本、张讲社、郑亚林编著:《计算智能中的仿生学:理论与算法》,科学出版社2003 年版,第245 页以下。例如,带有可信度因子的模糊推理方法,就是利用模糊关系算法求取推理结论的可信度,为决策提供准备。其推理公式可表示为:
IF(模糊条件)→ THEN(模糊结论) 置信度(b) 0≤b≤1②参见钟义信:《信息科学原理》,北京邮电大学出版社2013 年第5 版,第244 页。
由于模糊算法涉及复杂的技术问题,并非本文讨论的主题,兹不赘述。对法律人来说,最容易理解、也最值得关注的可能要算是扎德的词语计算和软计算理论。
(五)词语计算和软计算:使用语言方法分析复杂的人文系统
前文指出,出于对定量分析方法的推崇,人们一直试图将常规数学方法扩展到包括人文系统(humanistic system)在内的复杂系统的分析,但这种努力始终没有获得明显成效。③人文系统是相对于机械系统而言的。人文系统是受人类的判断、感觉或情感影响较大的系统,例如经济系统、政治系统、法律系统等都是人文系统的典型。单个的人及其思维过程也可以被视为一种人文系统。See L.A.Zadeh, Toward a Theory of Fuzzy Systems,NASA Report,NASA CR-1432 (September 1969).以扎德为代表的学者认识到,人文系统的复杂性排除了运用常规数学(不管是否借助于计算机)分析的可能。这一判断是基于“不相容性原理”:随着系统复杂度的增加,对其作出精确且有效判断的能力相应递减,直至一个阈值,此后,复杂性、精确性与有效性不能共存。④See L.A.Zadeh, The Concept of a Linguistic Variable and Its Application to Approximate Reasoning Ⅰ, 8(3) Information Sciences 199,201 (1975); L.A.Zadeh, A Fuzzy- Algorithmic Approach to the Definition of Complex or Imprecise Concepts, 8(3) International Journal of Man-Machine Studies 249, 250 (1976).这意味着,对于复杂系统,我们可做的,只能是运用近似推理出近似值。
从20 世纪70 年代开始,扎德撰写了关于语言变量及其在近似推理中应用的一系列论文,倡导使用语言方法(linguistic approach)分析人文系统。语言方法的最主要特征是使用一些模糊概念代替度量单位。不难发现,在分析机械系统时,数学方法的效用来自于一套基本的度量单位,用于表示长度、面积、重量、流量、力、热等基本参数。一般来说,人文系统不存在这样的度量单位,这就使得依赖度量单位的数学方法无法适用。但在语言方法中,一些模糊概念起着与度量单位类似的作用。使用语言修饰词,如“很”“十分”“有点”,它们与被修饰对象(基本模糊集)相结合,可以生成其他模糊集(具体的模糊语言值集合),从而使得以近似方法分析人文系统成为可能。
在此基础上,扎德于1996 年发表《模糊逻辑即词语计算》一文,详细讨论用词语取代数字进行计算及推理的方法。扎德指出,模糊逻辑的主要内容是词语计算,模糊逻辑可近似地认为与词语计算等同。之所以需要词语计算,原因主要有两点:其一,当可获得的信息太不精确而无法恰当地使用数字时,词语计算成为必然;其二,如果利用不精确性(近似简化)使问题变得易于处理、获得鲁棒性、降低求解费用并更符合实际时,词语计算也更为可取。①See L.A.Zadeh, Fuzzy Logic = Computing with Words, 4(2) IEEE Trans.On Fuzzy Systems 103, 103-111 (1996).
需要说明的是,扎德的词语计算建立在模糊信息粒化理论基础之上。“信息粒”概念是该理论的出发点。世界是一个整体,但我们对世界的认识,实际上都只是对其中一个片段的截取。很多时候,由于信息采集设备和度量的限制,不能满足对连续性的需求。这时,就需要对信息进行粒化。粒化是把整体分解为部分,把连续的信息离散化并压缩为一个个分立的信息粒。②扎德认为,有三个基本概念构成人类认识的基础:粒化、组织和因果关系。粒化是把整体分解为部分;组织是把部分结合为整体;因果关系则涉及原因和结果之间的联系。See L.A.Zadeh, Toward a Theory of Fuzzy Information Granulation and its Centrality in Human Reasoning and FuzzyLogic, 90(2) Fuzzy Sets and Systems 111, 111-127 (1997).粒化与前文所述“信息的抽象和封装”类似。很多领域都存在信息粒的概念。比如,一个证据既可以看作一个命题集合,也可以视为一个信息粒。从本质上来说,信息粒是数据点的模糊集,这些数据点由于相似性而结合在一起。
一般而言,信息粒都具有模糊的性质。尽管清晰分明的信息非常重要,但在大多数情况下,信息粒都是模糊的。因为人类处理细节、储存信息的能力有限,决定了粒的取值的模糊性始终存在,这是人类信息处理方法的一个特点。在词语计算中,词语即被视为模糊化的信息粒的标签。不过,尽管词语具有模糊性,但其仍然是对世界的描摹和反映。人类能在不确定、不完备信息条件下作出合理决策,这种非同寻常的能力所依靠的正是模糊信息粒化方法。③See L.A.Zadeh, Fuzzy Sets and Information Granularity, in: M.M.Gupta, R.K.Ragade and R.R.Yager, eds., Advances in Fuzzy Set Theory and Applications, North-Holland Publishing Co., 1979, p.433-448.
理解了“模糊信息粒化理论”,就容易理解扎德所说的词语计算的两个核心问题:首先是模糊约束的显示问题,即如何将用自然语言表述的隐含于命题中的模糊约束显示出来。其次是模糊约束的传递问题,即如何将前提中的模糊约束传递给结论。这两个问题解决之后,就可以将推论产生的模糊约束重译为用自然语言表示的命题(结论)。
词语计算的一个基本假设是:信息通过对变量的取值的约束进行传递,并假设信息是由一组通过自然或人工语言表示的命题所构成。④See L.A.Zadeh, Fuzzy Logic = Computing with Words, 4(2) IEEE Trans.On Fuzzy Systems 103, 104 (1996).在一般意义上,如香农所说,信息是对不确定性的消解。⑤这意味着,掌握越多的信息,就越能消除或减少事物的不确定性。See C.R.Rao, Statistics and Truth: Putting Chance to Work,World Scientific Publishing Co.Pte.Ltd., 1997(2nded.), p.161.根据扎德的理论,信息亦可看作对变量的约束。例如,命题“情节严重”通过对变量“情节”的取值约束,传递了关于违法事实的信息。这就意味着,我们熟知的哈特所称的语言的“开放结构”并不是完全开放的,而是同时存在模糊约束。在显示模糊约束时,需要把初始数据集中的命题表示为标准形式,即“p→X isr R”。⑥其中p 是自然语言命题,箭头→表示显示化,X 是受约束变量,R 是约束模糊关系,isr 是变元系词,用来定义R 约束X 的方式。See L.A.Zadeh, Fuzzy Logic = Computing with Words, 4(2) IEEE Trans.On Fuzzy Systems 103, 105-108 (1996).从这些标准形式出发,即可利用模糊逻辑中的推断规则进行从前提到结论的模糊约束传递。①Id, at 108-110.
