
基于深度学习的多源卫星遥感影像云检测方法
2023-12-28 07:25邓丁柱
自然资源遥感 2023年4期
邓丁柱
(内蒙古自治区测绘地理信息中心,呼和浩特 010051)
0 引言
21世纪,卫星遥感技术作为一种重要地球观测手段被广泛应用。然而,全球年平均云覆盖区域约为66%[1],意味着常规拍摄的光学卫星影像有一半以上受云遮挡难以获取有效信息,因而通过云检测技术生成掩模文件对于有效数据的筛选具有重要意义。近年来,随着卫星遥感技术的不断进步,遥感数据的规模也越来越大,据统计光学卫星影像单日接收量达数百景,传统云检测方式已难以满足大规模数据生产需求,研发快速、高效、准确的云检测方法对于保证后续遥感产品质量与服务效率至关重要[2]。目前,遥感影像云检测方法大致可以分为3种类型: 基于阈值的方法、基于传统机器学习的方法和基于卷积神经网络(convolutional neural network,CNN)的方法。基于阈值的算法常用于多光谱和高光谱图像的云检测[3-5]。这类方法的基本原理是利用云与其他物体在可见光—短波红外光谱范围内的反射率差异,通过人工设计特征提取规则对云进行识别和分割[6-8]。Fmask算法[3]及其改进版本[9-10]是这类方法的典型代表,并广泛用于特定类型卫星图像的云检测应用中,包括 Landsat[8],Terra/Aqua[11],Sentinel[12],HJ-1[13]和GF-5 多光谱图像[14]等。但是这类方法仍然存在一些不足。一是算法设计往往适用于具有多波段的特定载荷,不适用于一些只有4个波段的主流高分辨率卫星数据等; 二是基于像素计算很容易导致“椒盐”效应[15-16]; 三是阈值的设定往往依赖于专家知识,难以在复杂场景下推广应用[17-18]。
随着机器学习技术的兴起,针对云检测问题提出了人工神经网络[19]、支持向量机[20]和随机森林[21]等传统机器学习算法[22-23]。传统机器学习方法的优势在于提取规则和阈值的设定不再完全依赖专家知识[24-25]。然而,与基于阈值的算法一样仍难以克服 “椒盐” 效应,此外在融合空间和光谱信息方面仍有改进空间。
深度学习技术被逐步应用于遥感领域并取得了显著突破,涉及图像融合、图像配准、场景分类、目标检测、土地覆盖分类和地质体识别等[26-27]。与传统机器学习方法的不同在于,后者利用卷积操作可以更好地提取目标特征[28],且能够实现空间和光谱信息的融合提取。近年来,学者们尝试将深度学习技术应用于卫星影像云检测,对不同结构的网络模型的有效性进行了有益的探索[15,18,23-24,29-32],并针对不同类型的载荷研发了云检测方法[33-38]。然而,针对载荷参数不同的多种主流卫星影像均适用的通用型深度学习模型的研究依然有待于进一步开展。研究的主要难点在于以下3个方面: 一是获取具有代表性的多种类型卫星数据并通过标记形成训练样本集的成本较高; 二是不同载荷波段组合不一致为构建通用的深度学习模型提出了挑战; 三是深度学习模型种类众多且大多以解决计算机视觉领域问题被提出,应用于遥感数据需进行针对性优化。
在本文中,提出了一种适用于多源卫星影像的云检测模型,称为多源遥感云检测网络(multi-source remote sensing cloud detection network,MCDNet),以U型结构为基础,采用轻量化骨干网络设计,通过多尺度特征融合及门控机制提升识别精度。在全球范围内搜集多源卫星影像数据,其中即包括谷歌和Landsat等常用国外卫星数据,也包括GF-1,GF-2和 GF-5等国产卫星数据。为了保证模型的通用型,所有卫星影像均只保留真彩色3个波段用于构建云检测数据集。选取多个经典的语义分割网络作为对比开展实验,结果显示本文提出方法在云检测方面具有很好的应用潜力。
1 研究方法
1.1 MCDNet主体架构
MCDNet采用U型架构,由编码器、解码器和多尺度融合模块3部分构成(图1)。编码器由6组DCB(deep-wise convolutional block)卷积模块(深度卷积、归一化层和1×1卷积组合)构成,共包含3个下采样层,未采用更多下采样层的原因是考虑尽可能保留浅层的空间信息以提高识别结果的边界精度。DCB卷积模块由1个3×3的深度卷积和2个1×1普通卷积以及激活层组成,不同于传统轻量化模型中的瓶颈结构设计,这里处于中间位置的1×1卷积核数较大,呈现出“两头细,中间粗”的反瓶颈结构,经实验验证这种结构能够在不降低模型整体性能的前提下减少模型参数。解码器的开始部分参考了UNet[39]的设计,自下而上进行上采样的过程中用跳层连接叠加来自于编码器的特征。