在不谙于数学的法律人看来,词语计算的过程似乎有些复杂,其实不然。实际情况是,词语计算的数学表达方法使人觉得复杂(数学家则认为这种方法既简洁又精确),真实的人类词语计算过程基本上与数学无关(如前述“苹果红了”的例子),虽然其可以使用数学方法描述和刻画。正如扎德所说,词语计算的原型是人类的心智。该理论的原初意图是设计一种方案,利用计算机对人类的思维进行模拟,以获得问题的“机器解”,进而为运用人工智能方法处理不精确性铺平道路。②Id, at 103, 110.
在词语计算理论的基础上,扎德在1997 年提出了更值得关注的“软计算”理论。在由其主编的《软计算》创刊号序言中,扎德对“什么是软计算”作了解释:软计算是一些计算方法的综合,其核心方法包括模糊逻辑、概率算法、神经元算法以及遗传算法等。这些方法并无优劣之分,它们相互补充而发挥协同作用。③See Lotfi A.Zadeh, What is Soft Computing, Soft Computing, Vol.1, Preface (1997).
软计算理论的产生是因为人们越来越认识到,对现实世界到处弥漫着的不精确性而言,传统计算及硬计算技术都太过执着于追求精确性而不符合人类的实际决策过程。软计算方法允许不精确性、不确定性、真值的等级性及近似表达,因而可以复原或仿效人类在不确定、不完备信息环境下作出合理决策的能力。
软计算是如何进行的呢? 如果对统计学上的贝叶斯法则稍有了解④See ThomasBayes,An Essay towards Solving a Problem in the Doctrine of Chances, Philosophical Transactions of the Royal Society of London53(1763), 370-418.资料来源:https:/ /bayes.wustl.edu/Manual/an.essay.pdf.英国牧师兼业余数学家贝叶斯逝世两年后才发表的这篇论文提出的思想被后人概括为贝叶斯公式:P(A|B)=P(B|A)*P(A)/P(B),亦称“贝叶斯法则”或“贝叶斯定理”。其含义是:P(A|B)表示在现象B出现的条件下,事件A 发生的概率;P(B|A)表示事件A 发生时,现象B 出现的概率;P(A)表示事件A 发生的概率;P(B)表示现象B 出现的概率。简单来说,现象B 出现的情况下事件A 发生的概率,等于事件A 发生时现象B 出现的概率乘以事件A 发生的概率,再除以现象B 出现的概率。有数学家称这个简单公式为“智慧方程”,并认为它是数学中最优美的等式,人类的“理性”本质上可以归结为贝叶斯公式的运用。参见刘嘉:《刘嘉概率论通识讲义》,新星出版社2021 年版,第201 页;[法]黄黎原:《贝叶斯的博弈:数学、思维与人工智能》,方弦译,中国工信出版集团、人民邮电出版社2021 年版,第3-27 页。,就很容易理解软计算的实际过程。如前所述,由于人脑的语言并非数学语言,而是统计性质的语言,并且主要是自然语言,因此人类的心智计算是不追求精确解、富有灵活性的“软计算”,尤其是在信息不完备条件下,体现为贝叶斯方法和语言方法的综合运用。简言之,“软计算=贝叶斯法则+语言概率”。贝叶斯法则的本质是“用新证据修正概率”⑤这里的“新”证据,指的是次第出现的证据,并非特指上诉审意义上原审程序中未曾出现的证据。根据贝叶斯的解释,某个事件的概率是指我们对它会发生的“置信度”。对概率含义的这种理解在统计学上被称为贝叶斯主义。参见[英]伊恩·斯图尔特:《谁在掷骰子? 不确定的数学》,何生译,中国工信出版集团、人民邮电出版社2022 年版,第117-119 页。,而概率(置信度)可以用语言变量即前述关于“可能性”的模糊语言集中的某个元素来表示,软计算就是这两种方法的结合。申言之,人脑是一个天然的贝叶斯计算器,人类的思维遵循贝叶斯法则,在认识事物时通常先有一个“先验概率”的判断(初始置信度,类似伽达默尔所说的“成见”)①如果没有任何特别倾向,那么该先验概率称为“非信息先验分布”(noninformative prior distribution),即不以任何方式造成有偏见的先验。非信息先验并非无信息,而是给各种可能性分配了相等的概率。参见[以]谢伊·科恩:《自然语言处理中的贝叶斯分析》(原书第2 版),杨伟、袁科译,机械工业出版社2020 年版,第49、52 页;[法]黄黎原:《贝叶斯的博弈:数学、思维与人工智能》,方弦译,中国工信出版集团、人民邮电出版社2021 年版,第68 页。。先验概率如何取值不重要,因为贝叶斯方法允许先验概率的主观性,它会根据新证据提供的信息不断修正调整先验概率而得到客观化的后验概率(经改进的更全面的置信度)。人们对贝叶斯方法的质疑,通常是先验概率的约束问题,即先验概率的主观性。但已有统计学家用数学证明,随着新证据的不断增加,认识对象的“可能性空间”越来越小,先验概率的主观性将被后验概率的客观性替代,这一过程被称为“意见收敛定理”。该定理保证了贝叶斯推理方法的可靠性。②参见陈晓平:《意见收敛定理与休谟问题》,载《现代哲学》2008 年第5 期,第67-74 页;[英]吉利斯:《概率的哲学理论》,张健丰、陈晓平译,中山大学出版社2012 年版,第79 页。从认知科学的角度,这种贝叶斯法则和语言概率的综合运用,或可称之为“贝叶斯推理的语言方法”。
三、运用模糊逻辑“解码”法律问题
受扎德模糊理论的影响,在20 世纪80 年代初,已有法律学者开始研究模糊逻辑的适用,甚至还有人提出了建构“模糊法学”的设想,但对于如何运用模糊逻辑解决实际问题,既有的研究或缺乏明确的解说,或使用的模糊数学方法因过于抽象复杂而难以取得法学界的理解和共鸣。③参见邓建煦、梁志海、邹开其、赵汝怀、武汉:《模糊数学在环境污染案件审理中的应用》,载《中国社会科学》1983 年第5 期,第125-133;邓建煦、梁志海、邹开其、赵汝怀、武汉:《模糊数学在法学中的应用初探》,载《自然杂志》1984 年第4 期,第255-258 页;陈云良:《法律的模糊问题研究》,载《法学家》2006 年第6 期,第18-26 页。法律现实主义运动的代表人物弗兰克(Jerome Frank)等人20 世纪30年代即提出“法官先有模糊的结论,然后寻找能够证实该结论的前提”,实际上就是国外法律实践对模糊逻辑和贝叶斯方法的运用,尽管当时尚未产生模糊逻辑理论。See Jerome Frank, Law and The Modern Mind, Stevens & Sons Limited, 1949, p.100.有鉴于此,我们拟从有代表性的民法、刑法、行政法领域各找一个具体例证说明模糊逻辑如何运用。
(一)民法上的“主/次责任”:模糊集合的处理方法
“模糊集合”是模糊逻辑理论的核心概念。将某些不确定法律概念用模糊集合表示出来,令人困惑的难题就有可能迎刃而解。
例如,交通事故损害赔偿案件是一种很常见的民事案件类型。在这种案件中,法官需要根据交通行政执法部门认定的“全责”“主要责任”“次要责任”“同等责任”“无责任”五种情形之一确定具体的责任分担比例。其中,“全责”“同等责任”“无责任”比较容易处理,但“主/次责任”因其语义的模糊存在很大的不确定性。
在解决这一问题时,可以先将“主/次责任”按照责任比例抽象为一个模糊集合:
{6:4, 7:3, 8:2,[9:1]}
为简便起见,这个模糊集被简化为一个三元素有限集。①需要说明的是,在司法实践中,该集合中的“9:1”适用于“行人vs.机动车”而机动车方无责任、行人负全责的情形。这与我们通常理解的“无责任即不负任何责任”有所不同。“保护弱者”的价值因素在此发挥了作用。因而,这个适用于“主/次责任”的模糊集合实际上是一个三元素有限集。从理论上说,“主/次责任”可以抽象为一个无限元素的连续集,也就是说,该集合中的元素可细分为无限多个,只要责任双方的责任比例之和为正整数“1”(为便于理解,此处运用“插值法”将其设置为1 的倍数10),每个元素的小数点后有多少位都是可允许的。不过,如此复杂的设置没有必要,一个三元素有限集已经足以解决问题,因为此后还要根据具体案情对具体的责任分担比例作适当调整,小数点及其后的数字是一种冗余,人类大脑的计算方式倾向于将其作简化处理。
在针对个案选择具体的责任分担比例时,首先需要基于保护弱者的原则考虑主体因素,即责任双方涉及机动车、非机动车或行人的情况。在选定了某一责任比例,根据具体案情作适当调整时,综合考虑违法情节、受伤程度、车辆投保、当事人履行能力等因素,然后使用简单的加减乘除即可得到责任双方应当承担的具体金额。解决该问题的过程性知识并不见诸任何成文法规范,实践中却常常为法官所用。当然,就我们调查的范围而言,大多数法官并没有明确意识到其运用的是模糊逻辑。
(二)行政强制法上的“夜间”与“凌晨”:借助模糊度理论进行认定
不确定法律概念在行政法上比较多。以“夜间”为例,这一概念在多部行政法律中都有出现,如《中华人民共和国噪声污染防治法》(后文简称《噪声污染防治法》)《行政强制法》等。其中,《噪声污染防治法》第88 条明确规定:“夜间”是指晚上10 点至次日早晨6 点之间的期间。这一规定显然属于“法律拟制”(legal fiction),它是一种不可反驳的“立法决断”。我们暂且不讨论该规定在《噪声污染防治法》上的合理性。无疑,该规定是出于防治噪声污染的目的而进行的“法律拟制”,因而它并不具有普遍适用性,也就是说,如果将其适用于防治噪声污染以外的领域可能不妥。例如,《行政强制法》第43 条规定,行政机关不得在夜间实施强制执行。这里的“夜间”如何认定,需要考虑适用行政强制执行的场景,而不能照搬《噪声污染防治法》第88 条的规定。②但在实践中,有很多行政强制执行案件直接采纳了《噪声污染防治法》第63 条的规定。如“龙门县住建局诉龙门县大新装饰工程有限公司案”,广东省惠州市中级人民法院(2017)粤13 行终97 号行政判决书。在“程现齐诉阜南县曹集镇政府违法强拆案”中,一、二审法院皆认为,“夜间一般指当晚22 点至第2 天凌晨6 点之间,故阜南县曹集镇人民政府于19 ∶55 分执法不违反该条规定”。——“19 ∶55分不属于夜间”的说法不太有说服力。参见安徽省阜阳市中级人民法院(2017)皖12 行终322 号行政判决书。值得注意的是,经修订后自2022 年6 月5 日施行的《噪声污染防治法》第88 条同时规定,“设区的市级以上人民政府可以另行规定本行政区域夜间的起止时间,夜间时段长度为8 小时”,这无疑是给地方立法提出了如何认定“夜间”的问题。