图1 MCDNet网络结构示意图
1.2 多尺度融合模块
CNN利用降采样操作一方面降低了模型的参数量; 另一方面使得模型具有一定深度的同时饱有足够的感受野。降采样操作的最大缺点在于采样过程导致有效信息的丢失,在识别结果上表现为目标边界识别准确性差,如早期语义分割网络(fully convolutional networks,FCN)。以降采样操作形成的多个尺度的特征相结合被证实在计算机视觉任务上是有效的。本文提出一种适用于U型架构的多尺度融合模块,使模型能够在模型训练中根据识别场景对相关的尺度特征进行加权识别性能。首先,利用常规的CBR模块(卷积层、归一化层及激活层组合)对解码器输出的各个尺度的特征进行卷积操作,再将所有特征上采样至原始输入尺寸,最后将所有特征进行堆叠,利用通道注意力模块对有效特征进行加权。
进入到通道注意力中的特征首先经过全局池化层被抽象为具有C(通道个数)个单元的向量,利用多层感知机对该向量进行非线性变换,再利用Sigmoid函数将变换后的向量映射到[0,1]范围内,此时可将向量中的每一个数值看作是对应通道的权重,利用权重向量乘以原始数据即可实现对各个通道的加权处理。具体公式为:
Fc=σ{MLP[GAP(F)]}·F
,
(1)
式中:F为输入特征;Fc为加权处理后的特征; GAP表示全局池化操作; MLP表示多层感知机;σ为Sigmoid激活层。
1.3 评价方法
采用精确率、召回率、总体分类精度、F1值及交并比作为云检测精度的评价指标。各评价参数的计算方法分别为:
P=TP/(TP+FP)
,
(2)
R=TP/(TP+PN)
,
(3)
OA=(TP+TN)/(TP+TN+FP+FN)
,
(4)
F1=2(1/P+1/R)
,
(5)
IoU=TP/(TP+FP+FN)
,
(6)
式中:P为精确率;R为召回率;OA为总体分类精度;F1为 F1得分;IoU为交并比;TP为判正的正样本;FN为判负的正样本;FP为判正的负样本;TN为判负的负样本。
2 多源卫星影像及数据处理
搜集了目前已开源的具有代表性的云检测数据集,包括谷歌影像、Landsat系列影像、GF-1、GF-2及GF-5卫星影像,空间分辨率覆盖0.5~30 m(表1)。由于各个数据集组织方式略有不同,在原始影像的基础上进行二次裁切,获得256像素×256像素大小的切片数据,裁切方式为固定间隔顺序裁切。由于GF-1数据量较大,为了尽可能平衡不同空间分辨率数据的数量,对GF-1的切片影像进行筛选,剔除其中无云的纯背景影像,从剩余影像中随机选择8 400个作为训练数据。最终形成的样本数据共计2万个切片(256×256×3)。

表1 多源卫星遥感影像云检测数据集
在进行深度学习模型训练之前需要对影像切片进行预处理,首先按照载荷类型对数据进行统计分析,剔除数据中存在的负值及异常高值,将所有数据归一化至[0,1]范围内。所有数据经随机打乱后按照6∶2∶2划分为训练集、验证集和测试集,对比实验中精度评价均基于测试集进行。
3 实验及结果分析
3.1 实验设置
本次实验中引入多个经典语义分割网络作为对比模型,包括SegNet[43],UNet[39],PSPNet (pyramid scene parsing network)[44],BiSeNet (bilateral segmentation network)[45],HRNetV2(high-resolution representation network v2)[46],DeepLabV3+[47]和MFGNet(multiscale fusion gated network)[36]。所有模型均在相同数据集以相同的训练参数设置进行实验。实验在 TensorFlow(1.13.1)框架及NVIDIA Tesla V100 GPU下进行,训练过程中使用自适应学习率优化算法(Adam)作为优化器以0.000 5为初始学习率进行优化,以“Categorical_Crossentropy”作为损失函数,所有模型经过30轮训练后取其中最优模型进行对比。
3.2 模型性能对比分析
图2展示了训练过程中模型的训练和验证精度。随着训练的进行,训练集的准确率曲线迅速上升,同时损失曲线迅速下降,20个轮次后逐渐到稳定,并且在此期间训练集和验证集的精度曲线趋势相同,表明模型没有过拟合。
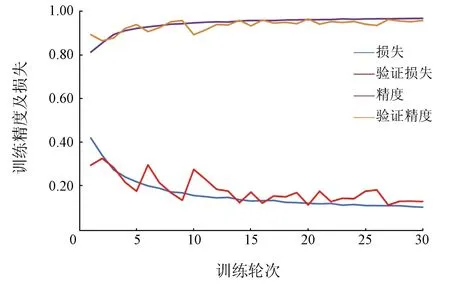
图2 MCDNet网络训练过程曲线
表2展示了各类模型在云检测任务上取得的实验结果。总的来说,所有参与实验的CNN对于云检测都是有效的,识别准确度均达到了90%以上。MCDNet在所有评估指标中均取得了最优的成绩,其中准确率达到0.97。值得一提的是,MCDNet 的召回值显著优于其他模型为0.95,表明该模型识别的假阴性率较低。F1得分综合了精确率和召回率的评价结果,可以更好地代表模型的整体性能。