前文指出,中国裁判文书网上有关《行政强制法》第43 条“夜间”的案件有300 多宗。尽管《行政强制法》上并无“凌晨”一词,但由于“凌晨”与“夜间”密不可分,很多案件的争点与“凌晨”有关。③以“《行政强制法》第四十三条”和“凌晨”为关键词检索中国裁判文书网可找到的裁判有117 篇(检索日期:2023 年5 月25 日)。很多案件的争点围绕强制拆除时间是“凌晨四时”“凌晨五(5)时”或“凌晨六时”。如“陈升泰诉北海市人民政府违法强制拆除案”,广西壮族自治区北海市中级人民法院(2019)桂05 行初34 号行政判决书;“陈海鹏诉北海市人民政府违法强制拆除案”,广西壮族自治区北海市中级人民法院(2019)桂05 行初36 号行政判决书。在有些案件中,法院认为“强制拆除行为在凌晨实施,违反《行政强制法》第43 条的规定”;有些案件,法院认为“凌晨拆违不违反《行政强制法》第43 条”。①参见“李秀琴、曾彬诉宝鸡市人民政府违反强拆案”,陕西省宝鸡市中级人民法院(2018)陕03 行初1 号行政判决书;“姚建兴诉庆元县人民政府行政强制案”,浙江省龙泉市人民法院(2015)丽龙行初字第32 号行政判决书,浙江省丽水市中级人民法院(2015)浙丽行终字第80 号行政判决书。糟糕的是,很多法院在认定“凌晨拆违不违反《行政强制法》第43 条”时,没有给出任何理由,这样的判决显然难以说服当事人和社会公众。明确、无争议、显而易见的事实才不需要证明,可由法院直接认定。“凌晨四/五/六点”是否是“夜间”这样的模糊事项,显然不属于司法认知的对象。故本节对“凌晨”和“夜间”一并进行研究。
关于“夜间”,虽然我们每个人在日常生活中都有直接体验,但要说清楚什么是“夜间”其实并不容易,因为白天与黑夜之间并非泾渭分明。同一切模糊事物一样,白天与黑夜都没有清晰的边界,我们不知道它们从哪里开始,又到哪里结束。而且昼夜有季节性变化,从冬至到夏至,日出到日落之间的时长,每天都在发生变化。夏天昼长夜短,冬天昼短夜长,自然的变化造成了昼夜的非匀定性。这使得“夜间”与“正义”一样,也有一张变化不定的“普洛透斯之脸”。再加上我国幅员辽阔,东西横跨五个地理时区,各地地方时的不同使得“夜间”的确定更为复杂。也正因为“夜间”界定的复杂性,中国传统社会的“夜五更制”和“十二时辰制”等纪时制度历经多个朝代的多番调整,才逐渐成为法律上的定制。②任何组织的有效运转,都需要时间的秩序来保持步调一致。由于时间信息涉及到国家秩序和社会运转,颁历授时(大时间尺度的纪年和小时间尺度的纪时)因而成为国家管理权的重要内容和体现。参见汪小虎:《颁历授时:国家权力主导下的时间信息传播》,载《新闻与传播研究》2018 年第3 期,第96 页;陈侃理:《十二时辰的产生与制度化》,载《中华文史论丛》2020 年第3 辑,第19 页;张闻玉:《古代天文历法讲座》,广西师范大学出版社2021 年第3 版,第80-85 页。
尽管如此,虽然白天与夜间两个时段之间并没有明确的界限,但是,有些时段确定属于“夜间”,有些则确定不属于。比如,午夜零时确定属于“夜间”,中午12 点则确定不属于。二者当中,有些时段容易确定,如22 ∶00 至2 ∶00;有些时段则难以确定,如夜幕降临前的黄昏、傍晚和天亮前的凌晨时分。由于“夜间”符合模糊事物的特性,因此我们可以用模糊度理论来认识和描述“夜间”。
1972 年,法国学者德拉卡提出对模糊集的定量描述问题,奠定了度量模糊性的理论基础。模糊度理论告诉我们,任何模糊集的模糊度都是[0, 1]上的一个数。一个普通集合,其模糊度为0,它是不模糊的,因为元素的隶属度或为0 或为1。隶属度越接近0.5 越模糊,隶属度为0.5 时最模糊。③参见王永庆:《人工智能原理与方法》,西安交通大学出版社2018 年第2 版,第37-38 页。据此,认识模糊事物,可以先找出最确定的元素(隶属度为0 或1),接下来寻找最模糊的元素(隶属度为0.5),然后再来认识中间的过渡区域。
具体到“夜间”,认定最确定的时段和最模糊的时段,需要依靠我们的生活经验。当然,这种经验不应当是纯粹个体的经验,而应当是具有社会共识的经验。因而,中国传统社会的“十二时辰制”和“夜五更制”具有重要参考价值。这两种纪时方法作为历史上法定的纪时制度,曾经长期通行于中国社会,并已融入我们的文化当中,成为我们认识世界的“模因”。尤其是,这两种纪时制度都具有很高的科学性。十二时辰的划分与昼夜的季节性变化无关,它是一种匀定时制,时间的长度均匀、恒定,并可逐一对应现代社会的24 小时。在其基础上专门用于夜间纪时的五更制,符合昼夜非等分的实际情形,有利于达成何谓“夜间”的共识。①在中国传统社会,十二时辰制主要适用于白天,夜间计时使用五更制。需要指出的是,白天和夜间不是等分的,二者之间的“晨昏蒙影”时间(约两个小时)被归入白天。下表反映的是夜五更制和现代计时方法的对应关系。
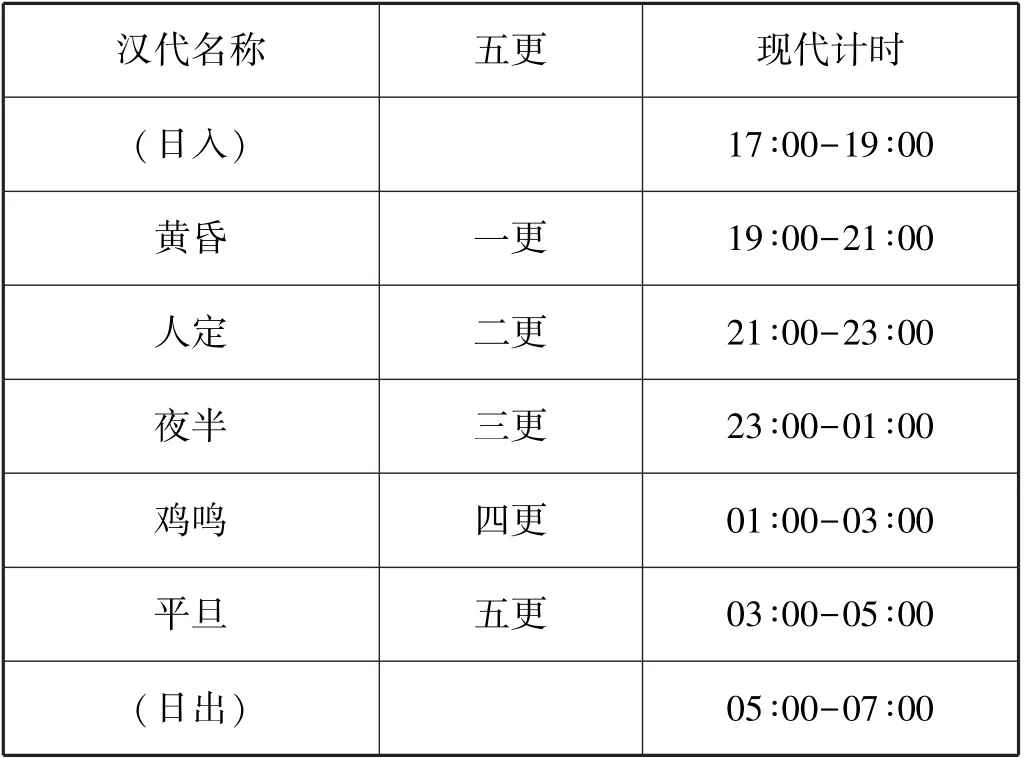
表1 夜五更制和现代计时制的对应关系
根据上述图表和我们的日常生活经验,可以确定:午夜零时是最肯定的“夜间”,其隶属度为1。最模糊的时间点是晚七时左右(央视《新闻联播》片头音乐响起时,很难说当时是否属于“夜间”),凌晨5 点也一样,其隶属度均为0.5。二者中间,即晚7 点和凌晨5 点之间的时段,其隶属度分布在0.5 和1 之间。各时点的隶属度如图1 和图2 所示:

图1 “夜间”各时间点的隶属度
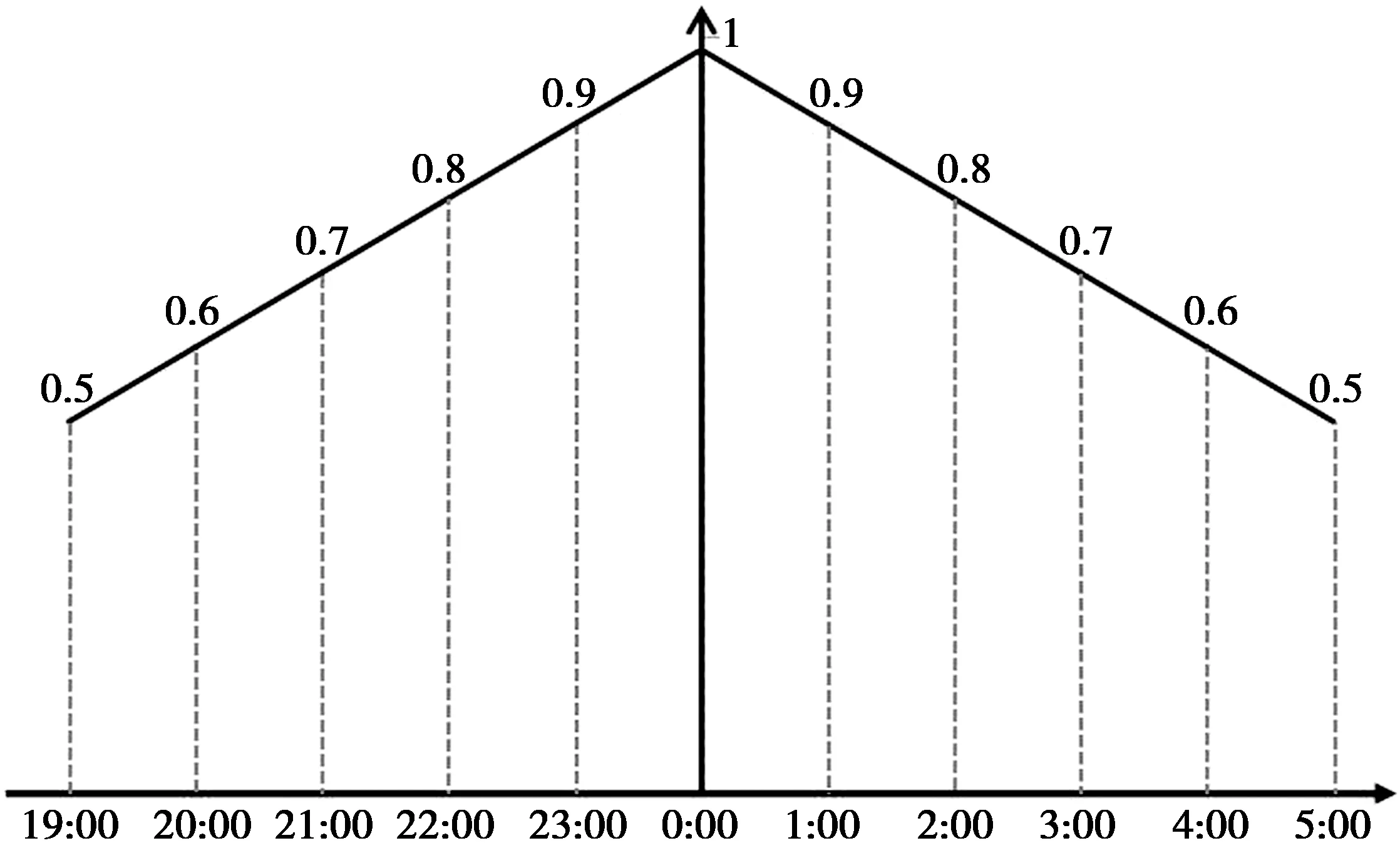
图2 “夜间”的隶属度函数曲线
从人类尺度而言,时间的集合可视为一个“连续统”,一个多元素的线性序集,具有“稠密无洞”的性质,即在任意两个元素之间都存在第三个元素。②不过,在量子物理学上,时间是分立、非连续的,最小的时间单位为“普朗克时间”(10-44 秒)。参见[意]卡洛·罗韦利:《时间的秩序》,杨光译,湖南科学技术出版社2019 年版,第58-59 页。但为简约起见,在图1 和图2 中,我们只取时间的整数值来确定“夜间”范围内各元素的隶属度。
在实际应用中,在使用模糊集描述事物进行推理时,需要在最后阶段将结论非模糊化,以给出确定的答案。易言之,基于截集概念提出的模糊截割理论,最后归结为运用一个适当的阈值进行截割,以作出非模糊化的判断。①参见苗东升:《系统科学精要》,中国人民大学出版社2016 年第4 版,第364 页。相应地,为了确定某一具体的时间点是否属于“夜间”,需要进行阈值设定,以实现“去模糊化”。由于《行政强制法》第43 条的立法目的是保护公民的正常生活作息免受干扰,“夜间”的认定应当偏向宽松,阈值的设定超过0.5 即可。因此,“夜间”对应的时间为晚7点—凌晨5 点(春秋分时)。考虑到冬夏差异和各地区地方时与北京时间的差异,在具体判断时可在1 小时范围内进行适当调整。
如果抛开《行政强制法》的特殊立法目的,仅考虑一般情况下“夜间”的认定,阈值的设定在0.6以上为宜,对应的时间为晚八点至晨四点(春秋分时)。结合模糊语言算子(有点、很、非常等)对语言变量的修饰作用,一种更一般、更直观简便的“夜间”确定方法如图3 所示:

图3 一般情况下“夜间”的确定方法
(三)刑法上的“情节严重”:定罪量刑过程中的“软计算”
与民法、行政法相比,刑法对法律语言明确性的要求更高。刑法上的罪刑法定原则强调明确规定罪与非罪以及对犯罪处以何种刑罚,是为了防止因法律语言的模糊不清而留下罪刑擅断的空间。罪刑法定亦因此成为各国刑法共同奉行的基本原则。
不过,刑法在要求法律语言明确性的同时,也使用了大量不确定法律概念,例如,“情节严重”“数额巨大”等。检视我国刑法规定,从总则到分则,使用这类词语的有一百多个条款,占比很大。仅以“情节”为例,就有“情节显著轻微、情节轻微、情节严重、情节特别严重”等各种规定。刑法之所以采用这种模糊化表述方式,盖因现实生活纷繁复杂,犯罪行为林林总总,立法者需要策略性地借助模糊语言进行适度的抽象概括,以实现刑法条文的简明与包容。
从模糊逻辑理论的视角来看,《中华人民共和国刑法》(后文简称《刑法》)事实上建立了一个有关“情节”的模糊集合:
{情节显著轻微;情节轻微;情节严重;情节特别严重}
该集合中的四个元素都是语言变量“情节”的值,每个元素都有对应的法律后果。根据刑法的这一规定,一个训练有素、富有经验的法官会自然而然地在其头脑中形成一个关于“情节”的模糊集合,在审理案件时,根据案件的具体事实选择对应的元素,并在此基础上选择相应的法律后果。
在选择适用前两个元素“情节显著轻微”“情节轻微”时,因属于简单案件情形,可以用三段论直接处理。申言之,根据扎德的理论,可用模糊条件语句刻画事实和法律后果之间的简单关系。这两种情况的处理如下:(1)“若A,则B”。《刑法》第37 条规定:“对于犯罪情节轻微不需要判处刑罚的,可以免予刑事处罚……”。(2)“若A 且B,则C”。①“若A且B,则C”是在“若A,则B”这种产生式规则的一般形式的基础上衍生出来的一种新形式,最早在著名的医疗专家系统MYCIN 中使用,又称“MYCIN 规则”。参见何新贵:《模糊知识处理的理论与技术》,国防工业出版社1998 年第2 版,第251 页。《刑法》第13 条规定:“……情节显著轻微危害不大的,不认为是犯罪。”“情节轻微”或“情节显著轻微”的情形不难判断处理,兹不赘述。