表2 多源遥感影像云检测精度
而交并比用于检测预测结果与真实值的重合程度,对于分割任务更有说服力。MCDNet的F1得分为0.94,交并比达到0.89明显优于其他方法。总的来说,所提出的模型一方面比其他方法具有更好的性能,同时也意味着其可以在包含多种卫星数据上表现得更加鲁棒。
3.3 模型消融实验
为了进一步验证所提出模型中关键结构的有效性,以MCDNet为基准,设计3组模型消融实验(表3)。MCDNet-withoutAT代表去除了注意力机制的MCDNet,MCDNet-Xcep是将编码器替换为Xcep-tion的MCDNet,MCDNet-withoutDC为将模型中深度卷积替换为普通卷积的MCDNet。结果显示去掉模型中任意结构都会导致模型性能的下降,其中影响最大的是通道注意力融合模块,去除后模型召回率和交并比降低了3~4个百分点。
3.4 云检测效果视觉评价
为了更好地展示MCNNet在云检测任务上的优势,本文从测试数据随机选出一组覆盖各类载荷且有不同程度云覆盖的卫星影像进行测试。从表4中各类卫星影像可见,测试影像中包含沙漠、雪地、森林、农田、河流和裸地等多种地物场景,场景中云的覆盖度不同,类型也不同。利用MCDNet预测得到的云掩模结果显示MCDNet在各类场景下均可实现对云的准确识别,值得一提测试数据中包含的一些易混淆目标如雪地等也能够被准确识别,且模型对于一些薄云的判断也较为恰当,表明模型通过海量的多源卫星影像样本的训练已经充分学习到云的语义表达。

表4 不同云覆盖度的多源遥感真彩色影像及MCDNet云检测结果
3.5 模型通用性测试
构建通用云检测模型的2个关键前提分别是拥有大量的样本和通用有效的模型设计,常用光学卫星应用的侧重点不同,且数据通道数不一致,因而以往云检测模型主要是针对载荷特点进行定制开发,模型迁移性不强。本文采用RGB真彩色影像作为输入源,一方面可以最大限度提升样本数量的同时降低制作成本; 另一方面的原因是验证不同载荷数据统一为3个通道数据对于模型的设计是否有利。实验数据中既包含DN值数据也包含反射率数据,所有数据均在剔除异常值后归一化至[0,1]范围内,因而使得不同传感器获取的不同时相的数据都具有相对接近的视觉表达(图3)。而通过CNN可以从真彩色影像中云的分布规律、纹理特征和空间关系等习得用于云检测的通用语义表达能力。为了进一步验证这一结论,利用训练样本中不存在的载荷类型数据作为实验目标进行测试。将之前训练的带有权重的MCDNet模型直接应用于5景哨兵2号卫星数据进行云检测,从图3中可见,识别结果依然很准确,F1得分为0.90,交并比为0.82。

(a) 哨兵2号影像
4 结论
本研究提出了一种多尺度特征融合神经网络模型,通过轻量化骨干网络设计结合多尺度特征融合及通道注意力机制实现了对多种类型卫星影像的高精度云检测。对比于多个经典的语义分割网络取得了最优的检测性能,得出如下结论:
1)采用真彩色影像结合语义分割网络可以实现对中高空间分辨率卫星影像高效准确的云检测。
2)本研究提出的模型在传统U型架构的基础上应用轻量化骨干设计、多尺度特征融合及注意力机制能够有效地提升模型性能,相较于经典语义分割模型具有明显优势。
3)MCDNet由全球分布的数万计样本训练而成,在多类卫星影像云检测中均实现了90%以上的识别精度,展现出较好的鲁棒性,为通用的卫星云检测模型设计提供参考。
但是,目前本研究只针对国产卫星中的GF-1,GF-2及GF-5影像开展了实验,今后的研究重点是将模型应用于更多类型的国产卫星数据,逐步优化完善尽早提出满足业务化生产需求的通用模型。
猜你喜欢
军民两用技术与产品(2021年10期)2021-11-25
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·新策略(2019年10期)2019-12-13
科学家(2019年3期)2019-08-18
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
科学与财富(2016年28期)2016-10-14
电视技术(2014年19期)2014-03-11