相比较而言,刑法分则条款中频见的“情节严重”“情节特别严重”等量刑加重情节的规定,不仅是刑法学上的重要问题,而且在司法实践中也最容易产生纷争。②需要说明的是,刑法上的“情节严重”,有作为法定刑升格条件的“情节严重”,还有作为犯罪成立条件的“情节严重”。后一种“情节严重”是情节犯的常态,与作为法定刑升格条件的“情节严重”不同。它是指行为的社会危害性或对法益的侵害达到了应当追究刑事责任的程度,其认定是为了解决定罪问题。由于这两者都属于“情节严重”的认定问题,本文对此暂不作区分。参见李翔:《情节犯研究》,上海交通大学出版社2006 年版,第61 页;余双彪:《论犯罪构成要件要素的“情节严重”》,载《中国刑事法杂志》2013 年第8 期,第30页。量刑情节是选择法定刑、决定宣告刑的依据,也是法官裁量刑罚、决定量刑轻重的事实根据。我国刑法规定的量刑情节种类繁多,包括犯罪动机、犯罪手段、犯罪中止、未遂、累犯、自首、坦白、立功、积极退赃退赔,等等。如何使刑法规定的这些量刑情节在具体案件中发挥作用呢?
研究表明,当前的量刑,一般采用传统的经验量刑法,或称为综合估量式的量刑方法,即首先审理案件,掌握案情,在法定刑范围内,参照司法实践经验,大致地估量出对犯罪人应处的刑罚(量刑起点);其次考虑各种法定的从重处罚、从轻、减轻和免除处罚的情节,并考虑其他影响刑罚轻重的非法定情节;最后综合估量出对犯罪人应判处的刑罚。这种量刑方法简便易行,而且,只要审判人员对案情的掌握全面,所参照的经验适当,裁量刑罚时的心态、情绪与情感正常,一般不会出现偏差。①参见张明楷:《刑法学》(第6 版),法律出版社2021 年版,第756 页。这种方法,也是人类在日常生活中常用的模糊决策方法,理论上称之为“模糊综合评判”。②参见雷英杰、路艳丽、王毅、申晓勇编著:《模糊逻辑与智能系统》,西安电子科技大学出版社2016 年版,第52 页。关于模糊综合评判的数学描述,参见张博侃:《模糊数学》,北京大学出版社2021 年版,第210-218 页。
然而,由于上述量刑方法并没有“科学”标准作为保障,一直有人担心甚至批评会出现量刑不适当的情况。基于这一考虑,近年来,人们提出了很多新的量刑方法,如数学模型法、定量分析法及电脑量刑法等等。这些方法虽然存在一定差别,但其核心观点都是对各种量刑情节进行定量分析,然后根据量的总和确定宣告刑。③参见张明楷:《刑法学》(第6 版),法律出版社2021 年版,第756 页。2021 年,最高人民法院、最高人民检察院(以下简称“两高”)亦出台司法解释,要求定罪量刑时同时采纳定量分析方法。④2021 年6 月,最高人民法院和最高人民检察院出台《关于常见犯罪的量刑指导意见(试行)》,综合采纳了传统的经验量刑法和新兴的定量分析思想,该文件明确指出:“量刑时,应当以定性分析为主,定量分析为辅,依次确定量刑起点、基准刑和宣告刑。”由于法官通常自己也说不清楚在定罪量刑过程中是如何形成“内心确信”的,面对学界对其定罪量刑方法“不科学”的批评,法官群体常常自感“理屈词穷”,不知道如何辩驳,传统的根据经验定罪量刑且行之有效的裁判方法面临着缺乏理论支撑的窘境。
事实上,在司法实践中,法官在定罪量刑时不需要也不可能采取精确的量化计算方法。不能精确计算是人脑天然的局限性。根据最高人民法院和最高人民检察院联合印发的《关于常见犯罪的量刑指导意见(试行)》,尽管要运用到定量方法,但这种定量方法仍然是较为简单的算术加减,并且主要还是“模糊综合评判”(最大60%以内基准刑调节比例和调节结果20%以内宣告刑的确定)。对“情节轻微”“情节严重”等问题,法官的处理方法实际上是“软计算”,其过程即前述“软计算=贝叶斯法则+语言概率”,或称“贝叶斯推理的语言方法”。申言之,在认定“情节轻微”或“情节严重”的过程中,法官的目光会在事实(犯罪的各种情节)与规范之间“顾盼流转”,按照贝叶斯法则,用新证据提供的信息不断修正调整自身以语言变量形式表示的概率性认识(即某一事实存在可能性的置信度),经渐进收敛,直至形成某种“内心确信”,最终作出“情节轻微”或“情节严重”的判断,同时确定相应的罪名和法律责任。可以说,软计算才是法官真实的思维过程。我们必须尊重人类的思维规律,而不能强求精确的量化计算方法。
四、模糊逻辑在法律领域的适用规则
研究模糊逻辑在法律领域的适用,需要概括、提炼出相应的规则,作为评判模糊推理有效性的标准。模糊集合论、模糊概念论、模糊判断论,共同构成了模糊推理的理论基础。⑤参见苗东升:《模糊逻辑趣谈》,中国人民大学出版社2020 年版,第155 页。我们按照这一认识并结合从前提到结论的推理过程的顺序,提炼总结模糊逻辑在法律领域的适用规则并对其作简要说明。
(一)模糊概念的认识规则
掌握模糊概念(假设为A)是一个动态渐进的过程,先弄清什么是典型的A(百分之百属于A 的对象),什么肯定不是A(百分之百不属于A 的对象),暂时忽略那些介于二者之间的复杂情况;在对核心区对象KerA 和外部对象ExtA 足够了解之后,再向A 的边缘EdgA 推进,逐步了解那些非典型的即带有模糊性的情形,区分不同对象具有A 的内涵的程度,最终达到全面准确地理解模糊概念A。这是一种容许认识存在片面性甚至是错误但不断修正错误的过程,真实的人类认识活动就是这样进行的。①同上注,苗东升书,第151 页。由此,可以概括出:
R1:每一模糊概念,都对应一个相对明确的参照标准;
R2:模糊概念的核心区域是确定的,显然不属于该概念的外部对象可以明确排除;
R3:根据常识或者专家经验确定模糊区域各元素的隶属度,隶属度达到设定阈值的元素属于模糊概念涵盖的范围。
以前述《行政强制法》上的“夜间”为例,“夜间”虽然具有模糊性,但午夜时分肯定属于夜间,认定22 ∶00 至2 ∶00 属于“夜间”不会有人提出质疑,这是“夜间”的核心区域(深夜);晚七时以前和凌晨五点以后的时间也基本上可以排除。考虑到《行政强制法》第43 条的立法目的是保护公民的正常生活作息免受非法干扰,“夜间”的认定应偏向宽松,阈值超过0.5 的时间段即晚七时和凌晨五点之间都可以认定为“夜间”。
(二)模糊集合的建立规则
无论是在立法环节,还是在认定事实、适用法律的过程中,都会使用到以语言变量形式表现出来的模糊集合。建立模糊集合是进行模糊推理的基础性工作。
R4:无穷连续值的模糊集合,可以简化为有限元素的离散集;
R5:作为模糊集的语言变量,可以细分成若干区间值模糊集;
R6:对模糊集取截集,可以建立模糊事物与普通集合之间的联系。
R4 说明:模糊逻辑有时被称为“无穷连续值逻辑”,以区别于一般的多值逻辑。但是,建立“无穷连续值集合”常常不利于解决问题。在社会实践中,人们对事物或事件的认识与判断,既追求有效性也同时追求经济性,必须在有效性与经济性之间取得某种平衡。比如,统计学上普遍接受的95%的置信度和3%的精度误差就是为了使试验或者调查切实可行。因而,需要对无穷连续值的模糊集进行简化。根据模糊信息粒化理论,粒化是把整体分解为部分,把连续的信息离散化并压缩为一个个分立的信息粒。这种粒化过程也是对无穷连续值的模糊集进行简化的过程。②See L.A.Zadeh, Toward a Theory of Fuzzy Information Granulation and its Centrality in Human Reasoning and Fuzzy Logic, 90(2)Fuzzy Sets and Systems 111, 111-114 (1997).前述表征交通事故损害赔偿案件中“主/次责任”的三元素有限集,即是一个把无穷连续值的集合简化为有限元素、离散集的例证。
R5 说明:模糊集通常是点值模糊集(或称“1 型模糊集”),这在实际应用中往往会遇到困难,因为建立隶属函数特别是阈值的设定很多时候难以取得一致意见,即使是同一领域的专家也往往难以在某一“点值”上达成一致。而用一个数值范围,即区间来描述某点对模糊概念的相关程度,则较易达成共识。在实践中,领域专家也更习惯于使用区间,即包含充分的有用信息的数值范围来刻画事物。这种区间值模糊集被称为“2 型模糊集”,在很多领域特别是在不确定性推理和优化决策中被广泛应用。①参见雷英杰、路艳丽、王毅、申晓勇编著:《模糊逻辑与智能系统》,西安电子科技大学出版社2016 年版,第83 页。前述传统社会五更制对“夜间”的界定及汉代使用的“黄昏”“人定”“夜半”“鸡鸣”“平旦”等名称,都是典型的区间值模糊集。我们在此基础上确定的“入夜”“夜间”“深夜”也吸收了区间值模糊集的合理内核。
R6 说明:在实践中,常常需要对模糊事物作出明确的判断。也就是说,总要确定一个明确的界限对模糊事物进行划分,否则很多计划无法操作执行。这就需要有一种方法把模糊集合与普通集合沟通起来。通过对模糊集取截集,可建立模糊事物与普通集合之间的联系。前述五更制对“夜间”的界定,即是一种取截集的方法,它在十二时辰制的基础上舍弃了与“夜间”关联度不大的时间点。采用取截集方法,有利于打破模糊事物难以划分的僵局。
模糊概念的认识和模糊集合的建立,都是为了形成某些模糊命题,作为模糊产生式规则的前提,为最终形成模糊判断提供基础。
(三)模糊判断的形成规则
模糊推理是利用模糊性知识得出近似结论的一种不确定性推理。模糊知识的表示,常用的方法是在模糊命题的基础上建立模糊产生式规则,即带有模糊因素的“if-then”规则。在模糊推理中,将模糊产生式规则作为大前提,事实证据作为小前提,在小前提与大前提中的模糊条件相匹配时,即可利用大前提中的模糊条件和结论之间的模糊关系R 与小前提中的事实之合成,得出模糊判断(近似结论)。这一过程涵盖的规则如下:
R7:模糊产生式规则的一般形式是:若A,则B (CF,λ);
R8:事实证据可以用模糊命题来表示,其一般形式为: x 是A’(CF);
R9:如果A 与A’的相似程度(匹配度)大于某个预先设定的阈值,则可运用模糊关系合成推理得出模糊结论B’;
R10:最终的模糊结论需要还原为用自然语言表示的确定性判断。
R7 说明:模糊推理的关键环节是建立模糊产生式规则(带有模糊因素的“若A,则B”),从而把模糊性知识有效组织、关联起来。其中,A 是模糊条件,B 是模糊结论。模糊条件用模糊命题来表示,它既可以是单个模糊命题表示的简单条件,也可以是多个模糊命题构成的复合条件。模糊结论也用模糊命题表示,它常常带有可信度因子CF。CF 既可以是一个确定的实数,也可以是一个模糊数或模糊语言值(法律领域常常使用模糊语言值而非数字,因此非专业读者可以忽略本节的数学化、形式化描述),它表示规则的强度,即相应知识的可信程度,取值范围为(0,1]。可信度因子CF的值越大,表示相应知识的可信度越高。CF 值由法律专家在给出知识时一并赋予。阈值λ 表示相应知识在什么情况下可以被应用。
R8 说明:模糊产生式规则是模糊推理的大前提,小前提是事实证据。小前提也可以用模糊命题来表示。其一般形式中的A’是一个模糊集,可信度因子CF 的值亦由法律专家在认定事实时赋予。
R9 说明:在模糊推理中,很多时候,大前提中的模糊条件A 与小前提(事实证据)的A’不一定完全相同,因而,在选择模糊规则进行推理时需要首先考虑哪条规则中的A 与A’相匹配,即它们的相似度大于某个预先设定的阈值。这就需要对可能同时存在的多个模糊规则的匹配度进行排序(ranking),以实现规则间的“冲突消解”。在确定了可优先适用的规则之后,运用模糊关系合成推理(即扎德所说的将大前提中的模糊条件和结论之间存在的模糊关系R 与小前提中的证据A’进行合成),将前提中的模糊语言算子(模糊约束限制)传递给结论,从而得出模糊判断B’。
R10 说明:运用模糊关系合成推理得出的模糊结论(近似结论),需要使用以自然语言表示的确定性判断来表述。前文指出,法律领域的近似推理,虽然本质上是运用模糊逻辑的模糊推理,但最终的结论必须是确定的,不能作出含糊的、“莫须有”的模糊判决。
需要说明的是,上述十项规则只是对法律领域模糊逻辑规则的不完全归纳。在实际应用中,随着问题复杂度的增加,模糊逻辑规则的数目可能会相应增加。不过,从法律人思维的全过程来看,上述规则基本上可以涵盖模糊推理遇到的大部分问题。因为,并不追求精确性的“软计算”可以大大减少模糊规则的数量。例如,插值法的使用(根据比例关系简化问题)即可以大幅简化计算量,从而降低所需要的模糊规则的数量。
五、结语:法学研究应引入计算思维
法律领域的模糊性无处不在。对法律确定性的追求,需要避免的是“空泛”“歧义”“模棱两可”,而非模糊性。法律具有模糊性,并不意味着法治的理想不能实现。
事实上,在法律实践中,人们一直在运用模糊逻辑,不过,那大多是自发的意识而非自觉的行动。扎德的模糊理论为我们提供了一种处理模糊性问题的有效工具。当然,自1965 年扎德发表第一篇模糊集的论文至今才经历五十多年时间,模糊逻辑理论在很多方面还处于探索阶段,将其拓展到法律领域并用来解释人类的法律思维过程,仍然面临着许多困难。正因为如此,更需要学界同仁一起参与对模糊逻辑研究的“接力跑”,一起提炼规则、总结规律,以有效指导今后的法律实践。
有物理学家指出,现实常常不似你所见。地球看起来是个平面,实际上是个球体;太阳看似在天上旋转,但其实旋转的是我们。这是由于我们的视角产生的错误。①参见[意]卡洛·罗韦利:《时间的秩序》,杨光译,湖南科学技术出版社2019 年版,“导言:也许时间是最大的奥秘”,第1-4 页。因而,为了克服单一视角的局限性,在研究法律中的模糊性问题时,我们也不能完全拘泥于扎德的理论,而应当将视野进一步拓宽,吸收、采纳多学科的知识和方法。例如,近年来蓬勃兴起的计算思维理论正在对各学科、各领域产生广泛而深刻的影响。①See Jeannette M.Wing, Computational Thinking, 49(3) Communications of the ACM 33 (2006).另见董荣胜:《计算思维的结构》,人民邮电出版社2017 年版,第2-7 页。扎德的“词语计算”“软计算”与计算思维理论密切相关,它们可谓计算思维的另一种表达。虽然计算思维也并非包治百病的“万灵丹”, 但至少它可以为我们打开一扇观察法律世界的新视窗,透过这个窗口,很可能看到不一样的风景线。
猜你喜欢
法律方法(2022年2期)2022-10-20
中国石油石化(2022年12期)2022-07-16
中学生百科·大语文(2021年11期)2021-12-05
纺织科学研究(2021年7期)2021-08-14
流行色(2020年9期)2020-07-16
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
刑法论丛(2018年4期)2018-05-21
37°女人(2017年11期)2017-11-14
